【Kafka】记录一次基于connect-mirror-maker做的Kafka集群迁移完整过程
文章目录
- 背景
- 环境
- 工具选型
- 实操
- MM1
- MM2
- 以MM2集群运行
- 以Standalone模式运行
- 验证
- 附录
- MM2配置表
- 其他
背景
一个测试环境的kafka集群,Topic有360+,Partition有2000+,部署在虚拟机上,由于多方面原因,要求迁移至k8s容器内(全量迁移),正好可以拿来练一下手。本文主要记录对MM1和MM2的实际操作过程,以及使用过程中遇到的问题及解决方案。
环境
source集群:kafka-2.6.0、2个broker、虚拟机
target集群:kafka-2.6.0、3个broker、k8s
工具:MM1(kafka-mirror-maker.sh)、MM2(connect-mirror-maker.sh)
需求:Topic名称不能改变、数据完整
条件:target集群需要开启自动创建Topic:auto.create.topics.enable=true
工具选型
本质上MM1是Kafka的消费者和生产者结合体,可以有效地将数据从源群集移动到目标群集,但没有提供太多其他功能。
并且在MM1多年的使用过程中发现了以下局限性:
- 静态的黑名单和白名单
- Topic信息不能同步,所有Topic同步到目标端都只有一个Partition
- 必须通过手动配置来解决active-active场景下的循环同步问题(MM2为解决这个问题,也做了体验很不好的改动)
- rebalance导致的性能问题
- 缺乏监控手段
- 无法保证Exactly Once
- 无法提供容灾恢复
- 无法同步Topic列表,只能同步有数据的Topic
MM2是基于kafka connect框架开发的。与其它的kafka connecet一样MM2有source connector和sink connetor组成,可以支持同步以下数据:
- 完整的Topic列表
- Topic配置
- ACL信息(如果有)
- consumer group和offset(kafka2.7.0之后版本才行)
- 其他功能:
- 支持循环同步检测
- 多集群自定义同步(同一个任务中,可以多集群同步:A->B、B->C、B->D)
- 提供可监控Metrics
- 可通过配置保证Exactly Once
- …
实操
秉着实操前先演练的原则,我自己搭建了一个和目标集群相同配置的集群,用于验证不同工具的操作结果。有足够把握之后,再对目标集群实际操作。
MM1
执行 --help 查看参数选项:
[root@XXGL-T-TJSYZ-REDIS-03 bin]# ./kafka-mirror-maker.sh --help
This tool helps to continuously copy data between two Kafka clusters.
Option Description
------ -----------
--abort.on.send.failure <String: Stop Configure the mirror maker to exit onthe entire mirror maker when a send a failed send. (default: true)failure occurs>
--consumer.config <String: config file> Embedded consumer config for consumingfrom the source cluster.
--consumer.rebalance.listener <String: The consumer rebalance listener to useA custom rebalance listener of type for mirror maker consumer.ConsumerRebalanceListener>
--help Print usage information.
--message.handler <String: A custom Message handler which will processmessage handler of type every record in-between consumer andMirrorMakerMessageHandler> producer.
--message.handler.args <String: Arguments used by custom messageArguments passed to message handler handler for mirror maker.constructor.>
--new.consumer DEPRECATED Use new consumer in mirrormaker (this is the default so thisoption will be removed in a futureversion).
--num.streams <Integer: Number of Number of consumption streams.threads> (default: 1)
--offset.commit.interval.ms <Integer: Offset commit interval in ms.offset commit interval in (default: 60000)millisecond>
--producer.config <String: config file> Embedded producer config.
--rebalance.listener.args <String: Arguments used by custom rebalanceArguments passed to custom rebalance listener for mirror maker consumer.listener constructor as a string.>
--version Display Kafka version.
--whitelist <String: Java regex Whitelist of topics to mirror.(String)>
[root@XXGL-T-TJSYZ-REDIS-03 bin]#
核心参数就两个:消费者和生产者的配置文件:
consumer.properties:(消费source集群)
bootstrap.servers=source:9092
auto.offset.reset=earliest
partition.assignment.strategy=org.apache.kafka.clients.consumer.RoundRobinAssignor
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
group.id=mm1-consumer
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-pwd";
producer.properties:(发送消息至目标集群)
bootstrap.servers= target:29092
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="Admin" password="hMOPbmZE";
acks=-1
linger.ms=10
batch.size=10000
retries=3
执行脚本:
./kafka-mirror-maker.sh --consumer.config ./consumer.properties --producer.config ./producer.properties --offset.commit.interval.ms 5000 --num.streams 2 --whitelist "projects.*"
MM1比较简单,只要两个配置文件没问题,sasl配置正确,基本就OK了,适合简单的数据同步,比如指定topic进行同步。
MM2
有四种运行MM2的方法:
- As a dedicated MirrorMaker cluster.(作为专用的MirrorMaker群集)
- As a Connector in a distributed Connect cluster.(作为分布式Connect群集中的连接器)
- As a standalone Connect worker.(作为独立的Connect工作者)
- In legacy mode using existing MirrorMaker scripts.(在旧模式下,使用现有的MirrorMaker脚本。)
本文介绍第一种和第三种:作为专用的MirrorMaker群集、作为独立的Connect工作者,第二种需要搭建connect集群,操作比较复杂。
以MM2集群运行
这种模式是最简单的,只需要提供一个配置文件即可,配置文件定制化程度比较高,根据业务需求配置即可
老样子,执行 --help 看看使用说明:
[root@XXGL-T-TJSYZ-REDIS-03 bin]# ./connect-mirror-maker.sh --help
usage: connect-mirror-maker [-h] [--clusters CLUSTER [CLUSTER ...]] mm2.propertiesMirrorMaker 2.0 driverpositional arguments:mm2.properties MM2 configuration file.optional arguments:-h, --help show this help message and exit--clusters CLUSTER [CLUSTER ...]Target cluster to use for this node.
[root@XXGL-T-TJSYZ-REDIS-03 bin]#
可以看到,参数简单了许多,核心参数就一个配置文件。
mm2.properties:
name = event-center-connector
connector.class = org.apache.kafka.connect.mirror.MirrorSourceConnector
tasks.max = 2# 定义集群别名
clusters = event-center, event-center-new# 设置event-center集群的kafka地址列表
event-center.bootstrap.servers = source:9193
event-center.security.protocol=SASL_PLAINTEXT
event-center.sasl.mechanism=PLAIN
event-center.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-pwd";
# 设置event-center-new集群的kafka地址列表
event-center-new.bootstrap.servers = target:29092
event-center-new.security.protocol=SASL_PLAINTEXT
event-center-new.sasl.mechanism=PLAIN
event-center-new.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-pwd";
# 开启event-center集群向event-center-new集群同步
event-center->event-center-new.enabled = true
# 允许同步topic的正则
event-center->event-center-new.topics = projects.*
event-center->event-center-new.groups = .*# MM2内部同步机制使用的topic,replication数量设置
checkpoints.topic.replication.factor=1
heartbeats.topic.replication.factor=1
offset-syncs.topic.replication.factor=1
offset.storage.replication.factor=1
status.storage.replication.factor=1
config.storage.replication.factor=1# 自定义参数
# 是否同步源topic配置
sync.topic.configs.enabled=true
# 是否同步源event-centerCL信息
sync.topic.acls.enabled=true
sync.group.offsets.enabled=true
# 连接器是否发送心跳
emit.heartbeats.enabled=true
# 心跳间隔
emit.heartbeats.interval.seconds=5
# 是否发送检查点
emit.checkpoints.enabled=true
# 是否刷新topic列表
refresh.topics.enabled=true
# 刷新间隔
refresh.topics.interval.seconds=60
# 是否刷新消费者组id
refresh.groups.enabled=true
# 刷新间隔
refresh.groups.interval.seconds=60
# DefaultReplicationPolicy / CustomReplicationPolicy
replication.policy.class=org.apache.kafka.connect.mirror.CustomReplicationPolicy
# 远端创建新topic的replication数量设置
replication.factor=3
需要注意的是:replication.policy.class 默认为:DefaultReplicationPolicy,这个策略会把同步至目标集群的topic都加上一个源集群别名的前缀,比如源集群别名为A,topic为:bi-log,该topic同步到目标集群后会变成:A.bi-log,为啥这么做呢,就是为了避免双向同步的场景出现死循环。
官方也给出了解释:
这是 MirrorMaker 2.0 中的默认行为,以避免在复杂的镜像拓扑中重写数据。 需要在复制流设计和主题管理方面小心自定义此项,以避免数据丢失。 可以通过对“replication.policy.class”使用自定义复制策略类来完成此操作。
针对如何自定义策略及使用方法,见我的另一篇文章:
为了保证脚本后台运行,写一个脚本包装一下:
run-mm2.sh:
#!/bin/bashexec ./connect-mirror-maker.sh MM2.properties >log/mm2.log 2>&1 &
之后执行脚本即可。
以Standalone模式运行
这种模式会麻烦点,需要提供一个kafka,作为worker节点来同步数据,使用的脚本为:connect-standalone.sh
–help看看如何使用:
./connect-standalone.sh --help
[2023-03-09 20:36:33,479] INFO Usage: ConnectStandalone worker.properties connector1.properties [connector2.properties ...] (org.apache.kafka.connect.cli.ConnectStandalone:63)
[root@XXGL-T-TJSYZ-REDIS-03 bin]#
需要两个配置文件,一个是作为worker的kafka集群信息(worker.properties),另一个是同步数据的配置(connector.properties)
worker.properties:
bootstrap.servers=worker:29092
security.protocol=PLAINTEXT
sasl.mechanism=PLAINkey.converter = org.apache.kafka.connect.converters.ByteArrayConverter
value.converter = org.apache.kafka.connect.converters.ByteArrayConverteroffset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
connector.properties:
name = MirrorSourceConnector
topics = projects.*
groups = *
connector.class = org.apache.kafka.connect.mirror.MirrorSourceConnector
tasks.max = 1# source
# 这个配置会使同步之后的Topic都加上一个前缀,慎重
source.cluster.alias = old
source.cluster.bootstrap.servers = source:9193
source.cluster.security.protocol=SASL_PLAINTEXT
source.cluster.sasl.mechanism=PLAIN
source.cluster.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-pwd";
# target
target.cluster.alias = new
target.cluster.bootstrap.servers = target:29092
target.cluster.security.protocol=SASL_PLAINTEXT
target.cluster.sasl.mechanism=PLAIN
target.cluster.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="Admin" password="hMOPbmZE";# 是否同步源topic配置信息
sync.topic.configs.enabled=true
# 是否同步源ACL信息
sync.topic.acls.enabled=true
sync.group.offsets.enabled=true
# 连接器是否发送心跳
emit.heartbeats.enabled=true
# 心跳间隔
emit.heartbeats.interval.seconds=5
# 是否发送检查点
emit.checkpoints.enabled=true
# 是否刷新topic列表
refresh.topics.enabled=true
# 刷新间隔
refresh.topics.interval.seconds=30
# 是否刷新消费者组id
refresh.groups.enabled=true
# 刷新间隔
refresh.groups.interval.seconds=30
# 连接器消费者预读队列大小
# readahead.queue.capacity=500
# 使用自定义策略
replication.policy.class=org.apache.kafka.connect.mirror.CustomReplicationPolicy
replication.factor = 3
执行:
./connect-standalone.sh worker.properties connector.properties
这种方式做一个简单的介绍,我最后采用的是上一种方式,比较简单直接
验证
验证:
-
消息数量 OK
使用kafka-tool工具连接上两个集群进行比对
-
Topic数量 OK
- source:
./kafka-topics.sh --bootstrap-server source:9193 --command-config command.properties --list > topics-source.txt- sink
./kafka-topics.sh --bootstrap-server sink:29092 --command-config command.properties --list > topics-sink.txt- command.properties示例:
security.protocol = SASL_PLAINTEXT sasl.mechanism = PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="admin" password="admin-pwd"; -
新消息是否同步 OK
-
新Topic是否同步 OK
-
Consumer是否同步 NO
./kafka-consumer-groups.sh --bootstrap-server source:9193 --command-config command.properties --list > consumer-source.txt
如果需要同步consumer,需要使用官方提供的工具:RemoteClusterUtils
-
consumer offset是否同步 NO
-
ACL是否同步 OK
通过kafka-acls.sh或者客户端工具kafka-tool可以查看
附录
MM2配置表
| property | default value | description |
|---|---|---|
| name | required | name of the connector, e.g. “us-west->us-east” |
| topics | empty string | regex of topics to replicate, e.g. “topic1|topic2|topic3”. Comma-separated lists are also supported. |
| topics.blacklist | “..internal, ..replica, __consumer_offsets” or similar | topics to exclude from replication |
| groups | empty string | regex of groups to replicate, e.g. “.*” |
| groups.blacklist | empty string | groups to exclude from replication |
| source.cluster.alias | required | name of the cluster being replicated |
| target.cluster.alias | required | name of the downstream Kafka cluster |
| source.cluster.bootstrap.servers | required | upstream cluster to replicate |
| target.cluster.bootstrap.servers | required | downstream cluster |
| sync.topic.configs.enabled | true | whether or not to monitor source cluster for configuration changes |
| sync.topic.acls.enabled | true | whether to monitor source cluster ACLs for changes |
| emit.heartbeats.enabled | true | connector should periodically emit heartbeats |
| emit.heartbeats.interval.seconds | 5 (seconds) | frequency of heartbeats |
| emit.checkpoints.enabled | true | connector should periodically emit consumer offset information |
| emit.checkpoints.interval.seconds | 5 (seconds) | frequency of checkpoints |
| refresh.topics.enabled | true | connector should periodically check for new topics |
| refresh.topics.interval.seconds | 5 (seconds) | frequency to check source cluster for new topics |
| refresh.groups.enabled | true | connector should periodically check for new consumer groups |
| refresh.groups.interval.seconds | 5 (seconds) | frequency to check source cluster for new consumer groups |
| readahead.queue.capacity | 500 (records) | number of records to let consumer get ahead of producer |
| replication.policy.class | org.apache.kafka.connect.mirror.DefaultReplicationPolicy | use LegacyReplicationPolicy to mimic legacy MirrorMaker |
| heartbeats.topic.retention.ms | 1 day | used when creating heartbeat topics for the first time |
| checkpoints.topic.retention.ms | 1 day | used when creating checkpoint topics for the first time |
| offset.syncs.topic.retention.ms | max long | used when creating offset sync topic for the first time |
| replication.factor | 2 | used when creating remote topics |
其他
参考:
https://cwiki.apache.org/confluence/display/KAFKA/KIP-382%253A+MirrorMaker+2.0
https://www.reddit.com/r/apachekafka/comments/q5s3al/mirrormaker2_is_not_able_to_replicate_groups_in/?sort=new
https://dev.to/keigodasu/transferring-commit-offset-with-mirrormaker-2-3kbf
https://learn.microsoft.com/zh-cn/azure/hdinsight/kafka/kafka-mirrormaker-2-0-guide
相关文章:

【Kafka】记录一次基于connect-mirror-maker做的Kafka集群迁移完整过程
文章目录背景环境工具选型实操MM1MM2以MM2集群运行以Standalone模式运行验证附录MM2配置表其他背景 一个测试环境的kafka集群,Topic有360,Partition有2000,部署在虚拟机上,由于多方面原因,要求迁移至k8s容器内&#x…...

实现VOC数据集与COCO数据集格式转换
实现VOC数据集与COCO数据集格式转换2、将voc数据集的xml转化为coco数据集的json格式2、COCO格式的json文件转化为VOC格式的xml文件3、将 txt 文件转换为 Pascal VOC 的 XML 格式<annotation><folder>文件夹目录</folder><filename>图片名.jpg</file…...

常用的密码算法有哪些?
我们将密码算法分为两大类。 对称密码(密钥密码)——算法只有一个密钥。如果多个参与者都知道该密钥,该密钥 也称为共享密钥。非对称密码(公钥密码)——参与者对密钥的可见性是非对称的。例如,一些参与者仅…...
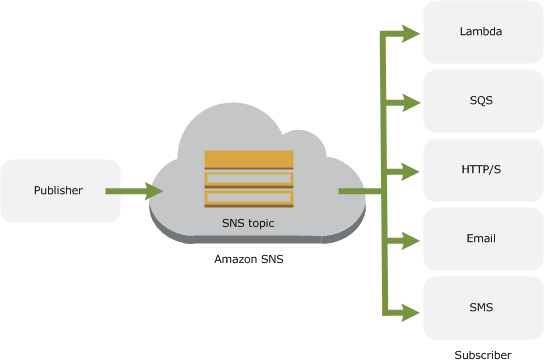
SNS (Simple Notification Service)简介
SNS (Simple Notification Service) 是一种完全托管的发布/订阅消息收发和移动通知服务,用于协调向订阅终端节点和客户端的消息分发。 和SQS (Simple Queue Service)一样,SNS也可以轻松分离和扩展微服务,分布式系统和无服务应用程序…...

JVM初步理解浅析
一、JVM的位置 JVM的位置 JVM在操作系统的上一层,是运行在操作系统上的。JRE是运行环境,而JVM是包含在JRE中 二、JVM体系结构 垃圾回收主要在方法区和堆,所以”JVM调优“大部分也是发生在方法区和堆中 可以说调优就是发生在堆中…...

【巨人的肩膀】MySQL面试总结(一)
💪 目录💪1、什么是ER图2、数据库范式了解吗3、超键、候选键、主键、外键分别是什么?4、为什么不推荐使用外键与级联5、什么是存储过程6、drop、delete与truncate区别7、数据库设计通常分为那几步8、什么是关系型数据库9、什么是SQL10、MySQL…...
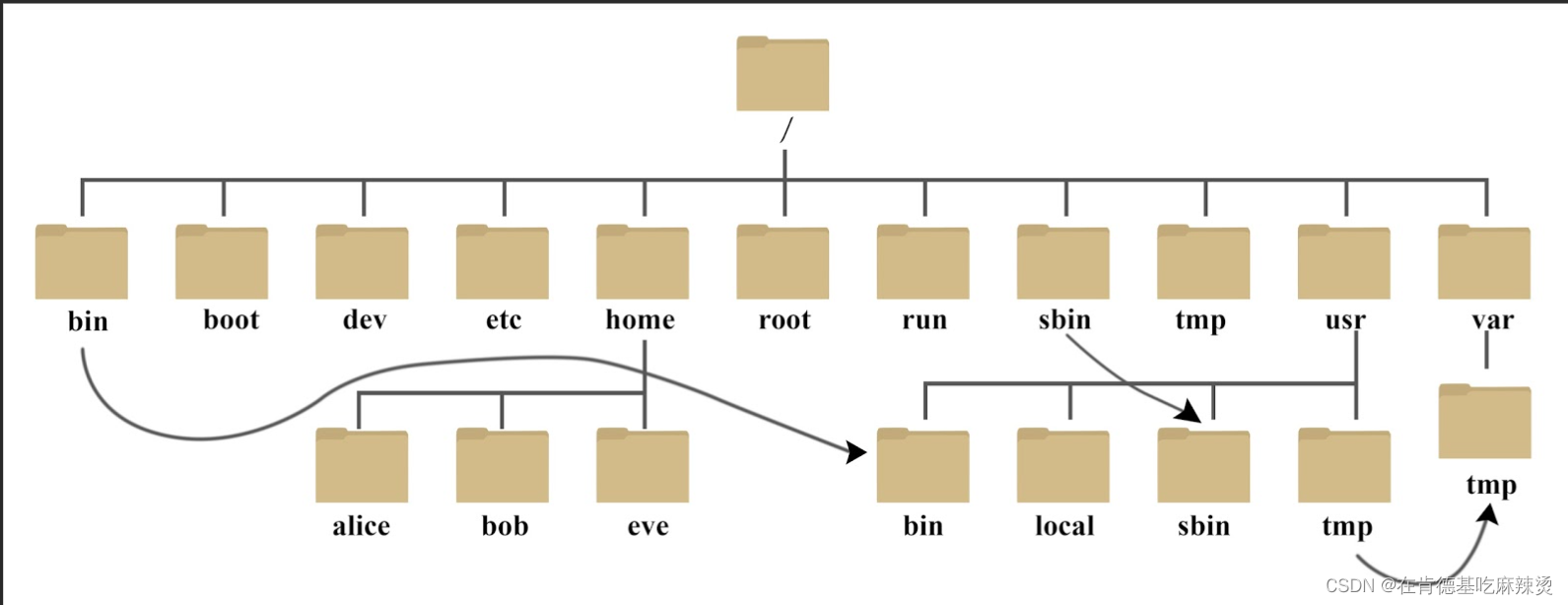
【数据结构之树】——什么是树,树的特点,树的相关概念和表示方法以及在实际的应用。
文章目录一、1.树是什么?2.树的特点二、树的相关概念三、树的表示方法1.常规方法表示树2.使用左孩子右兄弟表示法3. 使用顺序表来存储父亲节点的下标三、树在实际的应用总结一、1.树是什么? 树是一种非线性的数据结构,它是由n(n&…...
JavaScript语法
文章目录一、JavaScript是什么?JavaScript引入方式二、基础语法书写语法输出语句变量数据类型运算符流程控制语句数组函数JS变量作用域对象一、JavaScript是什么? JavaScript:是一门跨平台的脚本语言,用来控制网页行为࿰…...

【BIOS/UEFI】HII 基本框架及概述
HII(Human Interface Infrastructure )定义了一套管理用户输入的基础框架。HII数据库主要提供用户安装、卸载以及使用各种字符串、字体和图片等资源的接口。 HID Devices 是用户输入设备,如键盘、串口和网络;Display Devices 是输…...
溢出边界导致程序崩溃的问题)
sprintf(...)溢出边界导致程序崩溃的问题
文章目录小结问题及解决参考小结 使用sprintf(...)进行格式化是一种标准的做法,但是这样做是有一个极大的风险,由于sprintf(...)不进行边界检查,这样会有写操作溢出边界的风险,并导致程序崩溃。本文进行了简单写操作溢出边界的测…...

公式推导+dfs简版
写在前面的话:心可以冷,但手不能停 第一题:C. Flexible String 题目大意:给一个aaa字符串和bbb字符串和数字kkk,首先设置一个计数器cntcntcnt,其中可以对aaa字符串做以下操作:替换aaa中的一个字母xxx&#…...

论文笔记 | 标准误聚类问题
关于标准误的选择,如是否选择稳健性标准误、是否采取聚类标准误。之前一直是困惑的,惯用的做法是类似主题的文献做法。所以这一次,借计量经济学课程之故,较深入学习了标准误的选择问题。 在开始之前推荐一个知乎博主。他阅读了很…...
银行管理系统--课后程序(Python程序开发案例教程-黑马程序员编著-第7章-课后作业)
实例1:银行管理系统 从早期的钱庄到现如今的银行,金融行业在不断地变革;随着科技的发展、计算机的普及,计算机技术在金融行业得到了广泛的应用。银行管理系统是一个集开户、查询、取款、存款、转账、锁定、解锁、退出等一系列的功…...
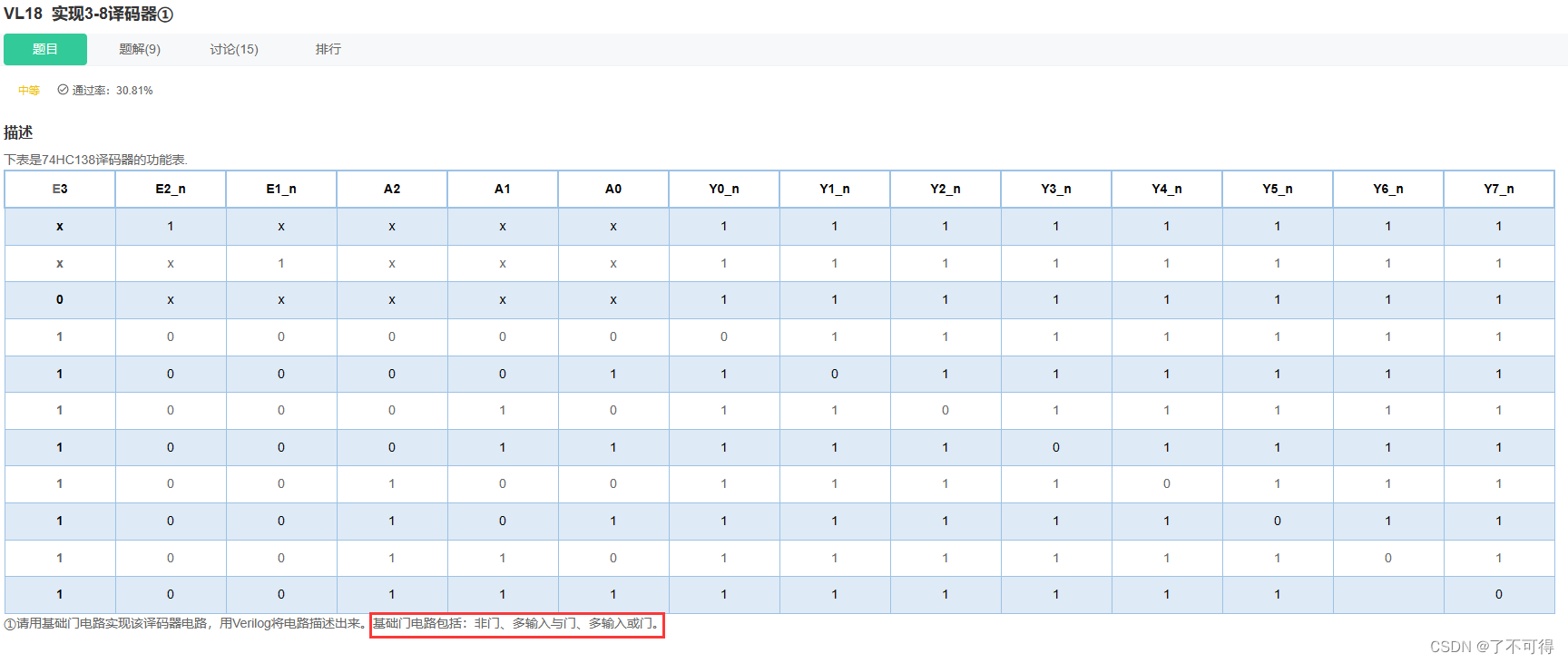
【18】组合逻辑 - VL18 实现3-8译码器①
VL18 实现3-8译码器① 1 题目 【这题我的思路非常绝境】奈斯 !! 看真值表的思路:Yi所在列【0仅一个其余全1】,故【以0为对象求解】 观察发现:E3 E2_n E1_n = 100 时 是 译码的使能信号 ; 并且E3 E2_n E1_n为其他值时,都不使能译码 然后就很简单,没有仿真就成功了 2 代…...

2020蓝桥杯真题最长递增 C语言/C++
题目描述 在数列a_1 ,a_2,⋯,a_n 中,如果a_i <a_i1 <a_i2<⋯<a_j,则称 a_i至 a_j为一段递增序列,长度为 j−i1。 定一个数列,请问数列中最长的递增序列有多长。 输入描述 输入的第一行包含一个整数 n。 第二行包含…...
| 机考必刷)
华为OD机试题 - 寻找连续区间(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:寻找连续区间题目输入输出示例一输入输出说明示例二输入输出Cod…...

一次疲惫的调试--累了及时透气
原创 射频清茶 深山小老虎 2023-03-11 14:32发表于广东 收录于合集 #射频调试3个 #网分4个 #Wi-Fi 2个 进来透透气 道不尽红尘舍恋 诉不完人间恩怨 世世代代都是缘 喝着相同的水 留着相同的血 这条路漫漫又长远 红花当然配绿叶 这一辈子谁来陪 渺渺茫茫来又回 往日情景再…...
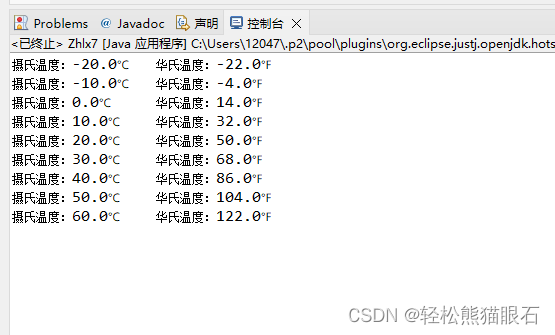
综合练习7 摄氏度转华氏温度(“\t“的使用,循环语句)
综合练习7 摄氏度转华氏温度 使用do…while循环,在控制台输入摄氏温度与华氏温度的对照表。 对照表从摄氏温度-30℃到50℃,每行间隔10℃,运行如下: 摄氏温度:-30℃ 华氏温度:-22.0℉ 摄氏温度:…...

AWS数据库总结
RDS – 联机事务处理OLTP(Online Transaction Processing),包括: SQL ServerOracleMySQL ServerPostgreSQLAuroraMariaDB非关系数据库DynamoDB数据仓库RedShift – 联机分析处理OLAP(Online Analytics Processing&…...
2个步骤就能批量给视频添加滚动字幕
现在很多小伙伴在剪辑视频的时候都会给自己的视频添加适配的字幕,但是有很多的视频想要添加一样的滚动字幕时,有一个能批量添加剪辑的工具非常重要,今天小编就给大家分享一个可以批量剪辑大量视频的工具,下面一起看看具体的操作步…...

ELClient:基于SLIP的ESP8266嵌入式Wi-Fi中间件
1. ELClient 库概述 ELClient 是一个面向嵌入式平台的轻量级 Wi-Fi 通信中间件,专为集成 ESP8266 SoC(System-on-Chip)而设计。其核心定位并非直接操作 ESP8266 的 AT 指令集,而是通过串行链路(UART)承载 S…...

嵌入式系统字节对齐原理与结构体内存布局实战
1. 字节对齐:嵌入式系统中不可忽视的内存布局规则在嵌入式开发实践中,字节对齐(Byte Alignment)并非仅关乎编译器优化的理论概念,而是直接影响硬件寄存器访问正确性、跨平台通信可靠性及系统稳定性的底层机制。本文基于…...

51单片机为何采用5V供电:TTL电平兼容与系统设计原理
1. 51单片机为何采用5V供电:从电平标准到系统设计的工程溯源 1.1 TTL电平标准的历史根基 51单片机普遍采用5V供电并非偶然选择,而是根植于20世纪70年代数字集成电路发展的技术惯性。其核心动因在于TTL(Transistor-Transistor Logicÿ…...

【杰理AC632N】巧用CDC与SPP_AND_LE双模,实现USB虚拟串口与BLE透传的智能切换
1. 杰理AC632N双模通信方案概述 在物联网设备开发中,经常遇到需要同时支持有线与无线通信的场景。杰理AC632N芯片提供的CDC(通信设备类)与SPP_AND_LE(经典蓝牙串口与低功耗蓝牙双模)协议栈组合,正好能解决这…...

松下伺服A6驱动器与PANATERM ver.6.0的兼容性问题:从错误警告到成功运行的避坑指南
松下A6伺服驱动器与PANATERM 6.0兼容性实战指南 当你在调试松下A6系列伺服驱动器时,是否遇到过PANATERM 6.0软件突然弹出38.1警告,或是33.2、33.3这类看似莫名其妙的错误代码?作为自动化设备维护的老手,我深知这些兼容性问题可能让…...

如何快速获取国家中小学智慧教育平台电子课本:面向教师与学生的完整指南
如何快速获取国家中小学智慧教育平台电子课本:面向教师与学生的完整指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具 项目地址: https://gitcode.com/GitHub_Trending/tc/tchMaterial-parser 在数字化教育快速发展的今天&…...

从一根跳线看全反射:手把手图解光纤8度角研磨如何‘干掉’反射光
光纤端面8度角研磨:用物理魔法驯服反射光的技术艺术 想象一下,你正用吸管喝饮料时突然对着吸管吹气——液滴会逆流溅回脸上。光纤通信中,光信号也会遭遇类似的"回溅"问题,而工程师们用一道8度的斜面就优雅地解决了这个困…...

LibXSVF:嵌入式轻量级SVF/XSVF JTAG编程器
1. LibXSVF:面向嵌入式平台的轻量级SVF/XSVF JTAG编程器实现LibXSVF 是一个专为资源受限嵌入式系统设计的开源 JTAG 编程器核心库,其本质是 Clifford Wolf 开源项目 Lib(X)SVF 的精简适配分支。该库并非通用型 PC 端 JTAG 工具链(如 OpenOCD、…...

Youtu-Parsing教育AI助手:学生作业图片→文字+公式+图表全要素解析
Youtu-Parsing教育AI助手:学生作业图片→文字公式图表全要素解析 1. 引言:当AI遇见学生作业 想象一下这个场景:一位老师收到了50份学生提交的物理作业照片,每份作业都包含了手写的解题步骤、复杂的数学公式、手绘的电路图&#…...

STM32_HAL_RTC_中断实现精准定时任务
1. 为什么你需要RTC中断来做定时任务? 如果你在用STM32做项目,尤其是那种需要长时间运行、还得定时干点啥的设备,比如每隔一小时记录一次温湿度数据,或者每天凌晨准时把数据打包发到服务器,那你肯定对“定时”这个事特…...