C/C++ string模拟实现
1.模拟准备
1.1因为是模拟string,防止与库发生冲突,所以需要命名空间namespace隔离一下,我们来看一下基本内容
namespace yx
{class string{private://char _buff[16]; lunix下小于16字节就存buff里char* _str;size_t _size;size_t _capacity;};
}1.2我们这里声明和定义分离,分为string.h和string.cpp
最简单的是:把声明和定义都往命名空间里包就可以
2.模拟实现
2.1遇到一个类,先来写构造和析构
构造和析构
我们来看一下下面代码对不对
namespace yx
{ string::string(const char* str):_str(str){}
}既然这么问了,那肯定是不对的,
因为你初始化string的时候,可能为常量字符串初始化的,它是不可以作为初始化对象的,当你扩容、修改就没法改了
yx::string s1("hello world");应该这样玩:
namespace yx
{ string::string(const char* str):_str(new char[strlen(str) + 1]){}
}我和你开一样的空间
完整写法👇
string::string(const char* str):_str(new char[strlen(str) + 1]), _size(strlen(str)), _capacity(strlen(str))
{strcpy(_str, str);
}但还是有点问题的,strlen的效率还是有点底的,它和sizeof不一样,sizeof是在编译时运行,根据存储规则,内存对齐规则来算,strlen是运行时算的,三个strlen就重复运算了。
我们可以把size放在初始化列表,把其他的放在函数体初始化
string::string(const char* str): _size(strlen(str))
{_str = new char[_size + 1];_capacity = _size;strcpy(_str, str);
}这是比较传统的写法,我们来看一下同样手法
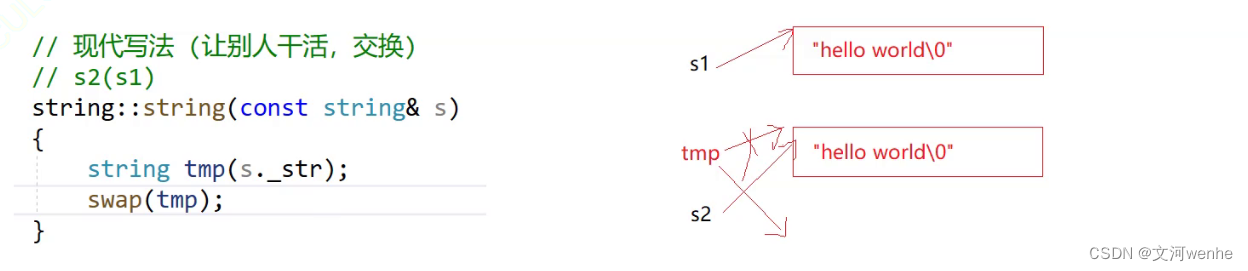
tring::string(const string& s)
{string tmp(s._str);std::swap(tmp._str, _str);std::swap(tmp._size, _size);std::swap(tmp._capacity, _capacity);
}创建一个临时变量tmp,s1给给tmp,然后把s2指向tmp,tmp指向s2的位置.
c_str
const char* c_str() const;const char* string::c_str() const
{return _str;
}加const是为了让const或非const成员都能访问到,c_str()的类型为const char*,相当于常量字符串,遇到\0就会停止
无参string
我们可不可以这样写呢?
string::string()
{_str = nullptr;_size = 0;_capacity = 0;
}看起来可以,但实际不可以,这里的delete和free是不会出问题的,因为delete是可以空指针的
我们看例子,后定义的先析构,程序崩溃了,为什么呢?
c_str ,类型为const char* 不会按指针打印,是常量字符串,就会解引用找到\0才停止。
但库里不会崩溃
为什么?
因为这个地方不是没有空间,库里面开了一个空间
所以初始化要改为
string::string()
{_str = new char[1] {'\0'};_size = 0;_capacity = 0;
}
new一个空间,而实践中不会这样写,无参的和带参的是可以和成一个的,就是全缺省
如下👇,冒号里的\0是可以不写的 默认就是\0 , 给的是字符串
namespace yx
{class string{public://string(); //无参构造 string(const char* str = "\0");~string();const char* c_str() const;//加上const,const成员和非const成员都可以调用private://char _buff[16]; lunix下小于16字节就存buff里char* _str;size_t _size;size_t _capacity;};
}遍历:运算符重载[] 和 size()
char& string::operator[](size_t pos)
{assert(pos < _size);return _str[pos];
}size_t string::size() const
{return _size;
}测试:可读可写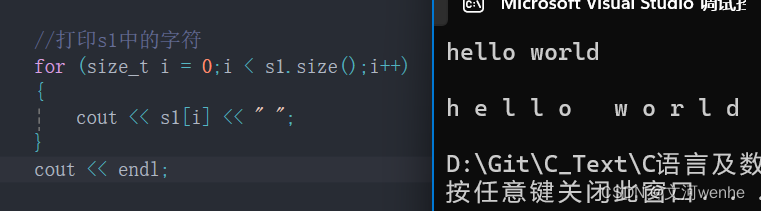
迭代器:begin 和 end
实现方式有两种,自定义类型的和简单点的,我们这里使用简单的
typedef char* iterator;iterator begin();
iterator end();string::iterator string::begin()
{return _str;
}
string::iterator string::end()
{return _str + _size;
}为什么这样写?

注:
这里必须用typedef,为什么?迭代器体现的是一种封装
这里的typedef相当于把char*用iterator封装起来,而且这里的迭代器一定是char*吗,在lunix下是char*吗,不同平台是不同的。
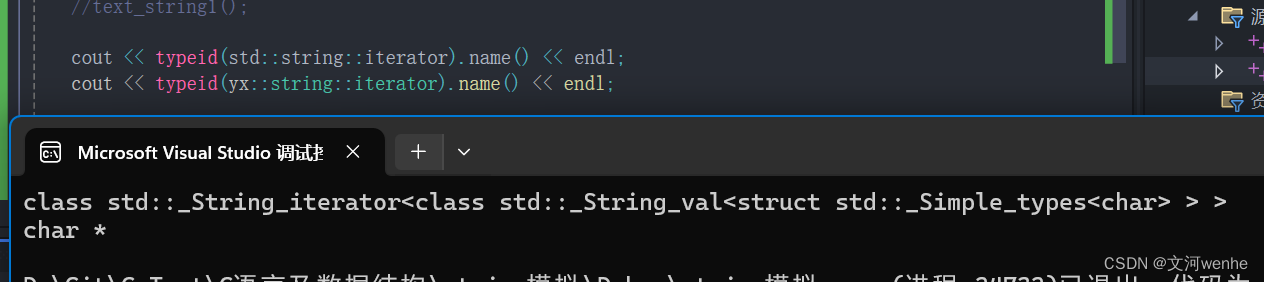
把不同类型,不同平台的类型都封装成Iterator,隐藏的底层的细节。它是一个像指针的东西。iterator的原生类型是不确定的,给了一种简单通用访问容器的方式。
无论哪个容器都重命名为iterator,各个类域也不会发生冲突。
const迭代器
定义及实现
const_iterator begin() const;
const_iterator end() const;string::const_iterator string::begin() const
{return _str;
}这里可以直接返回_str,_str类型为char*,begin为const char* ,相当于权限缩小。
string::const_iterator string::end() const
{return _str + _size;
}这里也是权限缩小,下面我们测试一下
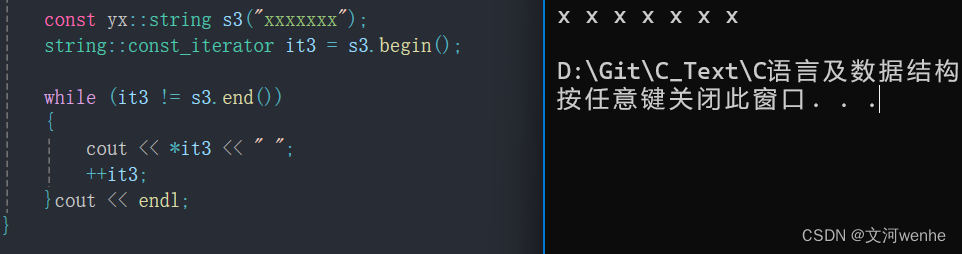 测试成功,而且是不能给常量赋值的,如下👇
测试成功,而且是不能给常量赋值的,如下👇

如果我们用方括号加size来遍历呢?
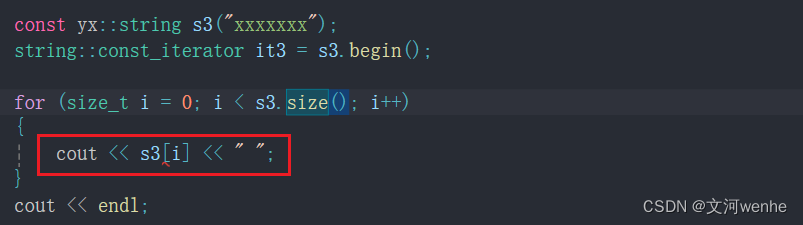
这里会报错,为啥?因为s3是常量,所以还需要重载一个const修饰的operator[]
const char& operator[](size_t pos) const;const char& string::operator[](size_t pos) const
{assert(pos < _size);return _str[pos];
}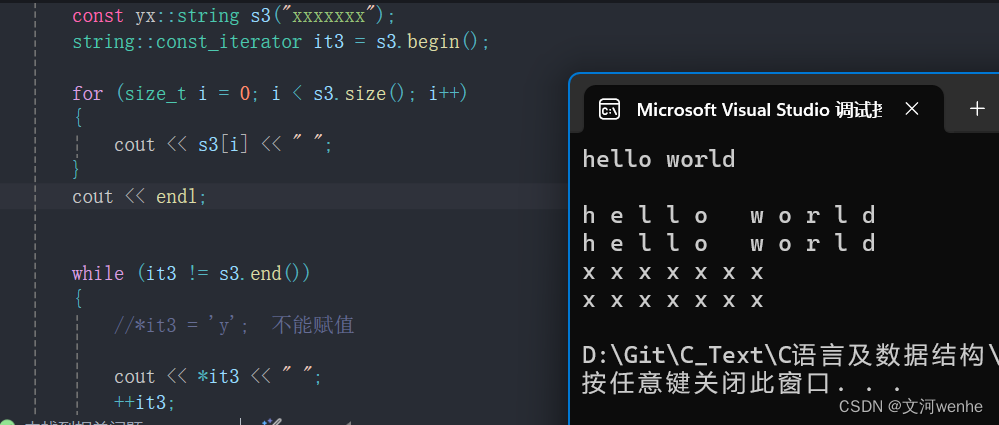
测试通过。
push_back() 、 append() 和 reserve()
完成了string的基本功能,下面我们来进行string的插入。
push_back()是尾插一个字符,append()插入一个字符串,这里我们会遇到一个问题,push_back()尾插扩容一倍或两倍,不会太大;append()是插入一个字符串,有可能需要扩容,但扩容多少呢?插入字符串长短不定,万一非常长,你扩容二倍?显然扩容多少倍是不确定的。这里我们引入reserve().
reserve()请求保留空间,一般不会缩容,如果空间比capacity大了就会扩容
void string::reserve(size_t n)
{if (n > _capacity){char* tmp = new char[n + 1];//为什么预留一个空间? 因为\0是不算在里面的strcpy(tmp,_str);delete[] _str;//释放旧空间_str = tmp;//指向新空间_capacity = n;}
}push_back()
void string::push_back(char ch)//插入字符
{if (_size == _capacity)//如果size 等于 容量大小才会扩容{size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);//传给reserve,如果比当前capacity大,就扩容}_str[_size] = ch;//_size是最后一个字符的下一个位置_str[_size + 1] = '\0';++_size;
}满足扩容条件才扩容,_size是最后一个字符的下一个位置,也就是\0的位置,所以需要把\0也处理一下。
append()
我们来看一下下面代码正确否?
void string::append(const char* str)//插入字符串
{size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);//现在有_size个,我们需要插入长度为len的字符串}strcat(_str, str);_size += len;
}使用了strcat(),直接在原字符串后面追加,我们测试一下

测试没问题。但是我们用strcat的时候要谨慎一些,他会从头开始找\0,效率低,这里我们采用strcpy(),从指定位置开始拷贝,带\0
void string::append(const char* str)//插入字符串
{size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);//现在有_size个,我们需要插入长度为len的字符串}strcpy(_str + _size, str);_size += len;
}同样测试通过,但效率很高
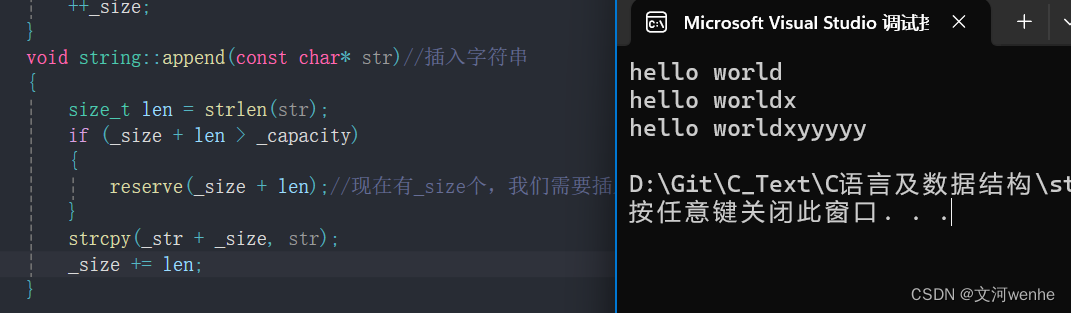
直接从\0位置开始插入

operator+=
说到尾插字符串,那必须得提到+=运算符重载,这里提供俩个版本
这里引用返回,返回对象本身,出了作用域对象还存在。
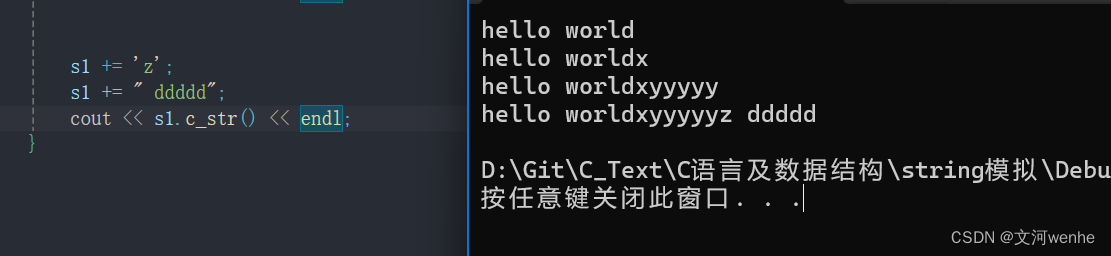
string& operator+=(char ch);//+=是需要返回值的,用引用返回减少拷贝
string& operator+=(const char ch);这里我们直接调用push_bakc和append
string& string::operator+=(char ch)
{push_back(ch);return *this;
}
string& string::operator+=(const char* str)
{append(str);return *this;
}测试
inset() 和 erase()
size_t insert(size_t pos,char ch); //pos位插入字符
size_t insert(size_t pos,const char* ch);//插入字符串
void erase(size_t pos, size_t len = npos);//pos开始删除len个字符private://char _buff[16]; lunix下小于16字节就存buff里char* _str;size_t _size;size_t _capacity;const static size_t npos;对于npos,静态成员如何初始化,在类里面声明,在类外定义。
类里的静态成员遍历,相当于全局变量,如果在string.h里定义,在预处理以后,string
.h会在string.cpp和test.cpp里展开,展开两份,俩文件最后生成.o文件,再一链接就出问题了,
声明和定义分离的时候把定义放在.cpp,声明放在.h。
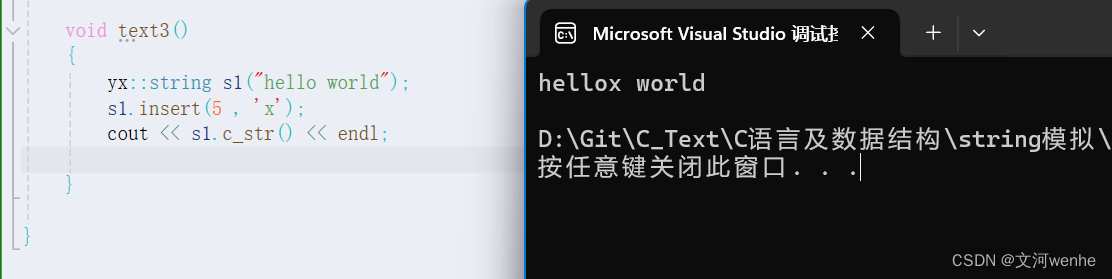
insert()插入一个字符
size_t string::insert(size_t pos, char ch)
{if (_size == _capacity)//空间不够,就扩容{size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}size_t end = _size;while (end >= pos){_str[end + 1] = _str[end];--end;}_str[pos] = ch;++_size;
}测试
如果我们在0出插入一个字符呢?
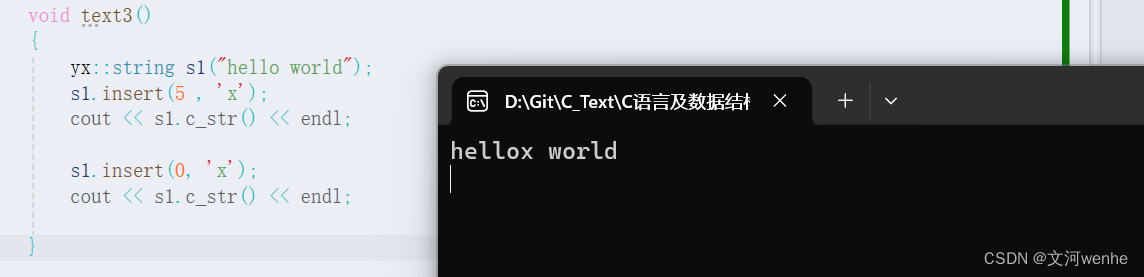
显然报错了,为什么?
因为edn >= 0 继续交换,把0之前的哪个未知值也交换进去了,
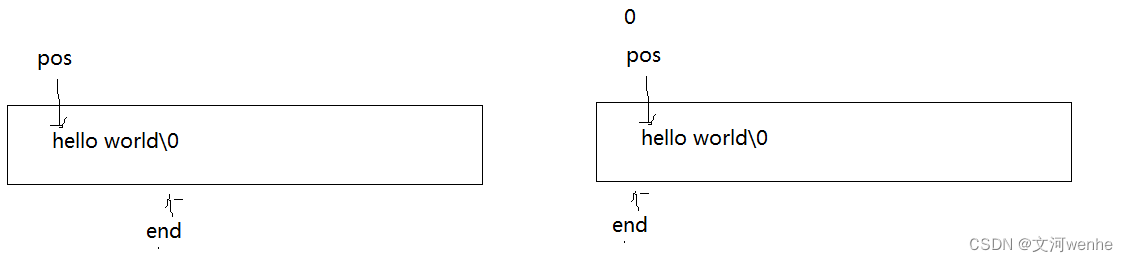
当end >= pos = 0 时,已将交换完了,但又进入循环了,为什么?因为当操作符两边的操作数类型不同的时候,会发生隐式类型转化,当有符号遇到无符号,有符号转换为无符号,end变为非常大的数,end依据大于pos。那有什么方法来修改呢?
我们是否可以把pos改为int类型呢?答案是不建议,因为我们要与库里的类型一样。
直接把pos强制转为int,运行测试提供。
void string::insert(size_t pos, char ch)
{if (_size == _capacity)//空间不够,就扩容{size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}size_t end = _size;while (end >= (int)pos){_str[end + 1] = _str[end];--end;}_str[pos] = ch;//把字符放进去++_size;
}那么我们可以不强转可以修改吗?可以
这里最根本的问题点在于end >= pos,只要是无符号遇到>=绝对是坑,无符号最小就是0,无法停止,非常扯淡。
这里我们去掉= ,把end的位置变为_size + 1,把前一个往后挪。
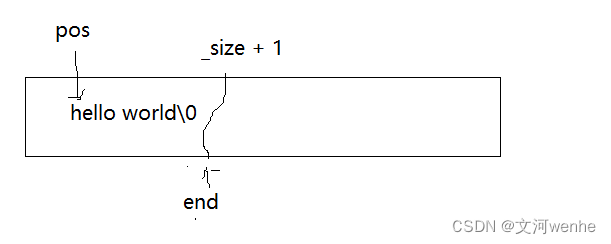

代码修改为:
void string::insert(size_t pos, char ch)
{if (_size == _capacity)//空间不够,就扩容{size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;reserve(newcapacity);}size_t end = _size + 1;while (end > pos){_str[end] = _str[end - 1];--end;}_str[pos] = ch;//把字符放进去++_size;
}测试通过
insert()插入一个字符串
void insert(size_t pos,const char* str);//插入字符串
首先pos不能越界,检查是否需要扩容,
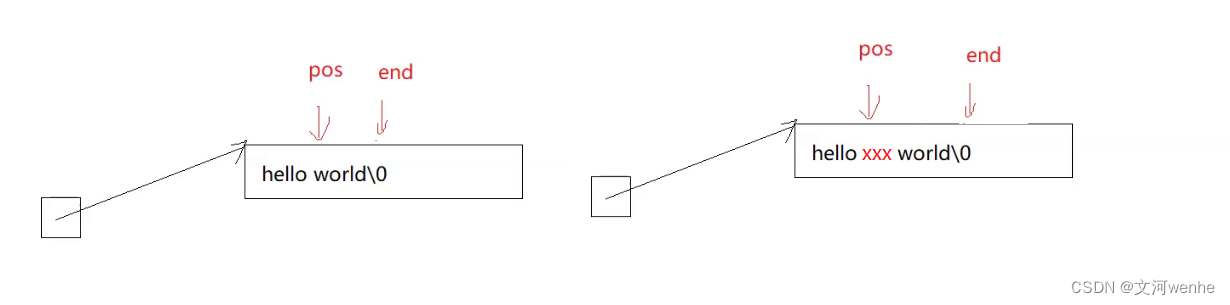
把xxx拷贝进去,不能用strcpy,它携带了\0,我们可以用strncpy或memcpy,这里我们采用memcpy
代码:
void string::insert(size_t pos, const char* str)
{ assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}int end = _size;while (end >= pos){_str[end + len] = _str[end];--end;}memcpy(_str + pos, str, len);_size += len;}测试通过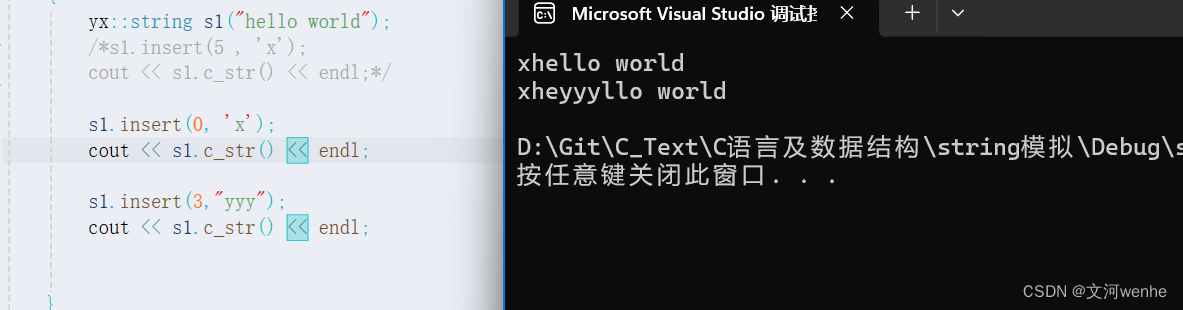
这是我们在0出插入,还是会遇到之前的问题
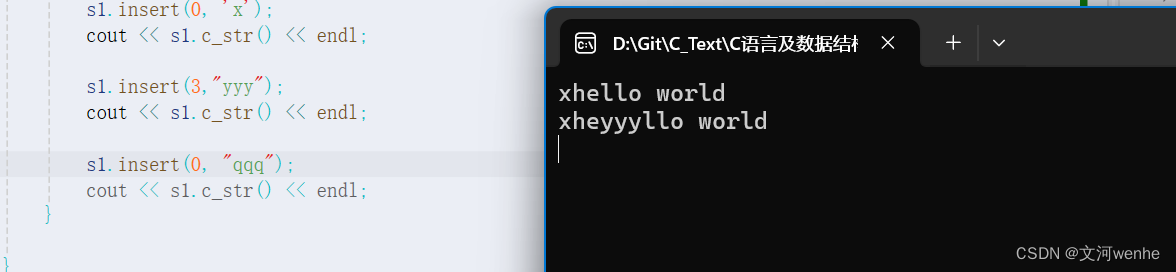
我们只需要把pos强制类型转化为int即可。
如果我们不想用这种方式,我们把=去掉,把前一个往后挪,
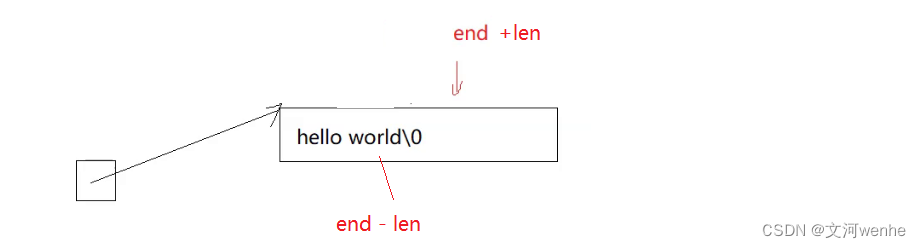
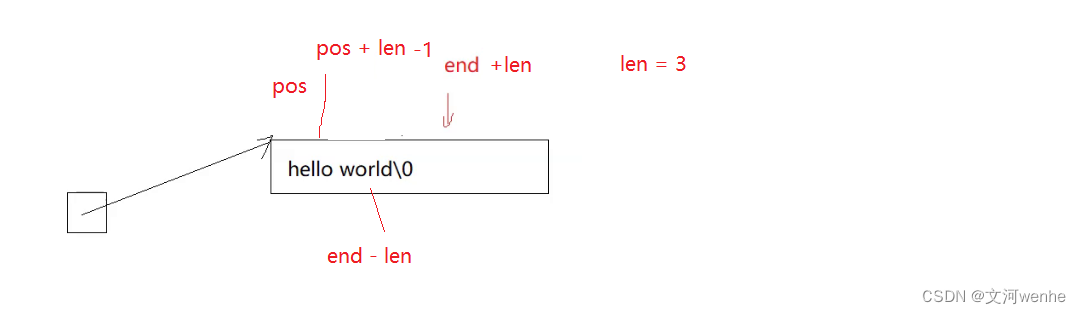
到pos + len依旧需要挪动,可以写成end>=pos+len
void string::insert(size_t pos, const char* str)
{ assert(pos <= _size);size_t len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}/*int end = _size;while (end >=(int) pos){_str[end + len] = _str[end];--end;}*/size_t end = _size + len;//len插入字符串长度while (end > pos + len - 1){_str[end] = _str[end - len];--end;}memcpy(_str + pos, str, len);_size += len;}erase()
void erase(size_t pos, size_t len = npos);//pos开始删除len个字符
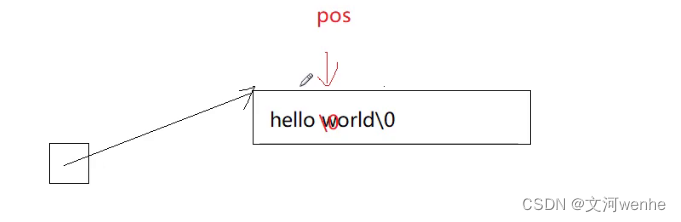

代码:第一种情况,删除的长度大于pos后的长度,直接全部删除;第二种情况,直接把不删除的字符覆盖在要删除的字符上。
void string::erase(size_t pos = 0, size_t len = npos)
{assert(pos < _size);if (len == npos || len >= _size - pos)//删除的字符大于pos后的字符{_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str + pos + len);_size -= len; }}find()
查找一个字符
size_t string::find(char ch, size_t pos = 0)
{for (size_t i = 0; i < _size; i++){if (_str[i] == ch){return i;}}return npos;
}查找一个子串
size_t string::find(const char* sub, size_t pos = 0)//从pos位置开始查找
{const char* p = strstr(_str + pos, sub);//在_str 种匹配sub子串,,返回对应位置指针return p - _str;//指针相减获取下标
}测试通过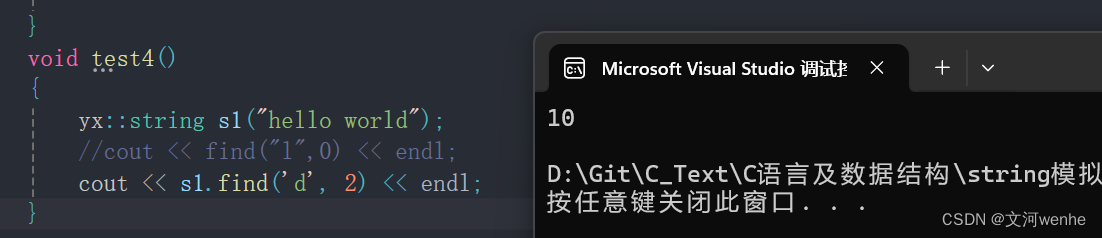
运算符重载 =
看下面代码,s1赋值拷贝给s2,s3赋值给s1,下面程序有没有问题呢?
void test5()
{yx::string s1("hello world");yx::string s2(s1);cout << s1.c_str() << endl;cout << s2.c_str() << endl;yx::string s3("yyyy");s1 = s3; // s3赋值给s1cout << s1.c_str() << endl;cout << s3.c_str() << endl;
}当然是有问题的,当我们没有运算符重载=时,编译器会默认提供一个版本,会执行浅拷贝,当 s2 被创建为 s1 的副本时,s2 实际上可能仅仅是指向 s1 所指向的字符串常量的另一个指针。这意味着,如果改变 s2 所指向的内容,s1 的内容也会随之改变。所以需要我们实现深拷贝版本。
修正:
string& string::operator=(const string& s)
{if (this != &s){char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;}
}重新开一个空间tmp,把需要拷贝的字符串拷贝进去,然后释放旧空间,把new的空间给给原空间
而且为了避免自己给自己赋值,需要再套一个判断 this != &s
优化写法:
s1 = s3,s是s3的别名
string& string::operator=(const string& s){if (this != &s){string tmp(s._str);this->swap(tmp);}return *this;}
s3拷贝给s1,设置一个临时变量tmp,s3拷贝构造tmp,然后再交换s1和tmp的空间。
而且tmp是个局部对象,出了作用域会析构,免去了释放空间这一步
最简化的写法:
s1 = s3
string& operator=(string tmp);string& string::operator=(string tmp)
{swap(tmp);return *this;
}和上面最大的区别在于没有引用,s3拷贝构造tmp,然后s1和tmp交换,和上面的道理一样,tmp是临时对象,出了作用域自动销毁,效率并没有提示,只是简化了代码
swap()
如果我们swap一下s1 和 s2呢?库里的swap能否帮我们完成任务呢?答案是可以的,因为他是模板,但是它的代价非常大,
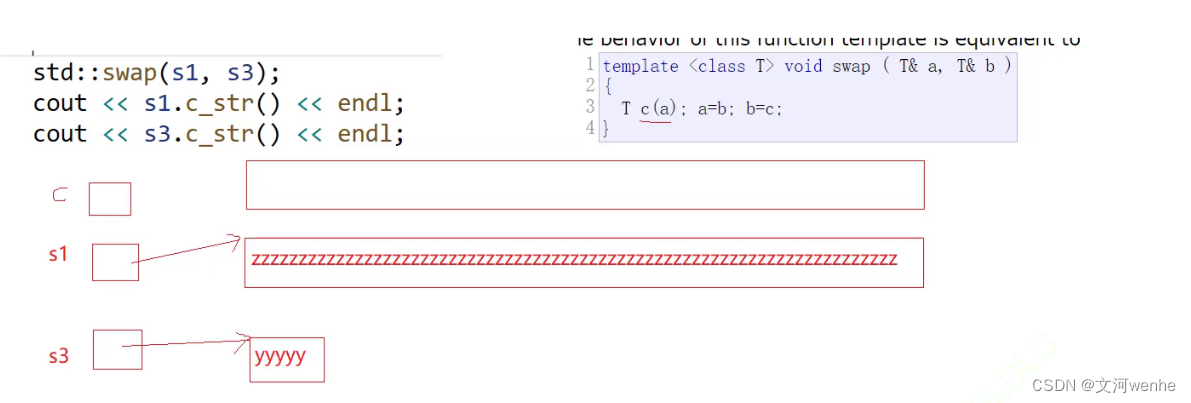
a 拷贝给 c,b 赋值给 a,c赋值给b,都会开空间,拷贝数据,传值传参代价都非常大。
自己实现:
void string::swap(string& s)
{std::swap(_str, s._str);//交换char*指针,size capacitystd::swap(_size, s._size);std::swap(_capacity, s._capacity);
}通过命名空间,来使用库里的swap,如果不写std,swap就会调用自己,而且这里面交换的都是内置类型
strsub()
从pos位置开始,取len个字符的子串
代码实现:
string string::substr(size_t pos, size_t len)
{if (len > _size - pos)//如果len大于pos后面的长度,有多少取多少{string sub(_str + pos);//_str(开始的指针 ) + pos 从pos位置开始取,然后构造一个子串返回return sub;}else{string sub;sub.reserve(len);//扩容for (size_t i = 0;i< len ;i++){sub += _str[pos + i];}return sub;}
}运算符重载 < > <= >= == !=
bool string::operator<(const string& s) const //比较大小
{return strcmp(_str, s._str) < 0;
}
bool string::operator>(const string& s) const
{return !(*this <= s);
}
bool string::operator<=(const string& s) const
{return *this < s || *this == s;
}
bool string::operator>=(const string& s) const
{return !(*this < s);
}
bool string::operator==(const string& s) const
{return strcmp(_str, s._str);
}
bool string::operator!=(const string& s) const
{!(*this == s);
}其实这里写两个,然后取反复用就可以。
流插入和流提取operator<< >>
istream& operator>>(istream& is, string& str)// is - cin
{char ch = is.get();is >> ch;while (ch != ' ' || ch != '\n')//不等于空格或换行{str += ch;//在io流里提取一个一个的char += 到str里char ch = is.get();}return is;
}
ostream& operator<<(ostream& os, const string& str)//os - cout
{for (size_t i = 0; i < str.size(); i++){os << str[i];//一个一个插入}return os;
}流插入和流提取的运算符重载不能写成成员函数,且不一定写成友元。
cin是不能获取空格的,而scanf可以 当输入 y 空格 y 时, 写两个cin ,两个cin都会获得y,而忽略空格。
clear()
void string::clear() //请调当前的数据
{_str[0] = '\0';_size = 0;
}相关文章:
C/C++ string模拟实现
1.模拟准备 1.1因为是模拟string,防止与库发生冲突,所以需要命名空间namespace隔离一下,我们来看一下基本内容 namespace yx {class string{private://char _buff[16]; lunix下小于16字节就存buff里char* _str;size_t _size;size_t _capac…...
:behaviors代码复用)
微信小程序学习(八):behaviors代码复用
小程序的 behaviors 方法是一种代码复用的方式,可以将一些通用的逻辑和方法提取出来,然后在多个组件中复用,从而减少代码冗余,提高代码的可维护性。 如果需要 behavior 复用代码,需要使用 Behavior() 方法,…...
】)
【The design pattern of Attribute-Based Dynamic Routing Pattern (ADRP)】
In ASP.NET Core, routing is one of the core functionalities that maps HTTP requests to the corresponding controller actions. While “Route-Driven Design Pattern” is a coined name for a design pattern, we can construct a routing-centric design pattern base…...

2713. 矩阵中严格递增的单元格数
题目 给定一个 m x n 的整数矩阵 mat,我们需要找出从某个单元格出发可以访问的最大单元格数量。移动规则是可以从当前单元格移动到同一行或同一列的任何其他单元格,但目标单元格的值必须严格大于当前单元格的值。需要返回最大可访问的单元格数量。 示例…...

git创建子模块
有种情况我们经常会遇到:某个工作中的项目需要包含并使用另一个项目。 也许是第三方库,或者你独立开发的,用于多个父项目的库。 现在问题来了:你想要把它们当做两个独立的项目,同时又想在一个项目中使用另一个。 Git …...
把Deepin塞进U盘,即插即用!Deepin To Go来袭
前言 小伙伴之前在某篇文章下留言说:把Deepin塞进U盘的教程。 这不就来了吗? 事实是可以的。这时候你要先做点小准备: 一个大小为8GB或以上的普通U盘 一个至少64GB或以上的高速U盘 一个Deepin系统镜像文件 普通U盘的大概介绍࿱…...

给【AI硬件】创业者的论文、开源项目和产品整理
一、AI 硬件精选论文 《DrEureka: Language Model Guided Sim-To-Real Transfer》 瑜伽球上遛「狗」这项研究由宾夕法尼亚大学、 NVIDIA 、得克萨斯大学奥斯汀分校的研究者联合打造,并且完全开源。他们提出了 DrEureka(域随机化 Eureka)&am…...

模拟面试题卷二
1. 什么是JavaEE框架,你能列举一些常用的JavaEE框架吗? 答:JavaEE框架是一套用于开发企业级应用的技术规范和工具集合。常用的JavaEE框架有Spring、Hibernate、Struts、JSF等。 2. 请解释一下面向对象技术和设计原则是什么,你能…...
22种常用设计模式示例代码
文章目录 创建型模式结构型模式行为模式 仓库地址https://github.com/Xiamu-ssr/DesignPatternsPractice 参考教程 refactoringguru设计模式-目录 创建型模式 软件包复杂度流行度工厂方法factorymethod❄️⭐️⭐️⭐️抽象工厂abstractfactory❄️❄️⭐️⭐️⭐️生成器bui…...

Java面试题:对比ArrayList和LinkedList的内部实现,以及它们在不同场景下的适用性
ArrayList和LinkedList是Java中常用的两个List实现,它们在内部实现和适用场景上有很大差异。下面是详细的对比分析: 内部实现 ArrayList 数据结构:内部使用动态数组(即一个可变长的数组)实现。存储方式:…...
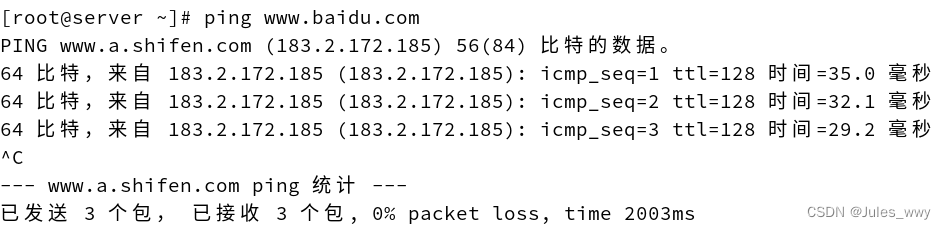
ping: www.baidu.com: 未知的名称或服务(IP号不匹配)
我用的是VMware上的Red Hat Enterprise Linux 9,出现了能联网但ping不通外网的情况。 问题描述:设置中显示正常连接,而且虚拟机右上角有联网的图标,但不能通外网。 按照网上教程修改了/etc/resolv.conf和/etc/sysconfig/network-…...

谷神前端组件增强:子列表
谷神Ag-Grid导出Excel // 谷神Ag-Grid导出Excel let allDiscolumns detailTable.getAllDisColumns() let columnColIds columns.map(column > column.colId) let columnKeys columnColIds.filter(item > ![select, "_OPT_FIELD_"].includes(item)) detailT…...

测试cudaStream队列的深度
测试cudaStream队列的深度 一.代码二.编译运行[得出队列深度为512] 以下代码片段用于测试cudaStream队列的深度 方法: 主线程一直发任务,启一个线程cudaEventQuery查询已完成的任务,二个计数器的值相减 一.代码 #include <iostream> #include <thread> #include …...
海康威视 isecure center 综合安防管理平台任意文件上传漏洞
文章目录 前言声明一、漏洞描述二、影响版本三、漏洞复现四、修复方案 前言 海康威视是以视频为核心的智能物联网解决方案和大数据服务提供商,业务聚焦于综合安防、大数据服务和智慧业务。 海康威视其产品包括摄像机、多屏控制器、交通产品、传输产品、存储产品、门禁产品、消…...
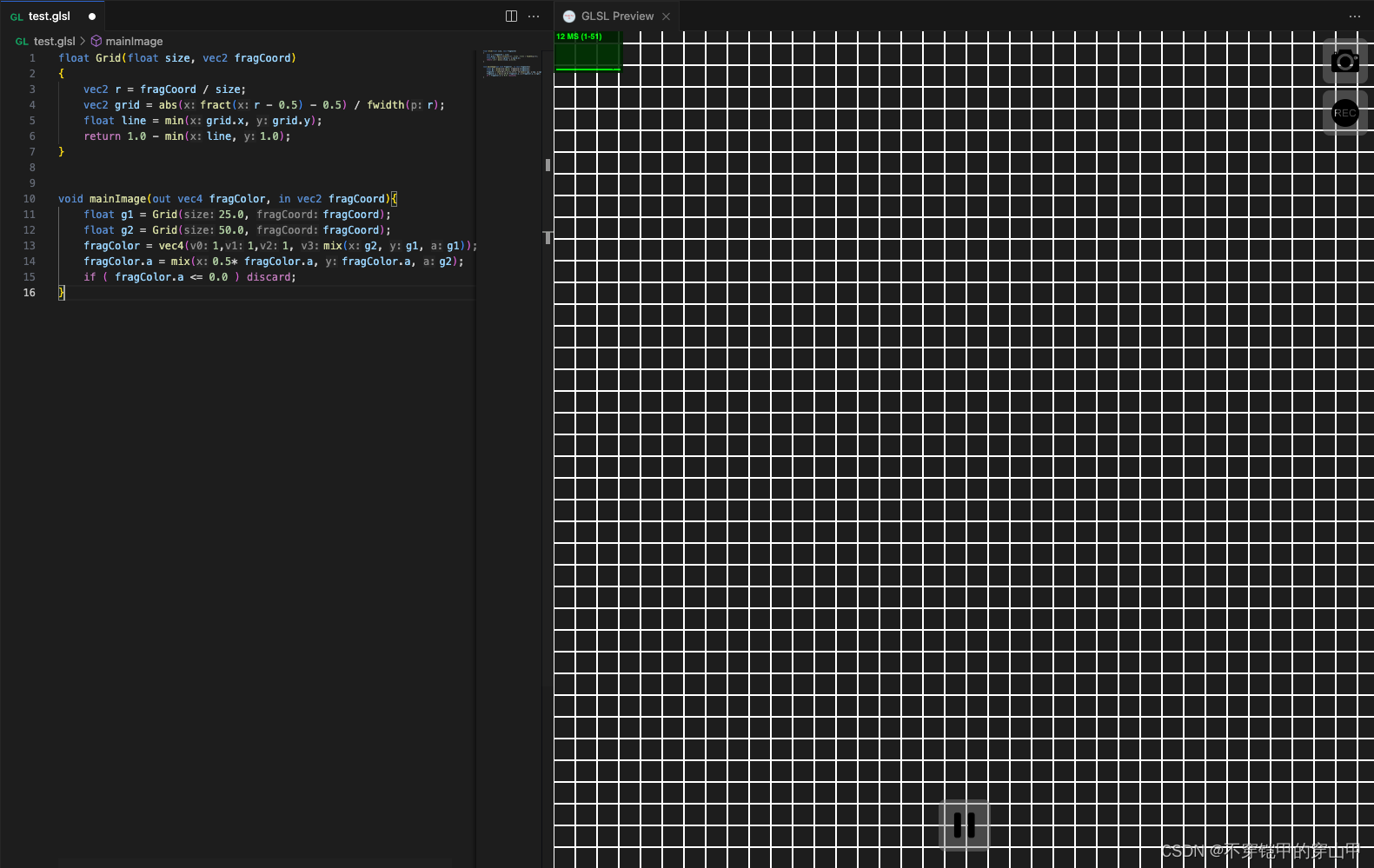
shadertoy-安装和使用
一、安装vscode 安装vscode流程 二、安装插件 1.安装glsl编辑插件 2.安装shader toy插件 三、创建glsl文件 test.glsl文件 float Grid(float size, vec2 fragCoord) {vec2 r fragCoord / size;vec2 grid abs(fract(r - 0.5) - 0.5) / fwidth(r);float line min(grid…...
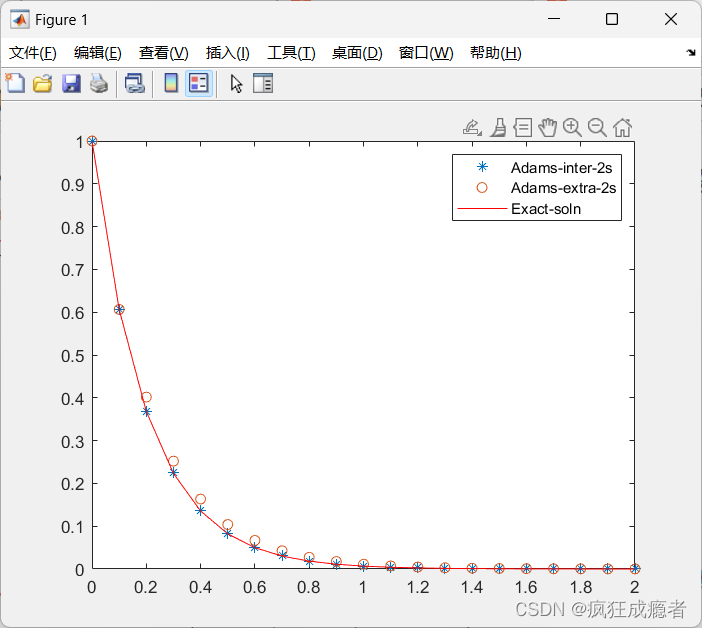
matlab线性多部法求常微分方程数值解
用Adamas内差二步方法,内差三步方法,外差二步方法,外差三步方法这四种方法计算。 中k为1和2. k为2和3 代码 function chap1_adams_methodu0 1; T 2; h 0.1; N T/h; t 0:h:T; solu exact1(t);f f1; u_inter_2s adams_inter_2steps(…...

前端页面实现【矩阵表格与列表】
实现页面: 1.动态表绘制(可用于矩阵构建) <template><div><h4><b>基于层次分析法的权重计算</b></h4><table table-layout"fixed"><thead><tr><th v-for"(_, colI…...

GPT4v和Gemini-Pro调用对比
要调用 GPT-4 Vision (GPT-4V) 和 Gemini-Pro,以下是详细的步骤分析,包括调用流程、API 使用方法和两者之间的区别,以及效果对比和示例。 GPT-4 Vision (GPT-4V) 调用步骤 GPT-4 Vision 主要通过 OpenAI 的 API 进行调用,用于处…...
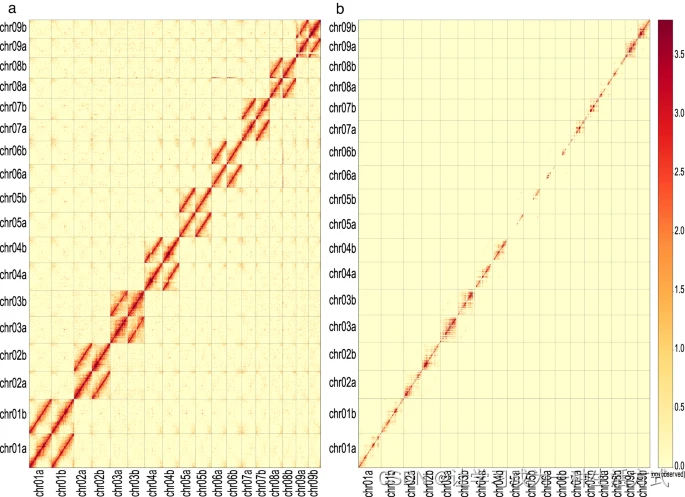
破布叶(Microcos paniculata)单倍型染色体级别基因组-文献精读22
Haplotype-resolved chromosomal-level genome assembly of Buzhaye (Microcos paniculata) 破布叶、布渣叶(Microcos paniculata)单倍型解析染色体级别基因组组装 摘要 布渣叶(Microcos paniculata)是一种传统上用作民间药物和…...
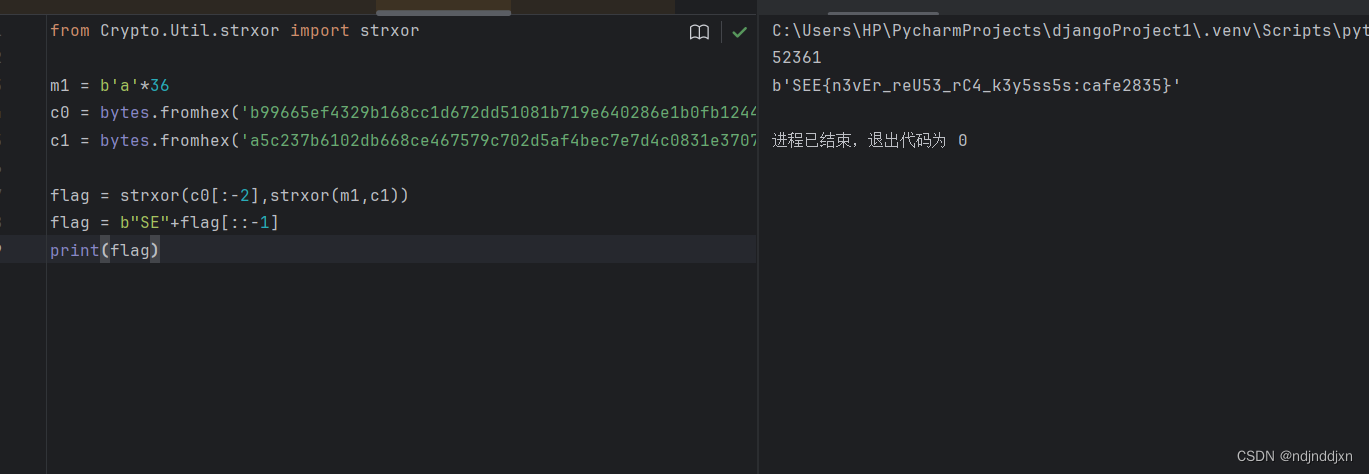
浅谈RC4
一、什么叫RC4?优点和缺点 RC4是对称密码(加密解密使用同一个密钥)算法中的流密码(一个字节一个字节的进行加密)加密算法。 优点:简单、灵活、作用范围广,速度快 缺点:安全性能较差&…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...