【性能优化】表分区实践最佳案例
背景
随着数字化建设的持续深入,企业的业务规模迎来了高速发展,其数据规模也呈现爆炸式增长,如果继续使用传统解决方案,将所有数据存储在一个表中,对数据的查询和维护效率将是一个巨大的挑战,在这个背景下,表分区技术应运而生。
分区的其核心思想是将数据按照某个特定的标准分成多个物理块,每个物理块即为一个分区,从而使数据的存储和管理更加高效,可帮助我们我们实现稳定的存储增长、高性能和易维护。
优势
- 提升查询性能: 通过将数据分成多个分区,查询只需要访问特定分区的数据,避免扫描全表,减少磁盘I/O,从而加速查询操作,降低响应时间。
- 提升运维便利: 分区使得数据维护操作更加精确,例如我们按年分区,要删除指定年份的数据,无需使用性能开销极大的 DELETE FROM … WHERE year=2001,而是直接使用 DROP TABLE table_partition_2001来快速删除分区数据(几乎无开销)。
- 提升可用性和扩展性:表分区允许根据业务需求进行定制,例如按时间、业务部门等进行分区,单个分区出现故障,其他分区数据仍可用,且修复成本更低;同时避免单表的无限增长而导致性能下降,为系统的可扩展性提供了更好的基础。
何时分区
在决定是否对表进行分区时,需要综合考虑以下几个因素,以确保分区对系统性能和数据管理带来实际的好处:
- 查询模式相对固定:例如经常按业务部门查询,可将其作为分区键以最大限度地减少查询所需扫描的数据规模,例如对超大数据量的表(如 500 GB 以上,非绝对标准)收益较为明显,可明显地降低查询耗时,提升查询效率。
- 数据按时间有序:例如日志数据,使用时间作为分区键可以使查询按时间范围过滤更加高效,同时方便对访问量极低的旧数据进行管理和归档。
设计表分区策略
设计适当的表分区策略是确保分区表性能最大化的关键一步,以下是一些步骤和考虑因素,可帮助您制定有效的分区策略:
- 分析查询需求:分析查询需求,重点关注经常被查询的数据的过滤条件,以选择适当的分区键,使得满足这些过滤条件的数据能够集中在同一分区中,从而优化查询性能。
- 确认数据类型:推荐使用 STRING 或时间类型的列作为分区键,通常可以帮助在数据均衡和分区数量上取得较好的平衡。
- 权衡分区规模:常规情况下,单个分区的数据量控制在 500GB 内,如果集群的 CPU 核数较多,可适当提升,此外,我们还需要关注数据的增长趋势,例如数据按时间增长,时间则是一个优秀的分区键,查询按时间范围过滤时会更高效。
- 选择分区策略:ArgoDB 支持范围分区和单值分区:
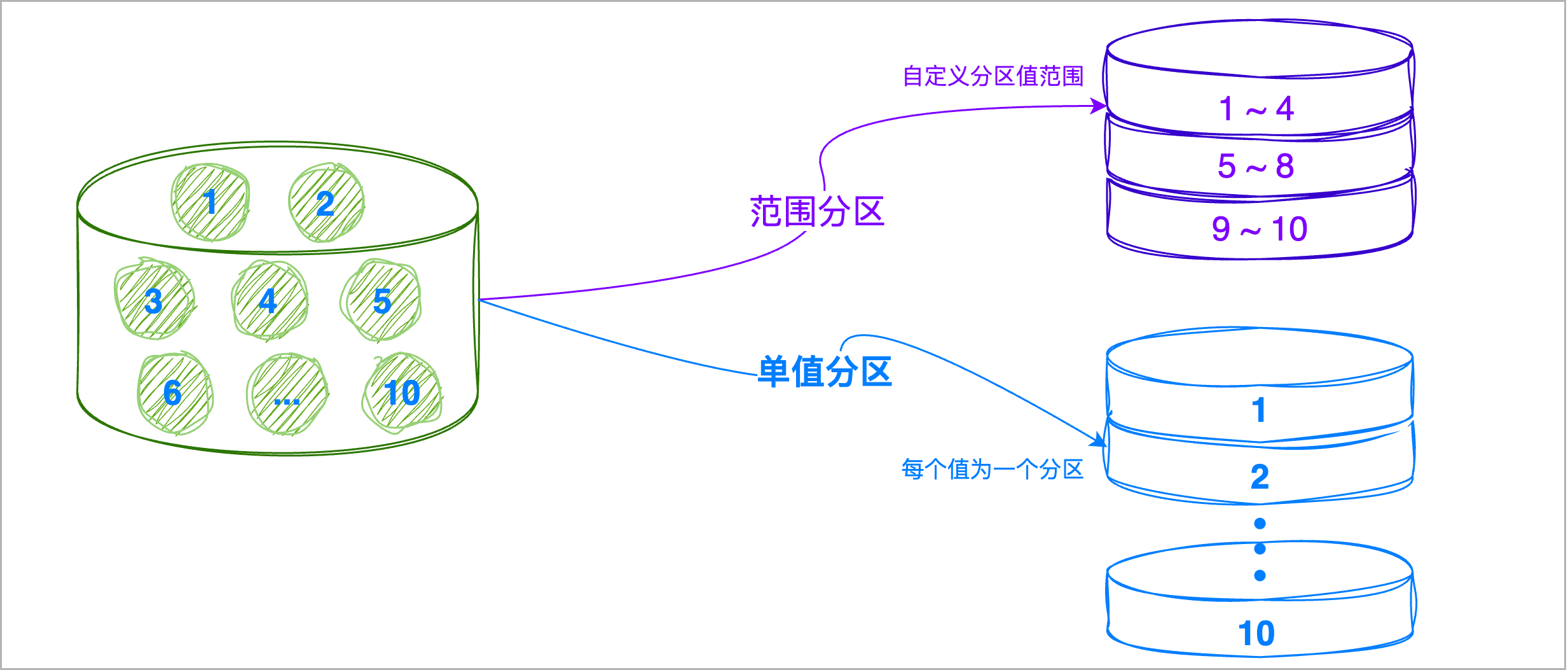
| 分区类型 | 说明 |
|---|---|
| 范围分区 | 按照分区键的值范围来划分分区,执行分区时可基于列值分布均衡度和查询需求来自由划分范围,可避免分区间的数据规模差距过大,提升查询效率。 |
| 单值分区 | 将拥有相同分区键值的记录划分在同一分区中,适用于列基数较少(例如城市名)且分布较为均衡的场景。 |
最佳实践
创建分区表
本案例中,我们以 TPC-DS 样例数据集为例,演示在搭建销售数据分析的数据仓库过程中,遇到的数据分区需求和具体流程。目前,我们的事实表 store_sales 的规模已经增长到了约 2.88 亿条数据(约 20 GB)且持续增长中,日常的报表分析会使用销售日期来作为过滤条件进行,我们希望优化按销售日期范围查询的性能,简化后的 ER 图如下:

操作流程
1. 选择分区键。
基于前面的介绍和场景需求,我们优先选择与时间关联的列作为分区键,而通过上面简化的 ER 图可以得知,store_sales 表虽然没有直接存储时间信息,但是通过外键(ss_sold_date_sk)关联到名为 date_dim 维度表的 d_date_sk 列,所以初步选择 ss_sold_date_sk 作为分区键。
2. 了解分区键的数据特性。
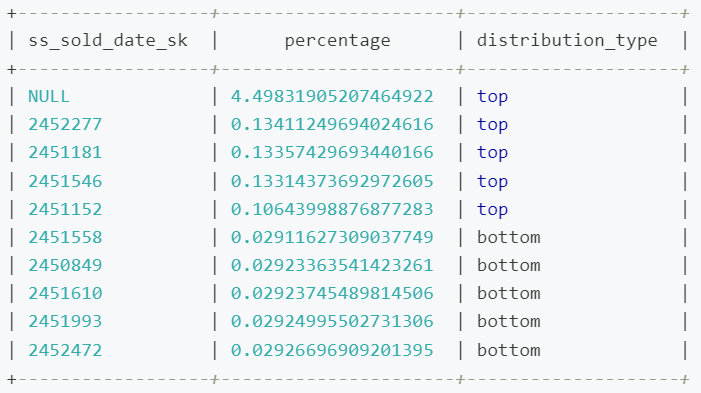
初步选择分区键后,我们还需要关注分区键 ss_sold_date_sk 的数据分布情况,为后续的分区设置提供参考,例如通过下述语句,查看 ss_sold_date_sk 列值中,排名前 5 个和倒数 5 个的数据占比辅助判断数据分布情况。
WITH partition_percentages AS (
SELECT ss_sold_date_sk, COUNT(*) * 100.0 / SUM(COUNT(*)) OVER() AS percentage
FROM store_sales
GROUP BY ss_sold_date_sk
)
SELECT ss_sold_date_sk, percentage, 'top' AS distribution_type
FROM partition_percentages
ORDER BY percentage DESC
LIMIT 5
UNION ALL
SELECT ss_sold_date_sk, percentage, 'bottom' AS distribution_type
FROM partition_percentages
ORDER BY percentage ASC
LIMIT 5;
输出结果如下,可以看到数据在时间分布上相对均衡,只有一个特殊 NULL 值占比约 4.5%,那么我们在分区时基本可以依据自然时间(如月份或季度)来划分,如果某些时间点对应的数据非常多,可在分区时适当调整其对应的分区范围。
除上述方法外,您还可以通过数据采样、标准差、直方图等方法来辅助判断数据分布的均衡情况。
3. 选择分区策略和分区规模。
i. 首先,我们查询候选的分区键(ss_sold_date_sk)的去重数来判断是否适用于单值分区。
SELECT COUNT(DISTINCT ss_sold_date_sk) AS distinct_count FROM store_sales;
返回结果为 1823,该列的基数较大,如果选择单值分区会导致数据过于分散,所以此处我们选择分区策略为范围分区。
ii. 接下来,我们关联查询事实表 store_sales 和维度表 date_dim,查看候选的分区键的值范围,即日期分布范围。
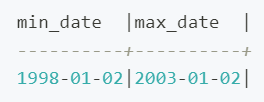
SELECT MIN(d.d_date) AS min_date, MAX(d.d_date) AS max_date
FROM store_sales s
JOIN date_dim d ON s.ss_sold_date_sk = d.d_date_sk;
输出结果如下,日期跨度为 5 年。
iii. 权衡并确认分区规模。
通过前面的分析,我们的查询通常是按照季度或月度数据来分析并输出报表,结合我们前面掌握候选的分区键的数据分布情况,同时考虑到分区数量不宜过多以避免维护的复杂性和额外的负载,权衡分区数和各分区预计包含的数据规模后,最终确定按照季度来划分数据:
数据的时间跨度为 5 年,按照季度划分则预计会创建 20 个分区,每个分区包含约 1400 万条(约 1 GB)的数据。
4. 通过 Beeline 登录至 ArgoDB 数据库,执行表分区操作。
注意:关于如何通过 Beeline 登录数据库,请参考Inceptor/ArgoDB如何连接数据库。
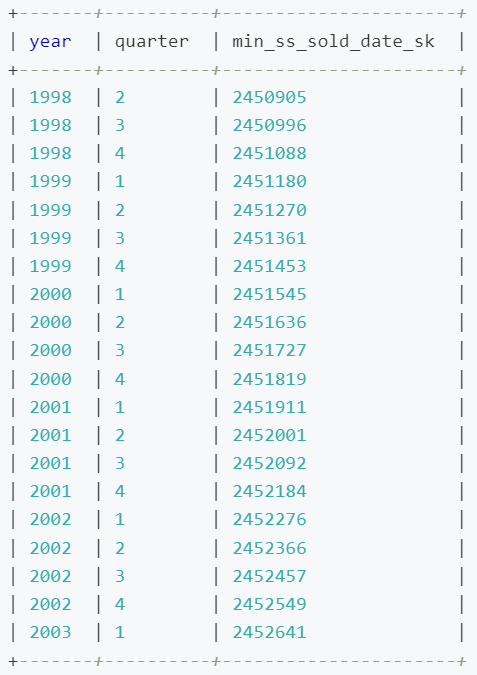
i. 由于 store_sales 表的 ss_sold_date_sk 存储的不是具体时间,我们先通过下述语句找出各分区对应的键值。
-- 创建分区时采用 VALUES LESS THAN 语法,所以开始时间为数据范围内的第二季度第一天,即 1998-04-01
SELECT DISTINCT YEAR(d.d_date) AS year,
QUARTER(d.d_date) AS quarter,
MIN(s.ss_sold_date_sk) AS min_ss_sold_date_sk
FROM store_sales s
JOIN date_dim d ON s.ss_sold_date_sk = d.d_date_sk
WHERE d.d_date BETWEEN '1998-04-01' AND '2003-01-02'
GROUP BY year, quarter
ORDER BY year, quarter;
输出结果如下:
ii. 确定分区键值后,执行下述命令创建分区表,详细语法可参考开发者指南中的定义分区章节。
CREATE TABLE store_sales_partition(
ss_sold_time_sk INTEGER ,
ss_item_sk INTEGER NOT NULL,
ss_customer_sk INTEGER ,
ss_cdemo_sk INTEGER ,
ss_hdemo_sk INTEGER ,
ss_addr_sk INTEGER ,
ss_store_sk INTEGER ,
ss_promo_sk INTEGER ,
ss_ticket_number BIGINT NOT NULL,
ss_quantity INTEGER ,
ss_wholesale_cost FLOAT ,
ss_list_price FLOAT ,
ss_sales_price FLOAT ,
ss_ext_discount_amt FLOAT ,
ss_ext_sales_price FLOAT ,
ss_ext_wholesale_cost FLOAT ,
ss_ext_list_price FLOAT ,
ss_ext_tax FLOAT ,
ss_coupon_amt FLOAT ,
ss_net_paid FLOAT ,]
ss_net_paid_inc_tax FLOAT ,
ss_net_profit FLOAT )
PARTITIONED BY RANGE(ss_sold_date_sk INTEGER) (
PARTITION p1998q1 VALUES LESS THAN (2450905),
PARTITION p1998q2 VALUES LESS THAN (2450996),
PARTITION p1998q3 VALUES LESS THAN (2451088),
PARTITION p1998q4 VALUES LESS THAN (2451180),
PARTITION p1999q1 VALUES LESS THAN (2451270),
PARTITION p1999q2 VALUES LESS THAN (2451361),
PARTITION p1999q3 VALUES LESS THAN (2451453),
PARTITION p1999q4 VALUES LESS THAN (2451545),
PARTITION p2000q1 VALUES LESS THAN (2451636),
PARTITION p2000q2 VALUES LESS THAN (2451727),
PARTITION p2000q3 VALUES LESS THAN (2451819),
PARTITION p2000q4 VALUES LESS THAN (2451911),
PARTITION p2001q1 VALUES LESS THAN (2452001),
PARTITION p2001q2 VALUES LESS THAN (2452092),
PARTITION p2001q3 VALUES LESS THAN (2452184),
PARTITION p2001q4 VALUES LESS THAN (2452276),
PARTITION p2002q1 VALUES LESS THAN (2452366),
PARTITION p2002q2 VALUES LESS THAN (2452457),
PARTITION p2002q3 VALUES LESS THAN (2452549),
PARTITION p2002q4 VALUES LESS THAN (2452641),
PARTITION pmax VALUES LESS THAN (MAXVALUE))
STORED AS HOLODESK
WITH PERFORMANCE;
5. 在业务低峰期执行下述命令,将 TXT 格式的外表数据写入至刚刚创建的分区表中。
-- 开启数据动态写入,即写入时基于分区键的值自动将数据放置到对应分区中
set hive.exec.dynamic.partition=true;
set stargate.dynamic.partition.enabled=true;
-- 执行数据写入操作
INSERT INTO store_sales_partition
PARTITION (ss_sold_date_sk)
SELECT
ss_sold_time_sk,
ss_item_sk,
ss_customer_sk,
ss_cdemo_sk,
ss_hdemo_sk,
ss_addr_sk,
ss_store_sk,
ss_promo_sk,
ss_ticket_number,
ss_quantity,
ss_wholesale_cost,
ss_list_price,
ss_sales_price,
ss_ext_discount_amt,
ss_ext_sales_price,
ss_ext_wholesale_cost,
ss_ext_list_price,
ss_ext_tax,
ss_coupon_amt,
ss_net_paid,
ss_net_paid_inc_tax,
ss_net_profit,
ss_sold_date_sk
FROM tpcds_text_100.store_sales;
注意:执行时间由集群负载、数据规模等因素共同决定,您可以登录 DBA Service,在查询页面中查看任务执行进度。

6. (可选)数据导入执行完成后,通过 SELECT COUNT(*) FROM store_sales_partition 来确认数据条目数与原表一致。
性能对比
接下来,我们选择一个典型的查询场景,即查询特定季度的销售数据并计算净利润,并使用分区前后的情况来进行对比,以展示分区对于查询性能的影响。
注:为更好地展示分区前后的性能对比,本案例使用的机器资源存在一定限制,因此查询响应时间仅供演示参考,真实业务场景中分区前的查询效率和速度会更高。
分区前
在分区之前,我们将数据存储在单一的大表 store_sales 中,假设我们查询 1999 年第一季度的净利润,查询 SQL 如下:
SELECT SUM(ss_net_profit) AS net_profit_1999q1
FROM store_sales
WHERE ss_sold_date_sk >= ( -- 通过子查询获取开始时间对应的 ss_sold_date_sk
SELECT MIN(d_date_sk)
FROM date_dim
WHERE d_year = 1999 AND d_qoy = 1
)
AND ss_sold_date_sk < ( -- 通过子查询获取结束时间对应的 ss_sold_date_sk
SELECT MIN(d_date_sk)
FROM date_dim
WHERE d_year = 1999 AND d_qoy = 2
);
等待查询执行完成,命令行将返回查询结果和耗时,具体如下:

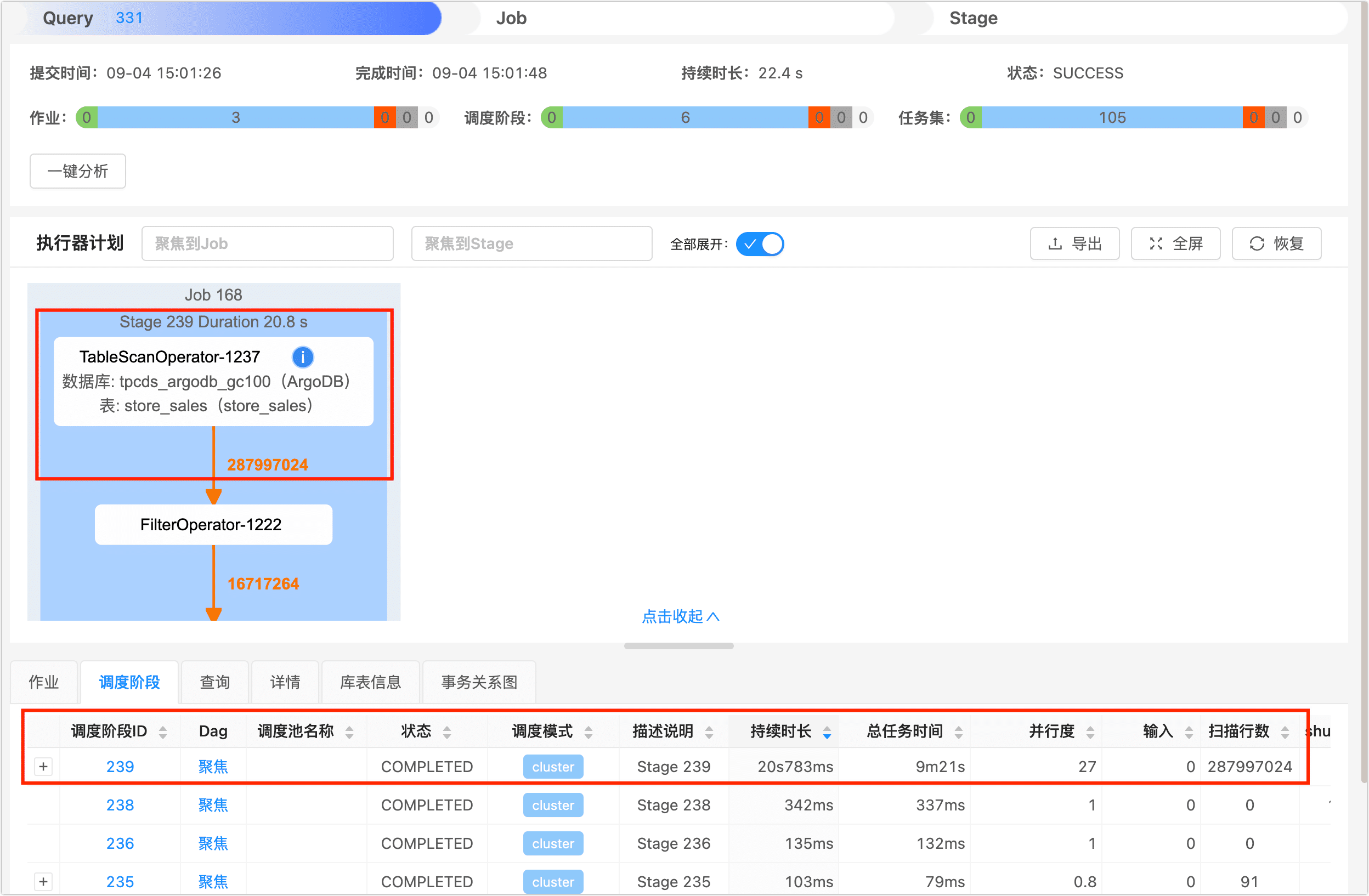
本次查询耗时约为 28.5 秒,为了进一步了解查询任务在任务执行的各阶段的耗时情况,我们登录到 DBA Service 平台,在查询页面找到并单击刚刚执行完成的查询作业,然后单击调度阶段页签,可以看到该查询任务被分为 4 个调度阶段,时间主要花费在了 ID 为 1679 的调度阶段上,原因是它为了取出满足 WHERE 条件的数据,执行了全表扫描,即扫描行数为 287997024(约 2.87 亿)。
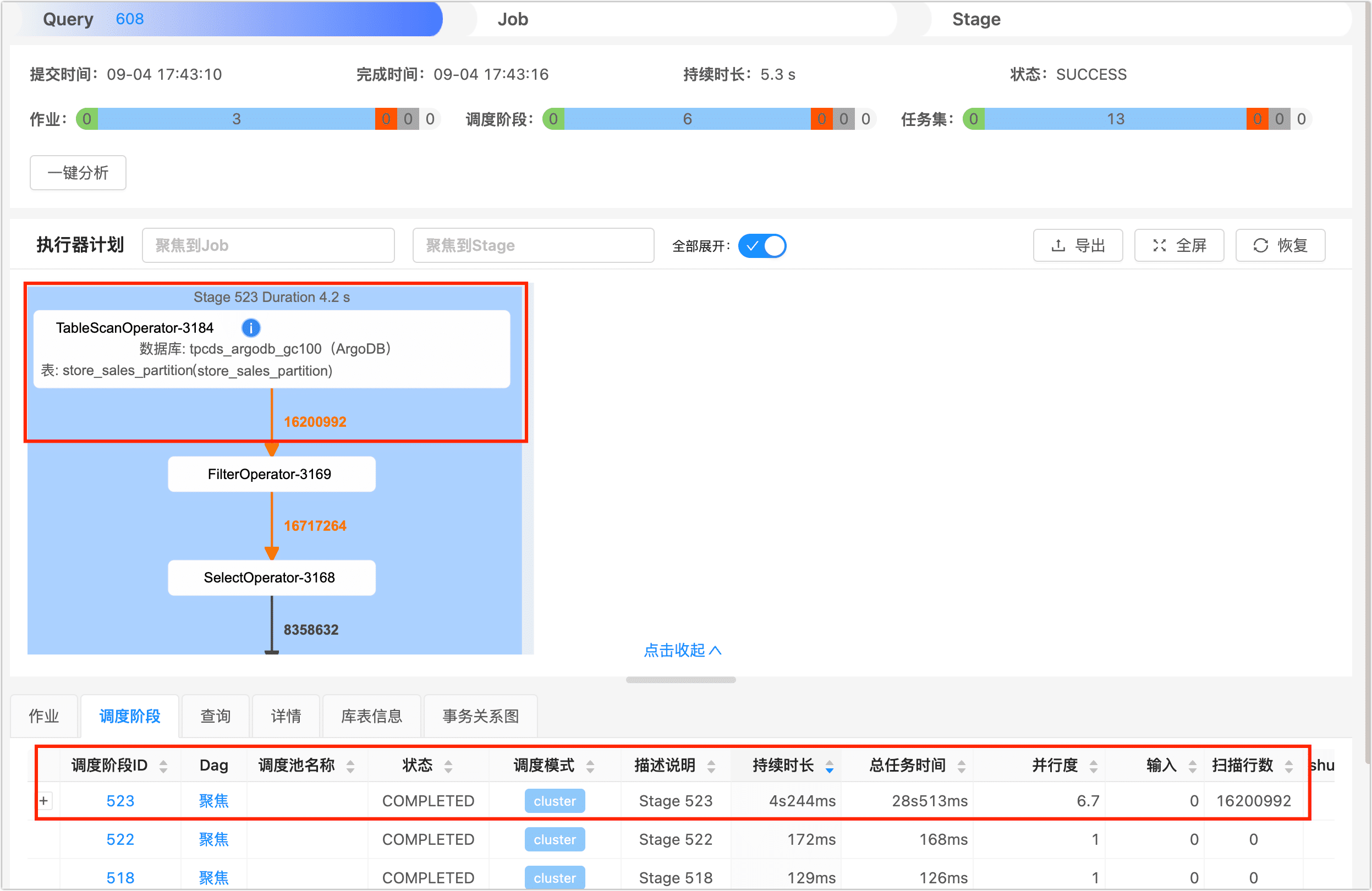
分区后
而在执行表分区后,我们使用分区表 store_sales_partition 执行相同的查询,本次查询只扫描了 16200992(约 1600 万)条记录,整体仅耗时为 6.9 秒,相较于之前查询速度提升了 4 倍以上。
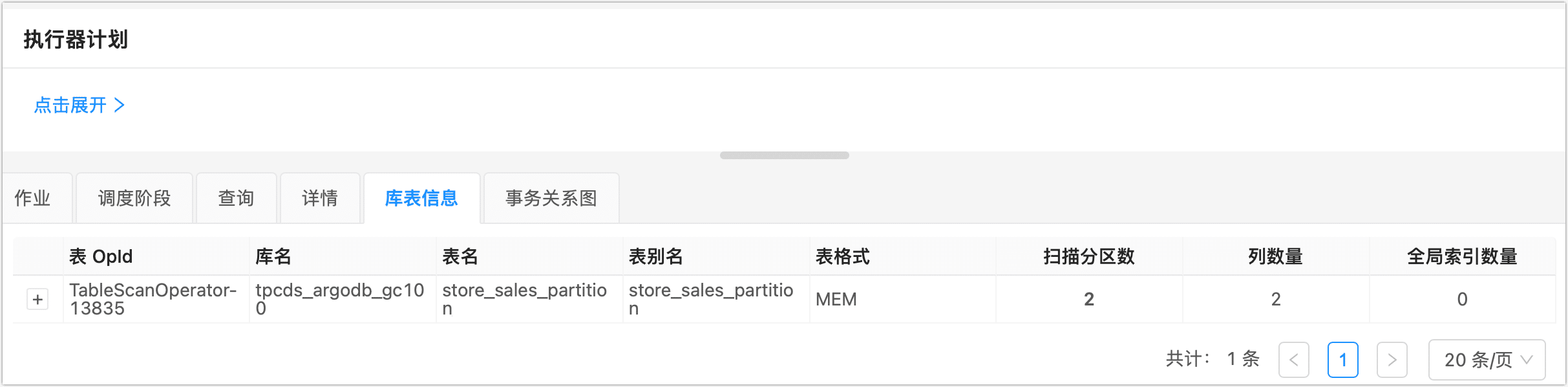
单击库表信息页签,可以看到本次查询的扫描分区数、列数和索引数等信息。
通过比较分区前后的查询性能,我们可以得出以下结论:
- 分区后的查询性能更优:由于分区表的优化,查询性能得到了显著提升。
- 分区使得查询范围更精确:分区键的使用使得查询范围更加精确,避免了不必要的数据扫描,从而提高了查询效率。
通过以上的性能对比,我们可以看到分区表的优势,特别是在处理大量数据和复杂查询时,分区能够显著提升查询性能和响应时间。这也强调了在数据模型设计和查询优化中合理使用分区的重要性。
维护分区表
对数据表执行分区操作,不仅可以更好地服务于查询,还可以帮助您更有效地维护历史数据,保障查询性能、数据管理和存储效率的持续优化。
- 性能保持:随着时间的推移,分区表可以保持查询性能的稳定。由于数据被分割成多个分区,查询通常只需要扫描特定分区,而不是整个表,从而提高了查询性能。
- 数据管理:分区表使得数据管理更加灵活。您可以轻松地添加、删除或迁移分区,而不会影响整个表。这对于数据归档、数据清理以及数据的日常维护非常有用。
- 节省存储:通过仅加载和保留必要的分区,避免不必要的数据持续占用存储资源。
接下来,我们通过几个案例演示如何维护分区数据:
删除旧分区
如果某些数据已经不再需要,您可以轻松地删除旧的分区,释放存储空间,且此操作相较于原先基于条件过滤数据并删除,其开销极低,示例如下:
ALTER TABLE store_sales_partition
DROP PARTITION p2000q1;
添加新分区
假设您的分区表按季度分区,现在要添加一个新的季度分区,例如第四季度,随后您可以将新的数据加载至该分区:
ALTER TABLE store_sales_partition_noncluster
ADD PARTITION p2003q4 VALUES LESS THAN (2452733);
提示:如果您在创建分区表时设置了 MAXVALUE 分区,我们需要先将 MAXVALUE 对应的分区删除才可以继续创建新分区。更多关于分区的的操作,请参考开发者指南中定义分区章节。
相关文章:
【性能优化】表分区实践最佳案例
背景 随着数字化建设的持续深入,企业的业务规模迎来了高速发展,其数据规模也呈现爆炸式增长,如果继续使用传统解决方案,将所有数据存储在一个表中,对数据的查询和维护效率将是一个巨大的挑战,在这个背景下…...

力扣SQL50 项目员工 I ROUND AVG
Problem: 1075. 项目员工 I 👨🏫 参考题解 Code select project_id,ROUND(AVG(e.experience_years),2) as average_years FROMproject as p LEFT JOINemployee as e ONp.employee_id e.employee_id GROUP BYp.project_id;...

nuscenes 数据集学习笔记
目录 数据信息类型: 数据信息类型: Map & Camera(png), Lidar(激光雷达) & Radar(雷达)(pcd), Json 文件结构(以v1.0-mini为例): maps: 存放Map的png文件samples: 存放Camera, Lidar, Radar关键非结构化数据信息, 带标注sweeps: 存放Camera, Lidar, Radar 次要非结构…...

在Windows上用MinGW编译OpenCV项目运行全流程
一、准备软件 OpenCV源码CMake工具MinGW工具链(需要选用 posix 线程版本:原因见此) 二、操作步骤 官网提供了VC16构建版本的二进制包,但是没有给出GCC编译的版本。所以如果使用MinGW进行构建,那就只能从源码开始构建…...

用Vite基于Vue3+ts+DataV+ECharts开发数据可视化大屏,即能快速开发又能保证屏幕适配
数据可视化大屏 基于 Vue3、Typescript、DataV、ECharts5 框架的大数据可视化(大屏展示)开发。此项目vue3实现界面,采用新版动态屏幕适配方案,全局渲染组件封装,支持数据动态刷新渲染、内部DataV、ECharts图表都支持自…...

大二学生眼中的Netty?基于Netty实现内网穿透!
爷的开场白 掘金的朋友们大家好!我是新来的Java练习生 CodeCodeBond! 这段时间呢,博主在学习Netty,想做一个自己感兴趣好玩的东西,那就是内网穿透!!(已经实现主要代理功能但有待优化…...

JavaStringBuffer与StringBuilder
StringBuffer、StringBuilder 文章目录 StringBuffer、StringBuilderStringBuffer和StringBuilder的理解可变性分析对于String对于StringBuilder 常用方法执行效率对比 StringBuffer和StringBuilder的理解 String 不可变的字符序列 StringBuffer 可变的字符序列 JDK1.0声明&…...

云徙科技助力竹叶青实现用户精细化运营,拉动全渠道销售额增长
竹叶青茶以其别具一格的风味与深厚的历史底蕴,一直被誉为茶中瑰宝。历经千年的传承与创新,竹叶青不仅坚守着茶叶品质的极致追求,更在数字化的浪潮中,率先打破传统,以科技力量赋能品牌,成为茶行业的领军者。…...
深度揭秘:深度学习框架下的神经网络架构进化
深度学习框架下的神经网络架构经历了从基础到复杂的显著进化,这一进程不仅推动了人工智能领域的突破性进展,还极大地影响了诸多行业应用。本文旨在深入浅出地揭示这一进化历程,探讨关键架构的创新点及其对现实世界的影响。 引言:…...

MySQL的DML语句
文章目录 ☃️概述☃️DML☃️添加数据☃️更新和删除数据☃️DML的重要性 ☃️概述 MySQL 通用语法分类 ● DDL: 数据定义语言,用来 定义数据库对象(数据库、表、字段) ● DML: 数据操作语言,用来对数据库表中的数据进行增删改 …...

Wireshark的基本用法以及注意事项
Wireshark 是一个流行的网络协议分析工具,可以捕获和分析网络数据包。以下是一些常见的 Wireshark 的用法: 安装和启动:首先需要下载和安装 Wireshark。安装完成后,可以通过启动 Wireshark 应用程序来打开它。 选择网络接口&…...

集团门户网站的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,论坛管理,集团文化管理,基础数据管理,公告通知管理 前台账户功能包括:系统首页,个人中心,论坛࿰…...
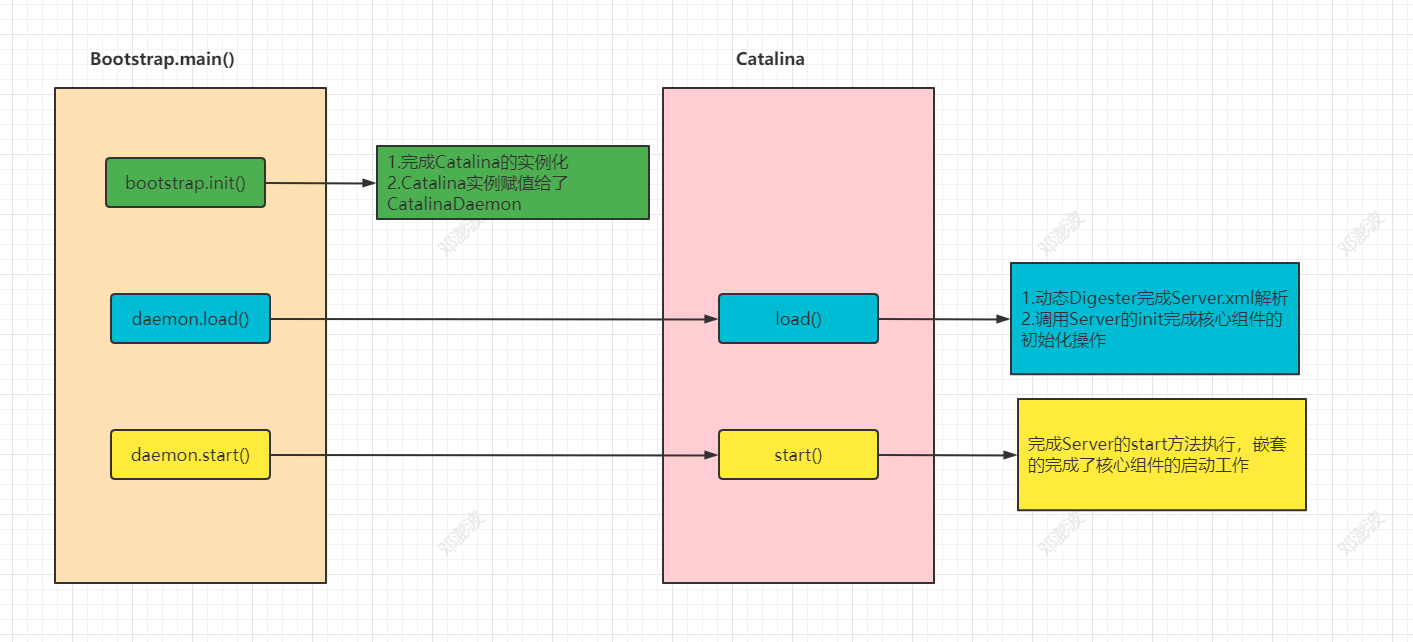
Tomcat基础详解
第一篇:Tomcat基础篇 lecture:邓澎波 一、构建Tomcat源码环境 工欲善其事必先利其器,为了学好Tomcat源码,我们需要先在本地构建一个Tomcat的运行环境。 1.源码环境下载 源码有两种下载方式: 1.1 官网下载 https://…...
)
【Python爬虫】爬取名人名言页面并进行简单的数据清洗(入门级)
目录 资源链接 一、网站选择 二、数据爬取要求 三、数据清洗要求 四、实现代码 1.数据采集 2.数据清洗 资源链接 下面有笔者所放的源码下载链接,读者可自行下载: 链接:https://pan.baidu.com/s/1YmTdlnbSJLvLrrx92zz6Qg 提取码&…...
Microsoft Visual C++ Redistributable 【安装包】【高速下载】
方法1、可以从官方下载,如下图 Visual C Redistributable for Visual Studio 2015 但是此链接只有一个版本 方法2 已经下载好并且已经整理好了2008--2022的所有版本点击下方链接即可高速下载 如果是win7-win8-win10-win11直接可以下载2015--2022版本,…...
MFC绘制哆啦A梦
文章目录 OnPaint绘制代码完整Visual Studio工程下载其他卡通人物绘制 OnPaint绘制代码 CPaintDC dc(this); // 用于绘画的设备上下文CRect rc;GetWindowRect(rc);int cxClient rc.Width();int cyClient rc.Height();// 辅助线HPEN hPen CreatePen(PS_DOT, 1, RGB(192, 192,…...

网络编程(TCP协议,UDP协议)
目录 网络编程三要素 IP IPv4 InetAddress类 端口号 协议 UDP协议 UDP协议发送数据 UDP协议接收数据 UDP的三种通信方式(代码实现) TCP协议 TCP通信程序 三次握手和四次挥手 练习 1、客户端:多次发送数据服务器:接收多次接收数据,并打印 2、客户端…...

读取Jar包下文件资源的问题及解决方案
问题 项目A代码调用到Resouces下的文件a.sh,打包成Jar包后,项目B调用对应方法时,出现报错,找不到a.sh文件路径,原来的代码可能是: URL resource getClass().getClassLoader().getResource("a.sh&qu…...

C++ 反转一个二进制串
描述 一个32位有符号整数,用二进制编码来表示。现需要将该二进制编码按位反转,计算出反转后的值。 示例1 输入: 1 返回值: -2147483648 说明: 00000000 00000000 00000000 00000001 翻转后为 10000000 000000…...

黑神话悟空-吉吉国王版本【抢先版】
在中国的游戏市场中,一款名为“黑神话悟空”的游戏引起了广泛的关注。这款游戏以中国传统的神话故事“西游记”为背景,创造了一个令人震撼的虚拟世界。今天,我们要来介绍的是这款游戏的一种特殊版本,那就是吉吉国王版本。 在吉吉国…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

水泥厂自动化升级利器:Devicenet转Modbus rtu协议转换网关
在水泥厂的生产流程中,工业自动化网关起着至关重要的作用,尤其是JH-DVN-RTU疆鸿智能Devicenet转Modbus rtu协议转换网关,为水泥厂实现高效生产与精准控制提供了有力支持。 水泥厂设备众多,其中不少设备采用Devicenet协议。Devicen…...
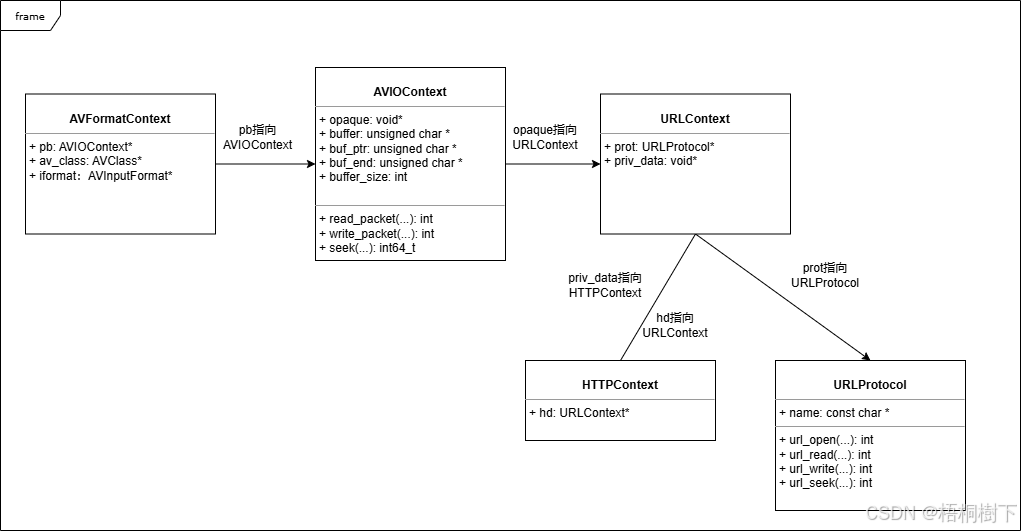
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...
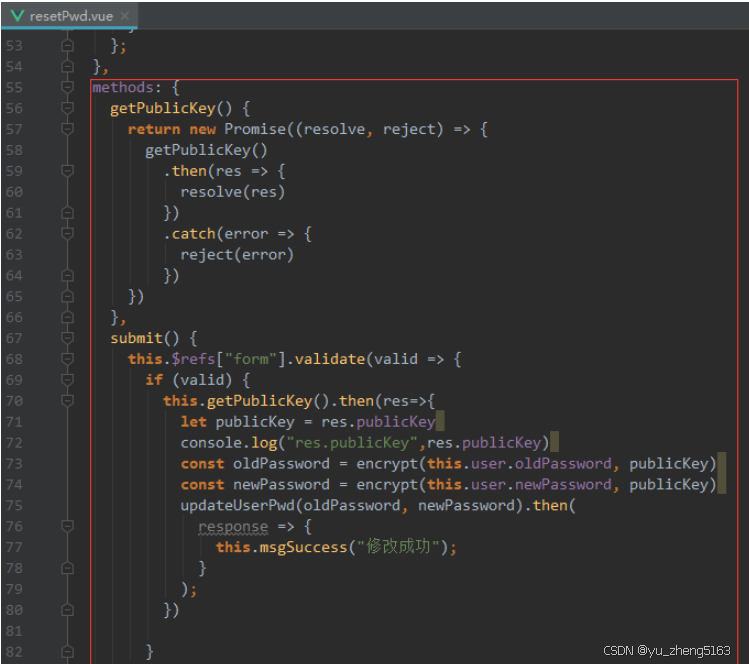
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

Appium下载安装配置保姆教程(图文详解)
目录 一、Appium软件介绍 1.特点 2.工作原理 3.应用场景 二、环境准备 安装 Node.js 安装 Appium 安装 JDK 安装 Android SDK 安装Python及依赖包 三、安装教程 1.Node.js安装 1.1.下载Node 1.2.安装程序 1.3.配置npm仓储和缓存 1.4. 配置环境 1.5.测试Node.j…...