爬虫经典案例之爬取豆瓣电影Top250(方法二)
在上一篇文章的基础上,改进了代码质量,增加了多个正则表达式匹配,但同事也增加了程序执行的耗时。
from bs4 import BeautifulSoup
import requests
import time
import re
from random import randint
import pandas as pdurl_list = ['https://movie.douban.com/top250']
base_url = 'https://movie.douban.com/top250?start={start}'
for start in range(25, 251, 25):url_list.append(base_url.format(start=start))headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'}
movie_info = []def parse_info(info):# 尝试第一个正则表达式pattern1 = re.compile(r"导演: (.*?)\s*/?\s*主演: (.*?)\s*(\d{4})\s*/\s*(.*?)\s*/\s*(.*)")match1 = re.search(pattern1, info)if match1:director = match1.group(1).strip()actors = match1.group(2).strip()year = match1.group(3).strip()countries = match1.group(4).strip().split(' ')genres = match1.group(5).strip().split(' ')return director, actors, year, countries, genres# 尝试第二个正则表达式pattern2 = re.compile(r"导演: (.*?)\s*/?\s*(\d{4})\s*/\s*(.*?)\s*/\s*(.*)")match2 = re.search(pattern2, info)if match2:director = match2.group(1).strip()actors = ""year = match2.group(2).strip()countries = match2.group(3).strip().split(' ')genres = match2.group(4).strip().split(' ')return director, actors, year, countries, genres# 尝试第三个正则表达式pattern3 = re.compile(r"导演: (.*?)\s*(\d{4})\s*/\s*(.*?)\s*/\s*(.*)")match3 = re.search(pattern3, info)if match3:director = match3.group(1).strip()actors = ""year = match3.group(2).strip()countries = match3.group(3).strip().split(' ')genres = match3.group(4).strip().split(' ')return director, actors, year, countries, genres# 尝试第四个正则表达式 (处理有多个年份的情况)pattern4 = re.compile(r"导演: (.*?)\s*主演: (.*?)\s*(.*?)\s*/\s*(.*?)\s*/\s*(.*)")match4 = re.search(pattern4, info)if match4:director = match4.group(1).strip()actors = match4.group(2).strip()year = match4.group(3).strip()countries = match4.group(4).strip().split(' ')genres = match4.group(5).strip().split(' ')return director, actors, year, countries, genres# 如果没有匹配,返回空值return "", "", "", [], []for url in url_list:time.sleep(randint(1, 3))response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')movie_items = soup.find_all('div', class_='item')for movie in movie_items:# 获取排名rank = movie.find('em').text.strip()# 获取电影标题title = movie.find('span', class_='title').text.strip()# 获取电影导演、演员、年份、上映地区等信息info = movie.find('div', class_='bd').find('p').text.strip()# 解析 info 字符串director, actors, year, countries, genres = parse_info(info)# 打印未匹配到的 infoif director == "" and actors == "" and year == "":print(f"未匹配到的info: {info}")# 获取评分信息rating_num = movie.find('span', class_='rating_num').text.strip()# 获取评价人数信息rate_people_num = movie.find('div', class_='star').find_all('span')[3].text.strip()# 将信息进行汇总mock_data = {'排名': rank,'电影名称': title,'导演': director,'演员': actors,'上映年份': year,'上映地区': countries,'电影类型': genres,'评分': rating_num,'投票人数': rate_people_num}movie_info.append(mock_data)df = pd.DataFrame(movie_info,columns=['排名', '电影名称', '导演', '演员', '上映年份', '上映地区', '电影类型', '评分', '投票人数'])
excel_path = 'movie_info.xlsx'
df.to_excel(excel_path, index=False)相关文章:
)
爬虫经典案例之爬取豆瓣电影Top250(方法二)
在上一篇文章的基础上,改进了代码质量,增加了多个正则表达式匹配,但同事也增加了程序执行的耗时。 from bs4 import BeautifulSoup import requests import time import re from random import randint import pandas as pdurl_list [https…...

如何优化React应用的性能?
优化React应用的性能是一个多方面的过程,涉及到代码的编写、组件的设计、资源的管理等多个层面。以下是一些常见的性能优化策略: 避免不必要的渲染: 使用React.memo、useMemo和useCallback来避免组件或其子组件不必要的重新渲染。 代码分割: 使用React.…...

css文字镂空加描边
css文字镂空加描边 <!DOCTYPE html> <html><head><meta charset"utf-8"><title>文字镂空</title><style>/* 公用样式 */html,body{width: 100%;height: 100%;position: relative;}/* html{overflow-y: scroll;} */*{margi…...

python数据分析与可视化
Python 在数据分析和可视化方面有着广泛的应用,并且拥有众多强大的库和工具来支持这些任务。以下是一些常用的 Python 库和它们的主要用途: 数据分析 Pandas: Pandas 是 Python 中用于数据处理和分析的主要库。 它提供了数据框(DataFrame)和序列(Series)两种数据结构…...

webkit 的介绍
WebKit 是一个开源的网页浏览器引擎,它是 Safari 浏览器和许多其他应用程序的基础。WebKit 最初由苹果公司开发,并在2005年作为开源项目发布。WebKit 的核心组件包括 WebCore 和 JavaScriptCore。以下是 WebKit 的详细介绍: ### WebKit 的主…...
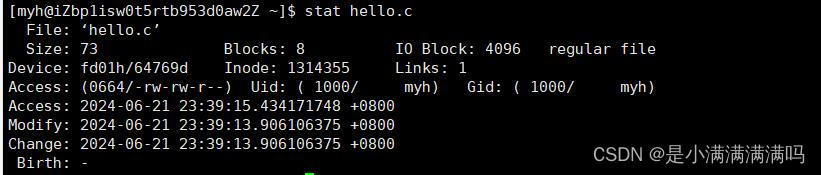
make与makefile
目录 一、make的默认目标文件与自动推导 二、不能连续make的原因 执行原理 touch .PHONY伪目标 make指令不回显 makefile多文件管理 简写依赖方法 三、回车与换行 四、缓冲区 一、make的默认目标文件与自动推导 假设这是一个makefile文件,make的时候默认生…...

深度神经网络一
文章目录 深度神经网络 (DNN)1. 概述2. 基本概念3. 网络结构 深度神经网络的层次结构详细讲解1. 输入层(Input Layer)2. 隐藏层(Hidden Layers)3. 输出层(Output Layer)整体流程深度神经网络的优点深度神经…...

Pnpm:包管理的新星,如何颠覆 Npm 和 Yarn
在探索现代 JavaScript 生态系统时,我们常常会遇到新兴技术的快速迭代和改进。其中,包管理工具的发展尤为重要,因为它们直接影响开发效率和项目性能。最近,pnpm 作为一种新的包管理工具引起了广泛关注。它不仅挑战了传统工具如 np…...
:i.MX linux开发之Yocto)
汽车IVI中控开发入门及进阶(三十二):i.MX linux开发之Yocto
前言: 对于NXP的i.mx,如果基于linux开发,需要熟悉以下文档: IMX_YOCTO_PROJECT_USERS_GUIDE.pdf IMX_LINUX_USERS_GUIDE.pdf IMX_GRAPHICS_USERS_GUIDE.pdf 如果基于android开发,需要熟悉一下文档: Android_Auto_Quick_Start_Guide.pdf ANDROID_USERS_GUIDE.pdf …...

tessy 编译报错:单元测试时,普通桩函数内容相关异常场景
目录 1,失败现象 2,原因分析 1,失败现象 1,在 step 桩函数正常的情况下报错。 2,测试代码执行的数据流 和 step 桩函数内容不一致。 2,原因分析 桩函数分为 test object, test case, test step 三种类别。…...

计算机专业是否仍是“万金油”
作为一名即将参加高考的学生,我站在人生的分岔路口上,面临着选择大学专业的重大抉择。在这个关键节点,计算机相关专业是否仍是炙手可热的选择? 首先,从行业的角度来看,计算机相关专业确实在近年来持续火…...
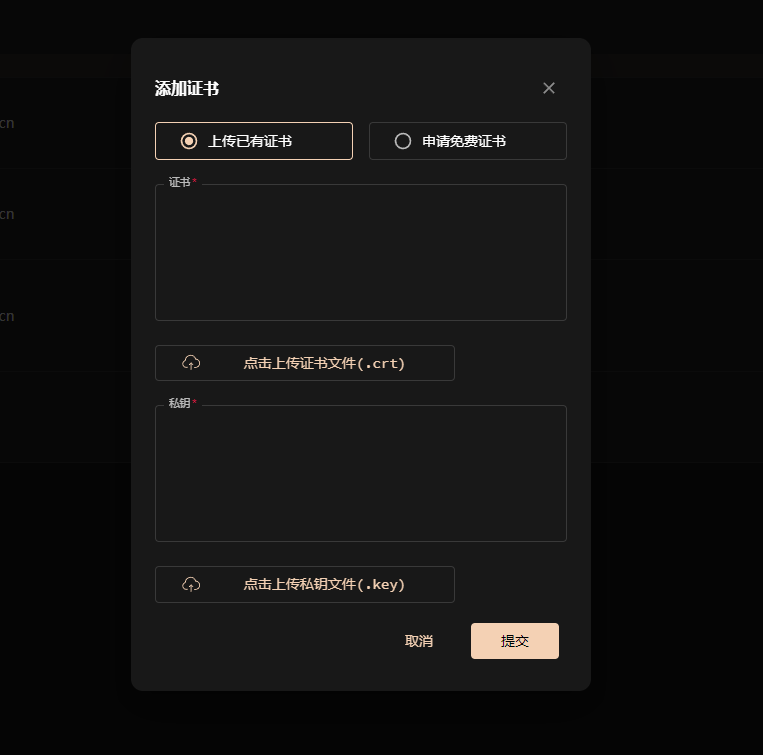
雷池社区版自动SSL
正常安装雷池,并配置站点,暂时不配置ssl 不使用雷池自带的证书申请。 安装(acme.sh),使用域名验证方式生成证书 先安装git yum install git 或者 apt-get install git 安装完成后使用 git clone https://gitee.com/n…...

怎样减少徐州服务器租用的成本?
服务器租用的出现,十分便于网络行业的发展,但是随着服务器租用的广泛应用,整体还是有着一定的成本的吗,不同的服务器类型在价格方面也是不同的,那么企业在选择服务器租用后,怎样才能减少服务器租用的成本呢…...
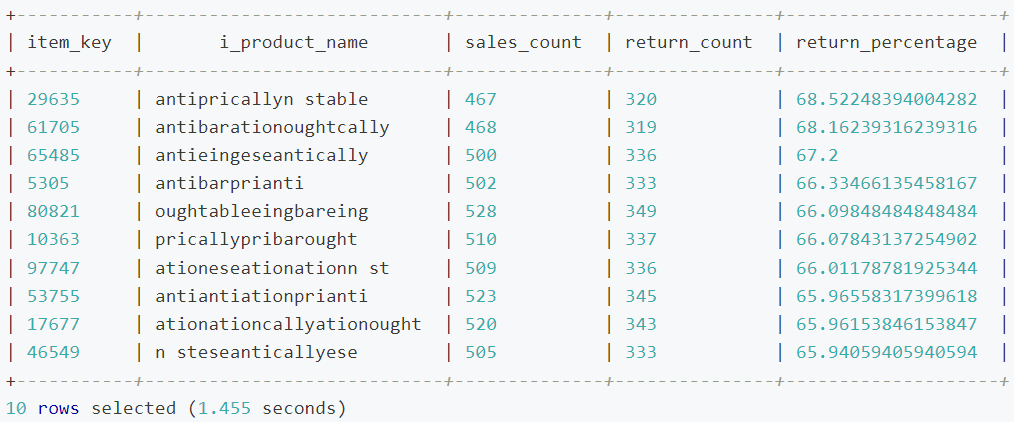
【性能优化】表分桶实践最佳案例
分桶背景 随着企业的数据不断增长,数据的分布和访问模式变得越来越复杂。我们前面介绍了如何通过对表进行分区来提高查询效率,但对于某些特定的查询模式,特别是需要频繁地进行数据联接查或取样的场景,仍然可能面临性能瓶颈。此外…...

数据仓库的挑战
建设数据仓库是一个复杂且资源密集的过程,需要考虑多个方面。以下是建设数据仓库时常见的挑战及其详细解释: 1. 数据集成 挑战: 数据来源多样:数据来自不同的系统、数据库、文件格式(如CSV、JSON、XML)、…...

基于ResNet-18的简单分类(新手,而且网络效果不咋滴,就是学个流程)
引言 先看问题: 我手边有一数据集,然后我想分分类!~~ 咳咳,最近刚做了一个:训练集有1143张,分为5类,里面图片是打乱的。测试集有248张,想把它分分类看看咋样。 再看一下效果: …...

自动化测试:Autorunner的使用
自动化测试:Autorunner的使用 一、实验目的 1、掌握自动化测试脚本的概念。 2、初步掌握Autorunner的使用 二、Autorunner的简单使用 autoRunner使用方法 新建项目 a) 在项目管理器空白区域,右键鼠标,选择新建项目 b) 输入项目名后,点击[确定]. 在初次打开aut…...
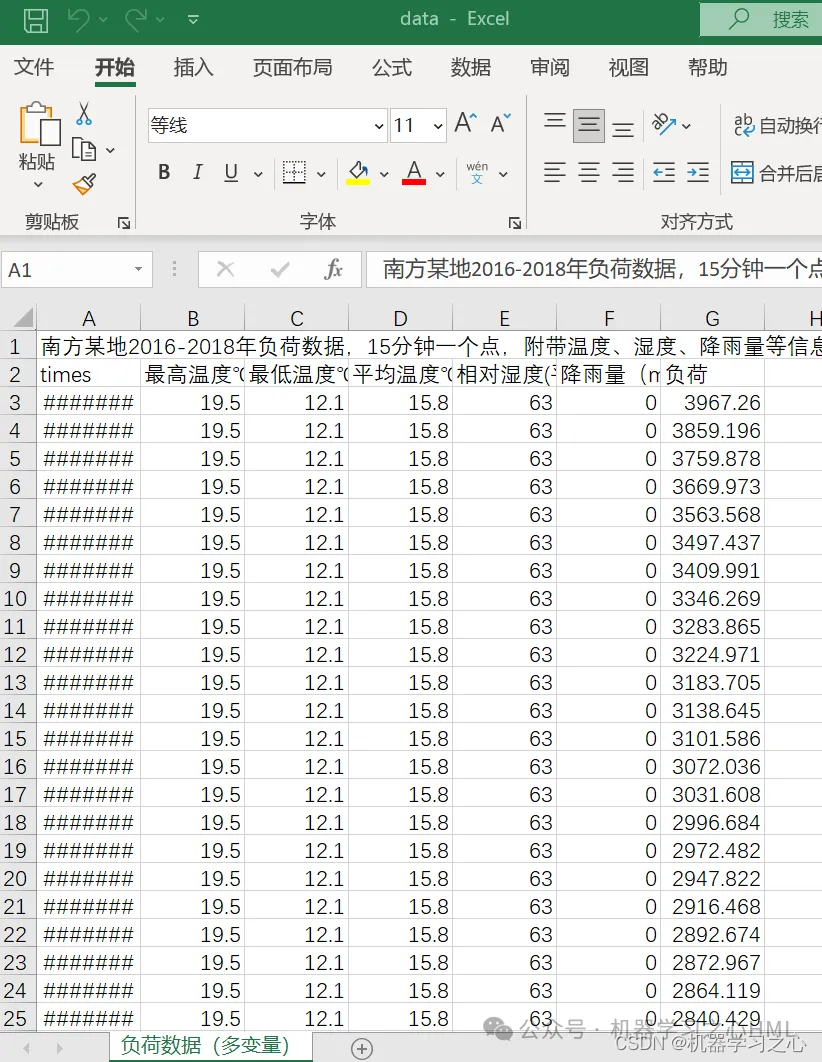
时序预测 | Matlab基于CNN-BiLSTM-Attention多变量时间序列多步预测
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab基于CNN-BiLSTM-Attention多变量时间序列多步预测; 2.多变量时间序列数据集(负荷数据集),采用前96个时刻预测的特征和负荷数据预测未来96个时刻的负荷数据&…...
)
软考 系统架构设计师系列知识点之杂项集萃(42)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(41) 第67题 Windows操作系统在图形界面处理方面采用的核心架构风格是( )风格。Java语言宣传的“一次编写,到处运行”的特性,从架构风格…...

FastBoot刷机获取root权限(Magisk)
1.首先要下载ADB、Fastboot等工具。 1.ADB、Fastboot工具 https://developer.android.com/studio/releases/platform-tools 2.安装FastBoot的USB驱动 https://developer.android.com/studio/run/oem-usb 2.下载对应的镜像 https://developers.google.com/android/images?…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

拉力测试cuda pytorch 把 4070显卡拉满
import torch import timedef stress_test_gpu(matrix_size16384, duration300):"""对GPU进行压力测试,通过持续的矩阵乘法来最大化GPU利用率参数:matrix_size: 矩阵维度大小,增大可提高计算复杂度duration: 测试持续时间(秒&…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...