使用TensorFlow和Keras对以ResNet50模型进行微调
以下是使用ResNet50进行微调以识别特定的新东西的代码演示。将使用TensorFlow和Keras进行这个任务。
数据集下载地址,解压到工程里面去:
https://www.kaggle.com/datasets/marquis03/cats-and-dogs
原始代码:
```
from keras.applications import ResNet50
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Model
from keras import models
from keras.layers import Dense, GlobalAveragePooling2D, Dropout
from keras.optimizers import Adam
import os# 加载ResNet50模型,并去掉顶层
base_model = ResNet50(weights='imagenet', include_top=False)# 添加自定义顶层
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
x = Dropout(0.5)(x) # 添加Dropout层以防止过拟合
predictions = Dense(2, activation='softmax')(x) # 用于二分类任务,输出层有两个神经元model = Model(inputs=base_model.input, outputs=predictions)# 冻结大部分卷积层,只训练顶层
for layer in base_model.layers:layer.trainable = False# 编译模型
model.compile(optimizer=Adam(learning_rate=0.01), # 调整学习率loss='categorical_crossentropy', # 使用categorical_crossentropy损失函数metrics=['accuracy'])# 假设数据存储在train_data_dir和validation_data_dir中,并且每个类有一个文件夹
train_data_dir = 'D:\\py\\tvr_search_py\\robot\\test\\catanddog\\train' # 替换为实际路径
validation_data_dir = 'D:\\py\\tvr_search_py\\robot\\test\\catanddog\\val' # 替换为实际路径
img_height, img_width = 224, 224
batch_size = 32# 检查目录是否存在
if not os.path.exists(train_data_dir):raise ValueError(f"训练数据目录不存在: {train_data_dir}")
if not os.path.exists(validation_data_dir):raise ValueError(f"验证数据目录不存在: {validation_data_dir}")train_datagen = ImageDataGenerator(rescale=1. / 255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1. / 255)train_generator = train_datagen.flow_from_directory(train_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical') # 用于二分类任务validation_generator = test_datagen.flow_from_directory(validation_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical') # 用于二分类任务# 确保steps_per_epoch和validation_steps不为零
if train_generator.samples == 0:raise ValueError(f"训练数据目录中没有找到图像: {train_data_dir}")
if validation_generator.samples == 0:raise ValueError(f"验证数据目录中没有找到图像: {validation_data_dir}")steps_per_epoch = max(1, train_generator.samples // batch_size)
validation_steps = max(1, validation_generator.samples // batch_size)epochs = 10 # 增加训练轮数model.fit(train_generator,steps_per_epoch=steps_per_epoch,validation_data=validation_generator,validation_steps=validation_steps,epochs=epochs)# model.summary()
# model.save('D:\\py\\tvr_search_py\\robot\\test\\model\\resnet50_model.keras')# 解冻部分或全部的卷积层并继续训练
#
for layer in base_model.layers[:]:layer.trainable = True
#
model.compile(optimizer=Adam(learning_rate=0.0001), # 用较低的学习率loss='categorical_crossentropy',metrics=['accuracy'])
#
model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=validation_generator,validation_steps=validation_generator.samples // batch_size,epochs=20)# # 再次保存模型
model.save('D:\\py\\tvr_search_py\\robot\\test\\model\\resnet50_finetuned_model.keras')
#
# # 加载模型
loaded_model = models.load_model('D:\\py\\tvr_search_py\\robot\\test\\model\\resnet50_finetuned_model.keras')
#
# # 打印模型结构
loaded_model.summary()
解析
-
安装必要的库:
pip3 install tensorflow keras -
导入库:
import tensorflow as tf from tensorflow.keras.applications import ResNet50 from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, GlobalAveragePooling2D from tensorflow.keras.optimizers import Adam -
加载ResNet50模型,并去掉顶层:
base_model = ResNet50(weights='imagenet', include_top=False) -
添加自定义顶层:
x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(num_classes, activation='softmax')(x) # `num_classes`是新数据集的类别数model = Model(inputs=base_model.input, outputs=predictions) -
冻结base_model的所有卷积层:
for layer in base_model.layers:layer.trainable = False -
编译模型:
model.compile(optimizer=Adam(learning_rate=0.001),loss='categorical_crossentropy',metrics=['accuracy']) -
准备数据:
假设数据存储在train_data_dir和validation_data_dir中,并且每个类有一个文件夹。train_data_dir = 'path_to_train_data' validation_data_dir = 'path_to_validation_data' img_height, img_width = 224, 224 batch_size = 32train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical')validation_generator = test_datagen.flow_from_directory(validation_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='categorical') -
训练模型:
epochs = 10model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=validation_generator,validation_steps=validation_generator.samples // batch_size,epochs=epochs) -
解冻部分或全部的卷积层并继续训练:
for layer in base_model.layers[:]:layer.trainable = Truemodel.compile(optimizer=Adam(learning_rate=0.0001), # 用较低的学习率loss='categorical_crossentropy',metrics=['accuracy'])model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=validation_generator,validation_steps=validation_generator.samples // batch_size,epochs=10)
在这段代码中,“添加自定义顶层”是指在预训练的ResNet50模型的基础上,增加一些新的层,这些层专门用于处理分类任务。ResNet50模型预先在ImageNet数据集上进行了训练,但它的输出层是针对ImageNet的1000个类别的。在微调过程中,希望将它应用到一个新的数据集,这个数据集的类别数可能不同,因此需要添加新的顶层来适应这个新的任务。
以下是这个过程的详细解释:
-
去掉顶层:首先,加载预训练的ResNet50模型,并去掉它的顶层(
include_top=False)。这样做的目的是只保留模型的卷积层部分,这些层已经在大量图像上学习到了很有用的特征。base_model = ResNet50(weights='imagenet', include_top=False) -
添加新的全局平均池化层:在base_model的输出之后,添加一个全局平均池化层(
GlobalAveragePooling2D)。这个层将把卷积层的输出转换成一个扁平的特征向量。x = base_model.output x = GlobalAveragePooling2D()(x) -
添加一个全连接层:接下来,添加一个全连接层(
Dense层),用于进一步处理特征向量。这个例子中,使用了一个具有1024个神经元和ReLU激活函数的全连接层。x = Dense(1024, activation='relu')(x) -
添加输出层:最后,添加一个输出层,这个层的神经元数目等于新数据集的类别数(
num_classes),并使用softmax激活函数来输出每个类别的概率。predictions = Dense(num_classes, activation='softmax')(x)num_classes是指在新的数据集中需要分类的类别数。它决定了最终输出层的神经元数量,每个神经元对应一个类别,并通过softmax激活函数输出每个类别的概率。以下是一个详细的解释和代码注释,帮助更好地理解这个概念:Detailed Explanation
In a classification task, the neural network aims to assign input images to one of several predefined categories. The number of these categories is called
num_classes. For example, if we are building a model to classify images of cats, dogs, and birds, thennum_classeswould be 3.在ResNet50的原始结构中,输出层的
num_classes是1000,因为它是在ImageNet数据集上预训练的,而ImageNet数据集包含1000个类别。如果希望用ResNet50模型来处理二分类任务(即只有两个类别),则需要将输出层的
num_classes改为1。但是,需要注意的是,在二分类任务中,通常会使用sigmoid激活函数而不是softmax激活函数。以下是将输出层改为适用于二分类任务的代码示例:
import tensorflow as tf from tensorflow.keras.applications import ResNet50 from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, GlobalAveragePooling2D from tensorflow.keras.optimizers import Adam# 加载ResNet50模型,并去掉顶层 base_model = ResNet50(weights='imagenet', include_top=False)# 添加自定义顶层 x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(1, activation='sigmoid')(x) # 用于二分类任务model = Model(inputs=base_model.input, outputs=predictions)# 冻结base_model的所有卷积层 for layer in base_model.layers:layer.trainable = False# 编译模型 model.compile(optimizer=Adam(learning_rate=0.001),loss='binary_crossentropy', # 使用binary_crossentropy损失函数metrics=['accuracy'])# 假设数据存储在train_data_dir和validation_data_dir中,并且每个类有一个文件夹 train_data_dir = 'path_to_train_data' # 替换为实际路径 validation_data_dir = 'path_to_validation_data' # 替换为实际路径 img_height, img_width = 224, 224 batch_size = 32train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory(train_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary') # 用于二分类任务validation_generator = test_datagen.flow_from_directory(validation_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary') # 用于二分类任务# 训练模型 epochs = 10model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=validation_generator,validation_steps=validation_generator.samples // batch_size,epochs=epochs)# 解冻部分或全部的卷积层并继续训练 for layer in base_model.layers[:]:layer.trainable = Truemodel.compile(optimizer=Adam(learning_rate=0.0001), # 用较低的学习率loss='binary_crossentropy',metrics=['accuracy'])model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=validation_generator,validation_steps=validation_generator.samples // batch_size,epochs=10)代码解释:
-
修改输出层:将输出层改为只有一个神经元,并使用
sigmoid激活函数。predictions = Dense(1, activation='sigmoid')(x) # 用于二分类任务 -
使用二分类损失函数:编译模型时,将损失函数设为
binary_crossentropy。model.compile(optimizer=Adam(learning_rate=0.001),loss='binary_crossentropy',metrics=['accuracy']) -
设置数据生成器的模式:将
class_mode设置为binary,以适应二分类任务。train_generator = train_datagen.flow_from_directory(train_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary')validation_generator = test_datagen.flow_from_directory(validation_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary')
-
-
创建新的模型:将新的顶层与base_model连接起来,创建一个新的完整模型。
model = Model(inputs=base_model.input, outputs=predictions) -
model.compile是Keras中用于配置模型的编译方法。它指定了优化器、损失函数和评估指标。具体解释如下:model.compile(optimizer=Adam(learning_rate=0.001),loss='binary_crossentropy', # 使用binary_crossentropy损失函数metrics=['accuracy'])参数解释
-
optimizer=Adam(learning_rate=0.001):optimizer: 指定用于训练模型的优化器。在这里使用的是Adam优化器,它是一种常用的、适合处理稀疏梯度的优化算法。learning_rate=0.001: 指定优化器的学习率,控制每次更新的步长大小。学习率是一个非常重要的超参数,它影响到模型收敛的速度和稳定性。
-
loss='binary_crossentropy':loss: 指定用于计算模型误差的损失函数。损失函数衡量模型预测值与真实值之间的差异,是模型训练的关键部分。binary_crossentropy: 二分类交叉熵损失函数,适用于二分类任务。该损失函数通过衡量实际标签和预测概率之间的交叉熵来计算误差。
-
metrics=['accuracy']:metrics: 指定评估模型性能的指标。在训练和评估过程中,这些指标将被计算并显示,以帮助评估模型的表现。accuracy: 准确率指标,表示模型预测正确的样本数占总样本数的比例。对于二分类任务,准确率是一个常用的评估指标。
-
-
具体的数据集应该具有以下结构:
-
训练数据目录 (
train_data_dir):-
该目录包含用于训练模型的图像数据,每个类别有一个单独的文件夹。
-
文件夹名称是类别标签。
-
note: train_data_dir = “…/to/path_to_train_data”
-
目录结构如下:
path_to_train_data/ ├── class1/ │ ├── image1.jpg │ ├── image2.jpg │ └── ... └── class2/├── image1.jpg├── image2.jpg└── ...
-
-
验证数据目录 (
validation_data_dir):-
该目录包含用于验证模型的图像数据,每个类别有一个单独的文件夹。
-
文件夹名称是类别标签。
-
note: train_data_dir = “…/to/path_to_validation_data”
-
目录结构如下:
path_to_validation_data/ ├── class1/ │ ├── image1.jpg │ ├── image2.jpg │ └── ... └── class2/├── image1.jpg├── image2.jpg└── ...
-
假设有一个包含猫和狗图像的数据集,训练和验证数据目录的结构可能如下:
训练数据目录 (
path_to_train_data)path_to_train_data/ ├── cats/ │ ├── cat1.jpg │ ├── cat2.jpg │ └── ... └── dogs/├── dog1.jpg├── dog2.jpg└── ...验证数据目录 (
path_to_validation_data)path_to_validation_data/ ├── cats/ │ ├── cat1.jpg │ ├── cat2.jpg │ └── ... └── dogs/├── dog1.jpg├── dog2.jpg└── ...在上述目录结构中:
cats文件夹包含所有猫的图像。dogs文件夹包含所有狗的图像。- 图像文件可以是任意名称,但通常使用.jpg、.png等常见图像格式。
-
-
代码解释
-
数据增强和预处理:
train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1./255)ImageDataGenerator:用于生成批次的图像数据,提供实时数据增强功能。它在训练时对图像进行随机变换,以增强模型的泛化能力。rescale=1./255:将图像的像素值缩放到0到1之间。原始像素值是0到255,缩放后有助于加速模型训练并提高准确率。shear_range=0.2:应用随机剪切变换,范围为0.2。这是一种几何变换,可以增加数据的多样性。zoom_range=0.2:应用随机缩放变换,范围为0.2。horizontal_flip=True:随机水平翻转图像。
-
训练和验证数据生成器:
train_generator = train_datagen.flow_from_directory(train_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary')validation_generator = test_datagen.flow_from_directory(validation_data_dir,target_size=(img_height, img_width),batch_size=batch_size,class_mode='binary')flow_from_directory:从目录中读取图像数据,并生成批次。这个方法会根据目录结构自动为图像分配标签。target_size=(img_height, img_width):将所有图像调整为指定的目标大小。在这个例子中,图像大小被调整为224x224像素。batch_size=batch_size:每个批次包含的图像数量。在这个例子中,批次大小为32。class_mode='binary':指定标签模式为二分类。对于二分类任务,标签是0或1。
-
-
代码解释
model.fit(train_generator,steps_per_epoch=train_generator.samples // batch_size,validation_data=validation_generator,validation_steps=validation_generator.samples // batch_size,epochs=epochs)参数解释
-
train_generator:- 这是之前定义的训练数据生成器,它从训练数据目录中批量生成增强后的图像数据和对应的标签。
-
steps_per_epoch=train_generator.samples // batch_size:steps_per_epoch:定义每个epoch需要执行的训练步骤数。在每个epoch中,模型会处理完所有训练数据一次。train_generator.samples:训练数据集中图像的总数。batch_size:每个批次包含的图像数量。train_generator.samples // batch_size:计算每个epoch中包含的批次数。这里使用整除操作,确保每个epoch处理完整的批次数。
-
validation_data=validation_generator:- 这是之前定义的验证数据生成器,它从验证数据目录中批量生成预处理后的图像数据和对应的标签,用于在训练过程中评估模型性能。
-
validation_steps=validation_generator.samples // batch_size:validation_steps:定义在每个epoch结束时需要执行的验证步骤数。validation_generator.samples:验证数据集中图像的总数。batch_size:每个批次包含的图像数量。validation_generator.samples // batch_size:计算每个epoch中包含的验证批次数,确保验证数据在每个epoch结束时得到充分评估。
-
epochs=epochs:epochs:训练的轮数,表示整个训练数据集将被处理的次数。
-
-
代码解释
for layer in base_model.layers[:]:layer.trainable = Truemodel.compile(optimizer=Adam(learning_rate=0.0001), # 用较低的学习率loss='binary_crossentropy',metrics=['accuracy'])参数解释
-
for layer in base_model.layers[:]:- 这个循环遍历
base_model的所有层。
- 这个循环遍历
-
layer.trainable = True- 将每一层的
trainable属性设置为True,表示这些层在训练过程中将被更新。 - 这种操作通常用于迁移学习的最后阶段,即在预训练模型的基础上进行微调。
- 将每一层的
-
model.compile-
optimizer=Adam(learning_rate=0.0001):- 使用Adam优化器进行梯度下降优化。
learning_rate=0.0001:设置学习率为0.0001,较低的学习率通常用于微调,以防止模型参数过大变化,导致模型性能下降。
-
loss='binary_crossentropy':- 损失函数使用二分类交叉熵损失,这在二分类任务中是常见的选择。
- 二分类交叉熵衡量模型预测的概率分布与实际标签之间的差异。
-
metrics=['accuracy']:- 使用准确率作为评价指标,表示模型在验证数据上的预测准确性。
-
-
-
model.compile的参数详细解释model.compile(optimizer=Adam(learning_rate=0.0001), # 用较低的学习率loss='binary_crossentropy',metrics=['accuracy'])optimizer
- Adam(learning_rate=0.0001):
- Adam: 一种自适应学习率优化算法,全称是Adaptive Moment Estimation。Adam结合了Momentum和RMSProp的优点,能更快地收敛并且更稳定。
- learning_rate=0.0001: 学习率,控制每次参数更新的步伐。0.0001 是一个较低的学习率,通常用于微调模型,以防止模型参数的剧烈变化,保持训练的稳定性。
loss
-
binary_crossentropy:
-
二分类交叉熵损失函数,常用于二分类问题。它度量的是预测的概率分布与实际标签之间的差异。公式如下:
Loss = − 1 N ∑ i = 1 N [ y i log ( p i ) + ( 1 − y i ) log ( 1 − p i ) ] \text{Loss} = -\frac{1}{N} \sum_{i=1}^{N} [y_i \log(p_i) + (1 - y_i) \log(1 - p_i)] Loss=−N1i=1∑N[yilog(pi)+(1−yi)log(1−pi)] -
其中,( y_i ) 是实际标签,( p_i ) 是预测概率,( N ) 是样本数。
-
metrics
-
accuracy:
- accuracy: 准确率,是最常用的评价指标之一。它表示预测正确的样本数占总样本数的比例。公式如下:
Accuracy = Number of correct predictions Total number of predictions \text{Accuracy} = \frac{\text{Number of correct predictions}}{\text{Total number of predictions}} Accuracy=Total number of predictionsNumber of correct predictions
- accuracy: 准确率,是最常用的评价指标之一。它表示预测正确的样本数占总样本数的比例。公式如下:
-
顶层(Top Layer)是什么
在深度学习模型,特别是卷积神经网络(CNN)中,顶层(Top Layer)指的是网络的最后几层,通常包括全连接层和输出层。这些层负责将前面卷积层提取到的特征映射到最终的分类结果或其他任务的输出。
示例
以VGG16模型为例,其顶层通常包括几个全连接层和一个输出层:
-
全连接层(Fully Connected Layer):
- 这些层接收来自卷积层的特征图,并通过全连接操作将这些特征映射到一个固定大小的向量。
-
输出层(Output Layer):
- 最后一层通常是一个全连接层,输出单元数目等于分类类别数。对于二分类问题,这一层的输出单元数为1,并使用Sigmoid激活函数。
在Keras中,
include_top=False意味着不包括这些顶层,只保留卷积层部分,这通常用于迁移学习,允许用户根据具体任务添加自定义的顶层结构。顶层的作用
-
特征变换:
- 将卷积层提取到的特征进行进一步处理和变换,以适应具体任务(如分类任务)。
-
输出预测:
- 最后一层输出预测结果,具体形式取决于任务类型(分类、回归等)。
-
-
全连接层(Fully Connected Layer)是什么
全连接层(Fully Connected Layer),也称作密集层(Dense Layer),是神经网络中一种基本的层类型。它的特点是每个神经元与上一层的所有神经元相连接。这种层通常用于卷积神经网络(CNN)中的最后几层,用于综合卷积层提取到的特征并进行最终的分类或回归任务。
全连接层的特征
-
连接方式:
- 全连接层中的每个神经元与上一层的所有神经元都有连接,这意味着这一层的每个输出单元都是前一层所有输入单元的加权求和。
-
权重和偏置:
- 每个连接都有一个权重,同时每个神经元还有一个偏置。通过训练,这些权重和偏置被不断调整,以最小化损失函数。
-
激活函数:
- 全连接层通常与激活函数一起使用,如ReLU、Sigmoid、Tanh等,以引入非线性,使模型能够拟合复杂的函数。
全连接层的作用
-
特征综合:
- 在卷积神经网络中,全连接层位于网络的末端,用于综合卷积层和池化层提取到的特征。
-
输出预测:
- 全连接层的最后一层通常是输出层,输出的单元数等于分类问题的类别数或者回归问题的目标数。
例子
下面是一个包含全连接层的简单神经网络结构:
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Flattenmodel = Sequential([# 输入层,假设输入是一个28x28的图像Flatten(input_shape=(28, 28)),# 第一个全连接层,128个神经元,使用ReLU激活函数Dense(128, activation='relu'),# 输出层,10个神经元,对应10个类别,使用Softmax激活函数Dense(10, activation='softmax') ])# 编译模型 model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# 打印模型结构 model.summary()在这个例子中:
-
Flatten层:- 将输入的28x28的图像展平成784个单位的向量,方便后续的全连接层处理。
-
第一个
Dense层:- 包含128个神经元,每个神经元与输入向量的所有单位相连接。使用ReLU激活函数引入非线性。
-
输出
Dense层:- 包含10个神经元,对应10个类别。使用Softmax激活函数将输出转换为概率分布,适用于多分类任务。
-
-
model = Model(inputs=base_model.input, outputs=predictions)中的inputs在深度学习中,使用 Keras 或 TensorFlow 框架定义和构建模型时,
inputs参数指的是模型的输入张量。这个张量描述了模型预期接收的数据的形状和类型。具体解释
model = Model(inputs=base_model.input, outputs=predictions)在这段代码中:
-
inputs=base_model.input:base_model: 这是一个预训练的模型实例,例如 VGG16、ResNet 等。base_model.input: 这是base_model模型的输入张量。它定义了模型期望接收的输入数据的形状。例如,如果base_model是 VGG16,那么base_model.input的形状通常是(None, 224, 224, 3),表示输入是形状为(224, 224, 3)的 RGB 图像,None表示批量大小可以是任意的。
-
outputs=predictions:predictions:这是在预训练模型基础上添加的自定义输出张量。它代表模型的最终输出,例如分类结果。
inputs` 的作用
- 定义输入形状:通过
inputs参数,明确告诉模型输入数据的形状和类型。这对于确保数据能够正确地通过模型的各层处理非常重要。 - 连接模型层次:在构建模型时,
inputs和outputs将模型的所有层次连接起来,从输入层到输出层。
-
-
模型的保存和加载
保存模型
-
保存整个模型:
这种方法保存了模型的结构、权重和训练配置(优化器、损失函数等)。可以直接加载并继续训练或进行推理。model.save('model_path.keras') -
保存模型的权重:
如果只需要保存模型的权重,可以使用save_weights方法。这种方法适合在模型架构不变的情况下进行权重的保存和加载。model.save_weights('model_weights.keras')
加载模型
-
加载整个模型:
可以使用load_model方法来加载之前保存的整个模型。from keras.models import load_model# 加载模型 model = load_model('model_path.keras') -
加载模型的权重:
如果只保存了模型的权重,需要先构建与保存时相同的模型架构,然后再加载权重。from tensorflow.keras.applications import ResNet50 from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, GlobalAveragePooling2D# 重新创建模型结构 base_model = ResNet50(weights=None, include_top=False, input_shape=(224, 224, 3)) x = base_model.output x = GlobalAveragePooling2D()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(1, activation='sigmoid')(x) model = Model(inputs=base_model.input, outputs=predictions)# 加载权重 model.load_weights('model_weights.keras')
-
-
在 TensorFlow Keras 中,加载模型的过程通常涉及两种不同的方法:加载本地保存的模型和从预训练模型库中下载模型。
#####加载本地保存的模型
当使用
model.save方法将模型保存到本地文件系统时,可以在后续的操作中从本地加载该模型。这种方式不需要每次都从网上下载。示例如下:#####保存模型
# 保存模型到本地文件系统 model.save('local_model_path.keras')#####加载模型
from tensorflow.keras.models import load_model# 从本地文件系统加载模型 model = load_model('local_model_path.keras')#####从预训练模型库中下载模型
当使用预训练模型,例如 ResNet50,并且指定
weights='imagenet'时,Keras 会从网上下载预训练的权重文件并缓存到本地目录(通常是~/.keras/models/)。一旦下载完成并缓存,就不需要每次重新下载。示例如下:加载预训练模型
from keras.applications import ResNet50# 加载预训练的 ResNet50 模型 base_model = ResNet50(weights='imagenet', include_top=False)缓存机制
Keras 使用的缓存机制会将下载的模型文件存储在本地用户目录下,以避免每次都重新下载。具体位置如下:
- Linux 和 MacOS:
~/.keras/models/ - Windows:
C:\Users\<username>\.keras\models\
在加载预训练模型时,如果缓存目录中已经存在所需的文件,Keras 会直接使用本地缓存文件。
- Linux 和 MacOS:
相关文章:

使用TensorFlow和Keras对以ResNet50模型进行微调
以下是使用ResNet50进行微调以识别特定的新东西的代码演示。将使用TensorFlow和Keras进行这个任务。 数据集下载地址,解压到工程里面去: https://www.kaggle.com/datasets/marquis03/cats-and-dogs原始代码: from keras.applications…...

Shell脚本要点和难点以及具体应用和优缺点介绍
Shell 脚本是一种用于自动化任务和简化常见系统命令的脚本语言,通常运行在 Unix 或 Unix-like 的系统上,如 Linux 和 macOS。Shell 脚本可以直接在命令行中执行,也可以保存为文件并通过 bash、sh、zsh 等 shell 解释器来执行。 以下是一个简单的 Shell 脚本示例,它演示了如…...

移动端浏览器的扫描二维码实现(vue-qrcode-reader与jsQR方式)
1. 实现功能 类似扫一扫的功能,自动识别到画面中的二维码并进行识别,也可以选择从相册中上传。 2. 涉及到的一些插件介绍 vue-qrcode-reader 一组用于检测和解码二维码的Vue.js组件 jsQR 一个纯粹的javascript二维码阅读库,该库接收原始…...

android中调用onnxruntime框架
创建空白项目 安装Android Studio及创建空白项目参考:【安卓Java原生开发学习记录】一、安卓开发环境的搭建与HelloWorld(详细图文解释)_安卓原生开发-CSDN博客 切记:build configuration language 一定选择Groovy!官…...
【机器学习】与【数据挖掘】技术下【C++】驱动的【嵌入式】智能系统优化
目录 一、嵌入式系统简介 二、C在嵌入式系统中的优势 三、机器学习在嵌入式系统中的挑战 四、C实现机器学习模型的基本步骤 五、实例分析:使用C在嵌入式系统中实现手写数字识别 1. 数据准备 2. 模型训练与压缩 3. 模型部署 六、优化与分析 1. 模型优化 模…...
Apollo9.0 PNC源码学习之Control模块(二)
前面文章:Apollo9.0 PNC源码学习之Control模块(一) 本文将对具体控制器以及原理做一个剖析 1 PID控制器 1.1 PID理论基础 如下图所示,PID各参数(Kp,Ki,Kd)的作用: 任何闭环控制系统的首要任务是要稳、准、快的响…...

直线度测量仪发展历程!
直线度测量仪的发展历程可以概括为以下几个关键阶段: 拉钢丝法: 早期直线度测量的简单直观方法,利用钢丝受重力自然下垂的原理来测量直线度误差。 随着机械设备的大型化和测量精度要求的提高,该方法逐渐无法满足要求,正…...
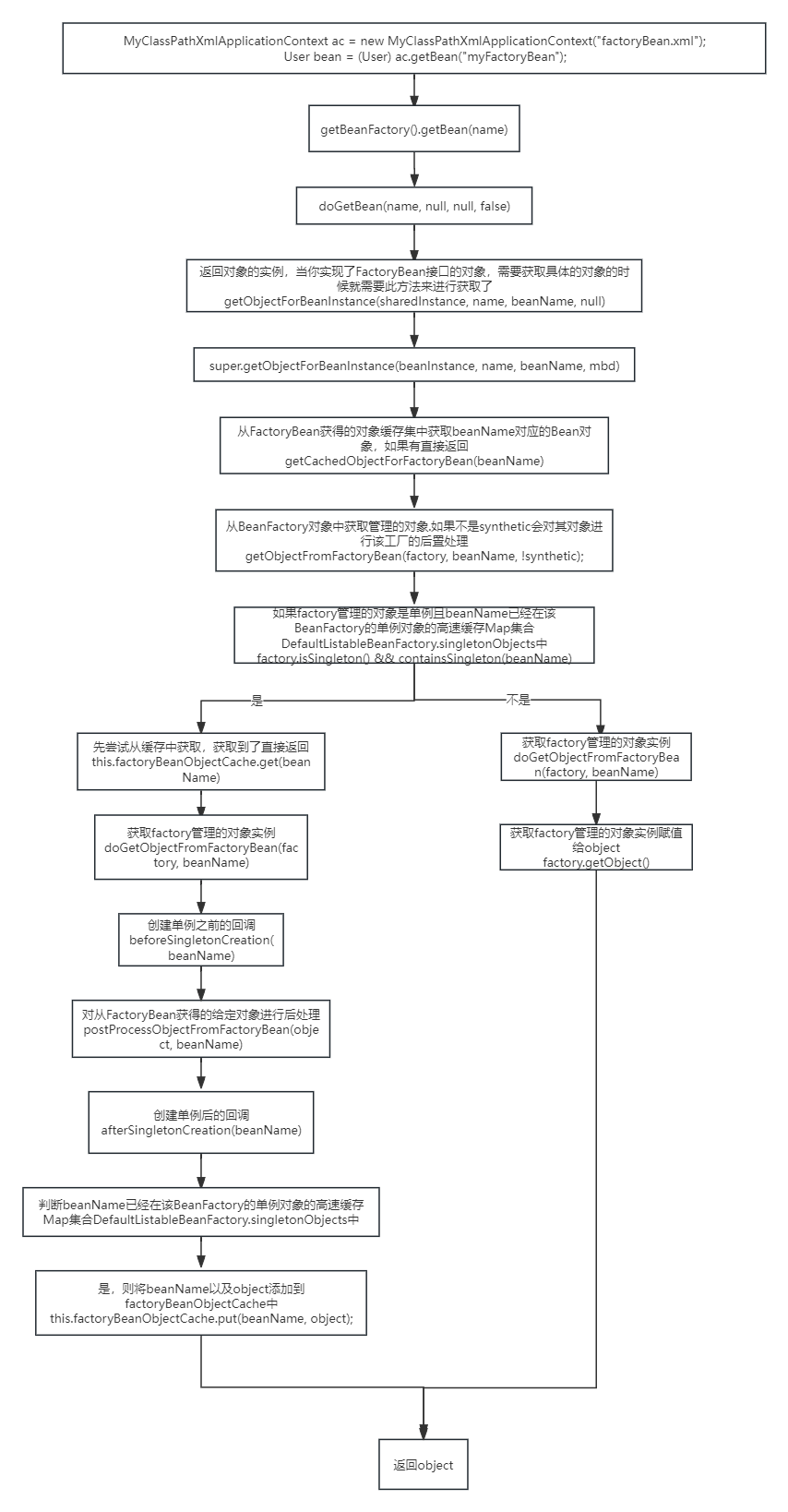
09-spring的bean创建流程(一)
文章目录 spring中bean的创建流程finishBeanFactoryInitialization(beanFactory)beanFactory.preInstantiateSingletons();getMergedLocalBeanDefinition(beanName);流程实现FactoryBean接口,里面的对象实例化过程 spring中bean的创建流程 finishBeanFactoryInitialization(be…...

spring中基于setting和构造器的注入方式
Spring中可以通过setting和构造器两种方式进行依赖注入。 1.基于setting的注入方式(Setter Injection): 实现方式:在类中添加对应的属性以及对应的setter方法,在配置文件中使用<property>元素进行注入。 示例代码…...

爬虫基本原理?介绍|实现|问题解决
爬虫基本原理: 模拟用户行为: 网络爬虫(Web Crawler)是一种自动化的程序,它模拟人类用户访问网站的方式,通过发送HTTP/HTTPS请求到服务器以获取网页内容。 请求与响应: 爬虫首先构建并发送带有…...
)
DevOps的原理及应用详解(六)
本系列文章简介: 在当今快速变化的商业环境中,企业对于软件交付的速度、质量和安全性要求日益提高。传统的软件开发和运维模式已经难以满足这些需求,因此,DevOps(Development和Operations的组合)应运而生&a…...
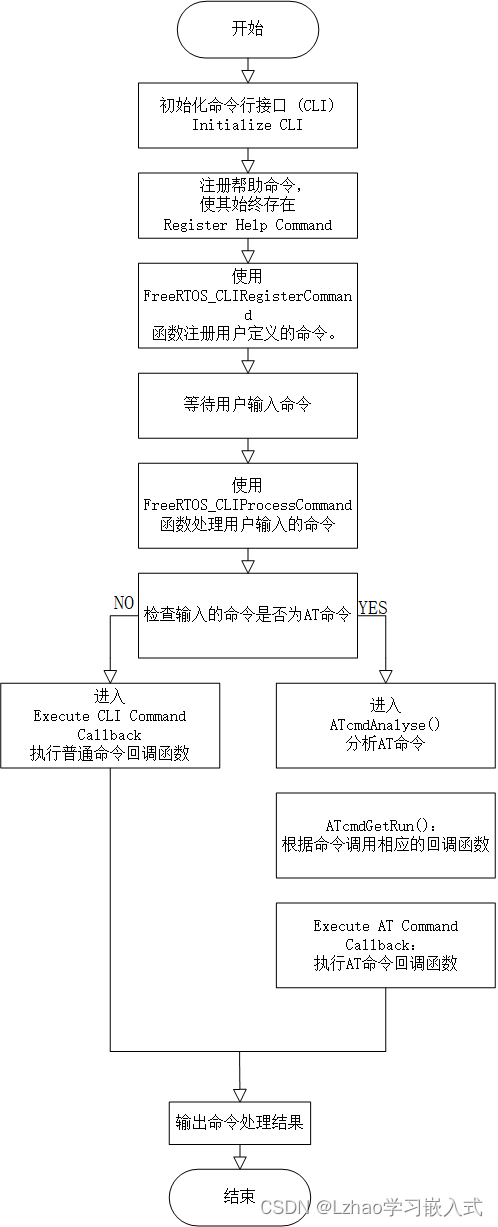
手撸 串口交互命令行 及 AT应用层协议解析框架
在嵌入式系统开发中,命令行接口(CLI)和AT命令解析是常见的需求。CLI提供了方便的调试接口,而AT命令则常用于模块间的通信控制。本文将介绍如何手动实现一个串口交互的命令行及AT应用层协议解析框架,适用于FreeRTOS系统…...

Redis几种部署模式介绍
Redis 提供了几种不同的部署模式,以满足不同的使用场景和可用性需求。这些模式包括单机模式、主从复制、哨兵模式和集群模式。下面我将简要介绍每种模式的特点和用途: 单机模式: 描述:单个 Redis 服务器实例运行在一台机器上&…...
【STM32HAL库学习】定时器功能、时钟以及各种模式理解
一、文章目的 记录自己从学习了定时器理论->代码实现使用定时->查询数据手册,加深了对定时器的理解以及该过程遇到了的一些不清楚的知识。 上图为参考手册里通用定时器框图,关于定时器各种情况的工作都在上面了,在理论学习和实际应用后…...

3588麒麟系统硬解码实战
目录 安装rockchip-mpp deb 查找头文件 .pro文件添加 检查库是否已安装 error: stdlib.h: No such file or directory ffmpeg 查找ffmpeg路径: 查找FFmpeg库和头文件的位置 使用pkg-config工具查找FFmpeg路径 ok的ffmpeg配置: ffmpeg查看是否支持libx264 ffmpeg …...

十二 nginx中location重写和匹配规则
十二 location匹配规则 ^~ ~ ~* !~ !~* /a / 内部服务跳转 十三 nginx地址重写rewrite if rewrite set return 13.1 if 应用环境 server location -x 文件是否可执行 $args $document_rot $host $limit_rate $remote_addr $server_name $document_uri if …...

python的视频处理FFmpeg库使用
FFmpeg 是一个强大的多媒体处理工具,用于录制、转换和流式传输音频和视频。它支持几乎所有的音频和视频格式,并且可以在各种平台上运行。FFmpeg 在 Python 中的使用可以通过调用其命令行工具或使用专门的库如 ffmpeg-python。以下是详细介绍如何在 Python 中使用 FFmpeg,包括…...

接口测试时, 数据Mock为何如此重要?
一、为什么要mock 工作中遇到以下问题,我们可以使用mock解决: 1、无法控制第三方系统某接口的返回,返回的数据不满足要求 2、某依赖系统还未开发完成,就需要对被测系统进行测试 3、有些系统不支持重复请求,或有访问…...

未授权与绕过漏洞
1、Laravel Framework 11 - Credential Leakage(CVE-2024-29291)认证泄漏 导航这个路径storage/logs/laravel.log搜索以下信息: PDO->__construct(mysql:host 2、 Flowise 1.6.5 - Authentication Bypass(CVE-2024-31621&am…...

云原生周刊:Kubernetes 十周年 | 2024.6.11
开源项目推荐 Kubernetes Goat Kubernetes Goat 是一个故意设计成有漏洞的 Kubernetes 集群环境,旨在通过交互式实践场地来学习并练习 Kubernetes 安全性。 kube-state-metrics (KSM) kube-state-metrics 是一个用于收集 Kubernetes 集群状态信息的开源项目&…...

从传感器到屏幕:手把手教你用STM32的ADC读取电位器,并用OLED实时显示电压值
从传感器到屏幕:手把手教你用STM32的ADC读取电位器,并用OLED实时显示电压值 在嵌入式开发中,模拟信号的采集与处理是一个基础但极其重要的技能。想象一下,当你旋转一个电位器,屏幕上的数字随之实时变化,这种…...

别再乱配Jackson了!这5个SerializationFeature和DeserializationFeature配置,能帮你避开90%的坑
别再乱配Jackson了!这5个SerializationFeature和DeserializationFeature配置,能帮你避开90%的坑 最近在重构一个老项目时,我又一次被Jackson的配置问题折腾得够呛。API返回的数据莫名其妙少了几个字段,日志输出的JSON格式混乱不堪…...

从晶体管到代码:聊聊Verilog里‘’、‘|’、‘~’这些符号背后的硬件故事
从晶体管到代码:Verilog逻辑运算符背后的硬件密码 在数字电路的世界里,每一行Verilog代码都是对物理世界的精确描述。当我们写下&、|、~这些看似简单的符号时,背后隐藏的是数十亿个晶体管在硅片上的精妙舞蹈。本文将带您穿越抽象的逻辑层…...
)
从Vivado/Quartus工程文件看起:Verilog语法避坑指南与最佳实践(新手必看)
从Vivado/Quartus工程文件看起:Verilog语法避坑指南与最佳实践(新手必看) 在FPGA开发中,Verilog代码的编写质量直接影响着综合结果和最终硬件性能。许多初学者在使用Vivado或Quartus等EDA工具时,常常陷入各种语法陷阱&…...

Yo‘City:基于多智能体的3D城市动态生成框架解析
1. 项目概述YoCity是一个革命性的3D城市生成框架,它通过多智能体系统实现了城市环境的无限扩展和动态生成。这个框架的核心创新点在于将传统静态的城市建模转变为由自主智能体驱动的有机生长过程。我在参与智慧城市项目时,发现传统3D建模存在两个致命缺陷…...

别再被0.1+0.2≠0.3搞懵了!一文搞懂JavaScript/Java中Double浮点数的那些‘坑’
别再被0.10.2≠0.3搞懵了!一文搞懂JavaScript/Java中Double浮点数的那些‘坑’ 第一次在控制台输入0.1 0.2看到结果是0.30000000000000004时,相信很多开发者都会怀疑自己的键盘是不是坏了。这不是代码写错了,而是计算机用二进制表示十进制小…...

ComfyUI-Manager终极指南:5步快速解决节点安装失败问题
ComfyUI-Manager终极指南:5步快速解决节点安装失败问题 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various cust…...

嵌入式热惯性里程计系统在无人机导航中的应用
1. 嵌入式高速热惯性里程计系统概述在无人机自主导航领域,GPS信号拒止环境下的可靠状态估计一直是个关键挑战。传统视觉惯性里程计(VIO)依赖可见光相机,在低光照或烟雾等视觉退化场景中性能急剧下降。我们开发的实时单目热惯性里程计(TIO)系统通过融合长…...

AI记忆系统演进:从废弃三层架构到实时向量存储实践
1. 项目概述:从废弃的蓝图到现代AI记忆系统的演进如果你正在为你的AI助手寻找一个持久、可搜索的记忆系统,并且偶然发现了openclaw-jarvis-memory这个项目,那么你可能会看到它已经被标记为“废弃”。别急着关掉页面,这恰恰是一个绝…...

文档即测试 —— doctest模块
一、核心概念解析 1.1 基础定义:什么是“文档即测试”? 想象一下你在教朋友玩一个新桌游: 普通文档:你写了一本规则书,里面说“玩家每次可以抽2张牌”文档即测试:你不仅写了规则,还附加了一句“…...