【MyBatis-plus】saveBatch 性能调优和【MyBatis】的数据批量入库
总结最优的两种方法:
方法1:
使用了【MyBatis-plus】saveBatch 但是数据入库效率依旧很慢,那可能是是因为JDBC没有配置,saveBatch 批量写入并没有生效哦!!!
详细配置如下:批量数据入库:rewriteBatchedStatements=true
# 数据源master:driver-class-name: org.postgresql.Driverurl: jdbc:postgresql://127.0.0.1:5444/mxpt_business_databases?useUnicode=true&characterEncoding=utf8¤tSchema=public&stringtype=unspecified&rewriteBatchedStatements=trueusername: postgrespassword: postgresschema: public
方法2:
使用【MyBatis】进行数据的批量入库:拼接sql语句,每1000条数据入库一次。
@Overridepublic String insertBoundValueListToDatabase(List<ResourceCalcSceneBoundValue> list){//1.先删除原有场次和工程的数据,再进行导入ResourceCalcSceneBoundValue gongkuangValue = list.get(0);Long scprodId = gongkuangValue.getScprodId();Long gongkuangId = gongkuangValue.getBoundId();List<ResourceCalcSceneBoundValue> listValue = resourceCalcSceneBoundValueMapper.selectResourceCalcSceneBoundValueList(gongkuangValue);if(listValue != null && listValue.size() > 0){resourceCalcSceneBoundValueMapper.deleteBoundValueByScprodIdAndBoundId(scprodId, gongkuangId);}//2.将结果插入到数据库中if (list.size() > 0) {//条数为1if(list.size() == 1){resourceCalcSceneBoundValueMapper.insertResourceCalcSceneBoundValueList(list.subList(0, 1));}//由于数据库对于插入字段的限制,在这里对批量插入的数据进行分批处理int batchCount = 120;//每批commit的个数int batchLastIndex = batchCount - 1;// 每批最后一个的下标for (int index = 0; index < list.size() - 1; ) {if (batchLastIndex > list.size() - 1) {batchLastIndex = list.size() - 1;resourceCalcSceneBoundValueMapper.insertResourceCalcSceneBoundValueList(list.subList(index, batchLastIndex + 1));break;// 数据插入完毕,退出循环} else {resourceCalcSceneBoundValueMapper.insertResourceCalcSceneBoundValueList(list.subList(index, batchLastIndex + 1));index = batchLastIndex + 1;// 设置下一批下标batchLastIndex = index + (batchCount - 1);}}return "边界过程数据入库成功! 条数为:"+list.size()+"条。 ";}return "数据条数为0。";}
xml代码:
<insert id="insertResourceCalcSceneBoundValueList" parameterType="java.util.List" useGeneratedKeys="false">INSERT INTO resource_calc_scene_bound_value(scprod_id, bound_id, tm, flow, water, kurong, inq, stcd, remark, jp, kaidu, kgnum)VALUES<foreach collection="list" item="item" index="index" separator=",">(#{item.scprodId,jdbcType=INTEGER},#{item.boundId,jdbcType=INTEGER},#{item.tm,jdbcType=TIMESTAMP},#{item.flow,jdbcType=NUMERIC},#{item.water,jdbcType=NUMERIC},#{item.kurong,jdbcType=NUMERIC},#{item.inq,jdbcType=NUMERIC},#{item.stcd,jdbcType=VARCHAR},#{item.remark,jdbcType=VARCHAR},#{item.jp,jdbcType=NUMERIC},#{item.kaidu,jdbcType=NUMERIC},#{item.kgnum,jdbcType=INTEGER})</foreach></insert>
参考博客:
https://www.cnblogs.com/natee/p/17428877.html
大神总结的超级详细!!!
一起学习!!!
发现接口处理速度慢的有点超出预期,感觉很奇怪,后面定位发现是数据库批量保存这块很慢。
这个项目用的是 mybatis-plus,批量保存直接用的是 mybatis-plus 提供的 saveBatch。 我点进去看了下源码,感觉有点不太对劲:
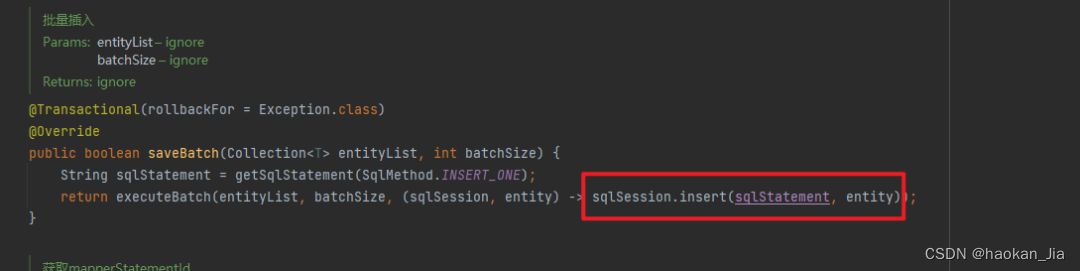
继续追踪了下,从这个代码来看,确实是 for 循环一条一条执行了 sqlSession.insert,下面的 consumer 执行的就是上面的 sqlSession.insert:
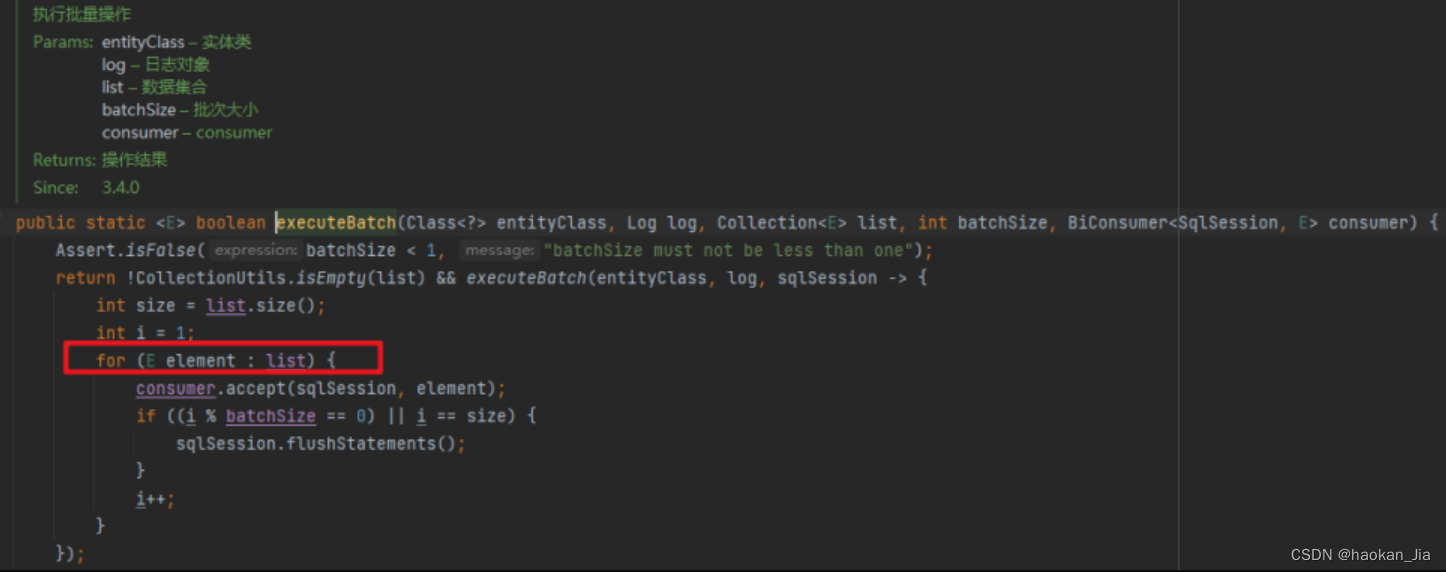
然后累计一定数量后,一批 flush。从这点来看,这个 saveBach 的性能肯定比直接一条一条 insert 快。
1、1000条数据,一条一条插入
@Test
void MybatisPlusSaveOne() {SqlSession sqlSession = sqlSessionFactory.openSession();try {StopWatch stopWatch = new StopWatch();stopWatch.start("mybatis plus save one");for (int i = 0; i < 1000; i++) {OpenTest openTest = new OpenTest();openTest.setA("a" + i);openTest.setB("b" + i);openTest.setC("c" + i);openTest.setD("d" + i);openTest.setE("e" + i);openTest.setF("f" + i);openTest.setG("g" + i);openTest.setH("h" + i);openTest.setI("i" + i);openTest.setJ("j" + i);openTest.setK("k" + i);//一条一条插入openTestService.save(openTest);}sqlSession.commit();stopWatch.stop();log.info("mybatis plus save one:" + stopWatch.getTotalTimeMillis());} finally {sqlSession.close();}
}

可以看到,执行一批 1000 条数的批量保存,耗费的时间是 121011 毫秒。
2、1000条数据用 mybatis-plus 自带的 saveBatch 插入
@Test
void MybatisPlusSaveBatch() {SqlSession sqlSession = sqlSessionFactory.openSession();try {List<OpenTest> openTestList = new ArrayList<>();for (int i = 0; i < 1000; i++) {OpenTest openTest = new OpenTest();openTest.setA("a" + i);openTest.setB("b" + i);openTest.setC("c" + i);openTest.setD("d" + i);openTest.setE("e" + i);openTest.setF("f" + i);openTest.setG("g" + i);openTest.setH("h" + i);openTest.setI("i" + i);openTest.setJ("j" + i);openTest.setK("k" + i);openTestList.add(openTest);}StopWatch stopWatch = new StopWatch();stopWatch.start("mybatis plus save batch");//批量插入openTestService.saveBatch(openTestList);sqlSession.commit();stopWatch.stop();log.info("mybatis plus save batch:" + stopWatch.getTotalTimeMillis());} finally {sqlSession.close();}
}

耗费的时间是 59927 毫秒,比一条一条插入快了一倍,从这点来看,效率还是可以的。
然后常见的还有一种利用拼接 SQL 方式来实现批量插入,我们也来对比试试看性能如何。
3、1000 条数据用手动拼接 SQL 方式插入, 搞个手动拼接:

来跑跑下性能如何:
@Test
void MapperSaveBatch() {SqlSession sqlSession = sqlSessionFactory.openSession();try {List<OpenTest> openTestList = new ArrayList<>();for (int i = 0; i < 1000; i++) {OpenTest openTest = new OpenTest();openTest.setA("a" + i);openTest.setB("b" + i);openTest.setC("c" + i);openTest.setD("d" + i);openTest.setE("e" + i);openTest.setF("f" + i);openTest.setG("g" + i);openTest.setH("h" + i);openTest.setI("i" + i);openTest.setJ("j" + i);openTest.setK("k" + i);openTestList.add(openTest);}StopWatch stopWatch = new StopWatch();stopWatch.start("mapper save batch");//手动拼接批量插入openTestMapper.saveBatch(openTestList);sqlSession.commit();stopWatch.stop();log.info("mapper save batch:" + stopWatch.getTotalTimeMillis());} finally {sqlSession.close();}
}

耗时只有 2275 毫秒,性能比 mybatis-plus 自带的 saveBatch 好了 26 倍!
这时,我又突然回想起以前直接用 JDBC 批量保存的接口,那都到这份上了,顺带也跑跑看!
4、1000 条数据用 JDBC executeBatch 插入
@Test
void JDBCSaveBatch() throws SQLException {SqlSession sqlSession = sqlSessionFactory.openSession();Connection connection = sqlSession.getConnection();connection.setAutoCommit(false);String sql = "insert into open_test(a,b,c,d,e,f,g,h,i,j,k) values(?,?,?,?,?,?,?,?,?,?,?)";PreparedStatement statement = connection.prepareStatement(sql);try {for (int i = 0; i < 1000; i++) {statement.setString(1,"a" + i);statement.setString(2,"b" + i);statement.setString(3, "c" + i);statement.setString(4,"d" + i);statement.setString(5,"e" + i);statement.setString(6,"f" + i);statement.setString(7,"g" + i);statement.setString(8,"h" + i);statement.setString(9,"i" + i);statement.setString(10,"j" + i);statement.setString(11,"k" + i);statement.addBatch();}StopWatch stopWatch = new StopWatch();stopWatch.start("JDBC save batch");statement.executeBatch();connection.commit();stopWatch.stop();log.info("JDBC save batch:" + stopWatch.getTotalTimeMillis());} finally {statement.close();sqlSession.close();}
}

耗时是 55663 毫秒,所以 JDBC executeBatch 的性能跟 mybatis-plus 的 saveBatch 一样(底层一样)。
综上所述,拼接 SQL 的方式实现批量保存效率最佳。
但是我又不太甘心,总感觉应该有什么别的法子,然后我就继续跟着 mybatis-plus 的源码 debug 了一下,跟到了 MySQL 的驱动,突然发现有个 if 里面的条件有点显眼: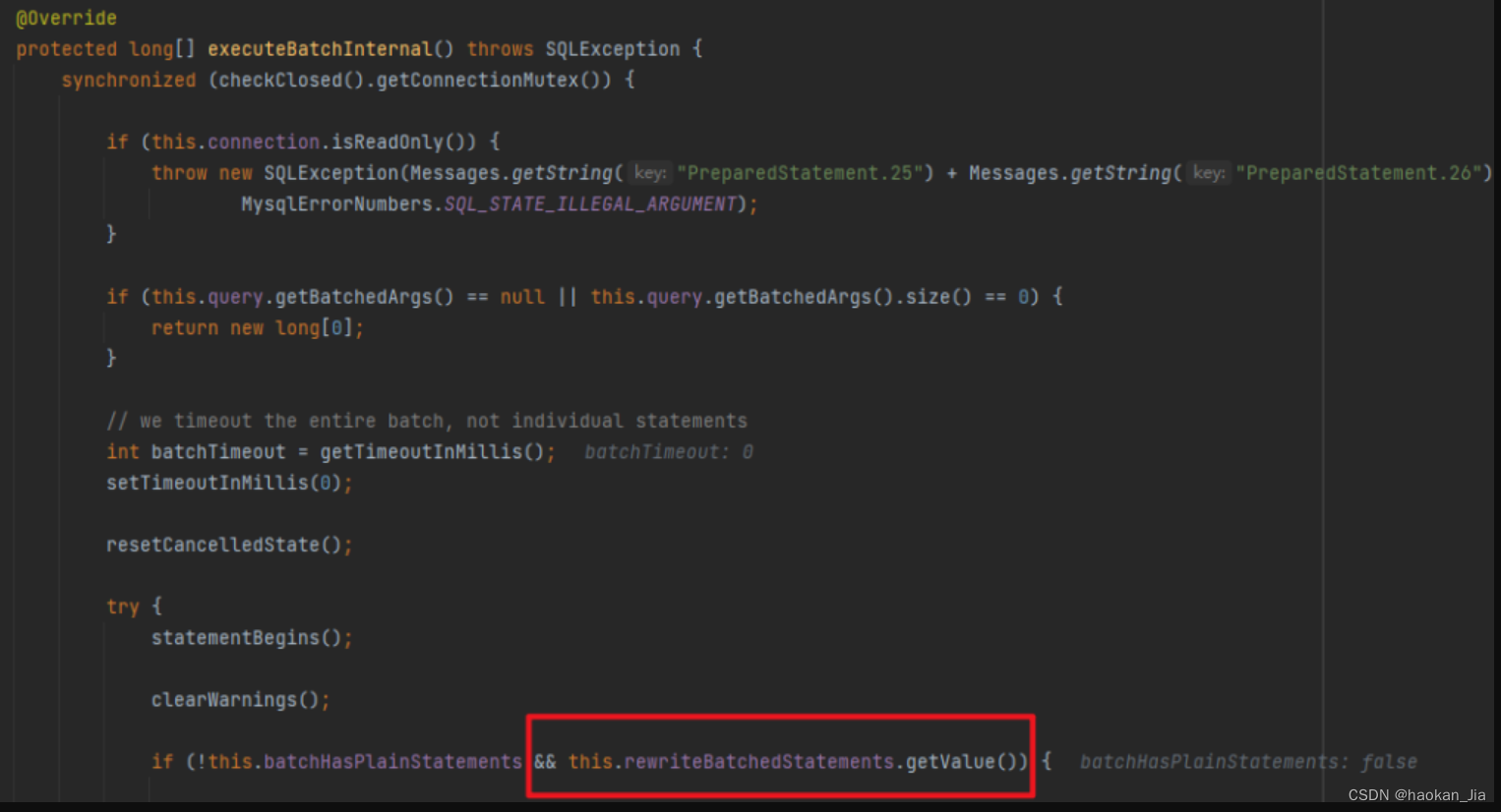
就是这个叫 rewriteBatchedStatements 的玩意,从名字来看是要重写批操作的 Statement,前面batchHasPlainStatements 已经是 false,取反肯定是 true,所以只要这参数是 true 就会进行一波操作。
我看了下默认是 false。
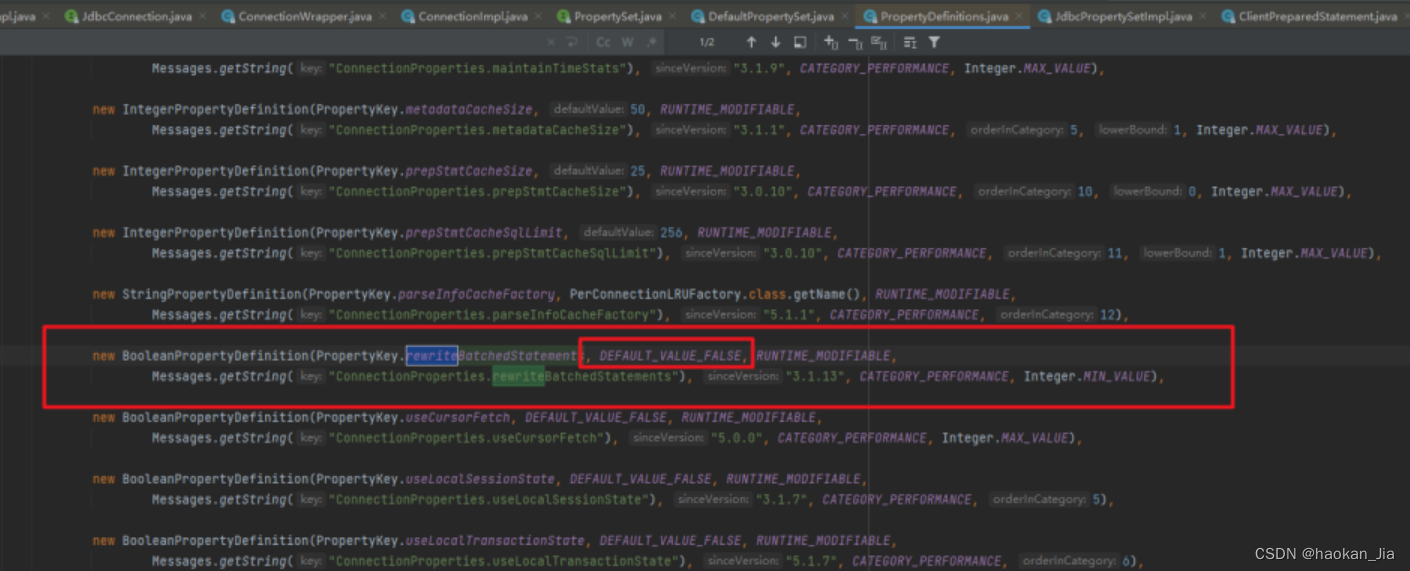
直接将 jdbcurl 加上了这个参数:

然后继续跑了下 mybatis-plus 自带的 saveBatch,果然性能大大提高,跟拼接 SQL 差不多!

然后我继续 debug ,来探探 rewriteBatchedStatements 究竟是怎么 rewrite 的! 如果这个参数是 true,则会执行下面的方法且直接返回:

看下 executeBatchedInserts 究竟干了什么:

看到上面我圈出来的代码没,好像已经有点感觉了,继续往下 debug。
果然!SQL 语句被 rewrite了:
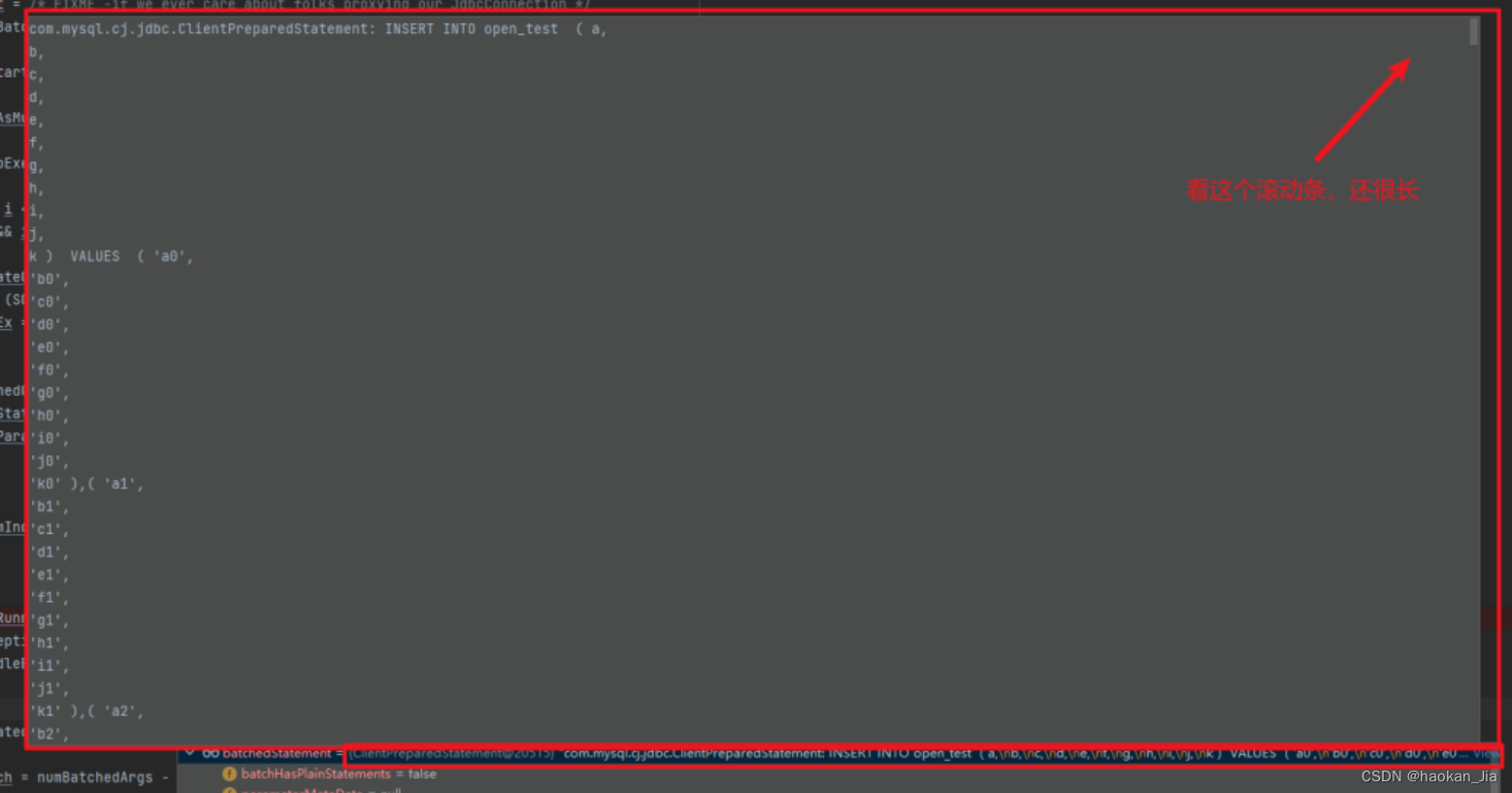
对插入而言,所谓的 rewrite 其实就是将一批插入拼接成 insert into xxx values (a),(b),©…这样一条语句的形式然后执行,这样一来跟拼接 SQL 的效果是一样的。
那为什么默认不给这个参数设置为 true 呢?主要有以下两点:
如果批量语句中的某些语句失败,则默认重写会导致所有语句都失败。
批量语句的某些语句参数不一样,则默认重写会使得查询缓存未命中。
看起来影响不大,所以我给我的项目设置上了这个参数!
最后
稍微总结下我粗略的对比(虽然粗略,但实验结果符合原理层面的理解),如果你想更准确地做实验,可以使用 JMH,并且测试更多组数(如 5000,10000等)的情况。
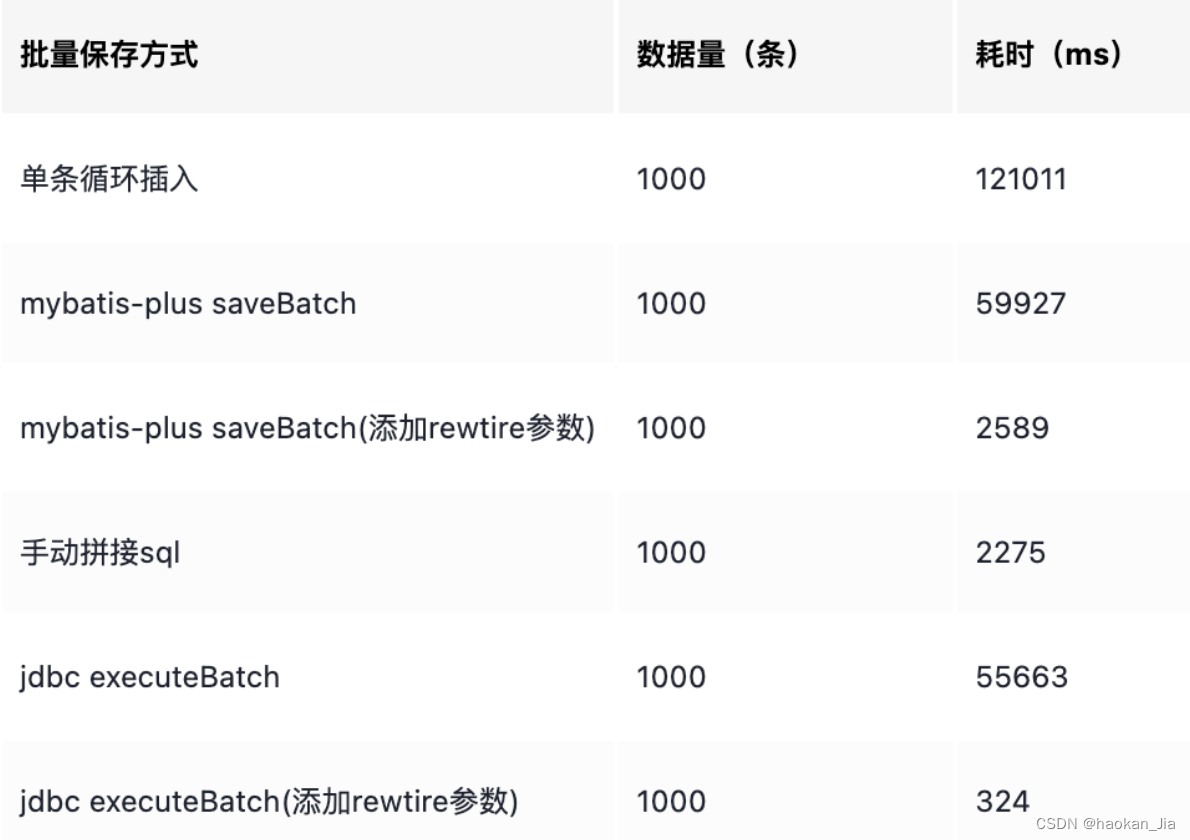
所以如果有使用 JDBC 的 Batch 性能方面的需求,要将 rewriteBatchedStatements 设置为 true,这样能提高很多性能。
然后如果喜欢手动拼接 SQL 要注意一次拼接的数量,分批处理。
相关文章:
【MyBatis-plus】saveBatch 性能调优和【MyBatis】的数据批量入库
总结最优的两种方法: 方法1: 使用了【MyBatis-plus】saveBatch 但是数据入库效率依旧很慢,那可能是是因为JDBC没有配置,saveBatch 批量写入并没有生效哦!!! 详细配置如下:批量数据入…...

前端三剑客之JavaScript基础入门
目录 ▐ 快速认识JavaScript ▐ 基本语法 🔑JS脚本写在哪? 🔑注释 🔑变量如何声明? 🔑数据类型 🔑运算符 🔑流程控制 ▐ 函数 ▐ 事件 ▐ 计时 ▐ HTML_DOM对象 * 建议学习完HTML和CSS后再…...

Fyndiq买家号下单:自养号测评如何打造本土物理环境系统?
Fyndiq 是一个瑞典电子商务平台,我们通过该平台为渴望讨价还价的购物者提供一系列产品。该公司为希望以可访问的方式提高销售额的所有类型的零售商提供销售渠道。Fyndiq几乎是瑞典家喻户晓的存在,是瑞典折扣促销平台。以销售质优价廉的商品吸引了大量忠实…...
自动检测曲别针数量:图像处理技术的应用
引言 在这篇博客中,我们将探讨如何使用计算机视觉技术自动检测图像中曲别针的数量。 如图: [1]使用灰度转换 由于彩色信息对于曲别针计数并不重要,我们将图像转换为灰度图,这样可以减少处理数据的复杂度,加速后续的…...
【Git】多人协作 -- 详解
一、多人协作(1) ⽬前,我们所完成的工作如下: 基本完成 Git 的所有本地库的相关操作,git 基本操作,分支理解,版本回退,冲突解决等等。 申请码云账号,将远端信息 clone…...

Eureka和Nacos有哪些区别?
Eureka和Nacos都能起到注册中心的作用,用法基本类似。但还是有一些区别的,例如: Nacos支持配置管理,而Eureka则不支持。 而且服务注册发现上也有区别,我们来做一个实验: 我们停止user-service服务&#x…...

如何正确使用 include-what-you-use
简单地说,由 Google 开发的 include-what-you-use(IWYU)让源代码文件包含代码里用到的所有头文件。这种方法确保在改动了一些接口之后,代码依然最有可能编译成功。 之前我写了一篇关于 include-what-you-use 工具的文章ÿ…...

企业内网安全软件分享,有什么内网安全软件
内网安全? 其实就是网络安全的一种。 什么是内网安全软件? 内网安全软件是企业保障内网安全的一种重要工具。 它主要帮助企业实现对网络设备、应用程序、用户行为等方面的监控和管理,以预防和应对各种网络攻击。 这类软件主要用于对内网中…...

【摘葡萄game】
您想要了解的“摘葡萄游戏”可能是一个编程项目或者是一个编程相关的练习。我可以提供一个简单的摘葡萄游戏的思路和代码示例。这个游戏可以用多种编程语言来实现,比如Python、Java等。这里我以Python为例,给出一个基础版本的摘葡萄游戏的概念和代码。 …...

java如何实现字符串连接
在java中,字符串与字符串连接可以用运算符和 比如有字符串a,字符串b 想要把a和b连接起来,定义一个字符串变量c cab 或者 ab 示例代码 public class Zifuchuanlianjie {public static void main(String[] args) {String a"我叫李狗蛋";S…...

流量卡选卡攻略,拯救不会选流量卡的小白!
家人们,你们知道不,选择一款性价比高的流量卡,真的超级省钱。 一、首先,说一说申请。 运营商推出线上流量卡,注意是线上的流量卡,都是免费领取,运营商包邮到家,在激活充值之前不…...

python class __format__ __bytes__区别
在Python中,__format__和__bytes__是两个特殊方法,它们允许对象自定义它们在特定情境下的字符串表示。以下是这两个方法的区别和作用: __format__ 作用:__format__方法用于定义对象在使用format()函数或格式化字符串(…...

C++ | Leetcode C++题解之第134题加油站
题目: 题解: class Solution { public:int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {int n gas.size();int i 0;while (i < n) {int sumOfGas 0, sumOfCost 0;int cnt 0;while (cnt < n) {int j (i …...
【Linux】ls命令
这个命令主要是用于显示指定工作目录下之内容(列出目前工作目录所含的文件及子目录)。 掌握几个重点的常使用的就可以: ls -l # 以长格式显示当前目录中的文件和目录 ls -a # 显示当前目录中的所有文件和目录&am…...

多态、虚函数表与动态绑定的深入解析
目录 多态简介 虚函数表与动态绑定 虚函数表 动态绑定机制 内存与性能影响 纯虚函数与抽象类 纯虚函数 抽象类 动态类型转换与typeid操作符 dynamic_cast typeid操作符 虚析构函数的重要性 在面向对象编程中,多态性是一种核心特性,它允许我们…...

VitePress+Docker+jenkins构建个人网站
VitePress官网 VitePress | 由 Vite 和 Vue 驱动的静态站点生成器 可以理解为一个前端脚手架:快速生成个人站点 最好先大概看一遍 快速开始 | VitePress 可以在线体验一下 安装条件 node -v 检查下node版本 在D盘创建一个文件夹 例如:VitePress 进入文件夹 cmd npm ini…...

Windows11下Docker使用记录(五)
目录 准备1. WSL安装cuda container toolkit2. win11 Docker Desktop 设置3. WSL创建docker container并连接cuda4. container安装miniconda(可选) Docker容器可以从底层虚拟化,使我们能够在 不降级 CUDA驱动程序的情况下使用 任何版本的CU…...
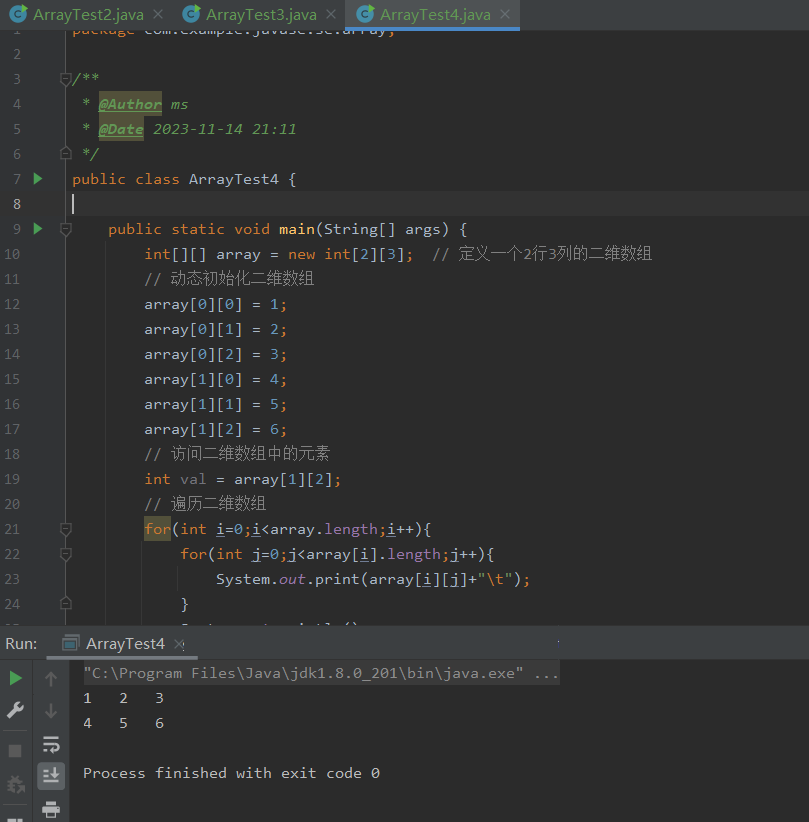
快速学习Java的多维数组技巧
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一…...

C语言运算类型有哪些
C语言中的运算类型主要分为以下几类: 1. 算术运算符: - 加法运算符 - 减法运算符 - - 乘法运算符 * - 除法运算符 / - 取模运算符 %(取余数) 2. 关系运算符: - 大于 > - 小于 < - 大…...

【深度学习】Loss为Nan的可能原因
文章目录 1. 问题情境2. 原因分析3. 导致Loss为Nan的其他可能原因 1. 问题情境 在某个网络架构下,我为某个数据项引入了一个损失函数。 这个数据项是nn.Embedding类型的,我加入的损失函数是对nn.Embedding空间做约束。 因为我在没加入优化loss前&#x…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...