2024海南省大数据教师培训-Hadoop集群部署
前言
本文将详细介绍Hadoop分布式计算框架的来源,架构和应用场景,并附上最详细的集群搭建教程,能更好的帮助各位老师和同学们迅速了解和部署Hadoop框架来进行生产力和学习方面的应用。

一、Hadoop介绍
Hadoop是一个开源的分布式计算框架,由Apache软件基金会维护,专为处理和存储大规模数据集(大数据)而设计。它最初由Doug Cutting和Mike Cafarella开发,灵感来源于Google的两篇论文:《Google File System》和《MapReduce: Simplified Data Processing on Large Clusters》。Hadoop的核心优势在于其高度可扩展性、容错性和成本效益,使得它成为大数据处理领域的基石。
 下面详细解析Hadoop的各个方面:
下面详细解析Hadoop的各个方面:
1. Hadoop分布式文件系统(HDFS)
HDFS是Hadoop的核心组件之一,它是一个高度容错性的分布式文件系统,旨在运行在低成本的硬件设备上。HDFS的设计理念是“一次写入,多次读取”,特别适合大规模数据集的存储。
- 架构:HDFS采用主/从(Master/Slave)架构,其中NameNode作为主节点管理文件系统的元数据(文件名、文件位置等),而DataNodes作为从节点负责实际存储数据块。每个文件会被分割成固定大小的块(默认64MB),并复制到多个DataNode上,通常复制因子为3,以确保数据的高可用性和容错性。
- 数据复制策略:第一个副本放置在客户端所在节点或随机节点,第二个副本放置在不同机架的节点上,第三个副本则位于与第二个副本相同机架的另一个节点上,以此来优化数据访问速度和容错能力。
2. MapReduce核心分布式计算模型
MapReduce是Hadoop中最核心的分布式计算模型,它是一种编程范式,允许开发者在分布式系统上处理和生成大数据集。MapReduce的概念最早由Google提出,并在Apache Hadoop项目中得到实现和广泛应用。以下是关于MapReduce的详细解释:
基本概念
MapReduce的核心思想是将复杂的计算任务分解为两个主要阶段:Map(映射)和Reduce(归约)。这两个阶段分别对应两个用户自定义的函数:map() 和 reduce()。
Map阶段:此阶段负责接收输入数据集并对数据进行初步处理。它将输入数据切分成多个小块(Splits),每个Split由一个Map任务处理。Map任务对每条记录执行用户定义的
map()函数,产生一系列的中间键值对(Intermediate Key-Value Pairs)。Shuffle & Sort阶段:在Map和Reduce阶段之间,有一个重要的步骤称为Shuffle(洗牌)和Sort(排序)。在这个阶段,Map任务产生的中间键值对会被按照键进行排序、分区,并且可能需要在网络上传输到相应的Reduce任务节点。
Reduce阶段:Reduce任务负责接收来自各个Map任务的特定键的所有值,对它们进行聚集操作(例如求和、平均、最大值等)。用户定义的
reduce()函数会对相同键的所有值进行迭代处理,生成最终的输出键值对。
关键特性
- 并行处理:Map和Reduce任务可以在Hadoop集群中的多个节点上并行执行,大大加快了数据处理的速度。
- 容错性:Hadoop MapReduce框架自动处理任务失败的情况,通过重新执行失败的任务来保证计算的完整性。
- 扩展性:可以通过向集群添加更多的节点来线性地扩展计算能力,处理更大的数据集。
- 资源管理:在Hadoop 2.x及之后的版本中,YARN(Yet Another Resource Negotiator)负责集群资源的管理和调度,使得MapReduce作业能够更高效地与其他计算框架共享资源。
使用场景
MapReduce适用于处理大规模离线数据,如日志分析、网页索引构建、数据统计分析等场景。它尤其适合那些可以被分解为大量独立操作的任务,但对实时性要求不高的情况。
缺点与限制
尽管MapReduce非常强大,但它也有一定的局限性:
- 延迟较高:由于数据处理流程涉及多次磁盘I/O和网络传输,MapReduce不适合低延迟或实时处理需求。
- 编程模型限制:所有的计算都必须能够表达为Map和Reduce操作,这在处理某些复杂计算逻辑时可能会显得笨拙。
- 资源消耗:在处理大量小文件时,MapReduce可能会因为启动大量任务而导致较高的资源开销。
3. YARN(Yet Another Resource Negotiator)
YARN(Yet Another Resource Negotiator)是Apache Hadoop项目中的一个关键组件,它作为从Hadoop 2.x版本开始引入的资源管理系统,彻底改变了Hadoop的工作方式,特别是对于如何管理集群资源以及运行各种类型的应用程序。YARN的设计目标是为了提高Hadoop的灵活性和通用性,使其不仅仅局限于批处理作业,还能支持流处理、交互式查询、机器学习等多种计算框架。
核心架构
YARN架构分为几个关键组件,这些组件协同工作,提供了动态、可伸缩的资源管理能力:
ResourceManager (RM): 负责整个集群的资源管理和分配。它是集群的中心管理者,接收来自各个应用的资源请求,并基于容量调度器(Capacity Scheduler)或公平调度器(Fair Scheduler)策略决定如何分配资源给各个应用程序。
NodeManager (NM): 部署在每个节点上,负责容器管理与监控,以及向ResourceManager报告本节点的资源使用情况和健康状况。容器是YARN中资源抽象的基本单位,包括CPU、内存等。
ApplicationMaster (AM): 每个应用程序在运行时会启动一个ApplicationMaster实例,负责向ResourceManager协商资源,并与NodeManager通信来启动和监控该应用的具体任务(比如MapReduce任务、Spark executor等)。ApplicationMaster是特定于应用程序的,了解如何运行和管理该类型的应用。
Client: 提交应用程序到ResourceManager的客户端。它还负责监控应用程序的状态,并在应用程序完成后获取其输出。
工作流程
- 应用提交:客户端向ResourceManager提交应用的资源请求。
- 资源分配:ResourceManager为应用分配一个ApplicationMaster,并在某个NodeManager上启动它。
- 任务调度:ApplicationMaster进一步向ResourceManager请求具体任务所需的资源,ResourceManager根据当前集群资源状况分配容器。
- 任务执行:ApplicationMaster与对应的NodeManager通信,指示其在分配的容器中启动任务。
- 监控与状态更新:ApplicationMaster监控所有任务的执行进度,并向ResourceManager报告应用状态。同时,NodeManager也定期向ResourceManager发送心跳,报告容器状态。
- 应用完成:当所有任务执行完毕,ApplicationMaster通知ResourceManager,然后关闭自己并释放资源。
优势
- 灵活性:YARN允许多种计算框架共存于同一集群中,不再局限于MapReduce。
- 高效资源利用:通过细粒度的资源分配和动态调整,提高了集群资源的利用率。
- 可扩展性:设计上支持大规模集群,容易横向扩展以处理更多数据和运行更多应用程序。
- 故障恢复:提供快速故障检测和恢复机制,确保应用程序的高可用性。
YARN的引入,使得Hadoop生态系统更加健壮,为大数据处理提供了更强大的支撑平台。
4. Hadoop生态系统
Hadoop生态系统是一个围绕Apache Hadoop核心组件(主要包括HDFS、MapReduce和YARN)构建起来的庞大而多样化的工具和框架集合,旨在解决大数据处理、存储、分析、管理和访问的各种需求。以下是一些关键组件和工具的概述:
核心组件
HDFS (Hadoop Distributed File System): 一个高度容错性的分布式文件系统,设计用于运行在商用硬件上。它将大文件分割成块并存储在不同的节点上,同时保持多个副本以确保数据的可靠性和高可用性。
MapReduce: 一个分布式计算框架,允许在大量计算节点上并行处理大规模数据集。它将数据处理任务分为两个阶段:Map(映射)和Reduce(归约),非常适合批处理任务。
YARN (Yet Another Resource Negotiator): Hadoop 2.x版本引入的资源管理器,它分离了资源管理与任务调度/监控,使Hadoop能够支持多种计算框架,而不仅仅是MapReduce。
重要工具和框架
Hive: 提供了一种类似SQL的查询语言(HQL),允许用户对存储在Hadoop中的数据进行查询和分析,适合大数据仓库应用。
Pig: 是一种数据流语言,设计用于处理大规模数据集,通过其Pig Latin脚本语言,用户可以编写复杂的数据转换和分析任务。
HBase: 是一个分布式、列式存储的NoSQL数据库,建立在HDFS之上,适合随机读写访问和实时查询。
ZooKeeper: 一个分布式的、开放源码的协调服务,提供配置管理、命名服务、分布式同步和组服务等功能,常作为其他组件的依赖。
Spark: 虽然不是Hadoop直接的组成部分,但常与Hadoop生态系统集成使用,提供了一个更快、更通用的数据处理框架,支持批处理、交互式查询、流处理和机器学习等多种计算模型。
Flume: 一个高可用、高可靠的系统用于收集、聚合和移动大量日志数据到HDFS或其他存储系统中。
Sqoop: 用于在Hadoop和关系型数据库之间高效传输数据,支持批量导入导出操作。
Oozie: 一个工作流调度系统,用于管理Hadoop作业的执行顺序,支持定时执行、依赖管理和错误处理。
Kafka: 虽然是一个独立的项目,但在Hadoop生态系统中常用于构建实时数据管道,作为高吞吐量的分布式消息系统。
Ambari: 一个用于管理和监控Hadoop集群的工具,提供了Web UI用于配置、管理和监控Hadoop生态系统中的各种服务。
5. 应用场景

Hadoop作为一个强大的大数据处理平台,其应用场景广泛且多样,涵盖了众多行业和领域。以下是一些典型的Hadoop应用场景:
(1). 在线旅游和电子商务
- 全球众多在线旅游网站(如Expedia)利用Hadoop处理和分析用户行为数据,优化搜索排名,个性化推荐旅行套餐,以及进行市场趋势分析。
- 电商平台(如eBay)使用Hadoop处理海量交易数据,进行用户行为分析、库存管理、价格优化以及销售预测。
(2). 移动数据分析
- Hadoop用于处理和分析来自智能手机的大量数据,包括用户行为、应用使用情况、位置服务等,帮助电信运营商优化网络性能、设计定制化服务和广告投放策略。
(3). 金融服务
- 金融机构运用Hadoop处理交易数据,进行风险评估、欺诈检测、信用评分以及市场趋势分析。
- 银行和保险公司使用Hadoop进行大规模数据的ETL(抽取、转换、加载)处理,构建数据仓库和数据湖。
(4). 社交媒体和内容平台
- 社交媒体公司利用Hadoop分析用户生成的内容、情感分析、趋势预测以及进行推荐系统的优化。
- 视频和内容分享平台使用Hadoop处理视频转码、内容分类和用户行为分析,以提升用户体验。
(5). 能源与公共事业
- 能源公司(如Chevron)利用Hadoop进行地质数据的分析,辅助油气勘探和开采决策。
- 公用事业公司(如Opower)使用Hadoop分析用户电表数据,提供节能建议和预测性维护服务。
(6). 医疗健康
- 医疗机构和研究机构利用Hadoop处理和分析电子病历、基因组数据,支持疾病研究、药物开发和个性化医疗。
(7). 广告技术和市场营销
- 广告公司利用Hadoop分析用户浏览习惯、点击流数据,进行精准营销和广告效果评估。
(8). 政府和公共部门
- 政府机构使用Hadoop整合和分析跨部门数据,进行人口统计分析、城市规划、公共安全监测等。
(9). 物联网(IoT)和传感器数据
- Hadoop处理来自智能设备和传感器的大量数据,用于预测性维护、能耗管理、环境监测等。
(10). 科研和学术
- 在科学研究中,Hadoop帮助处理天文观测、气候模拟、粒子碰撞实验等产生的庞大数据集,加速科学发现。
这些应用场景展示了Hadoop在处理大数据挑战方面的灵活性和强大能力,无论是数据存储、处理还是分析,Hadoop都能提供强大的支持。随着技术的进步和行业需求的增长,Hadoop的应用范围预计还会继续扩大。
6. 优缺点
优点:
- 高扩展性:容易横向扩展,支持处理PB级数据。
- 容错性强:通过数据复制和故障恢复机制保证数据安全。
- 成本效益:可在低成本硬件上运行,减少投入成本。
- 易于编程:MapReduce模型简化了分布式编程。
缺点:
- 低延迟问题:Hadoop更擅长批处理,对于实时或低延迟要求的处理不够理想。
- 小文件问题:处理大量小文件时效率较低。
- 复杂性:维护和管理一个Hadoop集群可能需要专门的技术团队。
Hadoop通过其强大的数据存储和处理能力,成为了大数据时代的重要基础设施,不断推动着数据驱动的决策制定和业务创新。
社区版和商业版
社区版
商业版
分支发展
Hadoop 的版本很特殊,是由多条分支并行的发展着。大的来看分为 3 个大 的系列版本:1.x、2.x、3.x。
Hadoop1.0 由一个分布式文件系统 HDFS 和一个离线计算框架 MapReduce 组成。架构落后,已经淘汰。Hadoop 2.0 则包含一个分布式文件系统 HDFS,一个资源管理系统 YARN 和一个离线计算框架 MapReduce。相比于 Hadoop1.0,Hadoop 2.0 功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。Hadoop 3.0 相比之前的 Hadoop 2.0 有一系列的功能增强。目前已经趋于稳
定,可能生态圈的某些组件还没有升级、整合完善。
Hadoop 集群搭建
搭建教程中使用到的所有文件和工具都可以在我的资源中下载到。
1、集群简介
NameNodeDataNodeSecondaryNameNode
ResourceManagerNodeManager
Standalone mode(独立模式)Pseudo-Distributed mode(伪分布式模式)Cluster mode(群集模式)
2、搭建角色分配
node1 NameNode DataNode ResourceManagernode2 DataNode NodeManager SecondaryNameNodenode3 DataNode NodeManager
3、网络环境配置
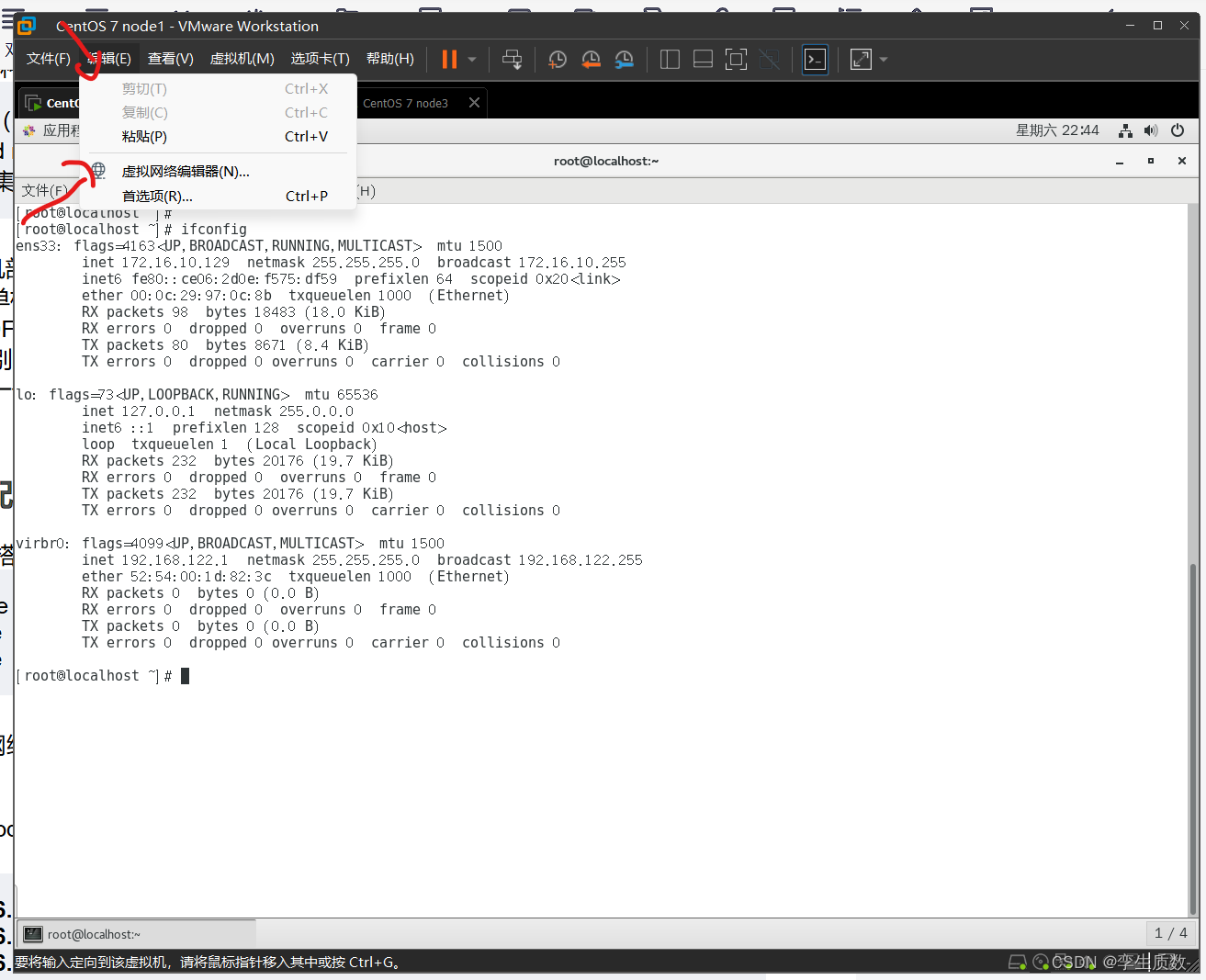
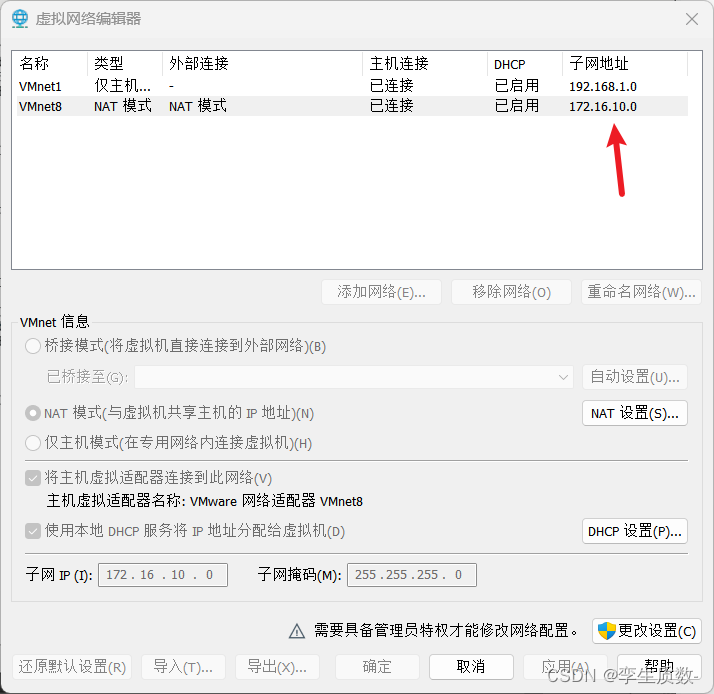
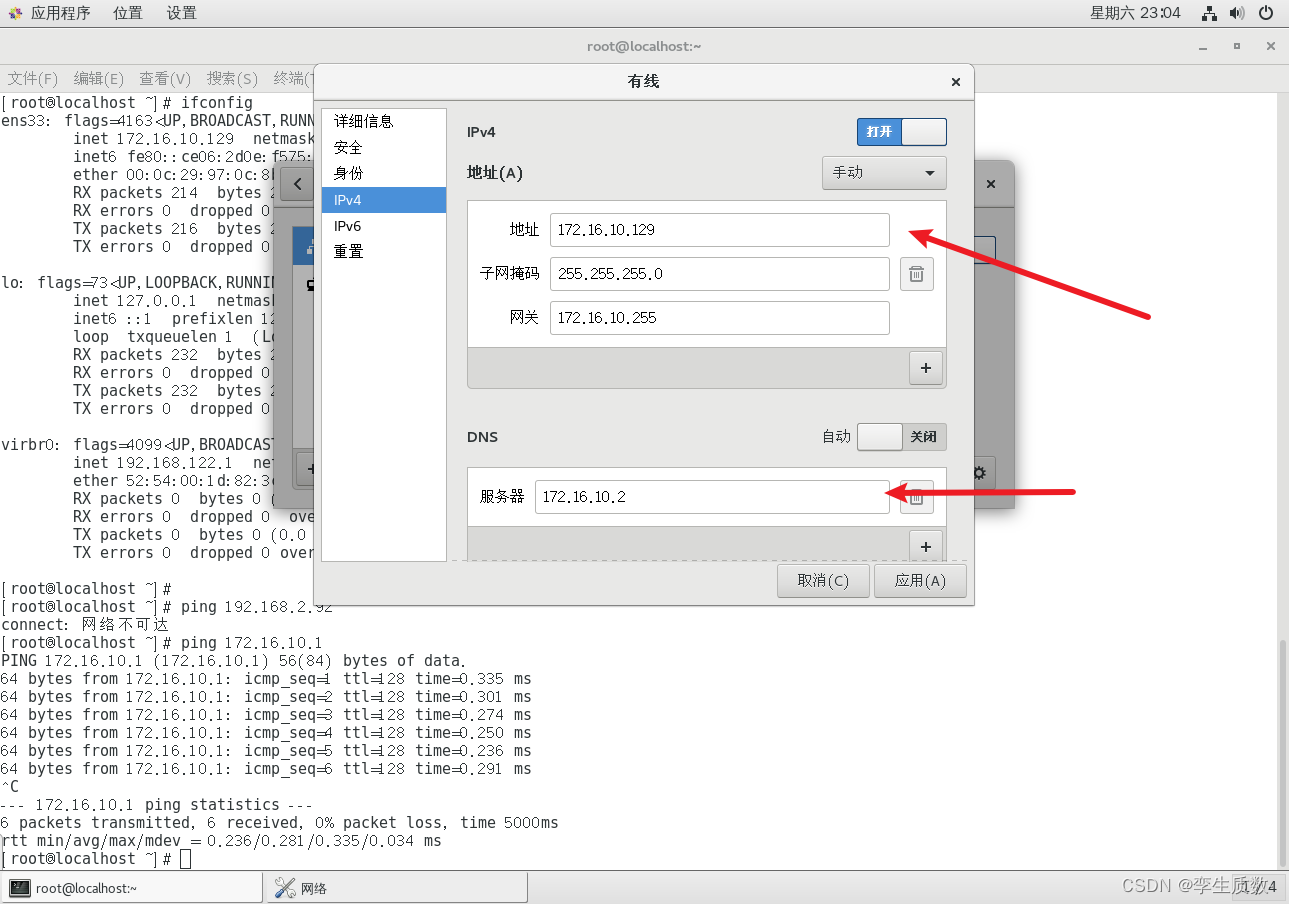
node 1 inet 172.16.10.129 netmask 255.255.255.0 broadcast 172.16.10.255node 2 inet 172.16.10.130 netmask 255.255.255.0 broadcast 172.16.10.255node 3 inet 172.16.10.131 netmask 255.255.255.0 broadcast 172.16.10.255
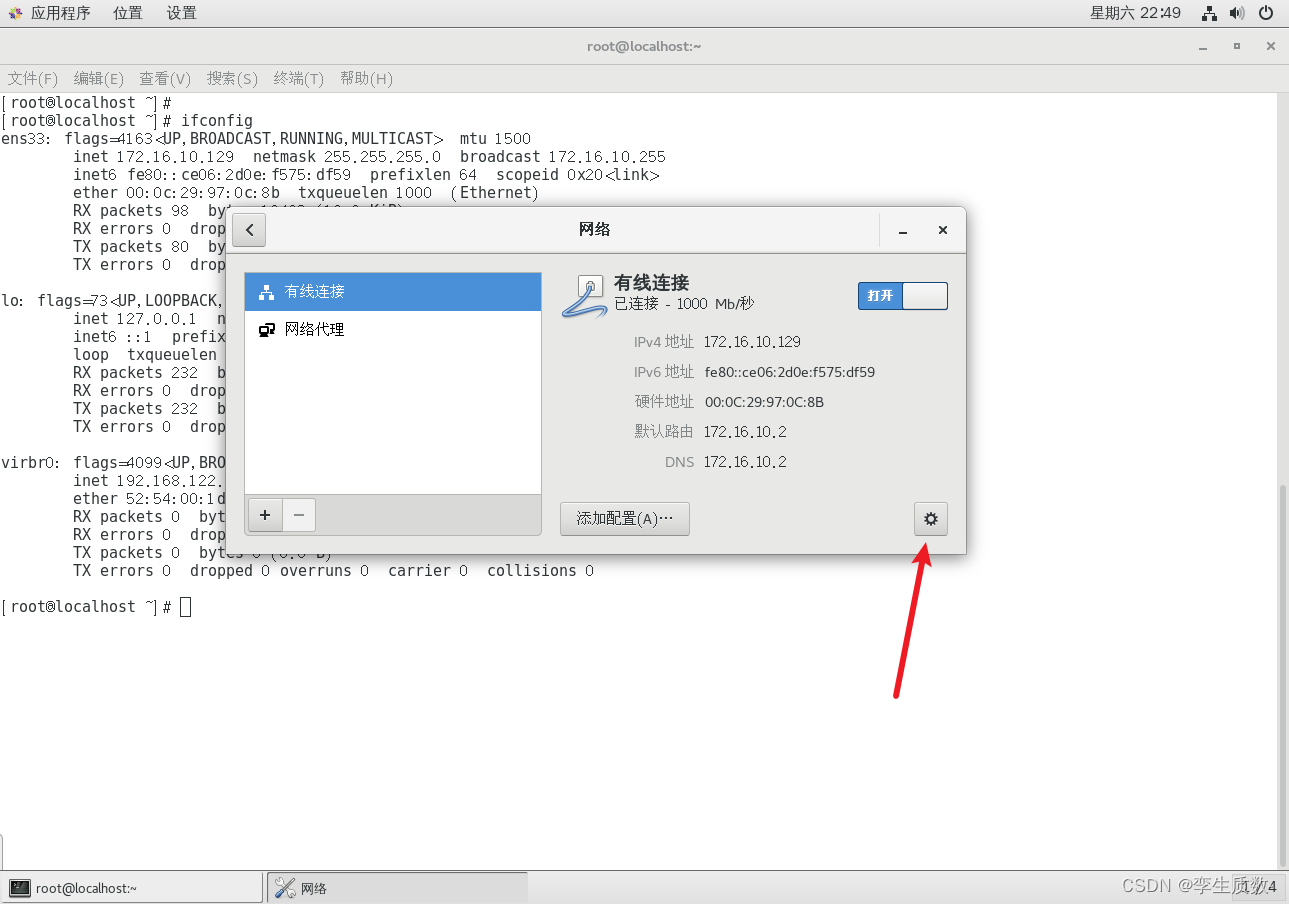
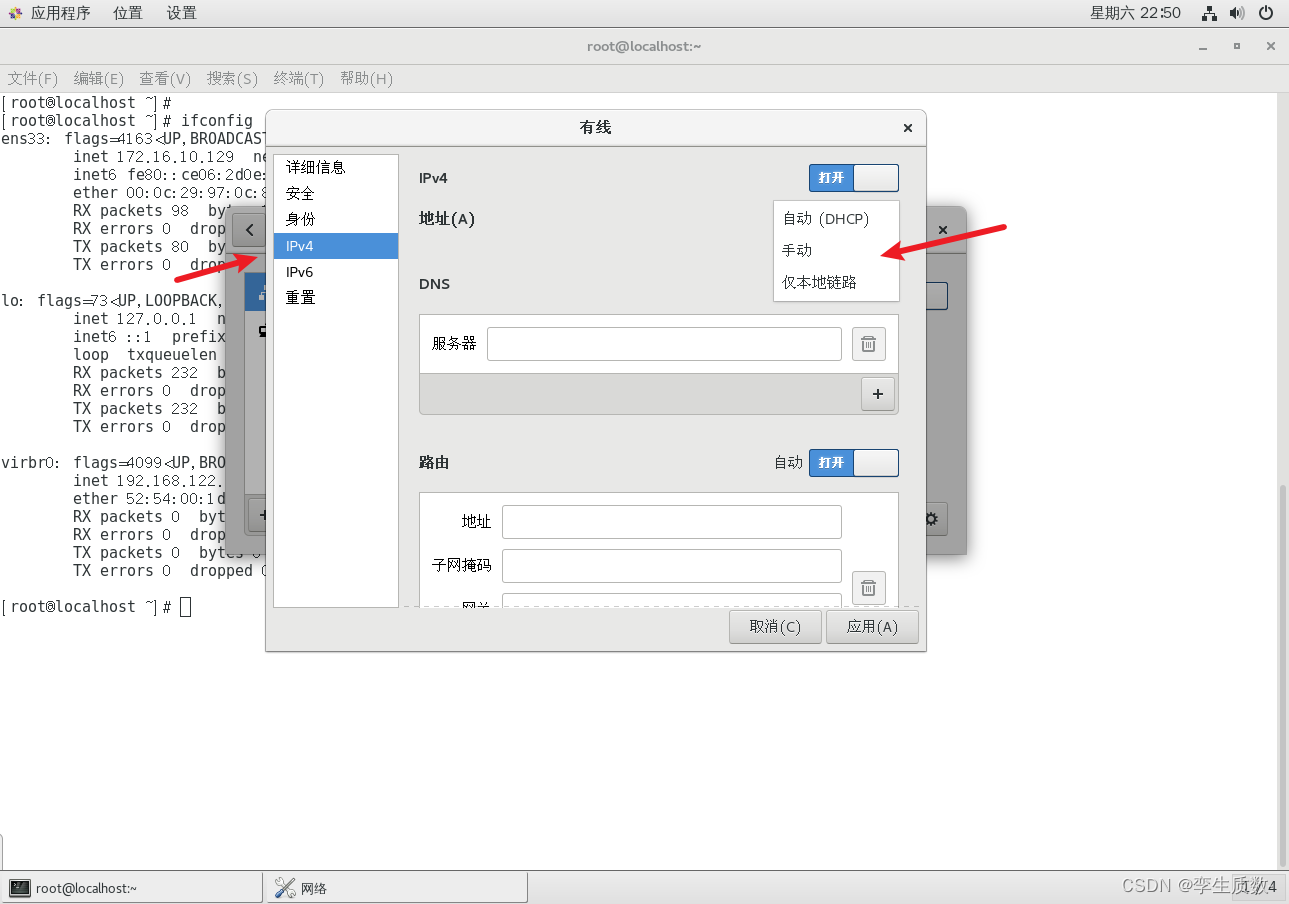
图形化设置: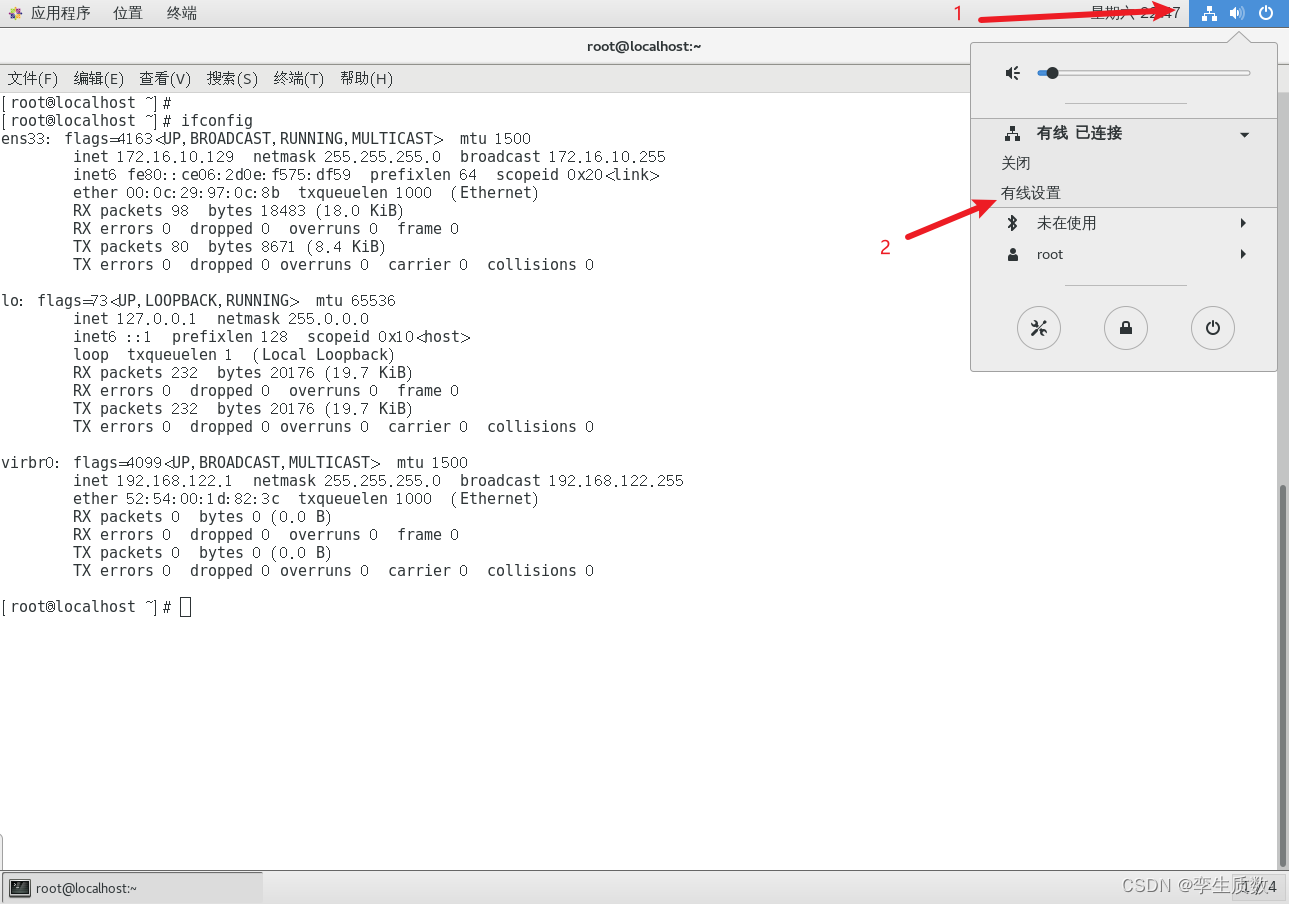
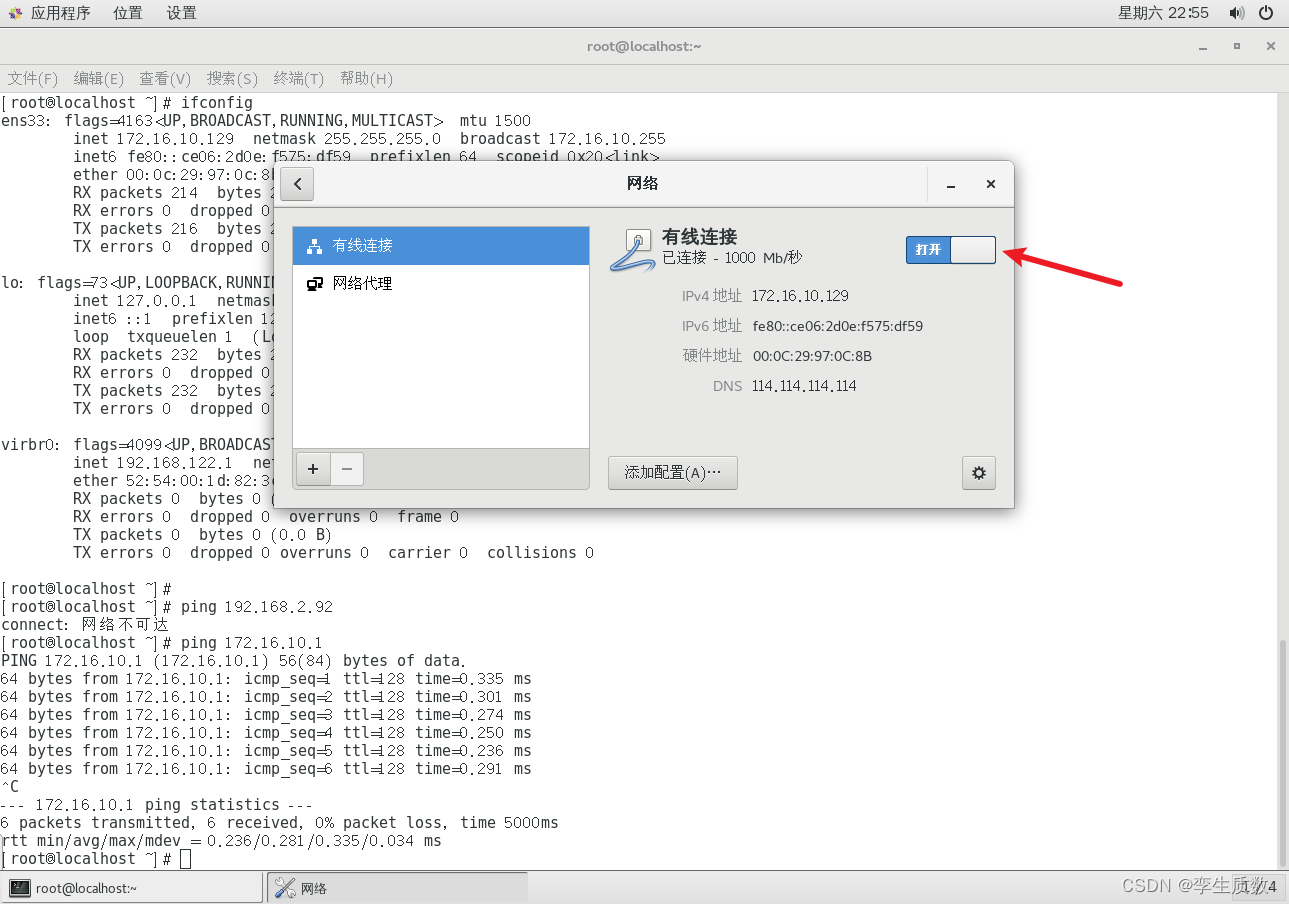
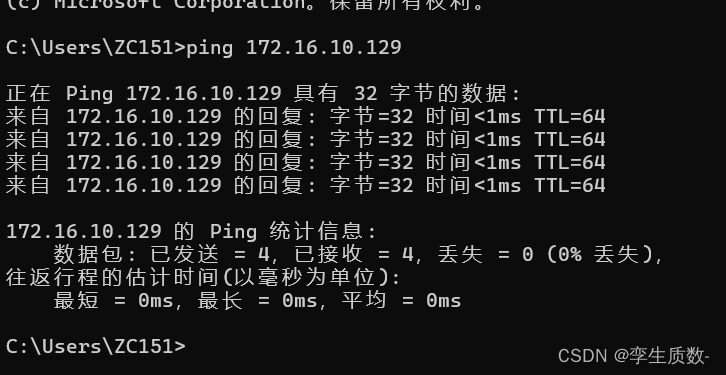
命令行配置:
(2)、修改各个虚拟机主机名
Linux中修改配置文件会频繁使用到vim这个工具,如果不会使用的可以点击下面的链接跳转到vim工具的认识和基础使用。Linux中vim编辑器的使用方法及命令详解_使用vim工具编写程序并显示行号,保存为文件txt-CSDN博客文章浏览阅读1.4w次,点赞14次,收藏63次。文章目录Vim编辑器的使用Vi简述vim的三种模式概述转换方式文本编辑1. 命令行模式功能键2.底行模式功能键上机任务:vi编辑器Vim编辑器的使用Vi简述Linux 提供了一系列功能强大的编辑器,如 vi 和 Emacs 。 vi 是 linux 系统的第一个全屏幕交互式编辑器。vim是vi的强化版本,完全兼容vi操作。vim的一般使用方法:# vim filepath //如..._使用vim工具编写程序并显示行号,保存为文件txthttps://blog.csdn.net/Sevel7/article/details/105189768
vi /etc/hostname
node1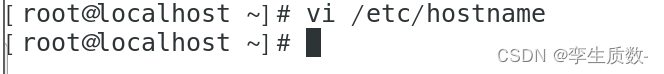

reboot #重启 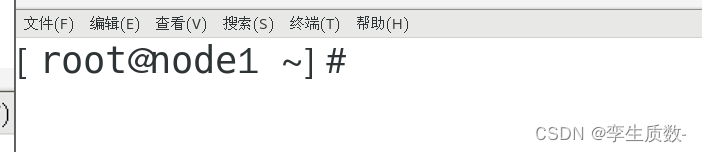
node 2 node 3 执行相同操作。
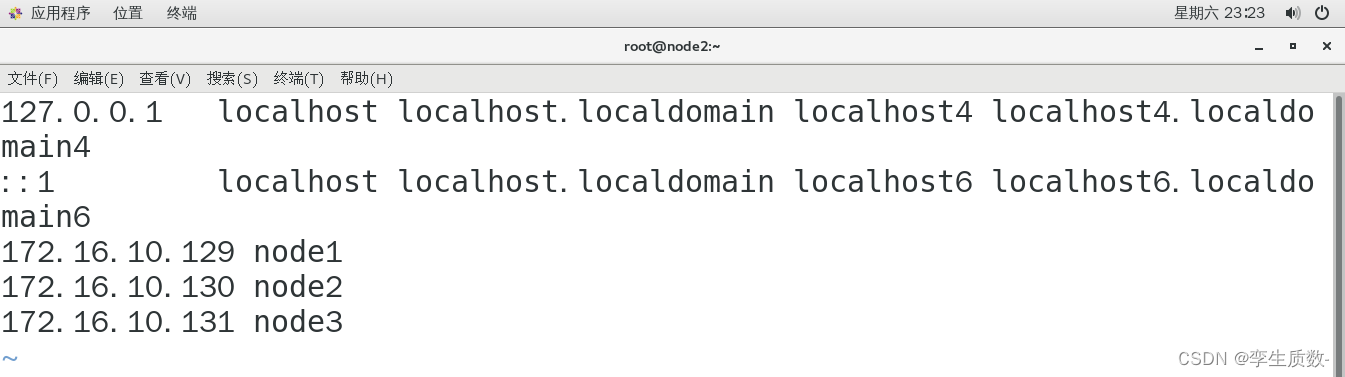
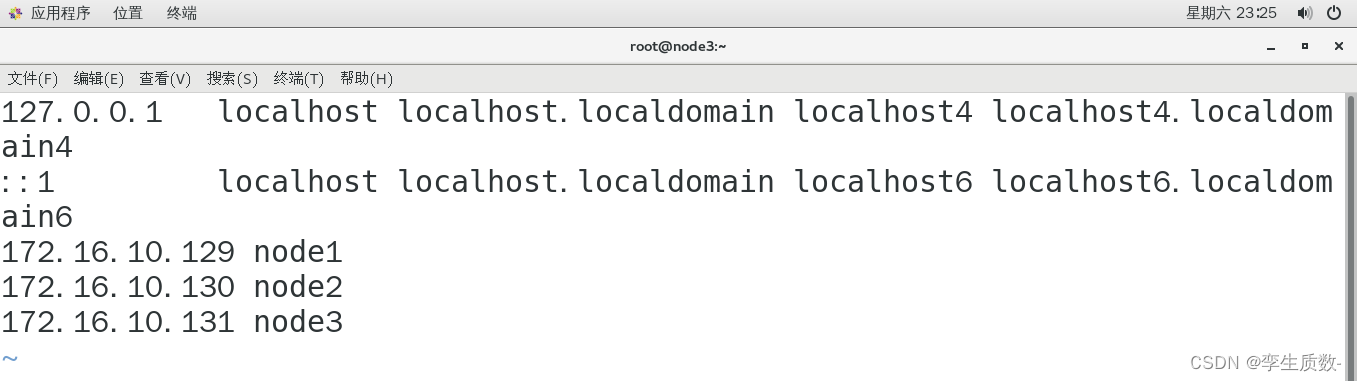
(3)、修改主机名和 IP 的映射关系
修改node1、node2、node3的hosts文件,添加以下几项映射关系。
vi /etc/hosts172.16.10.129 node1
172.16.10.130 node2
172.16.10.131 node3node1

/etc/init.d/network restart


测试:
node1:

node2:
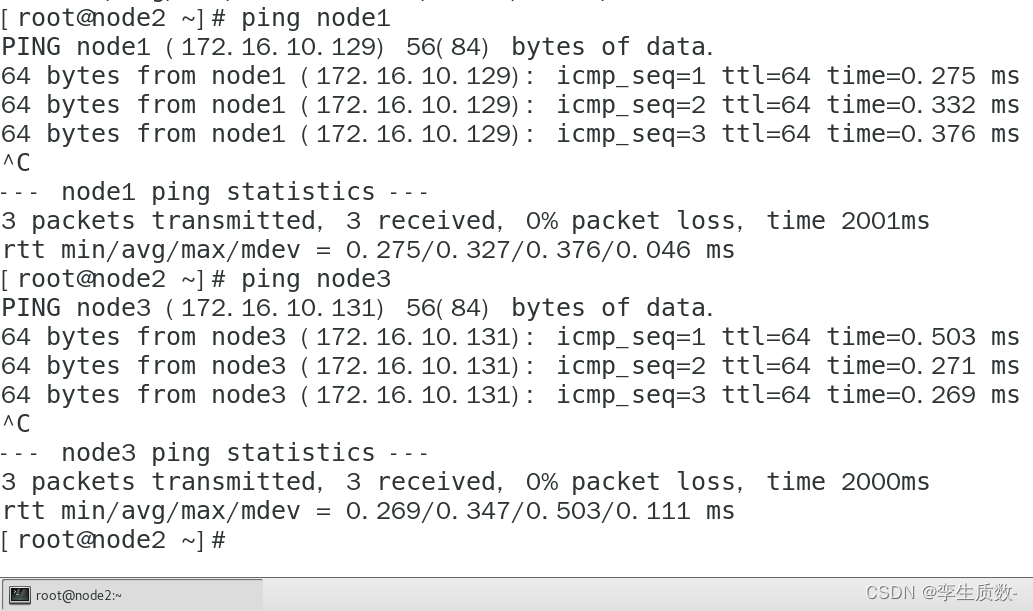
node3:
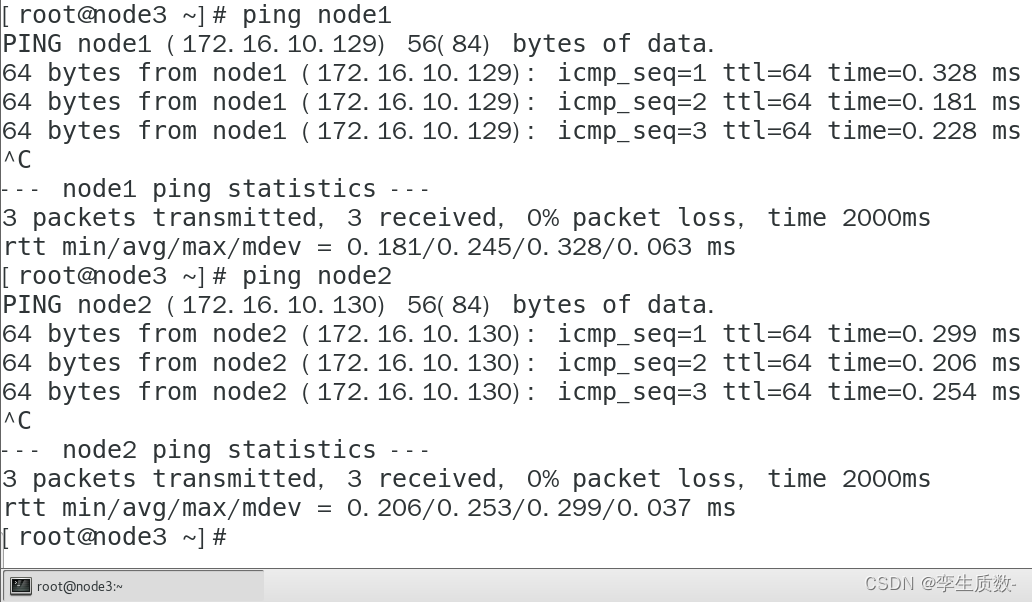
测试映射关系没问题,进行下一步。
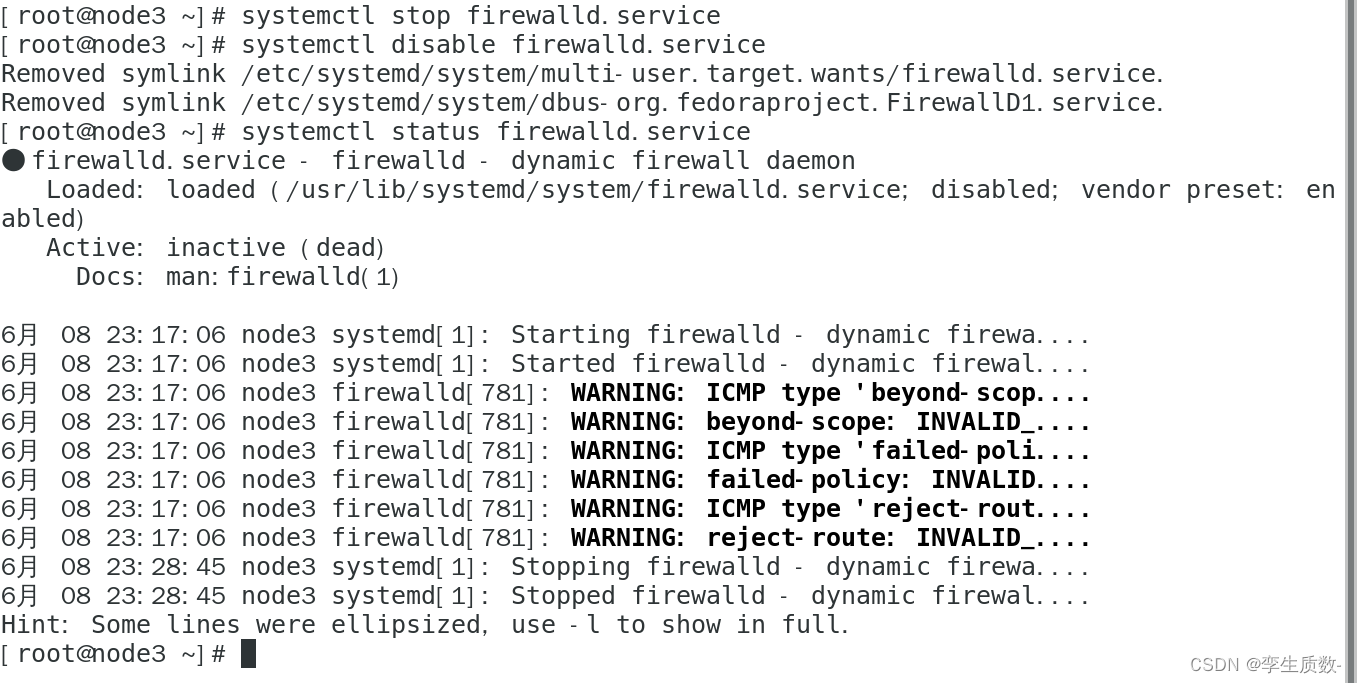
(4)、关闭防火墙
#查看防火墙状态
systemctl status firewalld.service
#关闭防火墙
systemctl stop firewalld.service
#关闭防火墙开机启动
systemctl disable firewalld.servicenode1、node2、node3都要关闭防火墙。
node1:
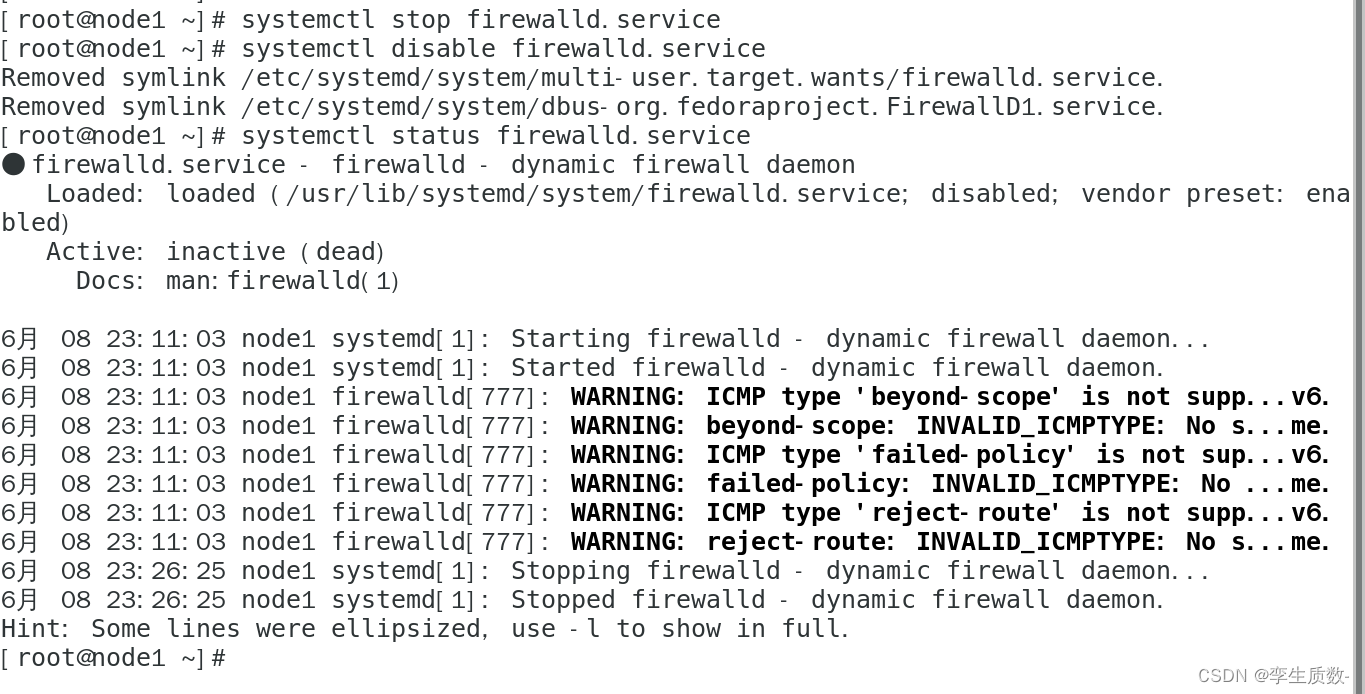
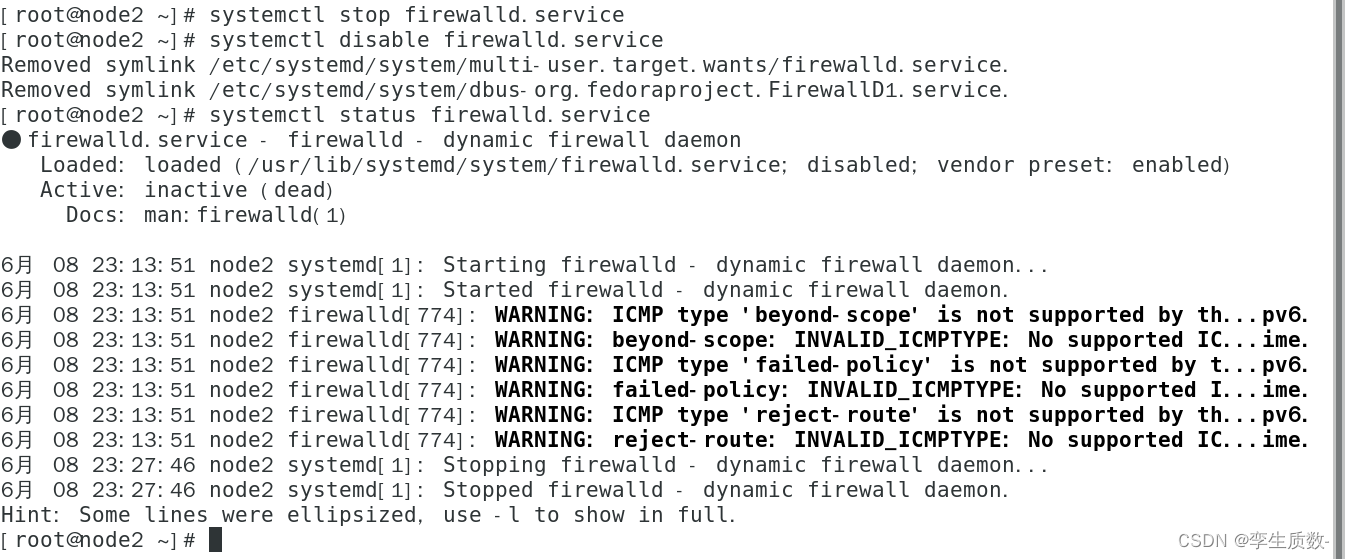
(5)、配置 ssh 免登陆
ssh-keygen -t rsa (一直回车)
执行完这个命令后,会生成两个文件 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3拷贝过程中首先会出现要求你输入yes确认,然后输入拷贝目标主机的ssh密码,输入完成后回车即可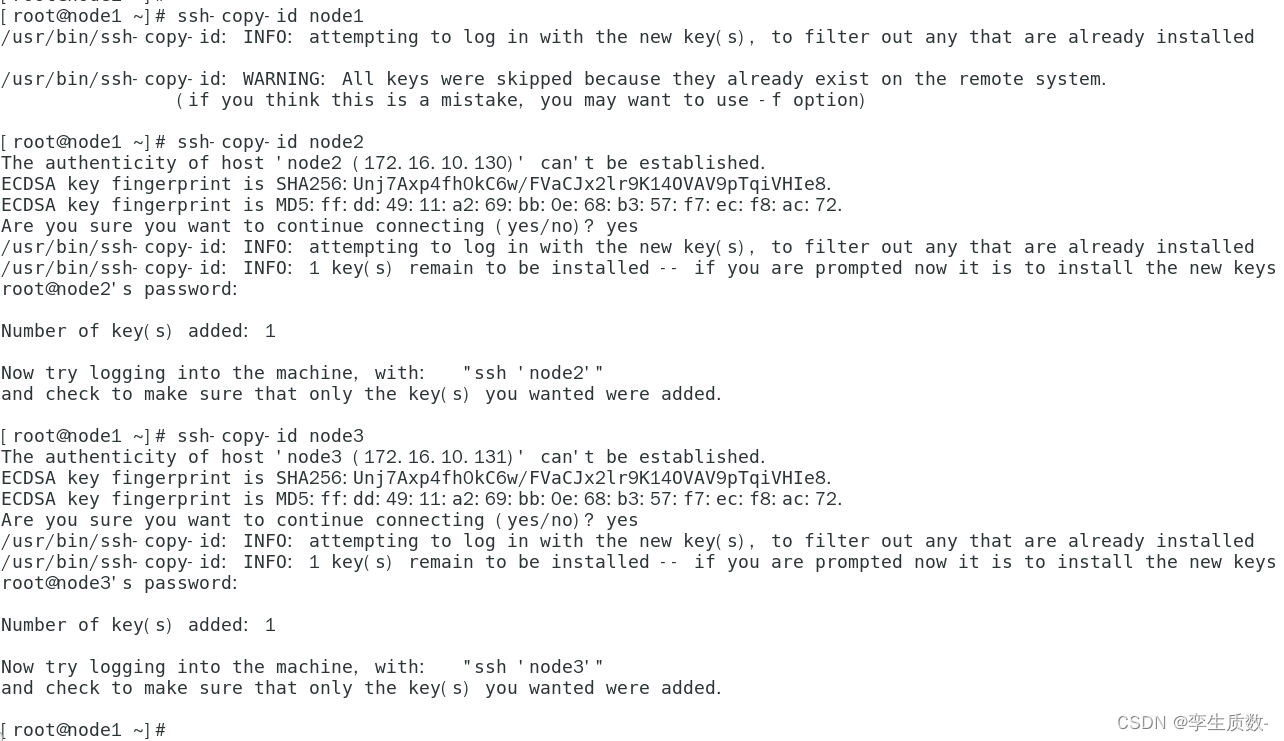
测试:
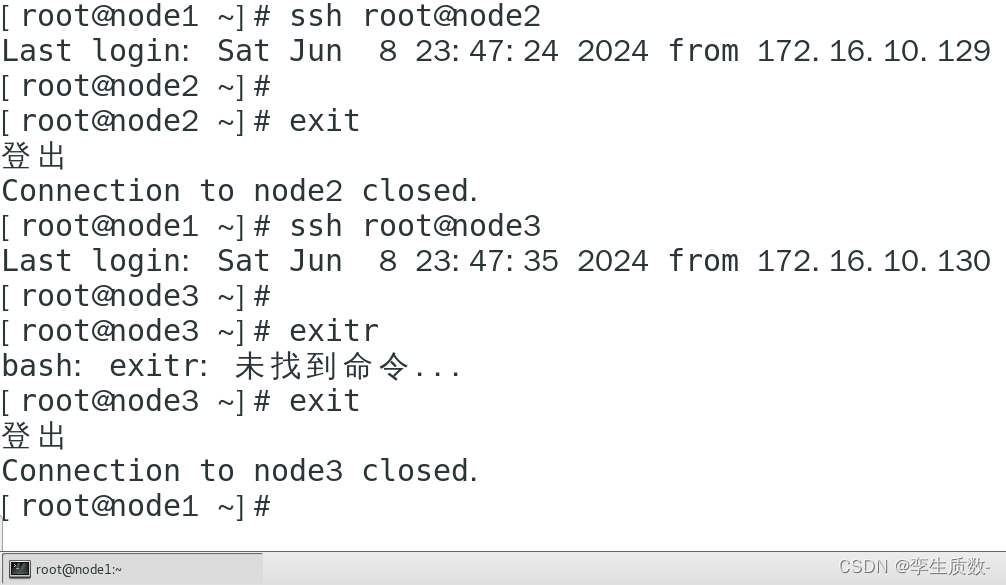
这里进入node2后又退出的原因是因为我们只做了node1免密node2和node3,而node2、3并没有免密node1和相互免密!!!
为了后面少出bug,我这里直接给node1、2、3全部配置上免密登录ssh。方法同上操作,一定要给自己也配置免密!!
从这里我将使用xshell7工具连接node1、2、3来操作。
(6)、同步集群时间
yum install ntpdate
ntpdate cn.pool.ntp.org 集群无法部署成功,很大一部分是集群的系统时间不同,因为同步集群时间不只这两行代码能完成,所以这里给出一个跳转链接,需要同步集群时间操作的可以去看看。CentOS-7的集群时间同步(ntp方式)_centos cluster ntp-CSDN博客![]() https://blog.csdn.net/zhangbeizhen18/article/details/107602525
https://blog.csdn.net/zhangbeizhen18/article/details/107602525
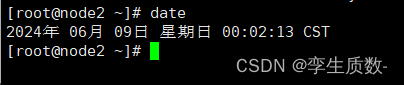
date因为多台服务器,你没必要i同时三台输入命令,查看系统时间,所以一般对上分钟就没多大问题。
node1:

4、JDK 环境安装
卸载虚拟机自带的 JDK
注意:如果你的虚拟机是最小化安装不需要执行这一步。[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodepsrpm -qa :查询所安装的所有 rpm 软件包grep -i :忽略大小写xargs -n1 :表示每次只传递一个参数rpm -e –nodeps :强制卸载软件



上传 jdk
jdk-8u241-linux-x64.tar.gz #资源在我主页资源中自行查找
创建目录
Linux常用命令:
Linux mkdir命令教程:如何创建目录(附实例详解和注意事项)_创建目录,mkdir.未定义标识符要怎么办?-CSDN博客![]() https://blog.csdn.net/u012964600/article/details/136169415node1、2、3都要创建。
https://blog.csdn.net/u012964600/article/details/136169415node1、2、3都要创建。
Mkdir -p /export/server
解压 jdk
tar -zxvf jdk-8u241-linux-x64.tar.gz -C /export/server

将 java 添加到环境变量中
先在node1配置,配置完成后使用scp命令同步到node2和node3即可。
vim /etc/profile.d/my_env.sh#在文件最后添加
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar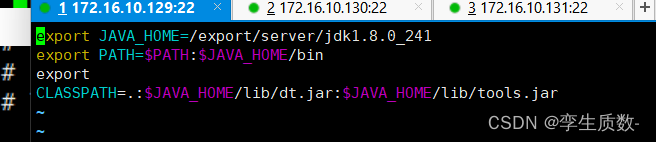
source /etc/profile
java -version


5、Hadoop 重新编译
6、Hadoop 安装包目录结构
bin : Hadoop 最基本的管理脚本和使用脚本的目录 ,这些脚本是 sbin 目录 下管理脚本的基 础实现,用户可以直接使用这些脚本管理和使用 Hadoop。etc : Hadoop 配置文件所在的目录 ,包括 core-site,xml、hdfs-site.xml、 mapred-site.xml 等从 Hadoop1.0 继承而来的配置文件和 yarn-site.xml 等
include :对外提供的编程库头文件(具体动态库和静态库在 lib 目录中), 这些头文件均是 用 C++定义的,通常用于 C++程序访问 HDFS 或者编写 MapReduce 程序。lib :该目录包含了 Hadoop 对外提供的编程动态库和静态库,与 include 目录中的头文件结 合使用。libexec :各个服务对用的 shell 配置文件所在的目录,可用于配置日志输 出、启动参数(比 如 JVM 参数)等基本信息。sbin : Hadoop 管理脚本所在的目录 ,主要包含 HDFS 和 YARN 中各类服务的 启动/关闭脚 本 。share : Hadoop 各个模块编译后的 jar 包所在的目录,官方自带示例 。
7、解压Hadoop3.3.0
将Hadoop上传到/exprot/server路径下,在此路径解压。
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
删除安装包。
给Hadoop-3.3.0目录赋予权限
chmod -R 777 hadoop-3.3.0/

8、Hadoop 配置文件修改
(1)、hadoop-env.sh
所在目录:/export/server/hadoop-3.3.0/etc/hadoop
export JAVA_HOME=/export/server/jdk1.8.0_241
#文件最后添加
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root编辑hadoop-env.sh文件,修改并添加上述参数。
vim hadoop-env.sh

:wq #保存退出(2)、core-site.xml
所在目录:/export/server/hadoop-3.3.0/etc/hadoop
vim core-site.xml<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置 HDFS web UI 用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合 hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>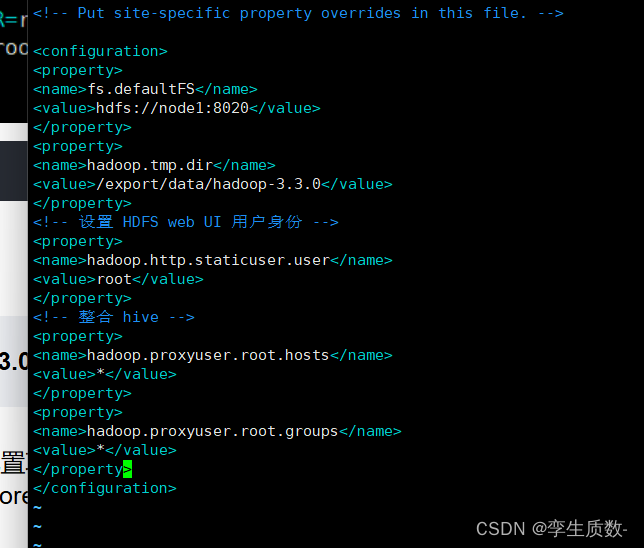
:wq #保存退出(3)、hdfs-site.xml
所在目录:/export/server/hadoop-3.3.0/etc/hadoop
vim hdfs-site.xml<!-- 指定 secondarynamenode 运行位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>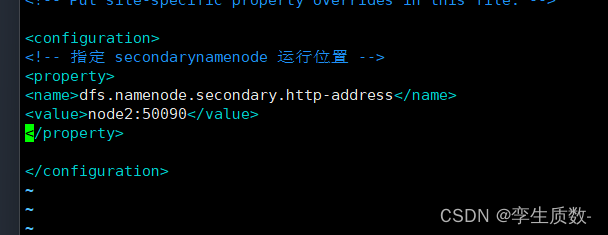
:wq #保存退出(4)、mapred-site.xml
所在目录:/export/server/hadoop-3.3.0/etc/hadoop
vim mapred-site.xml<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>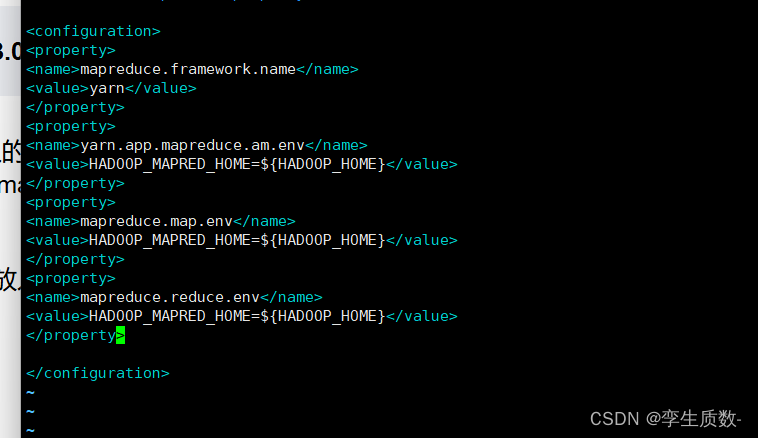
(5)、yarn-site.xml
所在目录:/export/server/hadoop-3.3.0/etc/hadoop
vim yarn-site.xml<!-- 指定 YARN 的主角色(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!-- NodeManager 上运行的附属服务。需配置成 mapreduce_shuffle,才可运行 MapReduce
程序默认值:"" -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置 yarn 历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>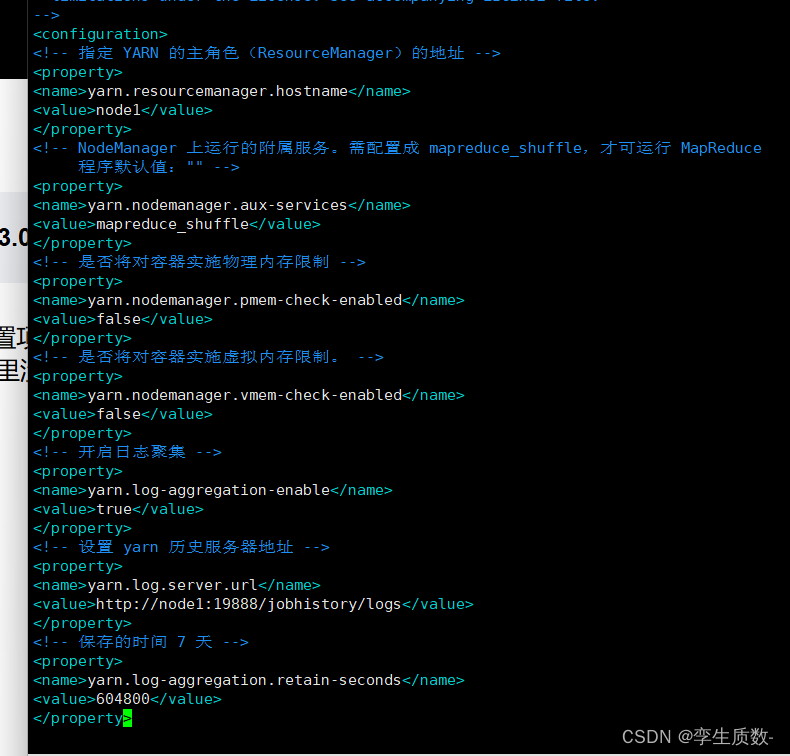
:wq #保存退出(6)、workers
所在目录:/export/server/hadoop-3.3.0/etc/hadoop
vim workers node1
node2
node3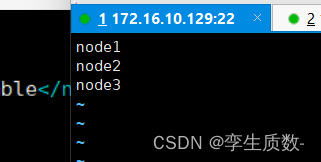
:wq #保存退出9. scp 同步安装包
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
10. Hadoop 环境变量
vim /etc/profile.d/my_env.shexport HADOOP_HOME=/export/server/hadoop-3.3.0export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

source /etc/profile
Hadoop 集群启动
初始-格式化
hadoop namenode -formatnode1:

单节点逐个启动
主节点(node1)、从节点(node2、node3)
在主节点上使用以下命令启动 HDFS NameNode:(node1)$HADOOP_HOME/bin/ hdfs --daemon start namenode在每个从节点上使用以下命令启动 HDFS DataNode:(node 1 、2、3)$HADOOP_HOME/bin/hdfs --daemon start datanode在 node2 上使用以下命令启动 HDFS SecondaryNameNode:$HADOOP_HOME/bin/hdfs --daemon start secondarynamenode在主节点上使用以下命令启动 YARN ResourceManager:(node1)$HADOOP_HOME/bin/ yarn --daemon start resourcemanager在每个从节点上使用以下命令启动 YARN nodemanager:(node 1 、2、3)$HADOOP_HOME/bin/yarn --daemon start nodemanager
脚本一键启动-(建议选择单节点逐个启动,两种方式任选一种即可)
hdfs:$HADOOP_PREFIX/sbin/start-dfs.shyarn: $HADOOP_PREFIX/sbin/start-yarn.sh停止集群:stop-dfs.sh、stop-yarn.sh
集群 web-ui
NameNode
http://172.16.10.129:port/ 默认 9870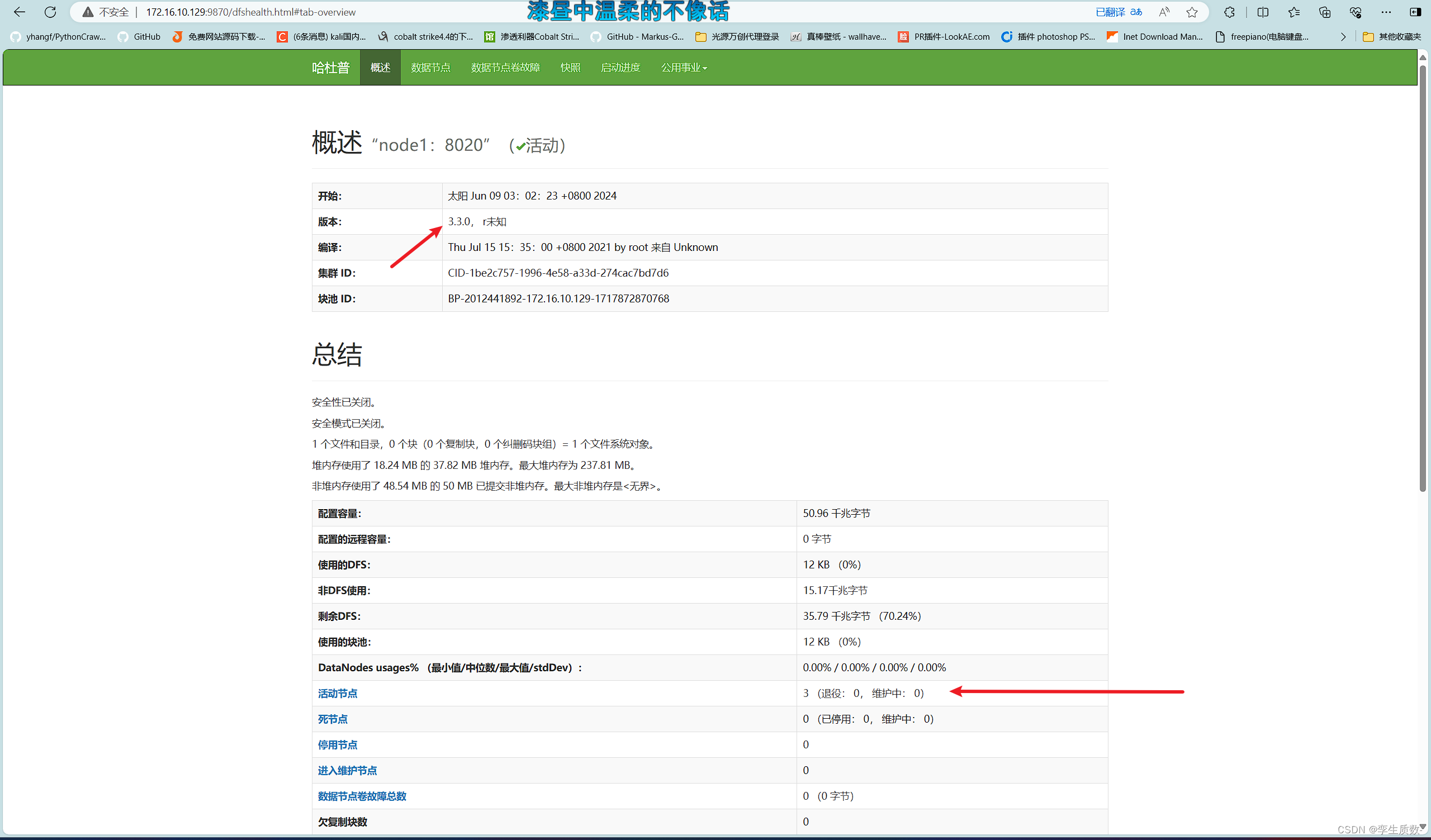 可以看到有三个节点在线。
可以看到有三个节点在线。ResourceManager
http://172.16.10.129:port/ 默认 8088 这边也可以看到三个活动节点。
这边也可以看到三个活动节点。
Hadoop 体验
HDFS 使用
从 Linux 本地上传一个文本文件到 hdfs 的/test/input 目录下
hadoop fs -mkdir -p /test/input #创建一个目录
hadoop fs -put /root/somewords.txt /test/input #上传文件到这个目录你可能会碰到的报错:
遇到这个错误提示“put:
/test/input': No such file or directory:hdfs://node1:8020/test/input'”时,意味着你在尝试使用Hadoop的hadoop fs -put命令上传文件到HDFS时,指定的目标目录不存在。Hadoop要求上传文件的目标路径必须是已存在的。这个问题可以通过以下几个步骤解决:
创建缺失的目录: 在上传文件之前,首先确保目标目录已经存在。你可以使用
Bashhadoop fs -mkdir命令来创建所需的目录。例如,如果想要上传到/test/input目录,先创建这个目录:1hadoop fs -mkdir -p /test/input
-p选项表示如果父目录不存在,也会一并创建。再次尝试上传: 一旦目标目录创建成功,就可以重新尝试使用
Bashput命令上传文件了。例如,如果你要上传本地的localfile.txt到HDFS的/test/input目录下,命令如下1hadoop fs -put localfile.txt /test/input/注意路径末尾的斜杠是可选的,但加上它可以明确表示这是一个目录。
检查权限: 如果问题仍然存在,可能是因为权限问题。确保你有权限在HDFS上创建目录和上传文件。这通常涉及到HDFS的权限设置,可以通过Hadoop的ACL(Access Control List)或者HDFS的配置来管理。
检查Hadoop集群状态: 确保Hadoop集群运行正常,尤其是NameNode(在你的例子中是
node1:8020)是活动且可访问的。可以通过检查集群的日志文件或使用Hadoop的管理工具(如Ambari、Cloudera Manager等)来验证。
上传成功。

运行 mapreduce 程序
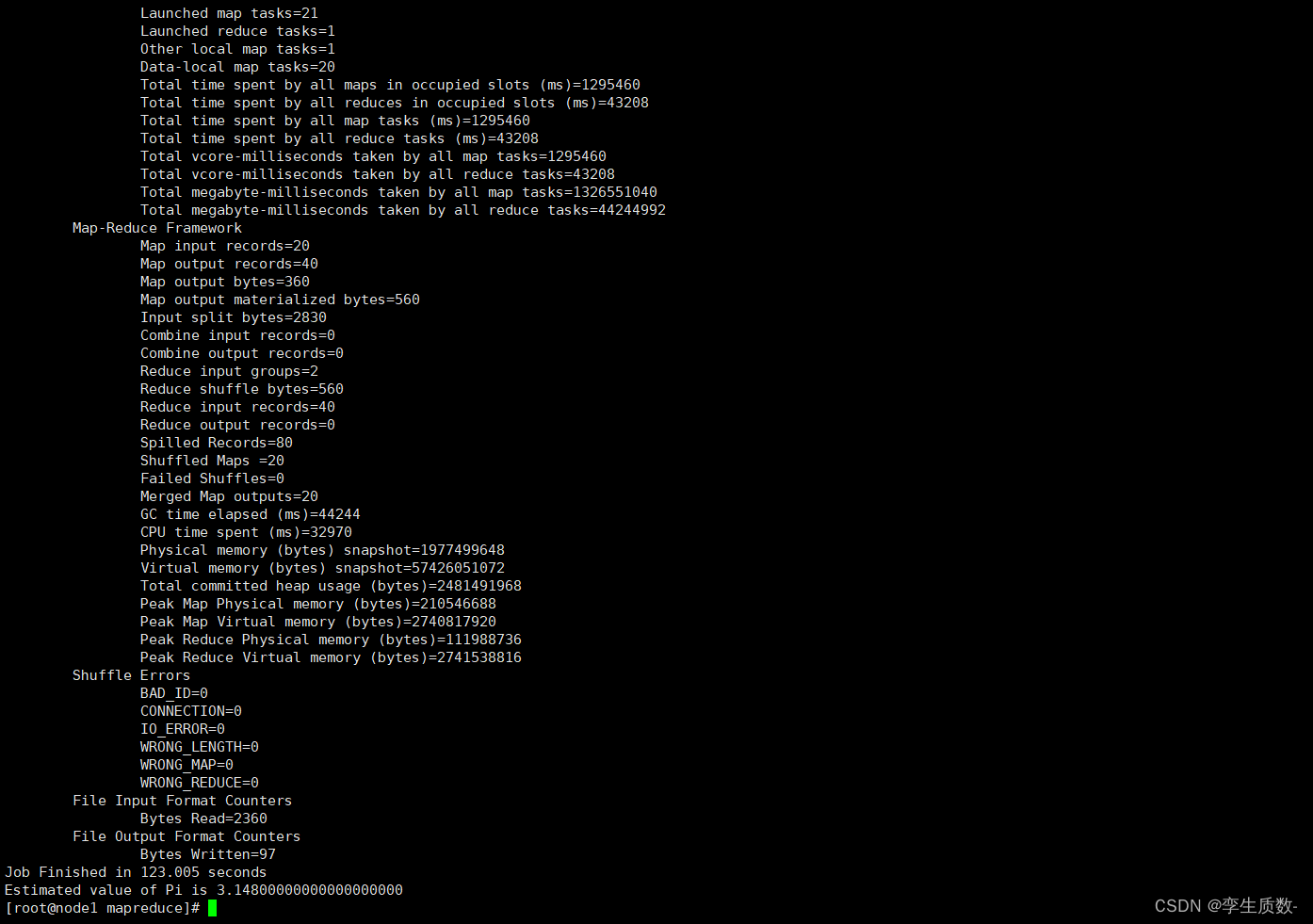
示例程序 jar:hadoop-mapreduce-examples-3.3.0.jar计算圆周率:hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 20 50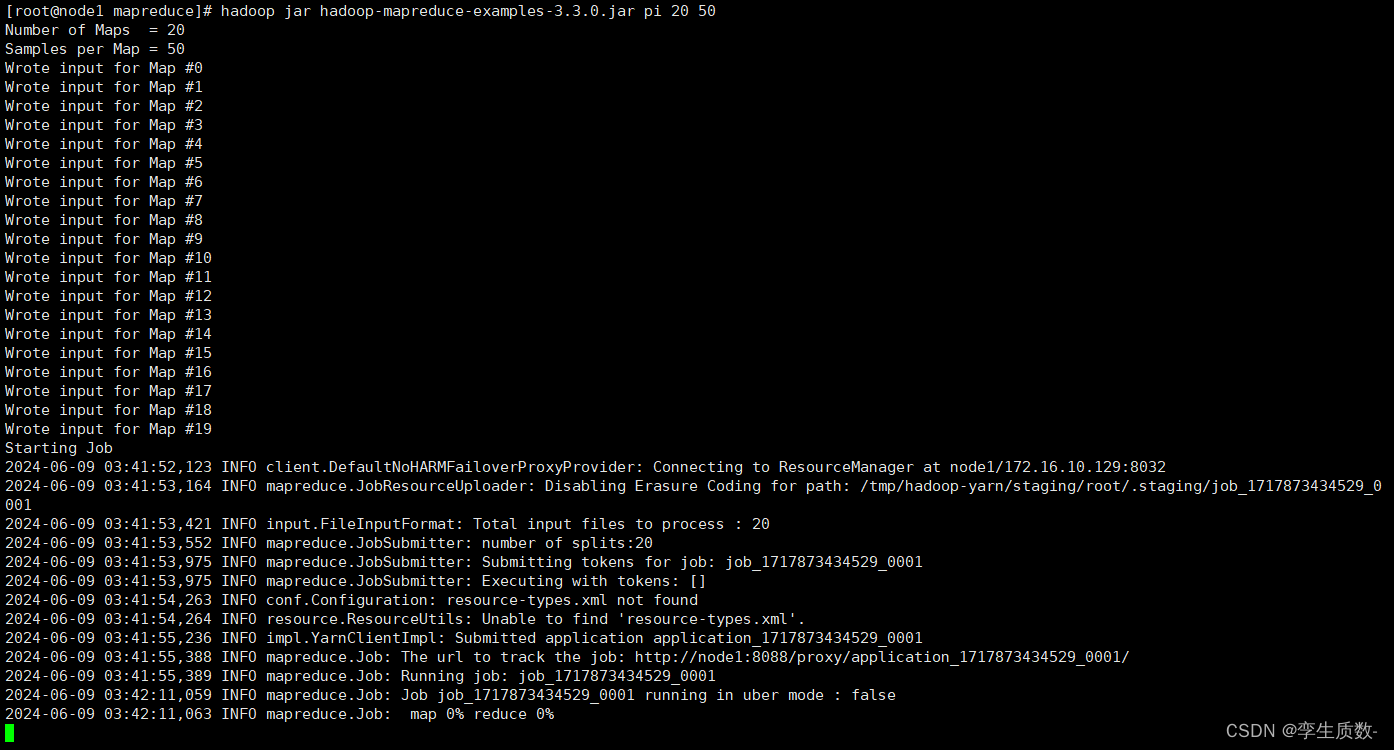

计算 wordcount:hello hello tom hello allen helloallen tom mac applehello apple spark allen tomhadoop-mapreduce-examples-3.3.0.jar wordcount /wordcount/input /wordcount/output
MapReduce jobHistory
1. 修改 mapred-site.xml
cd /export/servers/hadoop-3.3.0/etc/hadoop
vim mapred-site.xml<property><name>mapreduce.jobhistory.address</name><value>node1:10020</value></property>
<property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value></property>
2. 分发配置到其他机器
cd /export/servers/hadoop-3.3.0/etc/hadoop
scp -r mapred-site.xml node2:$PWD
scp –r mapred-site.xml node3:$PWD3. 启动 jobHistoryServer 服务进程
mapred --daemon start historyservermapred --daemon stop historyserver4. 页面访问 jobhistoryserver
http://node1:19888/jobhistory
HDFS 的垃圾桶机制
1. 垃圾桶机制解析
2. 垃圾桶机制配置
<property><name>fs.trash.interval</name><value>1440</value></property>
3. 垃圾桶机制验证
文末
部署是真麻烦,各种文档查半天,但是应用场景和功能都挺好的
相关文章:
2024海南省大数据教师培训-Hadoop集群部署
前言 本文将详细介绍Hadoop分布式计算框架的来源,架构和应用场景,并附上最详细的集群搭建教程,能更好的帮助各位老师和同学们迅速了解和部署Hadoop框架来进行生产力和学习方面的应用。 一、Hadoop介绍 Hadoop是一个开源的分布式计算框架&…...

力扣算法题:将数字变为0的操作次数--多语言实现
无意间看到,力扣存算法代码居然还得升级vip。。。好吧,我自己存吧 golang: func numberOfSteps(num int) int {steps : 0for num > 0 {if num%2 0 {num / 2} else {num - 1}steps}return steps } javascript: /*** param {number} num…...

vue前段处理时间格式,设置开始时间为00:00:00,设置结束时间为23:59:59
在Vue开发中,要在前端控制日期时间选择器的时间范围,可以通过以下方式实现: 使用beforeDestroy生命周期钩子函数来处理时间范围: 在Vue组件中,可以监听日期时间选择器的变化,在选择开始日期时,自…...

Java 8 新特性全面解读
Java 8,作为一次重大更新,于2014年引入了多项创新特性,极大地改善了Java的编程体验和性能。此版本不仅加入了对函数式编程的支持,还增强了接口的功能,引入了新的API,并优化了语言的整体效率。接下来&#x…...

JavaScript知识之函数
javascript函数 在JavaScript基础之上提供了部分函数,同时也可以自定义函数,JavaScript基础详见之前的文章javascript基础知识 自定义函数 //关键字 函数名 参数列表 函数体 function test(a,b,c){alert(a":"b":"c) }function test1(a,b){return a;//不…...

【Pepper机器人开发与应用】一、Pepper SDK for LabVIEW下载与安装教程
🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主 📑上期文章:『一文汇总对比英伟达、AMD、英特尔显卡GPU』 🍻本文由virobotics(仪酷智能)原创 🥳欢迎大家关注✌点赞&…...

HCIP-AI EI 认证课程大纲
该阶段详细介绍计算机视觉、注意力机制与Transformer、自然语言处理、语音处理等 AI 核心领域技术,并重点介绍华为云 EI 服务使用。 共计48 课时。第一节:计算机视觉技术概述与图像处理基础 - (3 课时) - 什么是计算机视觉&#x…...
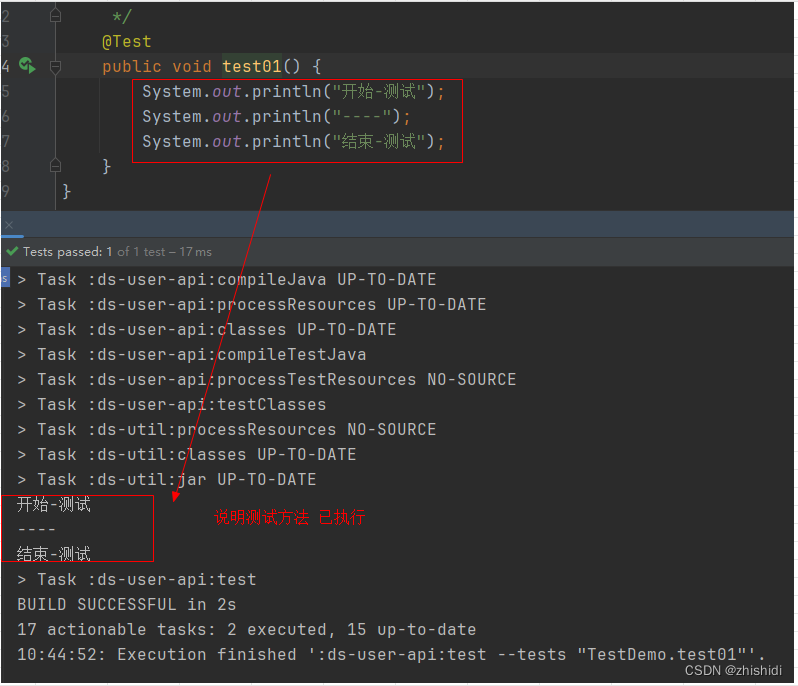
@Test注解方法,方法无法执行
1.背景 写了一个测试方法,执行后如图 2.原因是 该项目是springbootgradle...构建的项目 在build.gradle配置文件中关闭了单元测试: test {useJUnitPlatform()// 是否启用单元测试enabled false } 3.处理方式 开启单元测试 test {useJUnitPlatform()// 是否启用单元测试ena…...
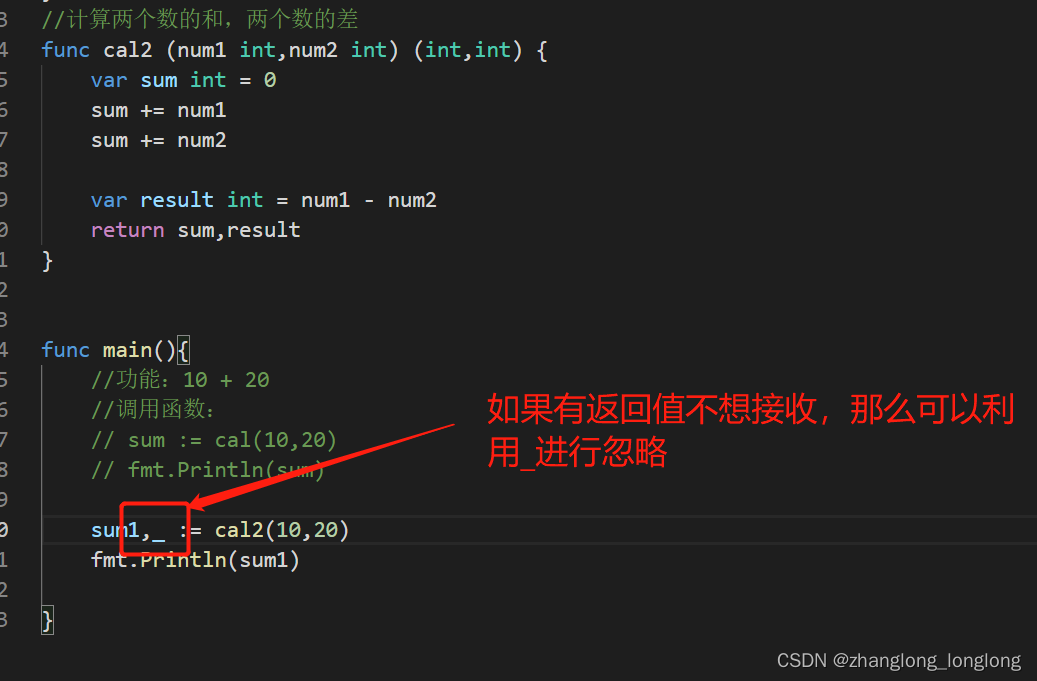
golang函数
【1】函数: 对特定的功能进行提取,形成一个代码片段,这个代码片段就是我们所说的函数 【2】函数的作用:提高代码的复用性 【3】函数和函数是并列的关系,所以我们定义的函数不能写到main函数中 【4】基本语法 func 函…...

ubuntu上存在多个版本python,根据需要选择你想使用的python版本
文章目录 前言一、二、使用步骤总结 前言 参考1 一、 sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.6 1二、使用步骤 总结...

idea 常用插件推荐
文章目录 1、Lombok2、Convert YAML and Properties File3、Grep Console4、MyBatisX5、Free MyBatis Tool6、MyBatis Log EasyPlus (SQL拼接)7、MyBatisPlus8、Eclipse theme9、Eclipse Plus Theme10、Rainbow Brackets Lite - Free and OpenSource&…...
训练大模型自动在RAG和记忆间选择
现如今,检索增强生成(Retrieval-augmented generation,RAG)管道已经能够使得大语言模型(Large Language Models,LLM)在其响应环节中,充分利用外部的信息源了。不过,由于RAG应用会针对发送给LLM的每个请求,都…...

抖店没人做了?不是项目不行了,而是商家们都换思路去玩了
我是王路飞。 有没有发现现在很多抖店新手都在吐槽,抖店不好做了,做不起来,没人做了,太内卷了...... 对这种做不起来还在怪项目本身的,一定要离他远一点,省得被他的负能量给影响到自己的状态。 任何项目…...

Qt5.15.2+VS2019新加类出现无法解析的外部符号
Qt5.15.2VS2019新加类出现无法解析的外部符号: 原因:没有生成对应的moc文件,导致没生成对应的元对象。 解决方案:记事本打开工程vcxproj,把报错的文件ClInclude,改为QtMoc,解决问题 未修改前&…...
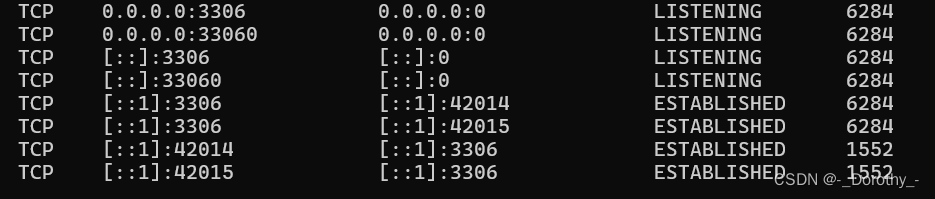
启动mysql 3.5时出现 MySql 服务正在启动 . MySql 服务无法启动。
有可能是端口冲突 netstat -ano | findstr :3306运行这段代码出现类似: 可以看到端口 3306 已经被进程 ID 为 6284 的进程占用。为了启动新的 MySQL 服务,我们需要停止这个进程或更改新服务的端口: 1、终止进程 taskkill /PID 6284 /F2、确…...
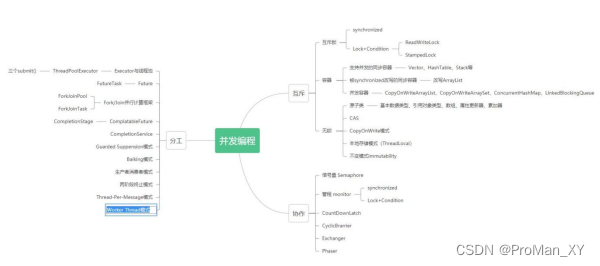
并发编程理论基础——可见性、原子性和有序性问题(一)
核心问题:分工,同步,互斥 分工:如何高效地拆解任务并分配给线程 生产者-消费者模式、Thread-Per-Message模式、Worker-Thread模式、ComplateableFuture和CompletionServiceJava SDK 并发包里的 Executor、Fork/Join、Future 本质上…...

心理咨询系统源码|心理咨询系统开发|心理咨询系统
心理咨询系统,作为一种集现代化科技与专业心理服务于一体的工具,正逐渐渗透到我们生活的各个角落。它不仅为个人提供了便捷的心理支持,还为企业和组织带来了全新的管理方式。下面,我们将深入探讨心理咨询系统的可应用范围及其带来…...
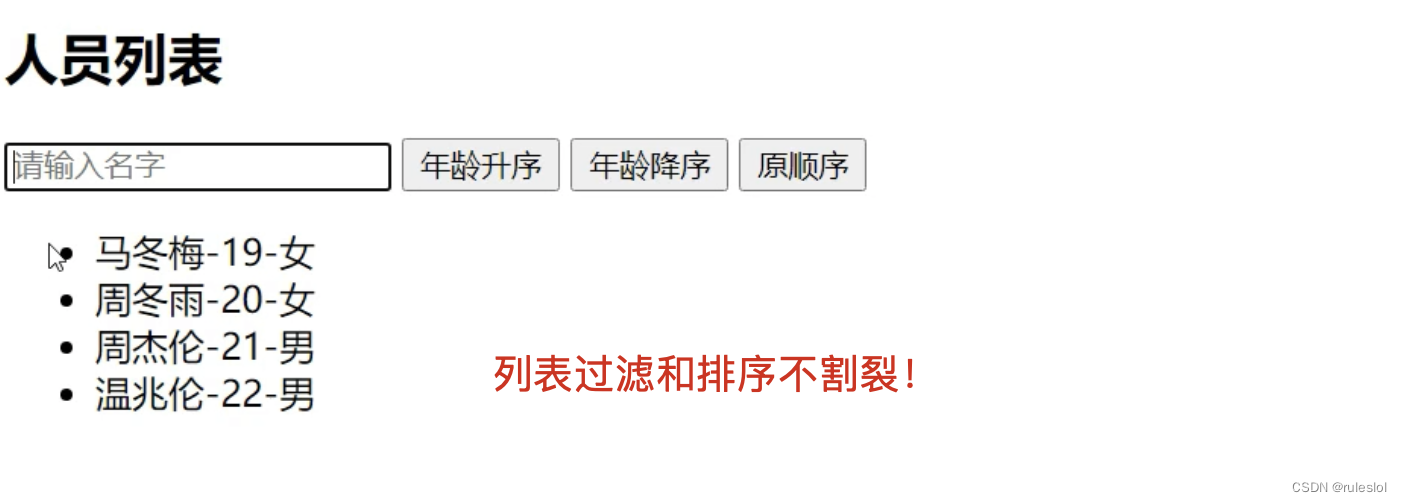
Vue21-列表排序
一、需求 二、解决方式 <body><div id"root"><h2>人员列表</h2><input type"text" placeholder"请输入" v-model"keyword"><button click"sortType 1">年龄升序</button><b…...

配置 JDK 和 Android SDK
目录 一、配置JDK 1. 安装 JDK 2. JDK 环境配置 3. JDK的配置验证 二、配置 adb 和Android SDK环境 1、下载 2、配置 Android SDK 环境 一、配置JDK 1. 安装 JDK 安装链接:Java Downloads | Oracle 我安装的是 .zip ,直接在指定的文件夹下解压就…...
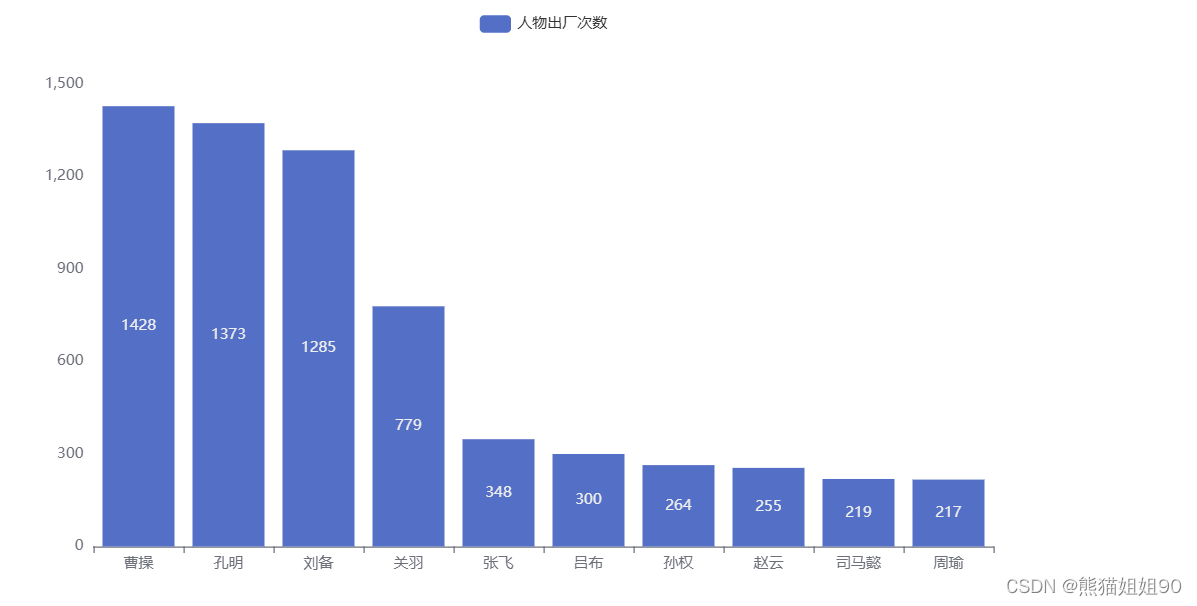
pyechart 创建柱形图
Pyecharts 是一个基于 Python 的开源数据可视化库,用于创建各种交互式的图表和可视化效果。它是在 Echarts 的基础上进行封装和优化,Echarts 是一个流行的 JavaScript 数据可视化库pyecharts 中文网站 : https://pyecharts.org/# pyecharts 模块 还支持…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...