机器学习归一化特征编码

特征缩放
因为对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1——10,第二个特征的取值范围为1——10000。在梯度下降算法中,代价函数为最小平方误差函数,所以在使用梯度下降算法的时候,算法会明显的偏向于第二个特征,因为它的取值范围更大。在比如,k近邻算法,它使用的是欧式距离,也会导致其偏向于第二个特征。对于决策树和随机森林以及XGboost算法而言,特征缩放对于它们没有什么影响。
常用的特征缩放算法有两种,归一化(normalization)和标准化(standardization)。归一化算法是通过特征的最大最小值将特征缩放到[0,1]区间范围
归一化(Normalization)
归一化是利用特征的最大最小值,为了方便数据处理,将特征的值缩放到[0,1]区间,对于每一列的特征使用min-max函数进行缩放,可以使处理过程更加便捷、快速,计算。
特征归一化的优势
- 提升收敛速度 :对于线性model来说,数据归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
造成图像的等高线为类似椭圆形状,最优解的寻优过程图像如下:
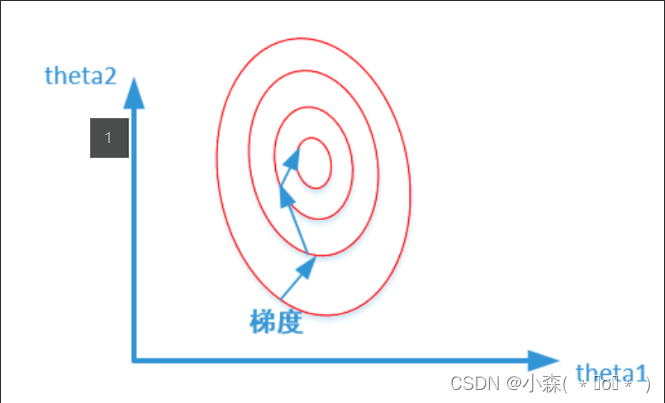
两个特征区别相差特别大。所形成的等高线比较尖锐。当时用梯度下降法时,很可能要垂直等高线走,需要很多次迭代才能收敛。
而数据归一化之后,损失函数的表达式可以表示为:
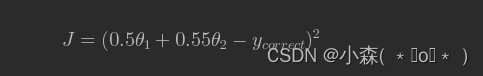
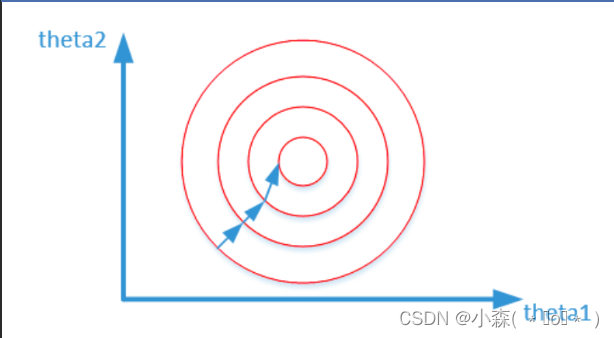
其中变量的前面系数几乎一样,则图像的等高线为类似圆形形状,最优解的寻优过程图像如下:
-
对两个原始特征进行了归一化处理,其对应的等高线相对来说比较圆,在梯度下降时,可以较快的收敛。 - 提升模型精度:如果我们选用的距离度量为欧式距离,如果数据预先没有经过归一化,那么那些绝对值大的features在欧式距离计算的时候起了决定性作用。 从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
特征归一化方法MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
x=[[10001,2],[16020,4],[12008,6],[13131,8]]
min_max_scaler = MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(x)#归一化后的结果
X_train_minmax# 它默认将每种特征的值都归一化到[0,1]之间MinMaxScaler的实现
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min这是向量化的表达方式,说明X是矩阵,其中
- X_std:将X归一化到[0,1]之间
- X.min(axis=0)表示列最小值
- max,min表示MinMaxScaler的参数feature_range参数。即最终结果的大小范围
以下例说明计算过程(max=1,min=0)
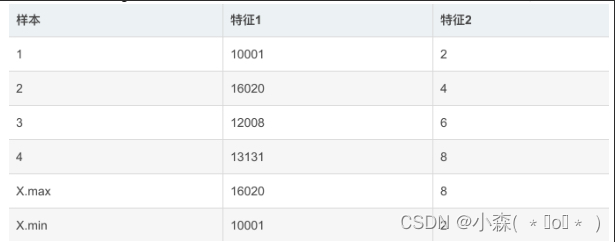
S11=(10001-10001)/(16020-10001)=0
S21=(16020-10001)/(16020-10001)=1
S31=(12008-10001)/(16020-10001)=0.333444
S41=(13131-10001)/(16020-10001)=0.52002
S12=(2-2)/(8-2)=0
S22=(4-2)/(8-2)=0.33
S32=(6-2)/(8-2)=0.6667
S42=(8-2)/(8-2)=1数据的标准化
和0-1标准化不同,Z-score标准化利用原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。同样是逐列进行操作,每一条数据都减去当前列的均值再除以当前列的标准差,在这种标准化操作下,如果原数据服从正态分布,处理之后的数据服从标准正态分布。Z-Score标准化计算公式如下:

我们也可通过如下方式对张量进行Z-Score标准化处理。
from sklearn.preprocessing import StandardScaler
x=[[10001,2],[16020,4],[12008,6],[13131,8]]
ss = StandardScaler()
X_train = ss.fit_transform(x)
X_trainarray([[-1.2817325 , -1.34164079],[ 1.48440157, -0.4472136 ],[-0.35938143, 0.4472136 ],[ 0.15671236, 1.34164079]])和0-1标准化不同,Z-Score标准化并不会将数据放缩在0-1之间,而是均匀地分布在0的两侧
特征编码
我们拿到的数据通常比较脏乱,特征变量除了数值外可能还会包括带有各种非数字特殊符号等特征值,比如中文。但一般的机器学习模型一般都是处理数值型的特征值,因此需要将一些非数值的特殊特征值转为为数值,因为只有数字类型才能进行计算。因此,对于各种特殊的特征值,我们都需要对其进行相应的编码,也是量化的过程,这就要用到特征编码。
编码方法
- LabelEncoder :适合处理字符型数据或label类,一般先用此方法将字符型数据转换为数值型,然后再用以下两种方法编码;
- get_dummies :pandas 方法,处理DataFrame 数据更便捷
- OneHotEncoder :更普遍的编码方法
LabelEncoder🏖️
label-encoding就是用标签进行编码的意思,即我们给特征变量自定义数字标签,量化特征。
将离散的数值或字符串,转化为连续的数值型数据。n个类别就用0到n-1个数表示。没有扩维,多用于标签列的编码(如果用于特征的编码,那编码后还要用get_dummies或OneHotEncoder进行再编码,才能实现扩维)。
import pandas as pd
Class=['大一','大二','大三','大四']
df = pd.DataFrame({'Class':Class})
classMap = {'大一':1,'大二':2,'大三':3,'大四':4}
df['Class'] = df['Class'].map(classMap)
上面就将Class特征进行相应的编码。其实,Label encoding并没有任何限制,你也可以将Class定义为10,20,30,40,只不过1,2,3,4看起来比较方便。因此总结概括,Label encoding就是将原始特征值编码为自定义的数字标签完成量化编码过程。
get_dummies🏖️
pandas编码工具,直接将数据扩维
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)import pandas as pd # 创建一个包含分类变量的 DataFrame
data = {'Color': ['Red', 'Blue', 'Green', 'Red', 'Blue']}
df = pd.DataFrame(data) print("原始 DataFrame:")
print(df) # 使用 get_dummies 进行独热编码
df_dummies = pd.get_dummies(df) print("\n独热编码后的 DataFrame:")
print(df_dummies)原始 DataFrame: Color
0 Red
1 Blue
2 Green
3 Red
4 Blue 独热编码后的 DataFrame: Color_Blue Color_Green Color_Red
0 0 0 1
1 1 0 0
2 0 1 0
3 0 0 1
4 1 0 0
同时在pandas可以指定 columns参数,pd.get_dummies(df,columns=[“length”,“size”])指定被编码的列,返回被编码的列和不被编码的列
df_4 =pd.get_dummies(df,columns=["length","size"])OneHotEncoder🏖️
当然,除了自然顺序编码外,常见的对离散变量的编码方式还有独热编码,独热编码的过程如下
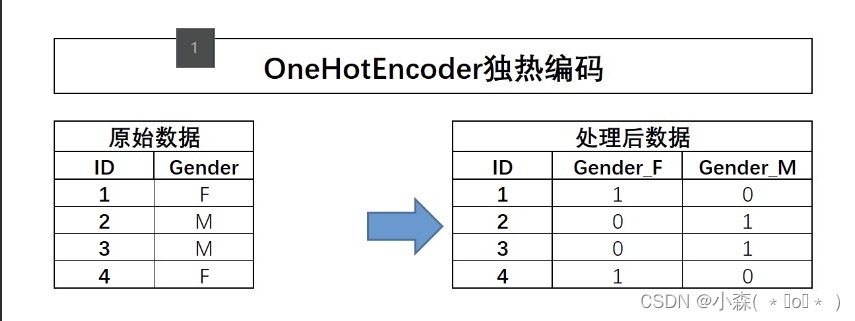
不难发现,独热编码过程其实和我们此前介绍的哑变量创建过程一致(至少在sklearn中并无差别)。对于独热编码的过程,我们可以通过pd.get_dummies函数实现,也可以通过sklearn中OneHotEncoder评估器(转化器)来实现。
import numpy as np
from sklearn.preprocessing import OneHotEncoder # 假设我们有一些分类数据
categories = np.array(['cat', 'dog', 'fish', 'cat', 'dog', 'bird']).reshape(-1, 1) # 创建 OneHotEncoder 实例
encoder = OneHotEncoder(sparse=False) # 使用数据拟合编码器并转换数据
onehot = encoder.fit_transform(categories) # 输出独热编码的结果
print(onehot) # 输出编码器的类别
print(encoder.categories_)[[1. 0. 0.] [0. 1. 0.] [0. 0. 1.] [1. 0. 0.] [0. 1. 0.] [0. 0. 0.]]
[array(['bird', 'cat', 'dog', 'fish'], dtype=object)]
对于独热编码的使用,有一点是额外需要注意的,那就是对于二分类离散变量来说,独热编码往往是没有实际作用的。例如对于上述极简数据集而言,Gender的取值是能是M或者F,独热编码转化后,某行Gender_F取值为1、则Gender_M取值必然为0,反之亦然。因此很多时候我们在进行独热编码转化的时候会考虑只对多分类离散变量进行转化,而保留二分类离散变量的原始取值。此时就需要将OneHotEncoder中drop参数调整为’if_binary’,以表示跳过二分类离散变量列
sklearn中逻辑回归的参数解释
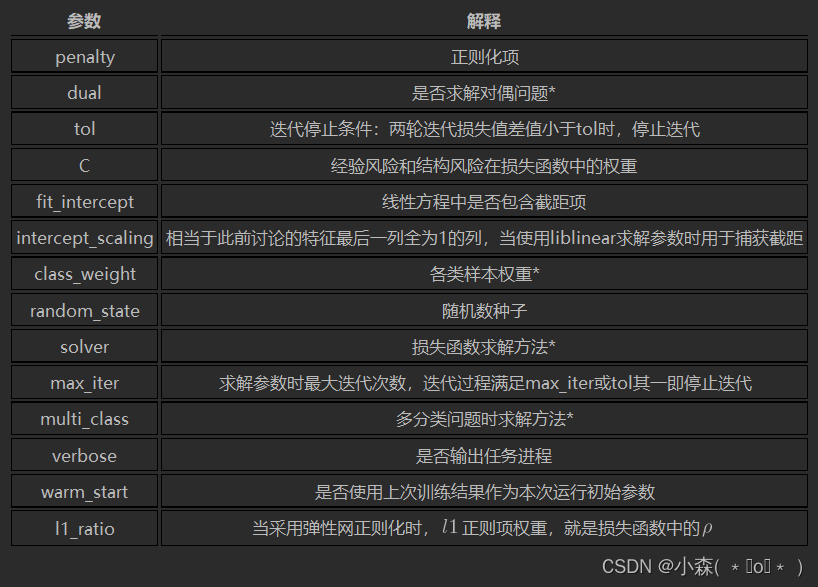
- C 惩罚系数
- penalty 正则化项
相比原始损失函数,正则化后的损失函数有两处发生了变化,其一是在原损失函数基础上乘以了系数C,其二则是加入了正则化项。其中系数C也是超参数,需要人工输入,用于调整经验风险部分和结构风险部分的权重,C越大,经验风险部分权重越大,反之结构风险部分权重越大。此外,在L2正则化时,采用的表达式,其实相当于是各参数的平方和除以2,在求最小值时本质上和w的2-范数起到的作用相同,省去开平方是为了简化运算,而除以2则是为了方便后续求导运算,和2次方结果相消。
其实除了最小二乘法和梯度下降以外,还有非常多的关于损失函数的求解方法,而选择损失函数的参数,就是solver参数。
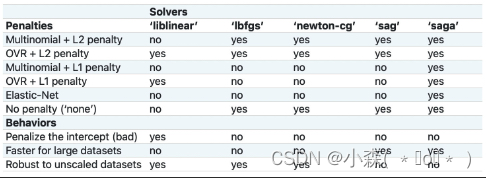
逻辑回归可选的优化方法包括:
- liblinear,这是一种坐标轴下降法,并且该软件包中大多数算法都有C++编写,运行速度很快,支持OVR+L1或OVR+L2;
- lbfgs,全称是L-BFGS,牛顿法的一种改进算法(一种拟牛顿法),适用于小型数据集,并且支持MVM+L2、OVR+L2以及不带惩罚项的情况;
- newton-cg,同样也是一种拟牛顿法,和lbfgs适用情况相同;
- sag,随机平均梯度下降,随机梯度下降的改进版,类似动量法,会在下一轮随机梯度下降开始之前保留一些上一轮的梯度,从而为整个迭代过程增加惯性,除了不支持L1正则化的损失函数求解以外(包括弹性网正则化)其他所有损失函数的求解;
- saga,sag的改进版,修改了梯度惯性的计算方法,使得其支持所有情况下逻辑回归的损失函数求解;
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
%matplotlib inlinedata = pd.read_csv("creditcard2.csv")from sklearn.preprocessing import MinMaxScaler
data['normAmount'] = MinMaxScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)X = data.iloc[:, data.columns != 'Class'].values
y = data.iloc[:, data.columns == 'Class']['Class'].valuesX_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 114)def kflod_scores(X,y):fold = KFold(5,shuffle=False)c_param_range = [0.01, 0.1, 1]show_result = pd.DataFrame()recalls = []cv = KFold(n_splits=5, shuffle=True, random_state=114)for c_param in c_param_range:lr_model = LogisticRegression(C=c_param, penalty="l2")print('-------------------------------------------')print('正则化惩罚力度: ', c_param)print('-------------------------------------------')print('')result = cross_validate(lr_model, X, y, cv=cv, scoring="recall", verbose=True, n_jobs=-1)print(result["test_score"])recalls.append(np.mean(result["test_score"]))show_result["c_param"] = list(c_param_range)show_result["recall"] = recallsreturn show_result
kflod_scores(X_train,y_train)刚刚进行的建模存在一些问题:
(1).过程不够严谨,诸如测试集中测试结果不能指导建模、参数选取及搜索区间选取没有理论依据等问题仍然存在;
(2).执行效率太低,如果面对更多的参数(这是更一般的情况),手动执行过程效率太低,无法进行超大规模的参数挑选;
(3).结果不够精确,一次建模结果本身可信度其实并不高,我们很难证明上述挑选出来的参数就一定在未来数据预测中拥有较高准确率。
网格搜索
sklearn中最常用的搜索策略就是使用GridSearchCV进行全搜索,即对参数空间内的所有参数进行搜索.
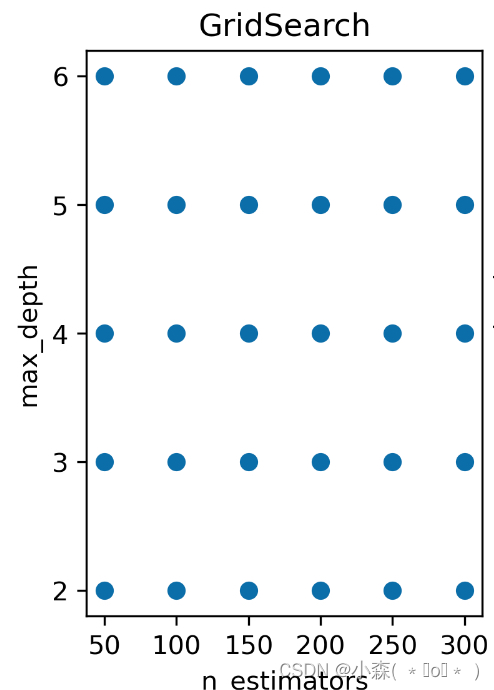
from sklearn.model_selection import GridSearchCVGridSearchCV它的参数主要如下
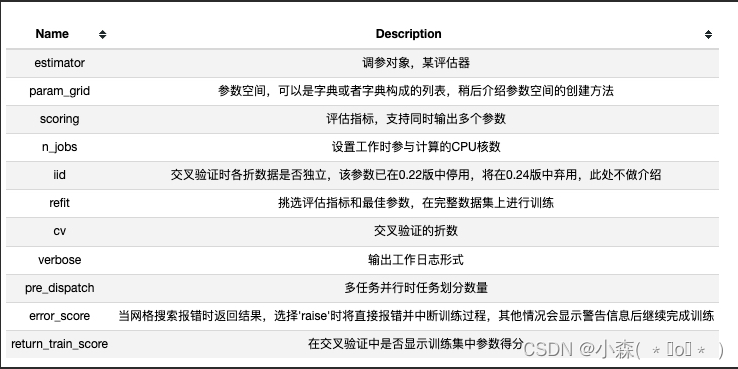
from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=114)param_grid_simple = {'penalty': ['l1', 'l2'],'C': [1, 0.5, 0.1, 0.05, 0.01]}search = GridSearchCV(estimator=lgr,param_grid=param_grid_simple)search.fit(X_train, y_train)search.best_estimator_
# 训练完成后的最佳评估器search.best_estimator_.coef_
# 逻辑回归评估器的所有属性search.best_score_
# 0.9727272727272727
在默认情况下(未修改网格搜索评估器中评估指标参数时),此处的score就是准确率。此处有两点需要注意:
- 其一:该指标和训练集上整体准确率不同,该指标是交叉验证时验证集准确率的平均值,而不是所有数据的准确率;
- 其二:该指标是网格搜索在进行参数挑选时的参照依据。
相关文章:
机器学习归一化特征编码
特征缩放 因为对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1——10,第二个特征的取值范围为1——10000。在梯度…...

抛光粉尘可爆性检测 打磨粉尘喷砂粉尘爆炸下限测试
抛光粉尘可爆性检测 抛光粉尘的可爆性检测是一种安全性能测试,用于确定加工过程中产生的粉尘在特定条件下是否会爆炸,从而对生产安全构成威胁。如果粉尘具有可爆性,那么在生产环境中就需要采取相应的防爆措施。粉尘爆炸的条件通常包括粉尘本身…...

python14 字典类型
字典类型 键值对方式,可变数据类型,所以有增删改功能 声明方式1 {} 大括号,示例 d {key1 : value1, key2 : value2, key3 : value3 ....} 声明方式2 使用内置函数 dict() 创建1)通过映射函数创建字典zip(list1,list2) 继承了序列的所有操作 …...

深入了解 .url文件中的 Prop3属性
在使用 Windows 操作系统时,我们经常会遇到以 .url 结尾的文件,它们通常被用来快速访问互联网上的特定网页。这些文件虽然看起来简单,但其中包含的 Prop3 属性却有其特殊的作用和意义。 1. Prop3 是什么? 在 .url 文件中&#x…...

vue3+vite:动态引入静态图片资源
目录 第一章 前言 第二章 vue2与vue3动态引入静态图片资源 2.1 vue2 webpack动态引入静态图片资源 2.1.1 了解 2.1.2 vue2项目动态引入静态图片资源 2.2 vue3 vite动态引入静态图片资源 2.2.1 了解 2.2.2 require vs import了解 2.2.3 vue3vite 项目动态引入静态图片…...

【K8s】专题五(3):Kubernetes 配置之 ConfigMap 与 Secret 异同
以下内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发!欢迎扫码关注个人公众号! 目录 一、相同点 二、不同点 一、相同点 功能作用:ConfigMap 与 Secret 都用于存储…...
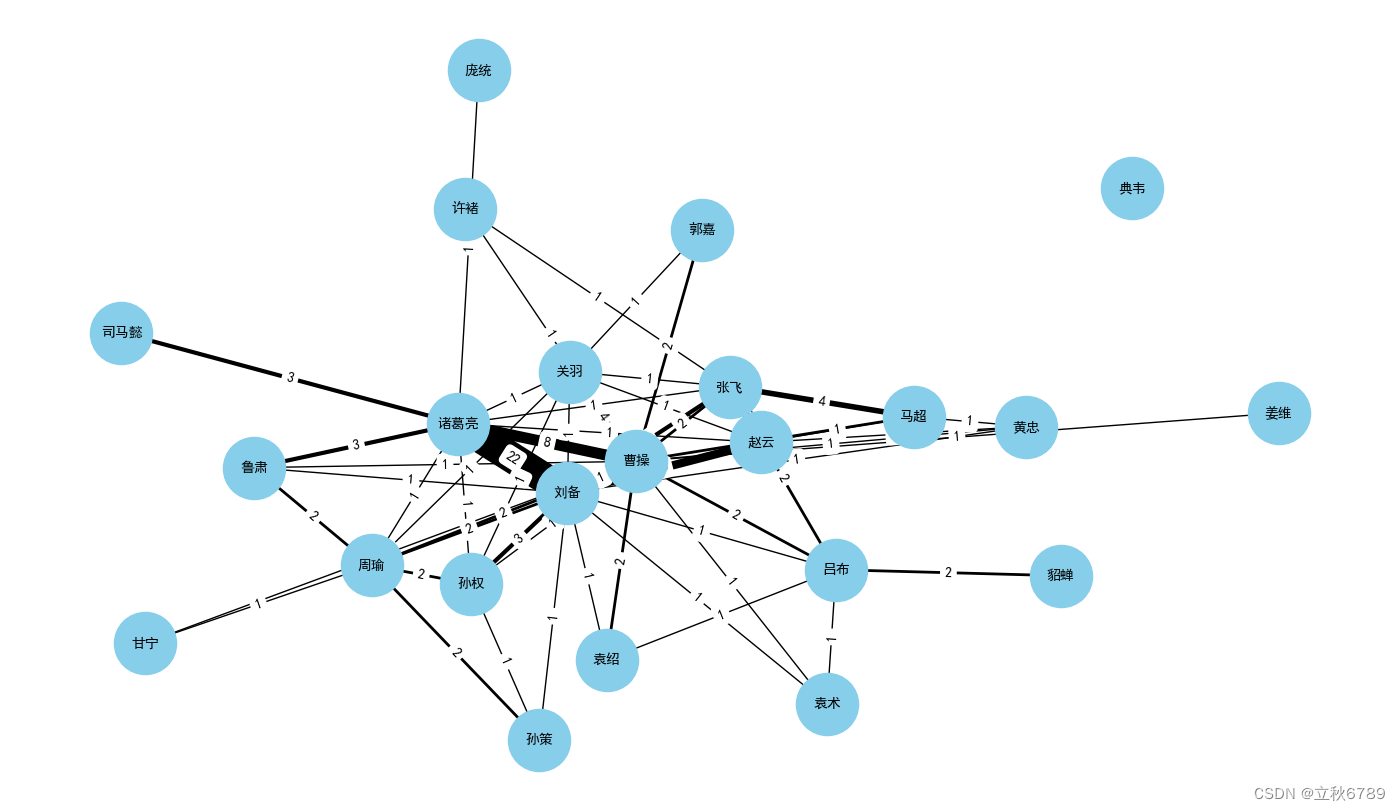
用Python分析《三国演义》中的人物关系网
用Python分析《三国演义》中的人物关系网 三国演义获取文本文本预处理分词与词频统计引入停用词后进行词频统计构建人物关系网完整代码 三国演义 《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间…...
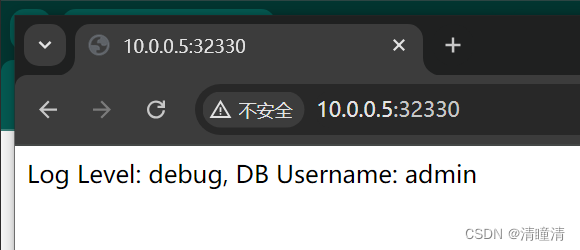
k8s上使用ConfigMap 和 Secret
使用ConfigMap 和 Secret 实验目标: 学习如何使用 ConfigMap 和 Secret 来管理应用的配置。 实验步骤: 创建一个 ConfigMap 存储应用配置。创建一个 Secret 存储敏感信息(如数据库密码)。在 Pod 中挂载 ConfigMap 和 Secret&am…...
hexo实战:(二)个人独立博客优化合集
前言 上次介绍了使用 HexoGitHub Pages,零成本搭建一个专属自己的独立博客网站。我觉得那篇文章是没有入门门槛的,不管你是什么行业,只要想打造个人 IP,又不太想受博客平台约束,那么读完后动手操作一下也能轻松完成。…...

PostgreSQL的pg_relation_filepath函数
PostgreSQL的pg_relation_filepath函数 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777在 PostgreSQL 中&…...

Vue开发中Element UI/Plus使用指南:常见问题(如Missing required prop: “value“)及中文全局组件配置解决方案
文章目录 一、vue中使用el-table的typeindex有时不显示序号Table 表格显示索引自定义索引报错信息解决方案 二、vue中Missing required prop: “value” 报错报错原因解决方案 三、el-table的索引值index在翻页的时候可以连续显示方法一方法二 四、vue3中Element Plus全局组件配…...
安装golang
官网:All releases - The Go Programming Language (google.cn) 下载对应的版本安装即可...

Kubernetes面试整理-Kubernetes的主要组件有哪些?
Kubernetes 的主要组件分为控制平面组件和节点组件。以下是每个组件的详细介绍: 控制平面组件 1. API 服务器(kube-apiserver): ● 是 Kubernetes 控制平面的前端,接收、验证并处理所有的 API 请求。 ● 提供集群的管理接口,所有的集群操作都是通过 API 服务器进行的。...
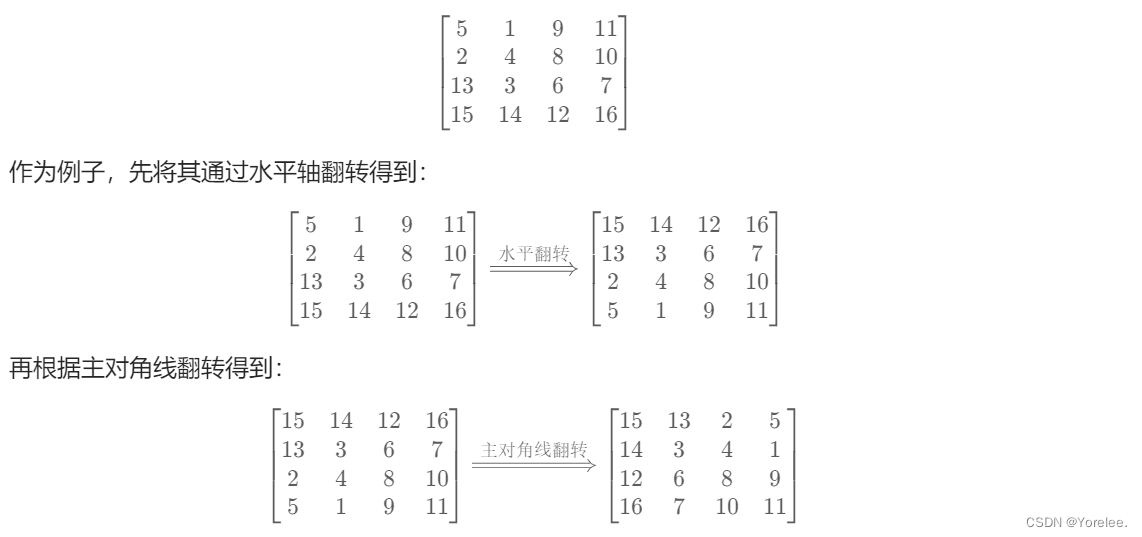
力扣hot100: 48. 旋转图像
LeetCode:48. 旋转图像 受到力扣hot100:54. 螺旋矩阵的启发,我们可以对旋转图像按层旋转,我们只需要记录四个顶点,并且本题是一个方阵,四个顶点就能完成图像的旋转操作。 1、逐层旋转 注意到࿰…...

基于FPGA的VGA协议实现
目录 一、VGA简介 二、VGA引脚的定义 三、VGA显示原理: 四、VESA标准下的VGA时序: 五、VGA显示模式以及相关参数: 六、数字信号与模拟信号的转换 实战演练一:VGA显示彩条 1、实验目标 2、各模块框图及其波形图 3、模块代…...

Java线程池的抛弃策略
Java线程池的抛弃策略 Java线程池是Java并发编程中非常重要的一个组件。它通过重用已创建的线程来减少线程创建和销毁的开销,从而提高应用程序的性能和响应速度。然而,当线程池中的任务数量超过其处理能力时,就需要一种机制来处理新提交的任…...

【python】Sklearn—Cluster
参考学习来自 10种聚类算法的完整python操作示例 文章目录 聚类数据集亲和力传播——AffinityPropagation聚合聚类——AgglomerationClusteringBIRCH——Birch(✔)DBSCAN——DBSCANK均值——KMeansMini-Batch K-均值——MiniBatchKMeans均值漂移聚类——…...
测试开发面经分享,面试七天速成 DAY 1
1. get、post、put、delete的区别 a. get请求: i. 用于从服务器获取资源。请求参数附加在URL的查询字符串中。 ii. 对服务器的请求是幂等的,即多次相同的GET请求应该返回相同的结果。 iii. 可以被缓存,可以被收藏为书签。 iv. 对于敏感数据不…...

C++ Primer Plus第五版笔记(p201-250)
第六章 函数(下) 在含有return语句的循环后面应该也有一条return语句 不要返回局部对象的引用或指针,当函数结束时临时对象占用的空间也就随之释放掉了,所以两条return语句都指向了不再可用的内存空间。 如果函数返回指针、引用…...
vba学习系列(5)--指定区域指定字符串计数
系列文章目录 文章目录 系列文章目录前言一、需求背景二、vba自定义函数1.引入库 总结 前言 一、需求背景 想知道所有客诉项目里面什么项目最多,出现过多少次。 二、vba自定义函数 1.引入库 引用: CountCharInRange(区域,“字符串”) Function CountCh…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...