StarRocks详解
什么是StarRocks?
StarRocks是新一代极速全场景MPP数据库(高并发数据库)。
StarRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果。
1.可以在Spark和Flink里面处理数据,然后将处理完的数据写到StarRocks里面。
2.可以实现将数据从Hadoop倒入到StarRocks里面去,也可以将StarRocks的数据倒入到Hadoop里面,都是可以实现的。
3.可以对接ES数据库(ElasticSearch)。
4.StarRocks兼容MySQL的协议,可以通过 MySQL的客户端 和 常用BI工具 对接StarRocks来进行数据分析。
5.StarRocks采用分布式架构,对数据表进行水平划分并且以多副本存储,集群规模可以灵活伸缩,能够支持10PB级别的数据分析,支持MPP框架,并行加速计算,支持多副本,具有弹性容错能力。
StarRocks适合什么场景?
1.OLAP多维分析:用户行为分析,用户画像,财务报表,系统监控分析。
2.实时数据分析:电商数据分析,直播质量分析,物流运单分析,广告投放分析。
3.高并发查询:广告主表分析,Dashboard多页面分析。
4.统一分析:通过使用一套系统解决上述场景,降低系统复杂度和多技术栈开发成本。
StarRocks基本概念:
1.FE:FrondEnd是StarRocks的前端节点,负责管理元数据,负责与客户端连接,进行查询规划,查询调度等工作。
2.BE:BackEnd时StarRocks的后端节点,负责数据存储,计算执行,以及Compaction,副本管理等工作。
3.Broker:Broker并不是必须出现的,当StarRocks和HDFS进行交互的时候(也就是数据从HDFS到StarRocks中 和 数据从StarRocks中到HDFS里面),那么StaRocks负责这个过程的中转服务,辅助提供导入导出功能。
4.StarRocksManager:StarRocks的可视化工具,提供StarRocks的集群管理,在线查询,故障查询,监控报警的可视化工具。
5.Tablet:StarRocks中表的逻辑分片,也是StarRocks中副本管理的基本单位,每个表根据分区和分桶机制被划分成多个Tablet存储在不同BE节点上。
StarRocks系统架构:
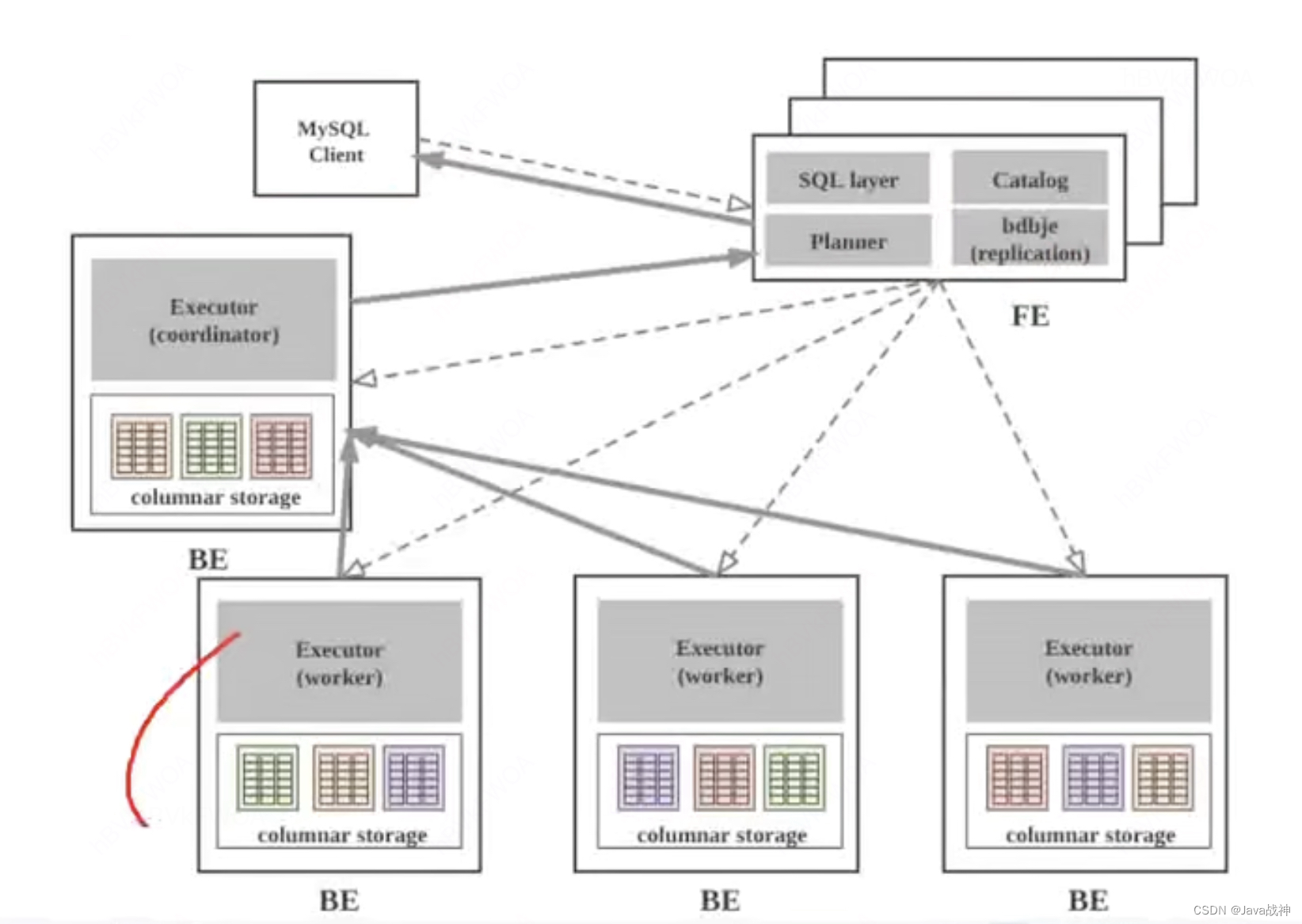
FE:
1.接受MySQL客户端的连接,解析并且执行SQL语句。
2.管理元数据,执行SQL DDL命令,用CataLog记录库,表,分区,tablet副本等信息。
3.FE高可用部署,使用 复制协议选主 和 主从同步 元数据,所有的元数据修改操作,都有FE的leader节点完成,FE的follower节点可执行读操作。元数据的读写满足顺序一致性,FE的节点数目采用2n+1,可以容忍n个节点故障,当FE leader故障的时候,可以从现有的follower节点中重新选主,完成故障切换。
4.FE中的SQL Layer对用户提交的SQL进行解析,分析,改写,语义分析和关系代数优化,生产逻辑执行计划。
5.FE中的Planner负责把逻辑计划转化为可分布式执行的物理计划,分发给一组BE。
6.FE监督BE,管理BE的上下线,根据BE的存活和健康状态,维持tablet副本的数量。
7.FE协调数据导入,保证数据导入的一致性。
BE:
1.BE管理tablet副本,tablet时table经过分区分桶形成的子表,采用列式存储。
2.BE受FE指导,创建或删除子表。
3.BE接收FE分发的物理执行计划并指定BE coordinator节点,在BE coordinator的调度下,与其他BE worker共同协作完成执行。
4.BE读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。
5.BE后台执行compact任务,减少查询时的读放大。
6.数据导入的时候,由FE指定BE coordinator,将数据以fanout的形式写入到tablet多副本所在的BE上。
StarRocks为什么快:
列式存储:StarRocks中,一张表的列可以分为维度列(key列)和指标列(value列),维度列用于分组和排序,指标列可通过聚合函数等累加起来。StarRocks可以认为是多维的key到多维指标的映射。(在写SQL的时候最好要根据表的前缀,类似于MySQL的索引最左前缀原则)
稀疏索引:当进行范围查询时,StarRocks能够快速定位到起始目标行,是因为shortkey index(稀疏索引)。

预先聚合:StarRocks支持聚合模型,维度列取值相同数据行可合并一行,合并后数据行的维度列取值不变,指标列的取值为这些数据行的聚合结果,用户需要给指标列指定聚合函数,通过预先聚合,可以加速聚合操作。
分区分桶:StarRocks的表被分为tablet,每个tablet多副本冗余存储在BE上,BE和tablet的数量可以根据计算资源和数据规模而弹性伸缩,查询时,多台BE可并行地查找tablet快速获取数据。而且tablet的副本可以复制和前一,增强了数据的可靠性,避免了数据倾斜。
列级别的索引技术:Bloomfilter可以快速判断数据块中不含所查找值,ZoneMap通过数据范围快速过滤待查找值,Bitmap索引可快速计算出枚举类型的列满足一定条件的行。
StarRocks的4种表模型:
明细模型(Duplicate key):关注历史数据。
聚合模型(Aggregate key):关注总量,平均值,最大值,最小值,计算一个统一的指标。
更新模型(Unique key):设定一个主键(uid),主键是唯一的,如果主键是第一次出现在表中,那么执行插入操作,如果主键第二次出现在表中,那么执行更新操作,覆盖前一条记录。(并不是真的覆盖,其实也存着明细数据,只是将最新的一条记录返回)
主键模型(Primary key):主键模型相当于是更新模型的升级版,速度更快一些。更新模型采用Merge on Read读时合并策略会大大限制查询功能,在主键模型更好地解决了行级的更新操作。配合Flink-connector-starrocks可以完成MySQL CDC实时同步的方案。存储引擎会为主键建立索引,导入数据时会把索引加载到内存中,所以主键模型对内存的要求更高。真正保证每个主键只有一条数据存在。
各自适用场景:
1.明细模型:建表的时候注意设置排序列(duplicate key)
关注历史明细数据。
2.聚合模型:建表的时候注意设置聚合列( distributed by hash(site_id) )
业务方进行查询为汇总类查询,比如sum,count,max。
不需要查看明细数据。
老数据不会被频繁修改,只会追加和新增。
3.更新模型:建表的时候注意设置UNIQUE KEY 唯一列(create_time,order_id)
数据需要进行更新,比如拉链表。
已经写入的数据有大量的更新需求。(比如电商场景中,订单的状态经常会发生变化,没必要用明细表记录变化趋势,使用更新模型记录最新的状态即可)
需要进行实时数据分析。
4.主键模型:建表的时候注意PRIMARY KEY主键列(user_id)
数据冷热特征:只有最近几天的数据才需要修改,老的冷数据很少需要修改,比如订单数据,老的订单完成后就不再更新,并且分区是按天进行分区的,那么在导入数据时历史分区的数据的主键就不会被加载,也就不会占用内存了,内存中仅会加载近几天的索引。
大宽表(数百列数千列):主键只占整个数据的很小一部分,内存开销比较低。比如用户状态/画像表,虽然列非常多,但总的用户数量不大,主键索引内存占用相对可控。
StarRocks排序列:
明细模型中的排序列可以理解成是 DUPLICATED KEY
聚合模型中的排序列可以理解成是 AGGREGATE KEY
更新模型中的排序列可以理解成是UNIQUE KEY
主键模型中的排序列可以理解成是PRIMARY KEY
排序列的设定顺序必须和建表语句的字段顺序一样,如果想使用到排序列那么必须要按照类似于MySQL的索引最左前缀原则,设定where条件。
使用排序键的本质其实就是在进行二分查找,所以排序列指定的越多,那么消耗的内存也会越大,StarRocks为了避免这种情况发生也对排序键做了限制:
1.排序键的列只能是建表字段的前缀。
2.排序键的列数不能超过3.
3.字节数不超过36字节。
4.不包含FLOAT/DOUBLE类型的列。
5.Varchar类型列只能出现一次,并且是末尾位置。
物化视图:Materialized View(MVs)物化视图
在基于维度进行分析的时候,需要使用物化视图。
StarRocks中Bitmap索引:
BitMap索引利用位数组(bit array)来表示数据集中某个属性的所有可能值是否出现,每个位对应数据表中的一行记录,如果该位为1,则表示该行记录具有指定的属性值;如果为0,则表示不具备。这种结构非常适合于 处理布尔型查询 或者 枚举类型比较少 的列查询,比如性别。
BitMap在一些场景下表现的比较优秀,但是同样也存在着局限性:
1.内存消耗:BitMap索引会占据比较大的内存空间。
2.更新成本:当数据插入,删除或者更新的时候,对应的位图需要维护,会产生开销。
总结:最适用的场景是针对于低基数(列中不同值的数量很少),会展现出更高的优化能力。
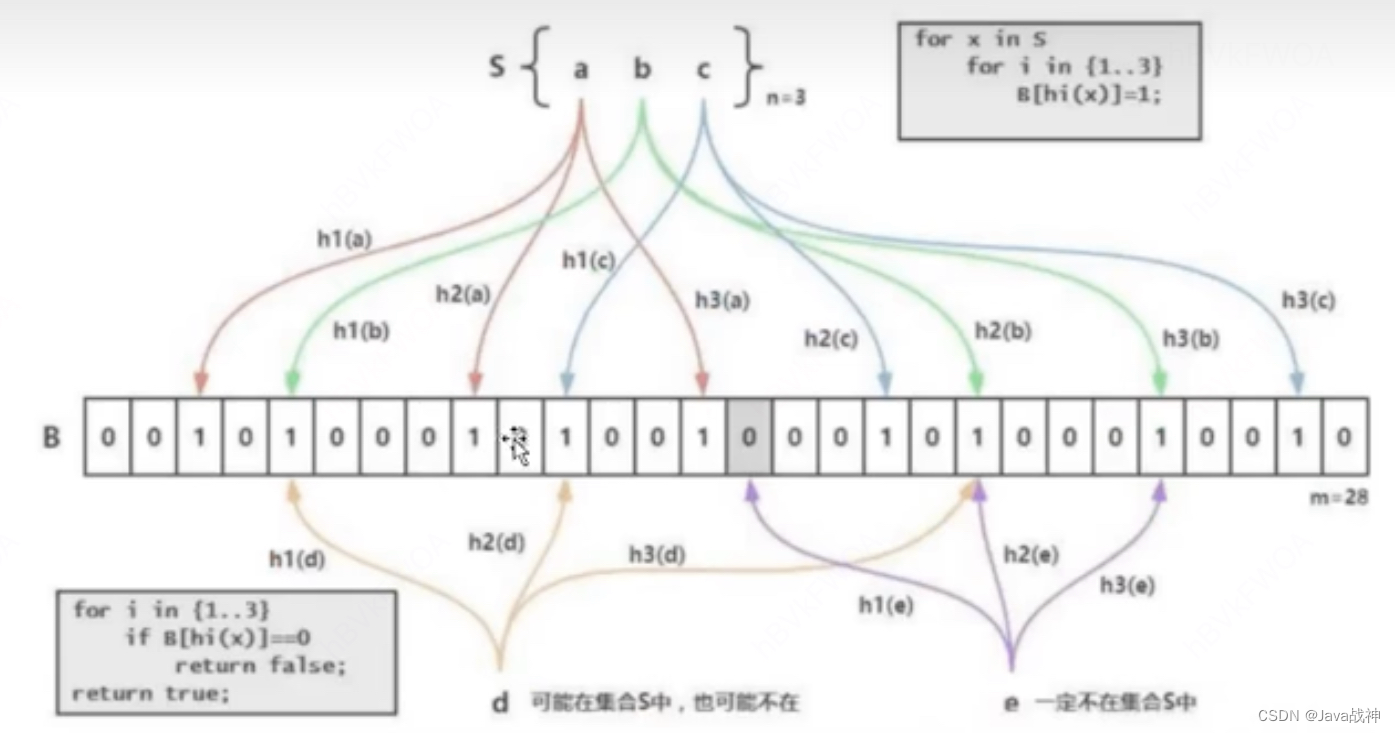
StarRocks中布隆过滤器:
Bloom Filter(布隆过滤器),是用于快速地判断某个元素是否在一个集合中的数据结构,优点是空间效率和时间效率都很高,缺点是有一定的误判率。就是说,如果布隆过滤器说一个元素不在集合中,那它确实不在;但如果说一个元素可能在这个集合中,这个结论也不一定是正确的。
工作原理:布隆过滤器 由一个 位数组(二进制向量) 和 一系列哈希函数 组成。在初始化的阶段,所有的位都是0。当一个元素被插入到布隆过滤器中时,会被每一个哈希函数处理,每个哈希函数都会产生一个位数组的索引,然后相应位置的位会被置为1。这样,每个元素的插入都会在位数组中留下多个标记。检查一个元素是否在集合中的时候,也是使用同样的哈希函数计算出多个索引的位置,如果所有这些位置的位都是1,那么可能在集合中,如果任何一位是0,那么就可以确定不在集合中。
(如果布隆过滤器已经判断出集合中不存在指定的值,就不需要读取数据文件。
如果布隆过滤器判断出集合中包含指定的值,就需要读取数据文件确认目标值是否存在。
另外,Bloom Filter索引无法确定具体是哪一行数据具有该指定的值)
在StarRocks中的应用:
减少磁盘I/O:在执行查询时,布隆过滤器可以先于实际数据读取之前被查询,用于快速排除那些肯定不包含查询结果的数据块,从而减少不必要的磁盘读取操作,提高查询效率。
分区剪枝(partition pruning):在分布式系统中,布隆过滤器可以帮助决定是否需要从特定分区或者节点中读取数据,实现查询的分区剪枝,减少网络传输和计算资源的消耗。
动态调整:StarRocks的布隆过滤器支持动态调整其误报率,以适应不同查询场景的需求。通过调整哈希函数的数量和位数组的大小,可以在误报率和存储空间之间找到平衡。
通过在建表的时候设定 PROPERTIES("bloom_filter_columns"="event_type,sex");
注意事项:
1.不支持对Tinyint,Float,Double类型的列建Bloom Filter索引。
2.Bloom Filter索引只对 'in' 和 '=' 过滤查询有加速效果。
3.如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看(TODO:加上查看Profile的链接)。
相关文章:
StarRocks详解
什么是StarRocks? StarRocks是新一代极速全场景MPP数据库(高并发数据库)。 StarRocks充分吸收关系型OLAP数据库和分布式存储系统在大数据时代的优秀研究成果。 1.可以在Spark和Flink里面处理数据,然后将处理完的数据写到StarRo…...

【C语言】进程间通信之管道pipe
进程间通信之管道pipe 一、进程间通信管道pipe()管道的读写行为 最后 一、进程间通信 管道pipe() 管道pipe也称为匿名管道,只有在有血缘关系的进程间进行通信。管道的本质就是一块内核缓冲区。 进程间通过管道的一端写,通过管道的另一端读。管道的读端…...
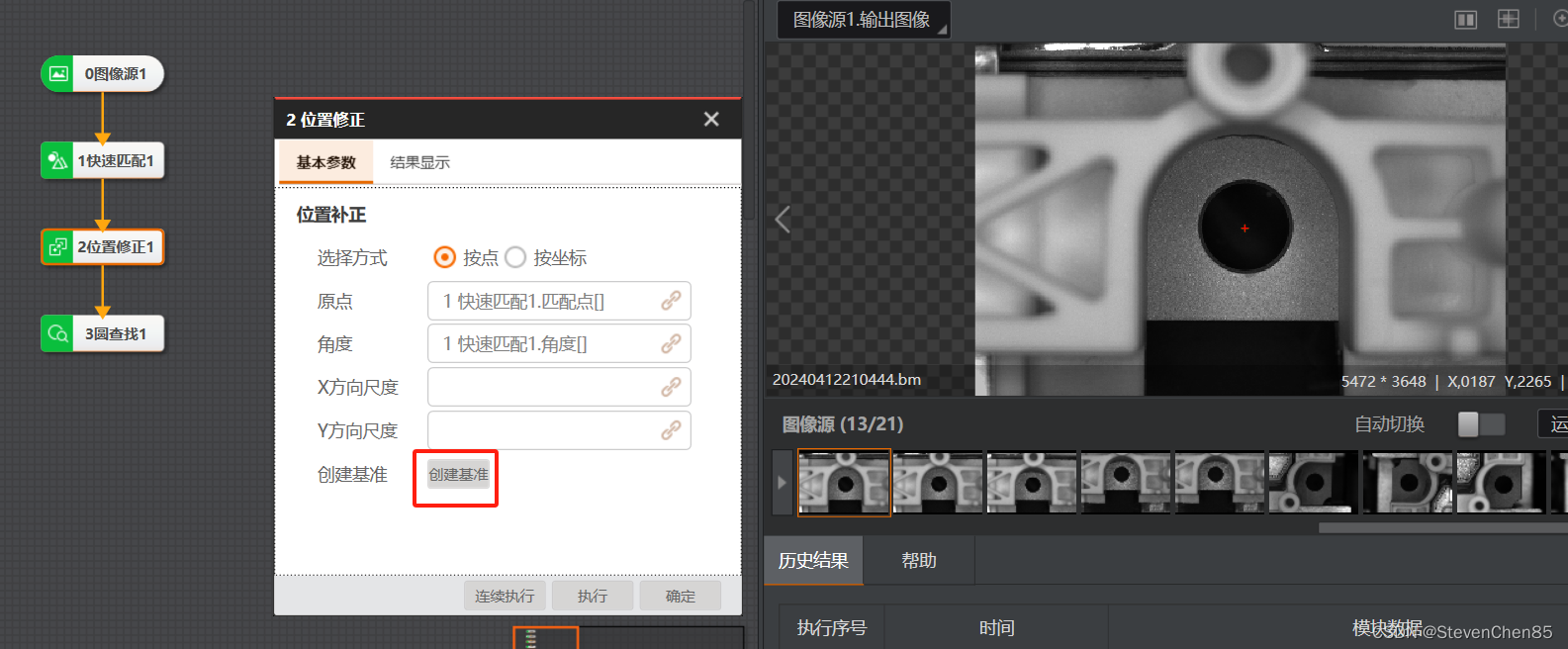
03.VisionMaster 机器视觉 位置修正 工具
VisionMaster 机器视觉 位置修正 工具 官方解释:位置修正是一个辅助定位、修正目标运动偏移、辅助精准定位的工具。可以根据模板匹配结果中的匹配点和匹配框角度建立位置偏移的基准,然后再根据特征匹配结果中的运行点和基准点的相对位置偏移实现ROI检测…...

Oracle 是否扼杀了开源 MySQL
Oracle 是否无意中扼杀了开源 MySQL Peter Zaitsev是一位俄罗斯软件工程师和企业家,曾在MySQL公司担任性能工程师。大约15年前,当甲骨文收购Sun公司并随后收购MySQL时,有很多关于甲骨文何时“杀死MySQL”的讨论。他曾为甲骨文进行辩护&#…...
机器学习归一化特征编码
特征缩放 因为对于大多数的机器学习算法和优化算法来说,将特征值缩放到相同区间可以使得获取性能更好的模型。就梯度下降算法而言,例如有两个不同的特征,第一个特征的取值范围为1——10,第二个特征的取值范围为1——10000。在梯度…...

抛光粉尘可爆性检测 打磨粉尘喷砂粉尘爆炸下限测试
抛光粉尘可爆性检测 抛光粉尘的可爆性检测是一种安全性能测试,用于确定加工过程中产生的粉尘在特定条件下是否会爆炸,从而对生产安全构成威胁。如果粉尘具有可爆性,那么在生产环境中就需要采取相应的防爆措施。粉尘爆炸的条件通常包括粉尘本身…...

python14 字典类型
字典类型 键值对方式,可变数据类型,所以有增删改功能 声明方式1 {} 大括号,示例 d {key1 : value1, key2 : value2, key3 : value3 ....} 声明方式2 使用内置函数 dict() 创建1)通过映射函数创建字典zip(list1,list2) 继承了序列的所有操作 …...

深入了解 .url文件中的 Prop3属性
在使用 Windows 操作系统时,我们经常会遇到以 .url 结尾的文件,它们通常被用来快速访问互联网上的特定网页。这些文件虽然看起来简单,但其中包含的 Prop3 属性却有其特殊的作用和意义。 1. Prop3 是什么? 在 .url 文件中&#x…...

vue3+vite:动态引入静态图片资源
目录 第一章 前言 第二章 vue2与vue3动态引入静态图片资源 2.1 vue2 webpack动态引入静态图片资源 2.1.1 了解 2.1.2 vue2项目动态引入静态图片资源 2.2 vue3 vite动态引入静态图片资源 2.2.1 了解 2.2.2 require vs import了解 2.2.3 vue3vite 项目动态引入静态图片…...

【K8s】专题五(3):Kubernetes 配置之 ConfigMap 与 Secret 异同
以下内容均来自个人笔记并重新梳理,如有错误欢迎指正!如果对您有帮助,烦请点赞、关注、转发!欢迎扫码关注个人公众号! 目录 一、相同点 二、不同点 一、相同点 功能作用:ConfigMap 与 Secret 都用于存储…...
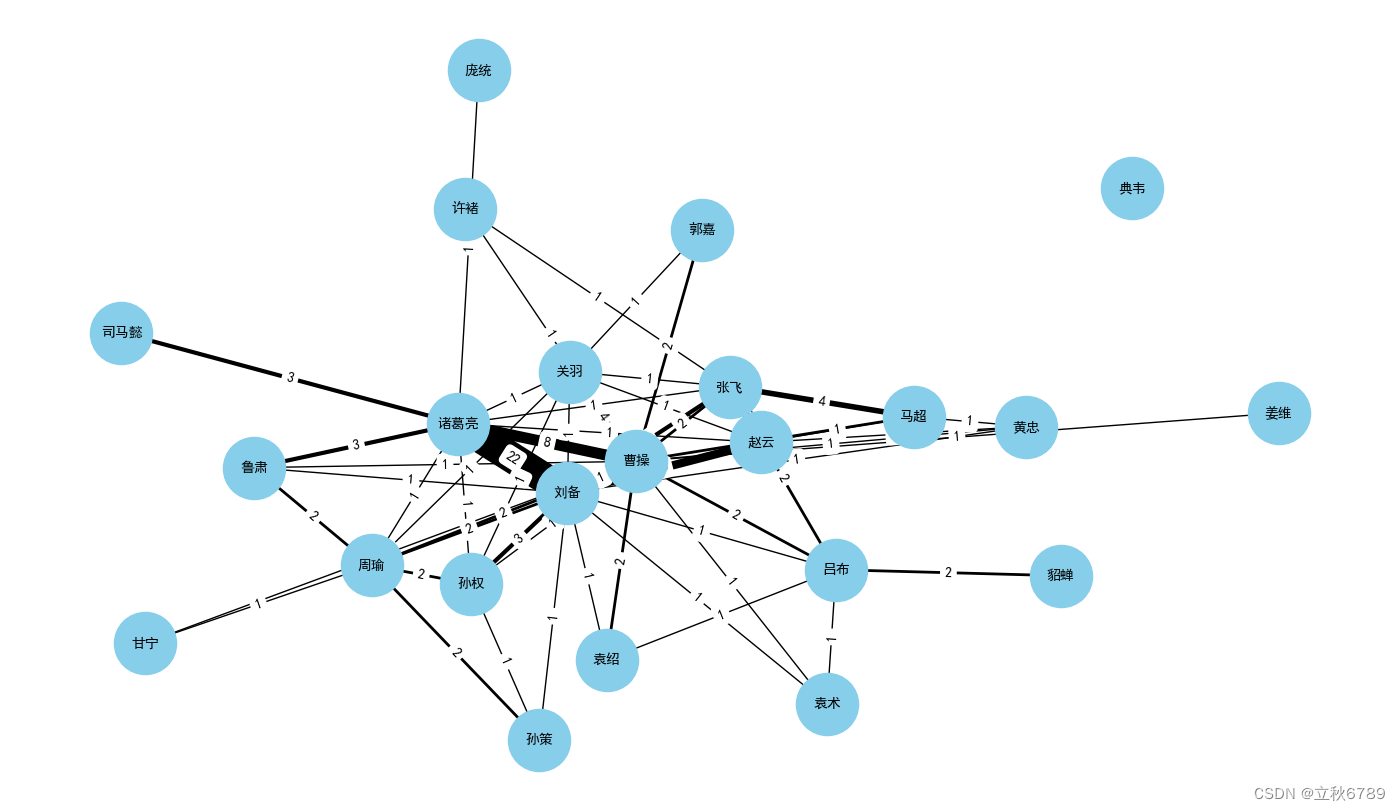
用Python分析《三国演义》中的人物关系网
用Python分析《三国演义》中的人物关系网 三国演义获取文本文本预处理分词与词频统计引入停用词后进行词频统计构建人物关系网完整代码 三国演义 《三国演义》是中国古代四大名著之一,它以东汉末年到晋朝统一之间的历史为背景,讲述了魏、蜀、吴三国之间…...
k8s上使用ConfigMap 和 Secret
使用ConfigMap 和 Secret 实验目标: 学习如何使用 ConfigMap 和 Secret 来管理应用的配置。 实验步骤: 创建一个 ConfigMap 存储应用配置。创建一个 Secret 存储敏感信息(如数据库密码)。在 Pod 中挂载 ConfigMap 和 Secret&am…...
hexo实战:(二)个人独立博客优化合集
前言 上次介绍了使用 HexoGitHub Pages,零成本搭建一个专属自己的独立博客网站。我觉得那篇文章是没有入门门槛的,不管你是什么行业,只要想打造个人 IP,又不太想受博客平台约束,那么读完后动手操作一下也能轻松完成。…...

PostgreSQL的pg_relation_filepath函数
PostgreSQL的pg_relation_filepath函数 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777在 PostgreSQL 中&…...

Vue开发中Element UI/Plus使用指南:常见问题(如Missing required prop: “value“)及中文全局组件配置解决方案
文章目录 一、vue中使用el-table的typeindex有时不显示序号Table 表格显示索引自定义索引报错信息解决方案 二、vue中Missing required prop: “value” 报错报错原因解决方案 三、el-table的索引值index在翻页的时候可以连续显示方法一方法二 四、vue3中Element Plus全局组件配…...
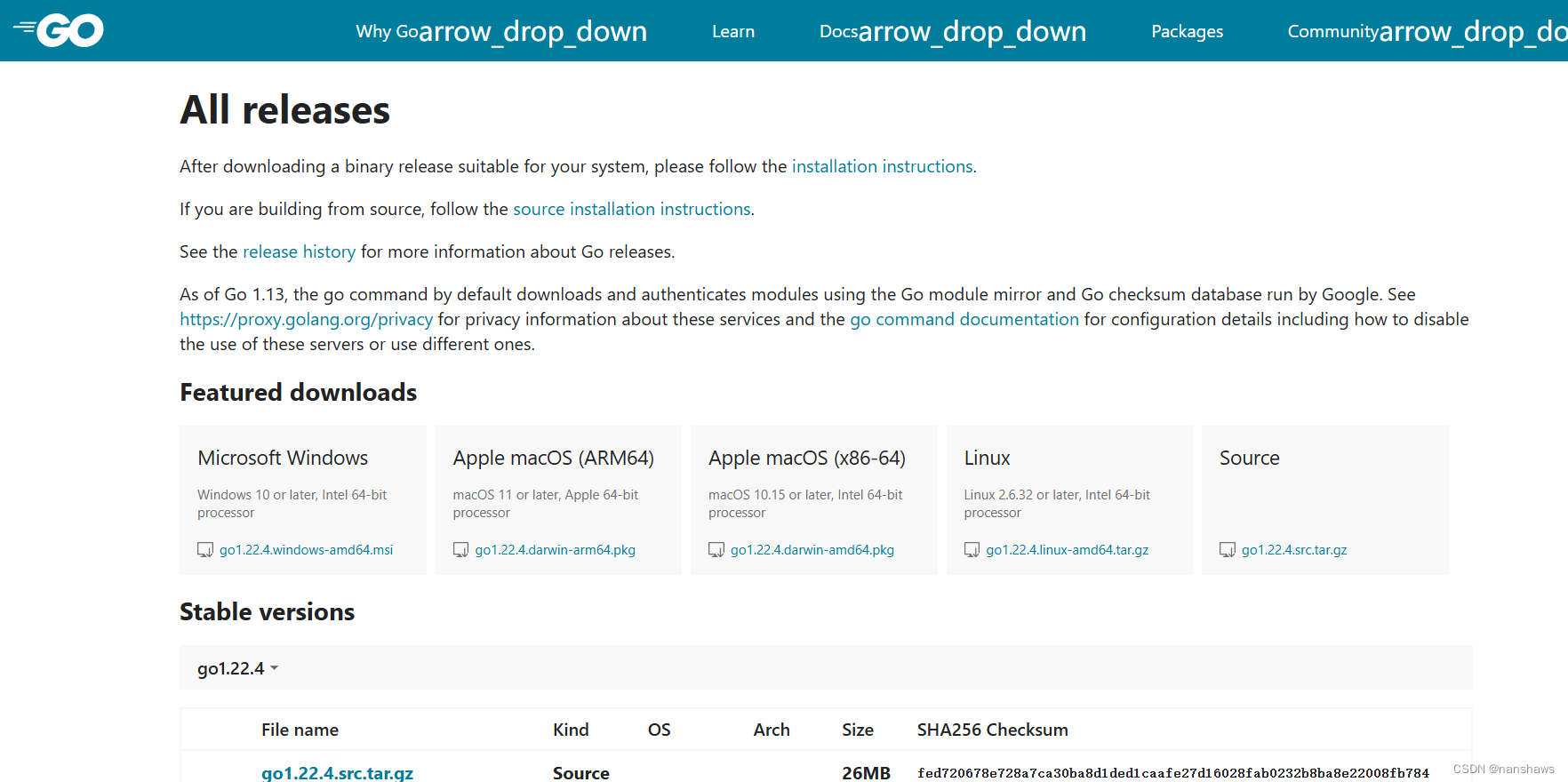
安装golang
官网:All releases - The Go Programming Language (google.cn) 下载对应的版本安装即可...

Kubernetes面试整理-Kubernetes的主要组件有哪些?
Kubernetes 的主要组件分为控制平面组件和节点组件。以下是每个组件的详细介绍: 控制平面组件 1. API 服务器(kube-apiserver): ● 是 Kubernetes 控制平面的前端,接收、验证并处理所有的 API 请求。 ● 提供集群的管理接口,所有的集群操作都是通过 API 服务器进行的。...
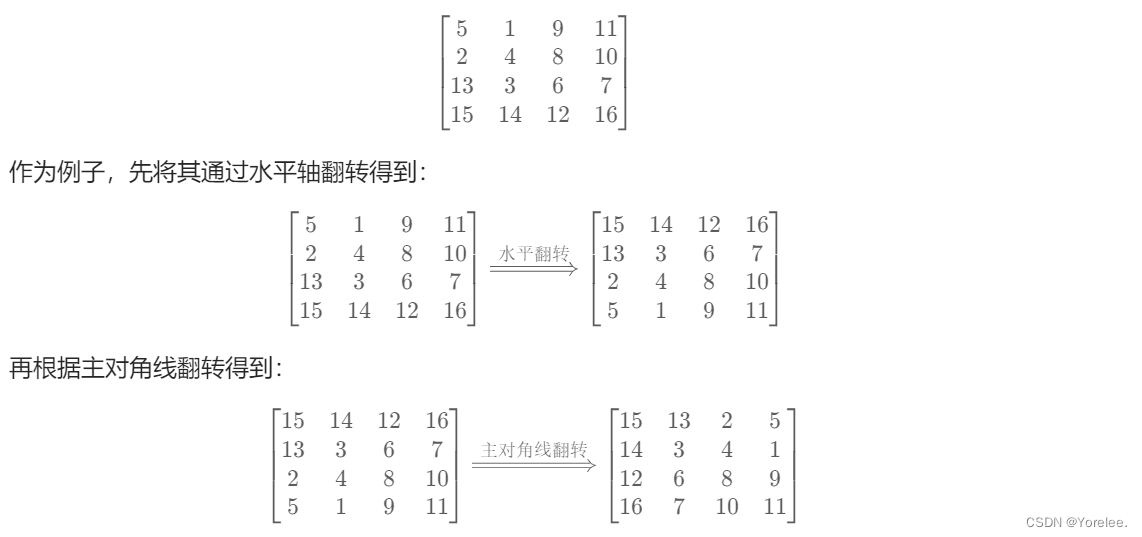
力扣hot100: 48. 旋转图像
LeetCode:48. 旋转图像 受到力扣hot100:54. 螺旋矩阵的启发,我们可以对旋转图像按层旋转,我们只需要记录四个顶点,并且本题是一个方阵,四个顶点就能完成图像的旋转操作。 1、逐层旋转 注意到࿰…...

基于FPGA的VGA协议实现
目录 一、VGA简介 二、VGA引脚的定义 三、VGA显示原理: 四、VESA标准下的VGA时序: 五、VGA显示模式以及相关参数: 六、数字信号与模拟信号的转换 实战演练一:VGA显示彩条 1、实验目标 2、各模块框图及其波形图 3、模块代…...

Java线程池的抛弃策略
Java线程池的抛弃策略 Java线程池是Java并发编程中非常重要的一个组件。它通过重用已创建的线程来减少线程创建和销毁的开销,从而提高应用程序的性能和响应速度。然而,当线程池中的任务数量超过其处理能力时,就需要一种机制来处理新提交的任…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

浅谈不同二分算法的查找情况
二分算法原理比较简单,但是实际的算法模板却有很多,这一切都源于二分查找问题中的复杂情况和二分算法的边界处理,以下是博主对一些二分算法查找的情况分析。 需要说明的是,以下二分算法都是基于有序序列为升序有序的情况…...