英伟达最新GPU和互联路线图分析

Nvidia在计算、网络和图形领域独树一帜,其显著优势在于雄厚的资金实力及在生成式人工智能市场的领先地位。凭借卓越的架构、工程和供应链,Nvidia能够自由实施创新路线图,引领行业未来。
到 21 世纪,Nvidia 已经是一个非常成功的创新者,它实际上没有必要扩展到数据中心计算领域。但 HPC 研究人员将 Nvidia 带入了加速计算领域,然后 AI 研究人员利用 GPU 计算创造了一个全新的市场,这个市场已经等待了四十年,希望以合理的价格实现大量计算,并与大量数据碰撞,真正让越来越像思考机器的东西成为现实。
向 Danny Hillis、Marvin Minksy 和 Sheryl Handler 致敬,他们在 20 世纪 80 年代尝试制造这样的机器,当时他们创立了 Thinking Machines 来推动 AI 处理,而不是传统的 HPC 模拟和建模应用程序,以及 Yann LeCun,他当时在 AT&T 贝尔实验室创建了卷积神经网络。他们既没有数据,也没有计算能力来制造我们现在所知道的 AI。当时,Jensen Huang 是 LSI Logic 的董事,该公司生产存储芯片,后来成为 AMD 的 CPU 设计师。就在 Thinking Machines 在 20 世纪 90 年代初陷入困境(并最终破产)时,黄仁勋在圣何塞东侧的 Denny's 与 Chris Malachowsky 和Curtis Priem 会面,他们创立了 Nvidia。正是 Nvidia 看到了来自研究和超大规模社区的新兴人工智能机遇,并开始构建系统软件和底层大规模并行硬件,以实现自第一天起就一直是计算一部分的人工智能革命梦想。
这一直是计算的最终状态,也是我们一直在走向的奇点——或者可能是两极。如果其他星球上有生命,那么生命总会进化到这样一个地步:那个世界拥有大规模毁灭性武器,并且总会创造出人工智能。而且很可能是在同一时间。
在那一刻之后,那个世界对这两种技术的处理方式决定了它能否在大规模灭绝事件中幸存下来。
这听起来可能不像是讨论芯片制造商发展路线图的正常开场白。事实并非如此,因为我们生活在一个有趣的时代。
在台北举行的年度 Computex 贸易展上,Nvidia 的联合创始人兼首席执行官在主题演讲中再次试图将生成式人工智能革命(他称之为第二次工业革命)置于其背景中,并一窥人工智能的未来,尤其是 Nvidia 硬件的未来。
我们获得了 GPU 和互连路线图的预览,据我们所知,这是直到最后一刻才列入计划的一部分,黄仁勋和他的主题演讲通常都是这样。
革命不可避免
生成式人工智能的关键在于规模,黄仁勋提醒我们这一点,并指出 2022 年底的 ChatGPT 时刻之所以会发生,只有出于技术和经济原因。
要实现 ChatGPT 的突破,需要大幅提高 GPU 的性能,然后在此基础上增加大量 GPU。Nvidia 确实实现了性能,这对于 AI 训练和推理都很重要,而且重要的是,它大大减少了生成大型语言模型响应中的 token 所需的能量。请看一看: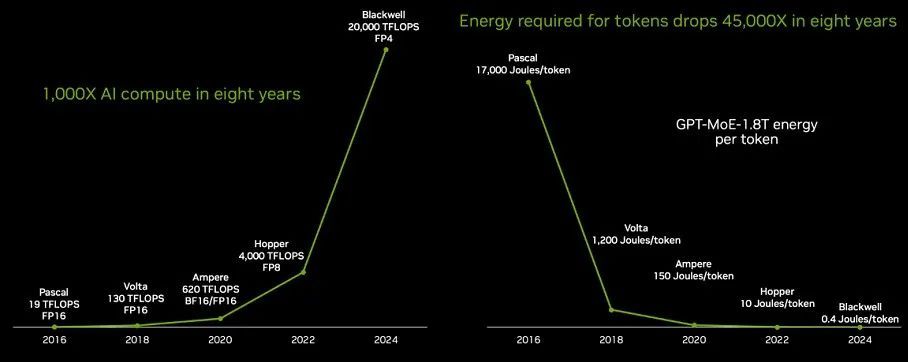
从“Pascal” P100 GPU 一代到“Blackwell” B100 GPU 一代,八年间 GPU 的性能提升了 1053 倍,后者将于今年晚些时候开始出货,并将持续到 2025 年。(我们知道图表上说的是 1000 倍,但这并不准确。)
部分性能是通过降低浮点精度来实现的——降低了 4 倍,从 Pascal P100、Volta V100 和 Ampere A100 GPU 中的 FP16 格式转变为 Blackwell B100s 中使用的 FP4 格式。如果没有这种精度的降低,性能提升将只有 263 倍,而这不会对 LLM 性能造成太大影响——这要归功于数据格式、软件处理和硬件中的大量数学魔法。请注意,对于 CPU 市场的八年来说,这已经相当不错了,每个时钟的核心性能提高 10% 到 15%,核心数量增加 25% 到 30% 都是正常的。如果升级周期为两年,那么在同样的八年里,CPU 吞吐量将增加 4 到 5 倍。
如上所示,每单位工作量的功耗降低是一个关键指标,因为如果你无法为系统供电,你就无法使用它。令牌的能源成本必须降低,这意味着 LLM 产生的每令牌能源的降低速度必须快于性能的提高。
在他的主题演讲中,为了给你提供更深入的背景知识,在 Pascal P100 GPU 上生成一个 token 需要 17000 焦耳的能量,这大致相当于点亮两个灯泡两天,平均每个单词需要大约三个 token。所以如果你要生成很多单词,那就需要很多灯泡!现在你开始明白为什么八年前甚至不可能以能够使其在任务上表现良好的规模运行 LLM。看看在 1.8 万亿个参数 8 万亿个 token 数据驱动模型的情况下训练 GPT-4 专家混合模型 LLM 所需的能力:
P100 集群的耗电量超过 1000 千兆瓦时,这真是太惊人了。
黄仁勋解释说,借助 Blackwell GPU,公司将能够在约 10,000 个 GPU 上用大约 10 天的时间来训练这个 GPT-4 1.8T MoE 模型。
如果人工智能研究人员和 Nvidia 没有转向降低精度,那么在这八年的时间里性能提升只会是 250 倍。
降低能源成本是一回事,降低系统成本又是另一回事。在传统摩尔定律的末期,两者都是非常困难的技巧,因为每 18 到 24 个月晶体管就会缩小一次,芯片变得越来越便宜、越来越小。现在,计算复合体已经达到光罩极限,每个晶体管都变得越来越昂贵——因此,由晶体管制成的设备本身也越来越昂贵。HBM 内存是成本的很大一部分,先进封装也是如此。
在 SXM 系列 GPU 插槽中(非 PCI-Express 版本的 GPU),P100 的发布价约为 5,000 美元;V100 的发布价约为 10,000 美元;A100 的发布价约为 15,000 美元;H100 的发布价约为 25,000 至 30,000 美元。B100 的预计售价在 35,000 至 40,000 美元之间——黄仁勋本人在今年早些时候接受CNBC采访时曾表示,Blackwell 的价格是这个数字。
黄仁勋没有展示的是,每一代需要多少 GPU 来运行 GPT-4 1.8T MoE 基准测试,以及这些 GPU 或电力在运行时的成本是多少。因此,我们根据黄所说的需要大约 10,000 个 B100 来训练 GPT-4 1.8T MoE 大约十天,制作了一个电子表格: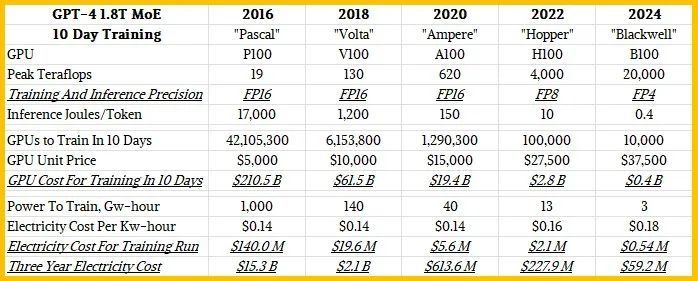
在这八年中,GPU 价格上涨了 7.5 倍,但性能却提高了 1,000 多倍。因此,现在可以想象使用 Blackwell 系统在十天左右的时间内训练出具有 1.8 万亿个参数的大型模型,比如 GPT-4,而两年前 Hopper 一代刚开始时,也很难在数月内训练出具有数千亿个参数的模型。现在,系统成本将与该系统两年的电费相当。(GPU 约占 AI 训练系统成本的一半,因此购买 10,000 个 GPU 的 Blackwell 系统大约需要 8 亿美元,运行十天的电费约为 540,000 美元。如果购买更少的 GPU,您可以减少每天、每周或每月的电费,但您也会相应增加训练时间,这会使成本再次上涨。)
你不可能赢,但你也不能放弃。
猜猜怎么着?Nvidia 也做不到。所以就是这样。即使 Hopper H100 GPU 平台是“历史上最成功的数据中心处理器”,正如黄仁勋在 Computex 主题演讲中所说,Nvidia 也必须继续努力。
附注:我们很乐意将 Hopper/Blackwell 的这次投资周期与六十年前 IBM System/360 的发布进行比较,正如我们去年所解释的那样,当时 IBM 做出了至今仍是企业历史上最大的赌注。1961 年,当 IBM 启动其“下一个产品线”研发项目时,它是一家年收入 22 亿美元的公司,在整个 60 年代花费超过 50 亿美元。蓝色巨人是华尔街第一家蓝筹公司,正是因为它花费了两年的收入和二十年的利润来创建 System/360。是的,它的一些部分有些晚了,表现也不佳,但它彻底改变了企业数据处理的性质。IBM 认为它可能会在 60 年代后期带来 600 亿美元的销售额(以我们调整后的 2019 年美元计算),但他们的销售额只有 1,390 亿美元,利润约为 520 亿美元。
Nvidia 无疑为数据中心计算的第二阶段掀起了更大的浪潮。那么现在真正的赢家可能被称为绿色芯片公司(green chip company)吗?
抵抗是徒劳的
无论是 Nvidia 还是其竞争对手或客户都无法抵挡未来的引力以及生成性人工智能带来的利润和生产力承诺,而这种承诺不仅仅是在我们耳边低语,更是在屋顶上大声呼喊。
因此,Nvidia 将加快步伐,突破极限。凭借 250 亿美元的银行存款和今年预计超过 1000 亿美元的收入,以及可能再有 500 亿美元的银行存款,它有能力突破极限,带领我们走向未来。
“在这一惊人增长时期,我们希望确保继续提高性能,继续降低成本——训练成本、推理成本——并继续扩展 AI 功能以供每家公司使用。我们越提高性能,成本下降得就越厉害。”
正如我们上面所列的表格清楚表明的那样,这是事实。
这给我们带来了更新的 Nvidia 平台路线图: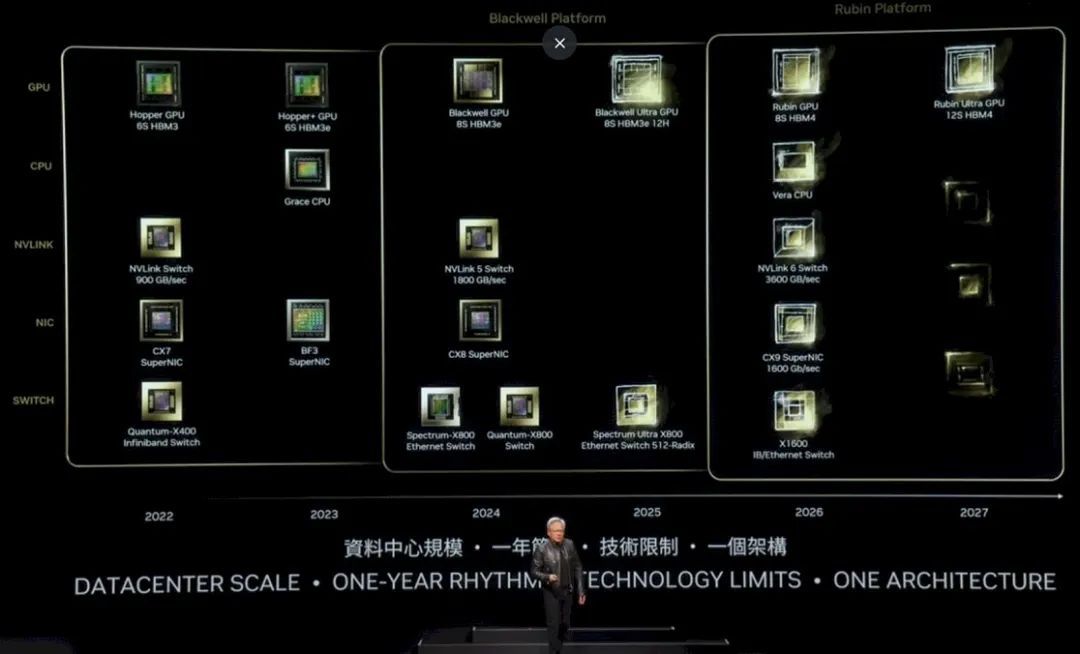
这有点难读,所以让我们仔细研究一下。
在 Hopper 一代中,最初的 H100 于 2022 年推出,具有六层 HBM3 内存,并配有一个具有 900 GB/秒端口的 NVSwitch 将它们连接在一起,并配有 Quantum X400(以前称为 Quantum-2)InfiniBand 交换机,具有 400 Gb/秒端口和 ConnectX-7 网络接口卡。2023 年,H200 升级为六层 HBM3E 内存,具有更高的容量和带宽,这提高了 H200 封装中底层 H100 GPU 的有效性能。BlueField 3 NIC 也问世了,它为 NIC 添加了 Arm 内核,以便它们可以执行附加工作。
2024 年,Blackwell GPU 当然会推出八层 HBM3e 内存,并与具有 1.8 TB/秒端口的 NVSwitch 5、800 Gb/秒 ConnectX-8 NIC 以及具有 800 GB/秒端口的 Spectrum-X800 和 Quantum-X800 交换机配对。
我们现在可以看到,到 2025 年,B200(上图称为 Blackwell Ultra)将拥有 8 堆叠 HBM3e 内存,每叠有 12 个die高。B100 中的叠层大概是 8 堆叠,因此这应该代表 Blackwell Ultra 上的 HBM 内存容量至少增加 50%,甚至可能更多,具体取决于所使用的 DRAM 容量。
HBM3E 内存的时钟速度也可能更高。Nvidia 对 Blackwell 系列的内存容量一直含糊其辞,但我们在 3 月份 Blackwell 发布会上估计,B100 将拥有 192 GB 内存和 8 TB/秒带宽。随着未来的 Blackwell Ultra 的推出,我们预计会有更快的内存,如果看到 288 GB 内存和 9.6 TB/秒带宽,我们也不会感到惊讶。
Nvidia 还将在 2025 年推出更高基数的 Spectrum-X800 以太网交换机,可能配备六个 ASIC,以创建无阻塞架构,就像其他交换机通常做的那样,将总带宽翻倍,从而使每个端口的带宽或交换机的端口数量翻倍。
2026 年,我们将看到“Rubin” R100 GPU,它在去年发布的 Nvidia 路线图中曾被称为 X100,正如我们当时所说,我们认为 X 是一个变量,而不是任何东西的缩写。事实证明确实如此。Rubin GPU 将使用 HBM4 内存,并将有 8 个堆栈,大概每个堆栈都有 12 个 DRAM,而 2027 年的 Rubin Ultra GPU 将有 12 个 HBM4 内存堆栈,并且可能还有更高的堆栈(尽管路线图没有提到这一点)。
我们要等到 2026 年,也就是当前“Grace”CPU 的后续产品“Vera”CPU 问世时,Nvidia 才会推出一款更强大的 Arm 服务器 CPU。NVSwitch 6 芯片与这些芯片配对,端口速度为 3.6 TB/秒,ConnectX-9 的端口速度为 1.6 Tb/秒。有趣的是,还有一种名为 X1600 IB/以太网交换机的产品,这可能意味着 Nvidia 正在融合其 InfiniBand 和以太网 ASIC,就像 Mellanox 十年前所做的那样。
或者,这可能意味着 Nvidia 试图让我们所有人都感到好奇,只是为了好玩。2027 年还有其他迹象表明,这可能意味着超级以太网联盟将完全支持 NIC 和交换机,甚至可能使用 UALink 交换机将节点内和跨机架将 GPU 连接在一起。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-
相关文章:
英伟达最新GPU和互联路线图分析
Nvidia在计算、网络和图形领域独树一帜,其显著优势在于雄厚的资金实力及在生成式人工智能市场的领先地位。凭借卓越的架构、工程和供应链,Nvidia能够自由实施创新路线图,引领行业未来。 到 21 世纪,Nvidia 已经是一个非常成功的创…...

Github 2024-06-10 开源项目日报 Top10
根据Github Trendings的统计,今日(2024-06-10统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量C项目2Go项目2PHP项目1Blade项目1TypeScript项目1Lua项目1Dart项目1Swift项目1Cuda项目1Python项目1MDX项目1Ventoy: 100%开源的可启动USB解决方…...

前后端分离项目中Spring Boot返回的时间与前端相差8个小时
概述 今天在做一个前后端分离项目时,发现从后端获取的时间与从数据库获取的时间相差八个小时,最终排查后发现由于Springboot使用本地时区导致,修改SpringBoot时区后解决 环境 MySQL8SpringBoot 原因排查 发现从后端获取的数据总是比前端快八个小时 …...

stm32MP135裸机编程:使用USB/UART烧录程序到SD卡并从SD卡启动点亮一颗LED灯
0 参考资料 轻松使用STM32MP13x - 如MCU般在cortex A核上裸跑应用程序.pdf STM32CubeProgrammer v2.16.0 烧录需要的二进制文件1 烧录到SD卡需要哪些文件 参考《轻松使用STM32MP13x - 如MCU般在cortex A核上裸跑应用程序》,烧录需要的SD卡文件如下: &a…...

【NoSQL数据库】Redis Cluster集群(含redis集群扩容脚本)
Redis Cluster集群 Redis ClusterRedis 分布式扩展之 Redis Cluster 方案功能数据如何进行存储 redis 集群架构集群伸缩向集群中添加一个新的master节点,并向其中存储 num10 .脚本对redis集群扩容缩容,脚本参数为redis集群,固定从6001移动200…...
重邮计算机网络803-(2)物理层
一.物理层 1.介绍 物理层的主要任务描述为确定与传输媒体的接口的一些特性,即: ①机械特性 指明接口所用接线器的形状和尺寸、引线数目和排列、固定和锁定装置等等。 ②电气特性 指明在接口电缆的各条线上出现的电压的范围。 ③功能特性 指明某条线上…...

uniapp使用webview内嵌H5的注意事项
一、描述 uniapp项目中构建app,需要内嵌H5页面,在使用webview时,遇到了以下几个问题: 内嵌H5,默认全屏显示;内嵌页面遮挡住了app的自定义tabbar组件;样式修改无效; 二、解决方案&a…...

现代 C++的高效并发编程模式
现代C提供了许多高效的并发编程模式,以满足日益增长的多核和分布式系统的需求。以下是一些常用的高效并发编程模式: 异步编程:使用std::async来创建异步任务,可以在后台执行任务,将结果返回给调用者。 并行编程&#…...
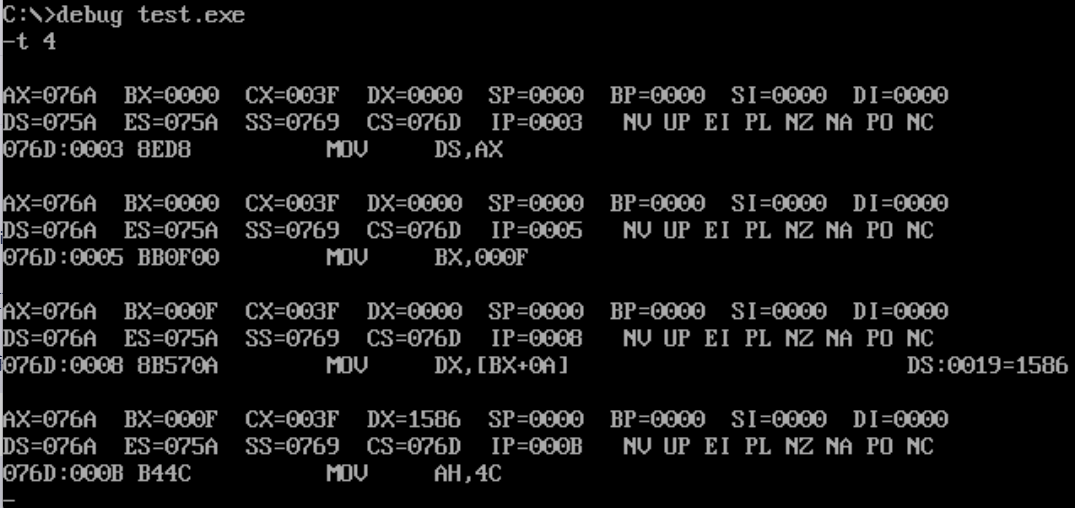
汇编语言作业(五)
目录 一、实验目的 二、实验内容 三、实验步骤以及结果 四、实验结果与分析 五、 实验总结 一、实验目的 1.熟悉掌握汇编语言的程序结构,能正确书写数据段、代码段等 2,利用debug功能,查看寄存器(CS,IP,AX,DS..)及数据段的…...
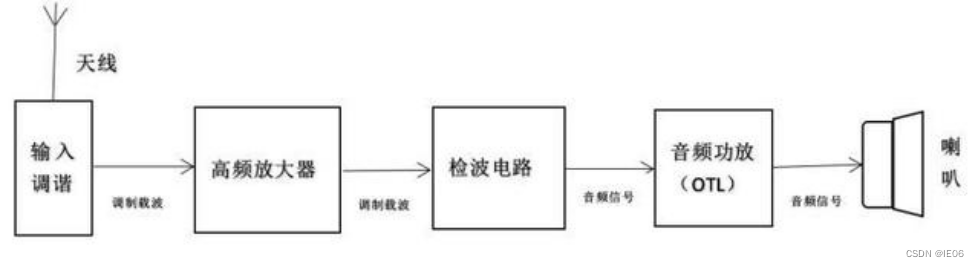
收音机的原理笔记
1. 收音机原理 有线广播:我们听到的声音是通过空气振动进行传播,因此可以通过麦克风(话筒)将这种机械振动转换为电信号,传到远处,再重新通过扬声器(喇叭)转换为机械振动,…...

排序算法案例
排序算法概述 排序算法是计算机科学中的一个重要主题,用于将一组数据按特定顺序排列。排序算法有很多种,每种算法在不同情况下有不同的性能表现。不同的排序算法适用于不同的场景和数据特征。在选择排序算法时,需要考虑数据规模、数据分布以…...

时间序列评价指标
评价指标 均方误差( M S E MSE MSE) 定义:预测值与实际值之间差异的平方和的平均值。公式: ( M S E 1 n ∑ i 1 n ( y i − y ^ i ) 2 ) (MSE \frac{1}{n}\sum_{i1}^{n}(y_i - \hat{y}_i)^2) (MSEn1∑i1n(yi−y^i)…...
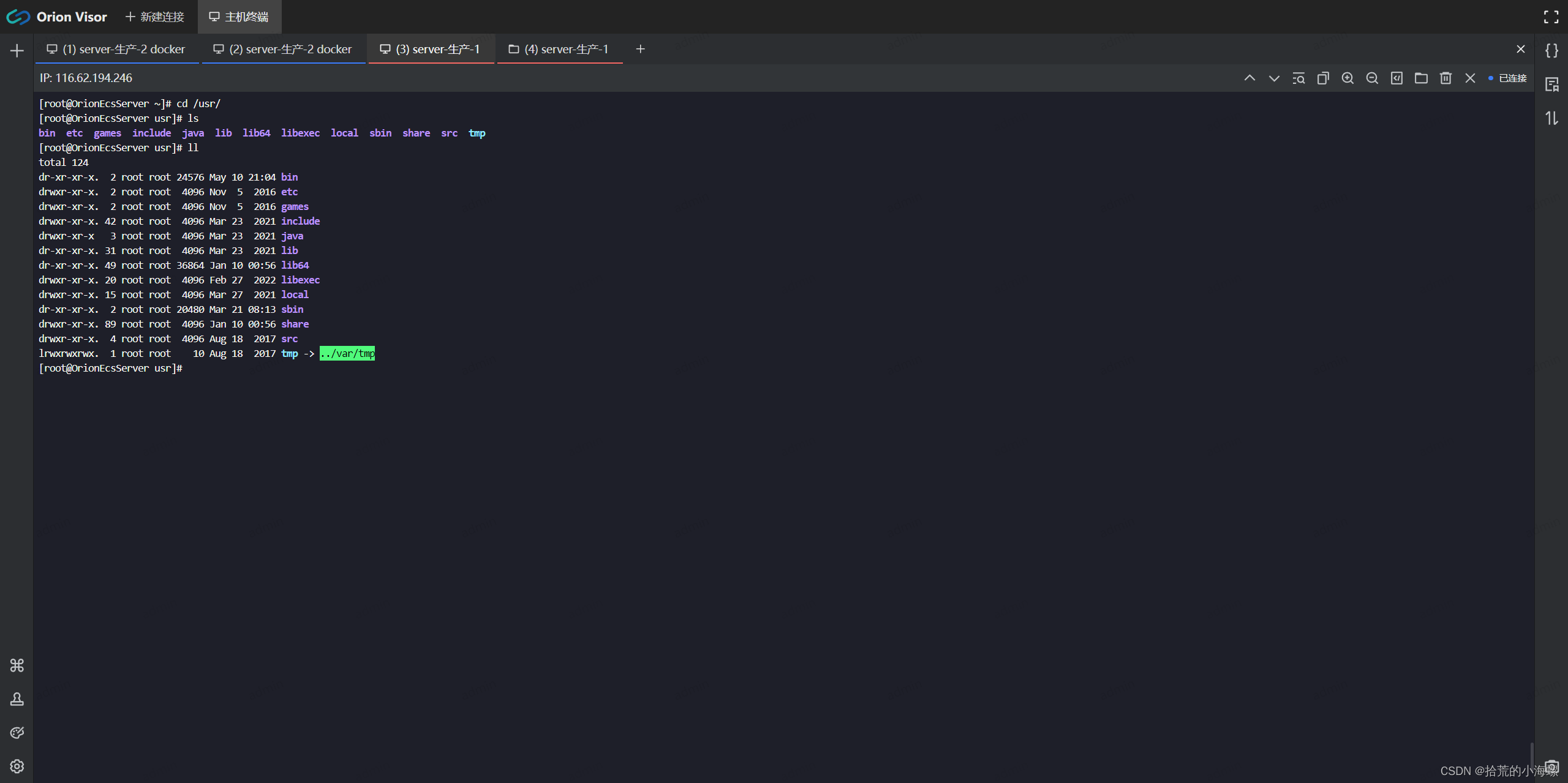
Docker:安装 Orion-Visor 服务器运维的技术指南
请关注微信公众号:拾荒的小海螺 博客地址:http://lsk-ww.cn/ 1、简述 Orion-Visor 是一种用于管理和监控容器的工具。它提供了一个直观的界面,用于查看容器的状态、资源使用情况以及日志等信息。在这篇技术博客中,我们将介绍如何…...
HarmonyOS Next 系列之底部标签栏TabBar实现(三)
系列文章目录 HarmonyOS Next 系列之省市区弹窗选择器实现(一) HarmonyOS Next 系列之验证码输入组件实现(二) HarmonyOS Next 系列之底部标签栏TabBar实现(三) 文章目录 系列文章目录前言一、实现原理二、…...
mac怎么录制屏幕?这2个方法你值得拥有
在数字化时代,屏幕录制已经成为一种常见且重要的工具,无论是教学演示、游戏直播还是会议记录,屏幕录制都发挥着不可或缺的作用。对于Mac用户而言,如何高效、便捷地进行屏幕录制,是一个值得探讨的话题,可是很…...

爱德华三坐标软件ACdmis.AC-dmis密码注册机
爱德华三坐标软件 AC-DMIS 是一款功能强大的三坐标测量软件,具有以下特点: • 支持多种测量模式:包括接触式测量、非接触式测量、复合式测量等,可以满足不同类型工件的测量需求。 • 高精度测量:采用先进的测量算法和…...

计算机网络 期末复习(谢希仁版本)第3章
对于点对点的链路,目前使用得最广泛的数据链路层协议是点对点协议 PPP (Point-to-Point Protocol)。局域网的传输媒体,包括有线传输媒体和无线传输媒体两个大类,那么有线传输媒体有同轴电缆、双绞线和光纤;无线传输媒体有微波、红…...

代码随想录——数组
给定一个n个元素有序(升序)的整型数组nums和一个目标值target,写一个函数搜索nums中的target,如果目标值存在返回下标,否则返回-1. //这个题说实话从逻辑上来看实在是太简单了,但是为什么每一次我写起来都感…...
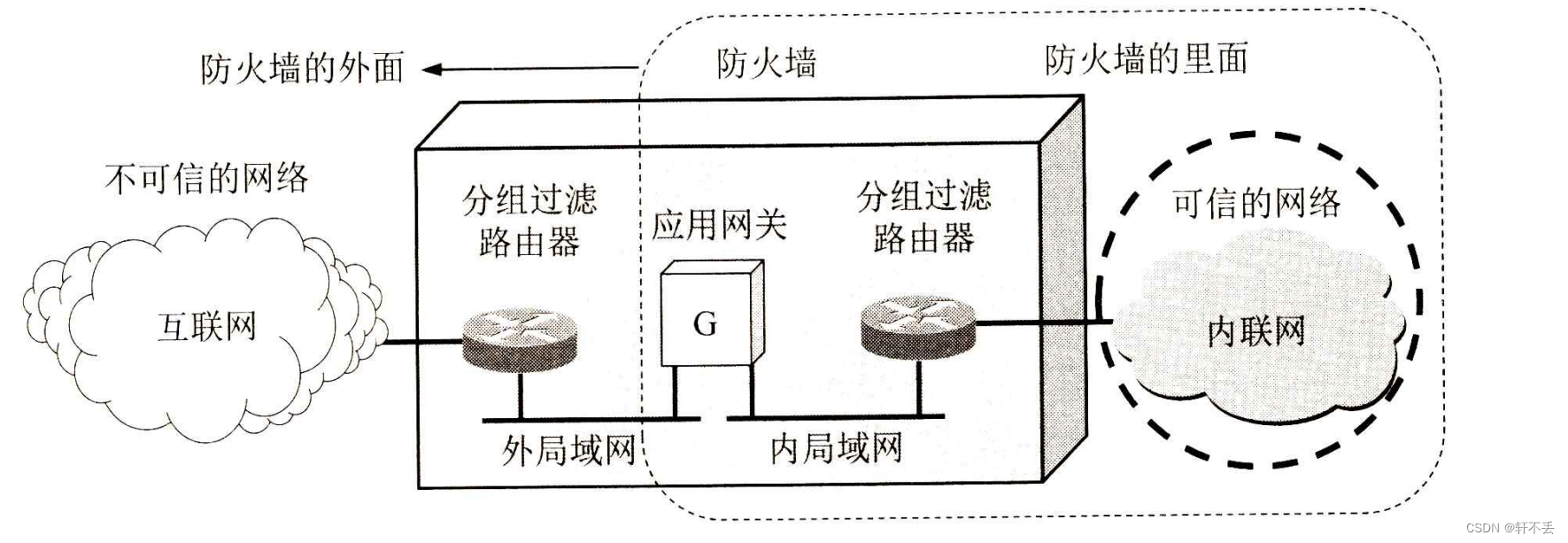
计算机网络7——网络安全4 防火墙和入侵检测
文章目录 一、系统安全:防火墙与入侵检测1、防火墙1)分组过滤路由器2)应用网关也称为代理服务器(proxy server), 二、一些未来的发展方向 一、系统安全:防火墙与入侵检测 恶意用户或软件通过网络对计算机系统的入侵或攻击已成为当今计算机安…...

html+CSS+js部分基础运用20
根据下方页面效果如图1所示,编写程序,代码放入图片下方表格内 图1.效果图 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" conte…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信
文章目录 Linux C语言网络编程详细入门教程:如何一步步实现TCP服务端与客户端通信前言一、网络通信基础概念二、服务端与客户端的完整流程图解三、每一步的详细讲解和代码示例1. 创建Socket(服务端和客户端都要)2. 绑定本地地址和端口&#x…...