Python re 模块
正则表达式是一种小型、高度专业化的编程语言。适用于任何语言,在 Python 中通过 re 模块实现。正则模式被编译成一系列的字节码,然后由 C 语言编写的匹配引擎执行。给字符串模糊匹配
正则用于匹配字符串,匹配字符串可以完全匹配和模糊匹配:
- **完全匹配:**普通字符,大多数字符和字母都和自身匹配
re.findall('rose', 'lialrosetom') - **模糊匹配:**元字符,不需要完全匹配即能匹配成功
. ^ $ * + ? { } [ ] | ( ) \
元字符
正则可以使用普通字符进行完全匹配,也可以使用元字符进行模糊匹配。正则表达式中所有元字符: . ^ $ * + ? { } [ ] | ( ) \ 。
通配符
正则中用一个点(.)来表示通配符,它可以匹配除换行符(\n)以外任何字符。一个点只能匹配一个字符
>>> re.findall('s..x', 'abshuxijd')
['shux']
开头结尾
正则中尖角号(^)用于匹配一行字符串的开头,($)用于匹配一行字符串的结尾。必须以匹配对象开头或结尾才能匹配成功,否则匹配失败。
>>> re.findall(r'^hello,\d+','hello,123')
['hello,123']
>>> re.findall(r'^hello,\d+','hi hello,123')
[]
>>> re.findall(r'hello,\d+$','hello,123')
['hello,123']
>>> re.findall(r'hello,\d+$','hello,123s')
[]
重复匹配
不管是点(.),还是数字匹配(\d)都只能匹配一个字符或数字。要想匹配多个就要进行重复匹配,正则中能够重复匹配的元字符有:* + ? {}。
| 元字符 | 描述 | 元字符 | 描述 |
|---|---|---|---|
| * | 对星号前面的子表达式匹配重复 [0, ∞] 次 | + | 对加号前面的子表达式匹配重复 [1, ∞] 次 |
| ? | 对问号前面的子表达式匹配重复 [0,1] 次,非贪婪模式 | {n} | 精确匹配 n 个前子表达式 |
**星号 ***
星号(*)可以对它前面的子表达式重复 0 次 或多次。
# 对 abc 的 c 重复 0 到多次,即可匹配 ab、abc、abcc、abc...
>>> re.findall(r'abc*','ab456abc123abccc')
['ab', 'abc', 'abccc']
加号 +
加号(+)可以对它前面的子表达式重复 1 次或多次。
>>> re.findall(r'abc+','ab456abc123abccc') # 即至少有有一个 c
['abc', 'abccc']
问号 ?
问号(?)可以对它前面的子表达式重复 0 次或 1 次。
>>> re.findall(r'abc?','ab456abc123abccc')
['ab', 'abc', 'abc']
大括号 {}
大括号({})可以对它前面的子表达式精确重复几次,它有多重模式:
{n}:对它前面的子表达式至少重复 n 次{m, n}:对它前面的子表达式重复 m 到 n 次{0, ∞}:相当于星号(*){1, ∞}:相当于加号(+){0, 1}:相当于问号(?)
>>> re.findall(r'abc{3}','ab456abc123abccc') # c 重复 3 次,匹配到 abccc
['abccc']
>>> re.findall(r'abc{1,3}','ab456abc123abccc') # 匹配 abc、abccc
['abc', 'abccc']
>>> re.findall(r'abc{1,3}','abc456abcc123abccc')
['abc', 'abcc', 'abccc']
管道符
管道符(|)表示或,a|b 表示 a 或 b。
>>> re.findall(r'a|b', 'abc')
['a', 'b']
>>> re.findall(r'ka|b', 'kahbc')
['ka', 'b']
>>> re.findall(r'ka|b', 'kahc')
['ka']
>>> re.findall(r'ka|b', 'ka|bhc')
['ka', 'b']
字符集
在正则表达式中,中括号([ ] )表示一个字符集,它用来表示一组字符。字符集中除 - ^ \ 有特殊意义外,其他元字符都是普通字符。
[mm]:匹配 m 或 n[^mn]:匹配除 m、n 以外的所有字符
>>> re.findall(r'abc[de]','abcd123abce567')
['abcd', 'abce']
>>> re.findall(r'[^de]+','abcd123abce567')
['abc', '123abc', '567']
横杠 -
字符集中横杠(-)用来表示范围,[a-z] 表示 a - z 任意一个字母。
>>> re.findall(r'b[a-z]', 'bs')
['bs']
>>> re.findall(r'[1-9]','12ab45')
['1', '2', '4', '5']
>>> re.findall(r'[1-9]+','12ab45')
['12', '45']
>>> re.findall(r'[A-Za-z0-9]+','12abCD45')
['12abCD45']>>> re.findall(r'\d+@[A-Za-z0-9]+\.[a-z]+','982561639@qq.com')
['982561639@qq.com']
尖角号 ^
尖角号(^)表示非,[^\d] 除数字以外。
>>> re.findall(r'[^\d]+','abc123def')
['abc', 'def']
>>> re.findall('b[^a-z]*', 'bs213') # s 没有匹配上,匹配停止
['b']
转义字符 \
反斜杠(\)表示对某个字符转义,可以把普通字符变成特殊字符,如:\d
>>> re.findall(r'[\d]+','abc123def456')
['123', '456']
转义字符
转义字符在元字符中是一个比较特殊的存在,在字符集里面、外面都有特殊意义。
- 反斜杠后面跟元字符去除特殊功能,如:
\.,其中这个点变成了普通的点 - 反斜杠后面跟普通字符实现特殊功能,如:
\d,匹配任何十进制数
转义字符 + 普通字符 = 特殊字符
| \d | 匹配任意十进制数,相当于 [0-9] |
|---|---|
| \D | 匹配任何非数字字符,相当于 [^0-9] |
| \s | 匹配任意空白字符,相当于 [\t\n\r\f\v] |
| \S | 匹配任意非空白字符,相当于 [^\t\n\r\f\v] |
| \w | 匹配任意字母数字字符,相当于 [a-zA-Z0-9_] |
| \W | 匹配任意非字母数字字符,相当于 [^a-zA-Z0-9_] |
| \b | 匹配任意一个特殊字符边界,如:空格、&、# 等 |
\b 在 Python 中本身是有特殊意义的,在匹配时,需要给它转义,或者加上原生字符串 r :
>>> re.findall(r'abc\b','abc123') # \b 匹配的是特殊字符边界,abc 后面没有空格,匹配失败
[]
>>> re.findall('abc\\b','abc 123') # abc 后面有空格,匹配成功
['abc']
>>> re.findall(r'abc\b','abc 123')
['abc']
>>> re.findall(r'abc\b','abc#123')
['abc']
给其他字符加上转义字符时:
import re
>>> re.findall('c\l','abc\le')
[]
>>> re.findall('c\\l','abc\le')
[]
>>> re.findall('c\\\\l','abc\le')
['c\\l']
>>> re.findall(r'c\\l','abc\le')
['c\\l']
\w 和 \s 用法示例:
>>> re.findall(r'\w', '12shdk34_') # 匹配数字字母以及下划线,加上+,匹配多个
['1', '2', 's', 'h', 'd', 'k', '3', '4', '_']
>>> re.findall(r'\w+', '12shdk34_')
['12shdk34_']>>> re.findall(r'\s+', '12 shdk 34_') # 匹配空白字符
[' ', ' ']
**Tips:**在使用正则的时候,尽量带上原生字符串 r,可以避免不必要的麻烦。
转义字符 + 元字符 = 普通字符
给元字符加上转义字符,元字符就失去了原有的意义,变成了一个普通字符。
>>> re.findall(r'www*', 'www*')
['www']
>>> re.findall(r'www\*', 'www*') # 要想把 * 也匹配上,就要给 * 转义
['www*']
贪婪与非贪婪
关于重复匹配,正则表达式默认是按照贪婪匹配的方式去匹配,即在符合条件的情况下,尽可能多的去匹配。而非贪婪匹配恰好与之相反。
贪婪匹配:
>>> re.findall(r'abc*','abc123abcc') # 尽可能多的匹配(* 的范围是 0 或 多次,它取了 多 次)
['abc', 'abcc']
>>> re.findall(r'<.+>','<html><title>Hello World</title></html>')
['<html><title>Hello World</title></html>']启用非贪婪模式,只需在表示重复的元字符后面加上一个问号(?)即可:
>>> re.findall(r'abc*?','abc123abcc') # 尽可能少的匹配(* 的范围是 0 或 多次,它取了 0 次)
['ab', 'ab']
>>> re.findall(r'<.+?>','<html><title>Hello World</title></html>')
['<html>', '<title>', '</title>', '</html>']
在贪婪匹配下,(.*)会尽可能多的匹配字符,因此它把 123456 匹配了,只留下了一个 7 给 \d+,最后得到的内容是 7 :
>>> content = 'Hello 1234567 World_This a Regex Demo'
>>> pattern = re.compile(r'^He.*(\d+).*Demo$')
>>> re.findall(pattern,content)
['7']
有时贪婪匹配匹配的结果并不是我们想要的那样,给我们带来了很大不便,这时我们就要使用非贪婪匹配比较合适:
>>> pattern = re.compile(r'^He.*?(\d+).*Demo$')
>>> re.findall(pattern,content)
['1234567']
修饰符
正则可以包含一些可选标志修饰符来控制匹配模式,修饰符被指定为一个可选的标志。
我们知道点(.)可以匹配除换行符以外的所有字符,但是当遇到换行时,就会引发匹配失败:
import re
content = """Hello 1234567 World_This
is a Regex Demo"""
result = re.match(r'^He.*?(\d+).*?Demo$',content)
print(result.group(1))
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-2-bd9088917b1a> in <module>()3 is a Regex Demo"""4 result = re.match(r'^He.*?(\d+).*?Demo$',content)
----> 5 print(result.group(1))AttributeError: 'NoneType' object has no attribute 'group'
之所以会报没有 group 方法,是因为我们使用了点(.)匹配任意字符,但是不能匹配换行符,也就匹配失败。而我们又调用了 group 方法,针对这种情况,我们只需在 match 方法最后添加一个 re.S 的修饰符即可,以便使点(.)能匹配换行:
result = re.match(r'^He.*?(\d+).*?Demo$',content,re.S)1234567
分组
分组优先匹配组里面的内容,也只显示括号里面的。要想全部显示可以在括号前面加上(?:),进行去优先级:
>>> re.findall('www\.(baidu|163)\.com', 'www.baidu.com')
['baidu']# 在分组前面加上 ?: 表示去组的优先级
>>> re.findall('www\.(?:baidu|163)\.com', 'www.baidu.com')
['www.baidu.com']>>> re.findall('(abc)+', 'abcabcabc')
['abc']
>>> re.findall('(?:abc)+', 'abcabcabc')
['abcabcabc']
分组后的结果通过 group() 方法即可取到:
>>> re.match(r'^th.*?(\d+).*?(\d+)','this is 123456 regex 567')
<_sre.SRE_Match object; span=(0, 24), match='this is 123456 regex 567'>
>>> re.match(r'^th.*?(\d+).*?(\d+)','this is 123456 regex 567').group()
'this is 123456 regex 567'
>>> re.match(r'^th.*?(\d+).*?(\d+)','this is 123456 regex 567').group(1)
'123456'
>>> re.match(r'^th.*?(\d+).*?(\d+)','this is 123456 regex 567').group(2)
'567'
另一种分组方式,?P<组名>,通过组名取值,当匹配的结果有很多时,可以这样取值 :
# 另一种分组方式,?P<组名> ,通过组名取值,当匹配的结果有很多时,可以这样取值
>>> re.search("(?P<name>[a-z]+)", "rose18john20tom22")
<_sre.SRE_Match object; span=(0, 4), match='rose'>
>>> re.search("(?P<name>[a-z]+)", "rose18john20tom22").group()
'rose'>>> re.search("(?P<name>[a-z]+)", "rose18john20tom22").group('name') # 名字分组为 name 'rose'
>>> re.search("(?P<name>[a-z]+)(?P<age>\d+)", "rose18john20tom22").group('age') # 名字分组为 age '18'
re 模块常用方法
match 方法
match(patter, string, flags=0) 方法从字符串开始位置匹配,如果匹配成功则返回匹配位置以及 match 对象,否则返回 None。
第一个参数为正则表达式,第二个参数为待匹配的字符串。
>>> re.match('\d', 'rose56')
>>> re.match('\d', '12rose56')
<_sre.SRE_Match object; span=(0, 1), match='1'>
>>> re.match('\d', '12rose56').group()
'1'
search 方法
search(pattern, string, flags=0)方法扫描整个字符串,搜索正则表达式模式匹配的第一个位置,并返回 match 对象。如果没有与之匹配的,则返回 None。正则表达式模式即为匹配规则,需要用原生字符串来写,避免不必要的麻烦。
第一个参数为正则表达式,第二个参数为待匹配的字符串。
>>> re.search(r'abc', 'abc123abc')
<_sre.SRE_Match object; span=(0, 3), match='abc'> # 返回第一个匹配结果的位置,以及 match 对象
使用 group() 方法可以拿到匹配结果:
>>> result = re.search(r'abc', 'abc123abc')
>>> result.group()
'abc'
使用 span() 方法可以拿到匹配结果范围:
>>> result = re.search(r'abc', 'abc123abc')
>>> result.span()
(0, 3)
split 方法
split(pattern, string, maxsplit=0, flags=0)分割字符串,返回结果存储到列表中,maxsplit 为早打分割次数。
>>> re.split(' ', 'hi hello six') # 按空格分
['hi', 'hello', 'six']
>>> re.split('[ |]', 'hi hello|six') # 按空格或 | 分
['hi', 'hello', 'six']
>>> re.split('[ab]', 'abc') # 先按 a 分(a的左边为空,因此分为 '' 和 'bc'),再按 b 分(b 的左边为空,因此分为 '' 和 'c'
['', '', 'c']
sub 方法
sub(pattern, repl, string, count=0, flags=0) 方法替换原字符串某个文本,第一个参数为正则,第二个为替换成的字符串,第三个为原字符串,第四个为替换次数。并返回替换后的字符串。
>>> re.sub(r'\d+', 'A', 'abcd12df45')
'abcdAdfA'
>>> re.sub(r'\d+', 'A', 'abcd12df45', 1)
'abcdAdf45'
subn() 方法可以返回替换次数:
>>> re.subn(r'\d+', 'A', 'abcd12df45')
('abcdAdfA', 2)
compile 方法
前面我们都是直接在 re 方法中使用正则,re 模块提供了一个 compile() 方法可以将正则编译成正则对象,以便匹配规则可以重复使用。
pattern = re.compile(r'\d+')
其他方式直接传入正则对象即可:
>>> content = '2018-11-17 17:18'
>>> pattern = re.compile(r'\d{2}:\d{2}')
>>> result = re.findall(pattern,content)
>>> result
['17:18']
finditer 方法
finditer(pattern, string, flags=0) 方法与 findall() 方法类似 ,不同的是前者将匹配结果封装成一个迭代器,而后者将全部匹配结果存为一个列表。
>>> ret = re.finditer('\d+', 'ss123dd456')
>>> next(ret).group()
'123'
findall 方法
search() 方法返回匹配结果的第一个内容,要想获得所有匹配内容。就需要借助 findall(pattern, string, flags=0) 方法,它会搜索整个字符串,并将匹配结果存到一个列表中。若没有匹配成功,则返回一个空列表。
>>> re.findall(r'\d+','12so45ch')
['12', '45']
相关文章:

Python re 模块
正则表达式是一种小型、高度专业化的编程语言。适用于任何语言,在 Python 中通过 re 模块实现。正则模式被编译成一系列的字节码,然后由 C 语言编写的匹配引擎执行。给字符串模糊匹配 正则用于匹配字符串,匹配字符串可以完全匹配和模糊匹配&…...

为什么越来越多的人开始学习大数据
因为根据国内的发展形势,大数据未来的发展前景会非常好,前景好需求高,自然会吸引越来越多的人进入大数据行业 我国市场环境处于急需大数据人才但人才不足的阶段,所以未来大数据领域会有很多的就业机遇。 2022年春季,…...
---引用)
【C++】C++核心编程(二)---引用
1.基本语法 作用:给变量起别名 语法:数据类型 &别名 原名(int &b a,其中别名与原名的数据类型必须一致) 注意事项: 引用必须初始化引用在初始化后,就不可以再改变了 代码演示&am…...

原型设计模式
介绍 原型模式 在Java中,原型模式是一种创建型设计模式,它允许通过复制一个现有对象来创建一个新对象,而不是通过创建新的对象来初始化一个对象,原型模式是一种基于克隆的设计模式,通过复制现有对象的数据来创建新的对象. 原型模式需要实现Cloneable接口并重写Object类中的c…...
JVM结构-类加载(类加载子系统,类加载的角色,类加载的过程,类加载器分类,双亲委派机制,类的主/被动使用)
JVM 结构-类加载2.1类加载子系统2.2类加载的角色2.3类加载的过程2.3.1加载2.3.2链接2.3.3初始化2.4类加载器分类2.4.1 引导类加载器2.4.2扩展类加载器2.4.3应用程序类加载器2.5双亲委派机制2.6类的主动/被动使用2.1类加载子系统 类加载器子系统负责从文件系统或者网络中加载 cl…...

vcpkg私有port的创建和使用
1,准备环境: 系统:windows 系统 2, 安装vcpkg 步骤一 :先git clone下载下来vcpkg文件夹 命令:git clone “https://github.com/Microsoft/vcpkg.git” 步骤二:添加vcpkg环境变量 例如下载目录:D:\woker_zj 步骤三:编译vcpkg 操作:双击bootstrap-vcpkg.bat 步骤四: 为…...
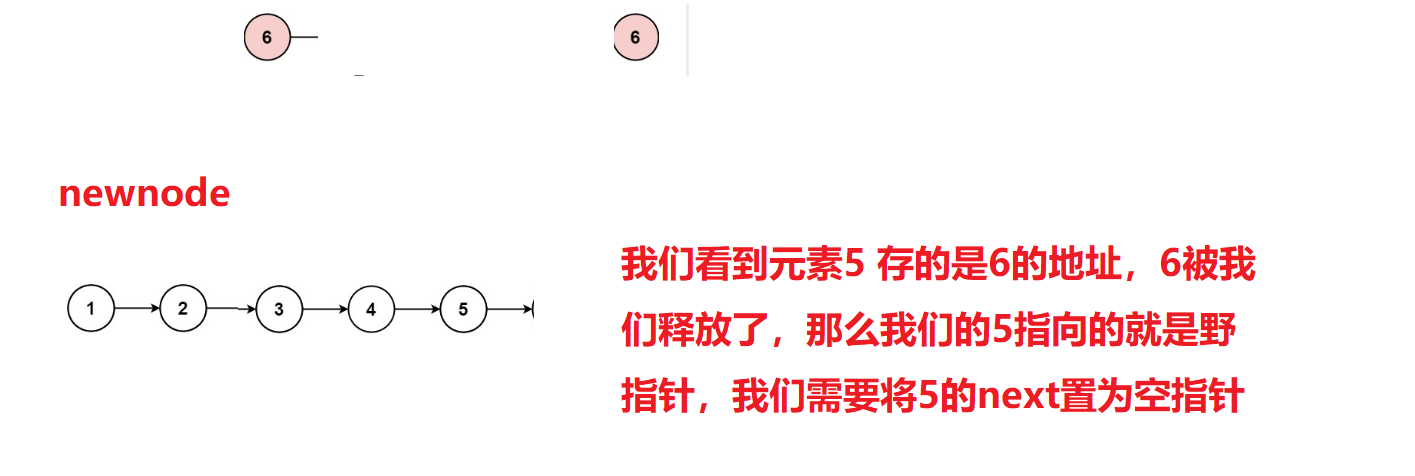
LeetCode——203. 移除链表元素
对于初学链表的学者来学,链表是比较困难的,这部分对指针结构体的要求比较高。我们通过练习是掌握知识的重要途经203. 移除链表元素 - 力扣(LeetCode)我们在数组中去除某元素是遍历一遍数组,如果某位置是要去除的元素&a…...
[Java Web]Request对象 | 超1w字带你熟悉Servlet中的request请求
⭐作者介绍:大二本科网络工程专业在读,持续学习Java,输出优质文章 ⭐所属专栏:Java Web ⭐如果觉得文章写的不错,欢迎点个关注😉有写的不好的地方也欢迎指正,一同进步😁 目录 Reque…...

求一个补码表示数的原始值的三种方式
求一个补码表示数的原始值的三种方式假设 a(10010)2′complement−14a (10010)_{2complement}-14a(10010)2′complement−14 方式1,通过补码求原始值公式求值(see article) x−xM−1∗2M−1∑i0M−2xi∗2ix-x_{M-1}*2^{M-1}\sum_{i0}^{M-2…...

【计算机组成原理】
第2章 运算方法和运算器 2.1 数据与文字的表示方法 2.1.1 数据格式 定点数的表示方法 定点纯小数纯小数表示范围定点纯整数定点表示法特点 浮点数的表示方法: 浮点的规格化表示:阶码、尾数、指数、基数IEEE754标准:单精度、双精度浮点数表…...

论文分享:图像识别与隐私安全
1、基于差分隐私框架的频域下人脸识别隐私保护算法Privacy-Preserving Face Recognition with Learnable Privacy Budget in Frequency Domain2、一种基于视觉密码学和可信计算的无密钥依赖的医学图像安全隐私保护框架A Privacy Protection Framework for Medical Image Securi…...

计算机基础小结
目录 ❤ 计算机基础编程 什么是编程语言? 什么是编程? 为什么要学习编程? ❤ 计算机组成原理 控制器 运算器 储存器 内存(主存) 外存 输入设备 输出设备 适配器 总线 机械硬盘 固态硬盘 ❤ 计算机操作系统 什么是操作系统? 什么是文件? 什么是应…...
Linux服务器还有漏洞?建议使用 OpenVAS 日常检查!
几乎每天都会有新的系统漏洞产生,系统管理员经常忙于管理服务器,有时候会忽略一些很明显的安全问题。扫描 Linux 服务器以查找安全问题并不是很简单的事情,所以有时候需要借助于一些专门的工具。 OpenVAS 就是这样一种开源工具,它…...
【Redis】P1 Redis - NoSQL
Redis - NoSQLSQL 与 NoSQL差别一:结构化 与 非结构化差别二:关联性 与 非关联性差别三:规范化查询语句 与 非规范化差别四:事务 与 无事务差别五:磁盘存储 与 内存存储RedisRedis 的安装当前数据库存储主要分为 关系型…...
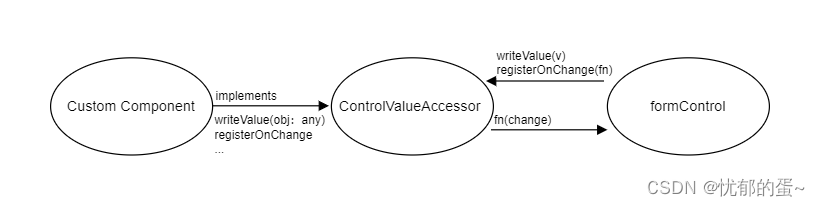
Angular学习之ControlValueAccessor接口详解
ControlValueAccessor 是什么?为什么需要使用 ?下面本篇文章就来带大家了解Angular中的ControlValueAccessor组件接口,希望对大家有所帮助! ControlValueAccessor 是什么? 简单来说ControlValueAccessor是一个接口&am…...

【GORM】高级查询方案
【GORM】高级查询方案1.Struct & Map查询为空的情况2.FirstOrInit3.FirstOrCreate4.高级查询1.Struct & Map查询为空的情况 当通过结构体进行查询时,GORM将会只通过非零值字段查询,这意味着如果你的字段值为0,‘’,false…...

MFC 简单使用事件
功能三个按钮,一个静态框,默认值是0,增加减少按钮和退出按钮.增加减少按钮显示在静态框中.退出按钮退出软件.实验事件思路新建三个事件,add事件sub事件quit事件,一个按钮触发一个事件,静态框新建一个线程接受事件做出对应的改变.UI添加的代码就不具体说,具体说下事件的代码,这才…...
| 机考必刷)
华为OD机试题 - 端口合并(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:端口合并题目输入输出示例一输入输出说明示例二输入输出说明示例…...
ECharts数据可视化--常用图表类型
目录 一.柱状图 1.基本柱状图 1.1最简单的柱状图 编辑 1.2多系列柱状图 1.3柱状图的样式 (1)柱条样式 (2)柱条的宽度和高度 (3)柱条间距 (4)为柱条添加背景颜色 编辑 2.堆…...
Flutter面试题解析-GridView详解与应用
一、前言Flutter 作为时下最流行的技术之一,凭借其出色的性能以及抹平多端的差异优势,早已引起大批技术爱好者的关注,甚至一些 闲鱼 , 美团 , 腾讯 等大公司均已投入生产使用。虽然目前其生态还没有完全成熟࿰…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

代码规范和架构【立芯理论一】(2025.06.08)
1、代码规范的目标 代码简洁精炼、美观,可持续性好高效率高复用,可移植性好高内聚,低耦合没有冗余规范性,代码有规可循,可以看出自己当时的思考过程特殊排版,特殊语法,特殊指令,必须…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...
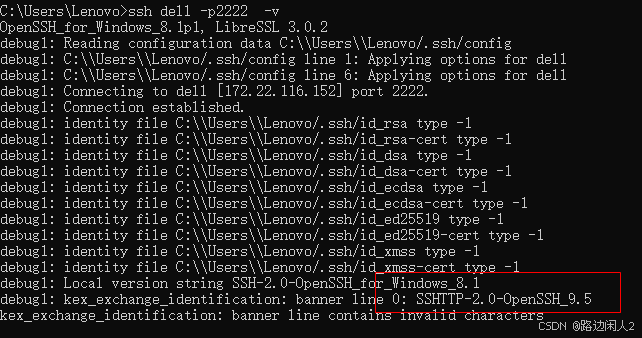
sshd代码修改banner
sshd服务连接之后会收到字符串: SSH-2.0-OpenSSH_9.5 容易被hacker识别此服务为sshd服务。 是否可以通过修改此banner达到让人无法识别此服务的目的呢? 不能。因为这是写的SSH的协议中的。 也就是协议规定了banner必须这么写。 SSH- 开头,…...
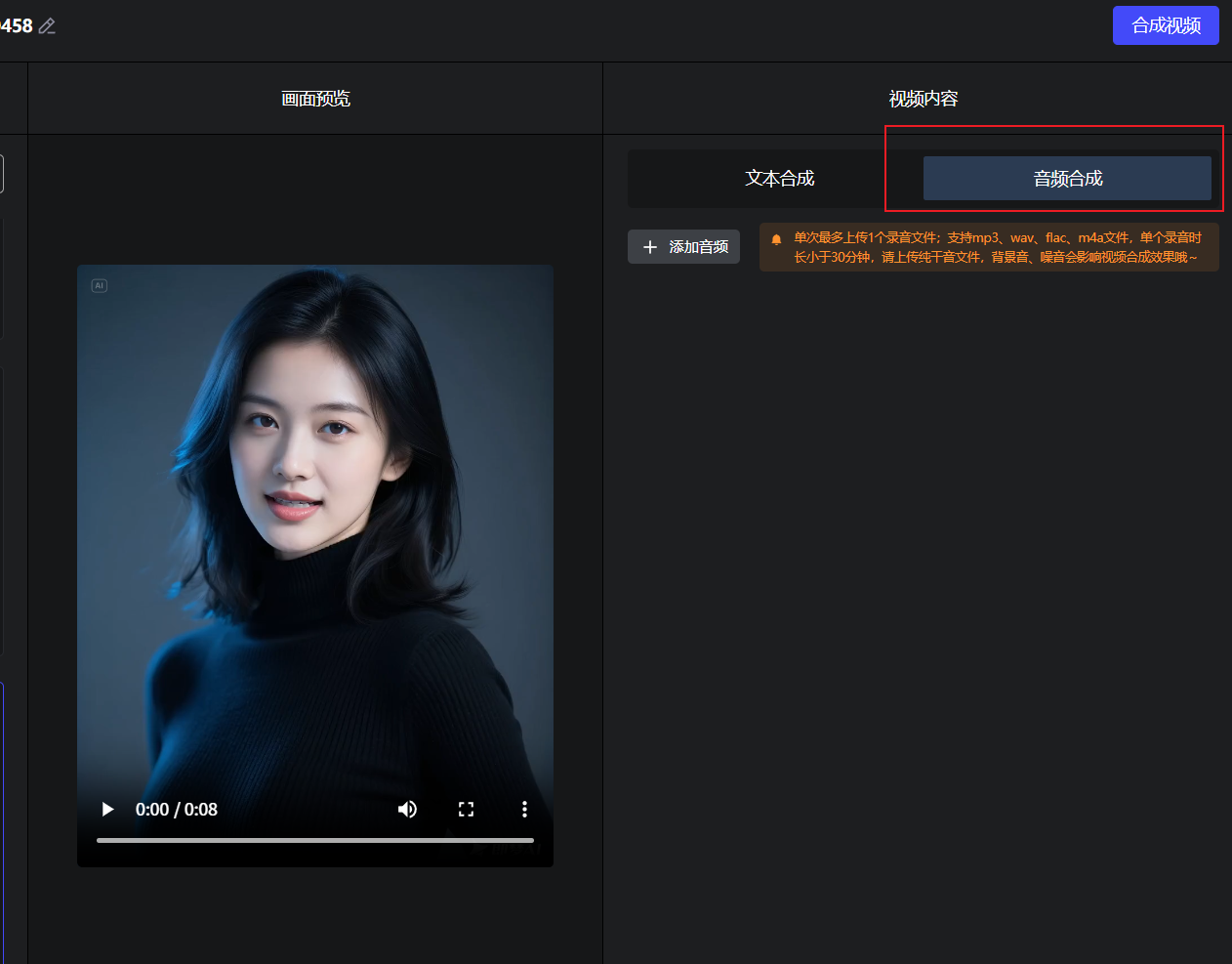
Heygem50系显卡合成的视频声音杂音模糊解决方案
如果你在使用50系显卡有杂音的情况,可能还是官方适配问题,可以使用以下方案进行解决: 方案一:剪映替换音色(简单适合普通玩家) 使用剪映换音色即可,口型还是对上的,没有剪映vip的&…...