机器学习——决策树
决策树
决策树可以理解为是一颗倒立的树,叶子在下端,根在最上面
一层一层连接的是交内部节点,内部节点主要是一些条件判断表达式,叶子叫叶节点,叶节点其实就是最终的预测结果,那么当输入x进去,一层一层的进行选择,就到最后的叶子节点,就完成整个流程,叶子节点的值就是最终的值。
决策树经常用来做分类任务,下面是基本的决策树的结构
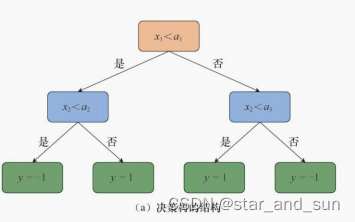
决策树的构造
在构造决策树的时候需要尽可能的减少模型的复杂度,可见决策树的层数和节点数不要过多才最好。
X,Y的取值范围是1,。。。,n 则信息熵的公式
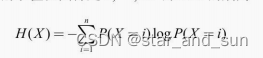
交叉熵
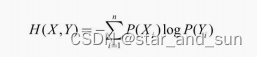
条件熵
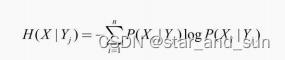
信息增益
**I=H(X)-H(X|Y)**
信息增益率
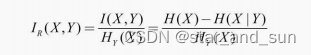
其中
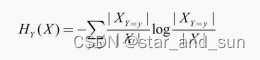
采用信息增益率可以减少模型整体的复杂度。
ID3和C4.5
ID3算法是基于信息增益来做的,C4.5是结合信息增益率来做的,只能解决分类问题。

CART算法
ID3算法,C4.5只能解决分类问题。在回归问题中,采用CART算法,其采用了误差的平方作为标准

此外CART算法可以解决分类问题

import numpy as np
import matplotlib.pyplot as plt
import pandas as pd# 读取数据
data = pd.read_csv('titanic/train.csv')
# 查看数据集信息和前5行具体内容,其中NaN代表数据缺失
print(data.info())
print(data[:5])# 删去编号、姓名、船票编号3列
data.drop(columns=['PassengerId', 'Name', 'Ticket'], inplace=True)
#%%
feat_ranges = {}
cont_feat = ['Age', 'Fare'] # 连续特征
bins = 10 # 分类点数for feat in cont_feat:# 数据集中存在缺省值nan,需要用np.nanmin和np.nanmaxmin_val = np.nanmin(data[feat]) max_val = np.nanmax(data[feat])feat_ranges[feat] = np.linspace(min_val, max_val, bins).tolist()print(feat, ':') # 查看分类点for spt in feat_ranges[feat]:print(f'{spt:.4f}')
#%%
# 只有有限取值的离散特征
cat_feat = ['Sex', 'Pclass', 'SibSp', 'Parch', 'Cabin', 'Embarked']
for feat in cat_feat:data[feat] = data[feat].astype('category') # 数据格式转为分类格式print(f'{feat}:{data[feat].cat.categories}') # 查看类别data[feat] = data[feat].cat.codes.to_list() # 将类别按顺序转换为整数ranges = list(set(data[feat]))ranges.sort()feat_ranges[feat] = ranges
#%%
# 将所有缺省值替换为-1
data.fillna(-1, inplace=True)
for feat in feat_ranges.keys():feat_ranges[feat] = [-1] + feat_ranges[feat]
#%%
# 划分训练集与测试集
np.random.seed(0)
feat_names = data.columns[1:]
label_name = data.columns[0]
# 重排下标之后,按新的下标索引数据
data = data.reindex(np.random.permutation(data.index))
ratio = 0.8
split = int(ratio * len(data))
train_x = data[:split].drop(columns=['Survived']).to_numpy()
train_y = data['Survived'][:split].to_numpy()
test_x = data[split:].drop(columns=['Survived']).to_numpy()
test_y = data['Survived'][split:].to_numpy()
print('训练集大小:', len(train_x))
print('测试集大小:', len(test_x))
print('特征数:', train_x.shape[1])
#%%
class Node:def __init__(self):# 内部结点的feat表示用来分类的特征编号,其数字与数据中的顺序对应# 叶结点的feat表示该结点对应的分类结果self.feat = None# 分类值列表,表示按照其中的值向子结点分类self.split = None# 子结点列表,叶结点的child为空self.child = []
#%%
class DecisionTree:def __init__(self, X, Y, feat_ranges, lbd):self.root = Node()self.X = Xself.Y = Yself.feat_ranges = feat_ranges # 特征取值范围self.lbd = lbd # 正则化系数self.eps = 1e-8 # 防止数学错误log(0)和除以0self.T = 0 # 记录叶结点个数self.ID3(self.root, self.X, self.Y)# 工具函数,计算 a * log adef aloga(self, a):return a * np.log2(a + self.eps)# 计算某个子数据集的熵def entropy(self, Y):cnt = np.unique(Y, return_counts=True)[1] # 统计每个类别出现的次数N = len(Y)ent = -np.sum([self.aloga(Ni / N) for Ni in cnt])return ent# 计算用feat <= val划分数据集的信息增益def info_gain(self, X, Y, feat, val):# 划分前的熵N = len(Y)if N == 0:return 0HX = self.entropy(Y)HXY = 0 # H(X|Y)# 分别计算H(X|X_F<=val)和H(X|X_F>val)Y_l = Y[X[:, feat] <= val]HXY += len(Y_l) / len(Y) * self.entropy(Y_l)Y_r = Y[X[:, feat] > val]HXY += len(Y_r) / len(Y) * self.entropy(Y_r)return HX - HXY# 计算特征feat <= val本身的复杂度H_Y(X)def entropy_YX(self, X, Y, feat, val):HYX = 0N = len(Y)if N == 0:return 0Y_l = Y[X[:, feat] <= val]HYX += -self.aloga(len(Y_l) / N)Y_r = Y[X[:, feat] > val]HYX += -self.aloga(len(Y_r) / N)return HYX# 计算用feat <= val划分数据集的信息增益率def info_gain_ratio(self, X, Y, feat, val):IG = self.info_gain(X, Y, feat, val)HYX = self.entropy_YX(X, Y, feat, val)return IG / HYX# 用ID3算法递归分裂结点,构造决策树def ID3(self, node, X, Y):# 判断是否已经分类完成if len(np.unique(Y)) == 1:node.feat = Y[0]self.T += 1return# 寻找最优分类特征和分类点best_IGR = 0best_feat = Nonebest_val = Nonefor feat in range(len(feat_names)):for val in self.feat_ranges[feat_names[feat]]:IGR = self.info_gain_ratio(X, Y, feat, val)if IGR > best_IGR:best_IGR = IGRbest_feat = featbest_val = val# 计算用best_feat <= best_val分类带来的代价函数变化# 由于分裂叶结点只涉及该局部,我们只需要计算分裂前后该结点的代价函数# 当前代价cur_cost = len(Y) * self.entropy(Y) + self.lbd# 分裂后的代价,按best_feat的取值分类统计# 如果best_feat为None,说明最优的信息增益率为0,# 再分类也无法增加信息了,因此将new_cost设置为无穷大if best_feat is None:new_cost = np.infelse:new_cost = 0X_feat = X[:, best_feat]# 获取划分后的两部分,计算新的熵new_Y_l = Y[X_feat <= best_val]new_cost += len(new_Y_l) * self.entropy(new_Y_l)new_Y_r = Y[X_feat > best_val]new_cost += len(new_Y_r) * self.entropy(new_Y_r)# 分裂后会有两个叶结点new_cost += 2 * self.lbdif new_cost <= cur_cost:# 如果分裂后代价更小,那么执行分裂node.feat = best_featnode.split = best_vall_child = Node()l_X = X[X_feat <= best_val]l_Y = Y[X_feat <= best_val]self.ID3(l_child, l_X, l_Y)r_child = Node()r_X = X[X_feat > best_val]r_Y = Y[X_feat > best_val]self.ID3(r_child, r_X, r_Y)node.child = [l_child, r_child]else:# 否则将当前结点上最多的类别作为该结点的类别vals, cnt = np.unique(Y, return_counts=True)node.feat = vals[np.argmax(cnt)]self.T += 1# 预测新样本的分类def predict(self, x):node = self.root# 从根结点开始向下寻找,到叶结点结束while node.split is not None:# 判断x应该处于哪个子结点if x[node.feat] <= node.split:node = node.child[0]else:node = node.child[1]# 到达叶结点,返回类别return node.feat# 计算在样本X,标签Y上的准确率def accuracy(self, X, Y):correct = 0for x, y in zip(X, Y):pred = self.predict(x)if pred == y:correct += 1return correct / len(Y)
#%%
DT = DecisionTree(train_x, train_y, feat_ranges, lbd=1.0)
print('叶结点数量:', DT.T)# 计算在训练集和测试集上的准确率
print('训练集准确率:', DT.accuracy(train_x, train_y))
print('测试集准确率:', DT.accuracy(test_x, test_y))
#%%
from sklearn import tree# criterion表示分类依据,max_depth表示树的最大深度
# entropy生成的是C4.5分类树
c45 = tree.DecisionTreeClassifier(criterion='entropy', max_depth=6)
c45.fit(train_x, train_y)
# gini生成的是CART分类树
cart = tree.DecisionTreeClassifier(criterion='gini', max_depth=6)
cart.fit(train_x, train_y)c45_train_pred = c45.predict(train_x)
c45_test_pred = c45.predict(test_x)
cart_train_pred = cart.predict(train_x)
cart_test_pred = cart.predict(test_x)
print(f'训练集准确率:C4.5:{np.mean(c45_train_pred == train_y)},' \f'CART:{np.mean(cart_train_pred == train_y)}')
print(f'测试集准确率:C4.5:{np.mean(c45_test_pred == test_y)},' \f'CART:{np.mean(cart_test_pred == test_y)}')
#%%
!pip install pydotplusfrom six import StringIO
import pydotplusdot_data = StringIO()
tree.export_graphviz( # 导出sklearn的决策树的可视化数据c45,out_file=dot_data,feature_names=feat_names,class_names=['non-survival', 'survival'],filled=True, rounded=True,impurity=False
)
# 用pydotplus生成图像
graph = pydotplus.graph_from_dot_data(dot_data.getvalue().replace('\n', ''))
graph.write_png('tree.png')
相关文章:
机器学习——决策树
决策树 决策树可以理解为是一颗倒立的树,叶子在下端,根在最上面 一层一层连接的是交内部节点,内部节点主要是一些条件判断表达式,叶子叫叶节点,叶节点其实就是最终的预测结果,那么当输入x进去,…...
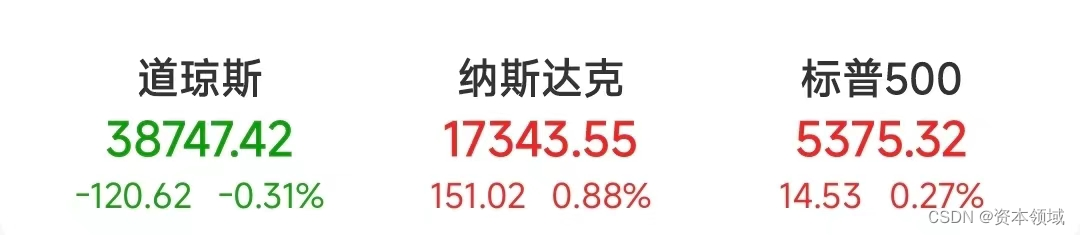
弘君资本:苹果股价暴涨,创历史新高!
当地时间6月11日,美股三大指数涨跌纷歧,标普500指数与纳指再创新高。 到收盘,道指跌0.31%,纳指涨0.88%,标普500指数涨0.27%。 苹果大涨逾7%创前史新高。美联储开端召开6月货币方针会议,周三发布利率决定。…...

web前端拖拽工具:探索其复杂性、困惑度与爆发度
web前端拖拽工具:探索其复杂性、困惑度与爆发度 在Web前端开发中,拖拽功能是一项常见且复杂的需求。拖拽工具可以帮助开发者更高效地实现这一功能,但同时也带来了一定的困惑和挑战。本文将从四个方面、五个方面、六个方面和七个方面对Web前端…...

Web前端数据驱动视图的深度解析
Web前端数据驱动视图的深度解析 在Web前端开发中,数据驱动视图的概念日渐重要,它不仅改变了传统的开发模式,更使得页面动态化和交互性得到了极大的提升。然而,对于许多初学者和开发者来说,如何深入理解和应用这一概念…...

HTML5的新语义化标签
HTML5 引入了一系列新的语义化标签,这些标签为网页内容提供了更明确的含义,有助于改善网页的可访问性和搜索引擎优化(SEO)。以下是一些主要的 HTML5 语义化标签: <article>: 表示页面、应用或网站中…...

周一美股集体低开后转涨,早盘仅道指小幅下跌,英伟达跌超3%后转涨超1%
美国非农就业报告发布“次日”,三大股指低开,但早盘均成功转涨。美股七姐妹涨跌各异,苹果WWDC大会今晚开幕,但早盘转跌,一度跌超1%;1拆10股正式生效的英伟达盘初曾跌超3.2%,开盘1.5小时内首次转…...
Phybers:脑纤维束分析软件包
摘要 本研究提供了一个用于分析脑纤维束数据的Python库(Phybers)。纤维束数据集包含由表示主要白质通路的3D点组成的流线(也称为纤维束)。目前已经提出了一些算法来分析这些数据,包括聚类、分割和可视化方法。由于流线的几何复杂性、文件格式和数据集的大小(可能包…...
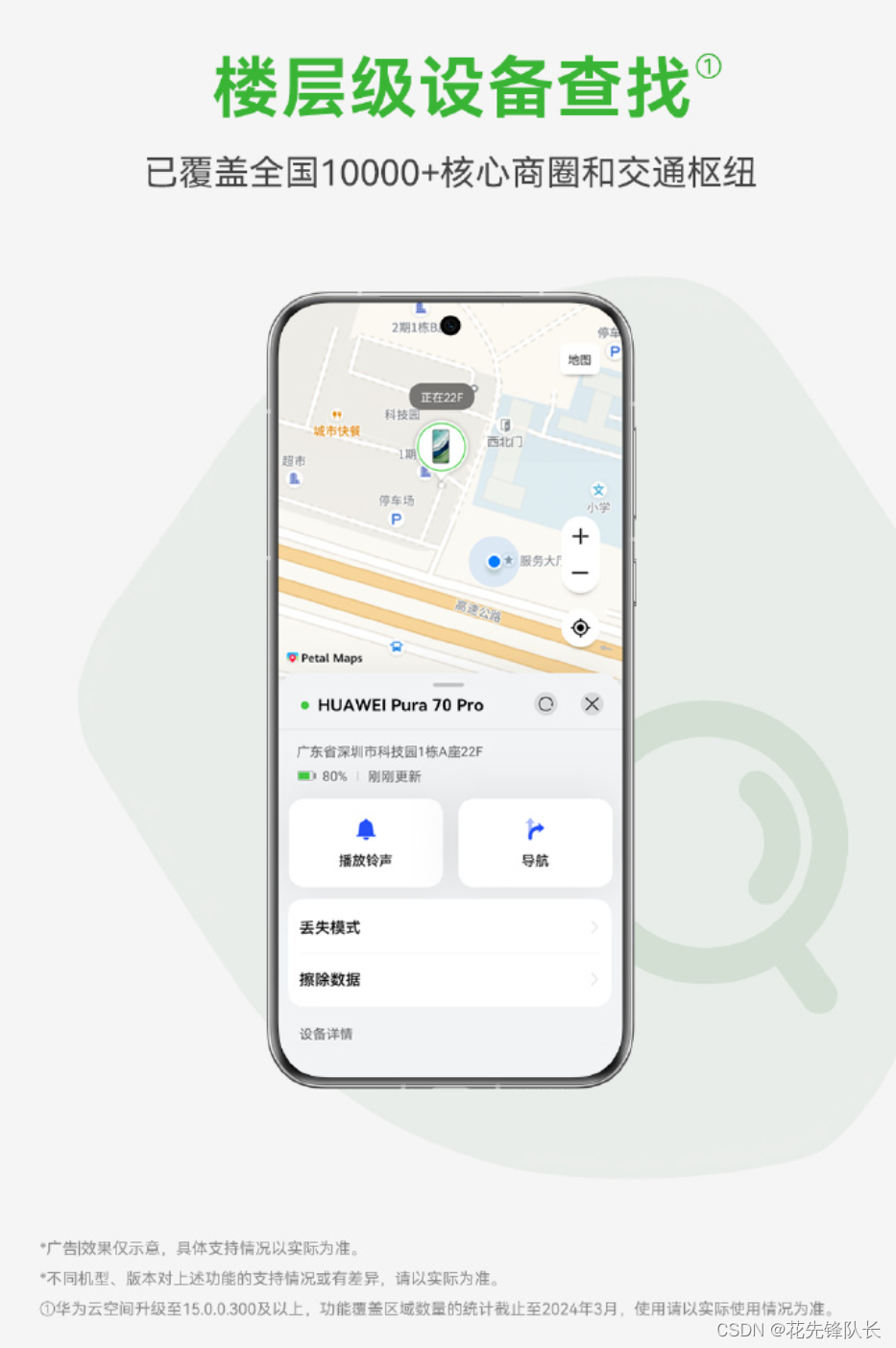
手机丢失不惊慌,华为手机已升级至楼层级设备查找!
出门总是丢三落四,手机丢了怎么办?不要怕,只要你的华为手机升级至云空间新版本,就可以进行楼层级设备查找,现在可以查看到具体的楼层了! 之前有手机丢失过的朋友,肯定有相似的经历,…...

SpringBoot 的多配置文件
文章目录 SpringBoot 的多配置文件spring.profiles.active 配置Profile 和 ActiveProfiles 注解 SpringBoot 的多配置文件 spring.profiles.active 配置 默认情况下,当你启动 SpringBoot 项目时,会在日志中看到如下一条 INFO 信息: No act…...
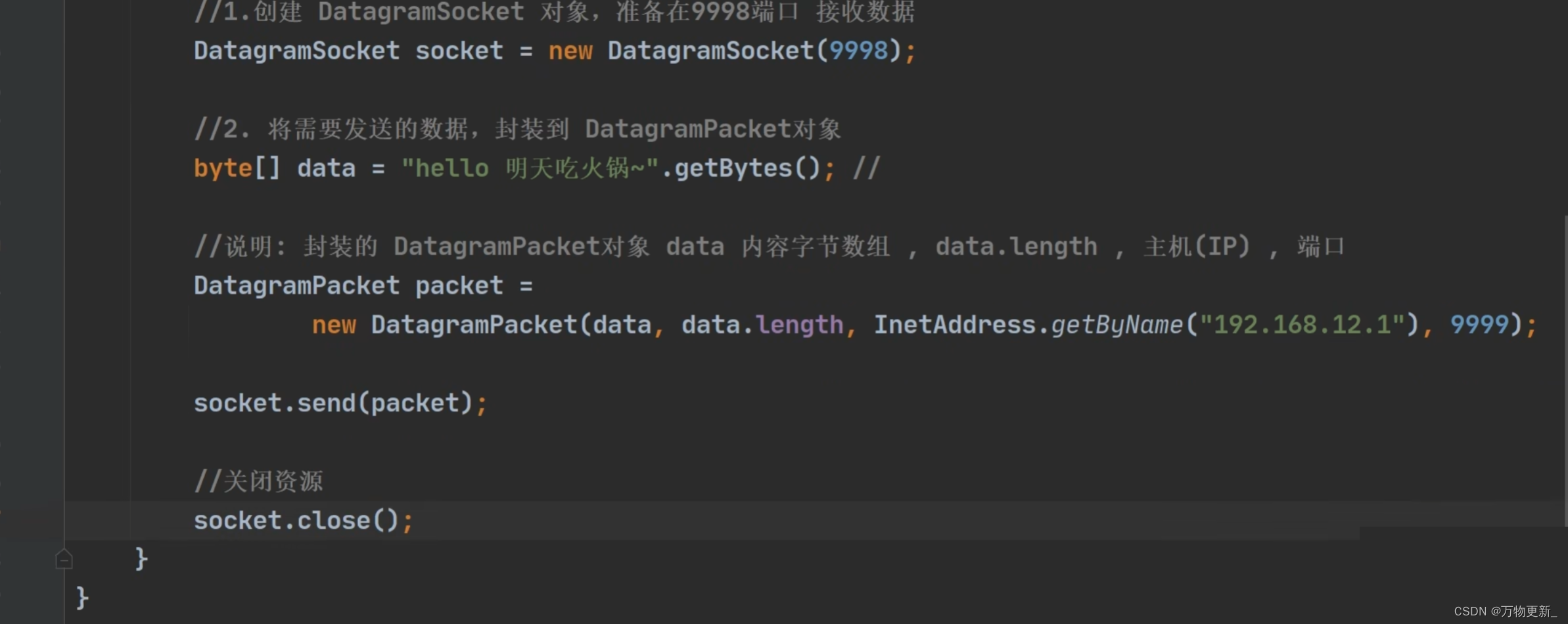
[Java基础揉碎]网络相关概念
目录 网络通信 网络 ip地址 编辑 域名 编辑 网络协议 TCP和UDP 网络编程比较重要的的InetAddress类 Socket 编辑 tcp字节流编程 案例一 案例二编辑 案例三 网络上传文件 编辑编辑 编辑 netstat tcp网络通信客户端也是通过端口和服务端进行通讯的…...
UE5 Sequencer 使用指导 - 学习笔记
https://www.bilibili.com/video/BV1jG411L7r7/?spm_id_from333.337.search-card.all.click&vd_source707ec8983cc32e6e065d5496a7f79ee6 Sequencer 01 1.1 调整视口 调整窗口数量 调整视口类型为Cinematic视口 视口显示网格,或者条件参考线 1.2 关卡动画与…...

Web前端项目源码:深入解析与未来探索
Web前端项目源码:深入解析与未来探索 Web前端项目源码,如同隐藏在数字世界中的宝藏,蕴含着丰富的技术与智慧。它是构建现代网页应用的核心,也是实现用户交互和界面呈现的关键所在。本文将从四个方面、五个方面、六个方面和七个方…...
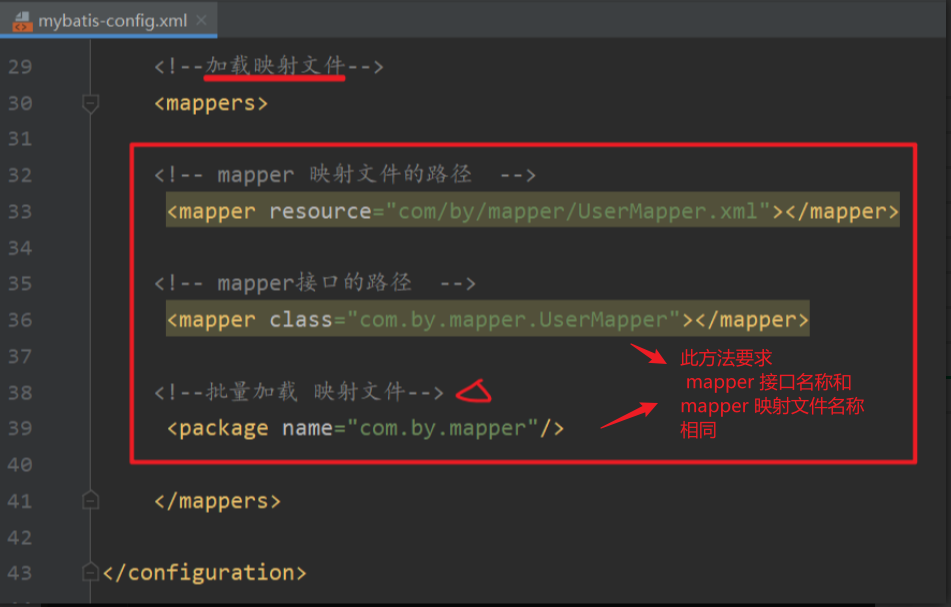
MyBatis的配置文件,即:src->main->resources的配置
目录 1、properties 标签 1.1 mybatis-config.xml 1.2 db.properties 1.3 在SqlMapConfig.xml 中 引入数据库配置信息 2、typeAliases 标签 2.1 定义别名 2.2 使用别名 3、Mappers标签 作用:用来在核心配置文件中引入映射文件 引入方式,有以下…...

completefuture造成的rpc重试事故
前言 最近经历了一个由于 completefuture 的使用,导致RPC重试机制触发而引起的重复写入异常的生产bug。复盘下来,并非是错误的使用了completefuture,而是一些开发时很难意识到的坑。 背景 用户反馈通过应用A使用ota批量升级设备时存在概率…...

6月11号作业
思维导图 #include <iostream> using namespace std; class Animal { private:string name; public:Animal(){}Animal(string name):name(name){//cout << "Animal;有参" << endl;}virtual void perform(){cout << "讲解员的…...

探究Vue源码:深入理解diff算法
前言 在Vue中 组件初次渲染时,会调用 render 函数生成初始的虚拟 DOM 树。 当组件的状态发生变化时,Vue 会重新调用 render 函数生成新的虚拟 DOM 树。 而Diff 算法是用来比较新旧虚拟 DOM 树的差异,并且只对差异部分进行更新的算法,从而尽量…...

qt自适应图片
在 Qt 中,通过重写 paintEvent 方法来添加自适应背景图片的过程如下: 创建一个自定义的 QWidget 子类。重写 paintEvent 方法,在该方法中使用 QPainter 绘制背景图片。使用 QPixmap 加载图片,并调整图片的大小以适应窗口的大小。…...

【区块链】解码拜占庭将军问题:区块链共识机制的哲学基石
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 解码拜占庭将军问题:区块链共识机制的哲学基石引言一、拜占庭将军问…...

MCK主机加固:智能科技,构筑网络安全的铜墙铁壁
在数字化转型的浪潮中,企业服务器的安全已成为维护业务连续性和保护数据资产的关键。MCK主机加固产品,以其创新技术,为企业提供了一个全面、智能、高效的安全解决方案。 一、智能安全监测 MCK主机加固产品采用深度学习算法,能够…...
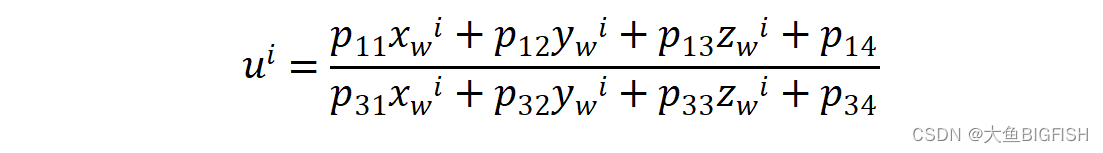
OpenCV 双目相机标定
文章目录 一、简介1.1单目相机标定1.2双目相机标定二、实现代码三、实现效果参考资料一、简介 1.1单目相机标定 与单目相机标定类似,双目标定的目的也是要找到从世界坐标转换为图像坐标所用到的投影P矩阵各个系数(即相机的内参与外参)。具体过程如下所述: 1、首先我们需要…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...