【王树森】深度强化学习(DRL)学习笔记
目录
- 第一部分:基础知识
- 1.机器学习基础
- 2.蒙特卡洛估计
- 3.强化学习基础知识
- 3.1 马尔科夫决策过程
- 马尔可夫决策过程(Markov decision process,MDP)
- 智能体
- 环境
- 状态
- 状态空间
- 动作
- 动作空间
- 奖励
- 状态转移
- 状态转移概率
- 3.2 策略
- 策略定义
- 3.3 随机性的来源
- 随机性的两个来源
- 马尔科夫性质(无后效性)
- 轨迹
- 3.4 回报与折扣汇报
- 回报
- 折扣回报
- 回报中的随机性
- 3.5 价值函数
- 动作-价值函数
- 第二部分:价值学习
- 4.DQN与Q学习
- 4.1 DQN
- 4.2 时间差分(TD)算法
- 4.3 用TD算法训练DQN
- 4.4 Q学习算法
- 4.5 同策略(On-policy) 与异策略(Off-policy)
- 行为策略
- 目标策略
- 同策略
- 异策略
- 5.SARSA算法
- 5.1 表格形式的SARSA
- SARSA表格形式
- Q学习与SARSA的对比
- 5.2 神经网络形式的SARSA
- 价值网络
- 5.3 多步TD 目标
- 5.4 蒙特卡洛与自举
- 自举
- 6.价值学习高级技巧
- 6.1 经验回放
- 经验回放定义
- 经验回放的优点
- 经验回放局限性
- 优先经验回放
- 6.2 高估问题及解决方法
- 自举导致高估
- 最大化导致高估
- 高估的危害
- 使用目标网络
- 双Q学习算法
- 6.3 对决网络
- 6.4 噪声网络
- 噪声网络的原理
- 第三部分:策略学习
- 7.策略梯度方法
- 7.1 策略网络
- 策略学习
- 策略网络
- 7.2 策略学习的目标函数
- 7.3 策略梯度定理的证明
- 近似策略梯度
- 7.4 REINFORCE
- REINFORCE简化推导
- 训练流程
- 7.5 Actor-Critic
- 价值网络
- 算法推导
- 训练过程
- 用目标网络改进训练
- 8.带基线的策略梯度方法
- 9.策略学习高级技巧
- 10.连续控制
- 11.对状态的不完全观测
- 12.模仿学习
- 第四部分:多智能体强化学习
- 13.并行计算
第一部分:基础知识
1.机器学习基础
2.蒙特卡洛估计
3.强化学习基础知识
- 基本术语:状态(state)、状态空间(state space)、动作(action)、动作空间(action space)、智能体(agent)、环境(environment)、策略 (policy)、奖励(reward)、状态转移(state transition)。
- 马尔可夫决策过程 (MDP) 通常指的是四元组 ( S , A , p , r ) (\mathcal{S}, \mathcal{A}, p, r) (S,A,p,r), 其中 S \mathcal{S} S 是状态空间, A \mathcal{A} A 是动作空间, p p p 是状态转移函数, r r r 是奖励函数。有时 MDP 指的是五元组 ( S , A , p , r , γ ) (\mathcal{S}, \mathcal{A}, p, r, \gamma) (S,A,p,r,γ),其中 γ \gamma γ 是折扣率。
- 强化学习中的随机性来自于状态和动作。状态的随机性来源于状态转移, 动作的随机性来源于策略。奖励依赖于状态和动作, 因此奖励也具有随机性。
- 回报(或折扣回报)是未来所有奖励的加和(或加权和)。回报取决于奖励,奖励取决于状态和动作, 因此回报的随机性来自于未来的状态和动作。强化学习的目标是最大化回报,而不是最大化奖励。
- 动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 、最优动作价值函数 Q ⋆ ( s , a ) Q^{\star}(s, a) Q⋆(s,a) 、状态价值函数 V π ( s ) V_\pi(s) Vπ(s) 。
- 强化学习分为基于模型的方法、无模型方法两大类。其中无模型方法又分为价值学习、策略学习两类。本书第二部分、第三部分会详细讲解价值学习和策略学习; 第 18 章用 AlphaGo 的例子讲解基于模型的方法。
3.1 马尔科夫决策过程
马尔可夫决策过程(Markov decision process,MDP)
一个MDP 通常由状态空间、动作空间、状态转移函数、奖励函数、折扣因子等组成
智能体
强化学习中谁做动作谁就是智能体
环境
与智能体交互的对象
状态
在每个时刻,环境有一个状态(state),可以理解为对当前时刻环境的概括
状态空间
指所有可能存在状态的集合,记作花体字母 S \mathcal{S} S。状态空间可以是离散的,也可以是连续的。状态空间可以是有限集合,也可以是无限可数集合。在超级玛丽、星际争霸、无人驾驶这些例子中,状态空间是无限集合,存在无穷多种可能的状态。围棋、五子棋、中国象棋这些游戏中,状态空间是离散有限集合,可以枚举出所有可能存在的状态(也就是棋盘上的格局)。
动作
智能体基于当前状态所做出的决策
动作空间
指所有可能动作的集合,记作花体字母 A \mathcal{A} A。动作空间可以是离散集合或连续集合,可以是有限集合或无限集合。
奖励
是指在智能体执行一个动作之后,环境返回给智能体的一个数值。奖励往往由我们自己来定义,奖励定义得好坏非常影响强化学习的结果
通常假设奖励是当前状态 s s s 、当前动作 a a a 、下一时刻状态 s ′ s^{\prime} s′ 的函数, 把奖励函数记作 r ( s , a , s ′ ) r\left(s, a, s^{\prime}\right) r(s,a,s′) 。有时假设奖励仅仅是 s s s 和 a a a 的函数, 记作 r ( s , a ) r(s, a) r(s,a) 。我们总是假设奖励函数是有界的, 即对于所有 a ∈ A a \in \mathcal{A} a∈A 和 s , s ′ ∈ S s, s^{\prime} \in \mathcal{S} s,s′∈S, 有 ∣ r ( s , a , s ′ ) ∣ < ∞ \left|r\left(s, a, s^{\prime}\right)\right|<\infty ∣r(s,a,s′)∣<∞ 。
此处隐含的假设是奖励函数是平稳的(stationary),即它不随着时刻t变化(不太理解)
状态转移
是指智能体从当前t时刻的状态 s s s转移到下一个时刻状态为 s ′ s^{\prime} s′的过程。
状态转移概率
- 状态转移可能是随机的,强化学习通常假设状态转移随机,随机性来源于环境。用状态转移概率函数描述状态转移: p ( s ′ ∣ s , a ) = P ( S ′ = s ′ ∣ S = s , A = a ) , p\left(s^{\prime} \mid s, a\right)=\mathbb{P}\left(S^{\prime}=s^{\prime} \mid S=s, A=a\right), p(s′∣s,a)=P(S′=s′∣S=s,A=a),
表示在当前状态 s s s, 智能体执行动作 a a a, 环境的状态变成 s ′ s^{\prime} s′的概率
大写字母表示随机变量,小写字母表示观测值 - 状态转移也可能是确定的,下一个状态 s ′ s^{\prime} s′完全由s和a决定
3.2 策略
策略定义
根据观测到的状态,如何做出决策,即如何从动作空间中选取一个动作。强化学习的目标就是得到一个策略函数,在每个时刻根据观测到的状态做出决策。
- 随机策略,记随机策略函数 π : ( s , a ) ↦ [ 0 , 1 ] \pi:(s, a) \mapsto[0,1] π:(s,a)↦[0,1]是一个概率密度函数 :
π ( a ∣ s ) = P ( A = a ∣ S = s ) . \pi(a \mid s)=\mathbb{P}(A=a \mid S=s) . π(a∣s)=P(A=a∣S=s).
策略函数的输入是状态s和动作a,输出是一个0到1之间的概率值。含义是给定状态s,做出动作a的概率 - 确定策略:输入状态s,直接输出相应的动作a
3.3 随机性的来源
随机性的两个来源
- 状态是随机的,依赖于状态转移函数
- 动作是随机的,依赖于策略函数
马尔科夫性质(无后效性)
假设状态转移具有马有马尔可夫性质, 即:
P ( S t + 1 ∣ S t , A t ) = P ( S t + 1 ∣ S 1 , A 1 , S 2 , A 2 , ⋯ , S t , A t ) . \mathbb{P}\left(S_{t+1} \mid S_t, A_t\right)=\mathbb{P}\left(S_{t+1} \mid S_1, A_1, S_2, A_2, \cdots, S_t, A_t\right) . P(St+1∣St,At)=P(St+1∣S1,A1,S2,A2,⋯,St,At).
公式的意思是下一时刻状态 S t + 1 S_{t+1} St+1 仅依赖于当前状态 S t S_t St 和动作 A t A_t At, 而不依赖于过去的状态和动作。
即在推导后面阶段的状态的时候,我们只关心前一个阶段的状态值,不关心这个状态是怎么一步一步推导出来的。
轨迹
指一回合(episode)游戏中,智能体观测到的所有的状态、动作、奖励。

3.4 回报与折扣汇报
回报
回报(return) 是从当前时刻开始到本回合结束的所有奖励的总和,所以回报也叫做累计奖励(cumulative future reward)
U t = R t + R t + 1 + R t + 2 + R t + 3 + ⋯ + R n U_t=R_t+R_{t+1}+R_{t+2}+R_{t+3}+\cdots+R_n Ut=Rt+Rt+1+Rt+2+Rt+3+⋯+Rn
强化学习的目标就是寻找一个策略,使得回报的期望最大化
折扣回报
在MDP中,通常使用折扣回报,给未来的奖励做折扣:
U t = R t + γ ⋅ R t + 1 + γ 2 ⋅ R t + 2 + γ 3 ⋅ R t + 3 + ⋯ U_t=R_t+\gamma \cdot R_{t+1}+\gamma^2 \cdot R_{t+2}+\gamma^3 \cdot R_{t+3}+\cdots Ut=Rt+γ⋅Rt+1+γ2⋅Rt+2+γ3⋅Rt+3+⋯其中, γ ∈ [ 0 , 1 ] \gamma∈[0,1] γ∈[0,1]叫做折扣率
回报中的随机性
t时刻的 U t U_t Ut依赖于t时刻往后所有的奖励,奖励又依赖于状态与动作,因此t时刻 U t U_t Ut是未知的。
3.5 价值函数
动作-价值函数
-
定义
在t时刻,我们不知道 U t U_t Ut的值,而我们又想预判 U t U_t Ut的值从而知道局势的好坏。该怎么办呢?解决方案就是对 U t U_t Ut求期望,消除掉其中的随机性。
假设我们已经观测到状态 s t s_t st,而且做完决策,选中动作 a t a_t at。那么 U t U_t Ut中的随机性来自于 t + 1 t + 1 t+1时刻起的所有的状态和动作:
S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ , S n , A n S_{t+1}, A_{t+1}, \quad S_{t+2}, A_{t+2}, \cdots, \quad S_n, A_n St+1,At+1,St+2,At+2,⋯,Sn,An对 U t U_t Ut 关于变量 S t + 1 , A t + 1 , ⋯ , S n , A n S_{t+1}, A_{t+1}, \cdots, S_n, A_n St+1,At+1,⋯,Sn,An 求条件期望, 得到的就是动作-价值函数:
Q π ( s t , a t ) = E S t + 1 , A t + 1 , ⋯ , S n , A n [ U t ∣ S t = s t , A t = a t ] Q_\pi\left(s_t, a_t\right)=\mathbb{E}_{S_{t+1}, A_{t+1}, \cdots, S_n, A_n}\left[U_t \mid S_t=s_t, A_t=a_t\right] Qπ(st,at)=ESt+1,At+1,⋯,Sn,An[Ut∣St=st,At=at]
动作价值函数 Q π ( s t , a t ) Q_\pi\left(s_t, a_t\right) Qπ(st,at) 仅依赖于 s t s_t st 与 a t a_t at, 而不依赖于 t + 1 t+1 t+1 时刻及其之后的状态和动作,因为随机变量 S t + 1 , A t + 1 , ⋯ , S n , A n S_{t+1}, A_{t+1}, \cdots, S_n, A_n St+1,At+1,⋯,Sn,An 都被期望消除了。由于动作 A t + 1 , ⋯ , A n A_{t+1}, \cdots, A_n At+1,⋯,An 的概率质量函数都是 π \pi π, 公式中的期望依赖于 π \pi π; 用不同的 π \pi π, 求期望得出的结果就会不同。因此 Q π ( s t , a t ) Q_\pi\left(s_t, a_t\right) Qπ(st,at) 依赖于 π \pi π, 这就是为什么动作价值函数有下标 π 。 \pi_。 π。
因此,动作价值函数依赖于三个因素,当前状态 s t s_t st,当前动作 a t a_t at,策略函数 π \pi π -
直观含义:Q(s,a) 表示的是智能体在状态 s 下选择动作a 后,并一直按照策略 π 行动所能获得的总奖励(回报)的期望
-
具体过程:
1.起始:在状态s下选择动作 a。
2.转移:选择动作 a后,环境根据转移概率转移到新状态s’,并给予即时奖励 r1。
3.策略 π 执行:从状态 s’开始,智能体按照策略 π选择下一个动作 a’ .
4.重复:从状态s’开始,重复上述步骤(2和3),直到达到终止状态或无限循环。
第二部分:价值学习
4.DQN与Q学习
- D Q N \mathrm{DQN} DQN 是对最优动作价值函数 Q ⋆ Q^{\star} Q⋆ 的近似。 D Q N \mathrm{DQN} DQN 的输入是当前状态 s t s_t st, 输出是每个动作的 Q \mathrm{Q} Q 值。 D Q N \mathrm{DQN} DQN 要求动作空间 A \mathcal{A} A 是离散集合, 集合中的元素数量有限。如果动作空间 A \mathcal{A} A 的大小是 k k k, 那么 D Q N \mathrm{DQN} DQN 的输出就是 k k k 维向量。 D Q N \mathrm{DQN} DQN 可以用于做决策, 智能体执行 Q \mathrm{Q} Q 值最大的动作。
- TD 算法的目的在于让预测更接近实际观测。以驾车问题为例, 如果使用 T D \mathrm{TD} TD 算法,无需完成整个旅途就能做梯度下降更新模型。
理解TD 目标、TD 误差- Q \mathrm{Q} Q 学习算法是 T D \mathrm{TD} TD 算法的一种, 可以用于训练 D Q N \mathrm{DQN} DQN 。 Q \mathrm{Q} Q 学习算法由最优贝尔曼方程推导出。 Q \mathrm{Q} Q 学习算法属于异策略, 允许使用经验回放。由任意行为策略收集经验,存入经验回放数组。事后做经验回放, 用 TD 算法更新 DQN 参数。
- 如果状态空间 S \mathcal{S} S 、动作空间 A \mathcal{A} A 都是较小的有限离散集合, 那么可以用表格形式的 Q \mathrm{Q} Q 学习算法学习 Q ⋆ Q^{\star} Q⋆ 。如今表格形式的 Q \mathrm{Q} Q 学习已经不常用。
- 理解同策略、异策略、目标策略、行为策略这几个专业术语, 理解同策略与异策略的区别。异策略的好处在于允许做经验回放, 反复利用过去收集的经验。但这不意味着异策略一定优于同策略。
4.1 DQN
4.2 时间差分(TD)算法
4.3 用TD算法训练DQN
4.4 Q学习算法
上一节用TD算法训练DQN,TD算法是一大类算法,常见的有Q学习和SARSA。 Q Q Q 学习的目的是学到最优动作价值函数 Q ⋆ Q^{\star} Q⋆, 而 SARSA 的目的是学习动作价值函数 Q π Q_\pi Qπ。
Q学习的表格形式是用一个表格 Q ~ \widetilde{Q} Q 来近似 Q ⋆ Q^{\star} Q⋆首先初始化 Q ~ \widetilde{Q} Q , 可以让它是全零的表格。然后用表格形式的 Q \mathrm{Q} Q 学习算法更新 Q ~ \widetilde{Q} Q , 每次更新表格的一个元素。最终 Q ~ \widetilde{Q} Q 会收敛到 Q ⋆ Q^{\star} Q⋆ 。Q学习的表格法与策略无关
4.5 同策略(On-policy) 与异策略(Off-policy)
行为策略
-
定义
在强化学习中,我们让智能体与环境交互,记录下观测到的状态、动作、奖励,用这些经验来学习一个策略函数。在这一过程中,控制智能体与环境交互的策略被称作行为策略 -
作用
收集经验(experience),即观测的状态、动作、奖励
目标策略
- 定义
强化学习的目的是得到一个策略函数,用这个策略函数来控制智能体。这个策略函数就叫做目标策略。
同策略
- 定义:用相同的行为策略和目标策略
异策略
- 定义:用不同的行为策略和目标策略
DQN 是异策略, 行为策略可以不同于目标策略, 可以用任意的行为策略收集经验, 比如最常用的行为策略是 ϵ \epsilon ϵ-greedy:
a t = { argmax a Q ( s t , a ; w ) , 以概率 ( 1 − ϵ ) ; 均匀抽取 A 中的一个动作, 以概率 ϵ . a_t= \begin{cases}\operatorname{argmax}_a Q\left(s_t, a ; \boldsymbol{w}\right), & \text { 以概率 }(1-\epsilon) ; \\ \text { 均匀抽取 } \mathcal{A} \text { 中的一个动作, } & \text { 以概率 } \epsilon .\end{cases} at={argmaxaQ(st,a;w), 均匀抽取 A 中的一个动作, 以概率 (1−ϵ); 以概率 ϵ.
让行为策略带有随机性的好处在于能探索更多没见过的状态。在实验中, 初始的时候让 ϵ \epsilon ϵ 比较大 (比如 ϵ = 0.5 \epsilon=0.5 ϵ=0.5 ) ; 在训练的过程中, 让 ϵ \epsilon ϵ 逐渐衰减, 在几十万步之后衰减到较小的值(比如 ϵ = 0.01 ) \epsilon=0.01 ) ϵ=0.01), 此后固定住 ϵ = 0.01 \epsilon=0.01 ϵ=0.01 。
异策略的好处是可以用行为策略收集经验, 把 ( s t , a t , r t , s t + 1 ) \left(s_t, a_t, r_t, s_{t+1}\right) (st,at,rt,st+1) 这样的四元组记录到一个数组里, 在事后反复利用这些经验去更新目标策略。这个数组被称作经验回放数组 (replay buffer), 这种训练方式被称作经验回放(experience replay)。注意,经验回放只适用于异策略, 不适用于同策略, 其原因是收集经验时用的行为策略不同于想要训练出的目标策略。

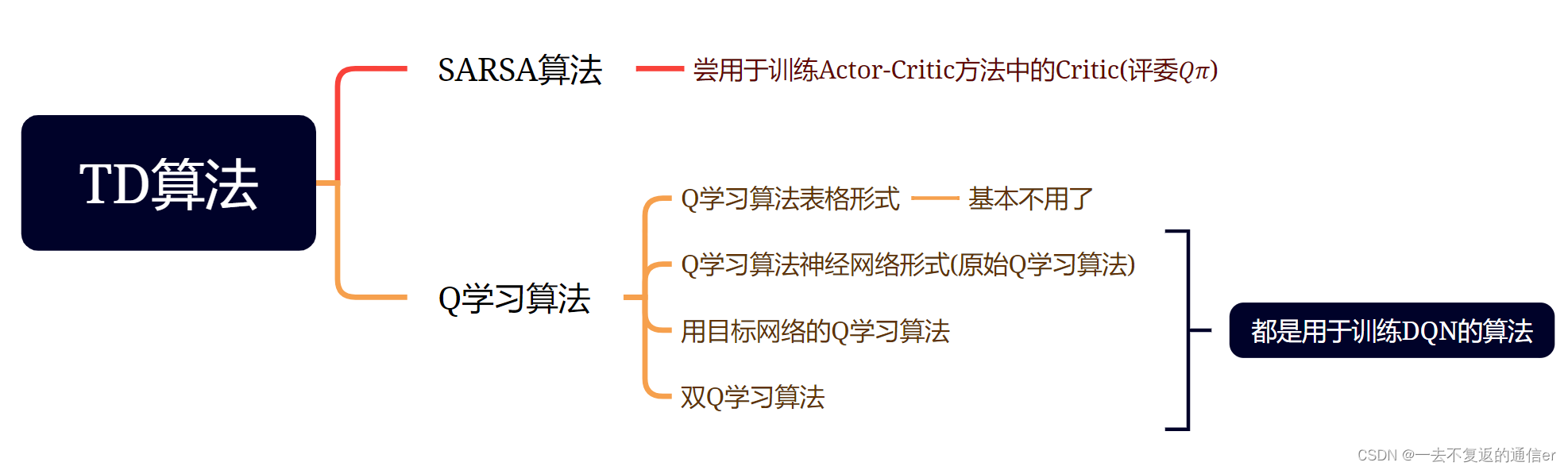
5.SARSA算法
- SARSA 和 Q \mathrm{Q} Q 学习都属于 T D \mathrm{TD} TD 算法, 但是两者有所区别。SARSA 算法的目的是学习动作价值函数 Q π Q_\pi Qπ, 而 Q \mathrm{Q} Q 学习算法目的是学习最优动作价值函数 Q ⋆ Q^{\star} Q⋆ 。SARSA 算法是同策略, 而 Q \mathrm{Q} Q 学习算法是异策略。SARSA 不能用经验回放, 而 Q \mathrm{Q} Q 学习可以用经验回放。
- 价值网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 是对动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 的近似。可以用 SARSA 算法学习价值网络。
- 多步 TD 目标是对单步 TD 目标的推广。多步 TD 目标可以平衡蒙特卡洛和自举,取得比单步 TD 目标更好的效果。
5.1 表格形式的SARSA
SARSA表格形式
Actor-Critic方法中,策略函数 π \pi π控制智能体,被当做Actor(运动员);动作价值函数 Q π Q_{\pi} Qπ评价策略的好坏,被当做Critic(评委);SARSA算法尝用于训练评委 Q π Q_{\pi} Qπ
用一个表格表示动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a),该表格与策略函数 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 相关联; 如果 π \pi π 发生变化,表格 Q π Q_\pi Qπ 也会发生变化。因此SARSA算法与策略有关【但注意:Q学习的表格与策略无关】
Q学习与SARSA的对比
- Q \mathrm{Q} Q 学习的目标是学到表格 Q ~ \tilde{Q} Q~, 作为最优动作价值函数 Q ⋆ Q^{\star} Q⋆ 的近似。因为 Q ⋆ Q^{\star} Q⋆ 与 π \pi π 无关, 所以在理想情况下, 不论收集经验用的行为策略 π \pi π 是什么, 都不影响 Q \mathrm{Q} Q 学习得到的最优动作价值函数。因此, Q \mathrm{Q} Q 学习属于异策略(off-policy), 允许行为策略区别于目标策略。Q 学习允许使用经验回放, 可以重复利用过时的经验。
- SARSA 算法的目标是学到表格 q q q, 作为动作价值函数 Q π Q_\pi Qπ 的近似。 Q π Q_\pi Qπ 与一个策略 π \pi π相对应, 用不同的策略 π \pi π, 对应 Q π Q_\pi Qπ 就会不同。策略 π \pi π 越好, Q π Q_\pi Qπ 的值越大。经验回放数组里的经验 ( s j , a j , r j , s j + 1 ) \left(s_j, a_j, r_j, s_{j+1}\right) (sj,aj,rj,sj+1) 是过时的行为策略 π old \pi_{\text {old }} πold 收集到的, 与当前策略 π now \pi_{\text {now }} πnow 及其对而不能用过时的 π old \pi_{\text {old }} πold 收集到的经验。这就是为什么 SARSA 不能用经验回放的原因。

5.2 神经网络形式的SARSA
价值网络
价值网络:如果状态空间 S \mathcal{S} S 是无限集, 那么我们无法用一张表格表示 Q π Q_\pi Qπ, 否则表格的行数是无穷。一种可行的方案是用一个神经网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 来近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a); 理想情况下,
q ( s , a ; w ) = Q π ( s , a ) , ∀ s ∈ S , a ∈ A . q(s, a ; \boldsymbol{w})=Q_\pi(s, a), \quad \forall s \in \mathcal{S}, a \in \mathcal{A} . q(s,a;w)=Qπ(s,a),∀s∈S,a∈A.
这个神经网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 被称为价值网络(value network), 其中的 w \boldsymbol{w} w 表示神经网络中可训练的参数。神经网络的结构是人预先设定的(比如有多少层, 每一层的宽度是多少), 而参数 w \boldsymbol{w} w 需要通过智能体与环境的交互来学习。
5.3 多步TD 目标
5.4 蒙特卡洛与自举
自举
自举意思是“用一个估算去更新同类的估算”,类似于“自己把自己给举起来”
6.价值学习高级技巧
- 经验回放可以用于异策略算法。经验回放有两个好处:打破相邻两条经验的相关性、重复利用收集的经验。
- 优先经验回放是对经验回放的一种改进。在做经验回放的时候,从经验回放数组中做加权随机抽样, T D \mathrm{TD} TD 误差的绝对值大的经验被赋予较大的抽样概率、较小的学习率。
- Q \mathrm{Q} Q 学习算法会造成 D Q N \mathrm{DQN} DQN 高估真实的价值。高估的原因有两个:第一,最大化造成 T D \mathrm{TD} TD 目标高估真实价值; 第二, 自举导致高估传播。高估并不是由 DQN 本身的缺陷造成的, 而是由于 Q \mathrm{Q} Q 学习算法不够好。双 Q \mathrm{Q} Q 学习是对 Q \mathrm{Q} Q 学习算法的改进, 可以有效缓解高估。
- 对决网络与 D Q N \mathrm{DQN} DQN 一样, 都是对最优动作价值函数 Q ⋆ Q_{\star} Q⋆ 的近似; 两者的唯一区别在于神经网络结构。对决网络由两部分组成: D ( s , a ; w D ) D\left(s, a ; \boldsymbol{w}^D\right) D(s,a;wD) 是对最优优势函数的近似, V ( s ; w V ) V\left(s ; \boldsymbol{w}^V\right) V(s;wV) 是对最优状态价值函数的近似。对决网络的训练与 D Q N \mathrm{DQN} DQN 完全相同。
- 噪声网络是一种特殊的神经网络结构, 神经网络中的参数带有随机噪声。噪声网络可以用于 DQN 等多种深度强化学习模型。噪声网络中的噪声可以鼓励探索, 让智能体尝试不同的动作, 这有利于学到更好的策略。
6.1 经验回放
经验回放定义
经验回放(experience replay)是强化学习中一个重要的技巧,可以大幅提升强化学习的表现。经验回放的意思是把智能体与环境交互的记录(即经验)储存到一个数组里,事后反复利用这些经验训练智能体。这个数组被称为经验回放数组(replay buffer)
具体来说, 把智能体的轨迹划分成 ( s t , a t , r t , s t + 1 ) \left(s_t, a_t, r_t, s_{t+1}\right) (st,at,rt,st+1) 这样的四元组, 存入一个数组。要人为指定数组的大小 (记作 b b b )。数组中只保留最近 b b b 条数据; 当数组存满之后, 删掉最旧的数据。数组的大小 b b b 是个需要调的超参数, 会影响训练的结果。通常设置 b b b 为 1 0 5 ∼ 1 0 6 10^5 \sim 10^6 105∼106 。
经验回放的优点
-
经验回放的一个好处在于打破序列的相关性。 训练 DQN 的时候, 每次我们用一个四元组对 DQN 的参数做一次更新。我们希望相邻两次使用的四元组是独立的。然而当智能体收集经验的时候, 相邻两个四元组 ( s t , a t , r t , s t + 1 ) \left(s_t, a_t, r_t, s_{t+1}\right) (st,at,rt,st+1) 和 ( s t + 1 , a t + 1 , r t + 1 , s t + 2 ) \left(s_{t+1}, a_{t+1}, r_{t+1}, s_{t+2}\right) (st+1,at+1,rt+1,st+2) 有很强的相关性。依次使用这些强关联的四元组训练 DQN,效果往往会很差。经验回放每次从数组里随机抽取一个四元组, 用来对 DQN 参数做一次更新。这样随机抽到的四元组都是独六的, 消除了相关性。
-
经验回放的另一个好处是重复利用收集到的经验,而不是用一次就丢弃,这样可以用更少的样本数量达到同样的表现。
注意:暂时还不太理解的点
在阅读文献的时候请注意“样本数量”(sample complexity)与“更新次数”两者的区别。样本数量是指智能体从环境中获取的奖励r的数量。而一次更新的意思是从经验回放数组里取出一个或多个四元组,用它对参数w 做一次更新。通常来说,样本数量更重要,因为在实际应用中收集经验比较困难。比如,在机器人的应用中,需要在现实世界做一次实验才能收集到一条经验,花费的时间和金钱远大于做一次计算。相对而言,做更新的次数不是那么重要,更新次数只会影响训练时的计算量而已。

经验回放局限性
经验回放只适用于异策略;不适用于同策略,比如SRASA,REINFORCE,A2C
优先经验回放
优先经验回放(prioritized experience replay)是一种特殊的经验回放方法, 它比普通的经验回放效果更好:既能让收敛更快,也能让收敛时的平均回报更高。经验回放数组里有 b b b 个四元组, 普通经验回放每次均匀抽样得到一个样本——即四元组 ( s j , a j , r j , s j + 1 ) \left(s_j, a_j, r_j, s_{j+1}\right) (sj,aj,rj,sj+1),用它来更新 DQN 的参数。优先经验回放给每个四元组一个权重, 然后根据权重做非均匀随机抽样。如果 DQN 对 ( s j , a j ) \left(s_j, a_j\right) (sj,aj) 的价值判断不准确, 即 Q ( s j , a j ; w ) Q\left(s_j, a_j ; \boldsymbol{w}\right) Q(sj,aj;w) 离 Q ∗ ( s j , a j ) Q^*\left(s_j, a_j\right) Q∗(sj,aj) 较远,则四元组 ( s j , a j , r j , s j + 1 ) \left(s_j, a_j, r_j, s_{j+1}\right) (sj,aj,rj,sj+1) 应当有较高的权重。
6.2 高估问题及解决方法
Q \mathrm{Q} Q 学习算法有一个缺陷:用 Q \mathrm{Q} Q 学习训练出的 D Q N \mathrm{DQN} DQN 会高估真实的价值, 而且高估通常是非均匀的。这个缺陷导致 DQN 的表现很差。高估问题并不是 DQN 模型的缺陷, 而是 Q \mathrm{Q} Q 学习算法的缺陷。 Q \mathrm{Q} Q 学习产生高估的原因有两个:第一, 自举导致偏差的传播; 第二, 最大化导致 TD 目标高估真实价值。为了缓解高估, 需要从导致高估的两个原因下手, 改进 Q \mathrm{Q} Q 学习算法。双 Q \mathrm{Q} Q 学习算法是一种有效的改进, 可以大幅缓解高估及其危害。
自举导致高估
最大化导致高估
高估的危害
如果高估是均匀的,则高估没有危害;如果高估非均匀,就会有危害
想要避免DQN 的高估,要么切断自举,要么避免最大化造成高估注意,高估并不是DQN 自身的属性,高估纯粹是算法造成的。想要避免高估,就要用更好的算法替代原始的Q学习算法。
使用目标网络
使用目标网络训练DQN可以缓解DQN高估
双Q学习算法
造成 D Q N \mathrm{DQN} DQN 高估的原因不是 D Q N \mathrm{DQN} DQN 模型本身的缺陷, 而是 Q \mathrm{Q} Q 学习算法有不足之处: 第一, 自举造成偏差的传播; 第二, 最大化造成 T D \mathrm{TD} TD 目标的高估。在 Q \mathrm{Q} Q 学习算法中使用目标网络, 可以缓解自举造成的偏差, 但是无助于缓解最大化造成的高估。本小节介绍双 Q \mathbf{Q} Q 学习(double Q \mathrm{Q} Q learning)算法, 它在目标网络的基础上做改进, 缓解最大化造成的高估。
注:本小节介绍的双 Q \mathrm{Q} Q 学习算法在文献中被称作 double D Q N \mathrm{DQN} DQN, 缩写 DDQN。本书不采用 D D Q N \mathrm{DDQN} DDQN 这名字, 因为这个名字比较误导。双 Q \mathrm{Q} Q 学习(即所谓的 DDQN)只是一种 T D \mathbf{T D} TD 算法而已, 它可以把 DQN 训练得更好。双 Q \mathrm{Q} Q 学习并没有用区别于 D Q N \mathrm{DQN} DQN 的模型。本节中的模型只有一个, 就是 D Q N \mathrm{DQN} DQN 。我们讨论的只是训练 D Q N \mathrm{DQN} DQN 的三种 T D \mathrm{TD} TD 算法:原始的 Q \mathrm{Q} Q 学习、用目标网络的 Q \mathrm{Q} Q 学习、双 Q \mathrm{Q} Q 学习。
下面是三种算法的对比:

注1:如果使用原始 Q \mathrm{Q} Q 学习算法, 自举和最大化都会造成严重高估。在实践中, 应当尽量使用双 Q \mathrm{Q} Q 学习, 它是三种算法中最好的。
注2:如果使用 SARSA 算法(比如在 actor-critic 中), 自举的问题依然存在, 但是不存在最大化造成高估这一问题。对于 SARSA, 只需要解决自举问题, 所以应当将目标网络应用到 SARSA。
6.3 对决网络
对决网络 (dueling network)是对 DQN 的神经网络结构的改进。它的基本想法是将最优动作价值 Q ⋆ Q^{\star} Q⋆ 分解成最优状态价值 V ⋆ V_{\star} V⋆ 加最优优势 D ⋆ D_{\star} D⋆ 。对决网络的训练与 D Q N \mathrm{DQN} DQN 完全相同, 可以用 Q \mathrm{Q} Q 学习算法或者双 Q \mathrm{Q} Q 学习算法。
6.4 噪声网络
噪声网络(noisy net)是一种非常简单的方法, 可以显著提高 DQN 的表现。噪声网络的应用不局限于 DQN, 它可以用于几乎所有的深度强化学习方法。
噪声网络的原理
把神经网络中的参数 w \boldsymbol{w} w 替换成 μ + σ ∘ ξ \mu+\sigma \circ \xi μ+σ∘ξ 。此处的 μ , σ , ξ \mu, \sigma, \xi μ,σ,ξ 的形状与 w \boldsymbol{w} w完全相同。 μ 、 σ \mu 、 \sigma μ、σ 分别表示均值和标准差, 它们是神经网络的参数, 需要从经验中学习。 ξ \boldsymbol{\xi} ξ 是随机噪声, 它的每个元素独立从标准正态分布 N ( 0 , 1 ) \mathcal{N}(0,1) N(0,1) 中随机抽取。符号“o”表示逐项乘积。如果 w \boldsymbol{w} w 是向量, 那么有
w i = μ i + σ i ⋅ ξ i . w_i=\mu_i+\sigma_i \cdot \xi_i . wi=μi+σi⋅ξi.
如果 w w w 是矩阵, 那么有
w i j = μ i j + σ i j ⋅ ξ i j . w_{i j}=\mu_{i j}+\sigma_{i j} \cdot \xi_{i j} . wij=μij+σij⋅ξij.
噪声网络的意思是参数 w \boldsymbol{w} w 的每个元素 w i w_i wi 从均值为 μ i \mu_i μi 、标准差为 σ i \sigma_i σi 的正态分布中抽取。

第三部分:策略学习
7.策略梯度方法
- 可以用神经网络 π ( a ∣ s ; θ ) \pi(a \mid s ; \boldsymbol{\theta}) π(a∣s;θ) 近似策略函数。策略学习的目标函数是 J ( θ ) = E S [ V π ( S ) ] J(\boldsymbol{\theta})=\mathbb{E}_S\left[V_\pi(S)\right] J(θ)=ES[Vπ(S)],它的值越大, 意味着策略越好。
- 策略梯度指的是 J ( θ ) J(\boldsymbol{\theta}) J(θ) 关于策略了参数 θ \boldsymbol{\theta} θ 的梯度。策略梯度定理将策略梯度表示成
g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) \boldsymbol{g}(s, a ; \boldsymbol{\theta}) \triangleq Q_\pi(s, a) \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(a \mid s ; \boldsymbol{\theta}) g(s,a;θ)≜Qπ(s,a)⋅∇θlnπ(a∣s;θ)的期望。- REINFORCE 算法用实际观测的回报 u u u 近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a), 从而把 g ( s , a ; θ ) \boldsymbol{g}(s, a ; \boldsymbol{\theta}) g(s,a;θ) 近似成:
g ~ ( s , a ; θ ) ≜ u ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \tilde{\boldsymbol{g}}(s, a ; \boldsymbol{\theta}) \triangleq u \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(a \mid s ; \boldsymbol{\theta}) . g~(s,a;θ)≜u⋅∇θlnπ(a∣s;θ).REINFORCE 算法做梯度上升更新策略网络: θ ← θ + β ⋅ g ~ ( s , a ; θ ) \boldsymbol{\theta} \leftarrow \boldsymbol{\theta}+\beta \cdot \tilde{\boldsymbol{g}}(s, a ; \boldsymbol{\theta}) θ←θ+β⋅g~(s,a;θ) 。- Actor-critic 用价值网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a), 从而把 g ( s , a ; θ ) \boldsymbol{g}(s, a ; \boldsymbol{\theta}) g(s,a;θ) 近似成:
g ^ ( s , a ; θ ) ≜ q ( s , a ; w ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \widehat{\boldsymbol{g}}(s, a ; \boldsymbol{\theta}) \triangleq q(s, a ; \boldsymbol{w}) \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(a \mid s ; \boldsymbol{\theta}) . g (s,a;θ)≜q(s,a;w)⋅∇θlnπ(a∣s;θ).
Actor-critic 用 SARSA 算法更新价值网络 q q q, 用梯度上升更新策略网络: θ ← θ + β \boldsymbol{\theta} \leftarrow \boldsymbol{\theta}+\beta θ←θ+β. g ^ ( s , a ; θ ) \widehat{\boldsymbol{g}}(s, a ; \boldsymbol{\theta}) g (s,a;θ)
策略网络→策略学习描述成最大化问题→策略梯度→用REINFORCE和Actor-critic训练策略网络→本章介绍的REINFORCE 和actor-critic 只是帮助大家理解算法而已,实际效果并不好
7.1 策略网络
策略学习
策略学习的意思是通过求解一个优化问题,学出最优策略函数或它的近似函数(比如策略网络)
策略网络
用神经网络 π ( a ∣ s ; θ ) \pi(a \mid s ; \boldsymbol{\theta}) π(a∣s;θ) 近似策略函数 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 。神经网络 π ( a ∣ s ; θ ) \pi(a \mid s ; \boldsymbol{\theta}) π(a∣s;θ) 被称为策略网络。 θ \boldsymbol{\theta} θ 表示神经网络的参数; 一开始随机初始化 θ \theta θ, 随后利用收集的状态、动作、奖励去更新 θ \boldsymbol{\theta} θ 。

7.2 策略学习的目标函数
-
回报 U t U_t Ut 是从 t t t 时刻开始的所有奖励之和。 U t U_t Ut 依赖于 t t t 时刻开始的所有状态和动作:
S t , A t , S t + 1 , A t + 1 , S t + 2 , A t + 2 , ⋯ S_t, A_t, S_{t+1}, A_{t+1}, \quad S_{t+2}, A_{t+2}, \cdots St,At,St+1,At+1,St+2,At+2,⋯
在 t t t 时刻, U t U_t Ut 是随机变量, 它的不确定性来自于未来未知的状态和动作。 -
动作价值函数的定义是:
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] . Q_\pi\left(s_t, a_t\right)=\mathbb{E}\left[U_t \mid S_t=s_t, A_t=a_t\right] . Qπ(st,at)=E[Ut∣St=st,At=at].条件期望把 t t t 时刻状态 s t s_t st 和动作 a t a_t at 看做已知观测值, 把 t + 1 t+1 t+1 时刻后的状态和动作看做未知变量, 并消除这些变量。 -
状态价值函数的定义:
V π ( s t ) = E A t ∼ π ( ⋅ ∣ s t ; θ ) [ Q π ( s t , A t ) ] . V_\pi\left(s_t\right)=\mathbb{E}_{A_t \sim \pi\left(\cdot \mid s_t ; \theta\right)}\left[Q_\pi\left(s_t, A_t\right)\right] . Vπ(st)=EAt∼π(⋅∣st;θ)[Qπ(st,At)].状态价值既依赖于当前状态 s t s_t st, 也依赖于策略网络 π \pi π 的参数 θ \boldsymbol{\theta} θ 。- 当前状态 s t s_t st 越好, 则 V π ( s t ) V_\pi\left(s_t\right) Vπ(st) 越大, 即回报 U t U_t Ut 的期望越大。例如, 在超级玛丽游戏中, 如果玛丽奥已经接近终点(也就是说当前状态 s t s_t st 很好), 那么回报的期望就会很大。
- 策略 π \pi π 越好(即参数 θ \boldsymbol{\theta} θ 越好), 那么 V π ( s t ) V_\pi\left(s_t\right) Vπ(st) 也会越大。例如, 从同一起点出发打游戏, 高手(好的策略)的期望回报远高于初学者(差的策略)。
如果一个策略很好, 那么状态价值 V π ( S ) V_\pi(S) Vπ(S) 的均值应当很大。因此我们定义目标函数:
J ( θ ) = E S [ V π ( S ) ] J(\boldsymbol{\theta})=\mathbb{E}_S\left[V_\pi(S)\right] J(θ)=ES[Vπ(S)]
这个目标函数排除掉了状态 S S S 的因素, 只依赖于策略网络 π \pi π 的参数 θ \boldsymbol{\theta} θ; 策略越好, 则 J ( θ ) J(\theta) J(θ) 越大。所以策略学习可以描述为这样一个优化问题:
max θ J ( θ ) \max _{\boldsymbol{\theta}} J(\boldsymbol{\theta}) θmaxJ(θ)
希望通过对策略网络参数 θ \boldsymbol{\theta} θ 的更新, 使得目标函数 J ( θ ) J(\boldsymbol{\theta}) J(θ) 越来越大, 也就意味着策略网络越来越强。想要求解最大化问题, 显然可以用梯度上升更新 θ \boldsymbol{\theta} θ, 使得 J ( θ ) J(\boldsymbol{\theta}) J(θ) 增大。设当前策略网络的参数为 θ now \theta_{\text {now }} θnow , 做梯度上升更新参数, 得到新的参数 θ new \theta_{\text {new }} θnew :
θ new ← θ now + β ⋅ ∇ θ J ( θ now ) . \boldsymbol{\theta}_{\text {new }} \leftarrow \boldsymbol{\theta}_{\text {now }}+\beta \cdot \nabla_{\boldsymbol{\theta}} J\left(\boldsymbol{\theta}_{\text {now }}\right) . θnew ←θnow +β⋅∇θJ(θnow ).
此处的 β \beta β 是学习率, 需要手动调整。上面的公式就是训练策略网络的基本思路, 其中的梯度
∇ θ J ( θ now ) ≜ ∂ J ( θ ) ∂ θ ∣ θ = θ now \left.\nabla_{\boldsymbol{\theta}} J\left(\boldsymbol{\theta}_{\text {now }}\right) \triangleq \frac{\partial J(\boldsymbol{\theta})}{\partial \boldsymbol{\theta}}\right|_{\boldsymbol{\theta}=\theta_{\text {now }}} ∇θJ(θnow )≜∂θ∂J(θ) θ=θnow
被称作策略梯度。策略梯度可以写成下面定理中的期望形式。之后的算法推导都要基于这个定理, 并对其中的期望做近似。

7.3 策略梯度定理的证明
证明过程见书
近似策略梯度
策略学习可以描述为一个最大化问题:
max θ { J ( θ ) ≜ E S [ V π ( S ) ] } . \max _\theta\left\{J(\theta) \triangleq \mathbb{E}_S\left[V_\pi(S)\right]\right\} . θmax{J(θ)≜ES[Vπ(S)]}.
求解这个最大化问题最简单的算法就是梯度上升:
θ ← θ + β ⋅ ∇ θ J ( θ ) . \boldsymbol{\theta} \leftarrow \boldsymbol{\theta}+\beta \cdot \nabla_{\boldsymbol{\theta}} J(\theta) . θ←θ+β⋅∇θJ(θ).
其中的 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ) 是策略梯度。
策略梯度表示为:
∇ θ J ( θ ) = E S [ E A ∼ π ( ⋅ ∣ S ; θ ) [ Q π ( S , A ) ⋅ ∇ θ ln π ( A ∣ S ; θ ) ] ] . \nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta})=\mathbb{E}_S\left[\mathbb{E}_{A \sim \pi(\cdot \mid S ; \boldsymbol{\theta})}\left[Q_\pi(S, A) \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(A \mid S ; \boldsymbol{\theta})\right]\right] . ∇θJ(θ)=ES[EA∼π(⋅∣S;θ)[Qπ(S,A)⋅∇θlnπ(A∣S;θ)]].
解析求出这个期望是不可能的, 因为我们并不知道状态 S S S 概率密度函数; 即使我们知道 S S S 的概率密度函数, 能够通过连加或者定积分求出期望, 我们也不愿意这样做, 因为连加或者定积分的计算量非常大。
回忆一下, 第 2 章介绍了期望的蒙特卡洛近似方法, 可以将这种方法用于近似策略梯度。每次从环境中观测到一个状态 s s s, 它相当于随机变量 S S S 的观测值。然后再根据当前的策略网络(策略网络的参数必须是最新的)随机抽样得出一个动作:
a ∼ π ( ⋅ ∣ s ; θ ) . a \sim \pi(\cdot \mid s ; \theta) . a∼π(⋅∣s;θ).
计算随机梯度:
g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \boldsymbol{g}(s, a ; \boldsymbol{\theta}) \triangleq Q_\pi(s, a) \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(a \mid s ; \boldsymbol{\theta}) . g(s,a;θ)≜Qπ(s,a)⋅∇θlnπ(a∣s;θ).
很显然, g ( s , a ; θ ) \boldsymbol{g}(s, a ; \boldsymbol{\theta}) g(s,a;θ) 是策略梯度 ∇ θ J ( θ ) \nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta}) ∇θJ(θ) 的无偏估计:
∇ θ J ( θ ) = E S [ E A ∼ π ( ⋅ ∣ S ; θ ) [ g ( S , A ; θ ) ] ] \nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta})=\mathbb{E}_S\left[\mathbb{E}_{A \sim \pi(\cdot \mid S ; \boldsymbol{\theta})}[\boldsymbol{g}(S, A ; \boldsymbol{\theta})]\right] ∇θJ(θ)=ES[EA∼π(⋅∣S;θ)[g(S,A;θ)]]
应用上述结论, 我们可以做随机梯度上升来更新 θ \boldsymbol{\theta} θ, 使得目标函数 J ( θ ) J(\theta) J(θ) 逐渐增长:
θ ← θ + β ⋅ g ( s , a ; θ ) . \boldsymbol{\theta} \leftarrow \boldsymbol{\theta}+\beta \cdot \boldsymbol{g}(s, a ; \boldsymbol{\theta}) . θ←θ+β⋅g(s,a;θ).
此处的 β \beta β 是学习率, 需要手动调整。但是这种方法仍然不可行, 我们计算不出 g ( s , a ; θ ) \boldsymbol{g}(s, a ; \boldsymbol{\theta}) g(s,a;θ),原因在于我们不知道动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 。在后面两节中, 我们用两种方法对 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a)做近似: 一种方法是 REINFORCE, 用实际观测的回报 u u u 近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a); 另一种方法是 actor-critic, 用神经网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 近似 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 。
7.4 REINFORCE
策略梯度 ∇ θ J ( θ ) \nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta}) ∇θJ(θ) 的无偏估计是下面的随机梯度:
g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \boldsymbol{g}(s, a ; \boldsymbol{\theta}) \triangleq Q_\pi(s, a) \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(a \mid s ; \boldsymbol{\theta}) . g(s,a;θ)≜Qπ(s,a)⋅∇θlnπ(a∣s;θ).
但是其中的动作价值函数 Q π Q_\pi Qπ 是未知的,导致无法直接计算 g ( s , a ; θ ) \boldsymbol{g}(s, a ; \boldsymbol{\theta}) g(s,a;θ) 。REINFORCE 进一步对 Q π Q_\pi Qπ 做蒙特卡洛近似, 把它替换成回报 u u u 。
REINFORCE简化推导
设一局游戏有 n n n 步, 一局中的奖励记作 R 1 , ⋯ , R n R_1, \cdots, R_n R1,⋯,Rn 。 t t t 时刻的折扣回报定义为:
U t = ∑ k = t n γ k − t ⋅ R k U_t=\sum_{k=t}^n \gamma^{k-t} \cdot R_k Ut=k=t∑nγk−t⋅Rk
而动作价值定义为 U t U_t Ut 的条件期望:
Q π ( s t , a t ) = E [ U t ∣ S t = s t , A t = a t ] . Q_\pi\left(s_t, a_t\right)=\mathbb{E}\left[U_t \mid S_t=s_t, A_t=a_t\right] . Qπ(st,at)=E[Ut∣St=st,At=at].
我们可以用蒙特卡洛近似上面的条件期望。从时刻 t t t 开始, 智能体完成一局游戏, 观测到全部奖励 r t , ⋯ , r n r_t, \cdots, r_n rt,⋯,rn, 然后可以计算出 u t = ∑ k = t n γ k − t ⋅ r k u_t=\sum_{k=t}^n \gamma^{k-t} \cdot r_k ut=∑k=tnγk−t⋅rk 。因为 u t u_t ut 是随机变量 U t U_t Ut 的观测值, 所以 u t u_t ut 是上面公式中期望的蒙特卡洛近似(不太理解)。在实践中, 可以用 u t u_t ut 代替 Q π ( s t , a t ) Q_\pi\left(s_t, a_t\right) Qπ(st,at),那么随机梯度 g ( s t , a t ; θ ) \boldsymbol{g}\left(s_t, a_t ; \boldsymbol{\theta}\right) g(st,at;θ) 可以近似成
g ~ ( s t , a t ; θ ) = u t ⋅ ∇ θ ln π ( a t ∣ s t ; θ ) . \tilde{\boldsymbol{g}}\left(s_t, a_t ; \boldsymbol{\theta}\right)=u_t \cdot \nabla_{\boldsymbol{\theta}} \ln \pi\left(a_t \mid s_t ; \boldsymbol{\theta}\right) . g~(st,at;θ)=ut⋅∇θlnπ(at∣st;θ).
g ~ \tilde{\boldsymbol{g}} g~ 是 g \boldsymbol{g} g 的无偏估计,所以也是策略梯度 ∇ θ J ( θ ) \nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta}) ∇θJ(θ) 的无偏估计; g ~ \tilde{\boldsymbol{g}} g~ 也是一种随机梯度。
我们可以用反向传播计算出 ln π \ln \pi lnπ 关于 θ \boldsymbol{\theta} θ 的梯度, 而且可以实际观测到 u t u_t ut, 于是我们可以实际计算出随机梯度 g ~ \tilde{\boldsymbol{g}} g~ 的值。有了随机梯度的值, 我们可以做随机梯度上升更新策略网络参数 θ \theta θ :
θ ← θ + β ⋅ g ~ ( s t , a t ; θ ) . \boldsymbol{\theta} \leftarrow \boldsymbol{\theta}+\beta \cdot \tilde{\boldsymbol{g}}\left(s_t, a_t ; \boldsymbol{\theta}\right) . θ←θ+β⋅g~(st,at;θ).
根据上述推导, 我们得到了训练策略网络的算法, 即 REINFORCE。
训练流程
当前策略网络的参数是 θ now。 \theta_{\text {now。 }} θnow。 REINFORCE 执行下面的步骤对策略网络的参数做一次更新:
-
用策略网络 θ now \theta_{\text {now }} θnow 控制智能体从头开始玩一局游戏 从开始玩到结束?, 得到一条轨迹 (trajectory):
s 1 , a 1 , r 1 , s 2 , a 2 , r 2 , ⋯ , s n , a n , r n . s_1, a_1, r_1, \quad s_2, a_2, r_2, \quad \cdots, \quad s_n, a_n, r_n . s1,a1,r1,s2,a2,r2,⋯,sn,an,rn. -
计算所有的回报:
u t = ∑ k = t n γ k − t ⋅ r k , ∀ t = 1 , ⋯ , n u_t=\sum_{k=t}^n \gamma^{k-t} \cdot r_k, \quad \forall t=1, \cdots, n ut=k=t∑nγk−t⋅rk,∀t=1,⋯,n -
用 { ( s t , a t ) } t = 1 n \left\{\left(s_t, a_t\right)\right\}_{t=1}^n {(st,at)}t=1n 作为数据, 做反向传播计算:
∇ θ ln π ( a t ∣ s t ; θ now ) , ∀ t = 1 , ⋯ , n . \nabla_{\boldsymbol{\theta}} \ln \pi\left(a_t \mid s_t ; \boldsymbol{\theta}_{\text {now }}\right), \quad \forall t=1, \cdots, n . ∇θlnπ(at∣st;θnow ),∀t=1,⋯,n. -
做随机梯度上升更新策略网络参数:
θ new ← θ now + β ⋅ ∑ t = 1 n γ t − 1 ⋅ u t ⋅ ∇ θ ln π ( a t ∣ s t ; θ now ) ⏟ 即随机梯度 g ~ ( s t , a t ; θ now ) . \boldsymbol{\theta}_{\text {new }} \leftarrow \boldsymbol{\theta}_{\text {now }}+\beta \cdot \sum_{t=1}^n \gamma^{t-1} \cdot \underbrace{u_t \cdot \nabla_{\boldsymbol{\theta}} \ln \pi\left(a_t \mid s_t ; \boldsymbol{\theta}_{\text {now }}\right)}_{\text {即随机梯度 } \tilde{\boldsymbol{g}}\left(s_t, a_t ; \theta_{\text {now }}\right)} . θnew ←θnow +β⋅t=1∑nγt−1⋅即随机梯度 g~(st,at;θnow ) ut⋅∇θlnπ(at∣st;θnow ).
注:在算法最后一步中, 随机梯度前面乘以系数 γ t − 1 \gamma^{t-1} γt−1 。读者可能会好奇, 为什么需要这个系数呢? 原因是这样的: 前面 REINFORCE 的推导是简化的, 而非严谨的数学推导; 按照我们简化的推导, 不应该乘以系数 γ t − 1 \gamma^{t-1} γt−1 。下一小节做严格的数学推导, 得出的 REINFORCE 算法需要系数 γ t − 1 \gamma^{t-1} γt−1 。读者只要知道这个事实就行了, 不必读懂下一小节的数学推导。
注:REINFORCE 属于同策略(on-policy), 要求行为策略(behavior policy)与目标策略 (target policy)相同, 两者都必须是策略网络 π ( a ∣ s ; θ now ) \pi\left(a \mid s ; \boldsymbol{\theta}_{\text {now }}\right) π(a∣s;θnow ), 其中 θ now \boldsymbol{\theta}_{\text {now }} θnow 是策略网络当前的参数。所以经验回放不适用于 REINFORCE。
7.5 Actor-Critic
本节的actor-critic用神经网络近似 Q π Q_{\pi} Qπ
价值网络
Actor-critic 方法用一个神经网络近似动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a), 这个神经网络叫做“价值网络”, 记为 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w), 其中的 w \boldsymbol{w} w 表示神经网络中可训练的参数。价值网络的输入是状态 s s s, 输出是每个动作的价值。
虽然价值网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 与之前学的 DQN 有相同的结构, 但是两者的意义不同, 训练算法也不同。
- 价值网络是对动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 的近似。而 DQN 则是对最优动作价值函数 Q ⋆ ( s , a ) Q_{\star}(s, a) Q⋆(s,a) 的近似。
- 对价值网络的训练使用的是 SARSA 算法, 它属于同策略, 不能用经验回放。对 DQN 的训练使用的是 Q \mathrm{Q} Q 学习算法, 它属于异策略, 可以用经验回放。
算法推导
- 训练策略网络
训练策略网络的基本想法是用策略梯度 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ) 的近似来更新参数 θ \boldsymbol{\theta} θ 。之前我们推导过策略梯度的无偏估计:
g ( s , a ; θ ) ≜ Q π ( s , a ) ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \boldsymbol{g}(s, a ; \boldsymbol{\theta}) \triangleq Q_\pi(s, a) \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(a \mid s ; \boldsymbol{\theta}) . g(s,a;θ)≜Qπ(s,a)⋅∇θlnπ(a∣s;θ).
价值网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 是对动作价值函数 Q π ( s , a ) Q_\pi(s, a) Qπ(s,a) 的近似,所以把上面公式中的 Q π Q_\pi Qπ 替换成价值网络,得到近似策略梯度:
g ^ ( s , a ; θ ) ≜ q ( s , a ; w ) ⏟ 评委的打分 ⋅ ∇ θ ln π ( a ∣ s ; θ ) . \widehat{\boldsymbol{g}}(s, a ; \boldsymbol{\theta}) \triangleq \underbrace{q(s, a ; \boldsymbol{w})}_{\text {评委的打分 }} \cdot \nabla_{\boldsymbol{\theta}} \ln \pi(a \mid s ; \boldsymbol{\theta}) . g (s,a;θ)≜评委的打分 q(s,a;w)⋅∇θlnπ(a∣s;θ).
最后做梯度上升更新策略网络的参数:
θ ← θ + β ⋅ g ^ ( s , a ; θ ) . \boldsymbol{\theta} \leftarrow \boldsymbol{\theta}+\beta \cdot \widehat{\boldsymbol{g}}(s, a ; \boldsymbol{\theta}) . θ←θ+β⋅g (s,a;θ). - 训练价值网络——SARSA
训练过程
下面概括 actor-critic 训练流程。设当前策略网络参数是 θ now \theta_{\text {now }} θnow , 价值网络参数是 w now。 w_{\text {now。 }} wnow。 执行下面的步骤, 将参数更新成 θ new \theta_{\text {new }} θnew 和 w new w_{\text {new }} wnew :
- 观测到当前状态 s t s_t st, 根据策略网络做决策: a t ∼ π ( ⋅ ∣ s t ; θ now ) a_t \sim \pi\left(\cdot \mid s_t ; \boldsymbol{\theta}_{\text {now }}\right) at∼π(⋅∣st;θnow ), 并让智能体执行动作 a t a_t at 。
- 从环境中观测到奖励 r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1 。
- 根据策略网络做决策: a ~ t + 1 ∼ π ( ⋅ ∣ s t + 1 ; θ now ) \tilde{a}_{t+1} \sim \pi\left(\cdot \mid s_{t+1} ; \boldsymbol{\theta}_{\text {now }}\right) a~t+1∼π(⋅∣st+1;θnow ), 但不让智能体执行动作 a ~ t + 1 \tilde{a}_{t+1} a~t+1 。
- 让价值网络打分:
q ^ t = q ( s t , a t ; w now ) 和 q ^ t + 1 = q ( s t + 1 , a ~ t + 1 ; w now ) \widehat{q}_t=q\left(s_t, a_t ; \boldsymbol{w}_{\text {now }}\right) \quad \text { 和 } \quad \widehat{q}_{t+1}=q\left(s_{t+1}, \tilde{a}_{t+1} ; \boldsymbol{w}_{\text {now }}\right) q t=q(st,at;wnow ) 和 q t+1=q(st+1,a~t+1;wnow ) - 计算 TD 目标和 TD 误差:
y ^ t = r t + γ ⋅ q ^ t + 1 和 δ t = q ^ t − y ^ t . \widehat{y}_t=r_t+\gamma \cdot \widehat{q}_{t+1} \quad \text { 和 } \quad \delta_t=\widehat{q}_t-\widehat{y}_t \text {. } y t=rt+γ⋅q t+1 和 δt=q t−y t. - 更新价值网络:
w new ← w now − α ⋅ δ t ⋅ ∇ w q ( s t , a t ; w now ) . \boldsymbol{w}_{\text {new }} \leftarrow \boldsymbol{w}_{\text {now }}-\alpha \cdot \delta_t \cdot \nabla_{\boldsymbol{w}} q\left(s_t, a_t ; \boldsymbol{w}_{\text {now }}\right) . wnew ←wnow −α⋅δt⋅∇wq(st,at;wnow ). - 更新策略网络:
θ new ← θ now + β ⋅ q ^ t ⋅ ∇ θ ln π ( a t ∣ s t ; θ now ) . \boldsymbol{\theta}_{\text {new }} \leftarrow \boldsymbol{\theta}_{\text {now }}+\beta \cdot \widehat{q}_t \cdot \nabla_{\boldsymbol{\theta}} \ln \pi\left(a_t \mid s_t ; \boldsymbol{\theta}_{\text {now }}\right) . θnew ←θnow +β⋅q t⋅∇θlnπ(at∣st;θnow ).
用目标网络改进训练
第 6.2 节讨论了 Q Q Q 学习中的自举及其危害, 以及用目标网络(target network)缓解自举造成的偏差。SARSA 算法中也存在自举一一即用价值网络自己的估值 q ^ t + 1 \widehat{q}_{t+1} q t+1 去更新价值网络自己; 我们同样可以用目标网络计算 TD 目标, 从而缓解偏差。把目标网络记作 q ( s , a ; w − ) q\left(s, a ; \boldsymbol{w}^{-}\right) q(s,a;w−), 它的结构与价值网络相同, 但是参数不同。使用目标网络计算 TD 目标, 那么 actor-critic 的训练就变成了:
- 观测到当前状态 s t s_t st, 根据策略网络做决策: a t ∼ π ( ⋅ ∣ s t ; θ now ) a_t \sim \pi\left(\cdot \mid s_t ; \boldsymbol{\theta}_{\text {now }}\right) at∼π(⋅∣st;θnow ), 并让智能体执行动作 a t a_t at 。
- 从环境中观测到奖励 r t r_t rt 和新的状态 s t + 1 s_{t+1} st+1 。
- 根据策略网络做决策: a ~ t + 1 ∼ π ( ⋅ ∣ s t + 1 ; θ now ) \tilde{a}_{t+1} \sim \pi\left(\cdot \mid s_{t+1} ; \boldsymbol{\theta}_{\text {now }}\right) a~t+1∼π(⋅∣st+1;θnow ), 但是不让智能体执行动作 a ~ t + 1 \tilde{a}_{t+1} a~t+1 。
- 让价值网络给 ( s t , a t ) \left(s_t, a_t\right) (st,at) 打分:
q ^ t = q ( s t , a t ; w now ) . \widehat{q}_t=q\left(s_t, a_t ; \boldsymbol{w}_{\text {now }}\right) . q t=q(st,at;wnow ). - 让目标网络给 ( s t + 1 , a ~ t + 1 ) \left(s_{t+1}, \tilde{a}_{t+1}\right) (st+1,a~t+1) 打分:
q ~ t + 1 = q ( s t + 1 , a ~ t + 1 ; w now − ) \widetilde{q}_{t+1}=q\left(s_{t+1}, \tilde{a}_{t+1} ; \boldsymbol{w}_{\text {now }}^{-}\right) q t+1=q(st+1,a~t+1;wnow −) - 计算 TD 目标和 TD 误差:
y ^ t − = r t + γ ⋅ q ^ t + 1 − 和 δ t = q t ^ − y ^ t − . \widehat{y}_t^{-}=r_t+\gamma \cdot \widehat{q}_{t+1}^{-} \quad \text { 和 } \quad \delta_t=\widehat{q_t}-\widehat{y}_t^{-} \text {. } y t−=rt+γ⋅q t+1− 和 δt=qt −y t−. - 更新价值网络:
w new ← w now − α ⋅ δ t ⋅ ∇ w q ( s t , a t ; w now ) \boldsymbol{w}_{\text {new }} \leftarrow \boldsymbol{w}_{\text {now }}-\alpha \cdot \delta_t \cdot \nabla_w q\left(s_t, a_t ; \boldsymbol{w}_{\text {now }}\right) wnew ←wnow −α⋅δt⋅∇wq(st,at;wnow ) - 更新策略网络:
θ new ← θ now + β ⋅ q ^ t ⋅ ∇ θ ln π ( a t ∣ s t ; θ now ) . \boldsymbol{\theta}_{\text {new }} \leftarrow \boldsymbol{\theta}_{\text {now }}+\beta \cdot \widehat{q}_t \cdot \nabla_{\boldsymbol{\theta}} \ln \pi\left(a_t \mid s_t ; \boldsymbol{\theta}_{\text {now }}\right) . θnew ←θnow +β⋅q t⋅∇θlnπ(at∣st;θnow ). - 设 τ ∈ ( 0 , 1 ) \tau \in(0,1) τ∈(0,1) 是需要手动调整的超参数。做加权平均更新目标网络的参数:
w new − ← τ ⋅ w new + ( 1 − τ ) ⋅ w now − . \boldsymbol{w}_{\text {new }}^{-} \leftarrow \tau \cdot \boldsymbol{w}_{\text {new }}+(1-\tau) \cdot \boldsymbol{w}_{\text {now }}^{-} . wnew −←τ⋅wnew +(1−τ)⋅wnow −.
8.带基线的策略梯度方法
上一章推导出策略梯度, 并介绍了两种策略梯度方法,REINFORCE 和 actor-critic。虽然上一章的方法在理论上是正确的,但是在实践中效果并不理想。本章介绍的带基线的策略梯度(policy gradient with baseline)可以大幅提升策略梯度方法的表现。使用基线 (baseline) 之后, REINFORCE 变成 REINFORCE with baseline, actor-critic 变成 advantage actor-critic (A2C)。|
- 在策略梯度中加入基线 (baseline) 可以降低方差, 显著提升实验效果。实践中常用 b = V π ( s ) b=V_\pi(s) b=Vπ(s) 作为基线。
- 可以用基线来改进 REINFORCE 算法。价值网络 v ( s ; w ) v(s ; \boldsymbol{w}) v(s;w) 近似状态价值函数 V π ( s ) V_\pi(s) Vπ(s),把 v ( s ; w ) v(s ; \boldsymbol{w}) v(s;w) 作为基线。用策略梯度上升来更新策略网络 π ( a ∣ s ; θ ) \pi(a \mid s ; \boldsymbol{\theta}) π(a∣s;θ) 。用蒙特卡洛(而非自举)来更新价值网络 v ( s ; w ) v(s ; \boldsymbol{w}) v(s;w) 。
- 可以用基线来改进 actor-critic, 得到的方法叫做 advantage actor-critic (A2C), 它也有一个策略网络 π ( a ∣ s ; θ ) \pi(a \mid s ; \boldsymbol{\theta}) π(a∣s;θ) 和一个价值网络 v ( s ; θ ) v(s ; \boldsymbol{\theta}) v(s;θ) 。用策略梯度上升来更新策略网络, 用 T D \mathrm{TD} TD 算法来更新价值网络。
9.策略学习高级技巧
本章介绍策略学习的高级技巧
- 置信域方法指的是一大类数值优化算法, 通常用于求解非凸问题。对于一个最大化问题,算法重复两个步骤一一做近似、最大化一一直到算法收玫。
- 置信域策略优化 (TRPO) 是一种置信域算法, 它的目标是最大化目标函数 J ( θ ) = J(\theta)= J(θ)= E S [ V π ( S ) ] \mathbb{E}_S\left[V_\pi(S)\right] ES[Vπ(S)] 。与策略梯度算法相比, TRPO 的优势在于更好的稳定性、用更少的样本达到收敛。
- 策略学习中常用熵正则这种技巧, 即鼓励策略网络输出的概率分布有较大的熵。熵越大, 概率分布越均匀; 摘越小, 概率质量越集中在少数动作上。
10.连续控制
本书前面章节的内容全部都是离散控制, 即动作空间是一个离散的集合, 比如超级玛丽游戏中的动作空间 A = { \mathcal{A}=\{ A={ 左, 右, 上 } \} } 就是个离散集合。本章的内容是连续控制, 即动作空间是个连续集合, 比如汽车的转向 A = [ − 4 0 ∘ , 4 0 ∘ ] \mathcal{A}=\left[-40^{\circ}, 40^{\circ}\right] A=[−40∘,40∘] 就是连续集合。如果把连续动作空间做离散化, 那么离散控制的方法就能直接解决连续控制问题; 我们在第10.1节讨论连续集合的离散化。然而更好的办法是直接用连续控制方法, 而非离散化之后借用离散控制方法。本章介绍两种连续控制方法:第10.2节介绍确定策略网络, 第10.5节介绍随机策略网络。
- 离散控制问题的动作空间 A \mathcal{A} A 是个有限的离散集,连续控制问题的动作空间 A \mathcal{A} A 是个连续集。如果想将 DQN 等离散控制方法应用到连续控制问题, 可以对连续动作空间做离散化, 但这只适用于自由度较小的问题。
- 可以用确定策略网络 a = μ ( s ; θ ) \boldsymbol{a}=\boldsymbol{\mu}(s ; \boldsymbol{\theta}) a=μ(s;θ) 做连续控制。网络的输入是状态 s s s, 输出是动作 a , a a, a a,a 是向量, 大小等于问题的自由度。
- 确定策略梯度(DPG)借助价值网络 q ( s , a ; w ) q(s, a ; \boldsymbol{w}) q(s,a;w) 训练确定策略网络。DPG 属于异策略, 用行为策略收集经验, 做经验回放更新策略网络和价值网络。
- DPG 与 DQN 有很多相似之处, 而且它们的训练都存在高估等问题。TD3 使用几种技巧改进 D P G \mathrm{DPG} DPG : 截断双 Q \mathrm{Q} Q 学习、往动作中加噪声、降低更新策略网络和目标网络的频率。
- 可以用随机高斯策略做连续控制。用两个神经网络分别近似高斯分布的均值和方差对数, 并用策略梯度更新两个神经网络的参数。
11.对状态的不完全观测
在很多应用中, 智能体只能部分观测到当前环境的状态, 这会给决策造成困难。本章内容分三节, 分别介绍不完全观测问题、循环神经网络(RNN)、用 RNN 策略网络解决不完全观测问题。
- 在很多强化学习的应用中, 智能体无法完整观测到环境当前的状态 s t s_t st 。我们把观测记作 o t o_t ot, 以区别完整的状态。仅仅基于当前观测 o t o_t ot 做决策, 效果会不理想。
- 一种合理的解决方案是记忆过去的状态, 基于历史上全部的观测 o 1 , ⋯ , o t o_1, \cdots, o_t o1,⋯,ot 做决策。常用循环神经网络(RNN)做为策略函数, 做出的决策依赖于历史上全部的观测。
12.模仿学习
模仿学习(imitation learning)不是强化学习, 而是强化学习的一种替代品。模仿学习与强化学习有相同的目的: 两者的目的都是学习策略网络, 从而控制智能体。模仿学习与强化学习有不同的原理:模仿学习向人类专家学习, 目标是让策略网络做出的决策与人类专家相同; 而强化学习利用环境反馈的奖励改进策略, 目标是让累计奖励(即回报)最大化。
本章内容分三节, 分别介绍三种常见的模仿学习方法:行为克隆 (behavior cloning)、逆向强化学习 (inverse reinforcement learning)、生成判别模仿学习 (GAIL)。行为克隆不需要让智能体与环境交互, 因此学习的“成本”很低。而逆向强化学习、生成判别模仿学习则需要让智能体与环境交互。
- 模仿学习起到与强化学习相同的作用, 但模仿学习不是强化学习。模仿学习从专家的动作中学习策略, 而强化学习从奖励中学习策略。
- 行为克隆是最简单的模仿学习, 其本质是分类或回归。行为克隆可以完全线下训练,无需与环境交互, 因此训练的代价很小。行为克隆存在错误累加的缺点, 实践中效果不如强化学习。
- 强化学习利用奖励学习策略, 而逆向强化学习(IRL)从策略中反推奖励函数。IRL 适用于不知道奖励函数的控制问题,比如无人驾驶。对于这种问题,可以先用 IRL 从人类专家的行为中学习奖励函数, 再利用奖励函数做强化学习; 这种方法被称作学徒学习。
- 生成判别模仿学习 (GAIL) 借用 GAN 的思想, 使用一个生成器和一个判别器。生成器是策略函数, 学习的目标是让生成的轨迹与人类专家的行为相似, 使得判别器无法区分。
第四部分:多智能体强化学习
13.并行计算
机器学习的实践中普遍使用并行计算, 利用大量的计算资源(比如很多块 GPU)缩短训练所需的时间, 用几个小时就能完成原本需要很多天才能完成的训练。深度强化学习自然也不例外。可以用很多处理器同时收集经验、计算梯度, 让原本需要很长时间的训练在较短的时间内完成。第 13.1 以并行梯度下降为例讲解并行计算基础知识。第 13.2 介绍异步并行梯度下降算法。第 13.3 介绍两种异步强化学习算法。
- 并行计算用多个处理器、多台机器加速计算, 使得计算所需的钟表时间减少。使用并行计算, 每块处理器承担的计算量会减小, 有利于减小钟表时间。
- 常用加速比作为评价并行算法的指标。理想情况下, 处理器数量增加 m m m 倍, 加速比就是 m m m 。然而并行计算还有通信、同步等代价, 加速比通常小于 m m m 。减小通信时间、同步时间是设计并行算法的关键。
- 可以用 MapReduce 在集群上做并行计算。MapReduce 属于 client-server 架构, 需要做同步。
- 同步算法每一轮更新模型之前, 要求所有节点都完成计算。这会造成空闲和等待,影响整体的效率。而异步算法无需等待, 因此效率更高。在机器学习的实践中, 异步并行算法比同步并行算法所需的钟表时间更短。
- 本章讲解了异步并行的双 Q \mathrm{Q} Q 学习算法与 A 3 C \mathrm{A} 3 \mathrm{C} A3C 算法。两种算法都是让 worker 端并行计算梯度, 在服务器端用梯度更新神经网络参数。
相关文章:
【王树森】深度强化学习(DRL)学习笔记
目录 第一部分:基础知识1.机器学习基础2.蒙特卡洛估计3.强化学习基础知识3.1 马尔科夫决策过程马尔可夫决策过程(Markov decision process,MDP)智能体环境状态状态空间动作动作空间奖励状态转移状态转移概率 3.2 策略策略定义 3.3…...

LLM应用实战:当图谱问答(KBQA)集成大模型(三)
1. 背景 最近比较忙(也有点茫),本qiang~想切入多模态大模型领域,所以一直在潜心研读中... 本次的更新内容主要是响应图谱问答集成LLM项目中反馈问题的优化总结,对KBQA集成LLM不熟悉的客官可以翻翻之前的文章《LLM应用实战:当KBQ…...

Django框架中Ajax GET与POST请求的实战应用
系列文章目录 以下几篇侧重点为JavaScript内容0.0 JavaScript入门宝典:核心知识全攻略(上)JavaScript入门宝典:核心知识全攻略(下)Django框架中Ajax GET与POST请求的实战应用VSCode调试揭秘:L…...

web前端怎么挣钱, 提升技能,拓宽就业渠道
web前端怎么挣钱 在当今数字化时代,Web前端技术已成为互联网行业中不可或缺的一部分。越来越多的人选择投身于这个领域,希望能够通过掌握前端技术来实现自己的职业发展和经济收益。那么,Web前端如何挣钱呢?接下来,我们…...

基于Python的信号处理(包络谱,低通、高通、带通滤波,初级特征提取,机器学习,短时傅里叶变换)及轴承故障诊断探索
Python是一种广泛使用的解释型、高级和通用的编程语言,众多的开源科学计算软件包都提供了Python接口,如计算机视觉库OpenCV、可视化工具库VTK等。Python专用计算扩展库,如NumPy、SciPy、matplotlab、Pandas、scikit-learn等。 开发工具上可用…...

大型语言模型智能体(LLM Agent)在实际使用的五大问题
在这篇文章中,我将讨论人们在将代理系统投入生产过程中经常遇到的五个主要问题。我将尽量保持框架中立,尽管某些问题在特定框架中更加常见。 1. 可靠性问题 可靠性是所有代理系统面临的最大问题。很多公司对代理系统的复杂任务持谨慎态度,因…...
C语言内存管理
1.进程的内存分布 练习:编写一个程序,测试栈空间的大小 #include<stdio.h>#define SIZE 1024*1024*7void main (void) {char buf[SIZE];buf[SIZE-1] 100;printf("%d\n",buf[SIZE-1]); }如果SIZE 大小超过8M(102410248),…...
AD24设计步骤
一、元件库的创建 1、AD工程创建 然后创建原理图、PCB、库等文件 2、电阻容模型的创建 注意:防止管脚时设置栅格大小为100mil,防止线段等可以设置小一点,快捷键vgs设置栅格大小。 1.管脚的设置 2.元件的设置 3、IC类元件的创建 4、排针类元件模型创建…...

基于MBD的大飞机模块化广域协同研制
引言 借鉴国外航空企业先进经验,在国内,飞机型号的研制通常采用基于模型定义(MBD)的三维数模作为唯一的设计制造协同数据源,从而有效减少了设计和制造部门之间的模型沟通成本和重构所需的时间,也减少或避免…...

鸿蒙轻内核M核源码分析系列二十 Newlib C
LiteOS-M内核LibC实现有2种,可以根据需求进行二选一,分别是musl libC和newlibc。本文先学习下Newlib C的实现代码。文中所涉及的源码,均可以在开源站点https://gitee.com/openharmony/kernel_liteos_m 获取。 使用Musl C库的时候,…...

力扣1818.绝对差值和
力扣1818.绝对差值和 把nums1拷贝复制一份 去重排序 对于每个nums2都找到差距最小的那个数(二分) 作差求最大可优化差值去重排序可以直接用set 自动去重排序了 const int N 1e97;class Solution {public:int minAbsoluteSumDiff(vector<int>& nums1, vector<i…...
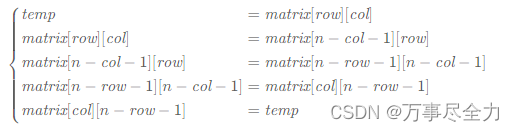
矩阵练习2
48.旋转图像 规律: 对于矩阵中第 i行的第 j 个元素,在旋转后,它出现在倒数第i 列的第 j 个位置。 matrix[col][n−row−1]matrix[row][col] 可以使用辅助数组,如果不想使用额外的内存,可以用一个临时变量 。 还可以通…...
2024海南省大数据教师培训-Hadoop集群部署
前言 本文将详细介绍Hadoop分布式计算框架的来源,架构和应用场景,并附上最详细的集群搭建教程,能更好的帮助各位老师和同学们迅速了解和部署Hadoop框架来进行生产力和学习方面的应用。 一、Hadoop介绍 Hadoop是一个开源的分布式计算框架&…...

力扣算法题:将数字变为0的操作次数--多语言实现
无意间看到,力扣存算法代码居然还得升级vip。。。好吧,我自己存吧 golang: func numberOfSteps(num int) int {steps : 0for num > 0 {if num%2 0 {num / 2} else {num - 1}steps}return steps } javascript: /*** param {number} num…...

vue前段处理时间格式,设置开始时间为00:00:00,设置结束时间为23:59:59
在Vue开发中,要在前端控制日期时间选择器的时间范围,可以通过以下方式实现: 使用beforeDestroy生命周期钩子函数来处理时间范围: 在Vue组件中,可以监听日期时间选择器的变化,在选择开始日期时,自…...

Java 8 新特性全面解读
Java 8,作为一次重大更新,于2014年引入了多项创新特性,极大地改善了Java的编程体验和性能。此版本不仅加入了对函数式编程的支持,还增强了接口的功能,引入了新的API,并优化了语言的整体效率。接下来&#x…...

JavaScript知识之函数
javascript函数 在JavaScript基础之上提供了部分函数,同时也可以自定义函数,JavaScript基础详见之前的文章javascript基础知识 自定义函数 //关键字 函数名 参数列表 函数体 function test(a,b,c){alert(a":"b":"c) }function test1(a,b){return a;//不…...

【Pepper机器人开发与应用】一、Pepper SDK for LabVIEW下载与安装教程
🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主 📑上期文章:『一文汇总对比英伟达、AMD、英特尔显卡GPU』 🍻本文由virobotics(仪酷智能)原创 🥳欢迎大家关注✌点赞&…...

HCIP-AI EI 认证课程大纲
该阶段详细介绍计算机视觉、注意力机制与Transformer、自然语言处理、语音处理等 AI 核心领域技术,并重点介绍华为云 EI 服务使用。 共计48 课时。第一节:计算机视觉技术概述与图像处理基础 - (3 课时) - 什么是计算机视觉&#x…...
@Test注解方法,方法无法执行
1.背景 写了一个测试方法,执行后如图 2.原因是 该项目是springbootgradle...构建的项目 在build.gradle配置文件中关闭了单元测试: test {useJUnitPlatform()// 是否启用单元测试enabled false } 3.处理方式 开启单元测试 test {useJUnitPlatform()// 是否启用单元测试ena…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...

aurora与pcie的数据高速传输
设备:zynq7100; 开发环境:window; vivado版本:2021.1; 引言 之前在前面两章已经介绍了aurora读写DDR,xdma读写ddr实验。这次我们做一个大工程,pc通过pcie传输给fpga,fpga再通过aur…...

更新 Docker 容器中的某一个文件
🔄 如何更新 Docker 容器中的某一个文件 以下是几种在 Docker 中更新单个文件的常用方法,适用于不同场景。 ✅ 方法一:使用 docker cp 拷贝文件到容器中(最简单) 🧰 命令格式: docker cp <…...