课设-机器学习课设-实现新闻分类
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆
🔥系列专栏 :课设-机器学习
📃新人博主 :欢迎点赞收藏关注,会回访!
💬舞台再大,你不上台,永远是个观众。平台再好,你不参与,永远是局外人。能力再大,你不行动,只能看别人成功!没有人会关心你付出过多少努力,撑得累不累,摔得痛不痛,他们只会看你最后站在什么位置,然后羡慕或鄙夷。
文章目录
- 一.工程摘要
- 二、研究背景与意义
- 2.1 研究背景及意义
- 2.2 文本特征提取方法
- 三、模型方法
- 3.1 数据集收集
- 3.2 数据集处理
- 3.3 **朴素贝叶斯模型**
- 3.4 多项式事件模型
- 3.5 模型建立
- 拉普拉斯平滑
- 拉普拉斯平滑
- 3.6 模型的评估
- 四.实验结果分析、对比和讨论
- 4.1 实验结果对比分析:
- 4.2 本次实验的不足
- 五.对本门课的感想、意见和建议
- 六.参考文献
一.工程摘要
摘要: 本次报告实现了新闻分类。从新闻网站上,收集了六类中文文本,分别是政治,体育,法律,经济,科技,美食。对文本采用词集模型和词袋模型分别处理,利用机器学习模型中的基于Multinomial event model模型的朴素贝叶斯文本分类预测进行分类,构建了一个新闻文本分类器。
二、研究背景与意义
2.1 研究背景及意义
中文文本分类在日渐完善的网络信息管理与网络平台建设方面都发挥着重要的作用。国内的信息发布和交流平台主要依靠中文文本进行信息的传递,随着用户的增多,涌现的文本数量也快速增长。平台上服务于用户的个性推荐、垃圾信息过滤等功能的实现主要依托于文本分类技术,然而在网络信息传播过程中,总会出现新鲜类别文本的数量呈爆炸性增长的情况,由于无法在短时间内针对新类别文本进行大量样本标注,会出现文本分类效果不佳的问题,导致与之相关的功能也受到影响。因此,高实时性要求的场景下快速准确的文本分类能力,对于保障网络平台功能的正常运作具有重要意义。基于此背景,本文对基于主动学习的中文文本分类问题进行了研究,能够在保证文本分类器性能的前提下,减少标注样本的使用。
2.2 文本特征提取方法
经过特征提取后保留的文本特征是文本中最重要的特征,但是计算机并不认识,因此需要进一步转化为计算机能识别的向量。特征选择作为文本分类过程中的关键技术之一,那么如何选取贡献程度比较大的特征项集合,大大的降低文本中特征项的维度,进而使文本分类的分类性能得以提升是亟待解决的问题。2005年,Yan 等人提出了正交质心特征选择算法,该算法主要是对正交质子空间学习算法的目标函数进行优化,在特征维度很低的时候,该算法拥有比较出色的表现。2009年,Lin Ying 等人提出了一种新的特征选择算法,该算法主要是基于词权重的概率模型。2013年,Deng和 Zhong提出了一种新的特征选择算法,该算法基于TF-IDF特征加权算法和KL散度,可以更精准的反映文本的类别和内容。2019年,Liu等人提出了一种用于不平衡数据分类的嵌入式特征选择方法。
特征加权同样作为文本分类过程中的一个重要环节,它可以进一步计算文本中的每一个特征项对于文本类别的划分所做的贡献程度值。选择合适的加权算法可以大大提高文本分类最终的分类性能。2007年,Samer等人提出了一种名为Random-Walk特征加权算法,该特征加权算法最终的分类结果也比较出色。2009年,Lin Yin等人提出了一种面向不平衡文本分类的特征加权算法。2010年,Nigam提出了一种基于嫡的特征加权算法,该算法主要是基于信息嫡来度量文本中特征项的权重。2014年,Peng等人提出了一种改进的TF-IDF特征加权算法,该算法可以同时反映文本特征在正类别文本与负类别文本中的重要性。2018年,张敏提出了一种局部一致性的信息嫡Relief特征加权算法。
三、模型方法
3.1 数据集收集
本次报告采用的数据集为新闻网公开的的数据集,分为六类,分别为政治,体育,法律,经济,科技,美食。共25655条数据,其中80%用作训练集,20%用作测试集。
3.2 数据集处理
因为训练集和测试集的处理方法是一致的,所以下文只介绍训练集。
1)首先,将txt中的文本的不同标签下的数据提取,放置于一个二维列表中,因为是有监督学习,所以将同种类的文本放置于同一个维度下,实现代码为load_data_set()和get_data_list()。因为下载的文章有各种标签,所以要用正则表达式读取,实现的代码如下:
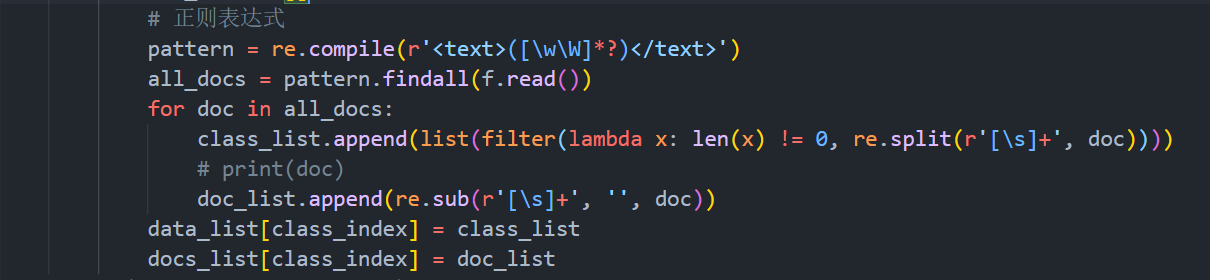
图表 1 数据的读取
2)对其去重,去停用词。去重为了生成词汇表。在生成词汇表时,可用python自带的set集合来表示,集合中不会有重复元素。划分词语时,有些词语是没有实际意思的,对后续的关键词提取就会加大工作量,并且可能提取的关键词是无效的。所以在分词处理以后,引入停用词去优化分词的结果。所以要在词汇表中删除停用词。实现的代码为create_vocab_list()和load_stop_words()。停用词表为网上公开的数据集,提前保存到txt文件中。实现的代码如下:
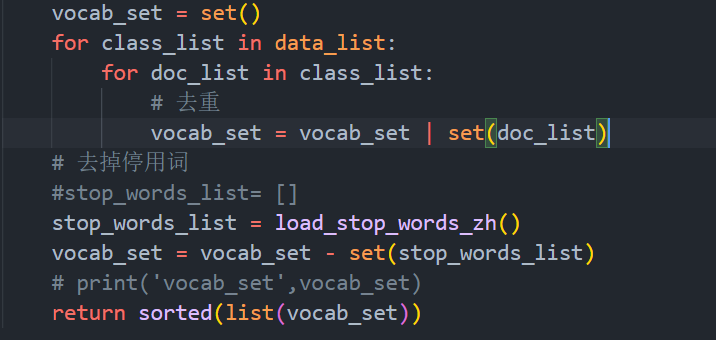
图表 2 生成词汇表和去停用词
3)文本向量化,以词为单位。分别利用如下的词集模型和词袋模型利用上述的词汇表将文本转换为向量。二者的不同点在于,对于重复出现的词在向量中的位置由1表示,还是由出现的次数表示。
词集模型
词袋模型
实现的代码如下:
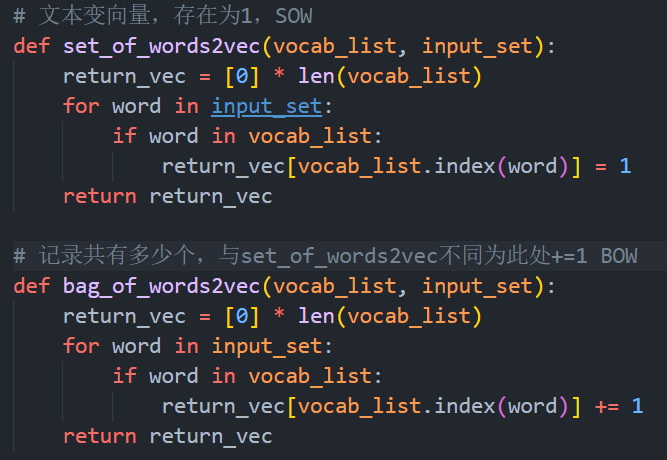
图表 3 SOW和BOW的代码实现
3.3 朴素贝叶斯模型
贝叶斯公式如下:
由于同一个训练集的p(x)和p(y)相等,则可以转化为如下公式:即类先验概率和类条件概率的乘积由于模型采用了y=cj,表明使用了标签信息,最后预测时,需要对测试样本属于每个标签的概率都要计算一遍。不像生成式一般直接就输出测试样本的概率分布。
3.4 多项式事件模型
1)模型概率计算:
假设每个类别的概率
将文本转换为字符统计,将重复字符转为N次方形式
联合概率
2)最大似然求参:
3)解出闭式解:
MLE 公式
应用拉格朗日乘法
4)闭式MLE解:
梯度
MLE解
为了避免在预测时出现概率为零的情况,应用拉普拉斯平滑
3.5 模型建立
程序首先输入预先统计好的词汇表数和文档数目,利用拉普拉斯平滑方法创建一个全为1的数组。然后继续利用拉普拉斯方法初始化所有标签的概率,即分子为相应的标签数量+1,分母为训练集总标签的数量+标签的分类数量(本报告为6)。
for i in range(len(p_class)):
拉普拉斯平滑
p_class[i] = np.log((train_category.count(i) + 1.0) / (len(train_category) + classes_num))
然后循环整个训练集,按照上述公式,累加相应标签下,相应词中每个元素的分子分母。
for i in range(classes_num):
拉普拉斯平滑
p_words_num.append(np.ones(num_words))
p_words_denom.append(num_words)
分子和分母相除时,要取对数,防止下溢出。
for i in range(classes_num):
p_words.append(np.log(p_words_num[i] / p_words_denom[i]))
即计算每个标签下的每个词出现的累加概率,此时的值即为后续验证集中某个词是否为相应标签下的权重。后续预测时,不像生成式一般直接就输出测试样本的概率分布,需要对测试样本属于每个标签的概率都要计算一遍。
for class_index in range(classes_num):
log_sum = p_class[class_index]
for i in range(len(bag_of_words_vec)):
if bag_of_words_vec[i] > 0:
log_sum += bag_of_words_vec[i] * p_words[class_index][i]
此时,选择概率最大的所属标签即为可能的标签。Python中的矩阵模块自带函数numpy.argmax可以得到每一维度下最大值所在的索引,刚好对应相应字典中的标签。此时便可在有监督学习下预测值是否正确。
3.6 模型的评估
过拟合:一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)(高方差)
欠拟合:一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)(高偏差)
初步测试时,将20%的测试集放入测试,得到准确率为93.90%,怀疑是过度拟合,将80%的测试集放入测试,得到准确率为99.16%,模型过于拟合,方差太高,我认为是有几点可以改进的地方,1、增大数据的训练量,2、减少特征维度,减少词汇表,3、正则化。本次报告从前两点入手。
起初,词汇表为23983条词汇。将词汇随机选取18000条,测试是否拟合程度可以下降。结果为将20%的测试集放入测试,得到准确率为94.93%,将80%的测试集放入测试,得到准确率为98.83%,得出结论,该程序过拟合,并且当适当缩小词汇表规模的情况下,可以增加准确率。所以需要降低特征维度,也就是降低词汇表中的数据集数量,所以设计程序以1000的间隔遍历词汇表,观察测试集和训练集的准确率。程序运行的结果如下图:
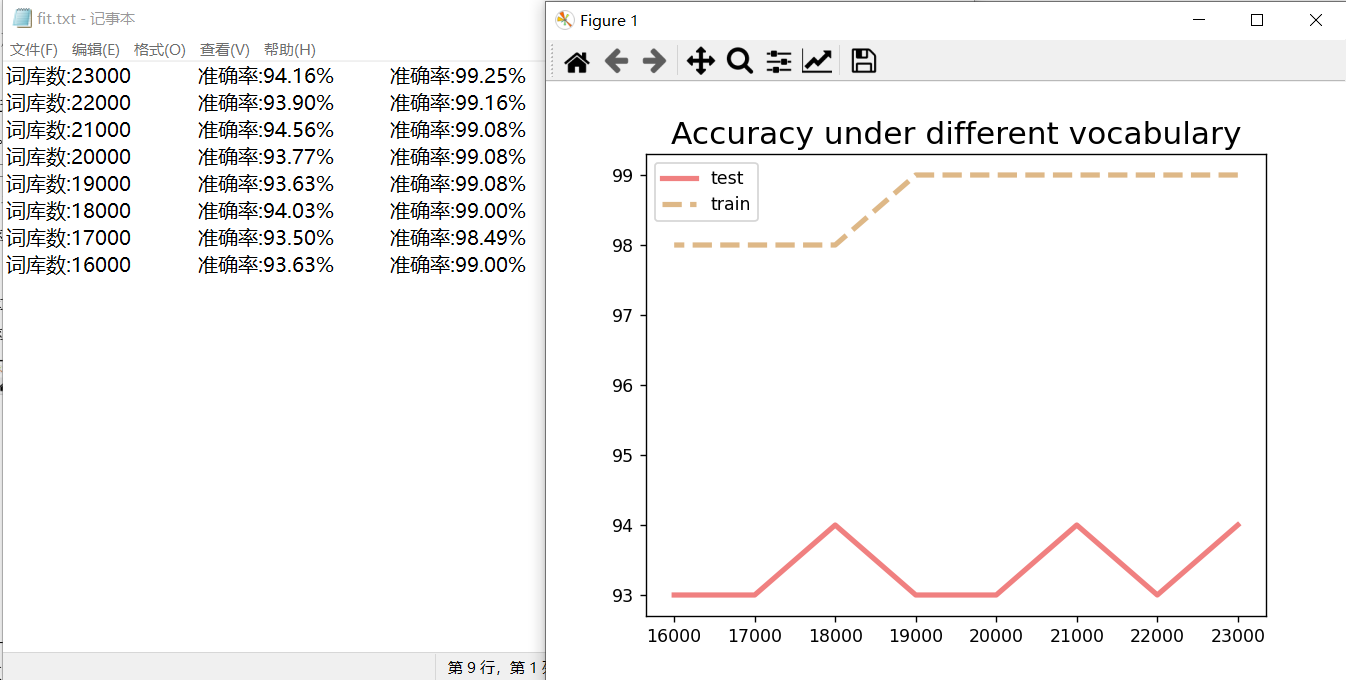
图表 4 词汇表在16000-23000的测试结果
由图像可知,在21000附近以100位单位继续划分,得到如下结果:
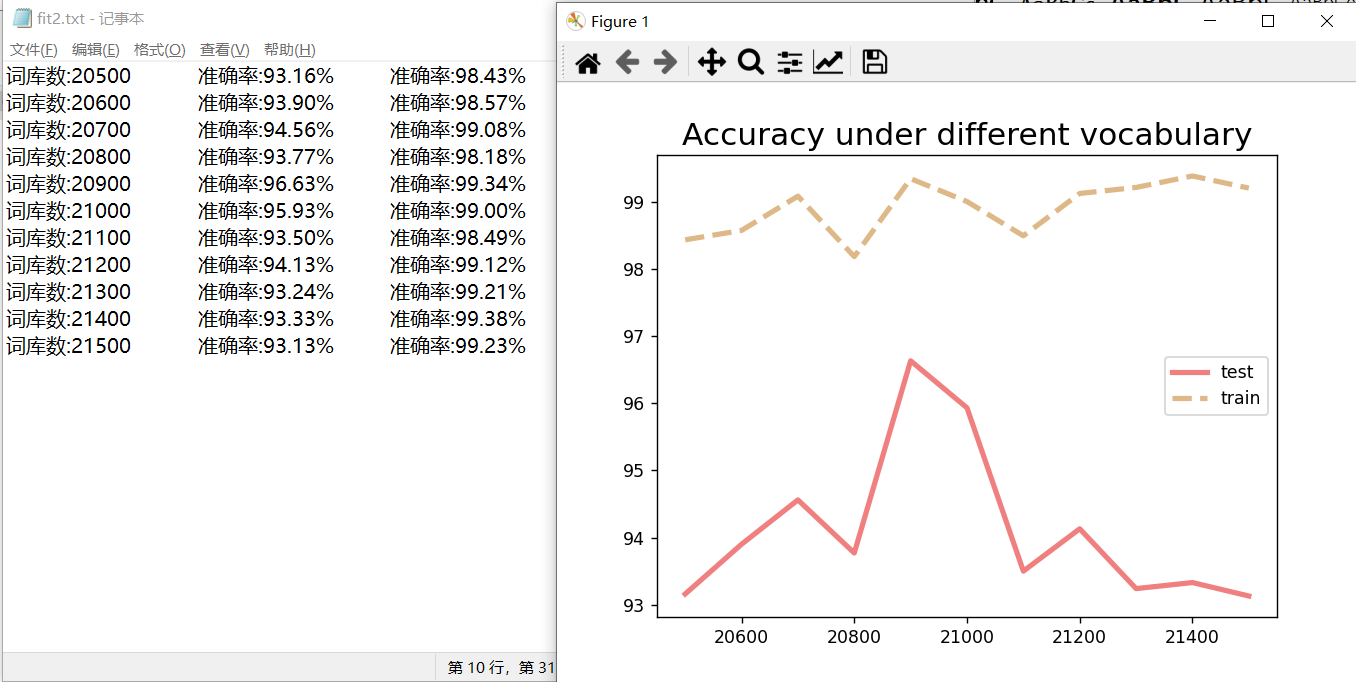
图表 5词汇表在20500-21500的测试结果
由上图可知,词汇表在20900附近,得到的模型较好,拟合度较高。
四.实验结果分析、对比和讨论
4.1 实验结果对比分析:
1)不同数量词汇表下的准确率:
一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)(高方差)。一个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了欠拟合的现象。(模型过于简单)(高偏差)经过对比和遍历循环,找到了最适合的,最拟合的数据集如下图所示:

图表 6 词汇表在20500-21500的测试结果
2)SOW和BOW模型下的准确率:
经过对比SOW和BOW模型下的准确率,发现BOW下的准确率略高于SOW,SOW是单个文本中单词出现在字典中,就将其置为1,而不管出现多少次。BOW是单个文本中单词出现在字典中,就将其向量值加1,出现多少次就加多少次。 所以BOW比SOW更能表现原始数据的特点吧,但是都是基于词之间保持独立性,没有关联为前提。这使得其统计方便,但同时也丢失了文本间词之间关系的信息。结果如下图:

图表 7 SOW和BOW模型
3)是否去停用词下的准确率
经过对比是否去掉停词,划分词语时,有些词语是没有实际意思的,对后续的关键词提取就会加大工作量,并且可能提取的关键词是无效的。所以在分词处理以后,引入停用词去优化分词的结果。所以结果如下图:
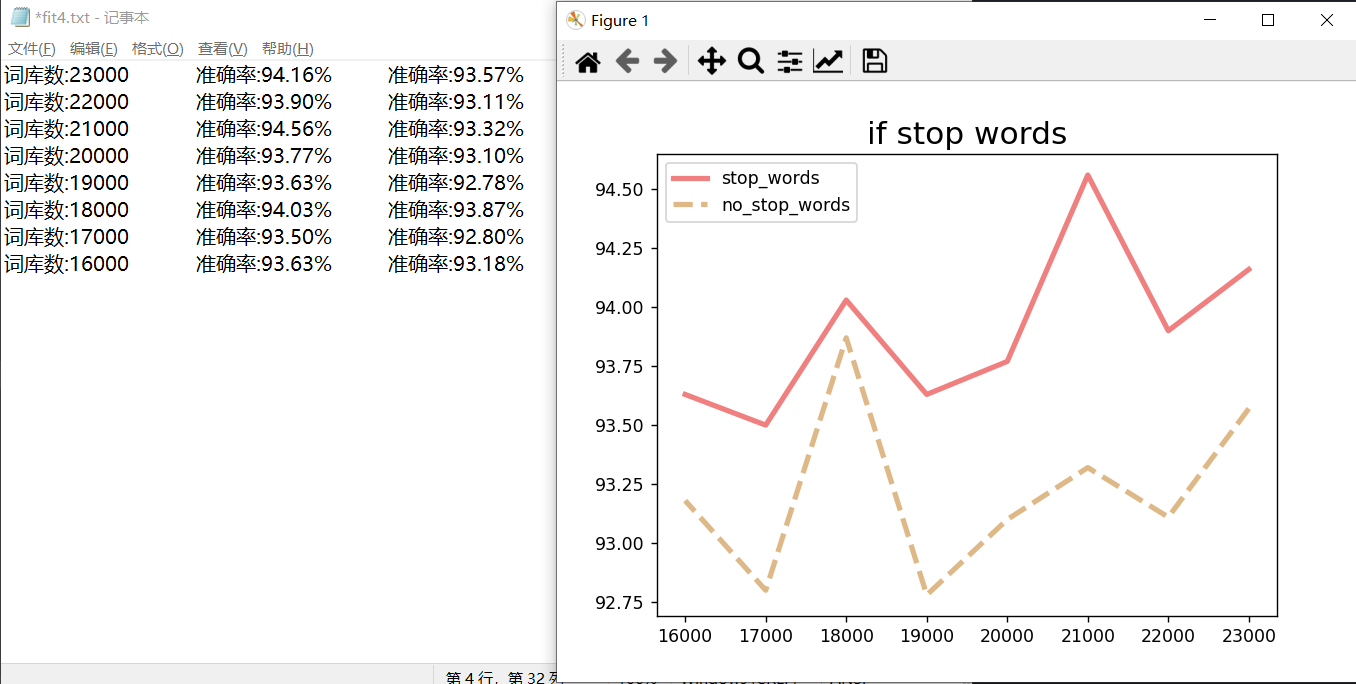
图表 8 是否去除停用词
3)多元伯努利事件模型和多项式事件模型下的准确率
二者的计算粒度不一样,多项式模型以词为粒度,伯努利模型以文件为粒度,因此二者的先验概率和类条件概率的计算方法都不同。计算后验概率时,对于一个文档d,多项式模型中,只有在d中出现过的词,才会参与后验概率计算,伯努利模型中,没有在d中出现,但是在全局单词表中出现的单词,也会参与计算,不过是作为“反方”参与的。所以在词汇表为23983条词汇时,结果如下表:
| 模型名称\准确率 | 测试集准确率 | 训练集准确率 |
|---|---|---|
| 多项式事件模型 | 93.90% | 99.16% |
| 多元伯努利事件模型 | 87.64% | 97.85% |
图表 9多元伯努利事件模型和多项式事件模型
4.2 本次实验的不足
1)SOW和BOW都是基于词之间保持独立性,没有考虑句子有关联为前提。这使得其统计方便,但同时也丢失了文本间词之间关系的信息。可以采用经典的One-hot模型、TF-IDF模型和基于深度学习的Word2vec模型。TF-IDF模型与One-hot模型相比,可以计算反词频概率值;Word2vec模型能解决One-hot模型和TF-IDF模型的维度灾难和向量稀疏的缺陷。
2)因为用到了随机函数,删掉了部分特征点(并没有考虑这些特征的权值),所以模型的参数最终是在一个合理的空间范围内,需要进一步的缩小范围,然后得到确切得值。
3)朴素贝叶斯分类器。朴素贝叶斯在机器学习中非常常见,尤其是在文本分类中对于情感分析、垃圾邮件处理等应用比较广泛。但是对于朴素贝叶斯分类算法,以后还可以考虑对条件概率的计算方法进行改进。
五.对本门课的感想、意见和建议
过本次实验,我熟悉了python语言的语法,并可以熟练的使用。同时也培养了我的动手能力,“实验就是为了让你动手做,去探索一些你未知的或是你尚不是深刻理解的东西。每个步骤我都亲自去做,不放弃每次锻炼的机会。经过这一周,让我的动手能力有了明显的提高。机器学习课程历时大半个学期,做实验时通过自己编写、运行程序,不仅可以巩固了以前所学过的知识,而且学到了很多在书本上所没有学到过的知识。以前对于编程工具的使用还处于一知半解的状态上,但是经过一段上机的实践,对于怎么去排错、查错,怎么去看每一步的运行结果。不仅巩固了书本所学的知识,还具有一定的灵活性,发挥了我们的创造才能。
通过这次课程设计使我懂得了理论与实际相结合是很重要的,只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能真正提高自己的实际动手能力和独立思考的能力。在设计的过程中遇到问题,可以说得是困难重重,这毕竟第一次做的,难免会遇到过各种各样的问题,同时在设计的过程中发现了自己的不足之处,对以前所学过的知识理解得不够深刻,掌握得不够牢固。这次课程设计终于顺利完成了,在设计中遇到了很多编程问题,最后在自己的思考以及和同学的讨论中,终于迎刃而解。
本门课程算是我最喜欢的一门课程了,他有完整的机器学习体系,可以让我们从0到1,合肥工业大学的老师和网课吴恩达老师相辅相成,共同助力我们理解机器学习,coursera网课配套的实验编程题题引导我一步一步导入数据,构建模型,评估模型,参数优化等,为今天的工程设计打下了夯实的基础。
六.参考文献
- 青盏.朴素贝叶斯模型 多元伯努利事件模型+多项式事件模型 Multi-Variate Bernoulli Event Model and Multinomial Event Model. https://blog.csdn.net/qq_16234613/article/. 2018
- 吴恩达.Machine Learning. https://www.coursera.org/ .2022
相关文章:
课设-机器学习课设-实现新闻分类
✅作者简介:CSDN内容合伙人、信息安全专业在校大学生🏆 🔥系列专栏 :课设-机器学习 📃新人博主 :欢迎点赞收藏关注,会回访! 💬舞台再大,你不上台,…...

关于异常控制流和系统级 I/O:进程
💭 写在前面:本文将学习《深入理解计算机系统》的第六章 - 关于异常控制流和系统级 I/O 的 进程部分。CSAPP 是计算机科学经典教材《Computer Systems: A Programmers Perspective》的缩写,该教材由Randal E. Bryant和David R. OHallaron 合著…...
)
Unet 基于TCGA颅脑肿瘤MRI分割(交叉熵损失+多通道输出)
目录 1. 介绍 2. Unet 2.1 unet 代码 2.2 测试网络 3. dataset 数据加载 4. train 训练...
)
货物摆放(蓝桥杯C/C++省赛)
题目描述 小蓝有一个超大的仓库,可以摆放很多货物。 现在,小蓝有 nn 箱货物要摆放在仓库,每箱货物都是规则的正方体。小蓝规定了长、宽、高三个互相垂直的方向,每箱货物的边都必须严格平行于长、宽、高。 小蓝希望所有的货物最…...

mysql 索引原理
文章目录 1、索引的本质2、索引的分类2.1、Hash 索引2.2、二叉树2.4、B树(二三树)2.5、B+树3、主键目录4、索引页5、索引页的分层6、非主键索引7.回表1、索引的本质 索引的本质是一种排好序的数据结构。 2、索引的分类 在数据库中,索引是分很多种类的(千万不要狭隘的认为…...
【Linux】文件系统详解
😊😊作者简介😊😊 : 大家好,我是南瓜籽,一个在校大二学生,我将会持续分享C/C相关知识。 🎉🎉个人主页🎉🎉 : 南瓜籽的主页…...
3句代码,实现自动备份与版本管理
前言:服务器开发程序、测试版本等越来越多,需要及时做好数据的版本管理和备份,作为21世界的青年,希望这些事情都是可以自动完成,不止做了数据备份,更重要的是做好了版本管理,让我们可以追溯我们…...
| 机考必刷)
华为OD机试题 - 删除指定目录(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:删除指定目录题目输入输出示例一输入输出说明Code解题思路华为O…...

3分钟上手,2小时起飞!教你玩转OceanBase Cloud
盼星星盼月亮!掰掰手指,距离 3 月 25 日还有 123456......两周啦🤩~ 除了白天的主论坛和分论坛的精彩分享外,晚间的 3 场 Hands-on Workshop 动手实验营也深得大家期待,从部署到迁移,从 On-Premise 到 Clou…...
location对象详解
location对象 location是最有用的BOM对象之一,它提供了与当前窗口中加载的文档信息,还提供了一些导航功能。既是window对象,也是document对象的属性,即window.location和document.location引用的是同一个对象。它主要的功能有以下…...
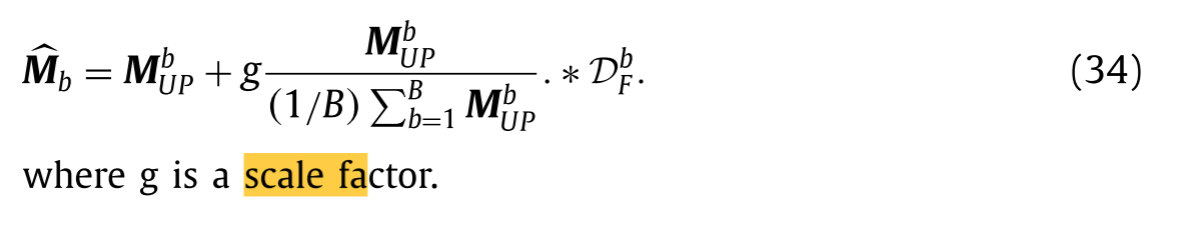
【强度混合和波段自适应细节融合:PAN-Sharpening】
Intensity mixture and band-adaptive detail fusion for pansharpening (用于全色锐化的强度混合和波段自适应细节融合) 全色锐化的目的是通过高分辨率单通道全色(PAN)图像锐化低分辨率多光谱(MS)图像&a…...

【随笔】《挥手自兹去》
挥手自兹去那样美的一束光照在我身上,挥手自兹去,下次又要何时再见?那日闲来无事,到小区前的公园里散步。绿草如因,野花点点,阳光照的人很舒服。一片空地上,我看见了一个女孩,她那么…...
| 机考必刷)
华为OD机试题 - 最差产品奖(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:最差产品奖题目输入输出示例一输入输出说明Code版权说明华为OD其…...

虚拟化介绍
1、为什么需要虚拟化 据调查传统的服务器在很多时候处于休眠状态,大概只有5%时间是在工作,工作效率低下,浪费资源,因此需要一种手段来提高计算机资源的利用率。 虚拟化前 每台主机一个操作系统 在同一台主机运行多个应用程序&am…...
c/c++开发,无可避免的模板编程实践(篇十)-c++11原位构造元素(emplace)
一、容器修改器的新特性 c11以前,标准库的容器修改器功能提供了数据插入成员函数inset、push_back,而在 c11标准化,标准库的容器修改器增加了emplace、emplace_back、emplace_front等插入成员函数。同样是插入函数,两者有何区别呢…...

基于bash通过cdo批处理数据
***#################################### ubuntu中编写shell脚本文件 第一步:用vim创建一个以.sh结尾的文件,此时这个文件是暂时性的文件,当编写好文件并保存时才能看到文件; 第二步:要首先按一下“i”键才能进行插入…...
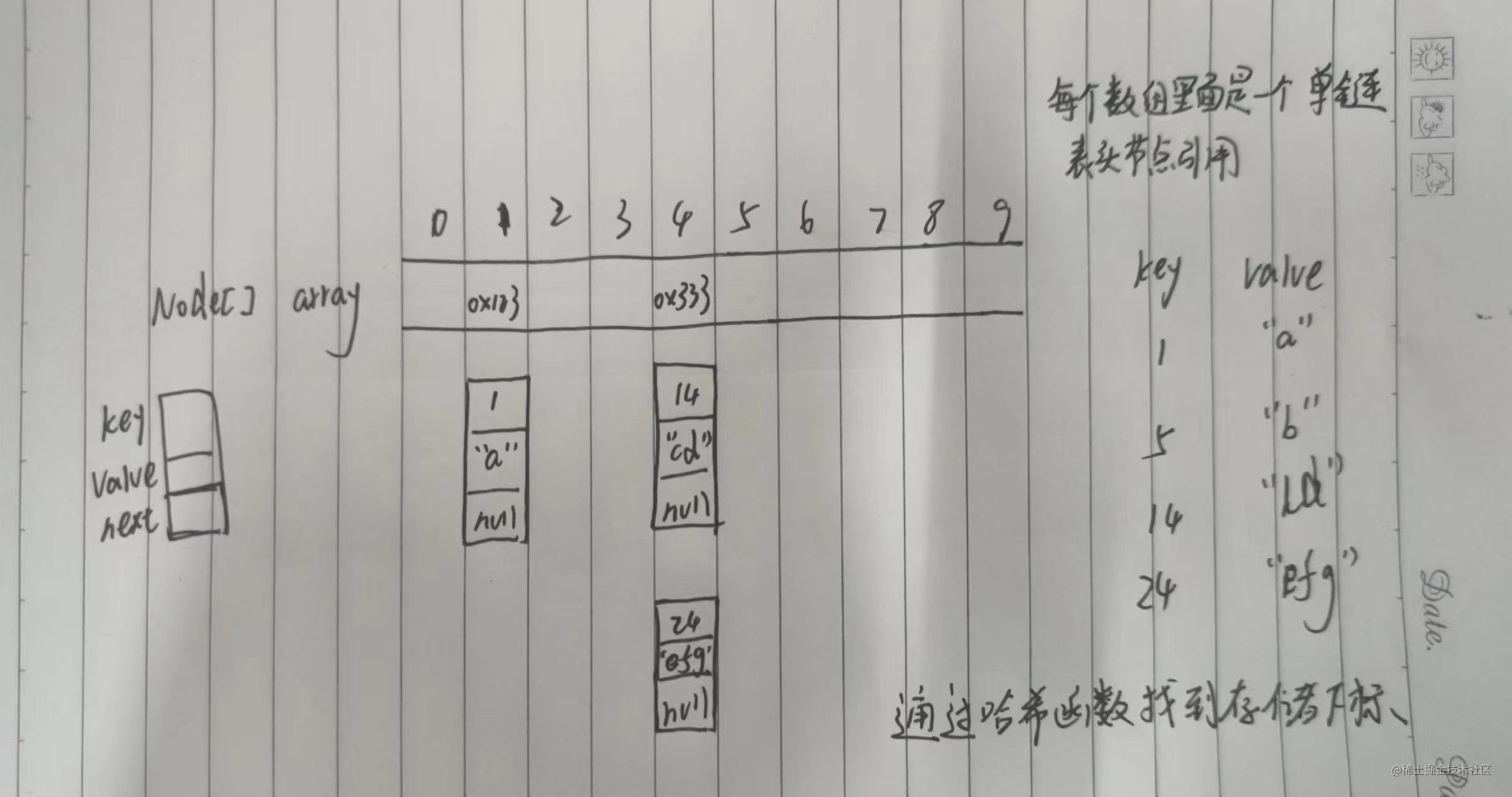
Map和Set总结
Map和Set Map和Set是专门用来进行搜索的数据结构,适合动态查找 模型 搜索的数据称为关键字(key),关键字对应的叫值(value),key-value键值对 key模型key-value模型 Map存储的就是key-value模型,Set只存储了key Map Map是接口类…...

pytorch网络模型构建中的注意点
记录使用pytorch构建网络模型过程遇到的点 1. 网络模型构建中的问题 1.1 输入变量是Tensor张量 各个模块和网络模型的输入, 一定要是tensor 张量; 可以用一个列表存放多个张量。 如果是张量维度不够,需要升维度, 可以先使用 …...

面试时候这样介绍redis,redis经典面试题
为什么要用redis做缓存 使用Redis缓存有以下几个优点: 1. 提高系统性能:缓存可以将数据存储在内存中,加快数据的访问速度,减少对数据库的读写次数,从而提高系统的性能。 2. 减轻后端压力:使用缓存可以减…...

机械学习 - scikit-learn - 数据预处理 - 2
目录关于 scikit-learn 实现规范化的方法详解一、fit_transform 方法1. 最大最小归一化手动化与自动化代码对比演示 1:2. 均值归一化手动化代码演示:3. 小数定标归一化手动化代码演示:4. 零-均值标准化(均值移除)手动与自动化代码演示&#x…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

智能仓储的未来:自动化、AI与数据分析如何重塑物流中心
当仓库学会“思考”,物流的终极形态正在诞生 想象这样的场景: 凌晨3点,某物流中心灯火通明却空无一人。AGV机器人集群根据实时订单动态规划路径;AI视觉系统在0.1秒内扫描包裹信息;数字孪生平台正模拟次日峰值流量压力…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

图表类系列各种样式PPT模版分享
图标图表系列PPT模版,柱状图PPT模版,线状图PPT模版,折线图PPT模版,饼状图PPT模版,雷达图PPT模版,树状图PPT模版 图表类系列各种样式PPT模版分享:图表系列PPT模板https://pan.quark.cn/s/20d40aa…...