算法24:LeetCode_并查集相关算法
目录
题目一:力扣547题,求省份数量
题目二:岛屿数量
题目三:岛屿数量拓展
什么是并查集,举个简单的例子。学生考试通常会以60分为及格分数,我们将60分及以上的人归类为及格学生,而60分以下归类为不及格的学生, 通过记录学生ID。现在要求根据学生的ID,迅速的找出这名学生成绩是否及格。这种归类就是合并,而根据学生ID查找就是查询,合起来就是并查集。
可能会有人说不用并查集也可以干这件事情,但是有没有想过一个问题,一个班级,一个年级,一个市,一个省,全中国。如果都要统计这些信息呢?如果要统计及格的全部人数呢?难到要一个一个去查吗?此处,并查集就发挥作用了。
下面推荐一篇博客,对并查集的解释还算通俗易懂,有兴趣的朋友可以看看https://blog.csdn.net/LWR_Shadow/article/details/124873281
下面来分享一些并查集的算法题:
题目一:力扣547题,求省份数量
题目的具体信息可以直接查看547. 省份数量
这是一道奇葩的题目,非此即彼,只要不相连的城市,就属于其他省。而现实中,比如苏州和无锡相连接,徐州和他们都不相连,但是无锡、苏州、徐州却都属于江苏省。既然题目是这么要求的,那我们就按照要求进行设计。
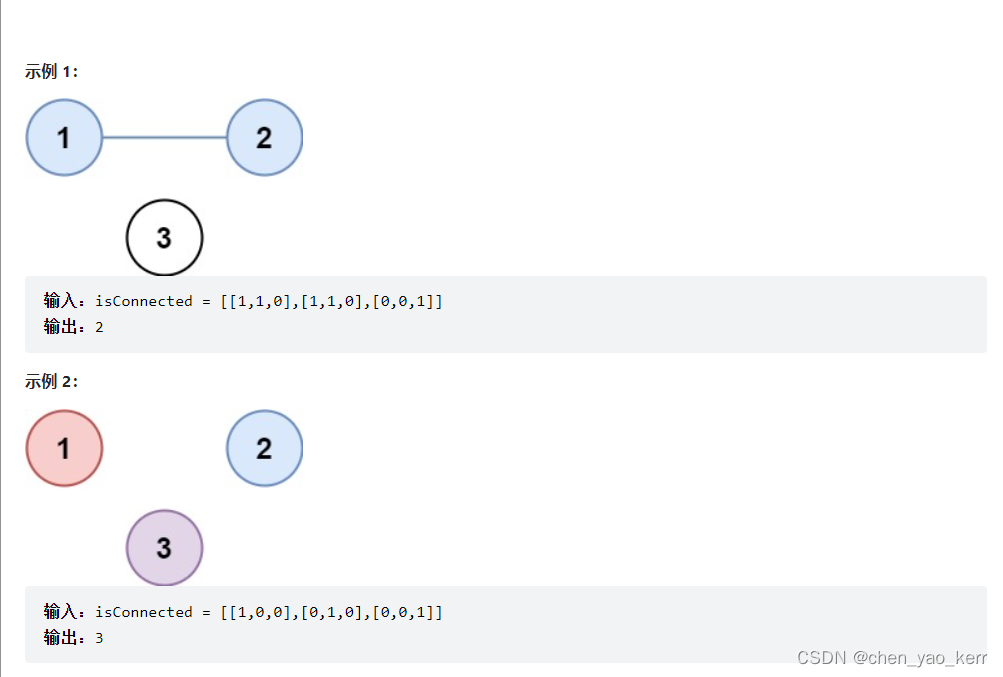
式例1:这组二维数组是什么意思呢?
从1节点的角度:【1,1,0】代表1节点自己连接自己,自己连接2节点,不连接点3节点。
从2节点的角度:【1,1,0】自己连接1节点,自己连接自己,自己不连接3节点。
从3节点的角度:【0,0,1】自己不连接1节点,不连接2节点,自己连接自己。
所以,得出的结论是节点1和节点2是同一个省,而3节点是另外一个省的城市,共2个省份
式例2:完全按照上方分析的思路去分析,节点1、节点2、节点3互不连接,也就是说他们分别属于不同的省份,这个demo共有3个省份。
下面使用并查集的知识进行解答:
package code03.并查集_04;/**** 链接 https://leetcode.cn/problems/number-of-provinces/*/
public class Code01_ProvinceCount {public static int findCircleNum(int[][] M){int length = M.length;UnionFind uom = new UnionFind(length);for (int i = 0; i < M.length; i++) {for (int j = i + 1; j < length; j++) {if (M[i][j] == 1) {uom.union(i, j);}}}return uom.size();}static class UnionFind {//父节点private int[] parent;// 辅助结构private int[] help;// 一共有多少个集合private int sets;// i所在的集合大小是多少private int[] size;UnionFind(int length){parent = new int[length];size = new int[length];//help的初始化, 个人想每次调用的时候初始化,但是数据量较大的//时候可能会吃内存help = new int[length];//本题比较特殊,二维数组长度为多少,集合最多就可能是多少sets = length;//记录数组的下标地址,可以通过下标找到父亲节点for (int i = 0; i < length; i++) {parent[i] = i;//i所在的集合大小是多少, 默认是自己, 所以是1size[i] = 1;}}public void union(int i, int j){//获取到的根节点索引. 需要注意的是,第一次调用这i和j,返回的是//他们本身的索引值。不会涉及到里面的while和for。 这样,我们本//方法体才能安稳的做合并操作,才会存在下挂的后代节点。int indexI = findRoot(i);int indexJ = findRoot(j);//如果他们两个值不相等,说明他们2个//还没有成为同一类数据。因此,我们需要//把他们设置成同一类数据if (indexI != indexJ){if (size[indexI] >= size[indexJ]) {/*** 此处的合并是合并2个不同的节点,将较小的节点指针指向较大的节点,* 这样就实现了并查集合并的目的.这是功能性合并** 而在findRoot方法中,合并的是同一节点的父节点,起到的是一个性能优化的作用*///等价于parent[indexJ] = parent[indexI], 因为没有合并之前,indexI == parent[indexI]parent[indexJ] = indexI;//更新合并后的根节点的后代数量size[indexI] = size[indexI] + size[indexJ];//被合并后的根节点,不再保存后代信息size[indexJ] = 0;}else {parent[indexI] = indexJ;size[indexJ] = size[indexJ] + size[indexI];size[indexI] = 0;}//因为我们默认的是有几组数据,就有几个省份。 但是此处发生了合并,也就意味着2组数据中//他们是在相同的省份中,因此默认值需要减少1.sets--;}}public int size() {return sets;}public int findRoot (int addressIndex){int index = 0;/*** 第一次肯定是可以找到地址的,因为每个城市的父节点都是自己,* 所以他们都是在parent数组中的** 但是, 经过合并后,我们只会保存合并后的父节点的地址下标。* 数组的形式,我们只是在parent数组中,更新当前城市的父节点* 下标地址。因此,以下的while循环就出出现了*/while (addressIndex != parent[addressIndex]) {//记录下每一次遍历的父节点的下标,有可能有很多help[index] = parent[addressIndex];//指针指向父节点的下标,这样我们就可以逐层//网上找到最顶层的根节点了。addressIndex = parent[addressIndex];index++; //index是比实际找的次数多1的}/*** 我们只是在parent数组中,更新当前城市的父节点下标地址* 这样我就达到了并查集,合并同类数据的功能** index是比实际找的次数多1的, 所以一开始就需要减1* 这也就不用担心help里面可能存在的脏数据问题了。*/for (index--; index >=0; index--) {/*** 路径压缩,把之前每一次找到的父节点下标全部指向了根节点,* 这样以后再找的话就会减少上面的while循环次数了。* 因为我们判断是否是同一类数据,就是根据根节点的下标进行判断的** 比如,a 和 b的根节点相同,那么我就可以认为a和b是同一类数据** help数组之前记录了parent数组父节点的下标,因此需要根据* 下标把这些值都给改成根节点的下标,这样这些节点以后就全部* 指向根节点了*/parent[help[index]] = addressIndex;}//其实,返回的就是一个父节点的地址下标值return addressIndex;}}public static void main(String[] args) {int[][] isConnected = {{1,1,0},{1,1,0},{0,0,1}};int size = findCircleNum(isConnected);System.out.println(size); //预期输出2int[][] isConnected2 = {{1,0,0},{0,1,0},{0,0,1}};int size2 = findCircleNum(isConnected2);System.out.println(size2); //预期输出2}
}
题目二:岛屿数量
原题可以直接查看200. 岛屿数量
这一题和上一题省份数量有相同和不同的部分:
相同部分是1和1相连接,就属于1片岛屿,还是算1个岛,这点和省份计算是一样的。
不同的部分是,省份中0也代表一个城市,只是它和其他城市不相连;而这道题中,0代表的是水,不是岛屿,因此在初始化的时候是有区别的。

并查集方式实现:
package code03.并查集_04;/*** https://leetcode.com/problems/number-of-islands/* 并查集方式实现*/
public class Code02_NumberOfLands {public int numIslands(char[][] grid){if (grid == null || grid.length == 0) {return 0;}int rowLength = grid.length;int colLength = grid[0].length;UnionFind uf = new UnionFind(grid);//合并第一行for (int j = 1; j < colLength; j++) {if (grid[0][j - 1] == '1' && grid[0][j] == '1') {uf.union(0, j - 1, 0, j);}}//合并第一列for (int i = 1; i < rowLength; i++) {if (grid[i - 1][0] == '1' && grid[i][0] == '1') {uf.union(i - 1, 0, i, 0);}}//从第二行第二列开始遍历for (int i = 1; i < rowLength; i++) {for (int j = 1; j < colLength; j++) {if (grid[i][j] == '1') {//上一行合并if (grid[i][j - 1] == '1') {uf.union(i, j - 1, i, j);}//前一列合并if (grid[i - 1][j] == '1') {uf.union(i - 1, j, i, j);}}}}return uf.sets;}static class UnionFind{int[] parents;int[] size;int sets;int[] helps;int row;int col;public UnionFind(char[][] gg){row = gg.length;col = gg[0].length;int length = row * col;parents = new int[length];size = new int[length];helps = new int[length];sets = 0;for (int i = 0; i < row; i++) {for (int j = 0; j < col; j++) {//优化,只有是1的是,才会更新parent下标为自己if (gg[i][j] == '1') {//生成唯一地址int index = index(i, j);//默认自己就是自己的父亲节点parents[index] = index;//每个父节点下挂的节点数量,默认为1size[index] = 1;//默认每出现1都是一个岛屿sets++;}}}}public void union (int row1, int col1, int row2, int col2){//父节点int parentIndex1 = index(row1, col1);int parentIndex2 = index(row2, col2);//根节点int rootIndex1 = findRoot(parentIndex1);int rootIndex2 = findRoot(parentIndex2);//根节点不同,则合并if (rootIndex1 != rootIndex2) {//将小的挂在大的下面if (size[rootIndex1] >= size[rootIndex2]) {parents[rootIndex2] = rootIndex1;size[rootIndex1] = size[rootIndex1] + size[rootIndex2];size[rootIndex2] = 0;}else {parents[rootIndex1] = rootIndex2;size[rootIndex2] = size[rootIndex1] + size[rootIndex2];size[rootIndex1] = 0;}sets--;}}public int index (int r, int c) {//列的长度是固定的colreturn r * col + c;}public int findRoot (int index){int rootIndex = 0;//并查集之前合并过while (index != parents[index]) {//记录下每一次找到的上层节点(父节点)helps[rootIndex] = parents[index];//当前地址指向上层节点(父节点)index = parents[index];rootIndex++;}//路径压缩for (rootIndex--; rootIndex > 0; rootIndex--) {//返回原始收集的上层节点地址下标int t = helps[rootIndex];//根据下标,更新到根节点地址,//这样所以的地址都指向了根点处,优化了性能parents[t] = index;}return index;}}public static void main(String[] args) {char[][] bb = {{'1','1','1','1','0'},{'1','1','0','1','0'},{'1','1','0','0','0'},{'0','0','0','0','0'}};Code02_NumberOfLands tt = new Code02_NumberOfLands();int num = tt.numIslands(bb);System.out.println(num);}
}
渲染方式实现:
package code03.并查集_04;/*** 感染方式实现,性能非常高* 局限是部分案例无法解决*/
public class Code02_NumberOfLands_extension {public int numIslands(char[][] grid){if (grid == null || grid.length == 0) {return 0;}int num = 0;for (int row = 0; row < grid.length; row++) {for (int col = 0; col < grid[row].length; col++) {if (grid[row][col] == '1') {num++;infect(grid, row, col);}}}return num;}public void infect (char[][] bb, int row, int col){if (row < 0 || row == bb.length|| col < 0 || col == bb[0].length|| bb[row][col] != '1') {return;}bb[row][col] = 0;//上infect(bb, row-1, col);//下infect(bb, row+1, col);//左infect(bb, row, col-1);//右infect(bb, row, col+1);}public static void main(String[] args) {char[][] bb = {{'1','1','1','1','0'},{'1','1','0','1','0'},{'1','1','0','0','0'},{'0','0','0','0','0'}};Code02_NumberOfLands_extension tt = new Code02_NumberOfLands_extension();int num = tt.numIslands(bb);System.out.println(num);}
}
这一道题,渲染的方式是最优解,它的性能是高于并查集实现方式的。但是,并查集的方式可以解决很多渲染方式无法解决的问题。 因此,渲染方式和并查集方式,我们都要掌握。
题目三:岛屿数量拓展
这是一道收费题:https://leetcode.com/problems/number-of-islands-ii/
* 题目: * 设定一个二维数组,行为 m 列为 n. * 现在给你一组地标数据,可以定位二维数组的具体位置。 每个地标都代表有1个岛屿, * 但是如果连在一起的话只能算做一个岛。要求每次空降一次数据,求每次的岛屿数量。 * * 假设 3 行 3列的 二维数组。 * 给定的坐标为:[[0,0],[0,1],[1,2],[2,,1]] * 【0,0】位置确定,此时岛为1 * 【0,1】位置确定,此时岛为1 * 【1,2】位置确定,此时岛为2 * 【2,1】位置确认,此时岛为3 * * 输出的结果为: 【1,1,2,3】 * 请设计一种算法
package code03.并查集_04;import java.util.ArrayList;
import java.util.List;/*** https://leetcode.com/problems/number-of-islands-ii/** 题目:* 设定一个二维数组,行为 m 列为 n.* 现在给你一组地标数据,可以定位二维数组的具体位置。 每组数据都代表有1个岛屿,* 但是如果连在一起的话只能算做一个岛。要求每次空降一次数据,求每次的岛屿数量。** 假设 3 行 3列的 二维数组。* 给定的坐标为:[[0,0],[0,1],[1,2],[2,,1]]* 【0,0】位置确定,岛为1* 【0,1】位置确定,岛为1* 【1,2】位置确定,岛为2* 【2,1】位置确认,岛为3** 输入的结果为: 【1,1,2,3】* 请设计一种算法*/
public class Code03_NunbOfLandsII {public List<Integer> numIslands(int m, int n, int[][] positions){List<Integer> list = new ArrayList<>();if (m < 0 || n < 0 ||positions == null || positions.length == 0|| positions[0].length == 0) {return list;}//此时的初始化内部不同于之前的初始化UnionFind uf = new UnionFind(m, n);for (int[] position : positions) {list.add(uf.connect(position[0], position[1]));}return list;}static class UnionFind{private int[] parents;private int[] size;private int[] helps;private int sets;private int col;private int row;public UnionFind(int m, int n) {int length = m * n;parents = new int[length];size = new int[length];helps = new int[length];sets = 0;row = m;col = n;}public int connect (int row, int col){//获取当前位置int curPosition = index(row, col);//判断空间的位置是否已经是岛屿,默认为0if (size[curPosition] == 0 ) {size[curPosition] = 1;parents[curPosition] = curPosition;sets++;//合并,和渲染解题思路有点相似union(row, col, row-1, col); //上一行union(row, col, row+1, col); //下一行union(row, col, row, col-1); //前一列union(row, col, row, col+1); //后一列}return sets;}public void union (int row1,int col1, int row2, int col2){//越界,无法合并if (row1 < 0 || row2 < 0 || col1 < 0 || col2 < 0|| row1 == row || row2 == row|| col1 == col || col2 == col) {return;}//父节点int parentIndex1 = index(row1, col1);int parentIndex2 = index(row2, col2);//如果2个中不全是岛屿,则不合并//需要注意的地方,写忘记了, debug才查出问题if (size[parentIndex1] == 0 || size[parentIndex2] == 0) {return;}//根节点int rootIndex1 = findRoot(parentIndex1);int rootIndex2 = findRoot(parentIndex2);//根节点不同,则合并if (rootIndex1 != rootIndex2) {//将小的挂在大的下面if (size[rootIndex1] >= size[rootIndex2]) {parents[rootIndex2] = rootIndex1;size[rootIndex1] = size[rootIndex1] + size[rootIndex2];}else {parents[rootIndex1] = rootIndex2;size[rootIndex2] = size[rootIndex1] + size[rootIndex2];}sets--;}}public int index (int r, int c) {return r * col + c;}public int findRoot (int index){int rootIndex = 0;//并查集之前合并过while (index != parents[index]) {//记录下每一次找到的上层节点(父节点)helps[rootIndex] = parents[index];//当前地址指向上层节点(父节点)index = parents[index];rootIndex++;}//路径压缩for (rootIndex--; rootIndex > 0; rootIndex--) {//返回原始收集的上层节点地址下标int t = helps[rootIndex];//根据下标,更新到根节点地址,//这样所以的地址都指向了根点处,优化了性能parents[t] = index;}return index;}}public static void main(String[] args) {int m = 3;int n = 3;int[][] positions = {{0,0},{0,1},{1,2},{2,1}};Code03_NunbOfLandsII tt = new Code03_NunbOfLandsII();List list = tt.numIslands(3, 3, positions);for(int i = 0; i < list.size(); i++) {System.out.println("第 " + (i+1) + " 次空降,岛屿数量为: " + list.get(i));}}
}
相关文章:
算法24:LeetCode_并查集相关算法
目录 题目一:力扣547题,求省份数量 题目二:岛屿数量 题目三:岛屿数量拓展 什么是并查集,举个简单的例子。学生考试通常会以60分为及格分数,我们将60分及以上的人归类为及格学生,而60分以下归…...

TypeScript核心知识点
TypeScript 核心 类型注解 知道:TypeScript 类型注解 示例代码: // 约定变量 age 的类型为 number 类型 let age: number 18 age 19: number 就是类型注解,它为变量提供类型约束。约定了什么类型,就只能给该变量赋值什么类型的…...

基于“遥感+”融合技术在碳储量、碳收支、碳循环等多领域监测与模拟实践
以全球变暖为主要特征的气候变化已成为全球性环境问题,对全球可持续发展带来严峻挑战。2015年多国在《巴黎协定》上明确提出缔约方应尽快实现碳达峰和碳中和目标。2019年第49届 IPCC全会明确增加了基于卫星遥感的排放清单校验方法。随着碳中和目标以及全球碳盘点的现…...
外卖点餐系统小程序 PHP+UniAPP
一、介绍 本项目是给某大学餐厅开发的外面点餐系统,该项目针对校内的学生,配送由学校的学生负责配送。因此,该项目不同于互联网的外卖点餐系统。 该系统支持属于 Saas 系统,由平台端、商家端、用户端、以及配送端组成。 其中&a…...

vuex3的介绍与state、actions和mutations的使用
一、定义官网:Vuex 是什么? | Vuex (vuejs.org)Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。二、安装cdn<script src"/path/…...

windows 自带端口转发
使用Portproxy模式下的Netsh命令即能实现Windows系统中的端口转发,转发命令如下: netsh interface portproxy add v4tov4 listenaddress[localaddress] listenport[localport] connectaddress[destaddress]listenaddress – 等待连接的本地ip地址 listenport – 本…...

【算法】算法基础入门详解:轻松理解和运用基础算法
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!Ǵ…...
2.9.1 Packet Tracer - Basic Switch and End Device Configuration(作业)
Packet Tracer - 交换机和终端设备的基本 配置地址分配表目标使用命令行界面 (CLI),在两台思科互联网络 操作系统 (IOS) 交换机上配置主机名和 IP 地址。使用思科 IOS 命令指定或限制对设备 配置的访问。使用 IOS 命令来保存当前的运行配置。配置两台主机设备的 IP …...
)
AtCoder Beginner Contest 216(F)
F - Max Sum Counting 链接: F - Max Sum Counting 题意 两个 大小为 nnn 的序列 aiaiai 和 bibibi,任意选取一些下标 iii,求 max(ai)>∑bi\max(ai) > \sum{bi}max(ai)>∑bi的方案数。 解析 首先考虑状态 一是和,…...

每天学一点之Stream流相关操作
StreamAPI 一、Stream特点 Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,负责存储数据,Stream流讲的是计算,负责处理数据!” 注意: ①Str…...

MatCap模拟光照效果实现
大家好,我是阿赵 之前介绍过各种光照模型的实现方法。那些光照模型的实现虽然有算法上的不同,但基本上都是灯光方向和法线方向的计算得出的明暗结果。 下面介绍一种叫做MatCap的模拟光照效果,这种方式计算非常简单,脱离灯光的计算…...

二十一、PG管理
一、 PG异常状态说明 1、 PG状态介绍 可以通过ceph pg stat命令查看PG当前状态,健康状态为“active clean” [rootrbd01 ~]# ceph pg stat 192 pgs: 192 activeclean; 1.3 KiB data, 64 MiB used, 114 GiB / 120 GiB avail; 85 B/s rd, 0 op/s2、pg常见状态 状…...

SAPUI5开发01_01-Installing Eclipse
1.0 简要要求概述: 本节您将安装SAPUI 5,以及如何在Eclipse Juno中集成SAPUI 5工具。 1.1 安装JDK JDK 是一种用于构建在 Java 平台上发布的应用程序、Applet 和组件的开发环境,即编写 Java 程序必须使用 JDK,它提供了编译和运行 Java 程序的环境。 在安装 JDK 之前,首…...
Qt之高仿QQ系统设置界面
QQ或360安全卫士的设置界面都是非常有特点的,所有的配置项都在一个垂直的ScrollArea中,但是又能通过左侧的导航栏点击定位。这样做的好处是既方便查看指定配置项,又方便查看所有配置项。 一.效果 下面左边是当前最新版QQ的系统设置界面,右边是我的高仿版本,几乎一毛一样…...

JVM概览:内存空间与数据存储
核心的五个部分虚拟机栈:局部变量中基础类型数据、对象的引用存储的位置,线程独立的。堆:大量运行时对象都在这个区域存储,线程共享的。方法区:存储运行时代码、类变量、常量池、构造器等信息,线程共享。程…...
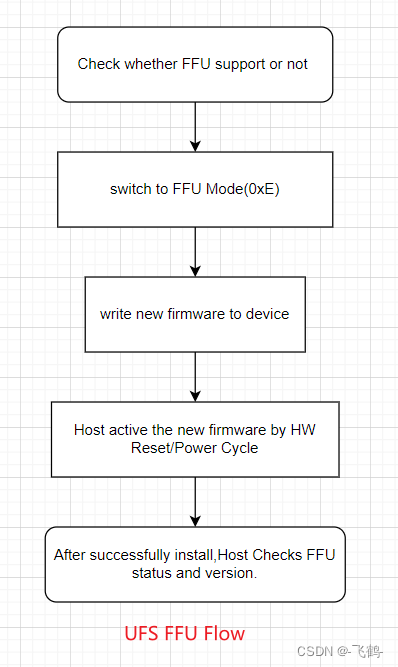
固态存储设备固件升级方案
1. 前言 随着数字化时代的发展,数字数据的量越来越大,相应的数据存储的需求也越来越大,存储设备产业也是蓬勃发展。存储设备产业中,发展最为迅猛的则是固态存储(Solid State Storage,SSS)。数字化时代,海量…...
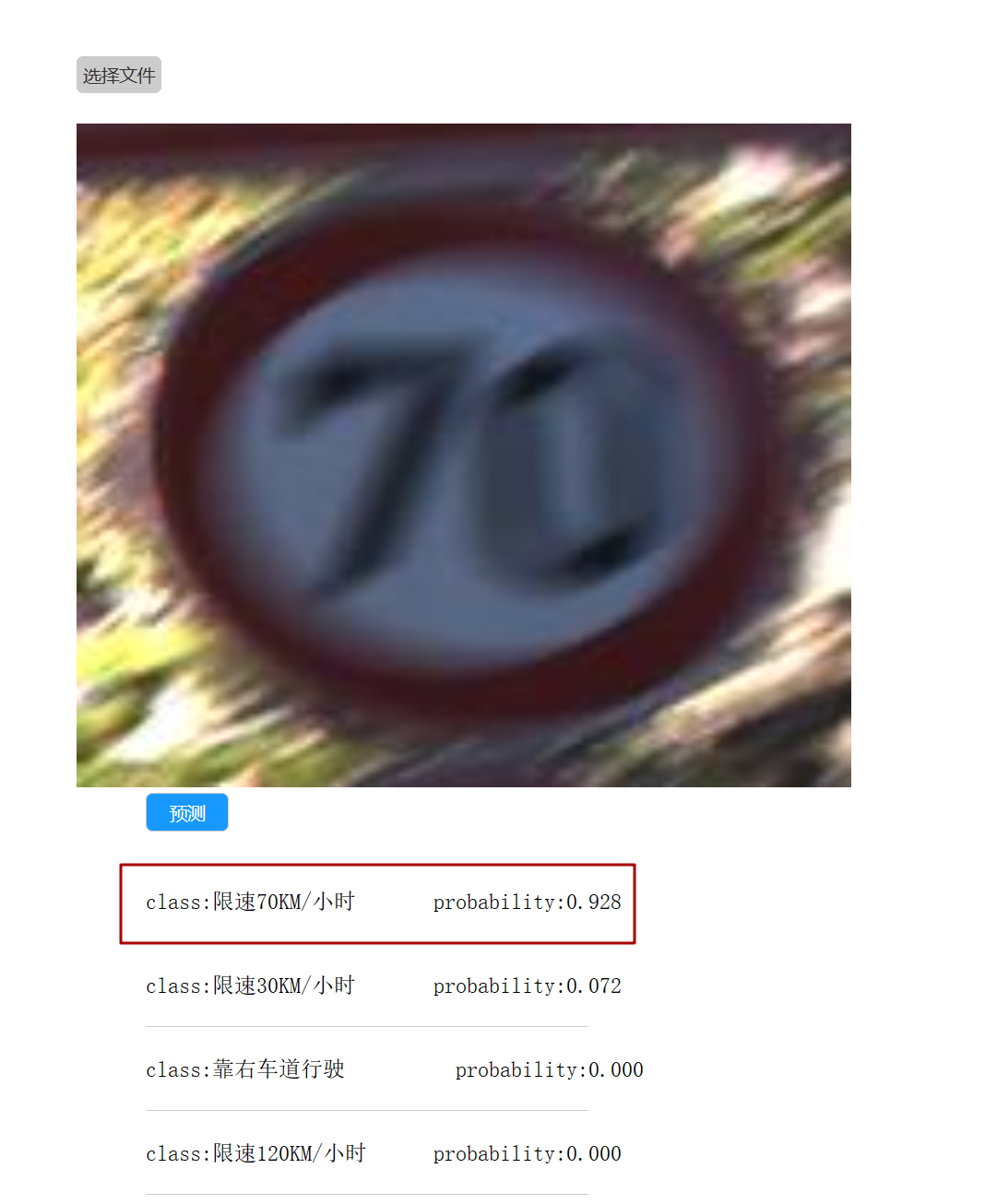
Python交通标志识别基于卷积神经网络的保姆级教程(Tensorflow)
项目介绍 TensorFlow2.X 搭建卷积神经网络(CNN),实现交通标志识别。搭建的卷积神经网络是类似VGG的结构(卷积层与池化层反复堆叠,然后经过全连接层,最后用softmax映射为每个类别的概率,概率最大的即为识别…...

基于Selenium+Python的web自动化测试框架(附框架源码+项目实战)
目录 一、什么是Selenium? 二、自动化测试框架 三、自动化框架的设计和实现 四、需要改进的模块 五、总结 总结感谢每一个认真阅读我文章的人!!! 重点:配套学习资料和视频教学 一、什么是Selenium? …...

Python进阶-----高阶函数zip() 函数
目录 前言: zip() 函数简介 运作过程: 应用实例 1.有序序列结合 2.无序序列结合 3.长度不统一的情况 前言: 家人们,看到标题应该都不陌生了吧,我们都知道压缩包文件的后缀就是zip的,当然还有r…...

win10打印机拒绝访问解决方法
一直以来,在安装使用共享打印机打印一些文件的时候,会遇到错误提示:“无法访问.你可能没有权限使用网络资源。请与这台服务器的管理员联系”的问题,那为什么共享打印机拒绝访问呢?别着急,下面为大家带来相关的解决方法…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...