笔记-python 中BeautifulSoup入门
在前面的例子用,我用了BeautifulSoup来从58同城抓取了手机维修的店铺信息,这个库使用起来的确是很方便的。本文是BeautifulSoup 的一个详细的介绍,算是入门把。文档地址:http://www.crummy.com/software/BeautifulSoup/bs4/doc/
什么是BeautifulSoup?
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
直接看例子:
#!/usr/bin/python# -*- coding: utf-8 -*-from bs4 import BeautifulSouphtml_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p><p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p><p class="story">...</p>"""soup = BeautifulSoup(html_doc)print soup.titleprint soup.title.nameprint soup.title.stringprint soup.pprint soup.aprint soup.find_all('a')print soup.find(id='link3')print soup.get_text()结果为:<title>The Dormouse's story</title>
title
The Dormouse's story
<p class="title"><b>The Dormouse's story</b></p>
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
…
可以看出:soup 就是BeautifulSoup处理格式化后的字符串,soup.title 得到的是title标签,soup.p 得到的是文档中的第一个p标签,要想得到所有标签,得用find_all
函数。find_all 函数返回的是一个序列,可以对它进行循环,依次得到想到的东西.
get_text() 是返回文本,这个对每一个BeautifulSoup处理后的对象得到的标签都是生效的。你可以试试 print soup.p.get_text()
其实是可以获得标签的其他属性的,比如我要获得a标签的href属性的值,可以使用 print soup.a[‘href’],类似的其他属性,比如class也是可以这么得到的(soup.a[‘class’])。
特别的,一些特殊的标签,比如head标签,是可以通过soup.head 得到,其实前面也已经说了。
如何获得标签的内容数组?使用contents 属性就可以 比如使用 print soup.head.contents,就获得了head下的所有子孩子,以列表的形式返回结果,
可以使用 [num] 的形式获得 ,获得标签,使用.name 就可以。
获取标签的孩子,也可以使用children,但是不能print soup.head.children 没有返回列表,返回的是 <listiterator object at 0x108e6d150>,
不过使用list可以将其转化为列表。当然可以使用for 语句遍历里面的孩子。
关于string属性,如果超过一个标签的话,那么就会返回None,否则就返回具体的字符串print soup.title.string 就返回了 The Dormouse’s story
超过一个标签的话,可以试用strings
向上查找可以用parent函数,如果查找所有的,那么可以使用parents函数
查找下一个兄弟使用next_sibling,查找上一个兄弟节点使用previous_sibling,如果是查找所有的,那么在对应的函数后面加s就可以
如何遍历树?
使用find_all 函数
find_all(name, attrs, recursive, text, limit, **kwargs)
举例说明:
print soup.find_all('title')
print soup.find_all('p','title')
print soup.find_all('a')
print soup.find_all(id="link2")
print soup.find_all(id=True)
返回值为:
[<title>The Dormouse's story</title>]
[<p class="title"><b>The Dormouse's story</b></p>]
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
通过css查找,直接上例子把:
print soup.find_all(“a”, class_=“sister”)
print soup.select(“p.title”)
通过属性进行查找
print soup.find_all(“a”, attrs={“class”: “sister”})
通过文本进行查找
print soup.find_all(text=“Elsie”)
print soup.find_all(text=[“Tillie”, “Elsie”, “Lacie”])
限制结果个数
print soup.find_all(“a”, limit=2)
结果为:
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[<p class="title"><b>The Dormouse's story</b></p>]
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[u'Elsie']
[u'Elsie', u'Lacie', u'Tillie']
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
总之,通过这些函数可以查找到想要的东西。
相关文章:

笔记-python 中BeautifulSoup入门
在前面的例子用,我用了BeautifulSoup来从58同城抓取了手机维修的店铺信息,这个库使用起来的确是很方便的。本文是BeautifulSoup 的一个详细的介绍,算是入门把。文档地址:http://www.crummy.com/software/BeautifulSoup/bs4/doc/ …...

Tomcat Websocket应用实例研究
概述 本文介绍了如何根据Tomcat给出的websocket实例,通过对实例的学习,定制自己基于websocket的应用。 环境及版本: Ubuntu 22.04.4 LTSApache Tomcat/10.1.20openjdk 11.0.23 2024-04-16浏览器:Chrome 相关资源及链接 Class…...

leetcode-11-二叉树前中后序遍历以及层次遍历
一、递归版 前序遍历 (先根遍历) 中左右 class Solution {public List<Integer> preorderTraversal(TreeNode root) {List<Integer> result new ArrayList<Integer>();preorder(root, result);return result;}public void preorder…...
——集合)
Python基础学习笔记(十一)——集合
目录 一、集合的介绍与创建二、集合的存储原理三、元素的修改1. 添加元素2. 删除元素 四、集合的运算五、集合的判定 一、集合的介绍与创建 集合(set),一种可变、无序、不重复的数据结构,由大括号{}内、用逗号分隔的一组元素组成。…...

FineReport
1.FineReport 官网 :FineReport产品简介- FineReport帮助文档 - 全面的报表使用教程和学习资料 下载地址 免费下载FineReport - FineReport报表官网 FineReport是一款用于报表制作,分析和展示的工具。 普通模板:是 FineReport 最常用…...

嵌入式就业前景好么
嵌入式就业前景在当前环境下是较为乐观的,以下是对嵌入式就业前景的详细分析: 广泛应用领域:嵌入式系统广泛应用于智能家居、医疗设备、航空航天等领域。随着物联网(IoT)的快速发展,预计到2024年ÿ…...
为啥找对象千万别找大厂男,还好我不是大厂的。。
网上看到一大厂女员工发文说:找对象千万别找大厂男,理由说了一大堆,无非就是大厂男为了逃避带娃,以加班为由宁愿在工位上玩游戏也不愿回家。当然这种观点有的人赞同有的人反对。 网友精彩评论: --------------下面是今…...

如何查看k8s中service的负载均衡策略
在Kubernetes中,Service的负载均衡策略一般由kube-proxy负责,kube-proxy使用iptables或IPVS规则进行负载均衡。默认情况下,kube-proxy使用的是轮询(Round Robin)策略,但是在使用IPVS模式时,可以…...
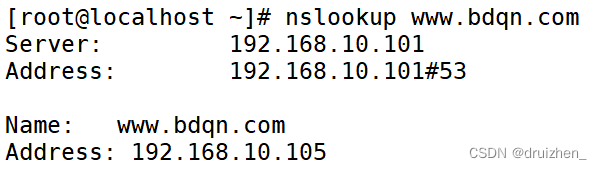
Linux-DNS域名解析服务01
BIND 域名服务基础 1、DNS(Domain Name System)系统的作用及类型 整个 Internet 大家庭中连接了数以亿计的服务器、个人主机,其中大部分的网站、邮件等服务器都使用了域名形式的地址,如 www.google.com、mail.163.com 等。很显然…...

[c++刷题]贪心算法.N01
题目如上: 首先通过经验分析,要用最少的减半次数,使得数组总和减少至一半以上,那么第一反应就是每次都挑数组中最大的数据去减半,这样可以是每次数组总和值减少程度最大化。 代码思路:利用大根堆去找数据中的最大值,…...

推荐常用的三款源代码防泄密软件
三款源代码防泄密软件——安秉源代码加密、Virbox Protector 和 MapoLicensor——确实各自在源代码保护的不同方面有其专长。这些软件可以满足企业对于源代码保护的三大需求:防止泄露、防止反编译和防止破解。 安秉源代码加密: 专注于源代码文件的加密&…...
Android 13 高通设备热点低功耗模式(2)
前言 之前写过一篇文章:高通热点被IOS设备识别为低数据模式,该功能仿照小米的低数据模式写的,散发的热点可以达到被IOS和小米设备识别为低数据模式。但是发现IOS设备如果后台无任何网络请求的时候,息屏的状态下过一会,会自动断开热点的连接。 分析 抓取设备的热点相关的…...

web前端任职条件:全面解析
web前端任职条件:全面解析 在当今数字化快速发展的时代,Web前端技术已经成为互联网行业不可或缺的一部分。作为一名Web前端开发者,需要具备哪些任职条件呢?本文将从四个方面、五个方面、六个方面和七个方面为您深入剖析。 四个方…...

分析医药零售数据该用哪个BI数据可视化工具?
数据是企业决策的重要依据,可以用于现代企业大数据可视化分析的BI工具有很多,各有各擅长的领域。那么哪个BI数据可视化工具分析医药零售数据又好又快? 做医药零售数据分析首推奥威BI数据可视化工具! 奥威BI数据可视化工具做医药…...

如何使用芯片手册做软件开发?
在阅读和利用芯片手册进行软件开发时,你应该关注以下几个关键点: 引脚功能:了解芯片上每个引脚的功能,包括它们可以被配置为输入还是输出,以及它们支持的特殊功能,如模拟输入、PWM输出、中断等。 寄存器映…...

基于深度学习的文本翻译
基于深度学习的文本翻译 基于深度学习的文本翻译,通常称为神经机器翻译(Neural Machine Translation, NMT),是近年来在自然语言处理(NLP)领域取得显著进展的技术。NMT通过使用深度神经网络来自动学习和翻译…...
Unity制作透明材质直接方法——6.15山大软院项目实训
之前没有在unity里面接触过材质的问题,一般都是在maya或这是其他建模软件里面直接得到编辑好材质的模型,然后将他导入Unity里面,然后现在碰到了需要自己在Unity制作透明材质的情况,所以先搜索了一下有没有现成的方法,很…...
)
【HarmonyOS NEXT】如何通过h5拉起应用(在华为浏览器中拉起应用)
华为浏览器支持拉起外部应用 浏览器访问网页经常会遇到deeplink的场景。当前处理方案统一为使用AMS系统能力startAbility去隐式拉起。传递的want参数为 { "actions": "ohos.want.action.viewData", "uri": deeplink链接 } 网页需要给自己的应用拉…...

模板方法模式(大话设计模式)C/C++版本
模板方法模式 C #include <iostream> using namespace std;class TestPaper { public:void TestQ1(){cout << "杨过得到,后来给了郭靖,炼成倚天剑,屠龙刀的玄铁可能是[ ]\na.球磨铸铁 b.马口贴 c.高速合金钢 d.碳素纤维&qu…...

数据提取:数据治理过程中的质量保障
一、引言 在数字化时代,数据已经成为企业决策和运营的核心资源。然而,数据的价值并不仅仅在于其数量,更在于其质量。数据治理作为确保数据质量、安全性和一致性的重要手段,对于企业的长期发展至关重要。其中,数据提取…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...
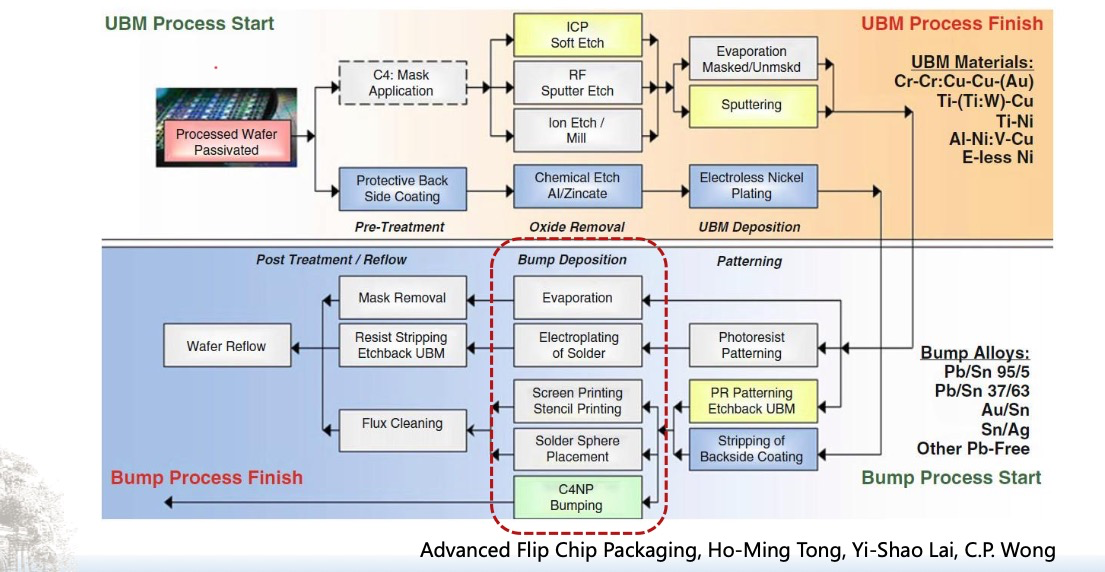
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...

文件上传漏洞防御全攻略
要全面防范文件上传漏洞,需构建多层防御体系,结合技术验证、存储隔离与权限控制: 🔒 一、基础防护层 前端校验(仅辅助) 通过JavaScript限制文件后缀名(白名单)和大小,提…...

十二、【ESP32全栈开发指南: IDF开发环境下cJSON使用】
一、JSON简介 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,具有以下核心特性: 完全独立于编程语言的文本格式易于人阅读和编写易于机器解析和生成基于ECMAScript标准子集 1.1 JSON语法规则 {"name"…...
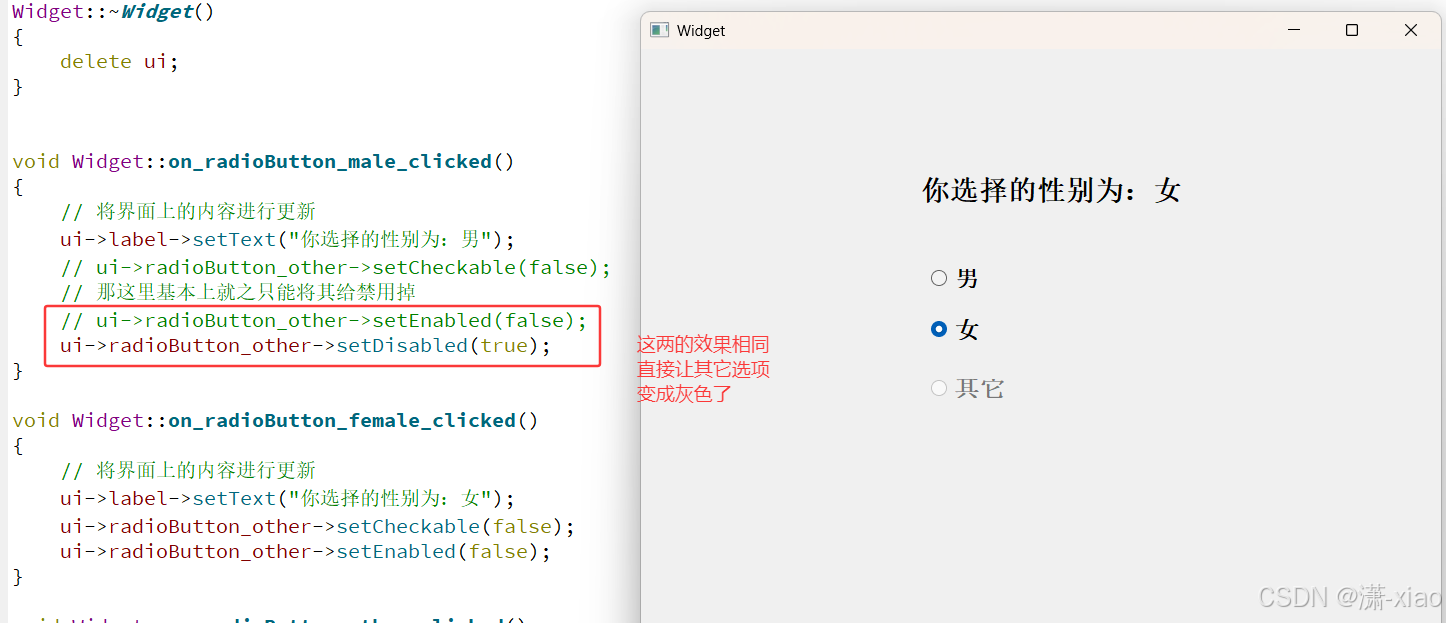
Qt 按钮类控件(Push Button 与 Radio Button)(1)
文章目录 Push Button前提概要API接口给按钮添加图标给按钮添加快捷键 Radio ButtonAPI接口性别选择 Push Button(鼠标点击不放连续移动快捷键) Radio Button Push Button 前提概要 1. 之前文章中所提到的各种跟QWidget有关的各种属性/函数/方法&#…...

JS面试常见问题——数据类型篇
这几周在进行系统的复习,这一篇来说一下自己复习的JS数据结构的常见面试题中比较重要的一部分 文章目录 一、JavaScript有哪些数据类型二、数据类型检测的方法1. typeof2. instanceof3. constructor4. Object.prototype.toString.call()5. type null会被判断为Obje…...