第一章---Pytorch快速入门---第三节---pytorch中的数据操作和预处理
目录
1.高维数组
1.1 回归数据准备
1.2 分类数据准备
2. 图像数据
1.torchvision.datasets模块导入数据并预处理
2.从文件夹中导入数据并进行预处理
pytorch中torch.utils.data模块包含着一些常用的数据预处理的操作,主要用于数据的读取、切分、准备等。
| 常用数据操作类 | 功能 |
| torch.utils.data.TensorDataset() | 将数据处理为张量 |
| torch.utils.data.ConcatDataset() | 连接多个数据集 |
| torch.utils.data.Subset() | 根据索引获取数据集的子集 |
| torch.utils.data.DataLoader() | 数据加载器 |
| torch.utils.data.random_split() | 随机将数据集拆分为给定长度的非重叠数据集 |
使用这些类能够对高维数组、图像等各种类型的数据进行预处理,以便深度学习模型的使用,针对文本数据的处理可以使用torchtext库进行相关的数据准备操作。
1.高维数组
在很多情况下,我们需要从文本(如CSV文件)中读取高维数组数据,这类数据的特征是每个样本都有很多个预测变量(特征)和一个被预测变量(目标标签),特征通常是数值变量或者离散变量,被预测变量如果是连续的数值,则对应着回归问题,如果是离散变量,则对应分类问题。
1.1 回归数据准备
import torch
import numpy as np
import torch.utils.data as Data
from sklearn.datasets import load_boston,load_iris
#读取波士顿回归数据
boston_x,boston_y=load_boston(return_X_y=True)
print(boston_x.dtype)
print(boston_y.dtype)
"""
上面程序输出的数据集的特征和被预测变量都是numpy的64位浮点型数据。
而使用Pytorch时需要的数据是torch的32位浮点数的张量
需要将boston_x,boston_y转换为32位浮点型张量
"""
#将训练集转换为张量
train_x=torch.from_numpy(boston_x.astype(np.float32))
train_y=torch.from_numpy(boston_y.astype(np.float32))
"""
上面一段程序先将numpy数据转化为32位浮点型
然后使用torch.from_numpy()函数转化为张量
在训练全连接神经网络的时候,通常一次使用一个
batch的数据进行权重更新,torch.utils.data.DataLoader()
函数可以将输入的数据集(包含数据特征张量和被预测变量张量)
获得一个加载器,每次迭代可使用一个batch的数据
"""
#将训练集转化为张量之后,使用TensorDataset将train_x,train_y整合
train_data=Data.TensorDataset(train_x,train_y)
#定义一个数据加载器,将训练数据集进行批量处理
train_load=Data.DataLoader(dataset=train_data,#使用的数据集batch_size=64,#批处理的样本大小shuffle=True,#每次迭代前打乱数据num_workers=0#使用一个线程
)
print("======================")
#检查训练数据集的一个batch的样本的维度是否正确
for step,(b_x,b_y) in enumerate(train_load):if step>0:break
print("b_x.shape",b_x.shape)
print("b_y.shape",b_y.shape)
print("b_x.dtype",b_x.dtype)
print("b_y.dtype",b_y.dtype)1.2 分类数据准备
分类数据与回归数据的不同之处在于,分类数据的被预测变量是离散型变量,所以在pytorch中默认的预测标签是64位有符号整型
import torch
import numpy as np
import torch.utils.data as Data
from sklearn.datasets import load_iris
iris_x,iris_y=load_iris(return_X_y=True)
print(iris_x.dtype)
print(iris_y.dtype)
"""
从上面程序输出可知,该数据集的特征数据(x)为64位浮点型,
标签y为32位整型。在pytorch构建网络中,x默认的数据格式是
torch.float32,所以转化为张量时,数据的特征要转化为32位浮点型
数据的类别标签y要转化为64位有符号整型,下面将x,y都转化为张量
"""
train_x=torch.from_numpy(iris_x.astype(np.float32))
train_y=torch.from_numpy(iris_y.astype(np.int64))
# print(train_x.dtype)
# print(train_y.dtype)
#将训练集转化为张量之后,使用TensorDataset将x,y整理到一块
train_data=Data.TensorDataset(train_x,train_y)
train_loader=Data.DataLoader(dataset=train_data,batch_size=10,#批处理样本大小shuffle=True,#每次迭代前打乱num_workers=0#使用两个线程
)
#检查一个训练集的batch样本维度是否正确
for step,(b_x,b_y) in enumerate(train_loader):if step>0:break
print("b_x.shape",b_x.shape)
print("b_y.shape",b_y.shape)
print("b_x.dtype",b_x.dtype)
print("b_y.dtype",b_y.dtype)2. 图像数据
torchvision中的datasets模块包含多种常用的分类数据集下载及导入函数
| 数据集对应的类 | 描述 |
| datasets.MNIST() | 手写字体数据集 |
| datasets.FashionMNIST() | 衣服、鞋子、包等10类数据集 |
| dataets.KMNIST() | 一些文字的灰度数据 |
| datasets.CocoCaptions() | 用于图像标注的MS coco数据 |
| datasets.CocoDetection() | 用于检测的MS COCO数据 |
| datasets.LSUN() | 10个场景和20个目标分类数据集 |
| datasets.CIFAR10() | CIFAR10类数据集 |
| datasets.CIFAR100() | CIFAR100类数据集 |
| datasets.STL10() | 包含10类的分类数据集和大量的未标注数据 |
| datasets.ImageFolder() | 定义一个数据加载器从文件夹中读取数据 |
torchvision中的transforms模块可以针对每张图像进行预处理操作。
| 数据集对应的类 | 描述 |
| transforms.Compose() | 将多个transform组合起来使用 |
| transforms.Scale() | 按照指定图像尺寸对图像进行调整 |
| transforms.CenterCrop() | 将图像进行中心切割,得到给定的大小 |
| transforms.RandomCrop() | 切割中心点的位置随机选取 |
| transforms.RandomHorizontalFlip() | 图像随机水平翻转 |
| transforms.RandomSizedCrop() | 将给定的图像随机切割,然后再变换为给定的大小 |
| transforms.Pad() | 将图像所有边用给定的pad value 填充 |
| transforms.ToTensor() | 把一个取值范围是[0-255]的PIL图像或形状为[H,W,C]的数组,转换成形状为[C,H,W],取值范围是[0,1.0]的张量 |
| transforms.Normalize() | 将给定的图像进行规范化操作 |
| transforms.Lambda(lam) | 使用lam作为转化器,可自定义图像操作方式 |
1.torchvision.datasets模块导入数据并预处理
FashionMNIST数据集包含一个60000张28*28的灰度图片作为训练集,以及10000张28*28的灰度图片作测试集。数据共10类,分别是鞋子、连衣裙等服饰类的图像。
import torch
import torch.utils.data as Data
from torchvision.datasets import FashionMNIST
import torchvision.transforms as transforms
from torchvision.datasets import ImageFoldertrain_data=FashionMNIST(root="./data/FashionMNIST",#数据的路径train=True,#只使用训练数据集transform=transforms.ToTensor(),download=False#数据集已经离线下载,无需再次下载
)
train_loader=Data.DataLoader(dataset=train_data,batch_size=64,shuffle=True,num_workers=2
)
"""
上面的程序主要完成了以下功能:
(1)通过FashionMNIST()函数来导入数据。在该函数中root参数用于指定需要导
入数据的所在路径(如果指定路径下已经有该数据集,需要指定对应的参数download= False,
如果指定路径下没有该数据集,需要指定对应的参数download=True,将会自动下载数据)。
参数train的取值为Ture或者False,表示导入的数据是训练集(60000张图片)或测试集(10000张图片)。
参数transform用于指定数据集的变换,transform = transforms.ToTensor()表示将数据中的
像素值转换到0 ~1之间,并且将图像数据从形状[H,W ,C]转换成形状为[C,H,W]
(2)在数据导入后需要利用数据加载器DataLoader()将整个数据集切分为多个batch,
用于网络优化时利用梯度下降算法进行求解。在函数中dataset参数用于指定使用的数据集;
batch__size参数指定每个batch使用的样本数量;shuffle = True表示从数据集中获取每个
批量图片时需先打乱数据;num_workers参数用于指定导人数据使用的进程数量(和并行处理相似)。
经过处理后该训练数据集包含938个batch
"""
#对训练集进行处理后,可以使用相同的方法对测试集进行处理
test_data=FashionMNIST(root="./data/FashionMNIST",train=False,download=False
)
#为数据添加一个通道维度,并且取值范围缩放到0-1之间
test_data_x=test_data.data.type(torch.FloatTensor) /255.0
test_data_x=torch.unsqueeze(test_data_x,dim=1)
test_data_y=test_data.targets
"""
上面的程序使用FashionMNIST()函数导入数据
使用train = False参数指定导入测试集
并将数据集中的像素值除以255.0,使像素值转化到0 ~1之间
再使用函数torch.unsqueeze()为数据添加一个通道即可得到测试数据集。
在test_data中使用test_data.data获取图像数据,
使用test_data.targets获取每个图像所对应的标签。"""2.从文件夹中导入数据并进行预处理
在torchvision的datasets模块中包含有ImageFolder()函数,它可以读取:在相同的文件路径下,每类数据都单独存放在不同的文件夹下。
#对训练集进行预处理
train_data_transforms=transforms.Compose(transforms.RandomResizedCrop(224),#随机长宽比裁剪224*224transforms.RandomHorizontalFlip(),#依据概率p=0.5水平翻转transforms.ToTensor(),#转化为将张量并归一化至[0-1]transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
)
#读取图像
train_data_dir="data/imageData"
train_data=ImageFolder(train_data_dir,transform=train_data_transforms)
train_data_loader=Data.DataLoader(train_data,batch_size=4,shuffle=True,num_workers=2
)相关文章:

第一章---Pytorch快速入门---第三节---pytorch中的数据操作和预处理
目录 1.高维数组 1.1 回归数据准备 1.2 分类数据准备 2. 图像数据 1.torchvision.datasets模块导入数据并预处理 2.从文件夹中导入数据并进行预处理 pytorch中torch.utils.data模块包含着一些常用的数据预处理的操作,主要用于数据的读取、切分、准备等。 常用…...

【代码随想录训练营】【Day38】第九章|动态规划|理论基础|509. 斐波那契数|70. 爬楼梯|746. 使用最小花费爬楼梯
理论基础 动态规划与贪心的区别并不是学习动态规划所必须了解的,所以并不重要。 想要了解动态规划算法题的特点,可以直接做下面三道入门简单题练练手感,找找感觉,很快就能体会到动态规划的解题思想。 总结成一句话就是…...
| 机考必刷)
华为OD机试题 - 快递货车(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:快递货车题目输入输出示例一输入输出Code解题思路版权说明华为O…...

前端——7.图像标签和路径
这篇文章,我们来讲解一下图像标签 目录 1.图像标签 1.1介绍 1.2实际展示 1.3图像标签的属性 1.3.1 alt属性 1.3.2 title属性 1.3.3 width / height 属性 1.3.4 border属性 1.4注意事项 2.文件夹 2.1目录文件夹和根目录 2.2 VSCode打开目录文件夹 3.路…...

java -- stream流
写在前面: stream流一直在使用,但是感觉还不够精通,现在深入研究一下。 stream这个章节中,会用到 函数式接口–lambda表达式–方法引用的相关知识 介绍 是jdk8引进的新特性。 stream流是类似一条流水线一样的操作,每次对数据进…...

【Spring6】| Bean的四种获取方式(实例化)
目录 一:Bean的实例化方式 1. 通过构造方法实例化 2. 通过简单工厂模式实例化 3. 通过factory-bean实例化 4. 通过FactoryBean接口实例化 5. BeanFactory和FactoryBean的区别(面试题) 6. 使用FactoryBean注入自定义Date 一:…...
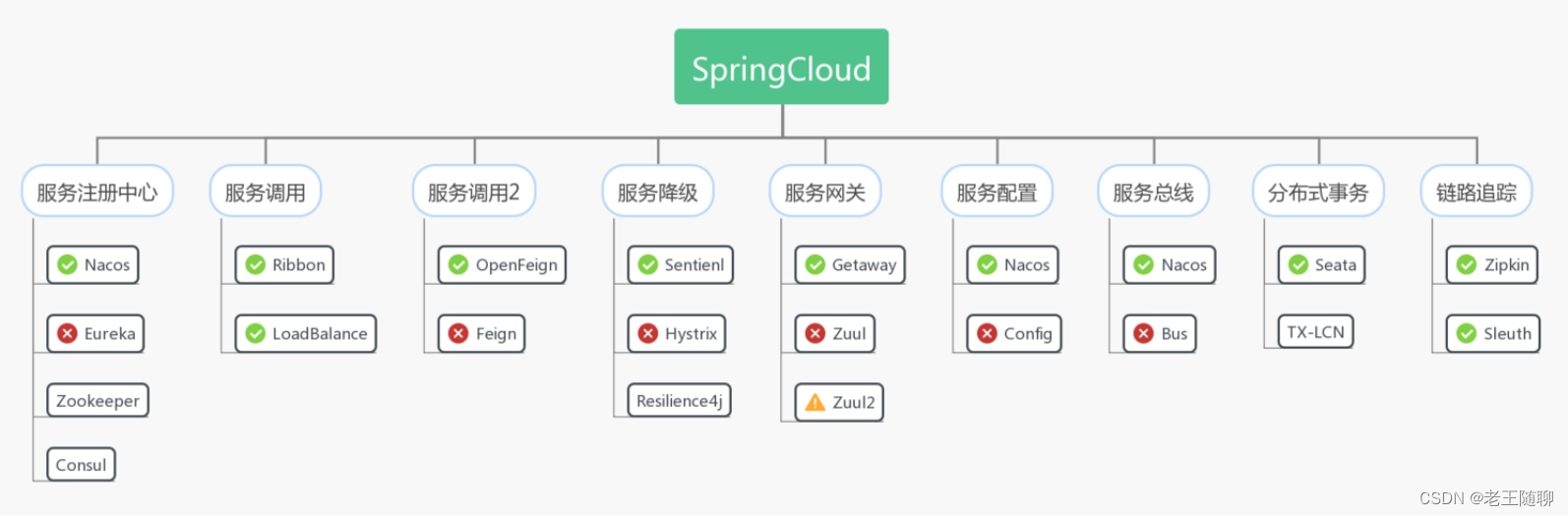
01: 新手学SpringCloud前需知道的5点
目录 第一点: 什么是微服务架构 第二点:为什么需要学习Spring Cloud 第三点: Spring Cloud 是什么 第四点: SpringCloud的优缺点 1、SpringCloud优点 2、SpringCloud缺点 第五点: SpringCloud由什么组成 1&…...

ubuntu apt安装arm交叉编译工具
查找查找编译目标为32位的gcc-arm交叉编译器命令apt-cache search arm|awk index($1,"arm")!0 {print}|grep gcc-arm\|g-arm #或者 apt-cache search arm|awk index($1,"arm")!0 {print}|grep -E gcc-arm|g\\-arm输出如下g-arm-linux-gnueabihf - GNU C co…...

阿里云一面经历
文章目录 ES 查询方式都有哪些?1 基于词项的查询term & terms 查询Fuzzy QueryWildcard Query2 基于全文的查询Match QueryQuery String QueryMatch Phrase Query3 复合查询Bool QueryElasticsearch 删除原理ES 大文章怎么存arthas 常用命令arthas 排查问题过程arthas 工作…...

Java Stream中 用List集合统计 求和 最大值 最小值 平均值
对集合数据的统计,是开发中常用的功能,掌握好Java Stream提供的方法,避免自己写代码统计,可以提高工作效率。 先造点数据: pigs.add(new Pig(1, "猪爸爸", 31, "M", false)); pigs.add(new Pig(…...
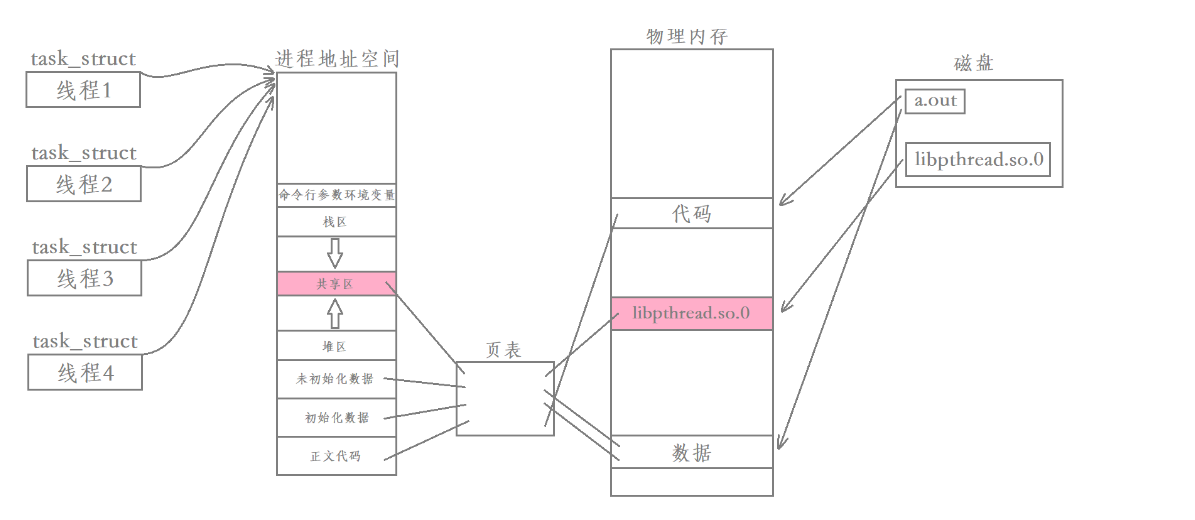
【Linux】多线程---线程控制
进程在前面已经讲过了,所以这次我们来讨论一下多线程。前言:线程的背景进程是Linux中资源及事物管理的基本单位,是系统进行资源分配和调度的一个独立单位。但是实现进程间通信需要借助操作系统中专门的通信机制,但是只这些机制将占…...
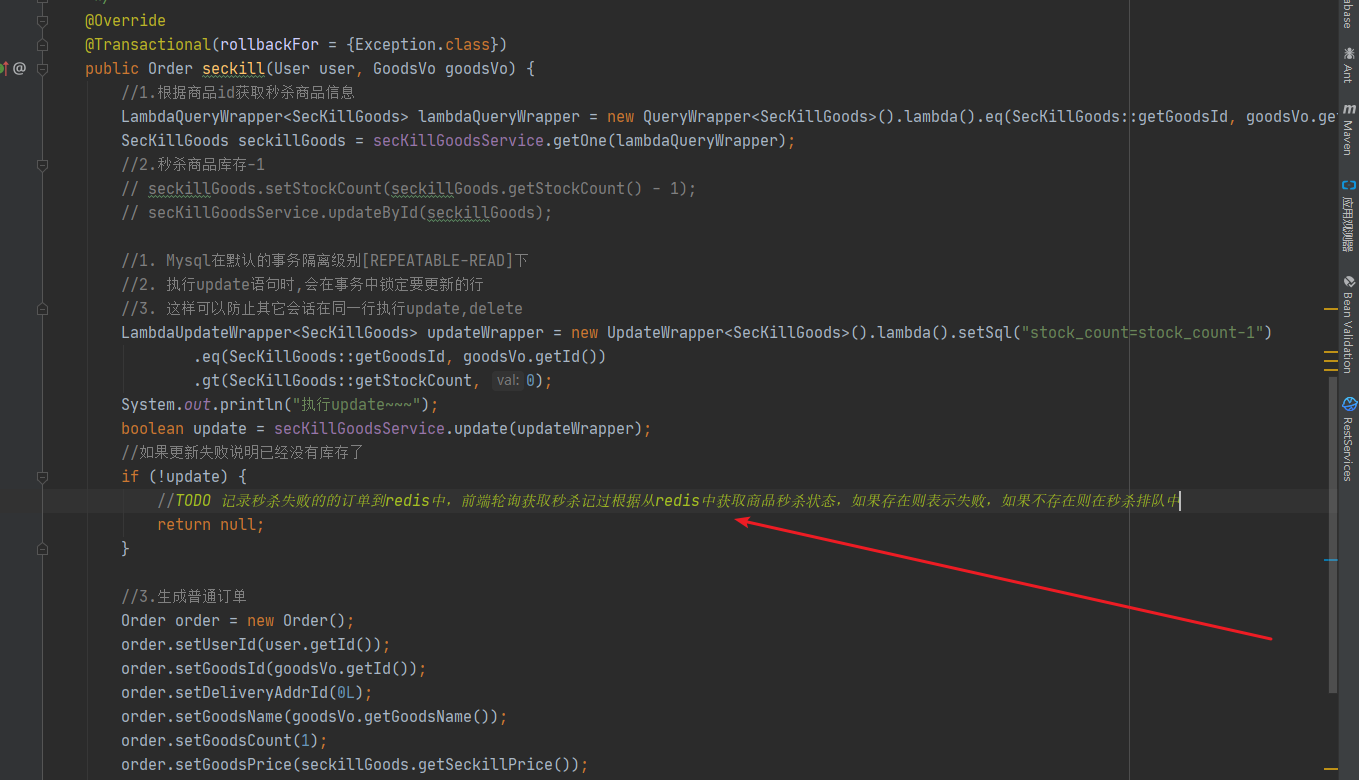
秒杀高并发解决方案
秒杀高并发解决方案 1.秒杀/高并发方案-介绍 秒杀/高并发 其实主要解决两个问题,一个是并发读,一个是并发写并发读的核心优化理念是尽量减少用户到 DB 来"读"数据,或者让他们读更少的数据, 并 发写的处理原则也一样针对秒杀系统需…...

【每日一题】蓝桥杯加练 | Day07
文章目录一、三角回文数1、问题描述2、解题思路3、AC代码一、三角回文数 原题链接:三角回文数 1、问题描述 对于正整数 n, 如果存在正整数 k 使得n123⋯k k(k1)2\frac{k(k1)}{2}2k(k1) , 则 n 称为三角数。例如, 66066 是一个三角数, 因为 66066123⋯363 。 如果一…...

条件语句(分支语句)——“Python”
各位CSDN的uu们你们好呀,最近总是感觉特别特别忙,但是却又不知道到底干了些什么,好像啥也没有做,还忙得莫名其妙,言归正传,今天,小雅兰的内容还是Python呀,介绍一些顺序结构的知识点…...

论文投稿指南——中文核心期刊推荐(国家财政)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…...
面向数据安全共享的联邦学习研究综述
开放隐私计算 摘 要:跨部门、跨地域、跨系统间的数据共享是充分发挥分布式数据价值的有效途径,但是现阶段日益严峻的数据安全威胁和严格的法律法规对数据共享造成了诸多挑战。联邦学习可以联合多个用户在不传输本地数据的情况下协同训练机器学习模型&am…...
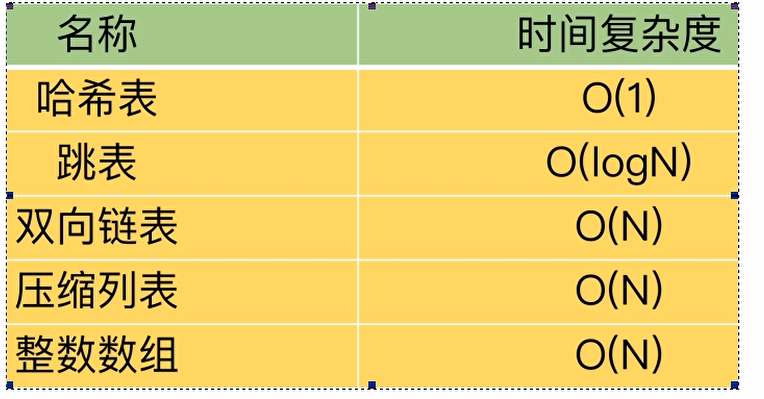
Redis经典五种数据类型底层实现原理解析
目录总纲redis的k,v键值对新的三大类型五种经典数据类型redisObject结构图示结构讲解数据类型与数据结构关系图示string数据类型三大编码格式SDS详解代码结构为什么要重新设计源码解析三大编码格式hash数据类型ziplist和hashtable编码格式ziplist详解结构剖析ziplist的优势(为什…...

Jackson 返回前端的 Response结果字段大小问题
目录 1、问题产生的背景 2、出现的现象 3、解决方案 4、成果展现 5、总结 6、参考文章 1、问题产生的背景 因为本人最近工作相关的对接外部项目,在我们国内有很多程序员都是使用汉语拼音或者部分字母加上英文复合体定义返回实体VO,这样为了能够符合…...

每天五分钟机器学习:你理解贝叶斯公式吗?
本文重点 贝叶斯算法是机器学习算法中非常经典的算法,也是非常古老的一个算法,但是它至今仍然发挥着重大的作用,本节课程及其以后的专栏将会对贝叶斯算法来做一个简单的介绍。 贝叶斯公式 贝叶斯公式是由联合概率推导而来 其中p(Y|X)称为后验概率,P(Y)称为先验概率…...

C++的入门
C的关键字 C总计63个关键字,C语言32个关键字 命名空间 我们C的就是建立在C语言之上,但是是高于C语言的,将C语言的不足都弥补上了,而命名空间就是为了弥补C语言的不足。 看一下这个例子。在C语言中会报错 #include<stdio.h>…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

Prompt Tuning、P-Tuning、Prefix Tuning的区别
一、Prompt Tuning、P-Tuning、Prefix Tuning的区别 1. Prompt Tuning(提示调优) 核心思想:固定预训练模型参数,仅学习额外的连续提示向量(通常是嵌入层的一部分)。实现方式:在输入文本前添加可训练的连续向量(软提示),模型只更新这些提示参数。优势:参数量少(仅提…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

Spring AI与Spring Modulith核心技术解析
Spring AI核心架构解析 Spring AI(https://spring.io/projects/spring-ai)作为Spring生态中的AI集成框架,其核心设计理念是通过模块化架构降低AI应用的开发复杂度。与Python生态中的LangChain/LlamaIndex等工具类似,但特别为多语…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...