动手学深度学习(Pytorch版)代码实践 -深度学习基础-13Kaggle竞赛:2020加州房价预测
13Kaggle竞赛:2020加州房价预测
# 导入所需的库
import numpy as np
import pandas as pd
import torch
import hashlib
import os
import tarfile
import zipfile
import requests
from torch import nn
from d2l import torch as d2l# 读取训练和测试数据
train_data = pd.read_csv('../data/california-house-prices/train.csv')
test_data = pd.read_csv('../data/california-house-prices/test.csv')# 打印数据形状
# print(train_data.shape)
# print(test_data.shape)
# (47439, 41)
# (31626, 40)# 打印前4行的部分列
# print(train_data.iloc[0:4, [0, 1, 2, 3, 4, 5, 6, -3, -2, -1]])# 合并训练和测试数据,用于特征工程
all_features = pd.concat((train_data.iloc[:, train_data.columns != 'Sold Price'], test_data.iloc[:, 1:]))
# all_features.info()
# print(all_features.shape)
# (79065, 40)# 去除ID列
all_features = all_features.iloc[:, 1:]# 将字符型日期列转化为日期型
all_features['Listed On'] = pd.to_datetime(all_features['Listed On'], format="%Y-%m-%d")
all_features['Last Sold On'] = pd.to_datetime(all_features['Last Sold On'], format="%Y-%m-%d")# 标准化数值特征
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
all_features[numeric_features] = all_features[numeric_features].fillna(0)# 打印每个字符型特征的唯一值数量
# for in_object in all_features.dtypes[all_features.dtypes == 'object'].index:
# print(in_object.ljust(20), len(all_features[in_object].unique()))
"""
in_object.ljust(20):将列名左对齐,并填充空格使其长度至少为20个字符,这样打印时更整齐。
len(all_features[in_object].unique()):计算该列中唯一值的数量。
便于后续的独热编码,防止内存爆炸
"""# 选择需要的特征
features = list(numeric_features)
features.extend(['Type'])
all_features = all_features[features[:]]# 独热编码
all_features = pd.get_dummies(all_features, dummy_na=True, dtype=float)
# print(all_features.shape)
# (79065, 195)# 查看全部特征的数据类型
# print(all_features.dtypes.unique())# 从pandas格式中提取NumPy格式,并将其转换为张量表示用于训练
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)train_labels = torch.tensor(train_data['Sold Price'].values.reshape(-1, 1),dtype=torch.float32
)# 是否使用GPU训练
if not torch.cuda.is_available():print('CUDA is not available. Training on CPU ...')
else:print('CUDA is available. Training on GPU ...')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 将特征和标签移到设备上
train_features = train_features.to(device)
test_features = test_features.to(device)
train_labels = train_labels.to(device)# 定义均方误差损失函数
loss = nn.MSELoss()# 输入特征的数量
in_features = train_features.shape[1]
# print(in_features)
# 195# 定义神经网络模型
dropout1, dropout2, dropout3 = 0.2, 0.3, 0.5def get_net():net = nn.Sequential(nn.Flatten(),nn.Linear(in_features, 128), nn.ReLU(),# nn.Dropout(dropout1),nn.Linear(128, 64), nn.ReLU(),# nn.Dropout(dropout2),nn.Linear(64, 32), nn.ReLU(),# nn.Dropout(dropout3),nn.Linear(32, 1))return net.to(device) # 使用GPU# 计算对数均方根误差
def log_rmse(net, features, labels):"""使用 torch.clamp 函数将预测值的下限限制在 1,确保所有预测值至少为 1。这是为了避免在取对数时出现负值或零值,因为对数在这些点上未定义或会导致数值问题。"""clipped_preds = torch.clamp(net(features), 1, float('inf'))rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))# 将 PyTorch 张量转换为 Python 标量return rmse.item()# 训练模型函数
def train(net, train_features, train_labels, test_features, test_labels,num_epochs, learning_rate, weight_decay, batch_size):train_ls, tets_ls = [], [] # 用于存储每个epoch的训练和测试损失train_iter = d2l.load_array((train_features, train_labels), batch_size) # 创建训练数据迭代器optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate,weight_decay=weight_decay) # 定义Adam优化器# weight_decay: 权重衰减,用于L2正则化。for epoch in range(num_epochs):for X, y in train_iter:X, y = X.to(device), y.to(device) # 确保批次数据在GPU上optimizer.zero_grad() # 梯度清零l = loss(net(X), y) # 计算损失l.backward() # 反向传播optimizer.step() # 更新模型参数# 计算并记录训练集上的对数均方根误差。train_ls.append(log_rmse(net, train_features, train_labels))if test_labels is not None:# 计算并记录测试集上的对数均方根误差tets_ls.append(log_rmse(net, test_features, test_labels))return train_ls, tets_ls# K折交叉验证
# 它选择第i个切片作为验证数据,其余部分作为训练数据
def get_k_fold_data(k, i, X, y):assert k > 1fold_size = X.shape[0] // kX_train, y_train = None, Nonefor j in range(k):idx = slice(j * fold_size, (j + 1) * fold_size)X_part, y_part = X[idx, :], y[idx]if j == i:X_valid, y_valid = X_part, y_partelif X_train is None:X_train, y_train = X_part, y_partelse:X_train = torch.cat([X_train, X_part], 0)y_train = torch.cat([y_train, y_part], 0)return X_train.to(device), y_train.to(device), X_valid.to(device), y_valid.to(device) # 确保在GPU上# 在K折交叉验证中训练K次后,返回训练和验证误差的平均值。
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,batch_size):train_l_sum, valid_l_sum = 0, 0for i in range(k):data = get_k_fold_data(k, i, X_train, y_train)net = get_net()train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,weight_decay, batch_size)train_l_sum += train_ls[-1]# 将 train_ls 列表中的最新值(即当前 epoch 的训练损失)累加到 train_l_sum 变量中。valid_l_sum += valid_ls[-1]if i == 0:d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],legend=['train', 'valid'], yscale='log')print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, 'f'验证log rmse{float(valid_ls[-1]):f}')return train_l_sum / k, valid_l_sum / k# 定义训练参数
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 0.01, 0, 256# 进行K折交叉验证
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, 'f'平均验证log rmse: {float(valid_l):f}')d2l.plt.show() # 提交Kaggle预测
def train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size):net = get_net()train_ls, _ = train(net, train_features, train_labels, None, None,num_epochs, lr, weight_decay, batch_size)d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',ylabel='log rmse', xlim=[1, num_epochs], yscale='log')print(f'训练log rmse:{float(train_ls[-1]):f}')# 将网络应用于测试集,并将结果从GPU转移到CPU再转换为NumPy数组preds = net(test_features).detach().cpu().numpy()# 将其重新格式化以导出到Kaggletest_data['Sold Price'] = pd.Series(preds.reshape(1, -1)[0])submission = pd.concat([test_data['Id'], test_data['Sold Price']], axis=1)submission.to_csv('../data/california-house-prices/submission.csv', index=False)# 训练模型并进行预测
train_and_pred(train_features, test_features, train_labels, test_data,num_epochs, lr, weight_decay, batch_size)d2l.plt.show()
运行结果:
折1,训练log rmse0.356748, 验证log rmse0.331666
折2,训练log rmse0.337252, 验证log rmse0.341875
折3,训练log rmse0.317294, 验证log rmse0.324516
折4,训练log rmse0.337175, 验证log rmse0.360625
折5,训练log rmse0.356537, 验证log rmse0.379667
5-折验证: 平均训练log rmse: 0.341001, 平均验证log rmse: 0.347670
训练log rmse:0.307162


竞赛得分:

相关文章:
动手学深度学习(Pytorch版)代码实践 -深度学习基础-13Kaggle竞赛:2020加州房价预测
13Kaggle竞赛:2020加州房价预测 # 导入所需的库 import numpy as np import pandas as pd import torch import hashlib import os import tarfile import zipfile import requests from torch import nn from d2l import torch as d2l# 读取训练和测试数据 train_…...

编程输出中间变量:深度解析与实战应用
编程输出中间变量:深度解析与实战应用 在编程过程中,中间变量是一个至关重要的概念。它们不仅有助于我们更好地理解和组织代码,还能提高程序的效率和可读性。那么,编程输出中间变量究竟是什么呢?本文将从四个方面、五…...

冒泡排序、选择排序
冒泡排序 按照冒泡排序的思想,我们要把相邻的元素两两比较,当一个元素大于右侧相元素时,交换它们的位置;当一个元素小于或等于右侧相邻元素时,位置不变 大的往右丢(往下沉),小的往…...

嵌入式实训day6
1、 from machine import Pin from neopixel import NeoPixel import timeif __name__"__main__"#创建RBG灯带控制对象,包含5个像素(5个RGB LED)rgb_led NeoPixel(Pin(4,Pin.OUT),5)#定义RGB颜色RED(255,0,0)GREEN(0,2…...

产品经理是青春饭吗?终于有了答案!
不少考生疑惑产品经理是青春饭吗?产品经理能干到多少岁?弄清楚这些问题,我们才会有长久的规划。产品经理是青春饭吗?产品经理能干到多少岁?一起来看看 一、产品经理是青春饭吗? 产品经理是否吃青春饭需要…...
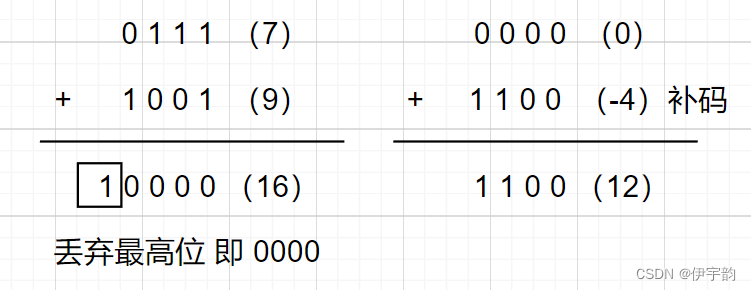
FPGA - 数 - 加减乘除
一,数的表示 首先,将二进制做如下解释: 2的0次方1 2的1次方2 2的2次方4 2的3次方8 ..... 以此类推,那么任何整数,或者说任意一个自然数均可以采用这种方式来表示。 例如,序列10101001,根据上述…...

软件性能测试之负载测试、压力测试详情介绍
负载测试和压力测试是软件性能测试中的两个重要概念,它们在保证软件质量和性能方面起到至关重要的作用,本文将从多个角度详细介绍这两种测试类型。 一、软件负载测试 负载测试是在特定条件下对软件系统进行长时间运行和大数据量处理的测试ÿ…...

科研辅助工具
科研工具收集 1. 如何筛选出最合适的SCI论文投稿杂志:点击直达 2. 分享三种正确查找期刊全称、缩写的网站: 点击直达...

亿达中国武汉园区入选“武汉市科技金融工作站”及“武汉市线下首贷服务站”
近日,武汉市2024科技金融早春行活动在深交所湖北资本市场培育基地举行。会上,第四批武汉市科技金融工作站试点单位名单及第五批武汉地区金融系统线下首贷服务站名单正式公布,武汉软件新城成功入选上述两个名单。 为缓解科技型企业融资难题&a…...
)
Docker配置阿里云加速器(2续)
默认情况下镜像是从docker hub下载,由于docker hub服务器在国外,由于网络原因镜像下载速度较慢,一般会配置镜像加速进行下载 国内镜像加速器有阿里云、网易云、中科大等,本章配置阿里云镜像加速器,速度较快 镜像加速源 镜像加速器 镜像加速器地址 <...

我用chatgpt写了一款程序
众所周知,Chatgpt能够帮助人们写代码,前几天苏音试着完全用Chatgpt写一款Python程序 有一句话我很赞同,未来能代替人的不是AI,是会使用AI的人。 最终,写下来效果还不错,完全提升了我的办公效率。 开发前…...
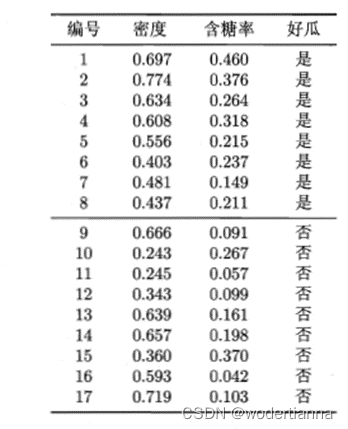
Python实现逻辑回归与判别分析--西瓜数据集
数据 数据data内容如下: 读取数据: import numpy as np import pandas as pd data pd.read_excel(D:/files/data.xlsx) 将汉字转化为01变量: label [] for i in data[好瓜]:l np.where(i 是,1,0)label.append(int(l)) data[label] lab…...
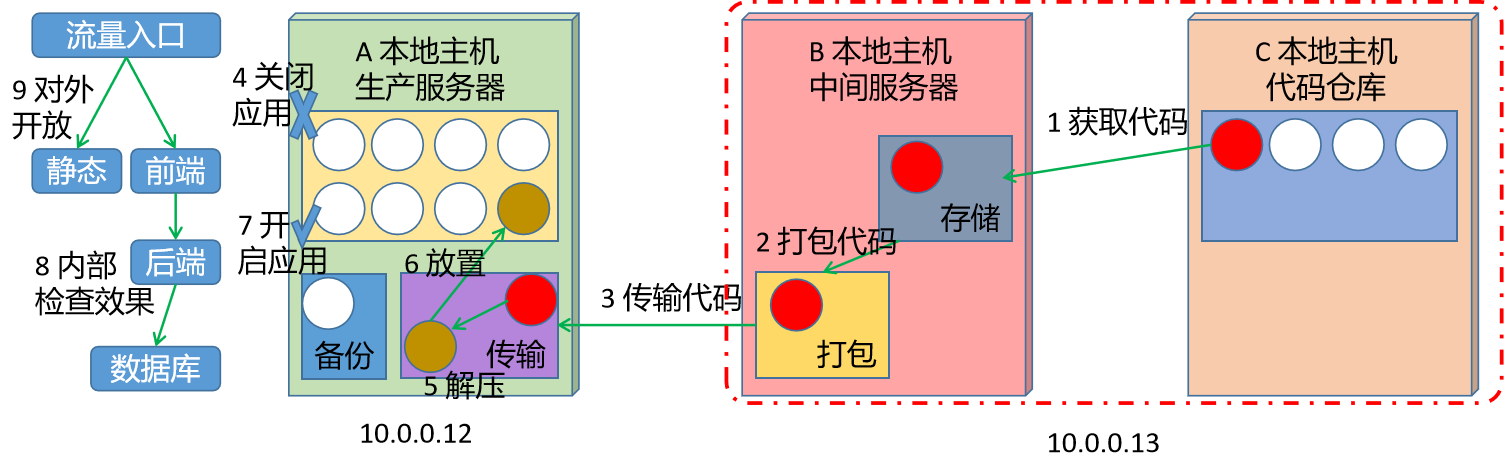
课时154:项目发布_手工发布_手工发布
1.2.3 手工发布 学习目标 这一节,我们从 基础知识、简单实践、小结 三个方面来学习 基础知识 简介 为了合理的演示生产环境的项目代码发布,同时又兼顾实际实验环境的资源,我们这里将 B主机和C主机 用一台VM主机来实现,A主机单…...
、ArkTS开发 --UI篇)
鸿蒙开发 一 (四)、ArkTS开发 --UI篇
相对布局 RelativeContainer 支持容器内部的子元素设置相对位置关系子元素支持指定兄弟元素作为锚点,也支持指定父容器作为锚点,基于锚点做相对位置布局 //alignRules 写法let AlignRus:Record<string,Record<string,string|VerticalAlign|Horiz…...

影音发烧友必入:高清先生M8 8K蓝光播放机使用体验8K播放器
影音发烧友必入:高清先生M8 8K蓝光播放机使用体验 高清先生在5.18成功举办新品8K蓝光播放机“M8”的发布会后,心心念念想尝鲜,于是果断下单了一台。 外形 收到货后,是牛皮纸包装,醒目的“高清先生”标识印在正面&…...

【34W字CISSP备考笔记】域1:安全与风险管理
1.1 理解、坚持和弘扬职业道德 1.1.1.(ISC)职业道德规范 1、行为得体、诚实、公正、负责、守法。 2、为委托人提供尽职、合格的服务。 3、促进和保护职业。 4、保护社会、公益、必需的公信和自信,保护基础设施。 1.1.2.组织道德规范 1、RFC 1087 ࿰…...

Camtasia Studio 2024软件下载附加详细安装教程
amtasia Studio 2024是一款功能强大的屏幕录制和视频编辑软件,由TechSmith公司开发。这款软件不仅能够帮助用户轻松地记录电脑屏幕上的任何操作,还可以将录制的视频进行专业的编辑和制作,最终输出高质量的视频教程、演示文稿、培训课程等。 …...
与机器学习(ML):塑造未来的技术引擎)
人工智能(AI)与机器学习(ML):塑造未来的技术引擎
目录 前言 一、人工智能(AI)概述 二、机器学习(ML)的作用:深入解析与应用前景 1、机器学习的作用机制 2、机器学习在各个领域的应用 3、机器学习的挑战与前景 三、AI与ML的融合与应用:深度解析与前景…...
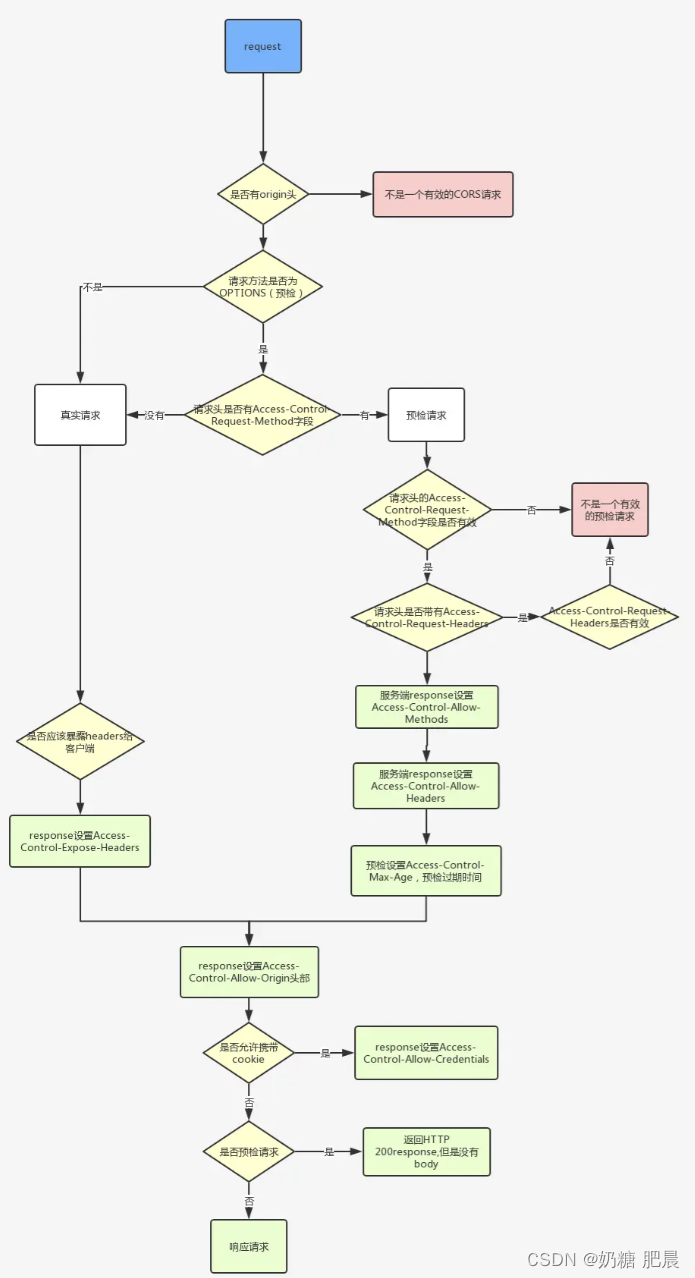
post为什么会发送两次请求详解
文章目录 导文跨域请求的预检复杂请求的定义服务器响应预检请求总结 导文 在Web开发中,开发者可能会遇到POST请求被发送了两次的情况,如下图: 尤其是在处理跨域请求时。这种现象可能让开发者感到困惑,但实际上它是浏览器安全机制…...

MySQl基础入门⑯【操作视图】完结
上一边文章内容 表准备 CREATE TABLE Students (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(100),email VARCHAR(255),major VARCHAR(100),score int,phone_number VARCHAR(20),entry_year INT,salary DECIMAL(10, 2) );数据准备 INSERT INTO Students (id, name, ema…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...
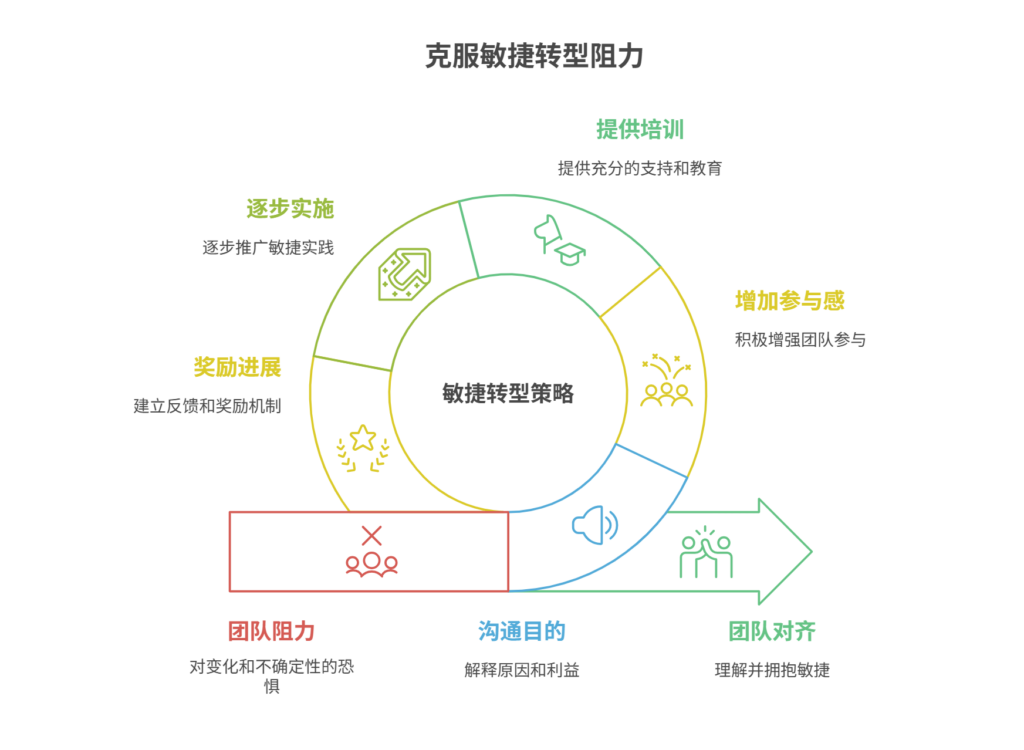
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...
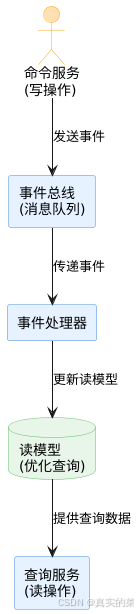
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...
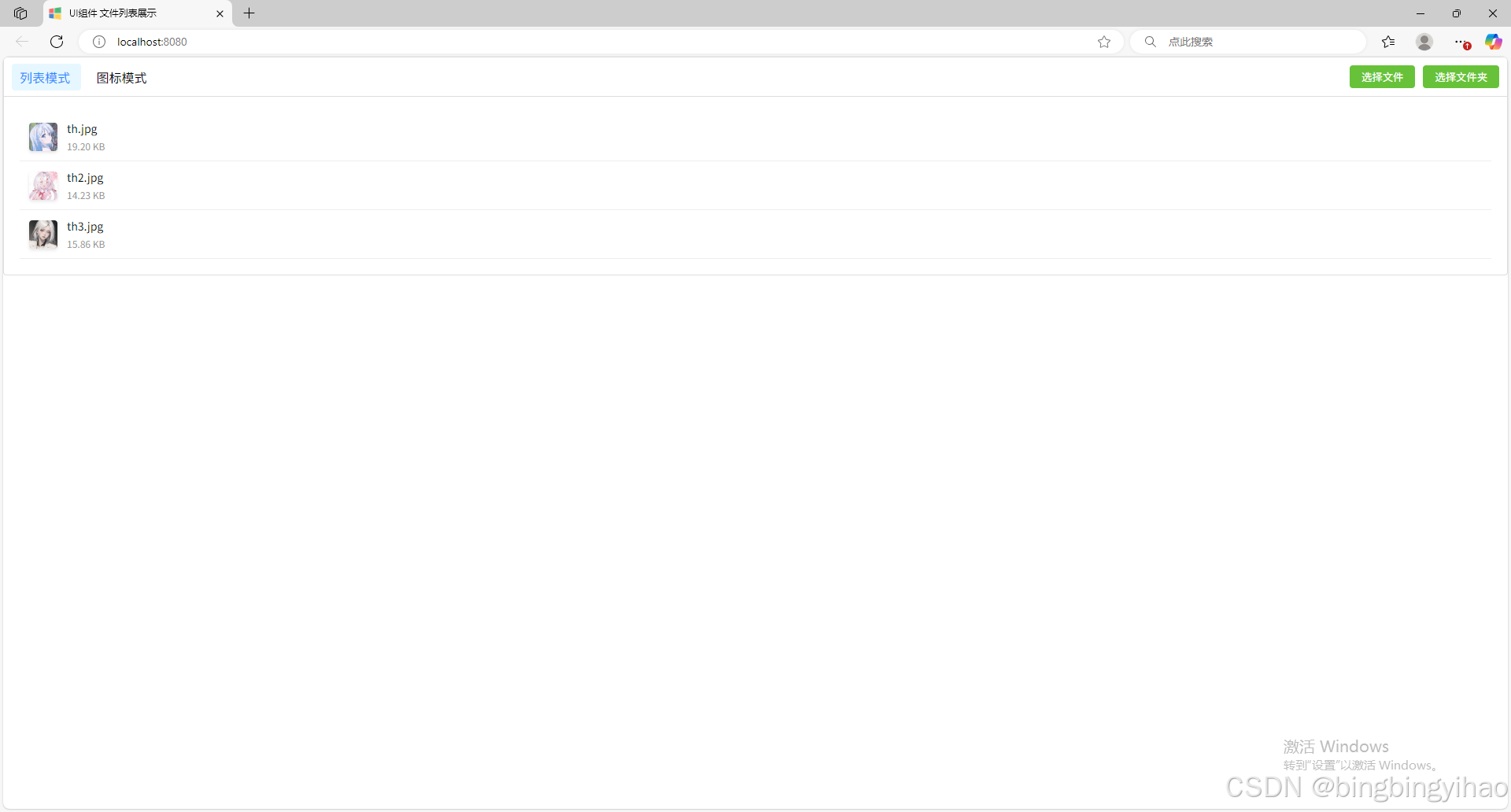
ui框架-文件列表展示
ui框架-文件列表展示 介绍 UI框架的文件列表展示组件,可以展示文件夹,支持列表展示和图标展示模式。组件提供了丰富的功能和可配置选项,适用于文件管理、文件上传等场景。 功能特性 支持列表模式和网格模式的切换展示支持文件和文件夹的层…...

webpack面试题
面试题:webpack介绍和简单使用 一、webpack(模块化打包工具)1. webpack是把项目当作一个整体,通过给定的一个主文件,webpack将从这个主文件开始找到你项目当中的所有依赖文件,使用loaders来处理它们&#x…...
)
stm32进入Infinite_Loop原因(因为有系统中断函数未自定义实现)
这是系统中断服务程序的默认处理汇编函数,如果我们没有定义实现某个中断函数,那么当stm32产生了该中断时,就会默认跑这里来了,所以我们打开了什么中断,一定要记得实现对应的系统中断函数,否则会进来一直循环…...

python读取SQLite表个并生成pdf文件
代码用于创建含50列的SQLite数据库并插入500行随机浮点数据,随后读取数据,通过ReportLab生成横向PDF表格,包含格式化(两位小数)及表头、网格线等美观样式。 # 导入所需库 import sqlite3 # 用于操作…...