pytorch 加权CE_loss实现(语义分割中的类不平衡使用)
加权CE_loss和BCE_loss稍有不同
1.标签为long类型,BCE标签为float类型
2.当reduction为mean时计算每个像素点的损失的平均,BCE除以像素数得到平均值,CE除以像素对应的权重之和得到平均值。

参数配置torch.nn.CrossEntropyLoss(weight=None,size_average=None,ignore_index=-100,reduce=None,reduction=‘mean’,label_smoothing=0.0)
增加加权的CE_loss代码实现
# 总之, CrossEntropyLoss() = softmax + log + NLLLoss() = log_softmax + NLLLoss(), 具体等价应用如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
import numpy as npclass CrossEntropyLoss2d(nn.Module):def __init__(self, weight=None):super(CrossEntropyLoss2d, self).__init__()self.nll_loss = nn.CrossEntropyLoss(weight, reduction='mean')def forward(self, preds, targets):return self.nll_loss(preds, targets)
语义分割类别计算
class CE_w_loss(nn.Module):def __init__(self,ignore_index=255):super(CE_w_loss, self).__init__()self.ignore_index = ignore_index# self.CE = nn.CrossEntropyLoss(ignore_index=self.ignore_index)def forward(self, outputs, targets):class_num = outputs.shape[1]# print("class_num :",class_num )# # 计算每个类别在整个 batch 中的像素数占比class_pixel_counts = torch.bincount(targets.flatten(), minlength=class_num) # 假设有class_num个类别class_pixel_proportions = class_pixel_counts.float() / torch.numel(targets)# # 根据类别占比计算权重class_weights = 1.0 / (torch.log(1.02 + class_pixel_proportions)).double() # 使用对数变换平衡权重# # print("class_weights :",class_weights)## 定义交叉熵损失函数,并使用动态计算的类别权重criterion = nn.CrossEntropyLoss(ignore_index=self.ignore_index,weight= class_weights)# 计算损失loss = criterion(outputs, targets)print(loss.item()) # 打印损失值return lossnp.random.seed(666)pred = np.ones((2, 5, 256,256))seg = np.ones((2, 5, 256, 256)) # 灰度label = np.ones((2, 256, 256)) # 灰度pred = torch.from_numpy(pred)seg = torch.from_numpy(seg).int() # 灰度label = torch.from_numpy(label).long()ce = CE_w_loss()loss = ce(pred, label)print("loss:",loss.item())
调用库(手动设置权重)
import torch
import torch.nn as nn# 假设有一些模型输出和目标标签
model_output = torch.randn(3, 5) # 假设有5个类别
target = torch.empty(3, dtype=torch.long).random_(5)# 定义权重
weights = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])# 定义交叉熵损失函数,并设置权重
criterion = nn.CrossEntropyLoss(weight=weights)# 计算损失
loss = criterion(model_output, target)
print(loss)
自适应计算权重
import torch
import torch.nn as nn
import numpy as np# 假设我们有一个包含10个样本的批次,每个样本属于4个类别之一
batch_size = 10
num_classes = 4# 随机生成未经过 softmax 的logits输出(网络的最后一层输出)
logits = torch.randn(batch_size, num_classes, requires_grad=True)# 真实的标签(每个样本的类别索引),例如 [0, 2, 1, 3, 0, 0, 1, 2, 3, 3]
labels = torch.tensor([0, 2, 1, 3, 0, 0, 1, 2, 3, 3])# 统计每个类别的频率
class_counts = torch.bincount(labels, minlength=num_classes).float()# 计算每个类别的权重,权重可以为类别频率的倒数
# 为了防止分母为零,这里加一个小的常数epsilon
epsilon = 1e-6
class_weights = 1.0 / (class_counts + epsilon)# 归一化权重,使其和为1
class_weights /= class_weights.sum()print('Class Counts:', class_counts)
print('Class Weights:', class_weights)# 创建带权重的交叉熵损失函数
criterion = nn.CrossEntropyLoss(weight=class_weights)# 计算损失值
loss = criterion(logits, labels)print('Logits:\n', logits)
print('Labels:\n', labels)
print('Weighted Cross-Entropy Loss:', loss.item())# 反向传播梯度
loss.backward()报错
Weight=torch.from_numpy(np.array([0.1, 0.8, 1.0, 1.0])).float() 报错
Weight=torch.from_numpy(np.array([0.1, 0.8, 1.0, 1.0])).double() 正确
参考:[1]https://blog.csdn.net/CSDN_of_ding/article/details/111515226
[2] https://blog.csdn.net/qq_40306845/article/details/137651442
[3] https://www.zhihu.com/question/400443029/answer/2477658229
相关文章:
pytorch 加权CE_loss实现(语义分割中的类不平衡使用)
加权CE_loss和BCE_loss稍有不同 1.标签为long类型,BCE标签为float类型 2.当reduction为mean时计算每个像素点的损失的平均,BCE除以像素数得到平均值,CE除以像素对应的权重之和得到平均值。 参数配置torch.nn.CrossEntropyLoss(weightNone,…...

【iOS】UI——关于UIAlertController类(警告对话框)
目录 前言关于UIAlertController具体操作及代码实现总结 前言 在UI的警告对话框的学习中,我们发现UIAlertView在iOS 9中已经被废弃,我们找到UIAlertController来代替UIAlertView实现弹出框的功能,从而有了这篇关于UIAlertController的学习笔记…...

django支持https
测试环境,可以用django自带的证书 安装模块 sudo pip3 install django_sslserver服务端https启动 python3 manage.py runsslserver 127.0.0.1:8001https访问 https://127.0.0.1:8001/quota/api/XXX...
)
算法题day41(补5.27日卡:动态规划01)
一、动态规划基础知识:在动态规划中每一个状态一定是由上一个状态推导出来的。 动态规划五部曲: 1.确定dp数组 以及下标的含义 2.确定递推公式 3.dp数组如何初始化 4.确定遍历顺序 5.举例推导dp数组 debug方式:打印 二、刷题…...
【附带源码】机械臂MoveIt2极简教程(四)、第一个入门demo
系列文章目录 【附带源码】机械臂MoveIt2极简教程(一)、moveit2安装 【附带源码】机械臂MoveIt2极简教程(二)、move_group交互 【附带源码】机械臂MoveIt2极简教程(三)、URDF/SRDF介绍 【附带源码】机械臂MoveIt2极简教程(四)、第一个入门demo 目录 系列文章目录1. 创…...
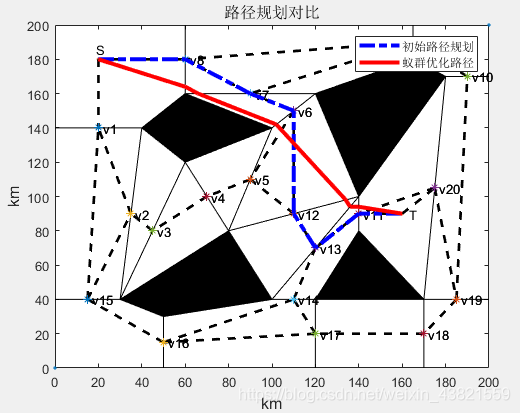
基于蚁群算法的二维路径规划算法(matlab)
微♥关注“电击小子程高兴的MATLAB小屋”获得资料 一、理论基础 1、路径规划算法 路径规划算法是指在有障碍物的工作环境中寻找一条从起点到终点、无碰撞地绕过所有障碍物的运动路径。路径规划算法较多,大体上可分为全局路径规划算法和局部路径规划算法两大类。其…...
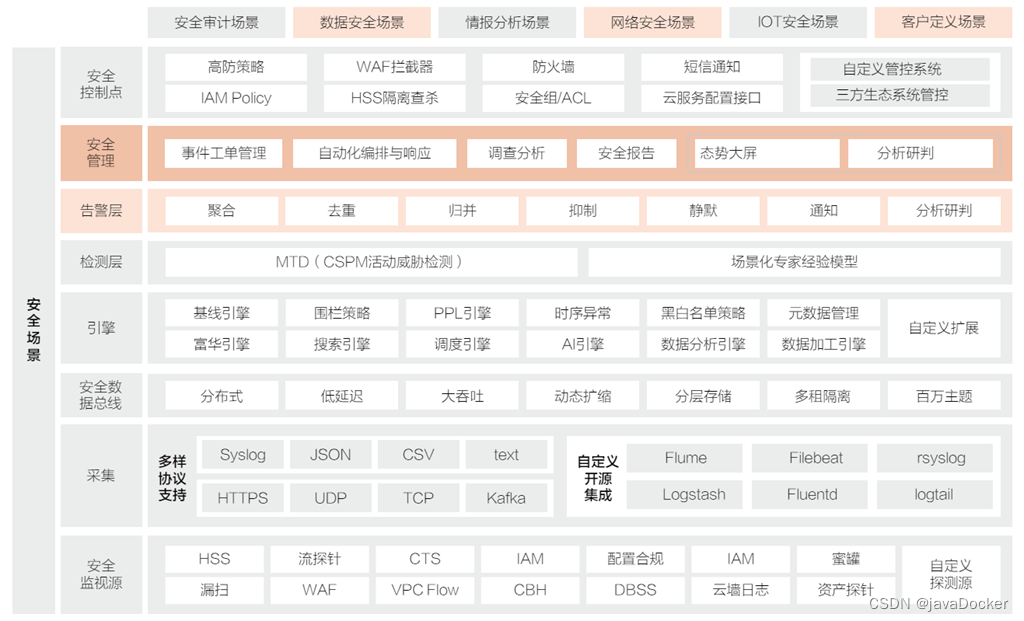
政务云参考技术架构
行业优势 总体架构 政务云平台技术框架图,由机房环境、基础设施层、支撑软件层及业务应用层组成,在运维、安全和运营体系的保障下,为政务云使用单位提供统一服务支撑。 功能架构 标准双区隔离 参照国家电子政务规范,打造符合标准的…...

android 13 aosp 预置so库
展讯对应的main.mk配置 device/sprd/qogirn**/ums***/product/***_native/main.mk $(call inherit-product-if-exists, vendor/***/build.mk)vendor/***/build.mk PRODUCT_PACKAGES \libtestvendor///Android.bp cc_prebuilt_library_shared{name:"libtest",srcs:…...

mongo篇---mongoDB Compass连接数据库
mongo篇—mongoDB Compass连接数据库 mongoDB笔记 – 第一条 一、mongoDB Compass连接远程数据库,配置URL。 URL: mongodb://username:passwordhost:port点击connect即可。 注意:host最好使用名称,防止出错连接超时。...

基于SOA海鸥优化算法的三维曲面最高点搜索matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于SOA海鸥优化算法的三维曲面最高点搜索matlab仿真,输出收敛曲线以及三维曲面最高点搜索结果。 2.测试软件版本以及运行结果展示 MATLAB2022A版本…...

前端js解析websocket推送的gzip压缩json的Blob数据
主要依赖插件pako https://www.npmjs.com/package/pako 1、安装 npm install pako 2、使用, pako.inflate(reader.result, {to: "string"}) 解压后的string 对象,需要JSON.parse转成json this.ws.onmessage (evt) > {console.log("…...
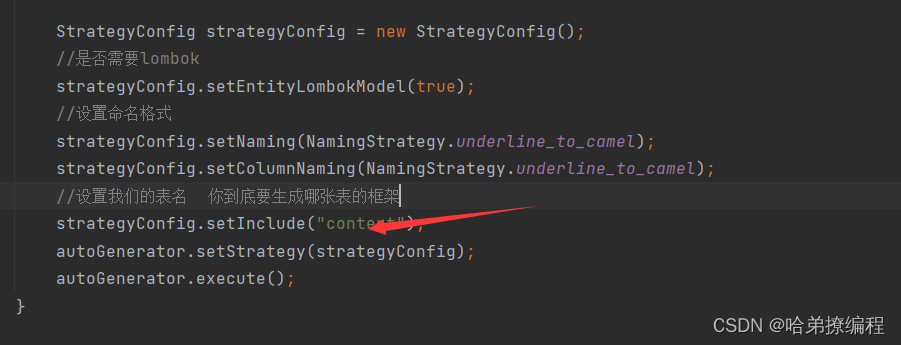
【wiki知识库】06.文档管理接口的实现--SpringBoot后端部分
目录 一、🔥今日目标 二、🎈SpringBoot部分类的添加 1.调用MybatisGenerator 2.添加DocSaveParam 3.添加DocQueryVo 三、🚆后端新增接口 3.1添加DocController 3.1.1 /all/{ebokId} 3.1.2 /doc/save 3.1.3 /doc/delete/{idStr} …...

c,c++,go语言字符串的演进
#include <stdio.h> #include <string.h> int main() {char str[] {a,b,c,\0,d,d,d};printf("string:[%s], len:%d \n", str, strlen(str) );return 0; } string:[abc], len:3 c语言只有数组的概念,数组本身没有长度的概念,需…...
vue-cli 快速入门
vue-cli (目前向Vite发展) 介绍:Vue-cli 是Vue官方提供一个脚手架,用于快速生成一个Vue的项目模板。 Vue-cli提供了如下功能: 统一的目录结构 本地调试 热部署 单元测试 集成打包上线 依赖环境:NodeJ…...

机器人--矩阵运算
两个矩阵相乘的含义 P点在坐标系B中的坐标系PB,需要乘以B到A到变换矩阵TAB。 M点在B坐标系中的位姿MB,怎么计算M在A中的坐标系? 两个矩阵相乘 一个矩阵*另一个矩阵的逆矩阵...

期末复习【汇总】
期末复习【汇总】 前言版权推荐期末复习【汇总】最后 前言 2024-5-12 20:52:17 截止到今天,所有期末复习的汇总 以下内容源自《【创作模板】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此话 本文首次发布于CSDN平台 作者是CSDN日星月云 博客主页是ht…...
- CONNACK Packet)
【IM即时通讯】MQTT协议的详解(3)- CONNACK Packet
【IM即时通讯】MQTT协议的详解(3)- CONNACK Packet 文章目录 【IM即时通讯】MQTT协议的详解(3)- CONNACK Packet前言说明一、固定同步详解、可变头部详解总结 前言 关于所有的类型的数据示例已经在上面一篇博客说完: …...

Linux - 深入理解/proc虚拟文件系统:从基础到高级
文章目录 Linux /proc虚拟文件系统/proc/self使用 /proc/self 的优势/proc/self 的使用案例案例1:获取当前进程的状态信息案例2:获取当前进程的命令行参数案例3:获取当前进程的内存映射案例4:获取当前进程的文件描述符 /proc中进程…...
Django DeleteView视图
Django 的 DeleteView 是一个基于类的视图,用于处理对象的删除操作。 1,添加视图函数 Test/app3/views.py from django.shortcuts import render# Create your views here. from .models import Bookfrom django.views.generic import ListView class B…...

代码杂谈 之 pyspark如何做相似度计算
在 PySpark 中,计算 DataFrame 两列向量的差可以通过使用 UDF(用户自定义函数)和 Vector 类型完成。这里有一个示例,展示了如何使用 PySpark 的 pyspark.ml.linalg.Vectorspyspark.sql.functions.udf 来实现这一功能:…...

Webdash社区贡献指南:如何参与开源项目并开发优质插件
Webdash社区贡献指南:如何参与开源项目并开发优质插件 【免费下载链接】webdash 🔥 Orchestrate your web project with Webdash the customizable web dashboard 项目地址: https://gitcode.com/gh_mirrors/we/webdash Webdash作为一款可定制的W…...

D2DX技术深度解析:如何为经典暗黑破坏神2注入现代图形渲染能力
D2DX技术深度解析:如何为经典暗黑破坏神2注入现代图形渲染能力 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx D…...

SQLines数据库迁移工具终极指南:5分钟快速上手跨平台SQL转换
SQLines数据库迁移工具终极指南:5分钟快速上手跨平台SQL转换 【免费下载链接】sqlines SQLines Open Source Database Migration Tools 项目地址: https://gitcode.com/gh_mirrors/sq/sqlines 在当今多元化的数据库环境中,数据库迁移和SQL转换已成…...

Richard Socher创业公司获6.5亿美元融资,欲让AI自动化研发引领底层范式转移
Richard Socher创业公司获巨额融资一家创业公司获得了GV(Alphabet旗下VC)和Greycroft共同领投的6.5亿美元早期融资,NVIDIA和AMD也参与本轮融资,它的估值达到了46.5亿美元。这家公司的创始人是Richard Socher,他是AI领域…...

工业边缘计算实战:基于Wind River Helix与App Cloud的云原生应用部署与管理
1. 项目概述:当工业边缘计算遇上云原生应用最近在跟几个做工业物联网和智能网关项目的朋友聊天,发现一个挺有意思的现象:大家手里的硬件平台越来越强,但软件开发和部署的效率却成了新的瓶颈。一个典型的场景是,你有一台…...

英特尔现代代码开发挑战:实战性能优化与工具链应用指南
1. 项目概述:一场面向开发者的实战演练最近深度参与并复盘了英特尔举办的“现代代码开发挑战”网络研讨会,感触颇深。这远不止是一场普通的技术分享会,而是一个精心设计的、让开发者亲手“触摸”现代硬件性能潜力的实战沙盒。如果你是一名C/C…...

SwinFusion论文精读与代码复现:拆解‘跨域远程学习’如何让图像融合效果开挂
SwinFusion技术解析:跨域远程学习如何重塑图像融合范式 图像融合技术正经历一场由Transformer架构引领的范式变革。传统方法在全局依赖建模和跨域交互方面的局限性,催生了基于Swin Transformer的创新解决方案。本文将深入剖析SwinFusion这一通用图像融合…...
理论,破解“限流“的底层逻辑)
短视频矩阵系统的信号密码:用数字信号处理(DSP)理论,破解“限流“的底层逻辑
你有没有想过一个问题:同样一条视频,A账号发了50万播放,B账号发了500播放。内容一样、时长一样、甚至发布时间都一样——到底差在哪?答案不在内容里,在信号里。今天用数字信号处理(DSP)的视角&a…...

昇腾CANN cann-samples:从示例代码到生产力工具的全路径
CANN 55 个仓库里,cann-samples 是最容易被低估的一个。它不定义新算子、不优化性能、不做架构设计——只提供可运行的代码示例。但正是因为「只提供示例」,cann-samples 是新手最快上手、老手最常查阅的仓库。每个示例都是独立可编译的项目:…...

深入nRF5340双核通信:拆解LE Audio同步背后的IPC与DPPI机制
深入拆解nRF5340双核通信:LE Audio同步背后的IPC与DPPI实战解析 当你在调试nRF5340的LE Audio应用时,是否遇到过这样的场景:网络核(NET Core)已经收到了完整的音频数据包,但应用核(APP Core)的音频处理却出现了微秒级的延迟&#…...