【可控图像生成系列论文(二)】MimicBrush 港大、阿里、蚂蚁集团合作论文解读2
【可控图像生成系列论文(一)】简要介绍了论文的整体流程和方法,本文则将就整体方法、模型结构、训练数据和纹理迁移进行详细介绍。

1.整体方法
MimicBrush 的整体框架如下图所示。为了实现模仿编辑,作者设计了一种具有双扩散模型的架构,并以自监督的方式进行训练。视频数据本身包含自然一致的内容,同时也展示了视觉变化,例如同一只狗的不同姿势。
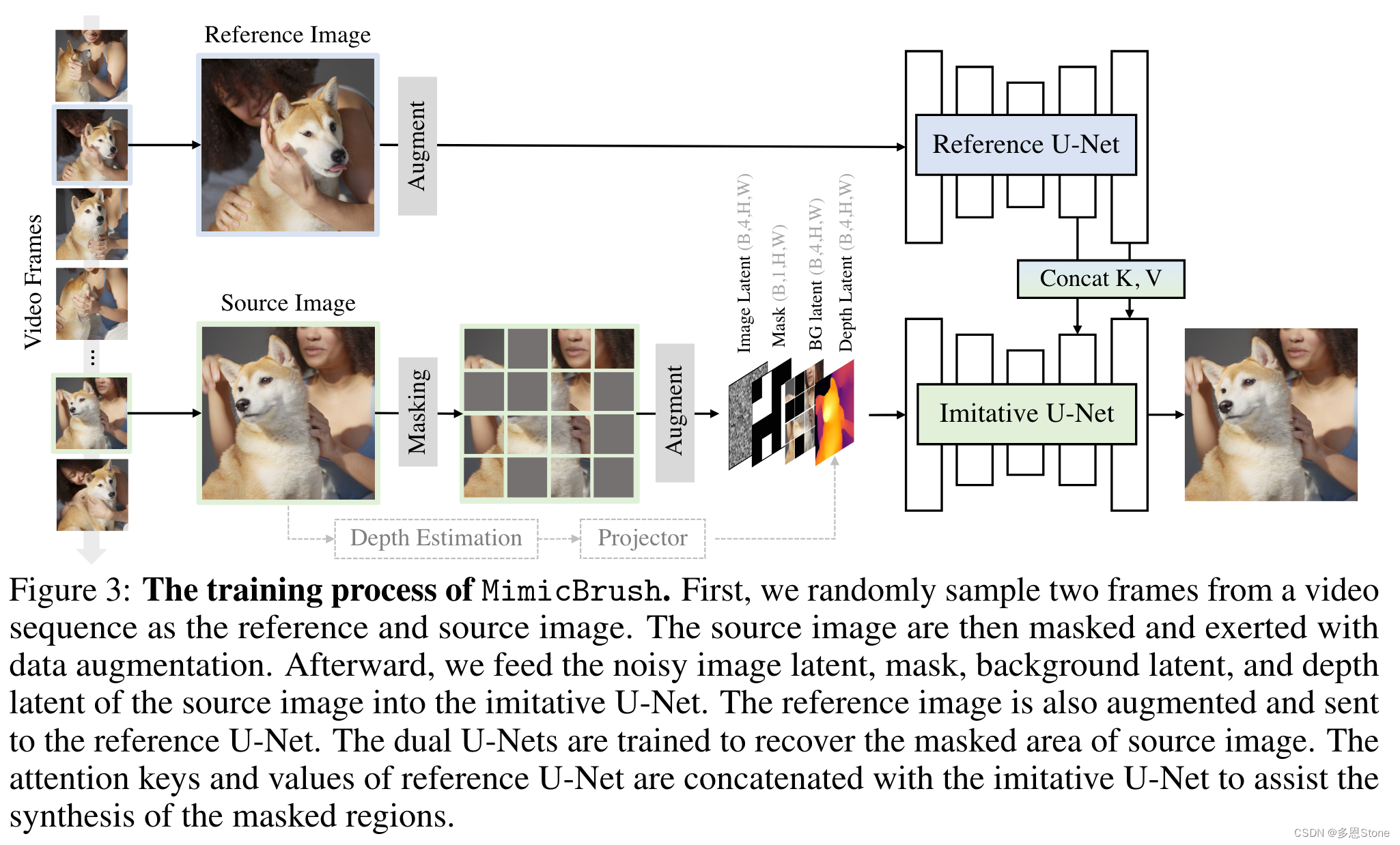
- 因此,作者从视频片段中随机选择两个帧作为 MimicBrush 的训练样本。一帧作为源图像,作者在其某些区域上进行遮罩。另一帧作为参考图像,帮助模型恢复被遮罩的源图像。
- 通过这种方式,MimicBrush 学会了定位相应的视觉信息(例如狗的脸),并将其重新绘制到源图像的遮罩区域中。
- 为了确保重新绘制的部分能够与源图像和谐融合,MimicBrush 还学习将视觉内容转移到相同的姿势、光照和视角下。
- 值得注意的是,这样的训练过程是基于原始视频片段进行的,不需要文本或跟踪注释,并且可以通过大量视频轻松扩展。
- MimicBrush 利用双分支的 U-Nets,即模仿 U-Net 和参考 U-Net,分别以源图像和参考图像为输入。这两个 U-Nets 在注意力层中共享它们的键和值,并被训练以从参考图像中寻找指示来复原被遮罩的源图像。
- 作者还对源图像和参考图像进行数据增强,以增加它们之间的区别。
- 同时,从未被遮罩的源图像中提取深度图,并将其作为可选条件添加到模仿 U-Net 中。通过这种方式,在推理过程中,用户可以决定是否启用源图像的深度图,以保留原始源图像中物体的形状。
2.模型结构
框架主要包括模仿 U-Net、参考 U-Net 和深度模型。
模仿 U-Net
- 模仿 U-Net 是基于 stable diffusion-1.5-inpainting1 模型初始化的。它以一个具有 13 个通道的张量作为输入。
- 图像潜变量(4 个通道)负责从初始噪声一步步扩散到输出潜变量代码。作者还连接了一个二进制遮罩(1 个通道)以指示生成区域,以及被遮罩源图像的背景潜变量(4 个通道)。此外,作者将深度图投射到一个(4 通道)深度潜变量,以提供形状信息。
- 原始 U-Net 还通过交叉注意力接收 CLIP 2 文本嵌入作为输入。在本研究中,作者用从参考图像中提取的 CLIP 图像嵌入替换了它。
- 按照之前的研究 3 4,作者在图像嵌入之后添加了一个可训练的投射层。为了简化图示,图 3 中未包含此部分。在训练期间,模仿 U-Net 和 CLIP 投射层的所有参数都是可优化的。
参考 U-Net
- 最近,一些研究 5 6 7 8 9 10 证明了利用额外的 U-Net 从参考图像中提取细粒度特征的有效性。
- 在本研究中,作者应用了类似的设计并引入了一个参考 U-Net。它是基于标准 stable diffusion-1.5 11 初始化的。它采用参考图像的 4 通道潜变量来提取多层次特征。
- 参考 12,作者在中间和上采样阶段将参考特征注入模仿 U-Net,通过将其键和值与模仿 U-Net 连接起来,如下公式所示。
Attention = softmax ( Q i ⋅ cat ( K i , K r ) T d k ) ⋅ cat ( V i , V r ) \text{Attention} = \text{softmax}\left( \frac{Q_i \cdot \text{cat}(K_i, K_r)^T}{\sqrt{d_k}} \right) \cdot \text{cat}(V_i, V_r) Attention=softmax(dkQi⋅cat(Ki,Kr)T)⋅cat(Vi,Vr) - 通过这种方式,模仿 U-Net 可以利用参考图像的内容来完成源图像的遮罩区域。
深度模型
- 作者利用 Depth Anything 13 来预测未遮罩源图像的深度图作为形状控制,这使 MimicBrush 能够进行纹理迁移。
- 作者冻结了深度模型并添加了一个可训练的映射器,将预测的深度图(3 通道)投射到深度潜变量(4 通道)。
- 在训练期间,作者设定以 0.5 的概率将深度模型的输入设为全零图。因此,用户在推理过程中可以选择是否启用形状控制。
3.训练数据
- 训练数据选择的要点:
- 首先,保证源图像和参考图像之间存在对应关系。
- 其次,作者预计源图像和参考图像之间会有很大的变化,这对于寻找视觉对应关系的稳健性至关重要。
- 如何确保“对应关系”?(数据选择)
- 在训练过程中,作者对同一视频中的两帧进行采样。参考前人的研究14,作者使用SSIM 15作为衡量视频帧之间的相似性的指标。
- 作者丢弃相似性过大或过小的帧(图片)对,以确保所选图像对包含语义对应和视觉变化。
- 训练数据来源:
- 作者从 Pexels 16 等开源网站收集了10万个高分辨率视频。
- 为了进一步扩大训练样本的多样性,还使用SAM 17数据集,该数据集包含1000万张图像和10亿个对象掩码。作者通过对来自SAM的静态图像应用强数据增强来构建伪帧,并利用对象分割结果来掩蔽源图像。
- 在训练期间,视频和SAM数据的采样部分为70%,而默认情况下为30%。
如上图所示,训练数据中的源图像和参考图像都通过了一定的数据增强后,再被分别送入 U-Net 中。
- 那么具体的数据增强是如何做的?
- 为了增加源图像和参考图像之间的变化,作者施加了较强的数据增强。
- 除了应用激进的颜色抖动、旋转、调整大小和翻转外,作者还实现了随机投影变换来模拟更强的变形。
4. 评估任务-纹理迁移

- 纹理迁移需要严格保持源对象的形状,并且仅迁移参考图像的纹理/图案。
- 为此任务,作者启用了深度图作为附加条件。与寻求语义对应的部分组合不同,在此任务中作者对完整对象进行遮罩,因此模型只能发现纹理(参考)和形状(源)之间的对应关系。
- 作者还制定了 inter-ID 和 inner-ID 两类。
- 前者涉及30个来自Pexels 18 的具有大变形的样本,比如将豹纹迁移到图4中的帽子上。
- 后者包含DreamBooth 19 数据集中额外的30个示例。作者遵循与部分组合相同的数据格式和评估指标。
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022 ↩︎
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021. ↩︎
X. Chen, L. Huang, Y. Liu, Y. Shen, D. Zhao, and H. Zhao. Anydoor: Zero-shot object-level image customization. CVPR, 2024. ↩︎
H. Ye, J. Zhang, S. Liu, X. Han, and W. Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv:2308.06721, 2023. ↩︎
L. Zhang. Reference-only controlnet. https://github.com/Mikubill/sd-webui-controlnet/ discussions/1236, 2023. ↩︎
L. Hu, X. Gao, P. Zhang, K. Sun, B. Zhang, and L. Bo. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. CVPR, 2024. ↩︎
Z. Xu, J. Zhang, J. H. Liew, H. Yan, J.-W. Liu, C. Zhang, J. Feng, and M. Z. Shou. Magicanimate: Temporally consistent human image animation using diffusion model. In CVPR, 2024. ↩︎
M. Chen, X. Chen, Z. Zhai, C. Ju, X. Hong, J. Lan, and S. Xiao. Wear-any-way: Manipulable virtual try-on via sparse correspondence alignment. arXiv:2403.12965, 2024. ↩︎
S. Zhang, L. Huang, X. Chen, Y. Zhang, Z.-F. Wu, Y. Feng, W. Wang, Y. Shen, Y. Liu, and P. Luo. Flashface: Human image personalization with high-fidelity identity preservation. arXiv:2403.17008, 2024. ↩︎
Z. Xu, M. Chen, Z. Wang, L. Xing, Z. Zhai, N. Sang, J. Lan, S. Xiao, and C. Gao. Tunnel try-on: Excavating spatial-temporal tunnels for high-quality virtual try-on in videos. arXiv:2404.17571, 2024. ↩︎
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022 ↩︎
Z. Xu, J. Zhang, J. H. Liew, H. Yan, J.-W. Liu, C. Zhang, J. Feng, and M. Z. Shou. Magicanimate: Temporally consistent human image animation using diffusion model. In CVPR, 2024. ↩︎
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. In CVPR, 2024. ↩︎
X. Chen, Z. Liu, M. Chen, Y. Feng, Y. Liu, Y. Shen, and H. Zhao. Livephoto: Real image animation with text-guided motion control. arXiv:2312.02928, 2023 ↩︎
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity. TIP, 2004. ↩︎
The best free stock photos, royalty free images & videos shared by creators. https://www. pexels.com, 2024 ↩︎
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al. Segment anything. In ICCV, 2023 ↩︎
The best free stock photos, royalty free images & videos shared by creators. https://www. pexels.com, 2024 ↩︎
N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, and K. Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In CVPR, 2023 ↩︎
相关文章:
【可控图像生成系列论文(二)】MimicBrush 港大、阿里、蚂蚁集团合作论文解读2
【可控图像生成系列论文(一)】简要介绍了论文的整体流程和方法,本文则将就整体方法、模型结构、训练数据和纹理迁移进行详细介绍。 1.整体方法 MimicBrush 的整体框架如下图所示。为了实现模仿编辑,作者设计了一种具有双扩散模型…...

Linux时间子系统6:NTP原理和Linux NTP校时机制
一、前言 上篇介绍了时间同步的基本概念和常见的时间同步协议NTP、PTP,本篇将详细介绍NTP的原理以及NTP在Linux上如何实现校时。 二、NTP原理介绍 1. 什么是NTP 网络时间协议(英语:Network Time Protocol,缩写:NTP&a…...

边缘微型AI的宿主?—— RISC-V芯片
一、RISC-V技术 RISC-V(发音为 "risk-five")是一种基于精简指令集计算(RISC)原则的开放源代码指令集架构(ISA)。它由加州大学伯克利分校在2010年首次发布,并迅速获得了全球学术界和工…...

MySQL—navicat创建数据库表
-- 创建学生表(列,字段) 使用SQL创建 -- 学号int 登录密码varchar(20) 姓名,性别varchar(2),出生日期(datetime),家庭住址,email -- 注意点:使用英文括号(),表的名称 …...
html做一个画柱形图的软件
你可以使用 HTML、CSS 和 JavaScript 创建一个简单的柱形图绘制软件。为了方便起见,我们可以使用一个流行的 JavaScript 图表库,比如 Chart.js,它能够简化创建和操作图表的过程。 以下是一个完整的示例,展示如何使用 HTML 和 Cha…...
Pyshark——安装、解析pcap文件
1、简介 PyShark是一个用于网络数据包捕获和分析的Python库,基于著名的网络协议分析工具Wireshark和其背后的libpcap/tshark库。它提供了一种便捷的方式来处理网络流量,适用于需要进行网络监控、调试和研究的场景。以下是PyShark的一些关键特性和使用方…...

java中的Random
Random 是 Java 中的一个内置类,它位于 java.util 包中,主要用于生成伪随机数。伪随机数是指通过一定算法生成的、看似随机的数,但实际上这些数是由确定的算法生成的,因此不是真正的随机数。然而,由于这些数在统计上具…...
PyMuPDF 操作手册 - 01 从PDF中提取文本
文章目录 一、打开文件二、从 PDF 中提取文本2.1 文本基础操作2.2 文本进阶操作2.2.1 从任何文档中提取文本2.2.2 如何将文本提取为 Markdown2.2.3 如何从页面中提取键值对2.2.4 如何从矩形中提取文本2.2.5 如何以自然阅读顺序提取文本2.2.6 如何从文档中提取表格内容2.2.6.1 提…...

ResNet——Deep Residual Learning for Image Recognition(论文阅读)
论文名:Deep Residual Learning for Image Recognition 论文作者:Kaiming He et.al. 期刊/会议名:CVPR 2016 发表时间:2015-10 论文地址:https://arxiv.org/pdf/1512.03385 1.什么是ResNet ResNet是一种残差网络&a…...
)
java基础·小白入门(五)
目录 内部类与Lambda表达式内部类Lambda表达式 多线程 内部类与Lambda表达式 内部类 在一个类中定义另外一个类,这个类就叫做内部类或内置类 (inner class) 。在main中直接访问内部类时,必须在内部类名前冠以其所属外部类的名字才能使用;在…...
微观时空结构和虚数单位的关系
回顾虚数单位的定义, 其中我们把称为周期(的绝大部分),称为微分,0称为原点或者起点(意味着新周期的开始),由此我们用序数的概念反过来构建了基数的概念。 周期和单位显然具有倍数关…...

go-zero使用goctl生成mongodb的操作使用方法
目录 MongoDB简介 MongoDB的优势 对比mysql的操作 goctl的mongodb代码生成 如何使用 go-zero中mogodb使用 mongodb官方驱动使用 model模型的方式使用 其他资源 MongoDB简介 mongodb是一种高性能、开源、文档型的nosql数据库,被广泛应用于web应用、大数据以…...
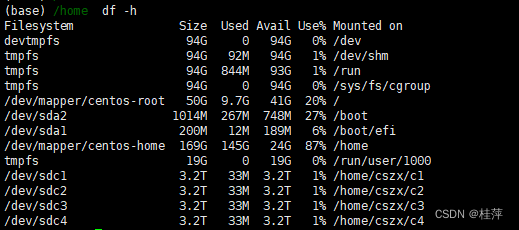
服务器新硬盘分区、格式化和挂载
文章目录 参考文献查看了一下起点现状分区(base) ~ sudo parted /dev/sdcmklabel gpt(设置分区类型)增加分区 格式化需要先退出quit(可以)(base) / sudo mkfs.xfs /dev/sdc/sdc1(失败)sudo mkfs.xfs /dev/s…...

Openldap集成Kerberos
文章目录 一、背景二、Openldap集成Kerberos2.1kerberos服务器中绑定Ldap服务器2.1.1创建LDAP管理员用户2.1.2添加principal2.1.3生成keytab文件2.1.4赋予keytab文件权限2.1.5验证keytab文件2.1.6增加KRB5_KTNAME配置 2.2Ldap服务器中绑定kerberos服务器2.2.1生成LDAP数据库Roo…...
(创新)基于VMD-CNN-BiLSTM的电力负荷预测—代码+数据
目录 一、主要内容: 二、运行效果: 三、VMD-BiLSTM负荷预测理论: 四、代码数据下载: 一、主要内容: 本代码结合变分模态分解( Variational Mode Decomposition,VMD) 和卷积神经网络(Convolutional neu…...

机器 reboot 后 kubelet 目录凭空消失的灾难恢复
文章目录 [toc]事故背景报错内容 修复过程停止 kubelet 服务备份 kubelet.config重新生成 kubelet.config重新生成 kubelet 配置文件对比 kubeadm-flags.env 事故背景 因为一些情况,需要 reboot 服务器,结果 reboot 机器后,kubeadm init 节点…...

Pytorch构建vgg16模型
VGG-16 1. 导入工具包 import torch.optim as optim import torch import torch.nn as nn import torch.utils.data import torchvision.transforms as transforms import torchvision.datasets as datasets from torch.utils.data import DataLoader import torch.optim.lr_…...
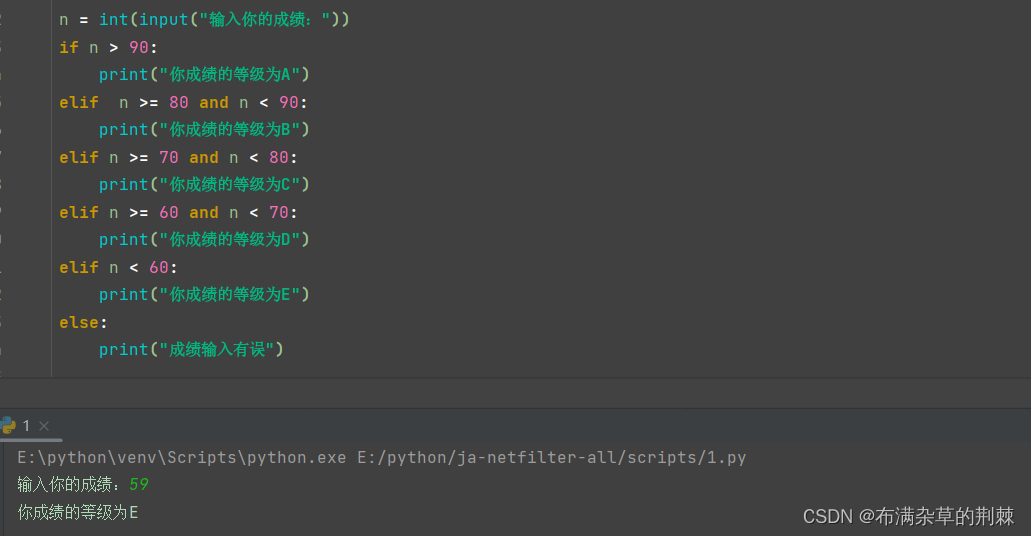
分支结构相关
1.if 语句 结构: if 条件语句: 代码块 小练习: 使用random.randint()函数随机生成一个1~100之间的整数,判断是否是偶数 import random n random.randint(1,100) print(n) if n % 2 0:print(str(n) "是偶数") 2.else语…...

flutter开发实战-RichText富文本居中对齐
flutter开发实战-RichText富文本居中对齐 在开发过程中,经常会使用到RichText,当使用RichText时候,不同文本字体大小默认没有居中对齐。这里记录一下设置过程。 一、使用RichText 我这里使用RichText设置不同字体大小的文本 Container(de…...
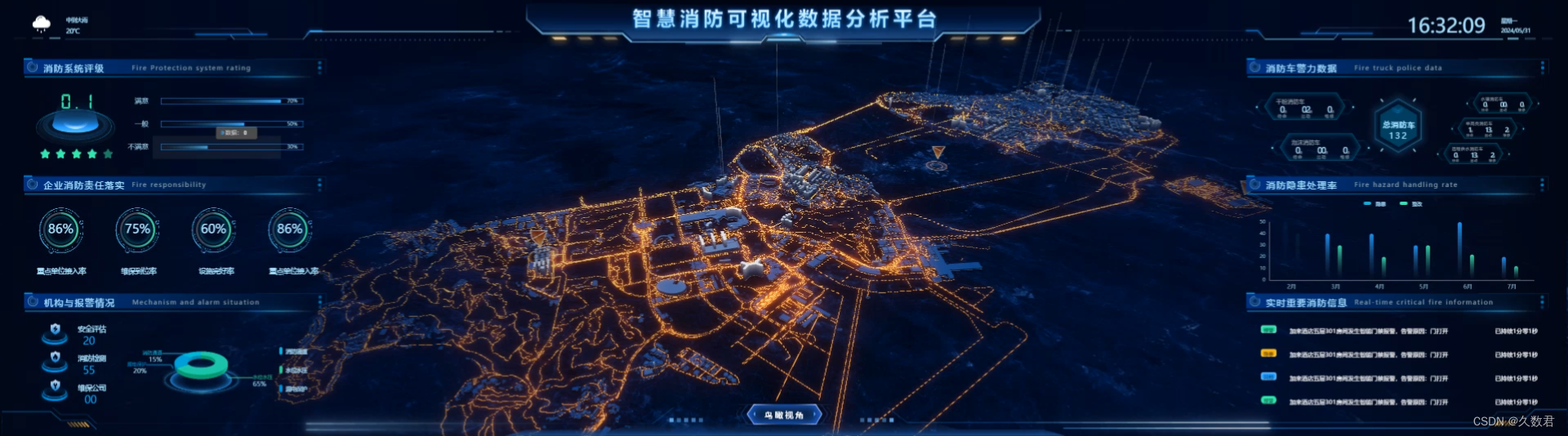
智慧消防新篇章:可视化数据分析平台引领未来
一、什么是智慧消防可视化数据分析平台? 智慧消防可视化数据分析平台,运用大数据、云计算、物联网等先进技术,将消防信息以直观、易懂的图形化方式展示出来。它不仅能够实时监控消防设备的运行状态,还能对火灾风险进行预测和评估…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

HTML前端开发:JavaScript 获取元素方法详解
作为前端开发者,高效获取 DOM 元素是必备技能。以下是 JS 中核心的获取元素方法,分为两大系列: 一、getElementBy... 系列 传统方法,直接通过 DOM 接口访问,返回动态集合(元素变化会实时更新)。…...

es6+和css3新增的特性有哪些
一:ECMAScript 新特性(ES6) ES6 (2015) - 革命性更新 1,记住的方法,从一个方法里面用到了哪些技术 1,let /const块级作用域声明2,**默认参数**:函数参数可以设置默认值。3&#x…...
与文本切分器(Splitter)详解《二》)
LangChain 中的文档加载器(Loader)与文本切分器(Splitter)详解《二》
🧠 LangChain 中 TextSplitter 的使用详解:从基础到进阶(附代码) 一、前言 在处理大规模文本数据时,特别是在构建知识库或进行大模型训练与推理时,文本切分(Text Splitting) 是一个…...