【性能优化】表分桶实践最佳案例
分桶背景
随着企业的数据不断增长,数据的分布和访问模式变得越来越复杂。我们前面介绍了如何通过对表进行分区来提高查询效率,但对于某些特定的查询模式,特别是需要频繁地进行数据联接查或取样的场景,仍然可能面临性能瓶颈。此外,随着数据的不断积累,可能会出现某些分区数据量过大,导致查询和处理效率受到影响。
为了更细粒度地管理和优化数据存储与访问,数据分桶(Bucketing)技术逐渐受到了关注,即对指定列的哈希值将其分配到固定数量的子集中(桶),保障数据的均匀分布,从而为复杂查询提供了更高效的处理方式。
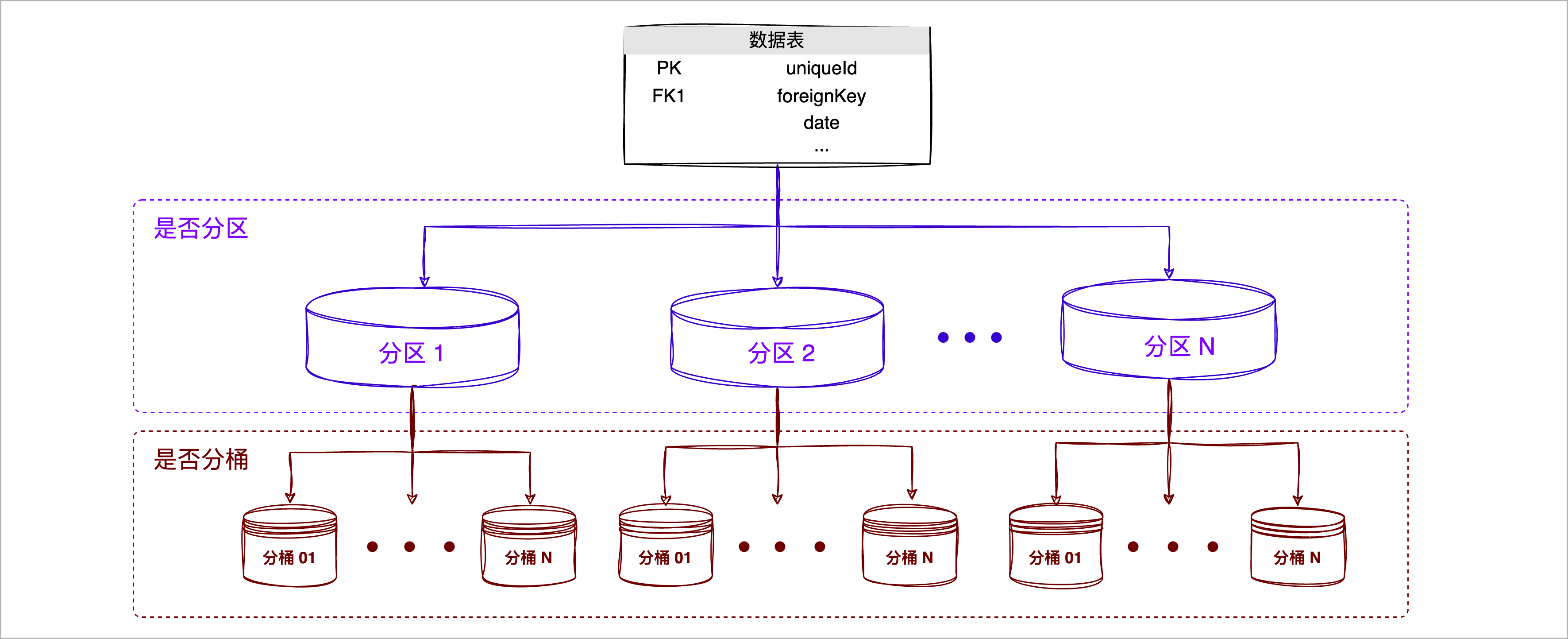
为什么要分桶
数据分桶通过对特定列的值进行哈希处理,帮助您更好地均匀分布数据、优化特定模式的查询,其优势如下:
- 优化特定查询模式: 对于涉及桶列的JOIN和过滤操作,分桶可以大大加速查询,因为它能确保只有相关的桶被访问和处理。例如,基于桶键的 JOIN 操作可以在 map 阶段执行,避免了 shuffle 和 reduce 阶段的开销。
- 此外,当查询的谓词包含分桶键时,可快速定位到具体的分桶,极大减少数据扫描范围,提升查询效率。
- 增加数据访问的预测性: 由于数据是基于哈希值进行分桶的,所以系统可以准确地知道哪些数据位于哪个桶中。这为数据访问提供了更高的预测性,从而进一步提高了查询性能。
何时分桶
数据分桶是一种大数据优化策略,主要目的是提高查询性能,在决定是否对表进行分桶时,需要综合考虑以下几个因素,以确保分桶对系统性能和数据管理带来实际的好处:
- 高频的连接操作: 当两个大表需要经常进行连接操作,并且连接基于某个特定的列,经常因为数据移动而产生大量的 Shuffle 读写,拖慢了查询效率。
- 频繁的聚合操作: 对于需要频繁执行的聚合操作,如果按照聚合的键进行数据分桶,可以大大提高查询性能,因为每个节点可以独立地完成其桶内的聚合操作。
设计表分桶策略
选择合适的分桶键是分桶优化成功的关键。以下是一些选择合适分桶键的指南和考虑因素:
| 步骤 | 说明 |
|---|---|
| 分析查询需求 | ● 常用的 JOIN 列:重点关注经常执行 JOIN 操作的列,基于桶键的 JOIN 可以在 Map 阶段执行,避免了 Shuffle 阶段的开销。 ● 常用的 WHERE 子句列:重点关注经被用作过滤条件的列,将其作为分桶键可避免全表或分区扫描,只需扫描特定桶,从而帮助提高查询效率,并确保数据在桶之间的均匀分布。 |
| 了解数据特征 | ● 分析数据在列上的分布情况,一个理想的分桶键应该有较大的基数和较少的重复值,避免桶中的数据不均衡。 |
| 选择分桶列数量 | ● 多分桶列:适用于处理高任务并行度的查询,假设数据的一个主要特征或多个特征经常被一起查询或用于 JOIN 操作,即使查询条件没有涵盖所有分桶列的等值条件,该查询也可通过扫描关联的分桶,提高任务执行的并行度。 ● 单分桶列:适用于高并发的点查询,使其只需扫描与该键匹配的特定桶,减少不同查询之间的 I/O 干扰,并提高系统的响应时间。 |
| 确认分桶数 | ● 默认情况下,分桶数由 ArgoDB 自动计算,可覆盖大部分业务场景,即 数据磁盘总数 * 5,然后取比起大的相邻质数,例如磁盘数为 12,先将其乘以 5,再取相邻质数,则默认分桶数为 61。 ● 如果表执行了分区操作,推荐单个分区中,分桶的数据规模为 50~100 MB,既可以避免文件过小触发小文件合并,给文件管理带来额外开销,同时也避免了 Block 文件数过多导致查询启动的 task 数过多影响执行和并发效率,需要注意应避免将分桶数设置为 31 及其倍数,减少潜在的哈希冲突。 |
在具体实践中,您也可以使用小规模数据量的表来尝试使用不同的分桶键,比较分桶获得到的查询收益,找出为您提供最佳性能的选择,此外,随着业务数据特性、查询需求的变化,可能还需要定期评估分桶键合理性。
最佳实践
创建分桶表
场景介绍
XYZ 是一家全球知名的电子产品零售商,主营智能手机、耳机、笔记本电脑等电子产品。近期,该企业注意到某些产品的退货率居高不下。高退货不仅影响了公司的利润,还可能导致顾客的不满和对品牌的不信任。为了深入研究这一问题,该企业希望通过分析历史业务数据,识别产品质量问题、优化库存管理,从而能够更加聚焦地改进其产品和服务,在竞争激烈的零售市场中保持领先地位。
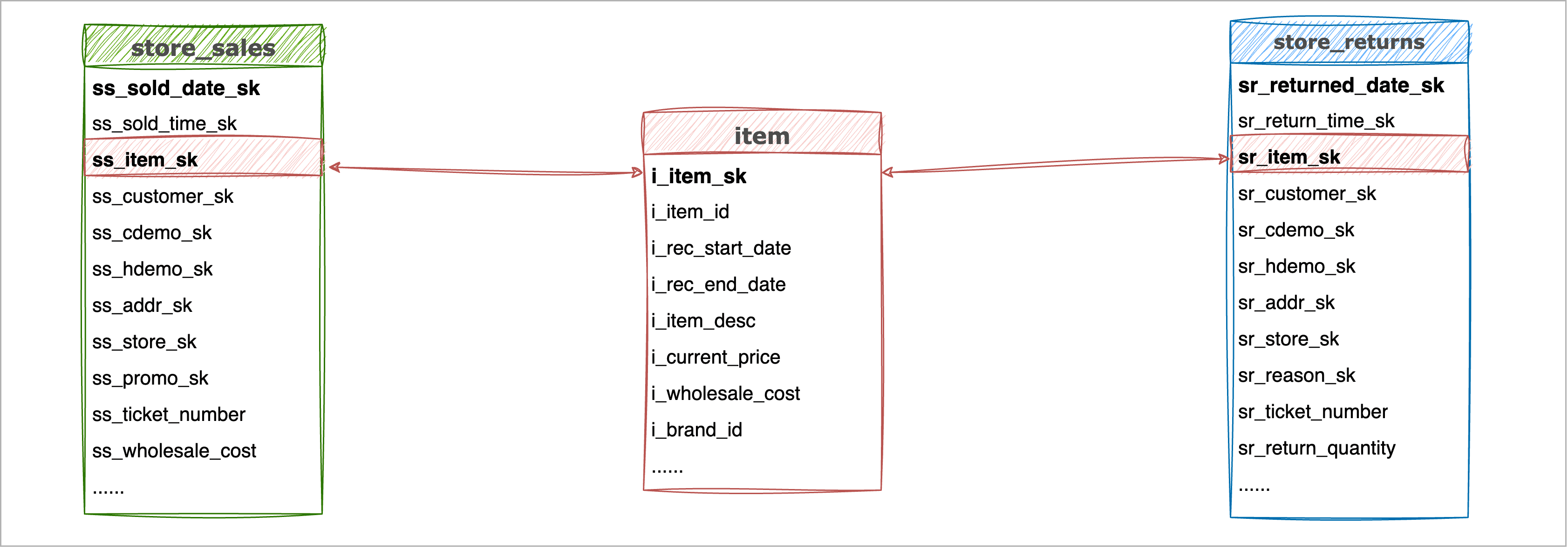
接下来,我们以 TPC-DS 样例数据集为例,演示在搭建退货数据分析的数据仓库过程中,如何通过数据分桶来提升数据查询性能,我们用到的表分别为:
- store_sales*:存储了商品的销售数据,约 2.88 亿*条数据(*38.1 GB)且持续增长中。
- sales_returns*:存储了商品的退货数据,约 2888 万*条数据(*3.2 GB)且持续增长中。
- item*:存储了商品信息,共 20.4 万条数据,该表作为上两个事实表的共同维度表。
简化后的 ER 关系图如下:
操作流程
1. 分析查询需求
本案例中,XYZ 公司的数据分析师希望查询特定日期范围内,找出销售数据良好但退货率较高的商品,希望通过对查询结果的分析,帮助质量团队和市场团队针对性的深入分析具体品类。
即关键的查询列对象为日期*、商品名称、销量和*退货量,从而基本确定查询语句中,要执行条件过滤的列、关联查询的列和执行算术运算的列。
2. 评估数据表规模和预计的查询设计,初步确认分桶键。
本案例中,我们的事实表 store_sales 和 store_returns 的数据规模都非常大,预计需要通过 Join 查询 item 表的方法来分析销售数量和退货数量等信息,所以我们初步选择将 store_sales 表的 ss_item_sk 列作为分桶键,将 store_returns 表的 sr_item_sk 列作为分桶键,即均为单列分桶,此场景下,两个大的事实表选择相同的分桶键有助于更好地提升查询性能。
除此以外,前面提到我们在分析退货数据时还希望能够基于时间范围来查询,例如为后续的环比同比来提供数据支持,验证商品质量改进是否取得预期效果,我们还可以基于时间来执行分区来提升查询效率。
3. 了解分桶键的数据特性。
初步选择分桶键后,我们还需要关注分桶键的数据分布情况,确保具有高度的数据离散性,从而避免数据发生倾斜。例如依次执行下述语句,分别查看 store_sales 表的 ss_item_sk 列和 store_returns 表的 sr_item_sk 列值中 ,排名前 5 个和倒数 5 个的数据占比,从而辅助我们判断数据分布情况。
-- 查看 store_sales 表的 ss_item_sk 列值分布情况
WITH partition_percentages AS (
SELECT ss_item_sk, COUNT(*) * 100.0 / SUM(COUNT(*)) OVER() AS percentage
FROM store_sales
GROUP BY ss_item_sk
)
SELECT ss_item_sk, percentage, 'top' AS distribution_type
FROM partition_percentages
ORDER BY percentage DESC
LIMIT 5
UNION ALL
SELECT ss_item_sk, percentage, 'bottom' AS distribution_type
FROM partition_percentages
ORDER BY percentage ASC
LIMIT 5;
-- 查看 store_returns 表的 sr_item_sk 列值分布情况
WITH partition_percentages AS (
SELECT sr_item_sk, COUNT(*) * 100.0 / SUM(COUNT(*)) OVER() AS percentage
FROM store_returns
GROUP BY sr_item_sk
)
SELECT sr_item_sk, percentage, 'top' AS distribution_type
FROM partition_percentages
ORDER BY percentage DESC
LIMIT 5
UNION ALL
SELECT sr_item_sk, percentage, 'bottom' AS distribution_type
FROM partition_percentages
ORDER BY percentage ASC
LIMIT 5;
输出结果分别如下,可以看到数据相对均衡,满足分桶键的值具有高度离散性的要求。


除上述方法外,您还可以通过数据采样、标准差、直方图等方法来辅助判断数据分布的均衡情况。
4. 默认情况下,分桶数由 ArgoDB 自动计算(可覆盖大多数业务场景),如需手动指定,可参考前面介绍的分桶数选择介绍,结合场景、数据规模与集群状态来综合考虑,来设定分桶数量。
让我们来带入本次案例来计算分桶数,由于我们还希望对日期进行过滤查询,为更快地过滤数据,我们还为 store_sales 表设计了分区,具体数据如下:
| 表名称 | 原始 TXT 格式表大小 | 入库后预估大小(平均压缩比 3:1) | 分区数 | 分桶容量计算基数 |
|---|---|---|---|---|
| store_sales | 38.1 GB | 12.7 GB | 20(按季度分区) | 38.1 ÷ 3 ÷ 20 = 0.635 GB |
| store_returns | 3.2 GB | 1.07 GB | 无 | 3.2 ÷ 3 = 1.07 GB |
通过上述计算,我们得到了分桶容量的计算基数,将其值转换为 GB 单位,然后分别除以 50 (每分桶推荐数据规模),store_sales 和 store_returns 的分桶数分别为 13 和 22*(四舍五入),再取其相邻的质数,则分别是 *13 和 23**。
前面我们计算得出这两个表的初始分桶数较为接近,考虑后续可能会利用到 Bucket Join 方法进一步提升关联查询性能,此处我们将分桶数设置相同,若设置为 23 可能导致 store_sales 表存储的 Block 文件数过小,所以此处我们将两个表的分桶数均暂定为 13,表数据的分区分桶规划如下:
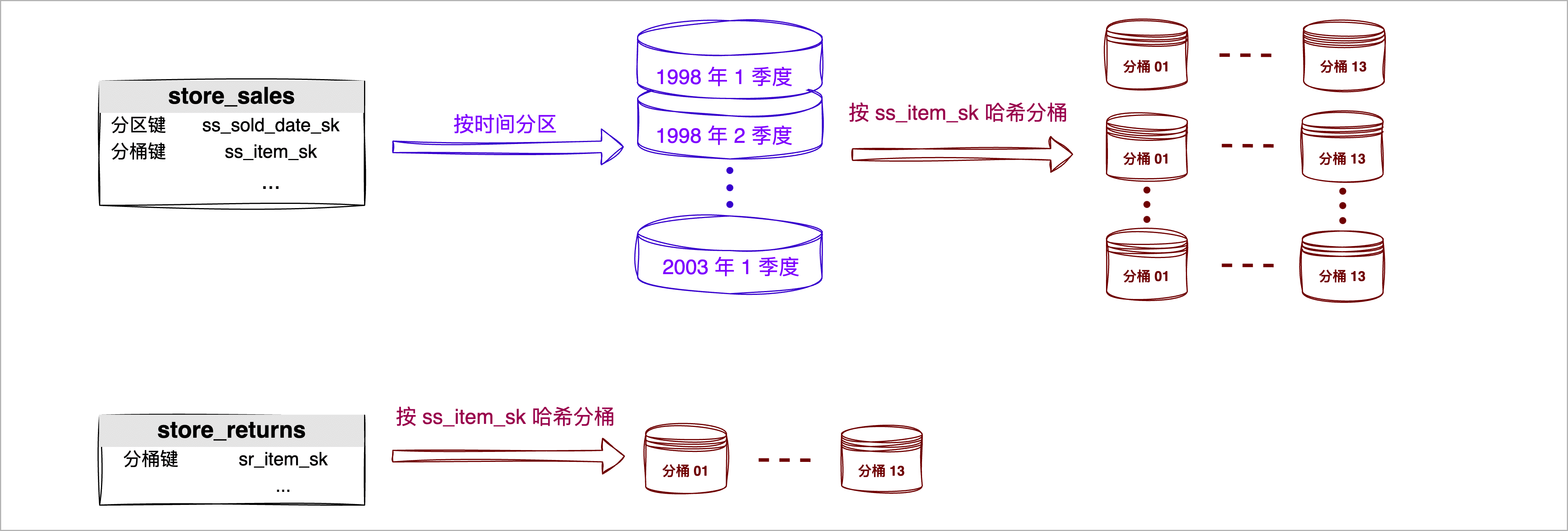
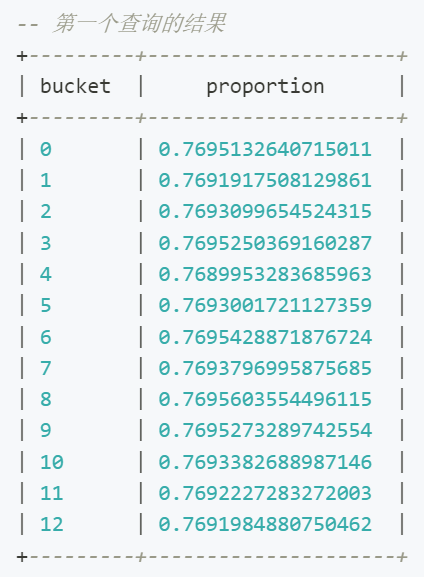
5. 为保障数据的均匀分布,依次执行下述命令,基于我们选择的分桶键来执行 HASH 算法,预估数据分布情况,数字 13 为分桶数。
-- 查看 store_sales 表的数据分桶预估情况
SELECT
hash(ss_item_sk) % 13 AS bucket,
COUNT(*) / (SELECT CAST(COUNT(*) AS FLOAT) FROM store_returns) AS proportion
FROM
store_sales
GROUP BY
hash(ss_item_sk) % 13;
-- 查看 store_returns 表的数据分桶预估情况
SELECT
hash(sr_item_sk) % 13 AS bucket,
COUNT(*) / (SELECT CAST(COUNT(*) AS FLOAT) FROM store_returns) AS proportion
FROM
store_returns
GROUP BY
hash(sr_item_sk) % 13;
查询结果如下,符合我们对数据均衡分布的预期:

6. 通过 Beeline 登录至 ArgoDB 数据库,执行下述命令创建分桶表。
i. 创建 store_sales 表,为其划分数据分区并指定分桶数量。
如您的查询场景经常涉及排序、聚合或范围查询,推荐在建表时将其相关字段作为桶内排序键,如设置多个排序键,建议优先级为分区键 > 分桶键 > 其他字段,具体语法介绍,见《开发者指南》。
CREATE TABLE store_sales(
ss_sold_time_sk INTEGER ,
ss_item_sk INTEGER NOT NULL,
ss_customer_sk INTEGER ,
ss_cdemo_sk INTEGER ,
ss_hdemo_sk INTEGER ,
ss_addr_sk INTEGER ,
ss_store_sk INTEGER ,
ss_promo_sk INTEGER ,
ss_ticket_number BIGINT NOT NULL,
ss_quantity INTEGER ,
ss_wholesale_cost FLOAT ,
ss_list_price FLOAT ,
ss_sales_price FLOAT ,
ss_ext_discount_amt FLOAT ,
ss_ext_sales_price FLOAT ,
ss_ext_wholesale_cost FLOAT ,
ss_ext_list_price FLOAT ,
ss_ext_tax FLOAT ,
ss_coupon_amt FLOAT ,
ss_net_paid FLOAT ,
ss_net_paid_inc_tax FLOAT ,
ss_net_profit FLOAT )
PARTITIONED BY RANGE(ss_sold_date_sk INTEGER) (
PARTITION p1998q1 VALUES LESS THAN (2450905),
PARTITION p1998q2 VALUES LESS THAN (2450996),
PARTITION p1998q3 VALUES LESS THAN (2451088),
PARTITION p1998q4 VALUES LESS THAN (2451180),
PARTITION p1999q1 VALUES LESS THAN (2451270),
PARTITION p1999q2 VALUES LESS THAN (2451361),
PARTITION p1999q3 VALUES LESS THAN (2451453),
PARTITION p1999q4 VALUES LESS THAN (2451545),
PARTITION p2000q1 VALUES LESS THAN (2451636),
PARTITION p2000q2 VALUES LESS THAN (2451727),
PARTITION p2000q3 VALUES LESS THAN (2451819),
PARTITION p2000q4 VALUES LESS THAN (2451911),
PARTITION p2001q1 VALUES LESS THAN (2452001),
PARTITION p2001q2 VALUES LESS THAN (2452092),
PARTITION p2001q3 VALUES LESS THAN (2452184),
PARTITION p2001q4 VALUES LESS THAN (2452276),
PARTITION p2002q1 VALUES LESS THAN (2452366),
PARTITION p2002q2 VALUES LESS THAN (2452457),
PARTITION p2002q3 VALUES LESS THAN (2452549),
PARTITION p2002q4 VALUES LESS THAN (2452641),
PARTITION pmax VALUES LESS THAN (MAXVALUE))
CLUSTERED BY (ss_item_sk) INTO 13 BUCKETS
STORED AS HOLODESK
WITH PERFORMANCE;
ii. 创建 store_returns 表,为其划分数据分区并指定分桶数量。
CREATE TABLE store_returns (
sr_returned_date_sk INTEGER,
sr_return_time_sk INTEGER,
sr_item_sk INTEGER NOT NULL,
sr_customer_sk INTEGER,
sr_cdemo_sk INTEGER,
sr_hdemo_sk INTEGER,
sr_addr_sk INTEGER,
sr_store_sk INTEGER,
sr_reason_sk INTEGER,
sr_ticket_number BIGINT NOT NULL,
sr_return_quantity INTEGER,
sr_return_amt FLOAT,
sr_return_tax FLOAT,
sr_return_amt_inc_tax FLOAT,
sr_fee FLOAT,
sr_return_ship_cost FLOAT,
sr_refunded_cash FLOAT,
sr_reversed_charge FLOAT,
sr_store_credit FLOAT,
sr_net_loss FLOAT
)
CLUSTERED BY (sr_item_sk) INTO 13 BUCKETS
STORED AS HOLODESK WITH PERFORMANCE;
7. 在业务低峰期依次执行下述命令,将 TXT 格式的外表数据写入至刚刚创建的分桶表中。
-- 开启数据动态写入,即写入时基于分区键的值自动将数据放置到对应分区中
set hive.exec.dynamic.partition=true;
set stargate.dynamic.partition.enabled=true;
-- 将数据写入 store_sales 表,该表已创建分区和分桶
INSERT INTO store_sales
PARTITION (ss_sold_date_sk)
SELECT
ss_sold_time_sk,
ss_item_sk,
ss_customer_sk,
ss_cdemo_sk,
ss_hdemo_sk,
ss_addr_sk,
ss_store_sk,
ss_promo_sk,
ss_ticket_number,
ss_quantity,
ss_wholesale_cost,
ss_list_price,
ss_sales_price,
ss_ext_discount_amt,
ss_ext_sales_price,
ss_ext_wholesale_cost,
ss_ext_list_price,
ss_ext_tax,
ss_coupon_amt,
ss_net_paid,
ss_net_paid_inc_tax,
ss_net_profit,
ss_sold_date_sk
FROM tpcds_text_100.store_sales;
-- 将数据写入 store_returns 表
INSERT INTO TABLE store_returns
SELECT
sr_returned_date_sk,
sr_return_time_sk,
sr_item_sk,
sr_customer_sk,
sr_cdemo_sk,
sr_hdemo_sk,
sr_addr_sk,
sr_store_sk,
sr_reason_sk,
sr_ticket_number,
sr_return_quantity,
sr_return_amt,
sr_return_tax,
sr_return_amt_inc_tax,
sr_fee,
sr_return_ship_cost,
sr_refunded_cash,
sr_reversed_charge,
sr_store_credit,sr_net_loss
FROM tpcds_text_100.store_returns;
:
提示:数据写入的执行时间由集群负载、数据规模等因素决定,您可以登录 DBA Service,在查询页面中查看任务执行进度。
8. (可选)数据导入执行完成后,通过 SELECT COUNT(*) 来确认这两个表的条目数是否与原表一致。
查询性能对比
为更好地展示分桶前后的性能对比,本案例使用的机器资源设定了一些的限制,因此查询响应时间仅供演示参考,真实业务场景中分区前的查询效率和速度会更高。
数据分桶前
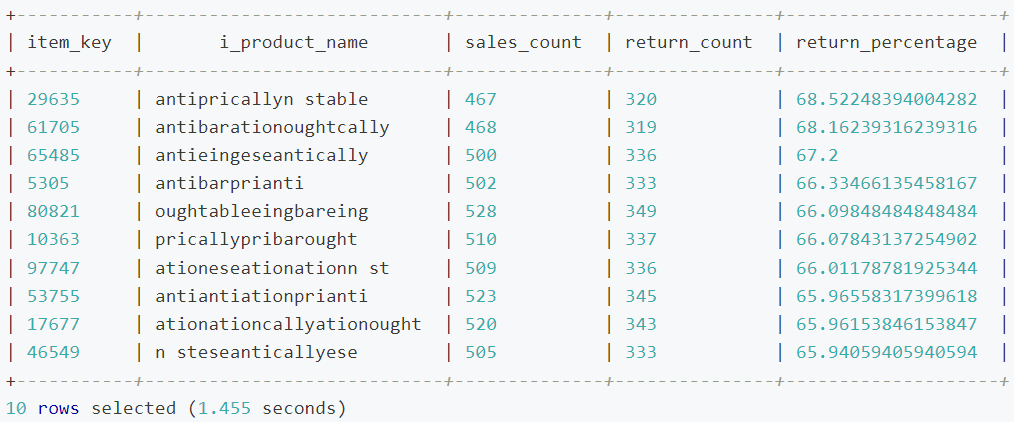
接下来,我们回到 XYZ 公司的业务需求,来设计一个 SQL 查询语句。由于高退货率可能意味着商品的质量、描述、定价或其他相关因素存在问题,XYZ 公司的数据分析团队希望找出销量超过 100 的商品的退货率,列出退货率最高的10个商品的具体名称,为售后团队的决策提供数据支持。
提示:为了确保数据的准确性和可靠性,该查询只考虑那些销售数量超过 100 的商品,避免因销售数量较少的商品带来的极端退货率数据干扰分析结果。
在查询设计中,我们首先使用 CTE(公共表表达式)分别预先聚合商品的销量和退货量,然后在主查询中联接这两个数据集以计算退货率,即退货数除以销售数的百分比,同时该查询还与 item 表联接,以便获取每个商品的具体名称,最后,将查询结果按退货率降序排列,并只返回退货率最高的前 10 个商品,具体 SQL 语句如下:
WITH SalesData AS (
SELECT
ss.ss_item_sk AS item_key,
COUNT(*) AS sales_count
FROM
store_sales ss
GROUP BY
ss.ss_item_sk
),
ReturnsData AS (
SELECT
sr.sr_item_sk AS item_key,
COUNT(*) AS return_count
FROM
store_returns sr
GROUP BY
sr.sr_item_sk
)
SELECT
s.item_key,
i.i_product_name,
s.sales_count,
r.return_count,
(CAST(r.return_count AS FLOAT) / s.sales_count) * 100 AS return_percentage
FROM
SalesData s
JOIN
ReturnsData r
ON s.item_key = r.item_key
JOIN
item i
ON s.item_key = i.i_item_sk -- 连接 item 表以获取产品名称
WHERE
s.sales_count > 100
ORDER BY
return_percentage DESC
LIMIT 10;
在 Beeline 中执行上述语句,等待查询执行完成,命令行将返回查询结果和耗时,具体如下:
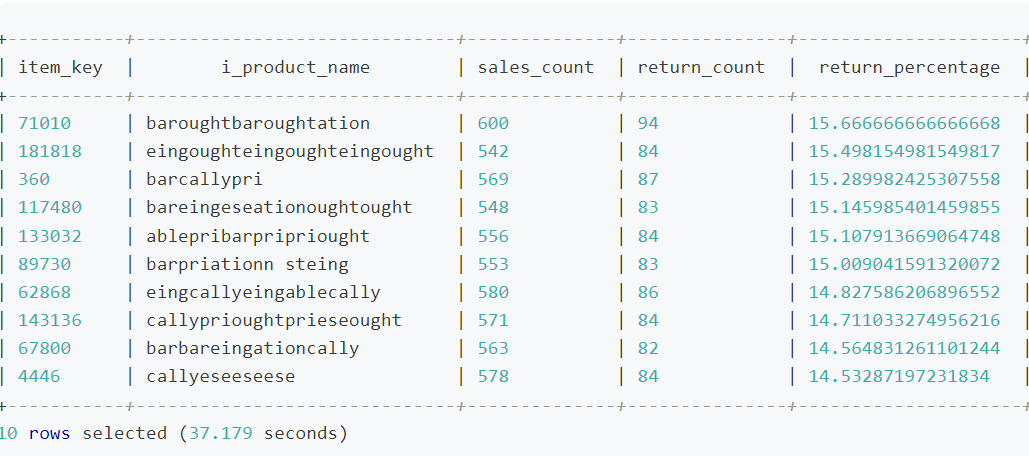
本次查询耗时约为 37.18 秒,为了进一步了解查询任务在任务执行的各阶段的耗时情况,我们登录到 DBA Service 平台,在查询*页面找到并单击刚刚执行完成的查询作业,然后单击*调度阶段页签。
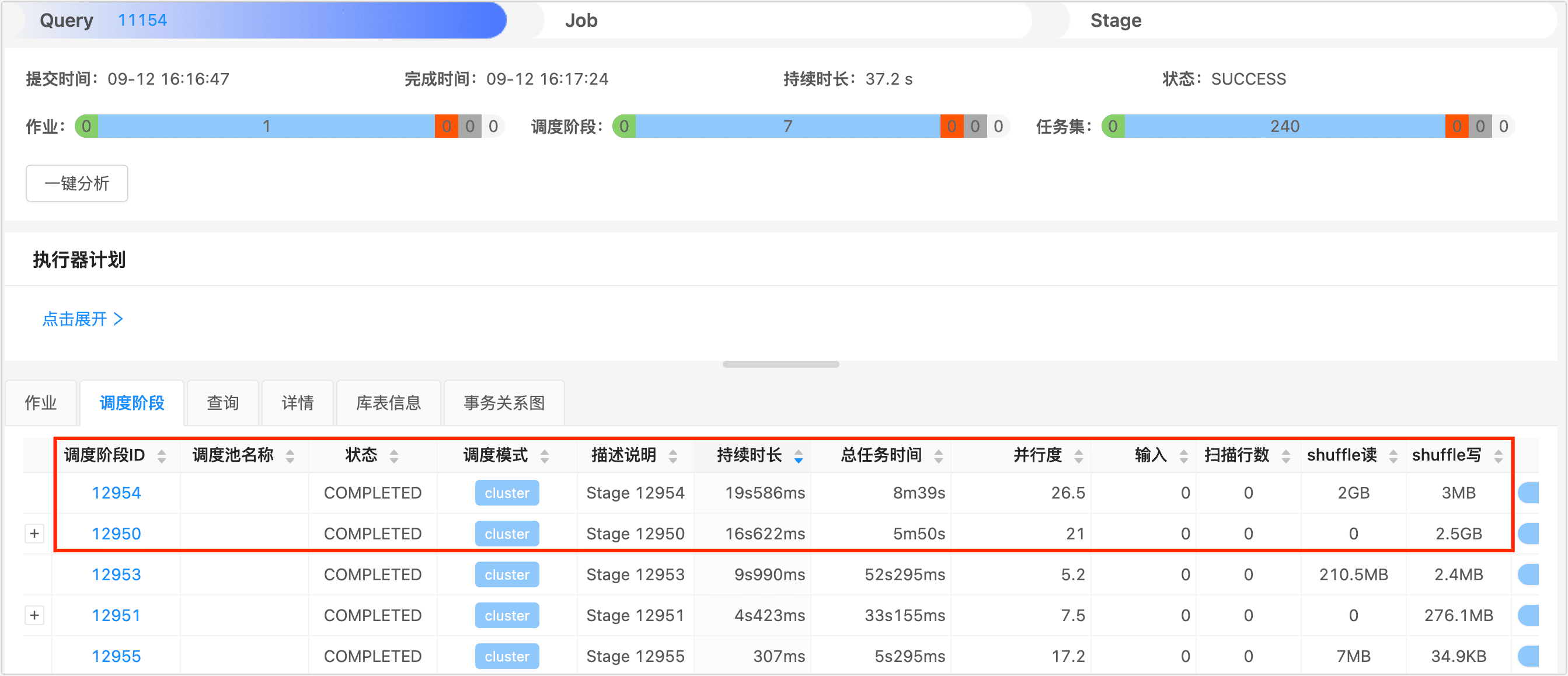
可以看到该查询任务被分为多个调度阶段,时间主要花费在了 ID 为 12954 和 12950 这 2 个调度阶段,在执行 Join 时,系统需要确保具有相同连接键的记录位于同一节点上,此时产生了大量的 Shuffle 读和写,如下图所示,Shuffle 读的数据量为 2 GB*,Shuffle 写的数据量为 2.5 GB,拖慢了整体的查询速度。
数据分桶后
而在对表执行数据分桶后,我们使用执行相同的查询,获得的查询结果和耗时如下:
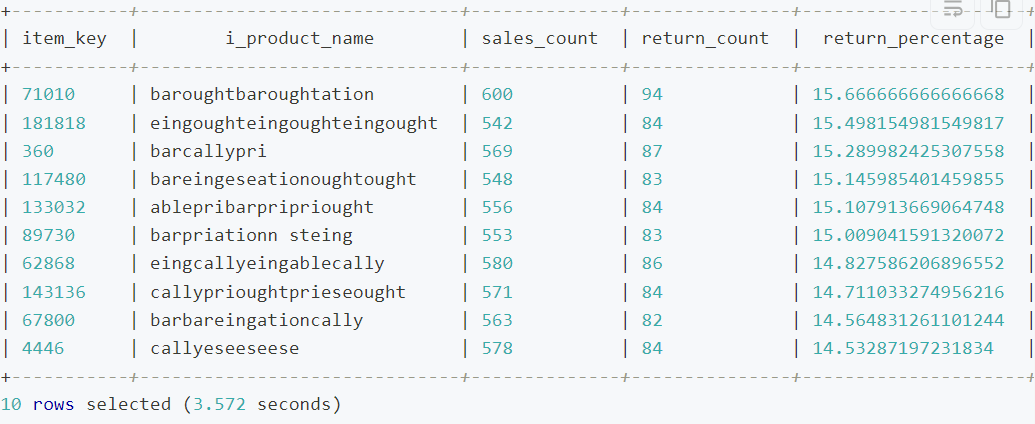
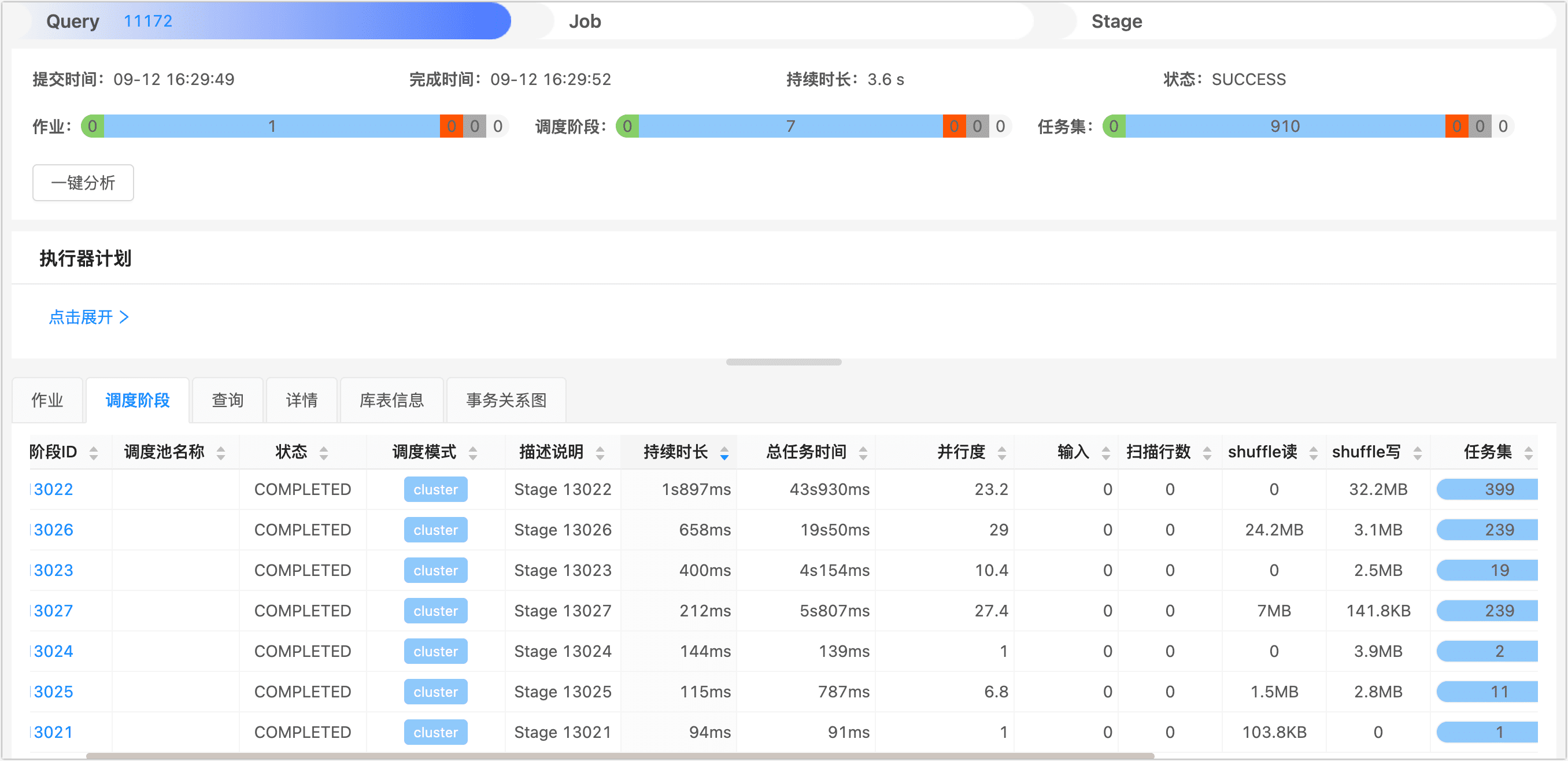
本次查询仅耗时约 3.57 秒,相较于之前查询速度提升了 10 倍以上,同样登录至 DBA Service 平台,在查询页面找到并单击刚刚执行完成的查询作业,由于 store_sales 和 store_returns 采用相同的分桶键,JOIN 操作可以在各个节点上高效地局部进行,而无需跨节点传输数据。如下图所示,本次查询只产生了极少的 Shuffle 读写,极大地提升了数据查询效率,此外,相较于分桶前,还提升了任务的并行度,进一步发挥了分布式集群并发执行任务的优势。
除此以外,前面我们提到,为了满足按时间范围查询退货数据的需求,我们还对 store_sales 表进行了分区,当查询的过滤条件包含分区键时,我们还可以获得进一步的查询性能提升,从而让数据处理的范围进一步缩小,例如我们在前面 SQL 查询语句的基础上限定查询 2000 年的数据,具体如下:
WITH SalesData AS (
SELECT
ss.ss_item_sk AS item_key,
COUNT(*) AS sales_count
FROM
store_sales ss
WHERE
ss.ss_sold_date_sk BETWEEN 2451545 AND 2451910 -- 限定查询时间范围
GROUP BY
ss.ss_item_sk
),
ReturnsData AS (
SELECT
sr.sr_item_sk AS item_key,
COUNT(*) AS return_count
FROM
store_returns sr
GROUP BY
sr.sr_item_sk
)
SELECT
s.item_key,
i.i_product_name, -- 产品名称
s.sales_count,
r.return_count,
(CAST(r.return_count AS FLOAT) / s.sales_count) * 100 AS return_percentage
FROM
SalesData s
JOIN
ReturnsData r
ON s.item_key = r.item_key
JOIN
item i
ON s.item_key = i.i_item_sk -- 连接 item 表以获取产品名称
WHERE
s.sales_count > 100 -- Sales threshold
ORDER BY
return_percentage DESC
LIMIT 10;
等待查询执行完成,由于处理的数据范围可以通过分区快速定位,本次查询可以处理更少的数据,最终查询耗时约为 1.45 秒。
通过比较分桶前后的查询性能,我们可以看到:
- 降低 Shuffle:本案例中,两个大的事实表采用相同的键分桶,连接和聚合操作可以在每个节点上独立执行,避免了数据在节点间的 shuffle,大大提高效率。
- 提升任务并行度:选择合适的分桶可以确保数据在多个桶中均匀地分布,提升任务并行度。
此外,我们还结合了分区表的优势(减少数据扫描等特性)进一步优化了查询性能,充分利用它们的优势并实现最佳的性能。
相关文章:
【性能优化】表分桶实践最佳案例
分桶背景 随着企业的数据不断增长,数据的分布和访问模式变得越来越复杂。我们前面介绍了如何通过对表进行分区来提高查询效率,但对于某些特定的查询模式,特别是需要频繁地进行数据联接查或取样的场景,仍然可能面临性能瓶颈。此外…...

数据仓库的挑战
建设数据仓库是一个复杂且资源密集的过程,需要考虑多个方面。以下是建设数据仓库时常见的挑战及其详细解释: 1. 数据集成 挑战: 数据来源多样:数据来自不同的系统、数据库、文件格式(如CSV、JSON、XML)、…...

基于ResNet-18的简单分类(新手,而且网络效果不咋滴,就是学个流程)
引言 先看问题: 我手边有一数据集,然后我想分分类!~~ 咳咳,最近刚做了一个:训练集有1143张,分为5类,里面图片是打乱的。测试集有248张,想把它分分类看看咋样。 再看一下效果: …...

自动化测试:Autorunner的使用
自动化测试:Autorunner的使用 一、实验目的 1、掌握自动化测试脚本的概念。 2、初步掌握Autorunner的使用 二、Autorunner的简单使用 autoRunner使用方法 新建项目 a) 在项目管理器空白区域,右键鼠标,选择新建项目 b) 输入项目名后,点击[确定]. 在初次打开aut…...
时序预测 | Matlab基于CNN-BiLSTM-Attention多变量时间序列多步预测
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab基于CNN-BiLSTM-Attention多变量时间序列多步预测; 2.多变量时间序列数据集(负荷数据集),采用前96个时刻预测的特征和负荷数据预测未来96个时刻的负荷数据&…...
)
软考 系统架构设计师系列知识点之杂项集萃(42)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(41) 第67题 Windows操作系统在图形界面处理方面采用的核心架构风格是( )风格。Java语言宣传的“一次编写,到处运行”的特性,从架构风格…...

FastBoot刷机获取root权限(Magisk)
1.首先要下载ADB、Fastboot等工具。 1.ADB、Fastboot工具 https://developer.android.com/studio/releases/platform-tools 2.安装FastBoot的USB驱动 https://developer.android.com/studio/run/oem-usb 2.下载对应的镜像 https://developers.google.com/android/images?…...
:SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking)
信息检索(43):SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking
SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking 摘要1 引言2 相关工作3 方法3.1 SparTerm3.2 SPLADE:稀疏词汇和扩展模型 4 实验5 结论 发布时间(2021) 标题:稀疏词汇 扩展模型 摘要 稀疏的优点…...

DockerHub 镜像加速
Docker Hub 作为目前全球最大的容器镜像仓库,为开发者提供了丰富的资源。Docker Hub 是目前最大的容器镜像社区,DokcerHub的不能使用,导致在docker下pull镜像无法下载,安装kubernetes镜像也受到影响,下面请看解决方式。 1.加速原理 Docker下载加速的原理…...

Oracle 迁移 Mysql
-- Oracle->MySQL -- 使用时改一下where条件的owner和table_name -- 字段数据类型映射时会将Oracle中的浮点NUMBER转换为decimal(65,8)定点数 -- 可以识别主键约束、非空约束,但无法识别外键约束、唯一约束、自定义check -- 对于Oracle字符串长度为4000的&#x…...

vue3父子组件通信
一,父传子——defineProps 方法: 在父组件的模板中使用子组件标签,并且给标签自定义属性和属性名,即通过v-bind绑定数值,而后传给子组件;子组件则通过defineProps接收使用。 父组件: <tem…...

CSS中使用应用在伪元素中的计数器属性counter-increment
在CSS中,counter-increment 是一个用于递增计数器值的属性。它通常与 counter-reset 和 content 属性一起使用,以在文档中的特定位置(如列表项、标题等)插入自动生成的数字或符号。 counter-increment 基本用法: 使…...

【SkiaSharp绘图08】SKPaint方法:自动换行、是否乱码、字符偏移、边界、截距、文本轮廓、测量文本
文章目录 SKPaint方法BreakText 计算指定宽度内可绘制的字符个数ContainsGlyphs字体是否包含文本字符(是否会乱码)GetGlyphOffsets 字符偏移量GetGlyphPositions 偏移坐标GetGlyphWidths 每个字符的宽度与边界GetHorizontalTextIntercepts 轮廓截距GetPositionedTextIntercepts…...

深入理解Servlet Filter及其限流实践
引言 在Java Servlet技术中,Filter是一个拦截器,它允许开发者在请求到达目标资源之前或响应发送给客户端之后,对请求或响应进行拦截和处理。这种机制为实现诸如身份验证、日志记录、请求修改等功能提供了极大的灵活性。 Filter基础 Filter…...

使用cv2对视频指定区域进行去噪
视频去噪其实和图象一样,只是需要现将视频截成图片,在对图片进行去噪,将去噪的图片在合成视频就行。可以利用cv2.imread()、imwrite()等轻松实现。 去噪步骤 1、视频逐帧读成图片 2、图片指定区域批量去噪 2、去噪后的图片写入视频 1、视频逐…...

AI在创造还是毁掉音乐?
AI对音乐产业的影响是复杂而多维的,既有创造性的贡献也存在潜在的挑战。我们可以从以下几个角度来分析这个问题: ### 创造性贡献 1. **音乐创作**:AI可以帮助音乐家创作新的旋律和和声,甚至生成完整的音乐作品。例如,…...

【2023年全国青少年信息素养大赛智能算法挑战赛复赛真题卷】
目录 2023全国青少年信息素养大赛智能算法挑战赛初中组复赛真题 2023全国⻘少年信息素养⼤赛智能算法挑战复赛⼩学组真题 2023全国青少年信息素养大赛智能算法挑战赛初中组复赛真题 1. 修复机器人的对话词库错误 【题目描述】 基于人工智能技术的智能陪伴机器人的语言词库被…...

Android系统揭秘(一)-Activity启动流程(上)
public ActivityResult execStartActivity( Context who, IBinder contextThread, IBinder token, Activity target, Intent intent, int requestCode, Bundle options) { IApplicationThread whoThread (IApplicationThread) contextThread; … try { … int result …...

使用Java实现哈夫曼编码
前言 哈夫曼编码是一种经典的无损数据压缩算法,它通过赋予出现频率较高的字符较短的编码,出现频率较低的字符较长的编码,从而实现压缩效果。这篇博客将详细讲解如何使用Java实现哈夫曼编码,包括哈夫曼编码的原理、具体实现步骤以…...
IDEA、PyCharm等基于IntelliJ平台的IDE汉化方式
PyCharm 或者 IDEA 等编辑器是比较常用的,默认是英文界面,有些同学用着不方便,想要汉化版本的,但官方没有这个设置项,不过可以通过插件的方式进行设置。 方式1:插件安装 1、打开设置 File->Settings&a…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...