【深度学习基础】详解Pytorch搭建CNN卷积神经网络LeNet-5实现手写数字识别
目录
写在开头
一、CNN的原理
1. 概述
2. 卷积层
内参数(卷积核本身)
外参数(填充和步幅)
输入与输出的尺寸关系
3. 多通道问题
多通道输入
多通道输出
4. 池化层
平均汇聚
最大值汇聚
二、手写数字识别
1. 任务描述和数据集加载
2. 网络结构(LeNet-5)
3. 模型训练
4. 模型测试
5. 直观显示预测结果
写在最后
写在开头
本文将将介绍如何使用PyTorch框架搭建卷积神经网络(CNN)模型。简易介绍卷积神经网络的原理,并实现模型的搭建、数据集加载、模型训练、测试、网络的保存等。实现机器学习领域的Hello world——手写数字识别。本文的讲解参考了B站两位up主:爆肝杰哥、炮哥带你学。有关Pytorch环境配置和CNN具体原理大家可以自行查阅资料,本文多数图片也来自于爆肝杰哥的讲解。这里也放上两位up主的视频链接:
从0开始撸代码--手把手教你搭建LeNet-5网络模型_哔哩哔哩_bilibili
Python深度学习:安装Anaconda、PyTorch(GPU版)库与PyCharm_哔哩哔哩_bilibili
本文使用的PyTorch为1.12.0版本,Numpy为1.21版本,相近的版本语法差异很小。有关数组的数据结构教程、神经网络的基本原理(前向传播/反向传播)、神经网络作为“函数模拟器”直观感受、深度神经网络的实现DNN详见本专栏的前三篇文章,链接如下:
【深度学习基础】NumPy数组库的使用-CSDN博客
【深度学习基础】用PyTorch从零开始搭建DNN深度神经网络_如何搭建一个深度学习神经网络dnn pytorch-CSDN博客
【深度学习基础】使用Pytorch搭建DNN深度神经网络与手写数字识别_dnn网络模型 代码-CSDN博客
基于深度神经网络DNN实现的手写数字识别,将灰度图像转换后的二维数组展平到一维,将一维的784个特征作为模型输入。在“展平”的过程中必然会失去一些图像的形状结构特征,因此基于DNN的实现方式并不能很好的利用图像的二维结构特征,而卷积神经网络CNN对于处理图像的位置信息具有一定的优势。因此卷积神经网络经常被用于图像识别/处理领域。下面我们将对CNN进行具体介绍。
一、CNN的原理
1. 概述
在上一篇博客介绍的深度神经网络DNN中,网络的每一层神经元相互直接都有链接,每一层都是全连接层,我们的目标就是训练这个全连接层的权重w和偏执b,最终得到预测效果良好的网络结构。
DNN的全连接层对应于CNN中的卷积层,而池化层(汇聚)其实与激活函数的作用类似。CNN中完整的卷积层的结构是:卷积-激活函数-池化(汇聚),其中池化层也有时可以省略。一个卷积神经网络的结构如下:
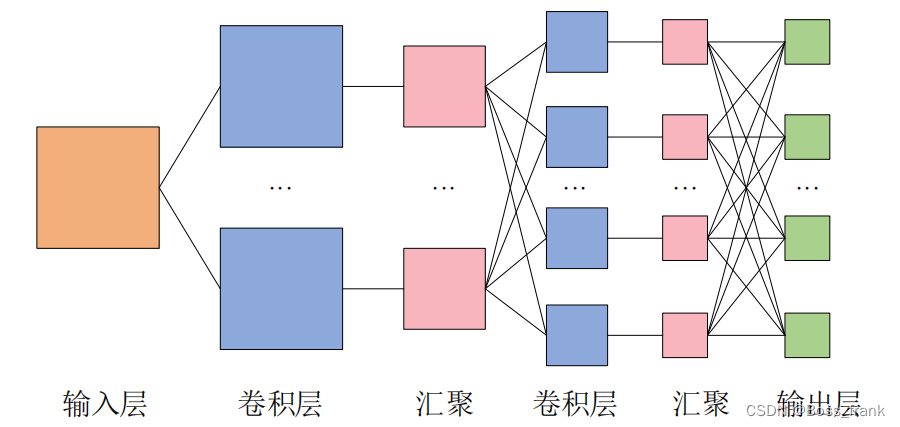
如上图所示,CNN的优势在于可以处理多为输入数据,并同样以多维数据的形式输出至下一层,保留了更多的空间信息特征。而DNN却只能将多维数据展平成一维数据,必然会损失一些空间特征。
2. 卷积层
内参数(卷积核本身)
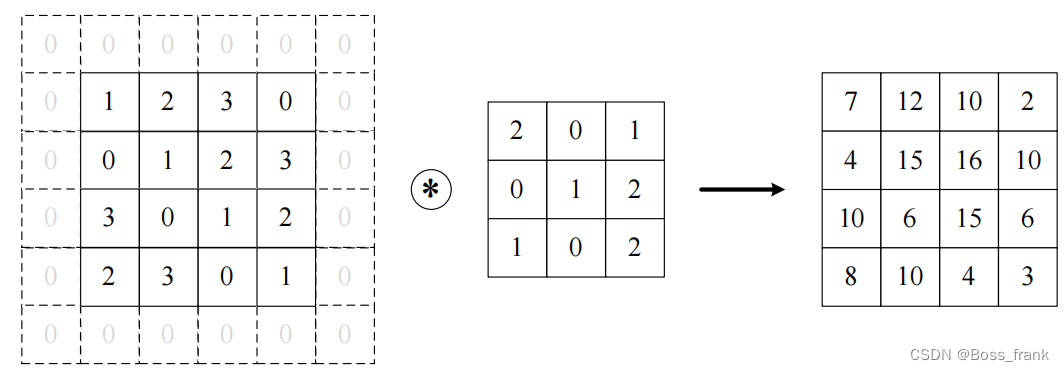
CNN中的卷积层和DNN中的全连接层是平级关系,在DNN中,我们训练的内参数是全连接层的权重w和偏置b,CNN也类似,CNN训练的是卷积核,也就相当于包含了权重和偏置两个内部参数。下面我们首先描述什么是卷积运算。当输入数据进入卷积层后,输入数据会与卷积核进行卷积运算,运算方法如下图所示:
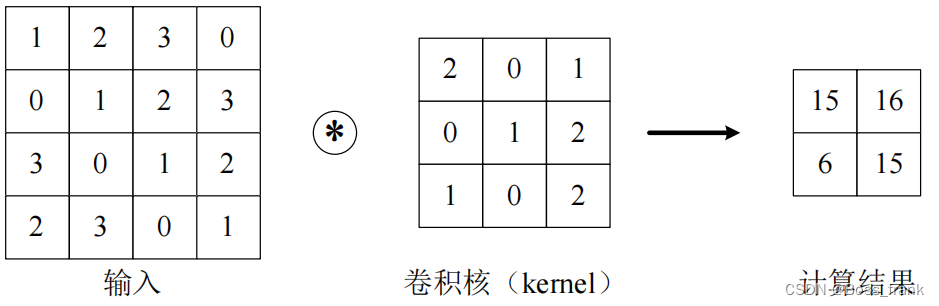
输入一个多维数据(上图为二维),与卷积核进行运算,即输入中与卷积核形状相同的部分,分别与卷积核进行逐个元素相乘再相加。例如计算结果中坐上角的15是根据如下过程计算得到的:
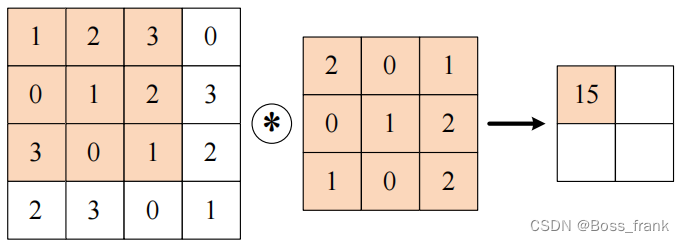
逐个元素相乘再相加,即:
1 * 2 + 2 * 0 + 3* 1 + 0 * 0 + 1 * 1 + 2 * 2 + 3 * 1 + 0 * 0 + 1 * 2 = 15
卷积核本身相当于权重,再卷积运算的过程中也可以存在偏置,如下:
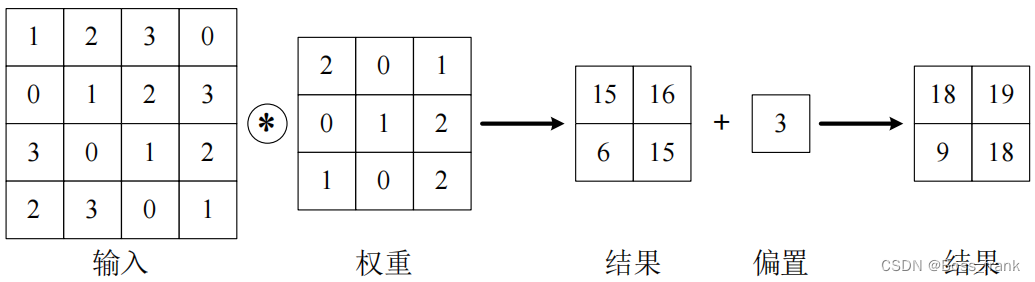
卷积核(即CNN的权重和偏置)本身为内参数,(具体里面的数字)是我们通过训练得出的,我们写代码的时候只要关注一些外部设定的参数即可。下面我们将介绍一些外参数。
外参数(填充和步幅)
填充(padding)
显然,只要卷积核的大小>1*1,必然会导致图像越卷越小,为了防止输入经过多个卷积层后变得过小,可以在发生卷积层之前,先向输入图像的外围填入固定的数据(比如0),这个步骤称之为填充,如下图:
在我们使用Pytorch搭建卷积层的时候,需要在对应的接口中添加这个padding参数,向上图中这种情况,相当于在3*3的卷积核外围添加了“一圈”,则padding = 1,卷积层的接口中就要这样写:
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, paddding=1)
参数in_channels和out_channels是对应于这个卷积层输入和输出的通道数参数,这里我们先放一放。
步幅(stride)
步幅指的是使用卷积核的位置间隔,即输入中参与运算的那个范围每次移动的距离。前面几个示意图中的步幅均为1,即每次移动一格,如果设置stride=2,kernel_size=2,则效果如下:
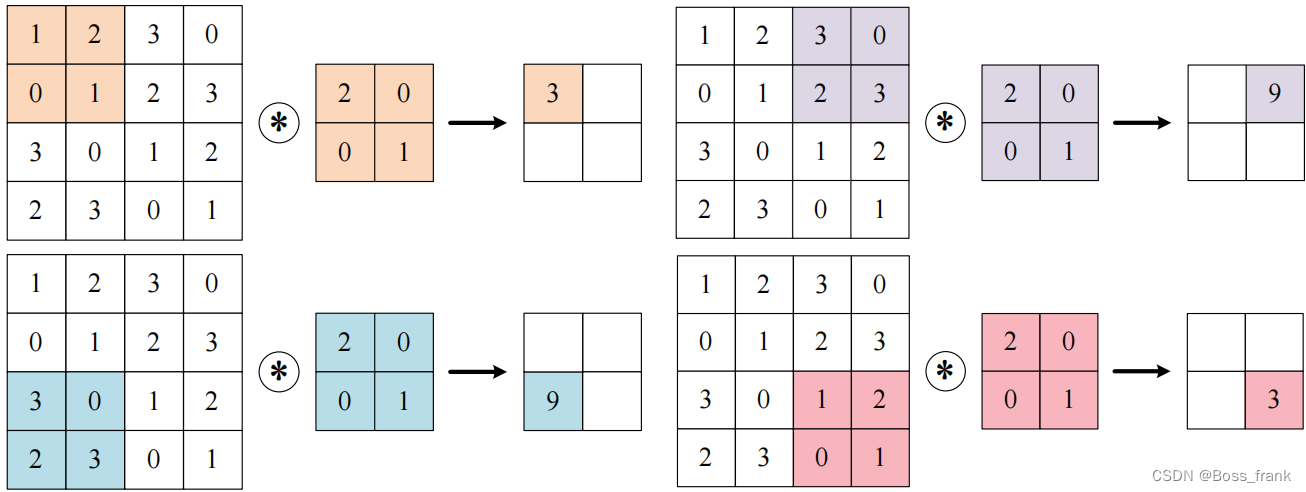
此时需要在卷积层接口中添加参数stride=2。
输入与输出的尺寸关系
综上所述,结合外参数(步幅、填充)和内参数(卷积核),可以看出如下规律:
卷积核越大,输出越小。
步幅越大,输出越小。
填充越大,输出越大。
用公式表示定量关系:
如果输入和卷积核均为方阵,设输入尺寸为W*W,输出尺寸为N*N,卷积核尺寸为F*F,填充的圈数为P,步幅为S,则有关系:
这个关系大家要重点掌握,也可以自己推导一下,并不复杂。如果输入和卷积核不为方阵,设输入尺寸是H*W,输出尺寸是OH*OW,卷积核尺寸为FH*FW,填充为P,步幅为S,则输出尺寸OH*OW的计算公式是:
3. 多通道问题
多通道输入
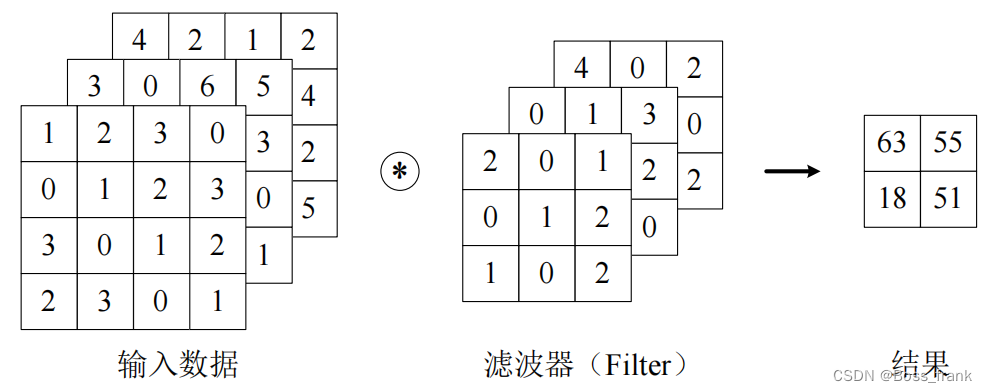
对于手写数字识别这种灰度图像,可以视为仅有(高*长)二维的输入。然而,对于彩色图像,每一个像素点都相当于是RGB的三个值的组合,因此对于彩色的图像输入,除了高*长两个维度外,还有第三个维度——通道,即红、绿、蓝三个通道,也可以视为3个单通道的二维图像的混合叠加。
当输入数据仅为二维时,卷积层的权重往往被称作卷积核(Kernel);
当输入数据为三维或更高时,卷积层的权重往往被称作滤波器(Filter)。
对于多通道输入,输入数据和滤波器的通道数必须保持一致。这样会导致输出结果降维成二维,如下图:
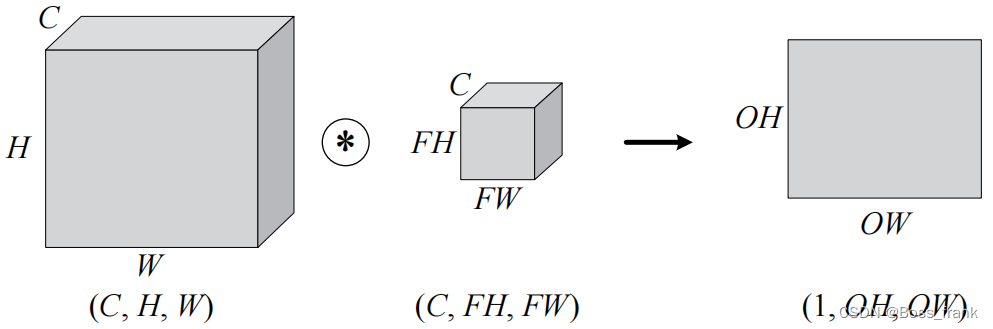
对形状进行一下抽象,则输入数据C*H*W和滤波器C*FH*FW都是长方体,结果是一个长方形1*OH*OW,注意C,H,W是固定的顺序,通道数要写在最前。
多通道输出
如果要实现多通道输出,那么就需要多个滤波器,让三维输入与多个滤波器进行卷积,就可以实现多通道输出,输出的通道数FN就是滤波器的个数FN,如下图:
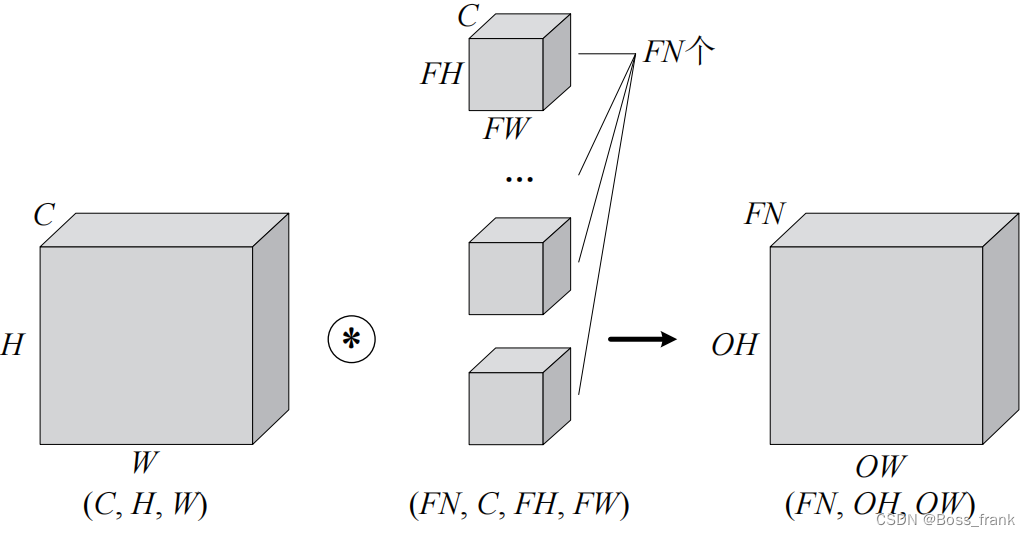
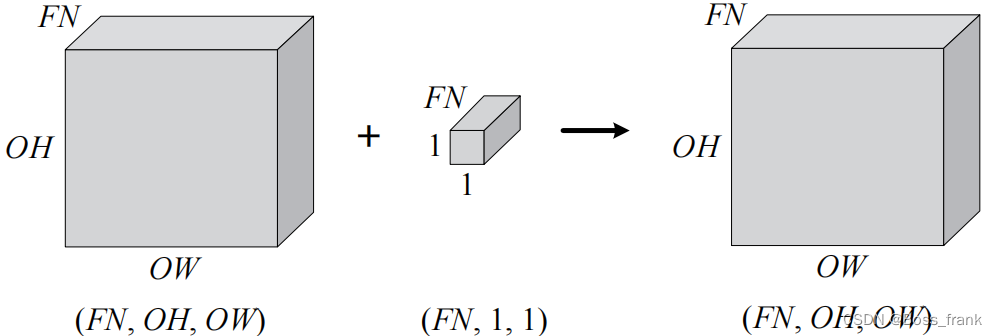
和单通道一样,卷积运算后也有偏置,如果进一步追加偏置,则结果如下:每个通道都有一个单独的偏置。
4. 池化层
池化,也叫汇聚(Pooling)。池化层通常位于卷积层之后(有时也可以不设置池化层),其作用仅仅是在一定范围内提取特征值,所以并不存在要学习的内部参数。池化仅仅对图像的高H和宽W进行特征提取,并不改变通道数C。
平均汇聚
一般有平均汇聚和最大值汇聚两种。平均汇聚如下:
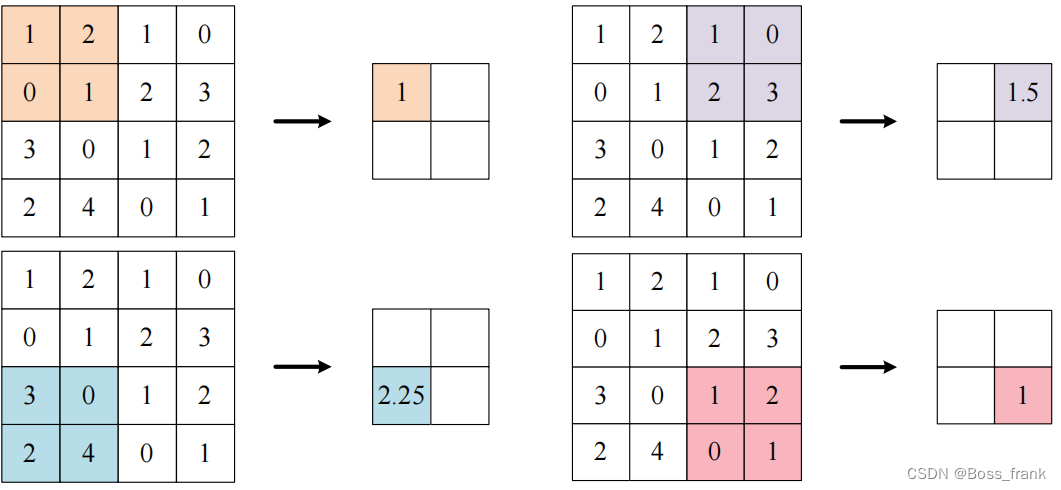
如上图,池化的窗口大小为2*2,对应的步幅为2,因此对于上图这种情况,对应的Pytorch接口如下:
nn.AvgPool2d(kernel_size=2, stride=2)
最大值汇聚
同理,如果使用最大值汇聚,如下图所示:
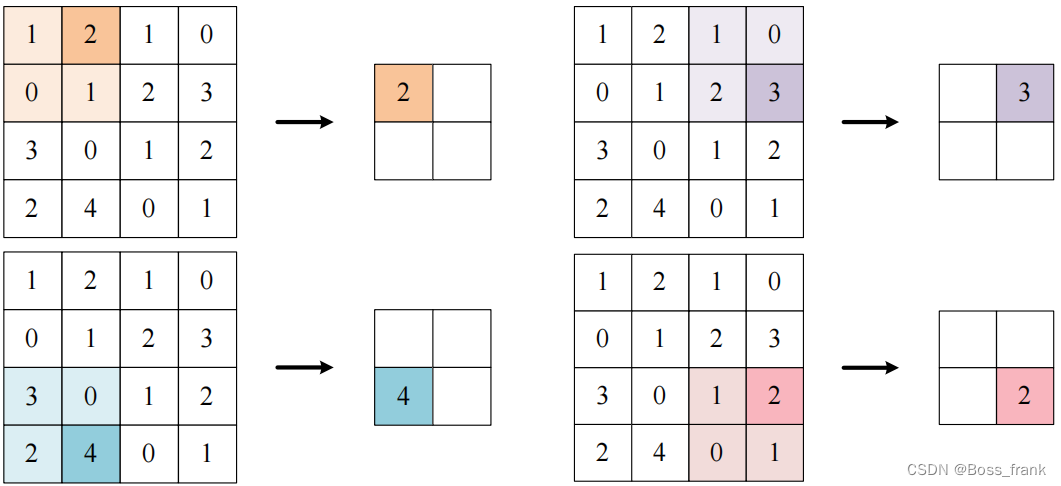
此处Pytorch函数就这么写:
nn.MaxPool2d(kernel_size=2, stride=2)
二、手写数字识别
1. 任务描述和数据集加载
此处和上一篇博客类似,详情见:
【深度学习基础】使用Pytorch搭建DNN深度神经网络与手写数字识别_dnn网络模型 代码-CSDN博客
接下来我们实现机器学习领域的Hello World——手写数字识别。使用的数据集MNIST是机器学习领域的标准数据集,其中的每一个样本都是一副二维的灰度图像,尺寸为28*28:

输入就相当于一个单通道的图像,是二维的。我们在实现的时候,要将每个样本图像转换为28*28的张量,作为输入,此处和上一篇DNN都一致。数据集则通过包torchvision中的datasets库进行下载。这里我快速给一段代码好了,详情可见上一篇博客。
import torch
from torchvision import datasets, transforms# 设定下载参数 (数据集转换参数),将图像转换为张量
data_transform = transforms.Compose([transforms.ToTensor()
])# 加载训练数据集
train_dataset = datasets.MNIST(root='D:\\Jupyter\\dataset\\minst', # 下载路径,读者请自行设置train=True, # 是训练集download=True, # 如果该路径没有该数据集,则进行下载transform=data_transform # 数据集转换参数
)# 批次加载器,在接下来的训练中进行小批次(16批次)的载入数据,有助于提高准确度,对训练集的样本进行打乱,
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)# 加载测试数据集
test_dataset = datasets.MNIST(root='D:\\Jupyter\\dataset\\minst', # 下载路径train=False, # 是训练集download=True, # 如果该路径没有该数据集,则进行下载transform=data_transform # 数据集转换参数
)test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)2. 网络结构(LeNet-5)
本文搭建的LeNet-5起源于1998年,在手写数字识别上非常成功。其结构如下:
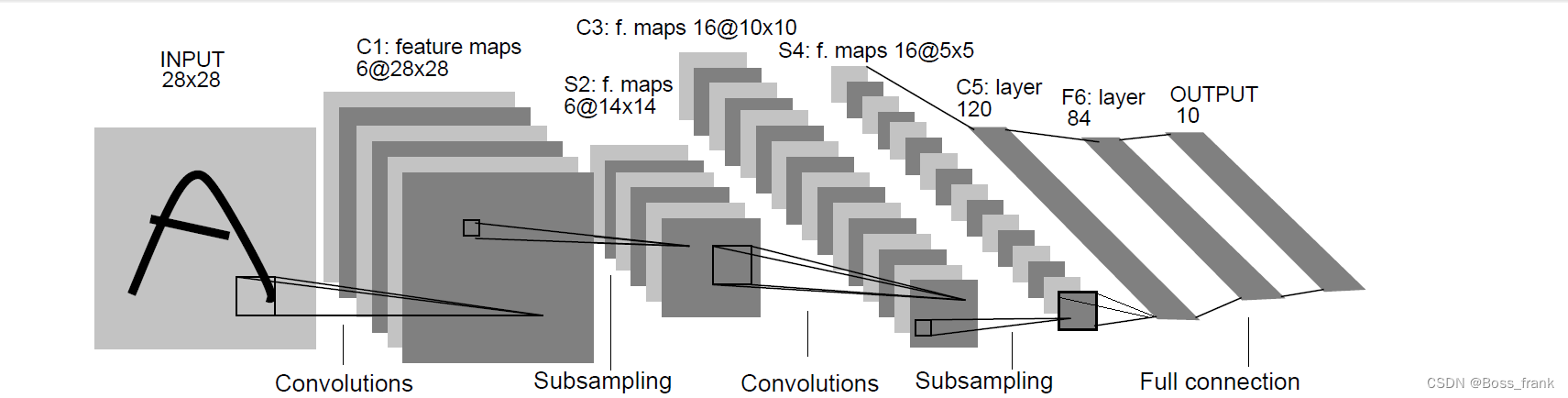
再列一个表格,具体结构如下:
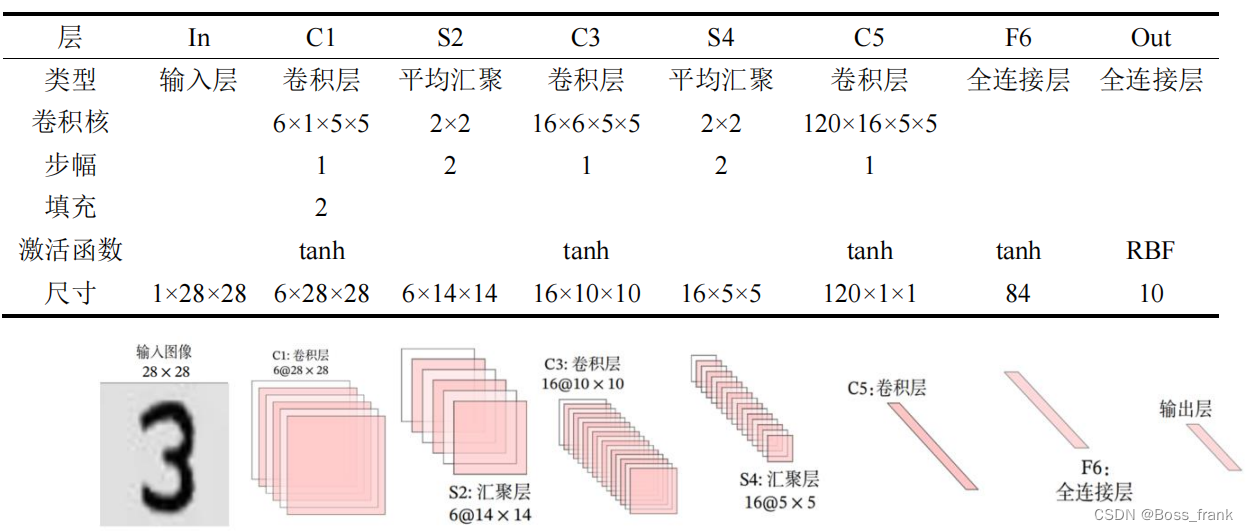 注:输出层的激活函数目前已经被Softmax取代。
注:输出层的激活函数目前已经被Softmax取代。
至于这些尺寸关系,我举个两例子吧:
以第一层C1的输入和输出为例。输入尺寸W是28*28,卷积核F尺寸为5*5,步幅S为1,填充P为2,那么输出N的28*28怎么来的呢?按照公式如下:
我们也可以观察到第一层的卷积核个数为6,则输出的通道数也为6。
再看一下第一个池化层S2,输入尺寸是28*28,卷积核F大小为2*2(此处的“卷积核”实际上指的是采样范围),步幅S=2,填充P为0,则输出的14*14是这么算出来的:
其他的没啥好说的,读者们可以自行计算这个尺寸关系。接下来我们给出完整的CNN网络代码,net.py如下:
import torch
from torch import nn# 定义网络模型
class MyLeNet5(nn.Module):# 初始化网络def __init__(self):super(MyLeNet5, self).__init__()self.net = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5), nn.Tanh(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5), nn.Tanh(),nn.Flatten(),nn.Linear(120, 84), nn.Tanh(),nn.Linear(84, 10))# 前向传播def forward(self, x):y = self.net(x)return y# 以下为测试代码,也可不添加
if __name__ == '__main__': x1 = torch.rand([1, 1, 28, 28])model = MyLeNet5()y1 = model(x1)print(x1)print(y1)这里我还在'__main__'添加了一些测试代码,正如表格中所示,假设我们向网络中输入一个1*1*28*28的向量,模拟批次大小为1,一个单通道28*28的灰度图输入。最终y应该是由10个数字组成的张量,结果如下:
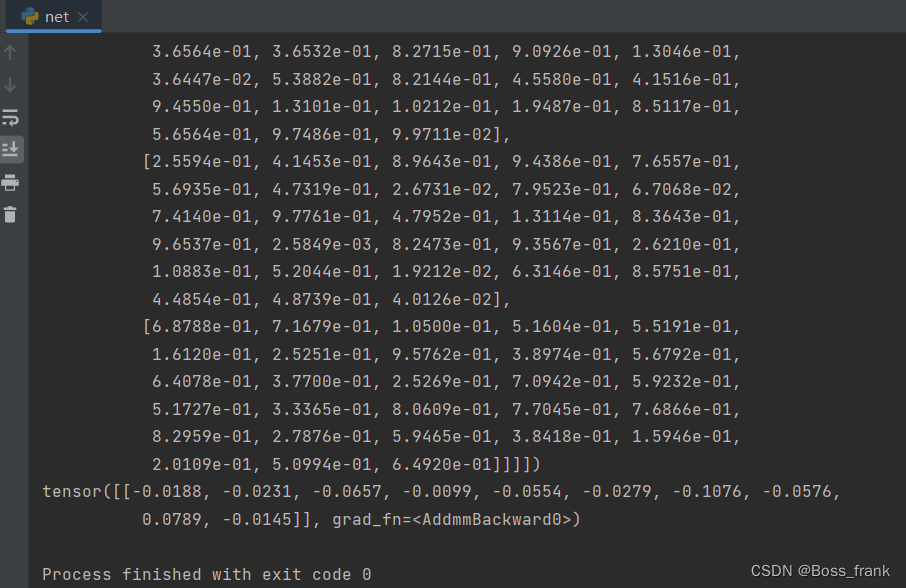
从输出我们可以直观的看到输入经过神经网络前向传播后的结果。另外特别注意这个网络的结构中的参数,其中卷积层的搭建API有5个外参数:
in_channels:输入通道数
out_channels:输出通道数
kernel_size: 卷积核尺寸
padding: 填充,不写则默认0
stride: 步幅,不写则默认1
这个LeNet-5网络结构就长这样,我们一定要严格遵守,否则有可能出现无论怎么训练,都始终欠拟合的情况。我就曾经试过更改/添加不同的激活函数,结果无论是训练还是测试,准确率都在10%徘徊,相当于随机瞎猜的效果,因此大家一定要严格遵循这个网络结构。
3. 模型训练
网络搭建好之后,所有的内参数(即卷积核)都是随机的,下面我们要通过训练尽可能提高网络的预测能力。在训练前,我们首先要选择损失函数(这里使用交叉熵损失函数),定义优化器、进行学习率调整等,代码如下:
import torch
from torch import nn
from net import MyLeNet5
from torch.optim import lr_scheduler# 判断是否有gpu
device = "cuda" if torch.cuda.is_available() else "cpu"# 调用net,将模型数据转移到gpu
model = MyLeNet5().to(device)# 选择损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数,自带Softmax激活函数# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)# 学习率每隔10轮次, 变为原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
然后我们可以写一个用于训练网络的函数,四个参数分别是批次加载器、模型、损失函数、优化器,代码如下:
# 定义模型训练的函数
def train(dataloader, model, loss_fn, optimizer):loss, current, n = 0.0, 0.0, 0for batch, (X, y) in enumerate(dataloader):# 前向传播X, y = X.to(device), y.to(device)output = model(X)cur_loss = loss_fn(output, y)# 用_和pred分别接收输出10个元素中的最大值和对应下标位置_, pred = torch.max(output, dim=1)# 计算当前轮次时,训练集的精确度,将所有标签值与预测值(即下标位置)cur_acc = torch.sum(y == pred)/output.shape[0]# 反向传播,对内部参数(卷积核)进行优化optimizer.zero_grad()cur_loss.backward()optimizer.step()# 计算准确率和损失,这里只是为了实时显示训练集的拟合情况。也可以不写loss += cur_loss.item()current += cur_acc.item()n = n + 1print("train_loss: ", str(loss/n))print("train_acc: ", str(current/n))只要调用这个函数,即可实现模型训练:
train(train_dataloader, model, loss_fn, optimizer)当然,我们最好是设定一个轮次epoch,我们后续会写这样一个循环,每训练一个epoch,就进行一次测试,实时显示一定轮次后训练集和测试集的拟合情况。
4. 模型测试
这里和模型训练类似,只不过我们要观察训练好的模型,在测试集的预测效果。与训练的代码相似,只是没有了反向传播优化参数的过程。用于测试的函数代码如下:
def test(dataloader, model, loss_fn):model.eval()loss, current, n = 0.0, 0.0, 0# 该局部关闭梯度计算功能,提高运算效率with torch.no_grad(): for batch, (X, y) in enumerate(dataloader):# 前向传播X, y = X.to(device), y.to(device)output = model(X)cur_loss = loss_fn(output, y)_, pred = torch.max(output, dim=1)# 计算当前轮次时,训练集的精确度cur_acc = torch.sum(y == pred) / output.shape[0]loss += cur_loss.item()current += cur_acc.item()n = n + 1print("test_loss: ", str(loss / n))print("test_acc: ", str(current / n))return current/n # 返回精确度如上代码,将测试集的精确度作为返回值,我们在外围调用这个函数时,可以通过循环找到测试集最大的精确度。
最终我们设定一个训练轮次epochs,此处epochs=50,每经过一个epoch的训练,就进行测试,实时打印观察训练集和测试集的拟合情况。当测试集的精确度是当前的最大值时,我们就保存这个模型的参数到save_model/best_model.pth,代码如下:
import os# 开始训练
epoch = 50
max_acc = 0
for t in range(epoch):print(f"epoch{t+1}\n---------------")# 训练模型train(train_dataloader, model, loss_fn, optimizer)# 测试模型a = test(test_dataloader, model, loss_fn)# 保存最好的模型参数if a > max_acc:folder = 'save_model'if not os.path.exists(folder):os.mkdir(folder)max_acc = aprint("current best model acc = ", a)torch.save(model.state_dict(), 'save_model/best_model.pth')
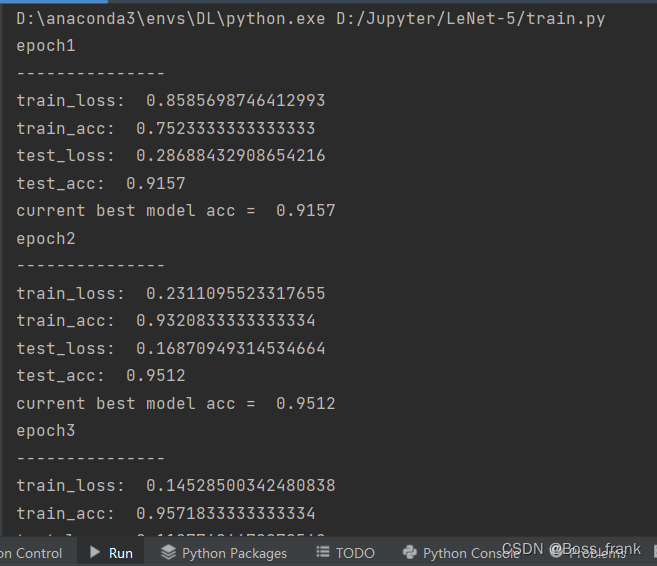
print("Done!")运行之后可以发现,测试集的精度经过1个epochs就达到了90%以上,最终经过50轮次的训练,测试集精度达到了99%左右:
模型参数也得以保存:
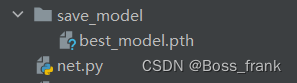
最后给出用于训练和测试的完整代码train.py,如下所示:
import torch
from torch import nn
from net import MyLeNet5
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
import os# 将图像转换为张量形式
data_transform = transforms.Compose([transforms.ToTensor()
])# 加载训练数据集
train_dataset = datasets.MNIST(root='D:\\Jupyter\\dataset\\minst', # 下载路径train=True, # 是训练集download=True, # 如果该路径没有该数据集,则进行下载transform=data_transform # 数据集转换参数
)# 批次加载器
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)# 加载测试数据集
test_dataset = datasets.MNIST(root='D:\\Jupyter\\dataset\\minst', # 下载路径train=False, # 是训练集download=True, # 如果该路径没有该数据集,则进行下载transform=data_transform # 数据集转换参数
)
test_dataloader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=True)# 判断是否有gpu
device = "cuda" if torch.cuda.is_available() else "cpu"# 调用net,将模型数据转移到gpu
model = MyLeNet5().to(device)# 选择损失函数
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数,自带Softmax激活函数# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)# 学习率每隔10轮次, 变为原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)# 定于训练函数
def train(dataloader, model, loss_fn, optimizer):loss, current, n = 0.0, 0.0, 0for batch, (X, y) in enumerate(dataloader):# 前向传播X, y = X.to(device), y.to(device)output = model(X)cur_loss = loss_fn(output, y)_, pred = torch.max(output, dim=1)# 计算当前轮次时,训练集的精确度cur_acc = torch.sum(y == pred)/output.shape[0]# 反向传播optimizer.zero_grad()cur_loss.backward()optimizer.step()loss += cur_loss.item()current += cur_acc.item()n = n + 1print("train_loss: ", str(loss/n))print("train_acc: ", str(current/n))def test(dataloader, model, loss_fn):model.eval()loss, current, n = 0.0, 0.0, 0# 该局部关闭梯度计算功能,提高运算效率with torch.no_grad():for batch, (X, y) in enumerate(dataloader):# 前向传播X, y = X.to(device), y.to(device)output = model(X)cur_loss = loss_fn(output, y)_, pred = torch.max(output, dim=1)# 计算当前轮次时,训练集的精确度cur_acc = torch.sum(y == pred) / output.shape[0]loss += cur_loss.item()current += cur_acc.item()n = n + 1print("test_loss: ", str(loss / n))print("test_acc: ", str(current / n))return current/n # 返回精确度# 开始训练
epoch = 50
max_acc = 0
for t in range(epoch):print(f"epoch{t+1}\n---------------")train(train_dataloader, model, loss_fn, optimizer)a = test(test_dataloader, model, loss_fn)# 保存最好的模型参数if a > max_acc:folder = 'save_model'if not os.path.exists(folder):os.mkdir(folder)max_acc = aprint("current best model acc = ", a)torch.save(model.state_dict(), 'save_model/best_model.pth')
print("Done!")5. 直观显示预测结果
截至目前,我们已经完成了手写数字识别这个任务,但是我们好像对于数据集长什么样并不是很了解,似乎仅仅是用torchvision中的datasets库下载了一下。因此本小节,我们的目标是从数据集取出几个特定的手写数字图片,并查看我们模型对其的预测效果。
首先我们还是加载数据集,和之前的代码一样,这里省略。然后我们加载模型:
from net import MyLeNet5# 调用net,将模型数据转移到gpu
model = MyLeNet5().to(device)
model.load_state_dict(torch.load('./save_model/best_model.pth'))我们取出测试集中的前5长图片做一个展示即可,完整代码show.py如下:
import torch
from net import MyLeNet5
from torchvision import datasets, transforms
from torchvision.transforms import ToPILImagedata_transform = transforms.Compose([transforms.ToTensor()
])# 加载训练数据集
train_dataset = datasets.MNIST(root='D:\\Jupyter\\dataset\\minst', # 下载路径train=True, # 是训练集download=True, # 如果该路径没有该数据集,则进行下载transform=data_transform # 数据集转换参数
)# 加载测试数据集
test_dataset = datasets.MNIST(root='D:\\Jupyter\\dataset\\minst', # 下载路径train=False, # 是训练集download=True, # 如果该路径没有该数据集,则进行下载transform=data_transform # 数据集转换参数
)# 判断是否有gpu
device = "cuda" if torch.cuda.is_available() else "cpu"# 调用net,将模型数据转移到gpu
model = MyLeNet5().to(device)
model.load_state_dict(torch.load('./save_model/best_model.pth'))# 获取结果
classes = ["0","1","2","3","4","5","6","7","8","9"
]# 把tensor转化为图片,方便可视化
image = ToPILImage()# 进入验证
for i in range(5):X, y = test_dataset[i][0], test_dataset[i][1] # X,y对应第i张图片和标签# image是ToPILImage的实例,将Pytorch张量转换为PIL图像,.show()方法会打开图像查看器并显示图像image(X).show()'''unsqueeze 方法在指定的 dim 维度上扩展张量的维度。这里 dim=0,所以它会在第0维添加一个维度.例如,原来的 X 形状是 (1, 28, 28),经过 unsqueeze 处理后,形状变为 (1, 1, 28, 28)。这样做的目的是将单张图像扩展成批次大小为1的形式,这样模型可以接收单张图像作为输入。'''X = torch.unsqueeze(X, dim=0).float().to(device)with torch.no_grad():# 前向传播获得预测结果pred(由10个元素组成的张量)pred = model(X)print(pred)# 将预测值和标签转化为对应的数字分类结果,pred中的最大值视为预测分类predicted, actual = classes[torch.argmax(pred[0])], classes[y]print(f"predicted: {predicted}, actual: {actual}")
运行结果如下,我们可以看到测试集中的前五张图片分别是7,2,1,0,4,且我们的模型都能对其进行成功预测分类。

预测结果均正确,如下:
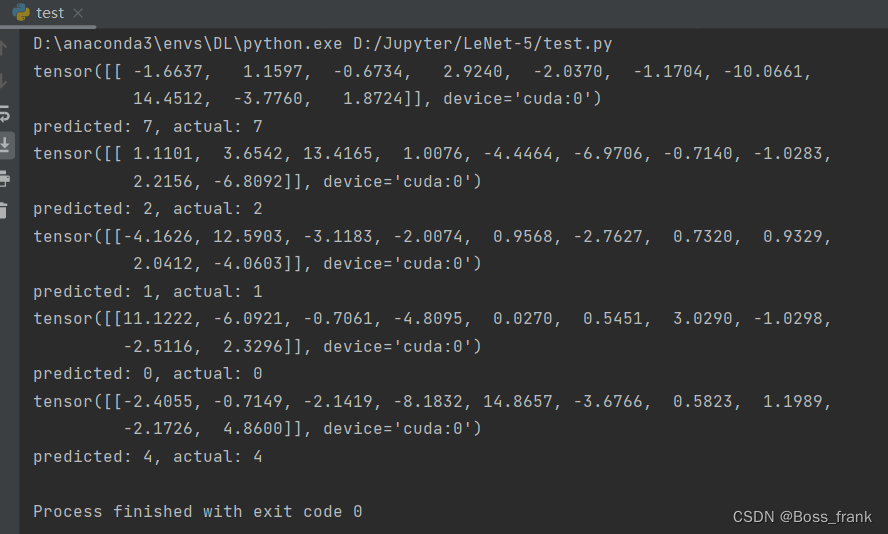
写在最后
本文介绍了如何使用PyTorch框架搭建卷积神经网络模型CNN。将CNN与DNN进行了类比。CNN中的卷积层与DNN的全连接层是平级关系。我们实现了LeNet-5的模型的搭建、模型训练、测试、网络的复用、直观查看数据集的图片预测结果等,实现了机器学习领域的Hello world——手写数字识别。在CNN原理中,读者应当重点关注输入输出的尺寸关系,并可以对照LeNet-5结构示意图写出对应Pytorch代码。至于模型训练和测试基本都是固定的代码形式。
这篇文章到这里就结束了,后续我还会继续更新深度学习的相关知识,另外近期我个人的研究方向涉及到图神经网络,回头也会更新一些相关博客。如果读者有相关建议或疑问也欢迎评论区与我共同探讨,我一定知无不言。总结不易,还请读者多多点赞关注支持!

相关文章:
【深度学习基础】详解Pytorch搭建CNN卷积神经网络LeNet-5实现手写数字识别
目录 写在开头 一、CNN的原理 1. 概述 2. 卷积层 内参数(卷积核本身) 外参数(填充和步幅) 输入与输出的尺寸关系 3. 多通道问题 多通道输入 多通道输出 4. 池化层 平均汇聚 最大值汇聚 二、手写数字识别 1. 任务…...

面试技巧:正确回答JavaScript中Map和Object的选择问题
在JavaScript的面试中,对于何时使用Map和Object的选择问题,是一个常见的考察点。这两个数据结构都能存储键值对,但它们各有优势和适用场景。本文将深入探讨两者的区别,并通过实际代码示例来指导您如何选择。 基本概念 Map&#…...

sd StableDiffusion库学习笔记
目录 DeepSpeed realesrgan BasicSR超分辨率,去噪,去模糊,去 JPEG 压缩噪声 segment_anything mmengine controlnet_aux accelerate transfersformer pytorch_fid einops compel transfersformer 文本嵌入调整库 报错:…...

【单片机毕业设计选题24017】-基于STM32的禽舍环境监测控制系统(蓝牙版)
系统功能: 系统分为主机端和从机端,主机端主动向从机端发送信息和命令,从机端 收到主机端的信息后回复温湿度氨气浓度和光照强度等信息。 主要功能模块原理图: 电源时钟烧录接口: 单片机和按键输入电路: 主机部分电路: 从机部分电路: 资料获取地址 主…...
- 系统聚类)
每天一个数据分析题(三百七十八)- 系统聚类
在系统聚类方法中,哪种系统聚类是直接利用了组内的离差平方和? A. 最长距离法 B. 重心法 C. Ward法 D. 类平均法 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据分析专项练习题库 内容涵盖Python&#…...
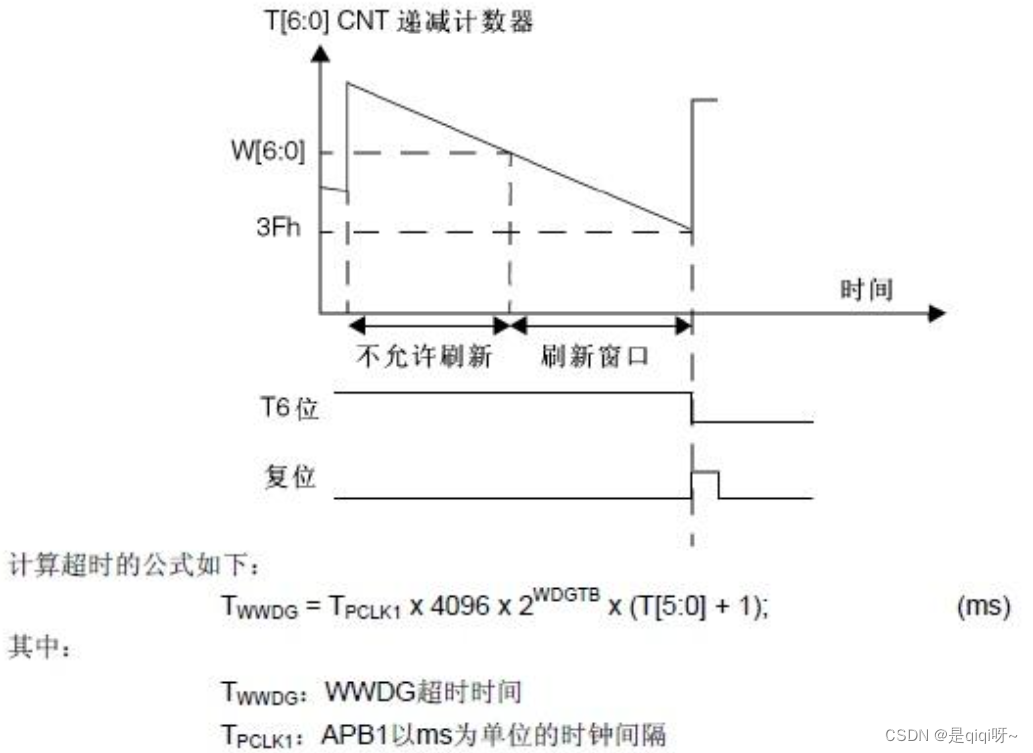
守护系统稳定性的关键技术之看门狗
目录 一、独立看门狗 二、窗口看门狗 三、总结 看门狗定时器(Watchdog Timer,WDT)是嵌入式系统中至关重要的组件,用于监控和维护系统的稳定性。主要是用来监测单片机运行状态和解决程序引起的故障的模块。在由单片机构成的微型…...

【Linux】进程间通信上 (1.5万字详解)
目录 一.进程间通信介绍 1.1进程间通信的目的 1.2初步认识进程间通信 1.3进程间通信的种类 二.匿名管道 2.1何为管道 2.1实现原理 2.3进一步探寻匿名管道 2.4编码实现匿名管道通信 2.5管道读写特点 2.6基于管道的进程池设计 三.命名管道 3.1实现原理 3.2代码实现 四.…...

测试用例设计:提升测试覆盖率的策略与方法
测试用例设计:提升测试覆盖率的策略与方法 前言测试用例设计的原则提高测试覆盖率的方法测试类型的分析 测试用例设计的基本方法等价类划分边界值分析正交法判定表法因果图法 方法与策略方法策略 如何评价测试用例结论 前言 在软件开发过程中,测试用例设…...

【微服务】什么是Hystrix?一文带你入门Hystrix
文章目录 强烈推荐引言主要功能实现容错应用场景1. 远程服务调用2. 防止级联故障3. 网络延迟和超时管理4. 资源隔离5. 高并发场景6. 熔断与自动恢复7. 故障检测与监控 示例应用场景使用实例1. 引入依赖2. 创建 Hystrix 命令类3. 使用 Hystrix 命令4. 配置 Hystrix5. 实时监控集…...

AI学习指南机器学习篇-支持向量机超参数调优
AI学习指南机器学习篇-支持向量机超参数调优 在机器学习领域中,支持向量机(Support Vector Machines,SVM)是一种非常常用的监督学习模型。它通过寻找一个最优的超平面来进行分类和回归任务。然而,在实际应用中&#x…...

掉电安全文件系统分析
掉电安全FS 掉电安全的文件系统(Power-Fail Safe File Systems)被设计为在电源故障或系统崩溃的情况下仍能保持数据一致性的文件系统。这样的文件系统通常通过使用日志(journaling)或写时复制(copy-on-writeÿ…...
React-Redux学习笔记(自用)
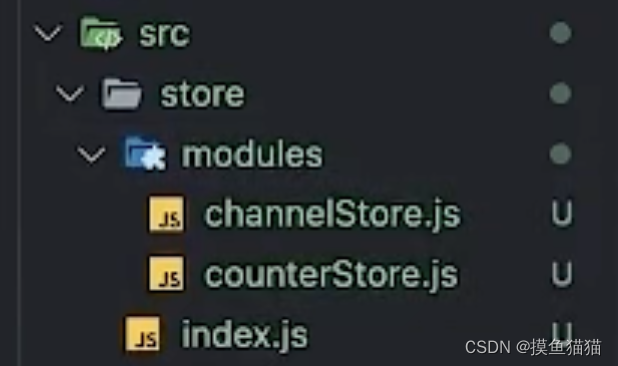
1. 环境搭建 插件安装:Redux Toolkit和react-redux npm i reduxjs/toolkit react-redux2、 store目录结构设计 集中状态管理的部分会单独创建一个store目录(在src下)应用通常会有很多个子模块,所以还会有个modules目录&#x…...

【机器学习】:线性回归模型学习路线
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...
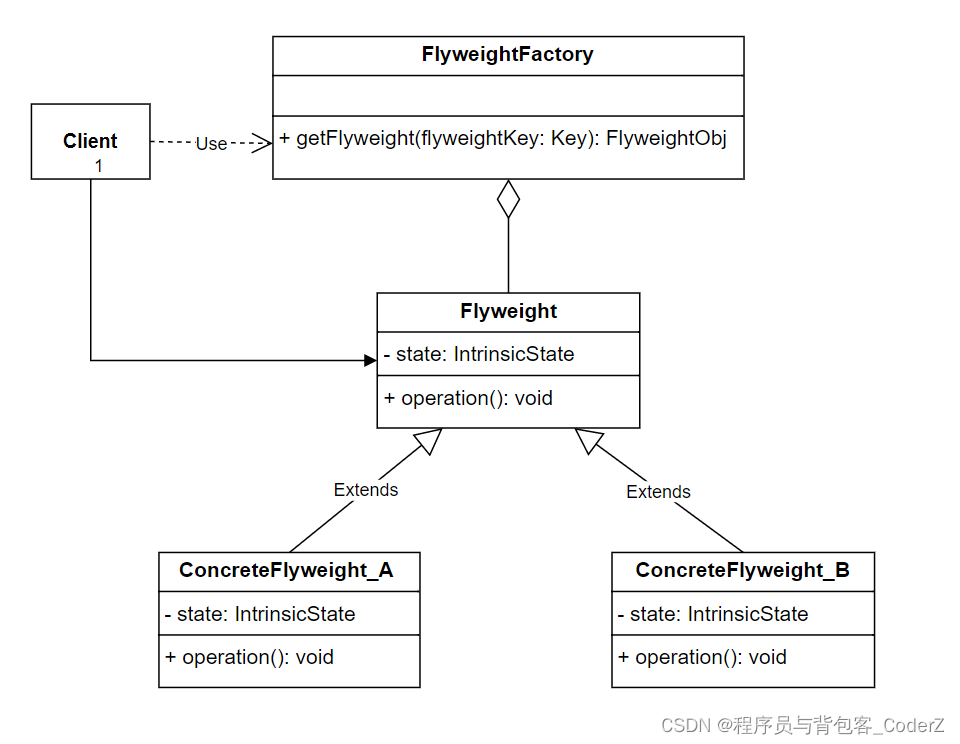
C++设计模式——Flyweight享元模式
一,享元模式简介 享元模式是一种结构型设计模式,它将每个对象中各自保存一份数据的方式改为多个对象共享同一份数据,该模式可以有效减少应用程序的内存占用。 享元模式的核心思想是共享和复用,通过设置共享资源来避免创建过多的实…...

Github 2024-06-19 开源项目日报 Top10
根据Github Trendings的统计,今日(2024-06-19统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量TypeScript项目3Rust项目2Go项目2JavaScript项目1Python项目1Dart项目1非开发语言项目1Ruby项目1HTML项目1项目化学习 创建周期:2538 天协议类…...

【ARM】如何通过Keil MDK查看芯片的硬件信息
【更多软件使用问题请点击亿道电子官方网站】 1、文档目标: 解决在开发过程中对于开发项目所使用的的芯片的参数查看的问题 2、问题场景: 在项目开发过程中,经常需要对于芯片的时钟、寄存器或者一些硬件参数需要进行确认。大多数情况下是需…...
elasticsearch的安装和配置
单节点安装与部署 我们通过docker进行安装 1.docker的安装 如果以及安装了docker就可以跳过这个步骤。 首先更新yum: yum update安装docker: yum install docker查看docker的版本: docker -v此时我们的docker就安装成功了。 2.创建网络 我们还需要部署kiban…...
华为云下Ubuntu20.04中Docker的部署
我想用Docker拉取splash,Docker目前已经无法使用(镜像都在国外)。这导致了 docker pull 命令的失败,原因是timeout。所以我们有必要将docker的源设置在国内,直接用国内的镜像。 1.在华为云下的Ubuntu20.04因为源的原因…...

1、C++编程中的基本运算 - 课件
一、基础知识 1、C程序的基本框架 // 预处理器指令,引入需要的头文件 #include <iostream> // 使用标准命名空间 using namespace std; // 主函数,程序的入口 int main() {// 局部变量声明// 程序逻辑代码// 返回值,表示程序正常结束…...

Java动态代理详解
文章目录 一、JDK动态代理1、关键类和接口2、实现步骤 二、CGLIB动态代理1、关键类2、实现步骤 三、总结 Java中的动态代理是一种设计模式,它允许在运行时创建代理对象,而不是在编译时。代理对象可以用来代理真实对象的方法调用。 Java中的动态代理主要…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

Python基于历史模拟方法实现投资组合风险管理的VaR与ES模型项目实战
说明:这是一个机器学习实战项目(附带数据代码文档),如需数据代码文档可以直接到文章最后关注获取。 1.项目背景 在金融市场日益复杂和波动加剧的背景下,风险管理成为金融机构和个人投资者关注的核心议题之一。VaR&…...