Hadoop小结
Hadoop是什么
Hadoop是一 个由Apache基金 会所开发的分布式系统基础架构。主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop通 常是指一个更广泛的概念一Hadoop 生态圈。
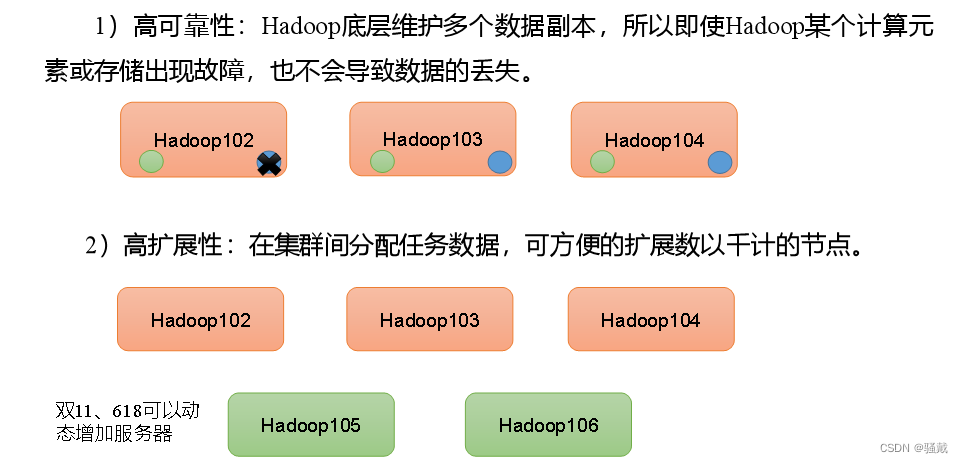
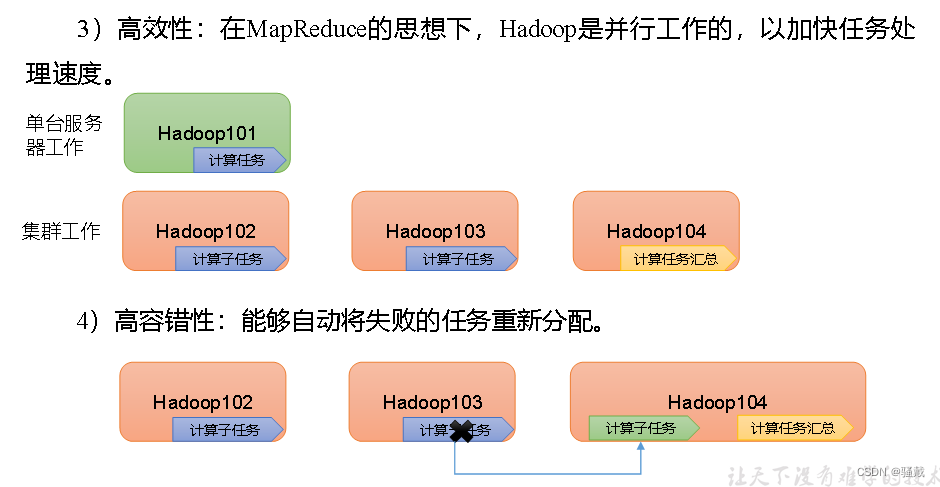
Hadoop优势
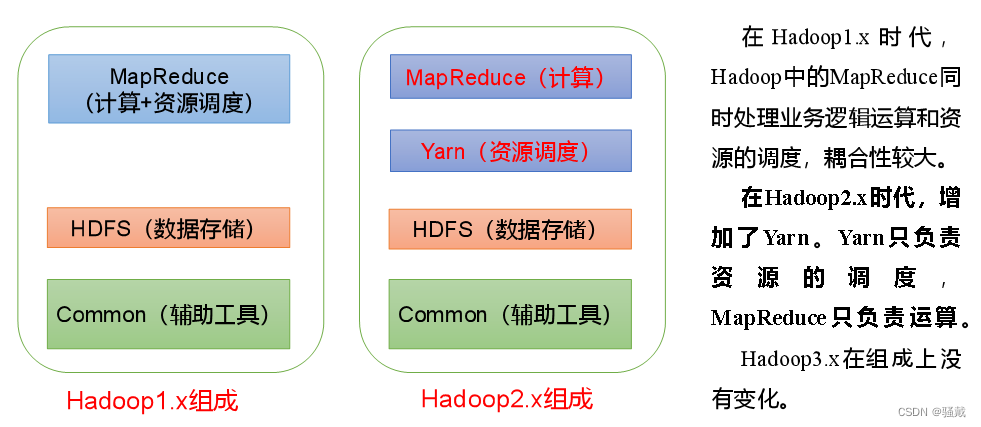
Hadoop组成
HDFS架构
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
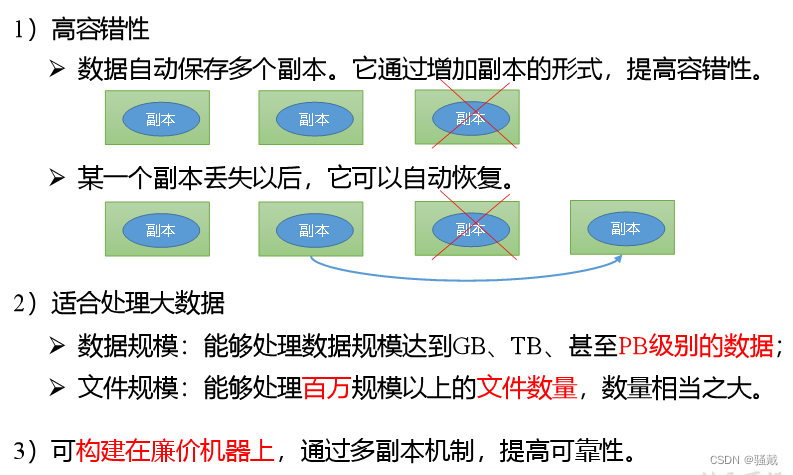
HDFS优缺点
优点
缺点

HDFS组成架构


常用命令实操
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hadoop fs
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
<acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]上传
1)-moveFromLocal:从本地剪切粘贴到HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
输入:shuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo
(./shuguo.txt 是当前路径 /sanguo是目标路径,也就是把shuguo.txt剪切到hdfs的/sanguo路径下去)
2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[atguigu@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
输入:weiguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo
3)-put:等同于copyFromLocal,生产环境更习惯用put
[atguigu@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
输入:wuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo
4)-appendToFile:追加一个文件到已经存在的文件末尾
[atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt
输入:liubei
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
下载
1)-copyToLocal:从HDFS拷贝到本地
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2)-get:等同于copyToLocal,生产环境更习惯用get
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
HDFS直接操作
1)-ls: 显示目录信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo
2)-cat:显示文件内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt
3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt
4)-mkdir:创建路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo
5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo
6)-mv:在HDFS目录中移动文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
7)-tail:显示一个文件的末尾1kb的数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt
8)-rm:删除文件或文件夹
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt
9)-rm -r:递归删除目录及目录里面内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo
10)-du统计文件夹的大小信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo(分别查看文件李的每个文件所占容量大小,第一个数是单个文件的容量,第二个数字是多个副本共同所占的容量)
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
说明:27表示文件大小;81表示27*3个副本;/jinguo表示查看的目录
11)-setrep:设置HDFS中文件的副本数量
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt

这里设置的副本数只是记录在NameNode的元数据中,是否真的会有这么多副本,还得看DataNode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
YARN架构
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器。
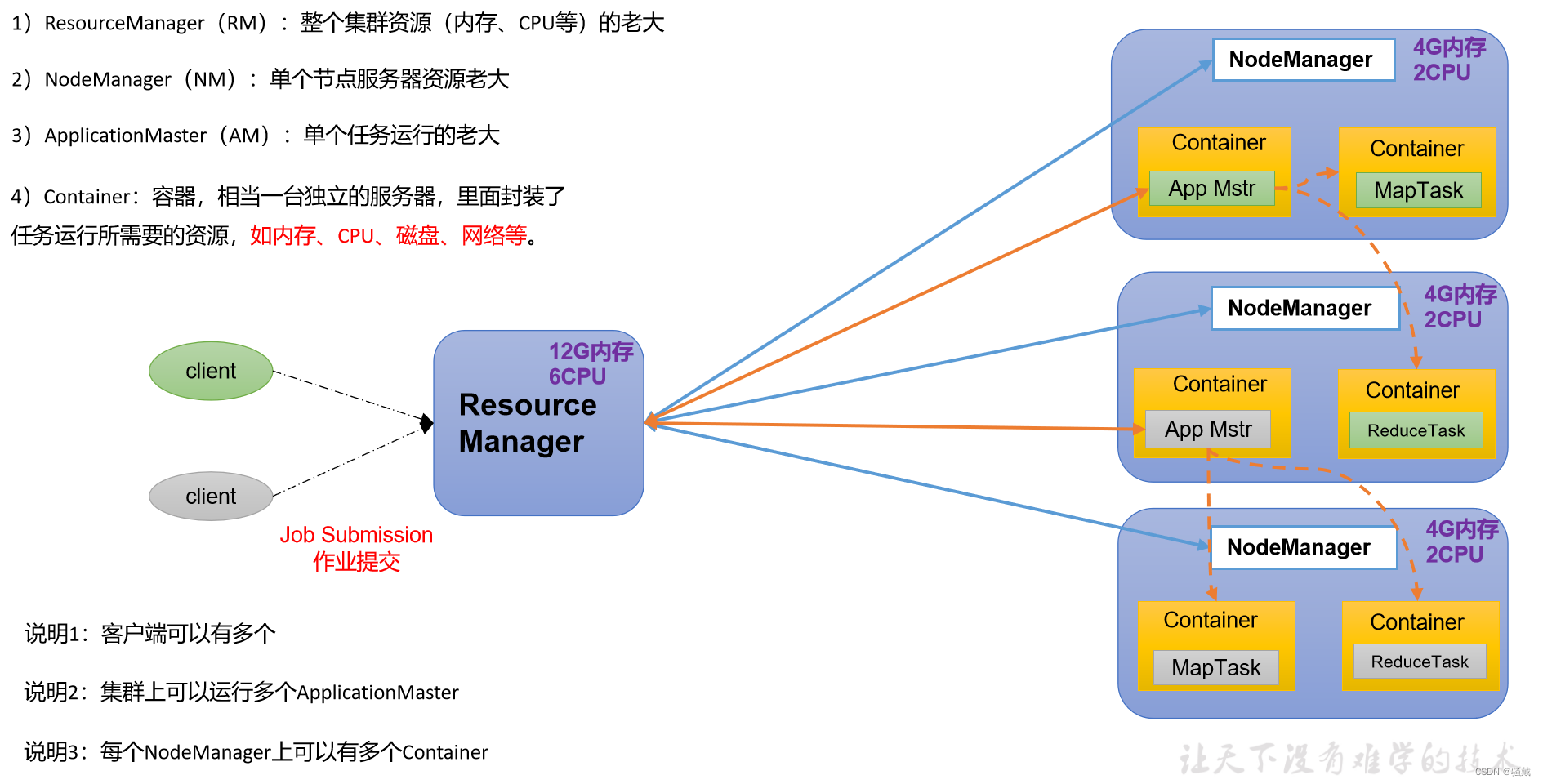
MapReduce架构
MapReduce是一个分布式运算程序的编程框架,MapReduce将计算过程分为两个阶段:Map和Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
MapReduce优缺点
优点
1)MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
MapReduce核心思想
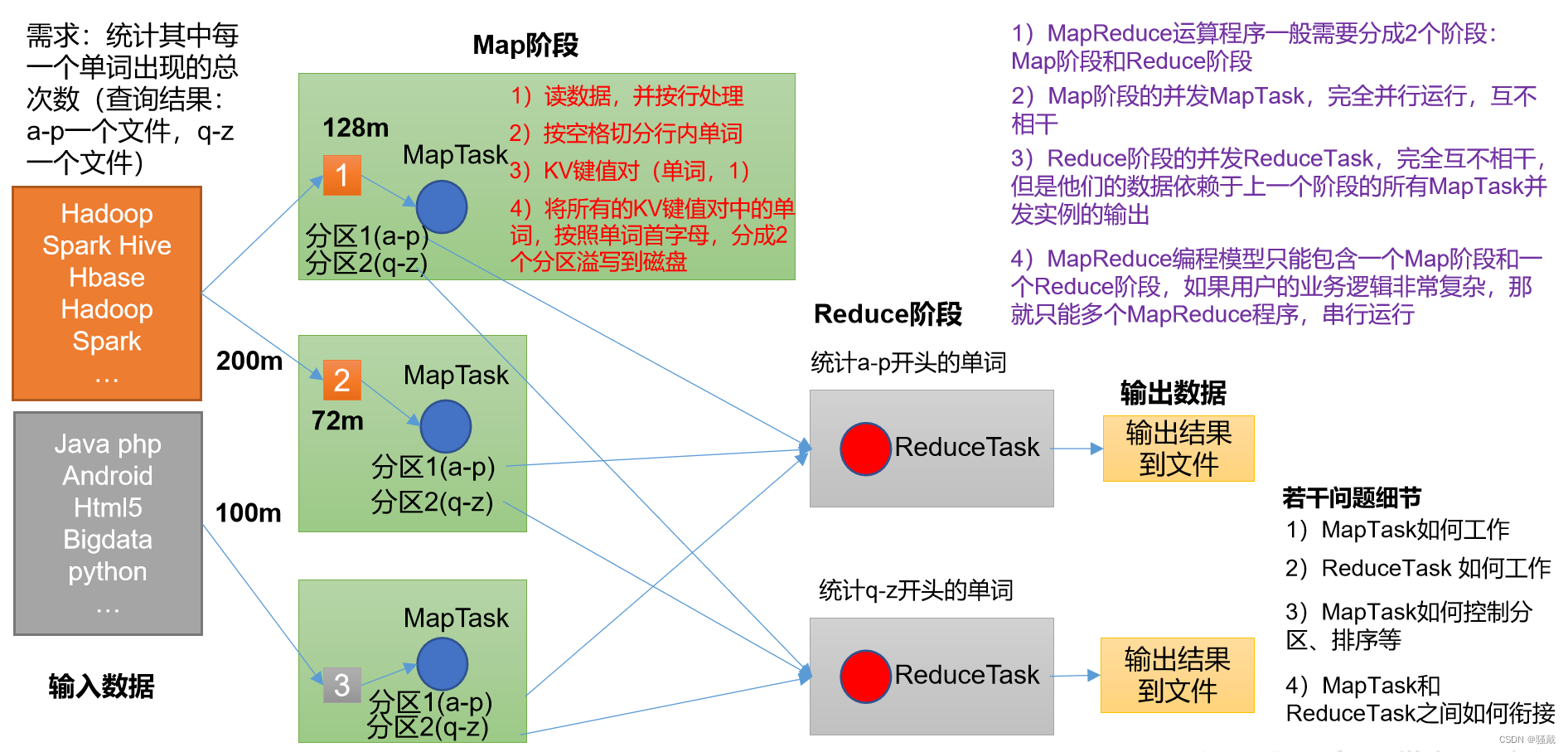
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
MapReduce进程
一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
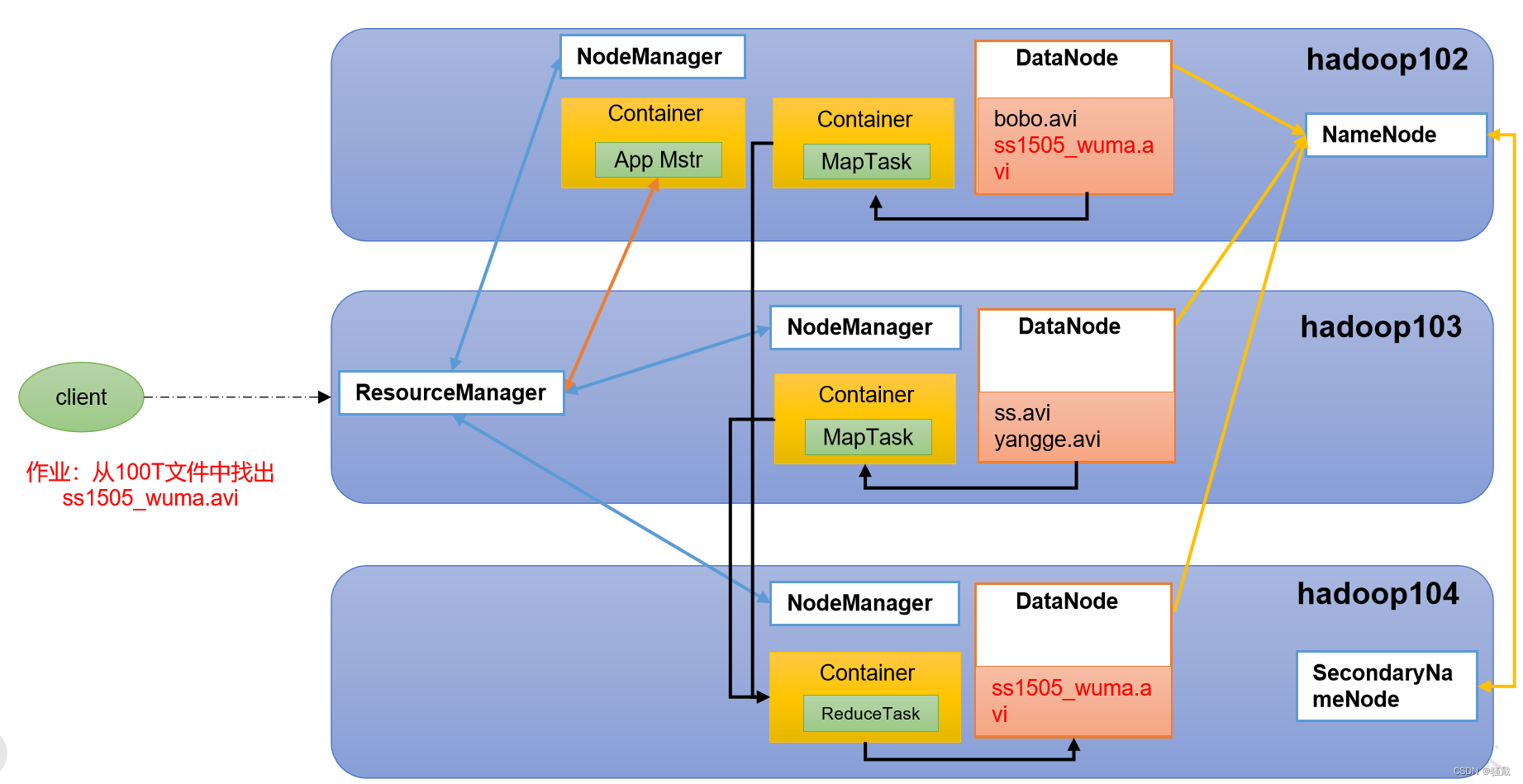
HDFS、YARN、MapReduce三者关系
遇到的bug
bug1
报错信息
在使用自动化部署的脚本的时候,报错连接不上数据库
报错原因
在确定数据库账号密码和ip地址无误的情况下,还是连接不上数据库,最后发现是自动化脚本不支持mysql8.0+
解决办法
在虚拟机上安装mysql5.7.41
bug2
参考文章:https://blog.csdn.net/qq_20780541/article/details/122035569安装mysql有很多报错
报错信息

报错原因
因为没有路径也没有权限,所以创建此路径并授权给mysql用户
解决办法
mkdir /var/log/mariadb
touch /var/log/mariadb/mariadb.log
# 用户组及用户
chown -R mysql:mysql /var/log/mariadb/
/usr/local/mysql/support-files/mysql.server start报错信息

解决办法
mkdir /var/lib/mysql
chmod 777 /var/lib/mysql报错信息

解决办法
ln -s /var/lib/mysql/mysql.sock /tmp/mysql.sock报错信息
Host is not allowed to connect to this MySQL server
解决办法
use mysql;
update user set user.Host='%' where user.User='root';
flush privileges;
或
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY 'Admin123@qwe' WITH GRANT OPTION;
flush privileges;报错信息
ERROR 1130: Host '192.168.10.173' is not allowed to connect to this MySQL ERROR 1062 (23000): Duplicate entry '%-root' for key 'PRIMARY'
解决办法
不用管他,使用flush privileges;刷新一下权限就可
忘记数据库密码教程:https://blog.csdn.net/m0_70556273/article/details/126490767
bug3
报错信息
ssh: connect to host master port 22: No route to host
报错原因
可能是防火墙或者网络的问题,但是我的防火墙是关闭了的,然后发现是vi /etc/hosts配置的ip有问题
解决办法
修改成正确的host配置即可
bug4
报错信息
在使用自动化部署脚本的时候发现hive和spark起不来,一直报错
报错原因
通过free -h查看后发现是内存不够,这里主要是缓存占的内存太多了,动不动就是3G以上,导致可用内存只有几百Mb,最后导致这两个服务没办法跑起来,然后把虚拟机的内存调到8G后,发现还是跑不起来,后来发现缓存就占了3个G以上,reboot重启虚拟机清空缓存,然后一个个的用下面的命令去手动启动才勉强跑起来
解决办法
cd /usr/lib/python2.7/site-packages/deployment*-py2.7.egg/deployment/hadoop/
python manager_hadoop.py-----------------------------------------------------------------------------------------------
restart_all 重启所有Hadoop相关组件,包括重启 Hadoop、Hive、Spark、Hbase、Phoenix-QueryServer
stop_all 停止所有Hadoop相关组件,包括停止 Hadoop、Hive、Spark、Hbase、Phoenix-QueryServer
start_all 启动所有Hadoop相关组件,包括启动 Hadoop、Hive、Spark、Hbase、Phoenix-QueryServer
start_hadoop 启动Hadoop,包括启动 Hdfs、Yarn、JobHistoryServer
stop_hadoop 停止Hadoop,包括停止 Hdfs、Yarn、JobHistoryServer
start_hive 启动Hive,包括启动 Hive元数据服务、HiveServer2
stop_hive 停止Hive所有相关进程,包括停止 Hive元数据服务、HiveServer2、Hive客户端连接等
start_spark 启动Spark,包括启动 Master、Worker
stop_spark 停止Spark,包括停止 Master、Worker
start_hbase 启动Hbase,包括启动 HMaster、HRegionServer
stop_hbase 停止Hbase,包括停止 HMaster、HRegionServer
start_phoenix_queryserver 启动Phoenix的QueryServer,用于支持瘦客户端连接方式
stop_phoenix_queryserver 停止Phoenix的QueryServer
help 使用帮助
------------------------------python manager_hadoop.py stop_allHadoop学习总结
本次在部署Hadoop时采用的是自动化脚本部署,一开始以为几分钟就可以弄好,后面发现在跑脚本的时候各种各样的错误,特别是内存导致的问题,我开三台服务,每台8G运行内存都不够用,跑了n次,通常都是跑到最后内存不足导致spark和hive安装失败,后面发现是缓存占得内存太多了,这里我不能理解为什么缓存动不动就是好几G内存,稍微不注意内存就满了,在这里我花费了大量的时间来排查和重新部署
在部署成功后通过大数据平台来实现测试hive数据库是否可用,把mysql的数据和hive数据库的数据互相进行跑批量同步,测试都没有问题,这里要注意在使用大数据平台的时候是不能直接连接虚拟机里的hive数据库的,需要做端口转发同时还要关闭防火墙才可以成功连接
在部署成功的过程中接触了很多陌生的技术概念,特别是hive、spark、hbase这些技术栈,完全不认识,由于时间有限,目前只额外的去了解了hive技术栈,当然也没有很深入的去了解,了解了hive的定义、架构、优缺点、常用命令等等,剩下的技术栈在本周末进行了解
目前学习主要是对常见的技术栈进行简单了解,最起码要知道这些技术栈是干什么的?有什么优势?架构是什么?然后在后续抽空系统的、深入的去学习这些框架,最后通过实战来加深对这些框架的理解,目前的学习计划和思路就是这样,一口吃不成个大胖子,学习要循环渐进,而不是一气呵成!整个学习过程中将伴随着尽可能的详细笔记,笔记越多越好,这样后续方便我复习看。
相关文章:
Hadoop小结
Hadoop是什么Hadoop是一 个由Apache基金 会所开发的分布式系统基础架构。主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop通 常是指一个更广泛的概念一Hadoop 生态圈。Hadoop优势Hadoop组成HDFS架构Hadoop Distributed File System,…...
)
经典卷积模型回顾14—vgg16实现图像分类(tensorflow)
VGG16是由牛津大学计算机视觉小组(Visual Geometry Group)开发的深度卷积神经网络模型。其结构由16层组成,其中13层是卷积层,3层是全连接层。 VGG16被广泛应用于各种计算机视觉任务,如图像分类、目标检测和人脸识别等。…...

#Vue2篇:keep-alive的属性和方法
定义 keep-alive 组件是 Vue.js 内置的一个高阶组件,用于缓存其子组件,以提高组件的性能和响应速度。 除了基本用法之外,它还提供了一些属性和方法,以便更好地控制缓存的组件。 属性 include属性用于指定哪些组件应该被缓存&a…...
webpack指南(项目篇)——webpack在项目中的运用
系列文章目录 webpack指南(基础篇)——手把手教你配置webpack webpack指南(优化篇)——webpack项目优化 文章目录系列文章目录前言一、配置拆分二、修改启动命令三、定义环境变量四、配置路径别名总结前言 前面我们对webpack的基…...
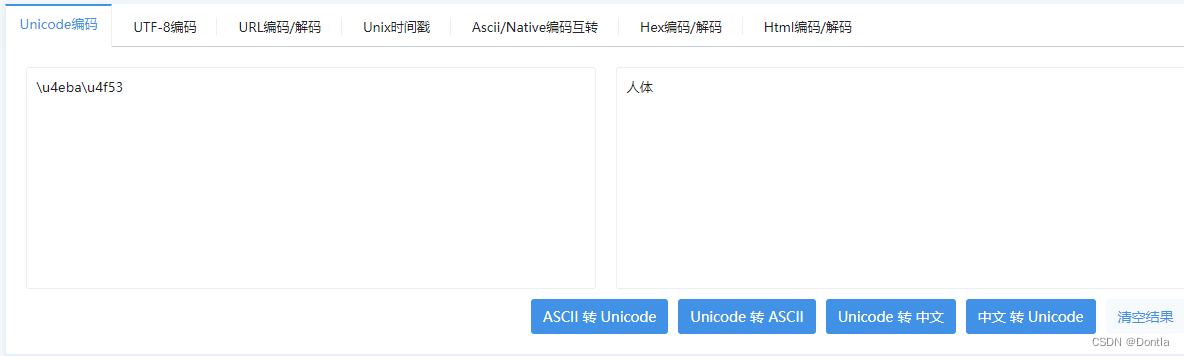
unicode字符集与utf-8编码的区别,unicode转中文工具、中文转unicode工具(汉字)
在cw上报的报警信息中,有一个name字段的值是\u4eba\u4f53 不知道是啥,查了一下,是unicode编码,用下面工具转换成汉字就是“人体” 参考文章:https://tool.chinaz.com/tools/unicode.aspx 那么我很好奇,uni…...

3D数学系列之——再谈特卡洛积分和重要性采样
目录一、前篇文章回顾二、积分的黎曼和形式三、积分的概率形式(蒙特卡洛积分)四、误差五、蒙特卡洛积分计算与收敛速度六、重要性采样七、重要性采样方法和过程八、重要性采样的优缺点一、前篇文章回顾 在前一篇文章3D数学系列之——从“蒙的挺准”到“蒙…...

Python错误 TypeError: ‘NoneType‘ object is not subscriptable解决方案汇总
目录前言一、引发错误来源二、解决方案2-1、解决方案一(检查变量)2-2、解决方案二(使用 [] 而不是 None)2-3、解决方案三(设置默认值)2-4、解决方案四(使用异常处理)2-5、解决方案五…...

VMware空间不足又无法删除快照的解决办法
如果因为快照删除半路取消或者失败,快照管理器就不再显示这个快照,但是其占用的空间还在,最终导致硬盘不足。 可以百度到解决方案,就是在快照管理器,先新建一个,再点删除,等待删除完成就可以将…...
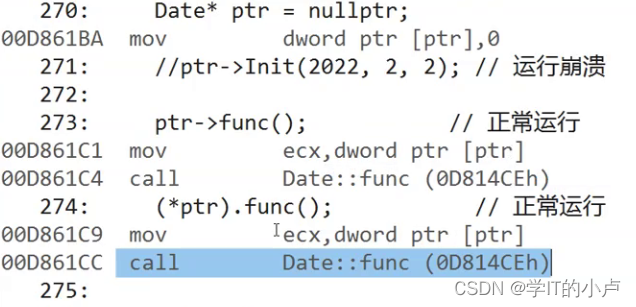
类和对象(一)
类和对象(一) C并不是纯面向对象语言 C是面向过程和面向对象语言的! 面向过程和面向对象初步认识: C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题。 C是基…...
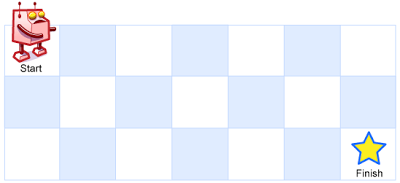
Java 不同路径
不同路径中等一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。问总共有多少条不同的路径?…...

【SAP PO】X-DOC:SAP PO 接口配置 REST 服务对接填坑记
X-DOC:SAP PO 接口配置 REST 服务对接填坑记1、背景2、PO SLD配置3、PO https证书导入1、背景 (1)需求背景: SAP中BOM频繁变更,技术人员在对BOM进行变更后,希望及时通知到相关使用人员 (2&…...
最新研究!美国爱荷华州立大学利用量子计算模拟原子核
爱荷华州立大学物理学和天文学教授James Vary(图片来源:网络)美国爱荷华州立大学物理学和天文学教授James Vary和来自爱荷华州立大学、马萨诸塞州塔夫茨大学,以及美国能源部加利福尼亚州劳伦斯伯克利国家实验室的研究人员…...

零入门kubernetes网络实战-22->基于tun设备实现在用户空间可以ping通外部节点(golang版本)
《零入门kubernetes网络实战》视频专栏地址 https://www.ixigua.com/7193641905282875942 本篇文章视频地址(稍后上传) 本篇文章主要是想做一个测试: 实现的目的是 希望在宿主机-1上,在用户空间里使用ping命令发起ping请求,产生的icmp类型的…...

web安全——Mybatis防止SQL注入 ssrf漏洞利用 DNS污染同源策略
目录 0x01 Mybatis防止SQL注入 0x02 sqlmap中报错注入判断 0x03 ssrf漏洞利用 0x04 SSRF重绑定 0x05 DNS污染...
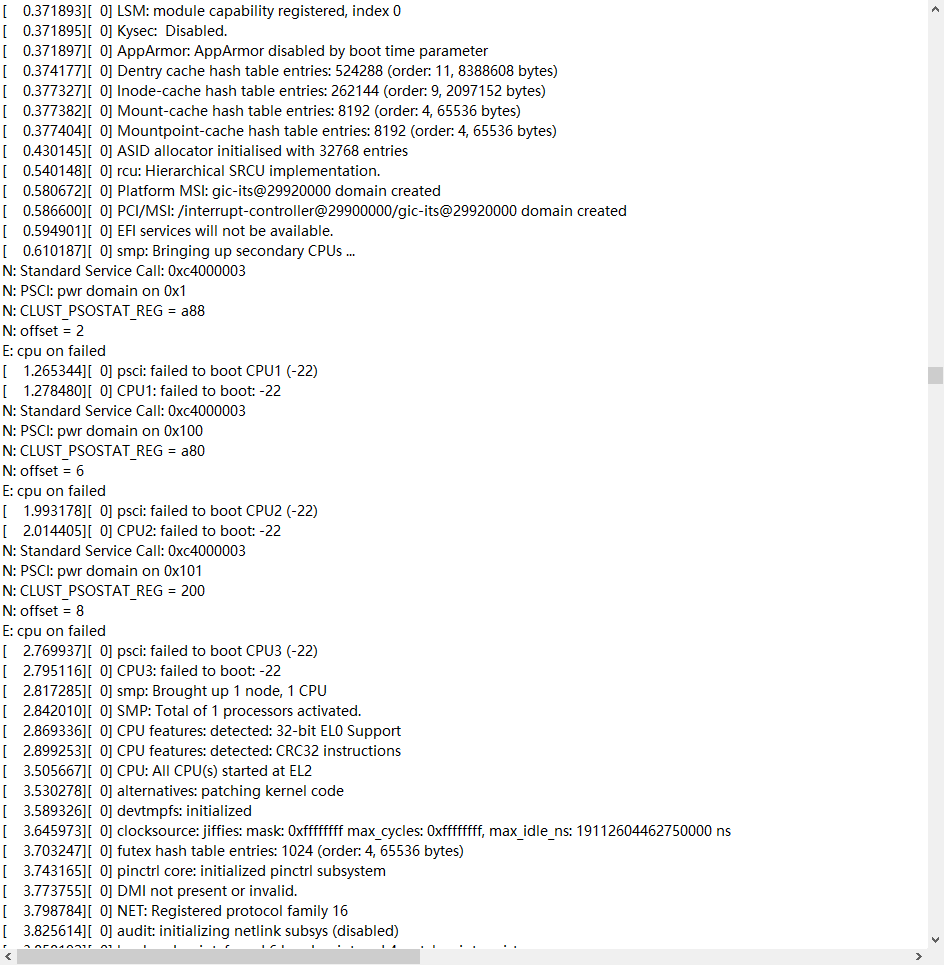
smp_init过程解析
当你看到这样的log,会不会很慌张?竟然由CPU没有启动成功,除了什么故障?本文将结合我遇到的一个问题,将启动过程中bringup secondary cpu的过程分析一下。smp_init代码如下:602 void __init smp_init(void) …...

判断推理之逻辑判断
考点一翻译推理(一)题目特征题干或选项中出现多组“逻辑关联词”,如:“如果……那么……”、“只要……就……”、“只有……才……”、“所有”、“有些”、“……且……”、“ ……或……”等典型逻辑关联词。(二&am…...
2023金三银四常见Handler面试总结,附带答案
以下的Handler的面试题都是在面试过程中总结出来比较常见的面试题,现在分享给大家,希望可以帮助你们!1.Handler的实现原理从四个方面看Handler、Message、MessageQueue 和 Looper Handler:负责消息的发送和处理 Message:消息对象,…...

为什么机器人操作系统ROS1、ROS2这么难学
AI回复:ROS1、ROS2是机器人操作系统,涉及到很多复杂的概念和技术,需要有一定的编程和机器人知识基础才能学习。此外,ROS1和ROS2的架构和设计也有很大的不同,需要花费一定的时间和精力去学习和适应。但是,一…...

day01
授课老师 :陶国荣 联系方式 : taogrtedu.cn 授课阶段 : Web前端基础 授课内容 : HTML CSS JavaScript 文章目录一、讲师和课程介绍二、Web前端介绍1. 什么是网页2. 网页的组成3. 网页的优势4. 开发前的准备三、 HTML语法介绍…...
)
第四十章 linux-并发解决方法五(顺序锁seqlock)
第四十章 linux-并发解决方法四(顺序锁seqlock) 文章目录第四十章 linux-并发解决方法四(顺序锁seqlock)顺序锁的设计思想是,对某一共享数据读取时不加锁,写的时候加锁。为了保证读取的过程中不会因为写入名…...

知识管理新范式:dedao-dl实现得到课程资源备份与永久归档指南
知识管理新范式:dedao-dl实现得到课程资源备份与永久归档指南 【免费下载链接】dedao-dl 得到 APP 课程下载工具,可在终端查看文章内容,可生成 PDF,音频文件,markdown 文稿,可下载电子书。 项目地址: htt…...

避免任务饿死:QP/C框架下优先级调度的5个最佳实践
避免任务饿死:QP/C框架下优先级调度的5个最佳实践 在嵌入式系统开发中,任务调度效率直接影响系统性能和响应能力。QP/C框架作为事件驱动开发的利器,其优先级抢占机制在保证实时性的同时,也可能导致低优先级任务长期无法获得CPU资源…...

Snap Hutao:5个必用功能彻底改变你的原神游戏体验
Snap Hutao:5个必用功能彻底改变你的原神游戏体验 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hutao …...

解锁欧空局10米土地利用数据:从注册到GIS应用全流程解析
1. 欧空局WorldCover数据简介 第一次接触欧空局10米土地利用数据的朋友可能会问:这到底是什么神仙数据?简单来说,这是目前全球分辨率最高的公开土地利用数据集之一,由哨兵1号和哨兵2号卫星数据融合生成。我去年在做城市扩张研究时…...

【从零到一:在STM32F103上构建FreeRTOS与micro-ROS的实时机器人节点】
1. 为什么选择STM32F103FreeRTOSmicro-ROS组合 在机器人控制领域,实时性和可靠性是核心诉求。STM32F103RCT6作为经典的Cortex-M3内核MCU,具有丰富的外设资源和成熟的生态支持,特别适合作为轻量级机器人控制器的核心。而FreeRTOS作为市场占有率…...

终极指南:如何使用 img2pdf 实现无损图像转 PDF
终极指南:如何使用 img2pdf 实现无损图像转 PDF 【免费下载链接】img2pdf mirror of https://gitlab.mister-muffin.de/josch/img2pdf for Travis and appveyor CI 项目地址: https://gitcode.com/gh_mirrors/im/img2pdf 想要将图像无损转换为 PDF 文件&…...

OpCore-Simplify:告别繁琐配置,5分钟构建完美OpenCore EFI的黑苹果神器
OpCore-Simplify:告别繁琐配置,5分钟构建完美OpenCore EFI的黑苹果神器 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify OpCore…...

LaTeX公式插件:在PowerPoint中高效插入数学公式的终极指南
LaTeX公式插件:在PowerPoint中高效插入数学公式的终极指南 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 想在PowerPoint中轻松创建专业数学公式吗?latex-ppt插件让你直接在PPT中使…...

3种突破智能家居生态壁垒的集成方案:Home Assistant与小米设备本地化控制实践
3种突破智能家居生态壁垒的集成方案:Home Assistant与小米设备本地化控制实践 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 在智能家居快速发展的今天&am…...

微信聊天记录数据管理与隐私保护全指南:本地分析与价值挖掘实践
微信聊天记录数据管理与隐私保护全指南:本地分析与价值挖掘实践 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending…...