Python酷库之旅-比翼双飞情侣库(10)
目录
一、xlrd库的由来
二、xlrd库优缺点
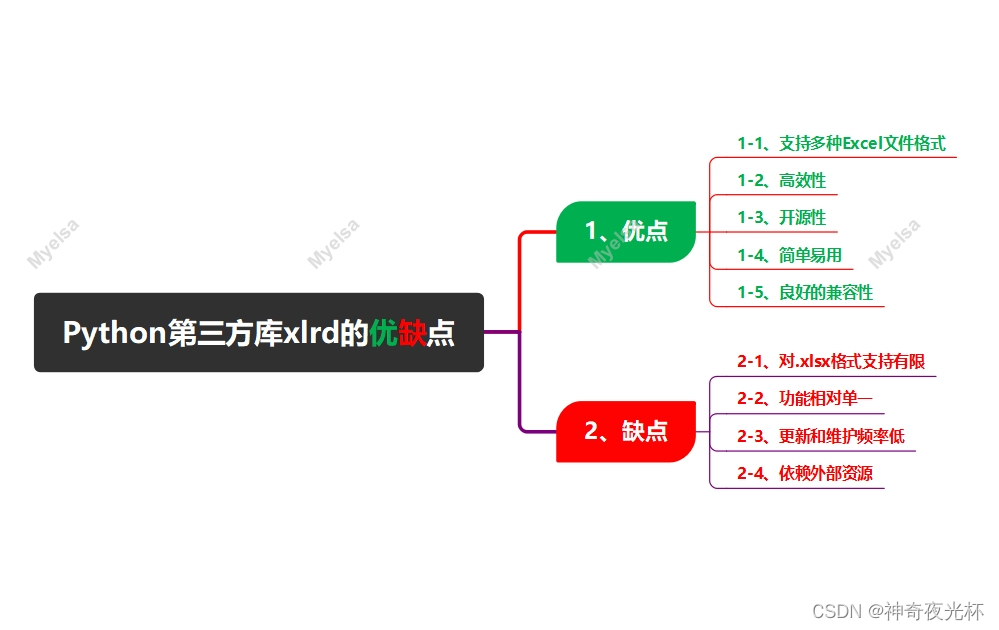
1、优点
1-1、支持多种Excel文件格式
1-2、高效性
1-3、开源性
1-4、简单易用
1-5、良好的兼容性
2、缺点
2-1、对.xlsx格式支持有限
2-2、功能相对单一
2-3、更新和维护频率低
2-4、依赖外部资源
三、xlrd库的版本说明
1、xlrd 1.2.0版本
2、xlrd 2.0.1版本
3、xlrd3(非官方名称)
四、如何学好xlrd库?
1、获取xlrd库的属性和方法
2、获取xlrd库的帮助信息
3、实战案例
3-38、通过索引引用工作表
3-39、通过名称引用工作表
3-40、通过sheet_names集合引用工作表
3-41、引用当前活动工作表
3-42、引用第一个工作表
3-43、引用最后一个工作表
3-44、引用所有的工作表
3-45、引用指定的多个工作表
3-46、引用新建的工作表
3-47、引用包含特定单元格的工作表
3-48、引用工作表名称中包含特定字符串的工作表
五、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页



在Excel中,通常所说的“情侣键”并非官方术语,而是对某些常用且经常成对出现的快捷键的一种形象化的称呼。其中,最为人熟知和广泛使用的“情侣键”是“Ctrl+C”和“Ctrl+V”。
1、Ctrl+C:这个快捷键的作用是“拷贝”或“复制”。当你在Excel中选中某个单元格、一行、一列或整个工作表的内容后,按下Ctrl+C键,这些内容就会被复制到计算机的剪贴板中,等待下一步的粘贴操作。
2、Ctrl+V:这个快捷键的作用是“粘贴”。在你按下Ctrl+C键将内容复制到剪贴板后,可以通过按下Ctrl+V键将这些内容粘贴到Excel中的另一个位置,这两个操作经常是连续进行的,因此Ctrl+C和Ctrl+V就像一对“情侣”,总是成对出现。
除了这对常见的“情侣键”外,Excel中还有许多其他的快捷键可以帮助用户更高效地完成各种操作。然而,这些快捷键通常并没有像Ctrl+C和Ctrl+V那样形成特定的“情侣”关系。
然而,今天我不再展开介绍“情侣键”,而是要重点推介Python中的“情侣库”,即xlrd和xlwt两个第三方库。
一、xlrd库的由来
xlrd库是一种用于在Python中读取Excel文件的库,它的名称中的"xl"代表Excel,"rd"代表读取,其开发者是John Machin(注:库名字符拆分诠释,只是一种猜测)。
xlrd最初是在2005年开始开发的,是基于Python的开源项目(下载:xlrd库官网下载)。
由于Excel文件在数据处理和分析中的重要性,xlrd库填补了Python在处理Excel文件方面的空白,使得用户可以方便地在Python环境中读取Excel文件的内容,并进行进一步的数据操作和分析。
二、xlrd库优缺点
1、优点
1-1、支持多种Excel文件格式
xlrd库支持多种Excel文件格式,包括`.xls`和`.xlsx`(在旧版本中),这使得无论数据存储在哪种格式的Excel文件中,用户都可以使用xlrd库来读取。
1-2、高效性
xlrd库使用C语言编写,因此其性能非常高,即使面对非常大的Excel文件,xlrd也可以快速地读取其中的数据。
1-3、开源性
xlrd是完全开源的,可以在GitHub等平台上找到其源代码,这使得任何人都可以根据自己的需求对其进行修改和扩展。
1-4、简单易用
xlrd提供了简单直接的API来获取单元格数据、行列数等,使得从Excel文件中读取数据变得简单而高效。
1-5、良好的兼容性
xlrd库适配多种Python版本,包括Python 2.7(不包括3.0-3.3)或Python 3.4及以上版本,这为用户提供了广泛的兼容性选择。
2、缺点
2-1、对.xlsx格式支持有限
在xlrd 1.2.0之后的版本中(大约从2020年开始),xlrd库不再支持`.xlsx`文件格式,这限制了xlrd在新版Excel文件(主要是`.xlsx`格式)上的应用。
2-2、功能相对单一
xlrd库主要专注于从Excel文件中读取数据,而不提供写入或修改Excel文件的功能,这使得在处理需要写入或修改Excel文件的任务时,用户需要结合其他库(如`openpyxl`或`xlwt`)使用。
2-3、更新和维护频率低
由于xlrd库主要关注于读取Excel文件的功能,并且随着`.xlsx`格式的普及,其使用范围逐渐缩小,因此,xlrd库的更新和维护频率可能相对较低。
2-4、依赖外部资源
在某些情况下,xlrd库可能需要依赖外部资源或库来完全发挥其功能,这可能会增加用户在使用xlrd库时的复杂性和不确定性。
总之,xlrd库在读取Excel文件方面具有高效、开源和简单易用等优点,但在对`.xlsx`格式的支持、功能单一以及更新和维护频率等方面存在一些缺点,用户在选择使用xlrd库时需要根据自己的需求进行权衡和选择。
三、xlrd库的版本说明
xlrd库适配的Python版本根据库的不同版本而有所不同。以下是针对几个主要版本的说明:
1、xlrd 1.2.0版本
1-1、适配Python>=2.7(不包括3.0-3.3)或Python>=3.4。
1-2、该版本支持xlsx文件格式,并且是一个广泛使用的版本,因为它能够处理小到中等大小的Excel文件,并且具有较好的性能表现。
2、xlrd 2.0.1版本
2-1、适配Python>=2.7(不包括3.0-3.5)或Python>=3.6。
2-2、该版本不再支持xlsx文件格式,仅支持旧版的xls文件格式,因为在xlrd 2.0版本之后,xlrd移除了对xlsx格式的支持。
3、xlrd3(非官方名称)
xlrd3是xlrd的开源扩展库,提供了对xlsx文件格式的支持,然而,请注意,xlrd3并不是xlrd的官方名称(下载:GitHub - Dragon2fly/xlrd3)。
四、如何学好xlrd库?
1、获取xlrd库的属性和方法
用print()和dir()两个函数获取xlrd库所有属性和方法的列表
# ['Book', 'FILE_FORMAT_DESCRIPTIONS', 'FMLA_TYPE_ARRAY', 'FMLA_TYPE_CELL', 'FMLA_TYPE_COND_FMT', 'FMLA_TYPE_DATA_VAL',
# 'FMLA_TYPE_NAME', 'FMLA_TYPE_SHARED', 'Operand', 'PEEK_SIZE', 'Ref3D', 'XLDateError', 'XLRDError', 'XLS_SIGNATURE',
# 'XL_CELL_BLANK', 'XL_CELL_BOOLEAN', 'XL_CELL_DATE', 'XL_CELL_EMPTY', 'XL_CELL_ERROR', 'XL_CELL_NUMBER', 'XL_CELL_TEXT', 'ZIP_SIGNATURE',
# '__VERSION__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__',
# '__spec__', '__version__',
# 'biff_text_from_num', 'biffh', 'book', 'cellname', 'cellnameabs', 'colname', 'compdoc', 'count_records', 'decompile_formula',
# 'dump', 'dump_formula', 'empty_cell', 'error_text_from_code', 'evaluate_name_formula', 'formatting', 'formula', 'info',
# 'inspect_format', 'oBOOL', 'oERR', 'oNUM', 'oREF', 'oREL', 'oSTRG', 'oUNK', 'okind_dict', 'open_workbook', 'open_workbook_xls',
# 'os', 'pprint', 'rangename3d', 'rangename3drel', 'sheet', 'sys', 'timemachine', 'xldate', 'xldate_as_datetime', 'xldate_as_tuple', 'zipfile']2、获取xlrd库的帮助信息
用help()函数获取xlrd库的帮助信息
Help on package xlrd:NAMExlrdDESCRIPTION# Copyright (c) 2005-2012 Stephen John Machin, Lingfo Pty Ltd# This module is part of the xlrd package, which is released under a# BSD-style licence.PACKAGE CONTENTSbiffhbookcompdocformattingformulainfosheettimemachinexldateFUNCTIONScount_records(filename, outfile=<_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>)For debugging and analysis: summarise the file's BIFF records.ie: produce a sorted file of ``(record_name, count)``.:param filename: The path to the file to be summarised.:param outfile: An open file, to which the summary is written.dump(filename, outfile=<_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>, unnumbered=False)For debugging: dump an XLS file's BIFF records in char & hex.:param filename: The path to the file to be dumped.:param outfile: An open file, to which the dump is written.:param unnumbered: If true, omit offsets (for meaningful diffs).inspect_format(path=None, content=None)Inspect the content at the supplied path or the :class:`bytes` content providedand return the file's type as a :class:`str`, or ``None`` if it cannotbe determined.:param path:A :class:`string <str>` path containing the content to inspect.``~`` will be expanded.:param content:The :class:`bytes` content to inspect.:returns:A :class:`str`, or ``None`` if the format cannot be determined.The return value can always be looked up in :data:`FILE_FORMAT_DESCRIPTIONS`to return a human-readable description of the format found.open_workbook(filename=None, logfile=<_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'>, verbosity=0, use_mmap=True, file_contents=None, encoding_override=None, formatting_info=False, on_demand=False, ragged_rows=False, ignore_workbook_corruption=False)Open a spreadsheet file for data extraction.:param filename: The path to the spreadsheet file to be opened.:param logfile: An open file to which messages and diagnostics are written.:param verbosity: Increases the volume of trace material written to thelogfile.:param use_mmap:Whether to use the mmap module is determined heuristically.Use this arg to override the result.Current heuristic: mmap is used if it exists.:param file_contents:A string or an :class:`mmap.mmap` object or some other behave-alikeobject. If ``file_contents`` is supplied, ``filename`` will not be used,except (possibly) in messages.:param encoding_override:Used to overcome missing or bad codepage informationin older-version files. See :doc:`unicode`.:param formatting_info:The default is ``False``, which saves memory.In this case, "Blank" cells, which are those with their own formattinginformation but no data, are treated as empty by ignoring the file's``BLANK`` and ``MULBLANK`` records.This cuts off any bottom or right "margin" of rows of empty or blankcells.Only :meth:`~xlrd.sheet.Sheet.cell_value` and:meth:`~xlrd.sheet.Sheet.cell_type` are available.When ``True``, formatting information will be read from the spreadsheetfile. This provides all cells, including empty and blank cells.Formatting information is available for each cell.Note that this will raise a NotImplementedError when used with anxlsx file.:param on_demand:Governs whether sheets are all loaded initially or when demandedby the caller. See :doc:`on_demand`.:param ragged_rows:The default of ``False`` means all rows are padded out with empty cells sothat all rows have the same size as found in:attr:`~xlrd.sheet.Sheet.ncols`.``True`` means that there are no empty cells at the ends of rows.This can result in substantial memory savings if rows are of widelyvarying sizes. See also the :meth:`~xlrd.sheet.Sheet.row_len` method.:param ignore_workbook_corruption:This option allows to read corrupted workbooks.When ``False`` you may face CompDocError: Workbook corruption.When ``True`` that exception will be ignored.:returns: An instance of the :class:`~xlrd.book.Book` class.DATAFILE_FORMAT_DESCRIPTIONS = {'xls': 'Excel xls', 'xlsb': 'Excel 2007 xl...FMLA_TYPE_ARRAY = 4FMLA_TYPE_CELL = 1FMLA_TYPE_COND_FMT = 8FMLA_TYPE_DATA_VAL = 16FMLA_TYPE_NAME = 32FMLA_TYPE_SHARED = 2PEEK_SIZE = 8XLS_SIGNATURE = b'\xd0\xcf\x11\xe0\xa1\xb1\x1a\xe1'XL_CELL_BLANK = 6XL_CELL_BOOLEAN = 4XL_CELL_DATE = 3XL_CELL_EMPTY = 0XL_CELL_ERROR = 5XL_CELL_NUMBER = 2XL_CELL_TEXT = 1ZIP_SIGNATURE = b'PK\x03\x04'__VERSION__ = '2.0.1'biff_text_from_num = {0: '(not BIFF)', 20: '2.0', 21: '2.1', 30: '3', ...empty_cell = empty:''error_text_from_code = {0: '#NULL!', 7: '#DIV/0!', 15: '#VALUE!', 23: ...oBOOL = 3oERR = 4oNUM = 2oREF = -1oREL = -2oSTRG = 1oUNK = 0okind_dict = {-2: 'oREL', -1: 'oREF', 0: 'oUNK', 1: 'oSTRG', 2: 'oNUM'...VERSION2.0.1FILEe:\python_workspace\pythonproject\lib\site-packages\xlrd\__init__.py3、实战案例
3-38、通过索引引用工作表
# 38、通过索引引用工作表
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook(r'E:\360Downloads\test.xls') # 替换为你的Excel文件路径
# 指定要引用的工作表的索引(从0开始)
sheet_index = 0 # 替换为你要引用的工作表的索引
# 通过索引引用工作表
try:sheet = workbook.sheet_by_index(sheet_index)# 工作表对象已成功获取,你可以在此进行后续操作print(f"引用到的工作表名称为:{sheet.name}") # 输出:引用到的工作表名称为:test1# 例如,读取第一行的数据row_values = sheet.row_values(0)print(f"第一行的数据为:{row_values}") # 输出:第一行的数据为:[45457.0, '', '', '']
except IndexError:print(f"索引 {sheet_index} 超出范围或文件未包含工作表")
# 不需要显式地将工作表或工作簿设置为None,因为Python有垃圾回收机制3-39、通过名称引用工作表
# 39、通过名称引用工作表
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook(r'E:\360Downloads\test.xls') # 替换为你的Excel文件路径
# 指定要引用的工作表的名称
sheet_name = 'test1' # 替换为你的工作表名称
# 通过名称引用工作表
try:sheet = workbook.sheet_by_name(sheet_name)# 工作表对象已成功获取,你可以在此进行后续操作print(f"引用到的工作表名称为:{sheet.name}") # 输出:引用到的工作表名称为:test1# 例如,读取第一行的数据row_values = sheet.row_values(0)print(f"第一行的数据为:{row_values}") # 输出:第一行的数据为:[45457.0, '', '', '']
except xlrd.XLRDError:print(f"未找到名为 {sheet_name} 的工作表")
# 不需要显式地将工作表或工作簿设置为None,因为Python有垃圾回收机制3-40、通过sheet_names集合引用工作表
# 40、通过sheet_names集合引用工作表
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook(r'E:\360Downloads\test.xls') # 替换为你的Excel文件路径
# 获取所有工作表的名称
sheet_names = workbook.sheet_names()
# 遍历工作表名称列表
for sheet_name in sheet_names:# 使用sheet_by_name方法获取工作表对象sheet = workbook.sheet_by_name(sheet_name)# 打印工作表名称print(f"工作表名称: {sheet_name}") # 输出:工作表名称: test1# 在这里你可以进一步处理每个工作表,比如读取数据等
# 不需要显式地将工作表或工作簿设置为None,因为Python有垃圾回收机制3-41、引用当前活动工作表
略,xlrd库不支持此功能3-42、引用第一个工作表
# 42、引用第一个工作表
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook(r'E:\360Downloads\test.xls') # 替换为你的.xls文件路径
# 获取第一个工作表
sheet = workbook.sheet_by_index(0) # 工作表索引从0开始
# 显示工作表名称(在xlrd中,我们不需要检查工作表类型,因为sheet_by_index返回的都是工作表)
print(f"当前活动工作表名称为:{sheet.name}") # 输出:当前活动工作表名称为:test1
# 不需要显式地将工作表或工作簿设置为None,因为Python有垃圾回收机制3-43、引用最后一个工作表
# 43、引用最后一个工作表
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook(r'E:\360Downloads\test.xls') # 替换为你的Excel文件路径
# 获取所有工作表的名称
sheet_names = workbook.sheet_names()
# 获取最后一个工作表的名称
last_sheet_name = sheet_names[-1]
# 通过名称获取最后一个工作表
last_sheet = workbook.sheet_by_name(last_sheet_name)
# 现在可以读取最后一个工作表中的数据了
# 例如,打印出该工作表的第一行数据
first_row_values = last_sheet.row_values(0)
print("最后一个工作表的第一行数据:", first_row_values) # 输出:最后一个工作表的第一行数据: [45457.0, '', '', '']3-44、引用所有的工作表
# 44、引用所有的工作表
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook(r'E:\360Downloads\test.xls') # 替换为你的Excel文件路径
# 获取所有工作表的名称
sheet_names = workbook.sheet_names()
# 遍历工作表名称列表
for index, sheet_name in enumerate(sheet_names):# 通过名称引用工作表(或者你也可以使用sheet_by_index(index))sheet = workbook.sheet_by_name(sheet_name)# 输出工作表的名称和第一行的数据(假设存在)print(f"工作表 {index + 1}: {sheet_name}")try:row_values = sheet.row_values(0)print(f"第一行的数据为:{row_values}")except IndexError:print(f"工作表 {sheet_name} 是空的或者没有第一行数据")# 不需要显式地将工作表或工作簿设置为None,因为Python有垃圾回收机制
# 输出:
# 工作表 1: test1
# 第一行的数据为:[45457.0, '', '', '']
# 工作表 2: test2
# 第一行的数据为:[45458.0, 'Bryce', '6岁']3-45、引用指定的多个工作表
# 45、引用指定的多个工作表
import xlrd
# 打开Excel文件
workbook = xlrd.open_workbook(r'E:\360Downloads\test.xls') # 替换为你的Excel文件路径
# 指定你想要引用的工作表名称列表
sheet_names_to_reference = ['test1', 'test2'] # 替换为你要引用的工作表名称
# 遍历工作表名称列表
for sheet_name in sheet_names_to_reference:# 检查工作表名称是否存在于工作簿中if sheet_name in workbook.sheet_names():# 通过名称引用工作表 sheet = workbook.sheet_by_name(sheet_name)# 输出工作表的名称和第一行的数据(假设存在)print(f"引用到的工作表名称为:{sheet_name}")try:row_values = sheet.row_values(0)print(f"第一行的数据为:{row_values}")except IndexError:print(f"工作表 {sheet_name} 是空的或者没有第一行数据")else:print(f"工作表 {sheet_name} 不存在于工作簿中")# 不需要显式地将工作表或工作簿设置为None,因为Python有垃圾回收机制
# 输出:
# 引用到的工作表名称为:test1
# 第一行的数据为:[45457.0, '', '', '']
# 引用到的工作表名称为:test2
# 第一行的数据为:[45458.0, 'Bryce', '6岁']3-46、引用新建的工作表
略,xlrd库无法单独实现,需结合外部其他库。3-47、引用包含特定单元格的工作表
# 47、引用包含特定单元格的工作表
import xlrd
def find_sheet_containing_cell(file_path, cell_content):# 打开 Excel 文件workbook = xlrd.open_workbook(file_path)# 遍历所有工作表for sheet in workbook.sheets():for row_idx in range(sheet.nrows):for col_idx in range(sheet.ncols):# 检查单元格内容是否匹配if sheet.cell(row_idx, col_idx).value == cell_content:print(f"Sheet '{sheet.name}' contains the cell with content '{cell_content}' at ({row_idx}, {col_idx})")return sheet.nameprint(f"No sheet contains the cell with content '{cell_content}'")return None
if __name__ == '__main__':file_path = r'E:\360Downloads\test.xls'cell_content = 'Bryce' # 替换为你要查找的单元格内容sheet_name = find_sheet_containing_cell(file_path, cell_content)if sheet_name:print(f"The sheet containing the cell is: {sheet_name}")
# 输出:
# Sheet 'test2' contains the cell with content 'Bryce' at (0, 1)
# The sheet containing the cell is: test23-48、引用工作表名称中包含特定字符串的工作表
# 48、引用工作表名称中包含特定字符串的工作表
import xlrd
def find_sheets_with_name_containing(file_path, name_substring):# 打开 Excel 文件workbook = xlrd.open_workbook(file_path)# 存储匹配的工作表名称matching_sheets = []# 遍历所有工作表for sheet in workbook.sheets():# 检查工作表名称是否包含特定字符串if name_substring in sheet.name:print(f"Sheet '{sheet.name}' contains the substring '{name_substring}'")matching_sheets.append(sheet.name)if not matching_sheets:print(f"No sheets contain the substring '{name_substring}' in their names.")return matching_sheets
if __name__ == '__main__':file_path = r'E:\360Downloads\test.xls'name_substring = 'test2' # 替换为你要查找的字符串matching_sheets = find_sheets_with_name_containing(file_path, name_substring)if matching_sheets:print(f"The sheets containing the substring are: {matching_sheets}")
# 输出:
# Sheet 'test2' contains the substring 'test2'
# The sheets containing the substring are: ['test2']五、推荐阅读
1、Python筑基之旅
2、Python函数之旅
3、Python算法之旅
4、Python魔法之旅
5、博客个人主页
相关文章:
Python酷库之旅-比翼双飞情侣库(10)
目录 一、xlrd库的由来 二、xlrd库优缺点 1、优点 1-1、支持多种Excel文件格式 1-2、高效性 1-3、开源性 1-4、简单易用 1-5、良好的兼容性 2、缺点 2-1、对.xlsx格式支持有限 2-2、功能相对单一 2-3、更新和维护频率低 2-4、依赖外部资源 三、xlrd库的版本说明 …...

2024年全国青少信息素养大赛python编程复赛集训第二天编程题分享
整理资料不容易,感谢各位大佬给个点赞和分享吧,谢谢 大家如果不想阅读前边的比赛内容介绍,可以直接跳过:拉到底部看集训题目 (一)比赛内容: 【小学组】 1.了解输入与输出的概念,掌握使用基本输入输出和简单运算 为主的标准函数; 2.掌握注释的方法; 3.掌握基本数…...

Java | Leetcode Java题解之第151题反转字符串中的单词
题目: 题解: class Solution {public String reverseWords(String s) {StringBuilder sb trimSpaces(s);// 翻转字符串reverse(sb, 0, sb.length() - 1);// 翻转每个单词reverseEachWord(sb);return sb.toString();}public StringBuilder trimSpaces(S…...

web前端教程全套:从入门到精通的全方位探索
web前端教程全套:从入门到精通的全方位探索 在数字时代的浪潮中,Web前端技术作为连接用户与数字世界的桥梁,日益受到重视。本文将围绕Web前端教程的全套内容,从四个方面、五个方面、六个方面和七个方面展开深入剖析,旨…...
什么是端口转发?路由器如何正确的设置端口转发和范围转发?(外网访问必备设置)
文章目录 📖 介绍 📖🏡 演示环境 🏡📒 端口转发 📒🚀 端口转发的应用场景💡 路由器如何设置端口转发(示例)💡 端口范围转发(示例)🎯 范围转发的应用场景🛠️ 设置范围转发📝 范围转发实操示例🎈 注意事项 🎈⚓️ 相关链接 ⚓️📖 介绍 📖 …...
【AI基础】第六步:纯天然保姆喂饭级-安装并运行qwen2-7b
整体步骤类似于 【AI基础】第五步:纯天然保姆喂饭级-安装并运行chatglm3-6b-CSDN博客。 此系列文章列表: 【AI基础】概览 【AI基础】第一步:安装python开发环境-windows篇_下载安装ai环境python 【AI基础】第一步:安装python开发环…...
基于粒子群优化算法的的微电网多目标优化调度----算法改进
前言: 当阅读过前一篇我的博客之后,并且认真去读懂了那篇文章末尾的代码,那么,后续的算法改进对于你来说应当是很容易的了。前文中提及过,粒子群在进行迭代时,每迭代一次,都会根据自己个体最优值…...
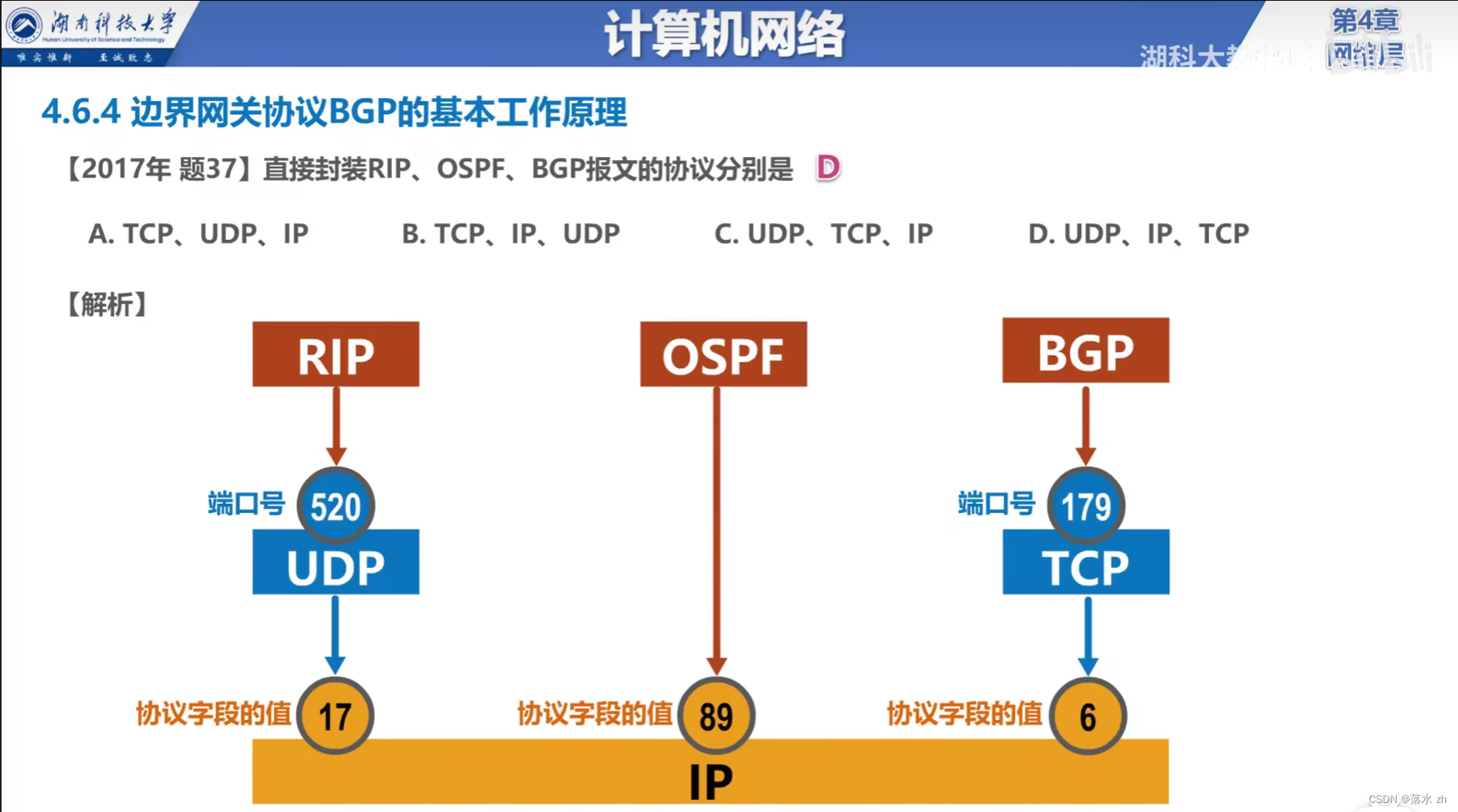
计算机网络 —— 网络层 (路由协议)
计算机网络 —— 网络层 (路由协议) 什么是路由协议内部网关协议RIP关键特性 OSPF主要特点 外部网关协议BGP关键特性 我们今天来看路由协议: 什么是路由协议 路由协议是网络设备(主要是路由器)用来决定数据包在网络中…...
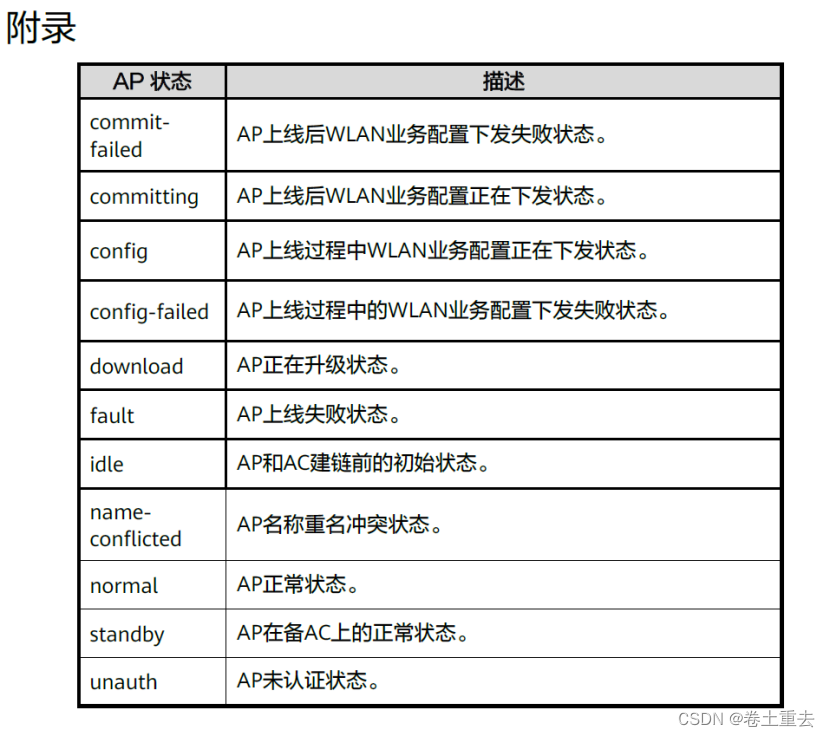
HCIA 15 AC+FIT AP结构WLAN基础网络
本例配置ACFIT,即瘦APAC组网。生活中家庭上网路由器是胖AP,相当于ACFIT二合一集成到一个设备上。 1.实验介绍及拓扑 某企业网络需要用户通过 WLAN 接入网络,以满足移动办公的最基本需求。 1. AC 采用旁挂核心组网方式,AC 与AP …...

给Windows软件添加异常捕获模块生成dump文件(附源码)
软件在运行过程中会时常发生内存越界、内存访问为例、stack overflow线程栈溢出、空指针与野指针等异常崩溃,仅仅是依靠Debug和Release下的调试是远远不够的,因为有些崩溃不是必现的,或者是Debug下很难出现的。所以我们需要在软件中添加异常捕获的模块,在捕获到异常时生成包…...
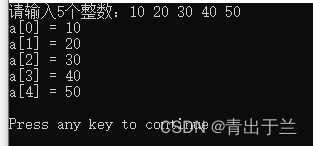
C语言| 数组
直接定义一个数组,并给所有元素赋值。 数组的下标从0开始,下标又表示数组的长度。 【程序代码】 #include <stdio.h> int main(void) { int a[5] {1, 2, 3, 4, 5}; int i; for(i0; i<5; i) { printf("a[%d] %d\…...
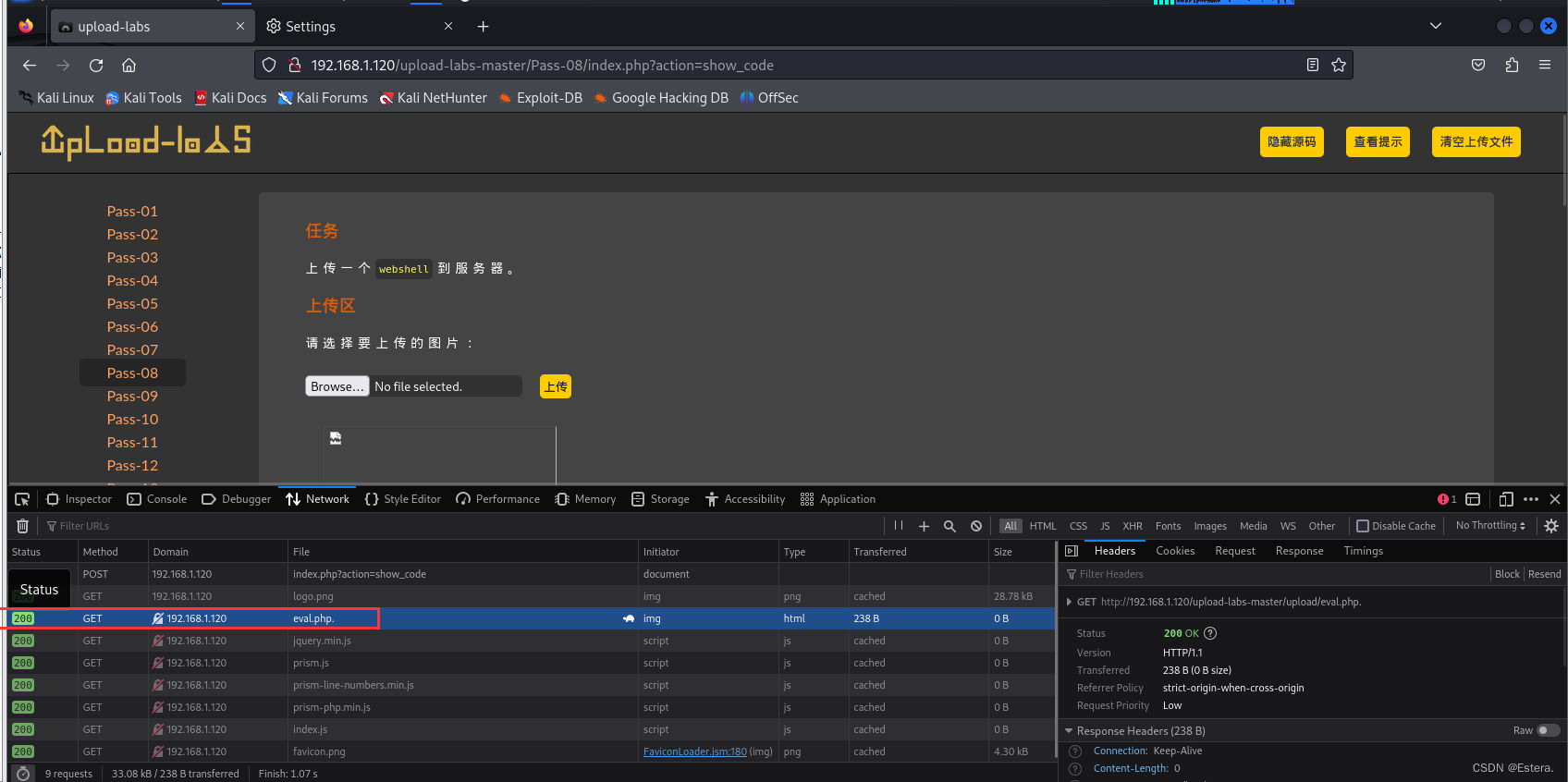
upload-labs第八关教程
upload-labs第八关教程 一、源代码分析代码审计 二、绕过分析点绕过上传eval.php使用burp suite进行抓包修改放包,查看是否上传成功使用中国蚁剑进行连接 一、源代码分析 代码审计 $is_upload false; $msg null; if (isset($_POST[submit])) {if (file_exists(U…...

平板消解加热台-温度均匀,防腐蚀-实验室化学分析
DBF系列防腐电热板 是精致路合金加热板块表面经进口高纯实验级PFATeflon氟塑料防腐不粘处理,专为实验室设计的电加热产品,是样品前处理中,加热、消解、煮沸、蒸酸、赶酸等处理的得力助手。可以满足物理、化学、生物、环保、制药、食品、饮品…...
Ubuntu基础-vim编辑器
目录 前言: 一. 安装 二. 配置 三. 基本使用 1.使用 Vim 编辑文本文件 2.代码编辑 3.多窗口编辑 四. 总结 前言: Vim 是从 VI 发展出来的一个文本编辑器,具有代码补充、错误跳转等功能,在程序员中被广泛使用。它的设计理念是命令的组合ÿ…...

Java 网站开发入门指南:如何用java写一个网站
Java 网站开发入门指南:如何用java写一个网站 Java 作为一门强大的编程语言,在网站开发领域也占据着重要地位。虽然现在 Python、JavaScript 等语言在网站开发中越来越流行,但 Java 凭借其稳定性、可扩展性和丰富的生态系统,仍然…...

Armbian OS(基于ubuntu24) 源码编译mysql 5.7
最近弄了个S905X3的盒子刷完Armbian OS (基于ubuntu24),开始折腾Arm64之旅。第一站就遇到了MySQL的问题,由于MySQL没有提供Arm64版本,又不想塞Docker镜像,因此选择源码来编译MySQL5.7。下面记录详细过程和遇…...
React+TS前台项目实战(六)-- 全局常用组件Button封装
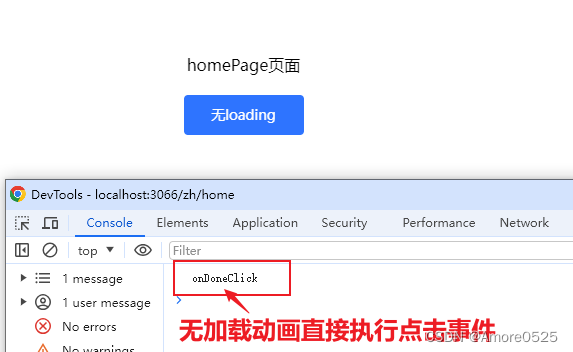
文章目录 前言Button组件1. 功能分析2. 代码注释说明3. 使用方式4. 效果展示(1)有加载动画,执行promise函数(2)无加载动画,执行click事件 总结 前言 今天这篇主要讲全局按钮组件封装,可根据UI设…...

Vite支持的React项目使用SASS指南
前言 在现代前端开发中,SASS是一种广受欢迎的CSS扩展语言,它提供了许多实用功能,如变量、嵌套、部分和混合等。 本教程将指导您在一个使用Vite作为构建工具的React项目中如何配置和使用SASS。 使用步骤 1、创建一个Vite React项目 首先确…...
实验12 路由重分布
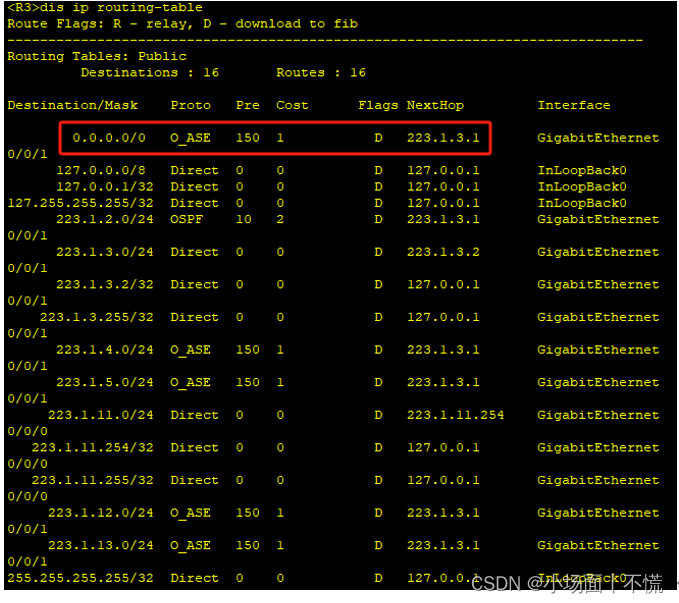
实验12 路由重分布 一、 原理描述二、 实验目的三、 实验内容四、 实验配置五、 实验步骤 一、 原理描述 在大型网络的组建过程中,隶属不同机构的网络部分往往会根据自身的实际情况来选用路由协议。例如,有些网络规模很小,为了管理简单&…...

version-manager最好用的SDK版本管理器,v0.6.2发布
项目地址:https://github.com/gvcgo/version-manager 中文文档:https://gvcgo.github.io/vdocs/#/zh-cn/introduction 功能特点: 跨平台,支持Windows,Linux,MacOS支持多种语言和工具,省心受到…...

生成xcframework
打包 XCFramework 的方法 XCFramework 是苹果推出的一种多平台二进制分发格式,可以包含多个架构和平台的代码。打包 XCFramework 通常用于分发库或框架。 使用 Xcode 命令行工具打包 通过 xcodebuild 命令可以打包 XCFramework。确保项目已经配置好需要支持的平台…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...
篇章二 论坛系统——系统设计
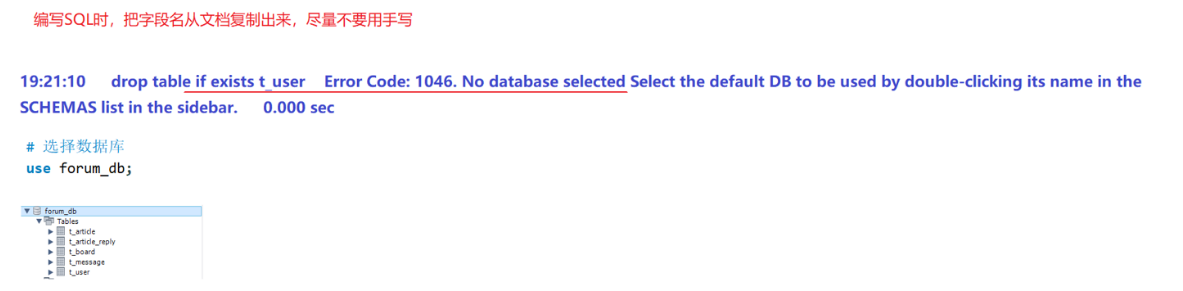
目录 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 1. 数据库设计 1.1 数据库名: forum db 1.2 表的设计 1.3 编写SQL 2.系统设计 2.1 技术选型 2.2 设计数据库结构 2.2.1 数据库实体 通过需求分析获得概念类并结合业务实现过程中的技术需要&#x…...
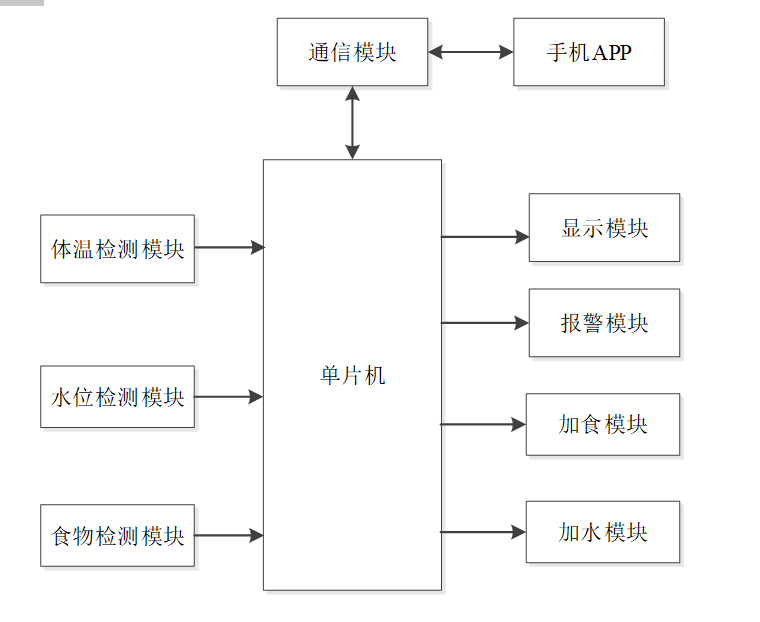
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...
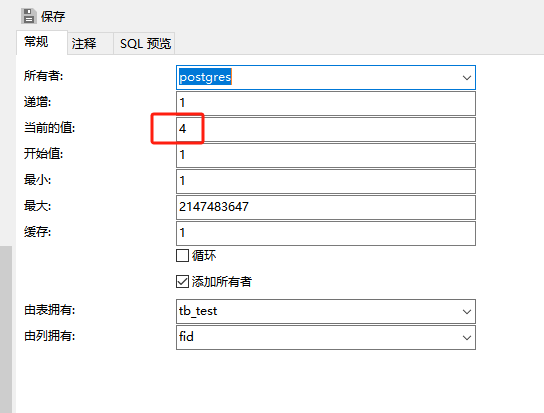
pgsql:还原数据库后出现重复序列导致“more than one owned sequence found“报错问题的解决
问题: pgsql数据库通过备份数据库文件进行还原时,如果表中有自增序列,还原后可能会出现重复的序列,此时若向表中插入新行时会出现“more than one owned sequence found”的报错提示。 点击菜单“其它”-》“序列”,…...