基于深度学习的电池健康状态预测(Python)
电池的故障预测和健康管理PHM是为了保障设备或系统的稳定运行,提供参考的电池健康管理信息,从而提醒决策者及时更换电源设备。不难发现,PHM的核心问题就是确定电池的健康状态,并预测电池剩余使用寿命。但是锂电池的退化过程影响因素众多,不仅受其本身工作模式的影响,外部环境的压力、温度等都会影响锂电池的退化。这些影响因素之间的相互耦合,导致锂电池的退化表现出很强的非线性及不确定性,这给SOH估计和RUL预测带来了很大的困难。
该项目代码较简单,主要包括Capacity predict,RUL predict,Trends predic,以Capacity predict为例,首先加载模块。
import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torch.utils.data import DataLoader, TensorDataset
import pandas as pdimport numpy as npimport osimport matplotlib.pyplot as pltimport warningswarnings.filterwarnings("ignore")device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")Debug = False
模型定义
# 定义LSTM模型class LSTMModel(nn.Module):def __init__(self, conv_input, input_size, hidden_size, num_layers, output_size):super(LSTMModel, self).__init__()self.conv=nn.Conv1d(conv_input,conv_input,1)self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True, bidirectional=True).to(device)#self.fc1 = nn.Linear(hidden_size*2, hidden_size*2)self.fc = nn.Linear(hidden_size, output_size)self.num_layers = num_layersself.hidden_dim = hidden_sizeself.dropout = nn.Dropout(p=0.3)def forward(self, x):x=self.conv(x)h0 = torch.randn((self.num_layers, x.shape[0], self.hidden_dim)).to(device) # 初始化隐藏状态c0 = torch.randn((self.num_layers, x.shape[0], self.hidden_dim)).to(device) # 初始化细胞状态output, _ = self.lstm(x,(h0,c0))output = self.dropout(output)output = self.fc(output[:, -1, :])return output
导入数据
# 创建一个空列表来存储读取的 DataFramesdataframes_Cap = []dataframes_EIS = []# 使用循环读取文件并分配名称for i in range(1, 9):# 构建文件名file_name_cap= f"Capacity_data/Data_Capacity_25C{i:02}.txt"file_name_EIS = f"EIS_data/EIS_state_V_25C{i:02}.txt" # 使用状态Vif not os.path.isfile(file_name_cap):print(f"Cap文件 {file_name_cap} 不存在,跳过...")continueelif not os.path.isfile(file_name_EIS):print(f"EIS文件 {file_name_EIS} 不存在,跳过...")continue# 读取文件并添加到列表df_cap = pd.read_csv(file_name_cap, sep="\t")df_EIS = pd.read_csv(file_name_EIS, sep="\t")#print(df_cap.columns)if i == 1 or i==5:cap_number = 3else:cap_number = 5#剔除表现不佳的电池if i == 4 or i == 8:continuecycle = []cap = []eis = []cycle_max = df_cap[df_cap.columns[1]].max()cycle_max2 = df_EIS[df_EIS.columns[1]].max()cycle_number = min(cycle_max,cycle_max2)max_scale = df_cap[df_cap[df_cap.columns[1]]==0][df_cap.columns[cap_number]][:].max()for i in range(1,int(cycle_number)+1):temp = df_cap[df_cap[df_cap.columns[1]]==i][df_cap.columns[cap_number]][-1:].max()temp_EIS_Re = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[3]][:])temp_EIS_Im = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[4]][:])cycle.append(i)cap.append(temp)eis.append(np.concatenate((temp_EIS_Re, temp_EIS_Im), axis=0))dataframes_Cap.append(cap)dataframes_EIS.append(eis)
#将35数据读入# 使用循环读取文件并分配名称for i in range(1, 3):# 构建文件名file_name_cap= f"Capacity_data/Data_Capacity_35C{i:02}.txt"file_name_EIS = f"EIS_data/EIS_state_V_35C{i:02}.txt" # 使用状态Vif not os.path.isfile(file_name_cap):print(f"Cap文件 {file_name_cap} 不存在,跳过...")continueelif not os.path.isfile(file_name_EIS):print(f"EIS文件 {file_name_EIS} 不存在,跳过...")continue# 读取文件并添加到列表df_cap = pd.read_csv(file_name_cap, sep="\t")df_EIS = pd.read_csv(file_name_EIS, sep="\t")cap_number = 3cycle = []cap = []eis = []cycle_max = df_cap[df_cap.columns[1]].max()cycle_max2 = df_EIS[df_EIS.columns[1]].max()cycle_number = min(cycle_max,cycle_max2)#max_scale = df_cap[df_cap[df_cap.columns[1]]==1][df_cap.columns[cap_number]][-1:].max()for i in range(1,int(cycle_number)+1):temp = df_cap[df_cap[df_cap.columns[1]]==i][df_cap.columns[cap_number]][-1:].max()temp_EIS_Re = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[3]][:])temp_EIS_Im = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[4]][:])#temp = temp/max_scalecycle.append(i)cap.append(temp)eis.append(np.concatenate((temp_EIS_Re, temp_EIS_Im), axis=0))dataframes_Cap.append(cap)dataframes_EIS.append(eis)
#将45数据读入for i in range(1, 3):# 构建文件名file_name_cap= f"Capacity_data/Data_Capacity_45C{i:02}.txt"file_name_EIS = f"EIS_data/EIS_state_V_45C{i:02}.txt" # 使用状态Vif not os.path.isfile(file_name_cap):print(f"Cap文件 {file_name_cap} 不存在,跳过...")continueelif not os.path.isfile(file_name_EIS):print(f"EIS文件 {file_name_EIS} 不存在,跳过...")continue# 读取文件并添加到列表df_cap = pd.read_csv(file_name_cap, sep="\t")df_EIS = pd.read_csv(file_name_EIS, sep="\t")#print(df_cap.columns)cap_number = 3cycle = []cap = []eis = []cycle_max = df_cap[df_cap.columns[1]].max()cycle_max2 = df_EIS[df_EIS.columns[1]].max()cycle_number = min(cycle_max,cycle_max2)#max_scale = df_cap[df_cap[df_cap.columns[1]]==1][df_cap.columns[cap_number]][-1:].max()for i in range(1,int(cycle_number)+1):temp = df_cap[df_cap[df_cap.columns[1]]==i][df_cap.columns[cap_number]][-1:].max()temp_EIS_Re = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[3]][:])temp_EIS_Im = np.array(df_EIS[df_EIS[df_EIS.columns[1]]==i][df_EIS.columns[4]][:])#temp = temp/max_scalecycle.append(i)cap.append(temp)eis.append(np.concatenate((temp_EIS_Re, temp_EIS_Im), axis=0))dataframes_Cap.append(cap)dataframes_EIS.append(eis)
X = []y = []for i in range(0,len(dataframes_Cap)):for j in range(len(dataframes_Cap[i])):X.append(dataframes_EIS[i][j])y.append(dataframes_Cap[i][j])X = np.array(X)y = np.array(y)print(X.shape,y.shape)
# 将EIS的每个实部和每个虚部分别各自归一化remax = []immax = []data={}from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()y = y.reshape(-1,1)# 对标签也进行归一化y = scaler.fit_transform(y)# 将每份电池单独制作,便于交叉训练和验证,start = 0for i in range(len(dataframes_Cap)):feature_name = f'EIS{i+1:02}'target_name = f'Cap{i+1:02}'n = len(dataframes_Cap[i])X_r = X[start:start+n,:60].copy()#将实部整体进行归一化X_r_flat = X_r.flatten()#取第一个EIS的最大最小值进行归一X_r_min = X_r_flat[:60].min()X_r_max = X_r_flat[:60].max()remax.append(X_r_flat[:].max()/X_r_max)normalized_Xr_flat = ((X_r_flat.reshape(-1, 1))-X_r_min)/(X_r_max-X_r_min)normalized_Xr_data = normalized_Xr_flat.reshape(X[start:start+n,:60].shape)#将虚部进行归一化X_i = X[start:start+n,60:]X_i_flat = X_i.flatten()X_i_min = X_i_flat[:60].min()X_i_max = X_i_flat[:60].max()immax.append(X_i_flat[:].max()/X_i_max)normalized_Xi_flat = ((X_i_flat.reshape(-1, 1))-X_i_min)/(X_i_max-X_i_min)normalized_Xi_data = normalized_Xi_flat.reshape(X[start:start+n,60:].shape)data[feature_name] = np.concatenate((normalized_Xr_data, normalized_Xi_data), axis=1)data[feature_name] = data[feature_name].reshape(-1,2, 60)#将数据形式转换为(batch,60,2),实部和虚部作为一个整体特征data[feature_name] = data[feature_name].transpose(0, 2, 1)data[target_name] = y[start:start+n].reshape(-1,1)start += n
if Debug:# 检查数据效果for i in range(15,20):x_plot = data["EIS01"][i][:60]y_plot = data["EIS01"][i][60:]plt.plot(x_plot, y_plot)plt.show()
if Debug:# 检查数据效果for i in range(15,20):x_plot = data["Cap02"][:]plt.plot(x_plot)plt.show()
start = 0for i in range(1,11):if i == 1:trainning_data = data[f"EIS{i:02}"][start:].copy()trainning_target = data[f"Cap{i:02}"][start:].copy()#剔除测试集elif i!=4 and i!= 8 and i!= 10:#else:trainning_data = np.vstack((trainning_data,data[f"EIS{i:02}"][start:]))trainning_target = np.vstack((trainning_target,data[f"Cap{i:02}"][start:]))
trainning_data = torch.tensor(trainning_data, dtype=torch.float32)trainning_target = torch.tensor(trainning_target, dtype=torch.float32)
开始训练
# 初始化模型、损失函数和优化器input_size = 2 # 特征数量hidden_size = 128num_layers = 5output_size = 1conv_input = 60batch_size = 128epochs = 1500n_splits = 5
from sklearn.model_selection import KFoldimport gcdef gc_collect():gc.collect()torch.cuda.empty_cache()gc_collect()
kf = KFold(n_splits=n_splits, shuffle=True)model_number = 0for train_idx, val_idx in kf.split(trainning_data):train_X, val_X = trainning_data[train_idx], trainning_data[val_idx]train_y, val_y = trainning_target[train_idx], trainning_target[val_idx]train_dataset = TensorDataset(train_X, train_y)val_dataset = TensorDataset(val_X, val_y)train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)model = LSTMModel(conv_input, input_size, hidden_size, num_layers, output_size)model = model.to(device)criterion = nn.MSELoss()optimizer = optim.Adam(model.parameters(), lr=0.0001,betas=(0.5,0.999))for epoch in range(epochs):model.train()for i, (inputs, labels) in enumerate(train_loader):inputs = inputs.to(device)labels = labels.to(device)optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()model.eval()with torch.no_grad():for inputs, labels in val_loader:inputs = inputs.to(device)labels = labels.to(device)outputs = model(inputs)val_loss = criterion(outputs, labels)if epoch%100 ==0:print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}, Validation Loss: {val_loss.item()}')torch.save(model.state_dict(), f"model_weights/CNNBiLSTM/test{model_number}.pth")model_number += 1
from sklearn.metrics import mean_squared_errorfrom sklearn.metrics import r2_scoreimport math
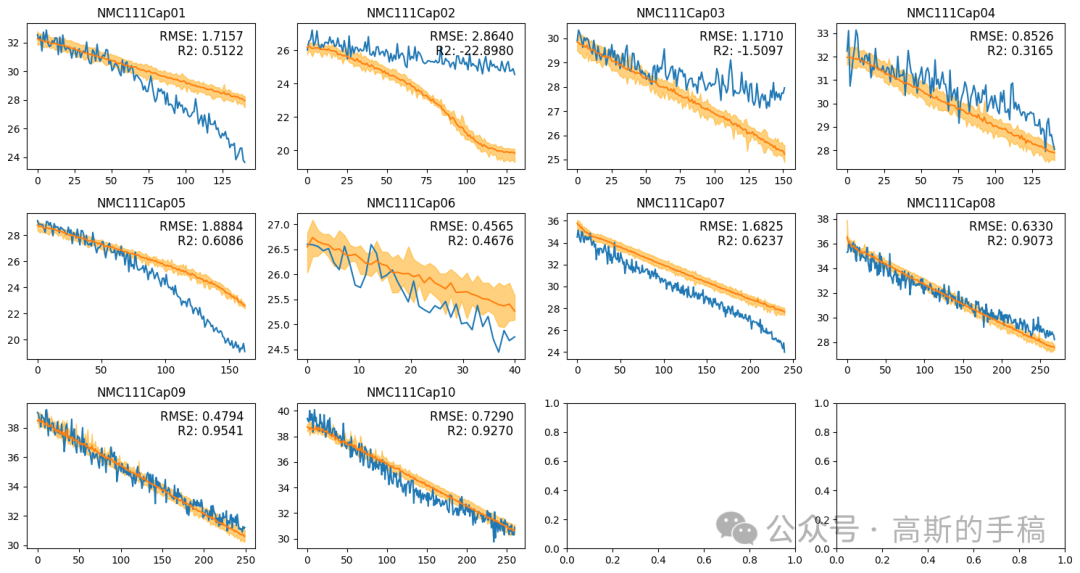
# 创建画布fig, axs = plt.subplots(nrows=3, ncols=4, figsize=(15, 8))ID = 1title_name = 1start = 0mean_RMSE_train = 0mean_RMSE_test = 0mean_R2_train = 0mean_R2_test = 0model = LSTMModel(conv_input, input_size, hidden_size, num_layers, output_size)model = model.to(device)# 在每个小区域中绘制图像for i in range(3):for j in range(4):result = []x = torch.tensor(data[f"EIS{ID:02}"], dtype=torch.float32)for k in range(n_splits):model.load_state_dict(torch.load(f"model_weights/CNNBiLSTM/test{k}.pth",map_location=torch.device(device)))out = model(x.to(device))out = out.cpu()out = out.detach().numpy()out = scaler.inverse_transform(out)result.append(out)result = np.array(result)out = np.mean(result, axis=0)out_upper = np.max(result, axis=0)out_upper = np.squeeze(out_upper)out_lower = np.min(result, axis=0)out_lower = np.squeeze(out_lower)true = data[f"Cap{ID:02}"]true = scaler.inverse_transform(true)MSE = mean_squared_error(out[start:], true[start:])R2_result = r2_score(true[start:], out[start:])RMSE_result = math.sqrt(MSE)mean_RMSE_train += RMSE_resultmean_R2_train += R2_resultRMSE_str = "{:.4f}".format(RMSE_result)R2_str = "{:.4f}".format(R2_result)x = np.linspace(0,x.shape[0],x.shape[0])axs[i, j].plot(x[start:], true[start:])axs[i, j].plot(x[start:], out[start:])axs[i, j].fill_between(x[start:], out_upper[start:], out_lower[start:], color='orange', alpha=0.5)axs[i, j].set_title(f"25Cap{title_name:02}")axs[i, j].text(0.95, 0.95, "RMSE: "+ RMSE_str, ha='right', va='top', fontsize=12, transform=axs[i, j].transAxes)axs[i, j].text(0.95, 0.85, "R2: "+ R2_str, ha='right', va='top', fontsize=12, transform=axs[i, j].transAxes)# 使用循环将数组中的每个元素写入文件with open(f"data/Nature_Cap_train{title_name:02}", 'w') as file:for item in range(out[start:].shape[0]):out_number = round(float(out[start:][item].flatten()), 4)#file.write(str(out_number) + '\t'+str(out_upper[start:][item])+ '\t'+str(out_lower[start:][item])+ '\n')file.write(str(out_number)+'\n')# 关闭文件file.close()ID += 1title_name += 1if ID == 11:break# 调整子图之间的距离plt.tight_layout()plt.savefig('figure_results/cap_alltempalldata_test_5_10_12.png')print("train RMSE: ", mean_RMSE_train/8)print("train R2: ", mean_R2_train/8)# 显示图像plt.show()

RUL预测结果:
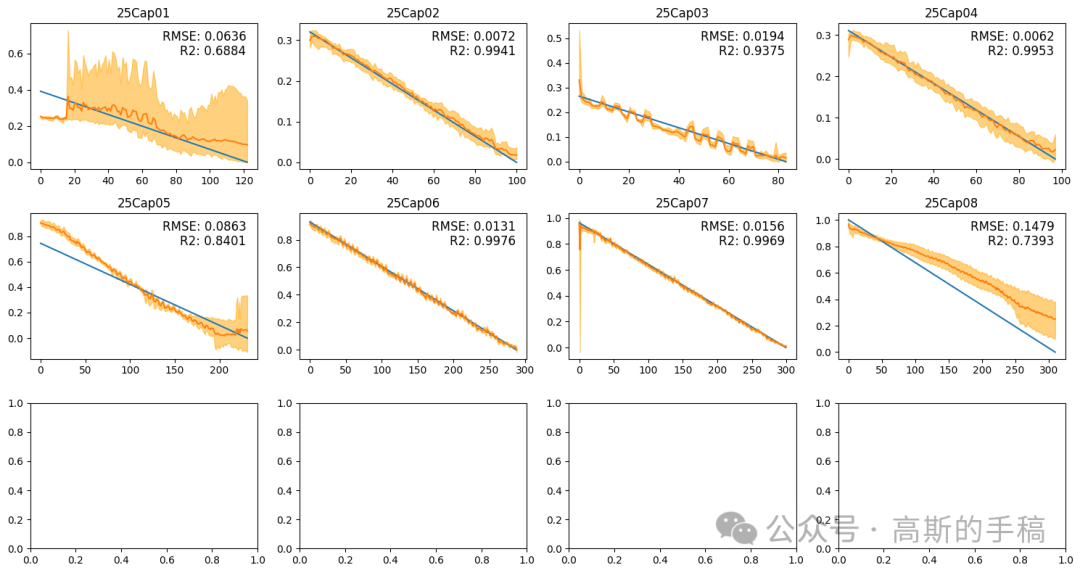
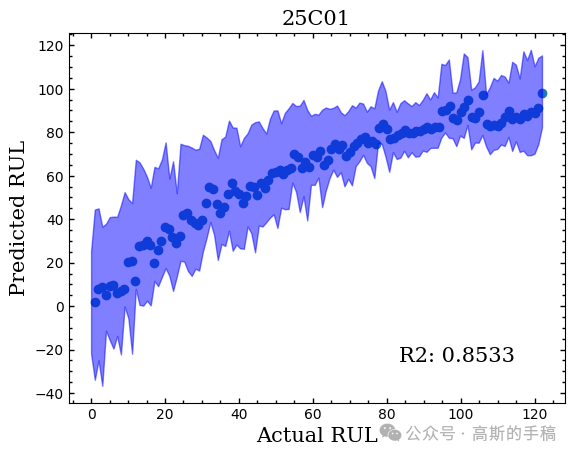
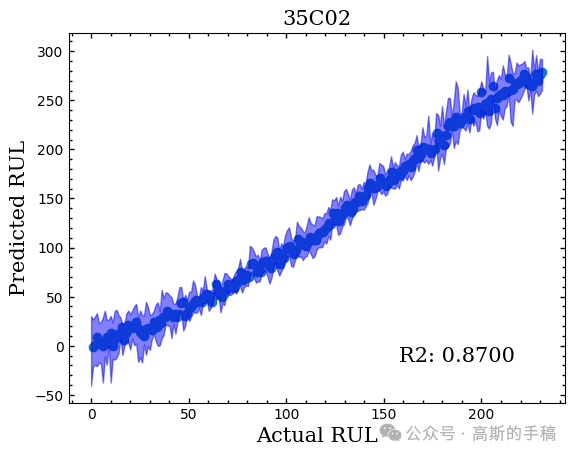
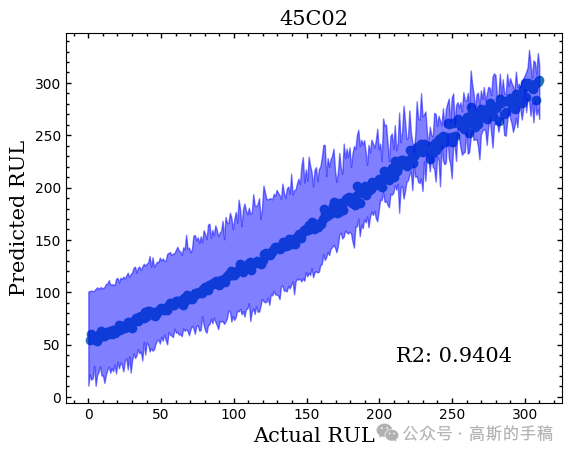
Trends预测结果
担任《Mechanical System and Signal Processing》《中国电机工程学报》《控制与决策》等期刊审稿专家,擅长领域:现代信号处理,机器学习,深度学习,数字孪生,时间序列分析,设备缺陷检测、设备异常检测、设备智能故障诊断与健康管理PHM等。
相关文章:
基于深度学习的电池健康状态预测(Python)
电池的故障预测和健康管理PHM是为了保障设备或系统的稳定运行,提供参考的电池健康管理信息,从而提醒决策者及时更换电源设备。不难发现,PHM的核心问题就是确定电池的健康状态,并预测电池剩余使用寿命。但是锂电池的退化过程影响因…...

【吊打面试官系列-Mysql面试题】MySQL 如何优化 DISTINCT?
大家好,我是锋哥。今天分享关于 【MySQL 如何优化 DISTINCT?】面试题,希望对大家有帮助; MySQL 如何优化 DISTINCT? DISTINCT 在所有列上转换为 GROUP BY,并与 ORDER BY 子句结合使用。 SELECT DISTINCT t…...

企业IT运维管理体系-总体规划
企业IT运维管理体系-总体规划 企业IT运维管理体系的总体规划通过科学的调研、分析、设计和建设,提升管理成熟度、增强服务能力、实现技术创新和优化资源配置。重点在于建立组织保障体系、制定运维制度、构建运维平台和完善度量指标。通过明确运维治理模式和外包管理…...
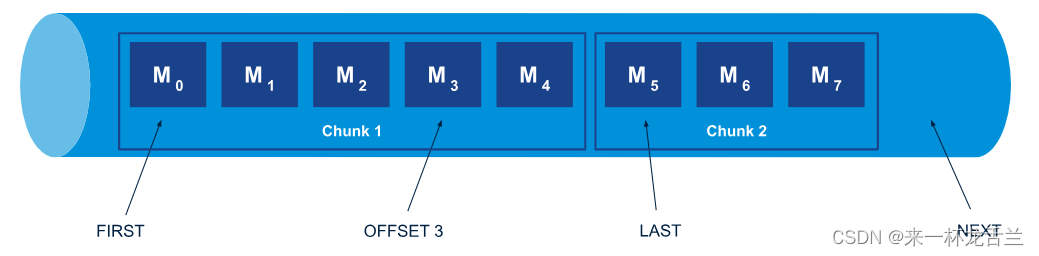
RabbitMQ-Stream(高级详解)
文章目录 什么是流何时使用 RabbitMQ Stream?在 RabbitMQ 中使用流的其他方式基本使用Offset参数chunk Stream 插件服务端消息偏移量追踪示例 示例应用程序RabbitMQ 流 Java API概述环境创建具有所有默认值的环境使用 URI 创建环境创建具有多个 URI 的环境 启用 TLS…...

Web前端图片并排显示的艺术与技巧
Web前端图片并排显示的艺术与技巧 在Web前端开发中,图片并排显示是一种常见的布局需求。然而,实现这一目标并非易事,需要掌握一定的技巧和艺术。本文将从四个方面、五个方面、六个方面和七个方面深入探讨Web前端图片并排显示的奥秘。 四个方…...

豆瓣电影信息爬虫【2024年6月】教程
豆瓣电影信息爬虫【2024年6月】教程,赋完整代码 在本教程中,我们将使用以下技术栈来构建一个爬虫,用于爬取豆瓣电影列表页面的信息: 完整代码放到最后 ; 完整代码放到最后 ; 完整代码放到最后 ;…...

Flutter- AutomaticKeepAliveClientMixin 实现Widget保持活跃状态
前言 在 Flutter 中,AutomaticKeepAliveClientMixin 是一个 mixin,用于给 State 类添加能力,使得当它的内容滚动出屏幕时仍能保持其状态,这对于 TabBarView 或者滚动列表中使用 PageView 时非常有用,因为这些情况下你…...

《计算机组成原理》期末复习题节选
第三章–存储系统 3.1 存储器性能指标 核心公式: 存储容量存储字数*字长 ,存储字数表示存储器的地址空间的大小,字长表示一次存取操作的数据量.数据传输率数据宽度/存储周期 1、设机器字长为32位,一个容量为16MB的存储器&…...

NSSCTF中的popchains、level-up、 What is Web、 Interesting_http、 BabyUpload
目录 [NISACTF 2022]popchains [NISACTF 2022]level-up [HNCTF 2022 Week1]What is Web [HNCTF 2022 Week1]Interesting_http [GXYCTF 2019]BabyUpload 今日总结: [NISACTF 2022]popchains 审计可以构造pop链的代码 <php class Road_is_Long{public $…...

量产维护 | 芯片失效问题解决方案:从根源找到答案
芯片失效分析是指对电子设备中的故障芯片进行检测、诊断和修复的过程。芯片作为电子设备的核心部件,其性能和可靠性直接影响整个设备的性能和稳定性。 随着半导体技术的迅速发展,芯片在各个领域广泛应用,如通信、计算机、汽车电子和航空航天等。 因此,对芯片故障原因进行…...

Linux忘记密码的解决方法
1、进入GRUB页面,选择对应的内核按下‘e’键; 2、进入内核修改信息界面,找到Linux这一行,在这一行的末尾加上 init/bin/sh 按下ctrlx进入单用户模式 3、进入单用户后,重新挂载根目录,使其可写࿱…...
数据结构(DS)学习笔记(二):数据类型与抽象数据类型
参考教材:数据结构C语言版(严蔚敏,杨伟民编著) 工具:XMind、幕布、公式编译器 正在备考,结合自身空闲时间,不定时更新,会在里面加入一些真题帮助理解数据结构 目录 1.1数据…...

【C++进阶】模板与仿函数:C++编程中的泛型与函数式编程思想
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:栈和队列相关知识 🌹🌹期待您的关注 🌹🌹 ❀模板进阶 🧩<&…...

华安保险:核心系统分布式升级,提升保费规模处理能力2-3倍 | OceanBase企业案例
在3月20日的2024 OceanBase数据库城市行的活动中,安保险信息科技部总经理王在平发表了以“保险行业核心业务系统分布式架构实践”为主题的演讲。本文为该演讲的精彩回顾。 早在2019年,华安保险便开始与OceanBase接触,并着手进行数据库的升级…...

佐西卡在美国InfoComm 2024展会上亮相投影镜头系列
6月12日至14日,2024美国视听显示与系统集成展览会将在拉斯维加斯会议中心盛大开幕。这场北美最具影响力的视听技术盛会,将汇集全球顶尖的视听解决方案,展现专业视听电子系统集成、灯光音响等领域的最新技术动态。 在这场科技盛宴中࿰…...

【权威出版/投稿优惠】2024年智慧城市与信息化教育国际会议(SCIE 2024)
2024 International Conference on Smart Cities and Information Education 2024年智慧城市与信息化教育国际会议 【会议信息】 会议简称:SCIE 2024 大会时间:点击查看 大会地点:中国北京 会议官网:www.iacscie.com 会议邮箱&am…...

Android 应用程序 ANR 问题分析总结
ANR (Application Not Responding) 应用程序无响应。如果应用程序在UI线程被阻塞太长时间,就会出现ANR,通常出现ANR,系统会弹出一个提示提示框,让用户知道,该程序正在被阻塞,是否继续等待还是关闭。 1、AN…...

爬虫案例:建设库JS逆向
爬虫流程 1. 确定目标网址和所需内容 https://www.jiansheku.com/search/enterprise/ 只是个学习案例,所以目标就有我自己来选择,企业名称,法定代表人,注册资本,成立日期 2. 对目标网站,进行分析 动态…...

基于springboot的酒店管理系统源码数据库
时代的发展带来了巨大的生活改变,很多事务从传统手工管理转变为自动管理。自动管理是利用科技的发展开发的新型管理系统,这类管理系统可以帮助人完成基本的繁琐的反复工作。酒店是出门的必需品,无论出差还是旅游都需要酒店的服务。由于在旺季…...

Web前端开发 - 5 - JavaScript基础
JavaScript 一、JavaScript基础1. JavaScript入门2. 语句3. 数据类型4. 函数5. 对象6. 数组 一、JavaScript基础 1. JavaScript入门 <script> </script> <script type"text/javascript" src"xxx.js"> </script>//单行注释 /* 多…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

连锁超市冷库节能解决方案:如何实现超市降本增效
在连锁超市冷库运营中,高能耗、设备损耗快、人工管理低效等问题长期困扰企业。御控冷库节能解决方案通过智能控制化霜、按需化霜、实时监控、故障诊断、自动预警、远程控制开关六大核心技术,实现年省电费15%-60%,且不改动原有装备、安装快捷、…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...
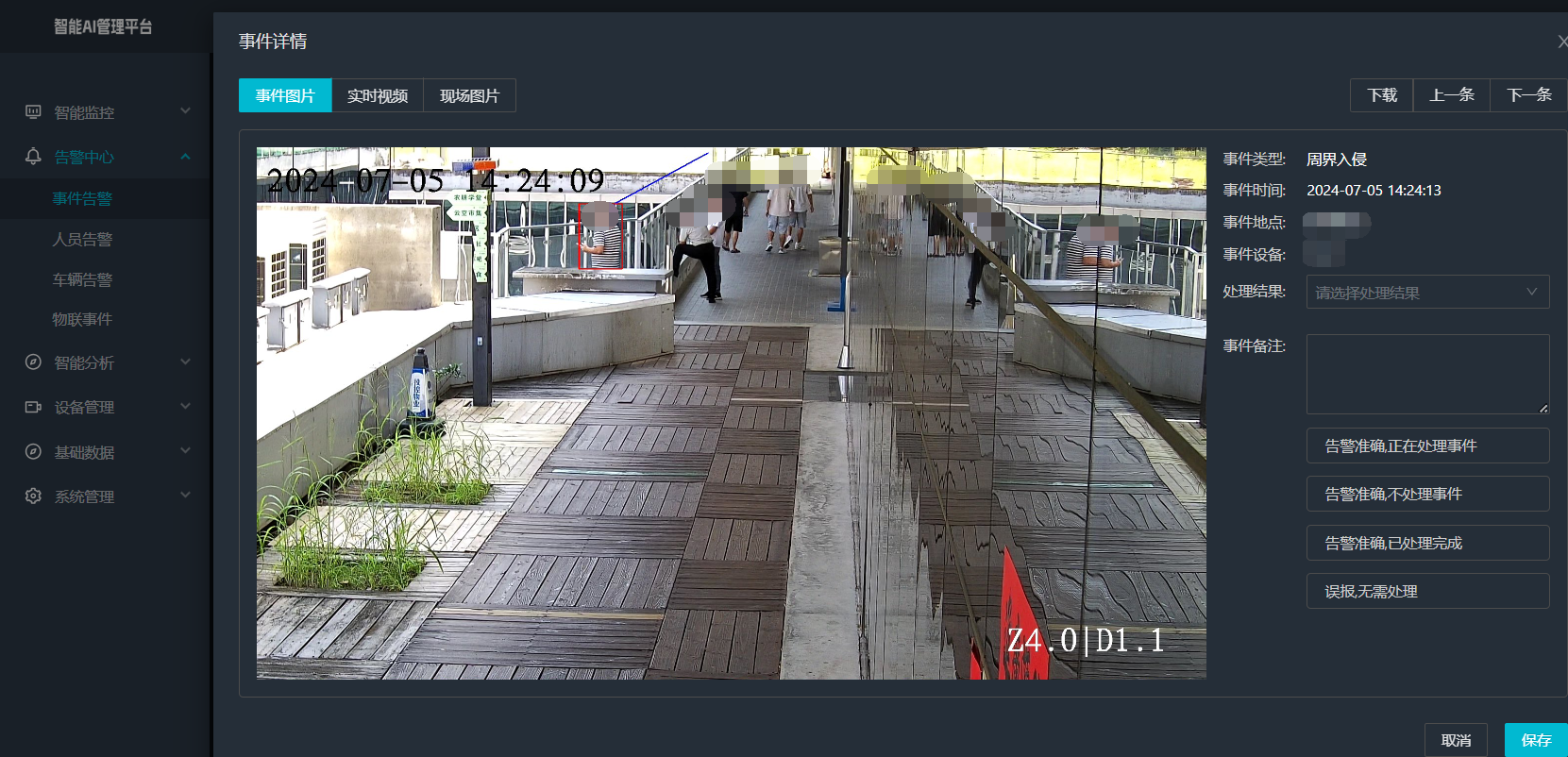
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...
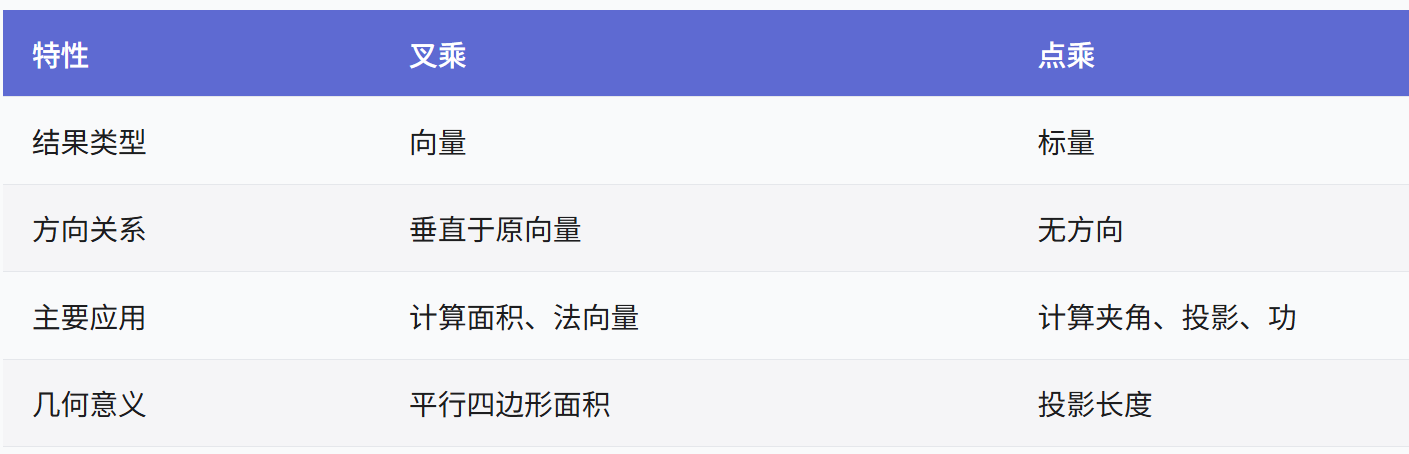
向量几何的二元性:叉乘模长与内积投影的深层联系
在数学与物理的空间世界中,向量运算构成了理解几何结构的基石。叉乘(外积)与点积(内积)作为向量代数的两大支柱,表面上呈现出截然不同的几何意义与代数形式,却在深层次上揭示了向量间相互作用的…...
echarts使用graphic强行给图增加一个边框(边框根据自己的图形大小设置)- 适用于无法使用dom的样式
pdf-lib https://blog.csdn.net/Shi_haoliu/article/details/148157624?spm1001.2014.3001.5501 为了完成在pdf中导出echarts图,如果边框加在dom上面,pdf-lib导出svg的时候并不会导出边框,所以只能在echarts图上面加边框 grid的边框是在图里…...