Spark MLlib机器学习
前言
随着大数据时代的到来,数据处理和分析的需求急剧增加,传统的数据处理工具已经难以满足海量数据的分析需求。Apache Spark作为一种快速、通用的集群计算系统,迅速成为了大数据处理的首选工具。而在Spark中,MLlib(机器学习库)则是其专门用于处理机器学习任务的库,为用户提供了丰富的算法和工具,以便轻松实现大规模机器学习任务。
一、Spark MLlib简介
Spark MLlib是Apache Spark的机器学习库,旨在提供简洁、高效、可扩展的机器学习算法。MLlib包括各种常见的机器学习算法,如分类、回归、聚类和协同过滤等。此外,它还提供了一些底层的优化算法和工具,如梯度下降法、数据管道、特征处理和评估指标等。
Spark MLlib的主要优点包括:
- 高效性:MLlib中的算法是为分布式计算设计的,可以在大规模数据集上高效运行。
- 可扩展性:MLlib可以轻松扩展到数百个节点,处理TB级别的数据。
- 易用性:MLlib提供了简单易用的API,用户可以快速实现复杂的机器学习任务。
- 与Spark的无缝集成:MLlib可以与Spark的其他模块(如Spark SQL、Spark Streaming)无缝集成,构建复杂的数据处理和分析管道。
二、Spark MLlib的核心组件
-
算法:MLlib提供了丰富的机器学习算法,包括线性回归、逻辑回归、支持向量机、决策树、随机森林、K-means聚类、朴素贝叶斯、协同过滤等。这些算法都经过优化,能够在分布式环境下高效运行。
-
特征处理:机器学习中的特征处理是至关重要的步骤。MLlib提供了一系列特征处理工具,包括标准化、归一化、独热编码、特征选择、特征抽取等,帮助用户从原始数据中提取和转换特征。
-
数据管道:MLlib的Pipeline API允许用户将数据预处理、特征提取和模型训练等步骤组合在一起,形成一个完整的数据处理和机器学习管道。Pipeline API使得整个过程更加模块化和可重用。
-
模型评估:MLlib提供了多种模型评估指标和方法,如准确率、精确率、召回率、F1-score、均方误差、均方根误差等,帮助用户评估模型的性能。
-
持久化和加载:MLlib支持模型和管道的持久化和加载,用户可以将训练好的模型保存到磁盘中,方便以后加载和使用。
三、Spark MLlib的主要算法
1. 分类
分类是机器学习中最常见的任务之一,目的是将数据分为两个或多个类别。MLlib提供了多种分类算法,包括:
- 逻辑回归:一种用于二分类问题的算法,通过学习数据的线性关系来进行分类。
- 决策树:一种树形结构的分类算法,通过构建决策树对数据进行分类。
- 随机森林:一种基于决策树的集成算法,通过构建多个决策树并进行投票来提高分类性能。
- 支持向量机(SVM):一种用于二分类的算法,通过寻找最佳的超平面将数据分开。
- 朴素贝叶斯:一种基于贝叶斯定理的分类算法,适用于文本分类等高维数据。
2. 回归
回归分析用于预测连续变量的值,MLlib提供了多种回归算法,包括:
- 线性回归:一种用于预测连续值的算法,通过学习数据的线性关系来进行预测。
- 决策树回归:通过构建决策树来进行回归分析。
- 随机森林回归:一种集成算法,通过构建多个决策树并进行平均来提高预测性能。
3. 聚类
聚类是无监督学习的一种,用于将数据分组,MLlib提供了常见的聚类算法:
- K-means聚类:一种将数据分成K个簇的算法,通过最小化簇内距离的平方和来实现。
- Gaussian Mixture Model(GMM):一种基于概率模型的聚类算法,通过混合多个高斯分布来对数据进行建模和聚类。
4. 协同过滤
协同过滤用于推荐系统,MLlib提供了基于矩阵分解的协同过滤算法:
- 交替最小二乘法(ALS):一种用于推荐系统的算法,通过矩阵分解来预测用户对物品的评分。
四、Spark MLlib的应用案例
1. 文本分类
文本分类是机器学习中的一个经典问题,通常用于垃圾邮件过滤、情感分析等。使用Spark MLlib,可以轻松实现文本分类任务。以下是一个简单的例子,使用逻辑回归对文本数据进行分类:
from pyspark.sql import SparkSession
from pyspark.ml.feature import HashingTF, IDF, Tokenizer
from pyspark.ml.classification import LogisticRegression# 创建SparkSession
spark = SparkSession.builder.appName("TextClassification").getOrCreate()# 加载数据
data = spark.read.csv("path/to/text_data.csv", header=True, inferSchema=True)# 文本预处理
tokenizer = Tokenizer(inputCol="text", outputCol="words")
wordsData = tokenizer.transform(data)hashingTF = HashingTF(inputCol="words", outputCol="rawFeatures", numFeatures=20)
featurizedData = hashingTF.transform(wordsData)idf = IDF(inputCol="rawFeatures", outputCol="features")
idfModel = idf.fit(featurizedData)
rescaledData = idfModel.transform(featurizedData)# 训练逻辑回归模型
lr = LogisticRegression(labelCol="label", featuresCol="features")
model = lr.fit(rescaledData)# 模型评估
predictions = model.transform(rescaledData)
predictions.select("text", "label", "prediction").show()
2. 推荐系统
推荐系统是电子商务和社交网络中的重要应用,通过向用户推荐感兴趣的物品来提高用户体验和销售量。以下是一个使用ALS算法构建推荐系统的例子:
from pyspark.sql import SparkSession
from pyspark.ml.recommendation import ALS
from pyspark.ml.evaluation import RegressionEvaluator# 创建SparkSession
spark = SparkSession.builder.appName("RecommendationSystem").getOrCreate()# 加载数据
data = spark.read.csv("path/to/ratings.csv", header=True, inferSchema=True)# 构建ALS模型
als = ALS(userCol="userId", itemCol="movieId", ratingCol="rating", coldStartStrategy="drop")
model = als.fit(data)# 模型评估
predictions = model.transform(data)
evaluator = RegressionEvaluator(metricName="rmse", labelCol="rating", predictionCol="prediction")
rmse = evaluator.evaluate(predictions)
print(f"Root-mean-square error = {rmse}")# 生成推荐
userRecs = model.recommendForAllUsers(10)
movieRecs = model.recommendForAllItems(10)userRecs.show()
movieRecs.show()
五、总结
Spark MLlib作为Apache Spark的重要组件,为大规模机器学习任务提供了强大的工具和算法。它不仅高效、可扩展,而且易于使用,能够与Spark的其他模块无缝集成,构建复杂的数据处理和分析管道。通过MLlib,用户可以轻松实现各种机器学习任务,如分类、回归、聚类和推荐系统等,并且能够处理TB级别的数据,满足大数据时代的需求。
随着机器学习和大数据技术的不断发展,Spark MLlib也在不断演进和优化。未来,MLlib将继续引领大规模机器学习的发展,为用户提供更加丰富和高效的机器学习解决方案。在实际应用中,MLlib已经广泛应用于各个领域,如金融、医疗、电商、社交网络等,展现了其强大的应用潜力和商业价值。通过不断学习和探索,相信我们能够更好地利用Spark MLlib,挖掘数据的价值,为业务决策和创新提供有力支持。
相关文章:

Spark MLlib机器学习
前言 随着大数据时代的到来,数据处理和分析的需求急剧增加,传统的数据处理工具已经难以满足海量数据的分析需求。Apache Spark作为一种快速、通用的集群计算系统,迅速成为了大数据处理的首选工具。而在Spark中,MLlib(…...
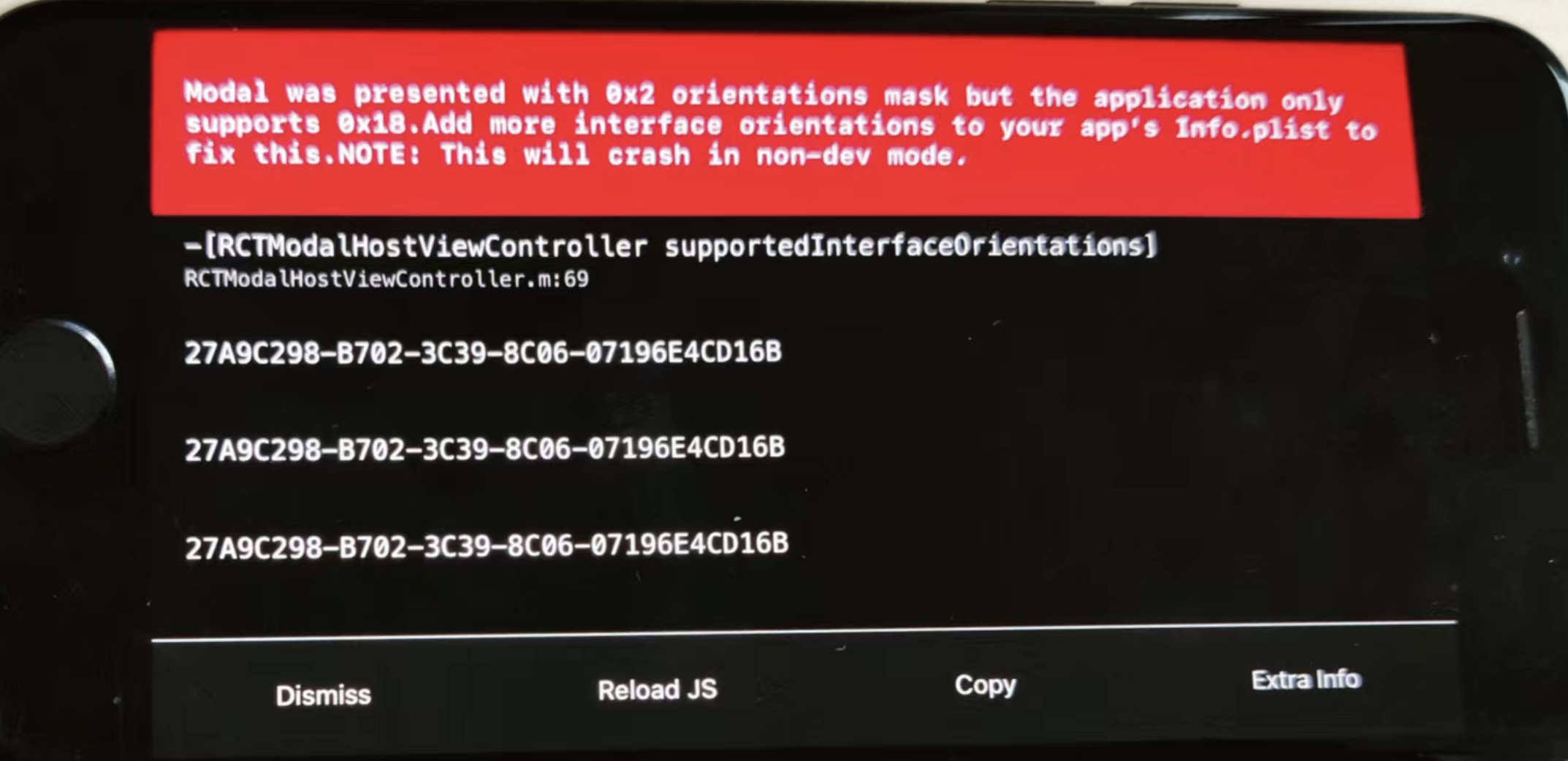
React Native将 ipad 端软件设置为横屏显示后关闭 Modal 弹窗报错
问题: 将 ipad 端软件设置为横屏显示后,关闭 Modal 弹窗报错。 Modal was presented with 0x2 orientations mask but the application only supports 0x18.Add more interface orientations to your apps Info.plist to fix this.NOTE: This will cras…...

JavaEE大作业之班级通讯录系统(前端HTML+后端JavaEE实现)PS:也可选网络留言板、图书借阅系统、寝室管理系统
背景: 题目要求: 题目一:班级通讯录【我们选这个】 实现一个B/S结构的电子通讯录,其中的每条记录至少包含学号、姓名、性别、班级、手机号、QQ号、微信号,需要实现如下功能: (1)…...
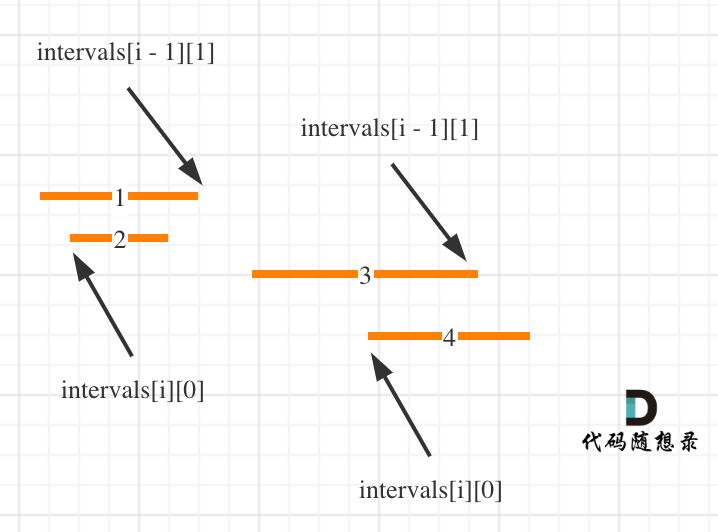
代码随想录算法训练营第37天|● 56.合并区间● 738.单调递增的数字
合并区间 56. 合并区间 - 力扣(LeetCode) 按照左边界从小到大排序之后,如果 intervals[i][0] < intervals[i - 1][1] 即intervals[i]的左边界 < intervals[i - 1]的右边界,则一定有重叠。(本题相邻区间也算重贴…...

SQL Server中的CTE和临时表优化
在SQL Server中,优化查询性能是数据库管理的核心任务之一。使用公用表表达式(CTE)和临时表是两种重要的技术手段。本文将深入探讨CTE如何简化代码,以及临时表如何优化查询性能。通过实例和详尽解释,我们将展示这两种技…...

CCRC信息安全服务资质认证是什么
什么是CCRC认证? CCRC 全称 China Cybersecurity Review Technology and Certification Center。CCRC认证是指中国网络安全审查技术与认证中心进行的信息安全服务资质认证。简称信息安全服务资质认证。 CCRC,即中国网络安全审查技术与认证中心࿰…...
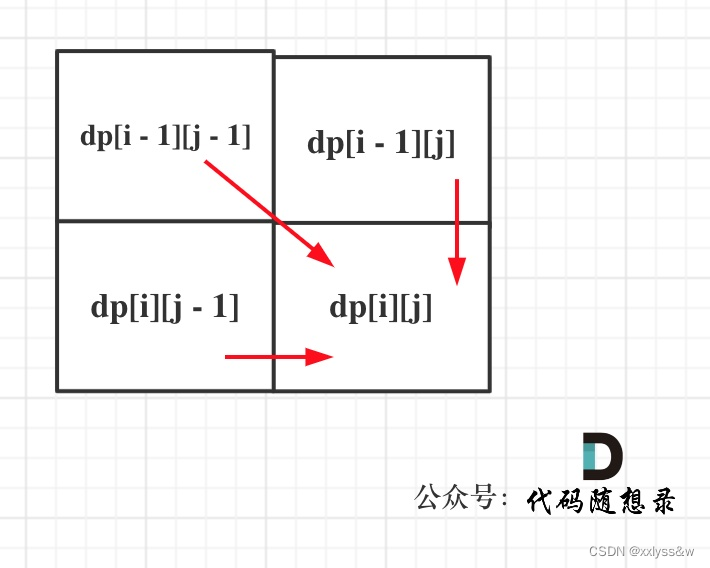
第五十一天 | 1143.最长公共子序列
题目:1143.最长公共子序列718.最长重复子数组的区别是,子序列不要求连续,子数组要求连续。这一差异体现在dp数组含义和递推公式中,本题是子序列,那就要考虑上nums1[i - 1] ! nums2[j - 1]的情况。 本道题与 1.dp数组…...

未来的5-10年,哪些行业可能会被AI代替?
在未来的5-10年,多个行业可能会受到AI技术的影响,其中一些工作可能会被AI所代替。以下是对可能被AI替代的行业及工作的一些概述: 客户服务与代表:随着AI技术的发展,特别是自动话术对话和语音生成技术的进步࿰…...

据报道,FTC 和 DOJ 对微软、OpenAI 和 Nvidia 展开反垄断调查
据《纽约时报》报道,联邦贸易委员会 (FTC) 和司法部 (DOJ) 同意分担调查微软、OpenAI 和 Nvidia 潜在反垄断违规行为的职责。 美国司法部将牵头对英伟达进行调查,而联邦贸易委员会将调查 OpenAI 与其最大投资者微软之间的交易。 喜好儿网 今年 1 月&a…...

人工智能发展历程和工具搭建学习
目录 人工智能的三次浪潮 开发环境介绍 Anaconda Anaconda的下载和安装 下载说明 安装指导 模块介绍 使用Anaconda Navigator Home界面介绍 Environment界面介绍 使用Jupter Notebook 打开Jupter Notebook 配置默认目录 新建文件 两种输入模式 Conda 虚拟环境 添…...

Dijkstra算法的原理
Dijkstra算法的原理可以清晰地分为以下几个步骤和要点: 初始化: 引入一个辅助数组D,其中D[i]表示从起始点(源点)到顶点i的当前已知最短距离。如果起始点与顶点i之间没有直接连接,则D[i]被初始化为无穷大&a…...
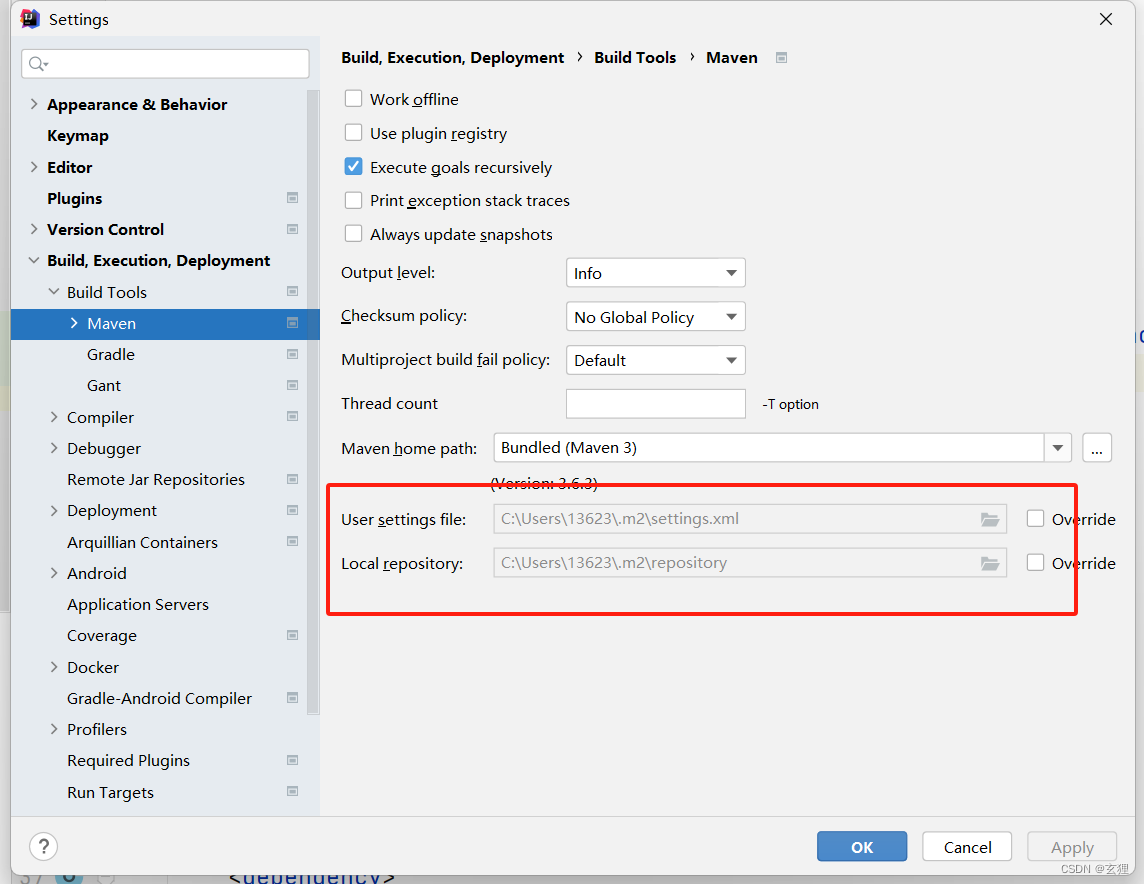
maven引入依赖时莫名报错
一般跟依赖的版本无关,会报出 Cannot resolve xxx 的错误。 这种情况下去IDEA的setting中找maven的仓库位置 在仓库中顺着包路径下寻找,可能会找到.lastUpdated 的文件,这样的文件一般是下载失败了,而且在一段时间内不再下载&…...

graalvm编译springboot3 native应用
云原生时代容器先行,为了更好的拥抱云原生,spring boot3之后,推出了graalvm编译boot项目,利用jvm的AOT( Ahead Of Time )运行前编译技术,可以将javay源码直接构建成机器码二进制的文件ÿ…...

代码随想录Day58
392.判断子序列 题目:392. 判断子序列 - 力扣(LeetCode) 思路:定义重合数记录s与t的比对情况,挨个取出t的字符,与s的字符进行比较,如果相同,重合数就加1,跳到s的下一个字…...
 与 dm-verity 之间的关系、相同点与差异点)
Android Verified Boot (AVB) 与 dm-verity 之间的关系、相同点与差异点
标签: AVB; dm-verity ;Android Android Verified Boot (AVB) 与 dm-verity 之间的关系、相同点与差异点 概述 Android Verified Boot (AVB) 和 dm-verity 是 Android 操作系统中用于确保设备启动过程和运行时数据完整性的两个重要技术。尽管它们有着不同的实现和侧重点,…...

C++学习笔记“类和对象”:多态;
目录 4.7 多态 4.7.1 多态的基本概念 4.7.2 多态案例--计算器类 4.7.3 纯虚函数和抽象类 4.7.4 多态案例二 - 制作饮品 4.7.5 虚析构和纯虚析构 4.7.6 多态案例三-电脑组装 4.7 多态 4.7.1 多态的基本概念 多态是C面向对象三大特性之一 多态分为两类 静志多态: 函数…...
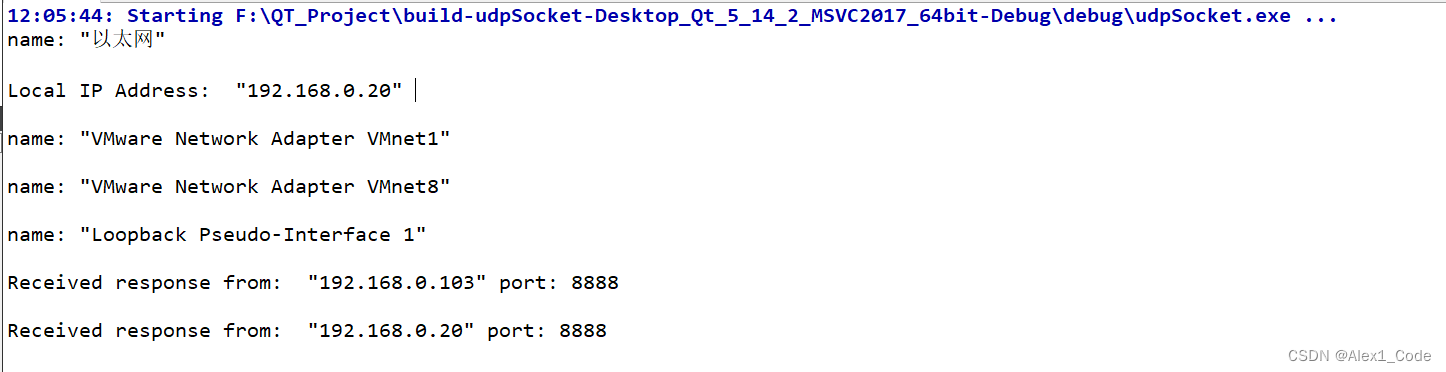
QT Udp广播实现设备发现
测试环境 本文选用pc1作为客户端,pc2,以及一台虚拟机作为服务端。 pc1,pc2(客户端): 虚拟机(服务端): 客户端 原理:客户端通过发送广播消息信息到ip:255.255.255.255(QHostAddress::Broadcast),局域网…...

PyTorch 统计属性-Tensor基本操作
最小 min, 最大 max, 均值 mean,累加 sum,累乘 prod … >>> a torch.arange(0,8).view(2,4).float() >>> a tensor([[0., 1., 2., 3.],[4., 5., 6., 7.]])>>> a.min() ## 最小值:tensor(0.) >>> a.ma…...
波拉西亚战记加速器 台服波拉西亚战记免费加速器
波拉西亚战记是一款新上线的MMORPG游戏,游戏内我们有多个角色职业可以选择,可以体验不同的战斗流派玩法,开放式的地图设计,玩家可以自由的进行探索冒险,寻找各种物资。各种随机事件可以触发,让玩家的冒险过…...

Mocha + Chai 测试环境配置,支持 ES6 语法
下面是一个完整的 Mocha Chai 测试环境配置,支持 ES6 语法。我们将使用 Babel 来转译 ES6 代码。 步骤一:初始化项目 首先,在项目目录中运行以下命令来初始化一个新的 Node.js 项目: npm init -y步骤二:安装必要的…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...