Apache Kafka与Spring整合应用详解
引言
Apache Kafka是一种高吞吐量的分布式消息系统,广泛应用于实时数据处理、日志聚合和事件驱动架构中。Spring作为Java开发的主流框架,通过Spring Kafka项目提供了对Kafka的集成支持。本文将深入探讨如何使用Spring Kafka整合Apache Kafka,并通过详细的代码示例帮助新人理解和掌握这一技术。
环境准备
在开始之前,请确保你已经安装并配置好了以下环境:
- Apache Kafka集群
- Java JDK 8或更高版本
- Maven或Gradle构建工具
- Spring Boot 2.3.0或更高版本
项目依赖配置
首先,我们需要在pom.xml中添加Spring Kafka的依赖。
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
</dependencies>
Kafka配置
在Spring Boot应用中,我们需要在application.properties中配置Kafka的相关信息。
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=my-group
spring.kafka.consumer.auto-offset-reset=earliest
生产者配置与实现
生产者用于将消息发送到Kafka主题中。我们首先定义一个配置类来配置Kafka生产者。
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.support.serializer.JsonSerializer;import java.util.HashMap;
import java.util.Map;@Configuration
public class KafkaProducerConfig {@Beanpublic ProducerFactory<String, String> producerFactory() {Map<String, Object> configProps = new HashMap<>();configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);return new DefaultKafkaProducerFactory<>(configProps);}@Beanpublic KafkaTemplate<String, String> kafkaTemplate() {return new KafkaTemplate<>(producerFactory());}
}
接着,我们创建一个生产者服务类,用于发送消息。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;@Service
public class KafkaProducerService {private static final String TOPIC = "my_topic";@Autowiredprivate KafkaTemplate<String, String> kafkaTemplate;public void sendMessage(String message) {kafkaTemplate.send(TOPIC, message);}
}
消费者配置与实现
消费者用于从Kafka主题中读取消息。我们也需要定义一个配置类来配置Kafka消费者。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.support.serializer.ErrorHandlingDeserializer;
import org.springframework.kafka.support.serializer.JsonDeserializer;import java.util.HashMap;
import java.util.Map;@EnableKafka
@Configuration
public class KafkaConsumerConfig {@Beanpublic ConsumerFactory<String, String> consumerFactory() {Map<String, Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ConsumerConfig.GROUP_ID_CONFIG, "my-group");props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);return new DefaultKafkaConsumerFactory<>(props);}@Beanpublic ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(consumerFactory());return factory;}
}
接着,我们创建一个消费者服务类,用于接收消息。
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;@Service
public class KafkaConsumerService {@KafkaListener(topics = "my_topic", groupId = "my-group")public void consume(String message) {System.out.println("Consumed message: " + message);}
}
控制器实现
为了测试我们的Kafka生产者和消费者,我们可以创建一个简单的Spring Boot控制器。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
public class KafkaController {@Autowiredprivate KafkaProducerService producerService;@GetMapping("/send")public String sendMessage(@RequestParam("message") String message) {producerService.sendMessage(message);return "Message sent to Kafka topic: " + message;}
}
运行应用
启动Spring Boot应用,打开浏览器,访问http://localhost:8080/send?message=HelloKafka。你应该会看到控制台输出:
Consumed message: HelloKafka
总结
本文详细介绍了如何使用Spring Kafka整合Apache Kafka,包括项目依赖配置、Kafka配置、生产者与消费者的实现以及简单的测试控制器。通过这些示例代码,新人可以快速上手,并且深入理解Spring与Kafka的集成方式。希望本文对你有所帮助,祝你在Java开发的路上越来越顺利!
相关文章:

Apache Kafka与Spring整合应用详解
引言 Apache Kafka是一种高吞吐量的分布式消息系统,广泛应用于实时数据处理、日志聚合和事件驱动架构中。Spring作为Java开发的主流框架,通过Spring Kafka项目提供了对Kafka的集成支持。本文将深入探讨如何使用Spring Kafka整合Apache Kafka,…...
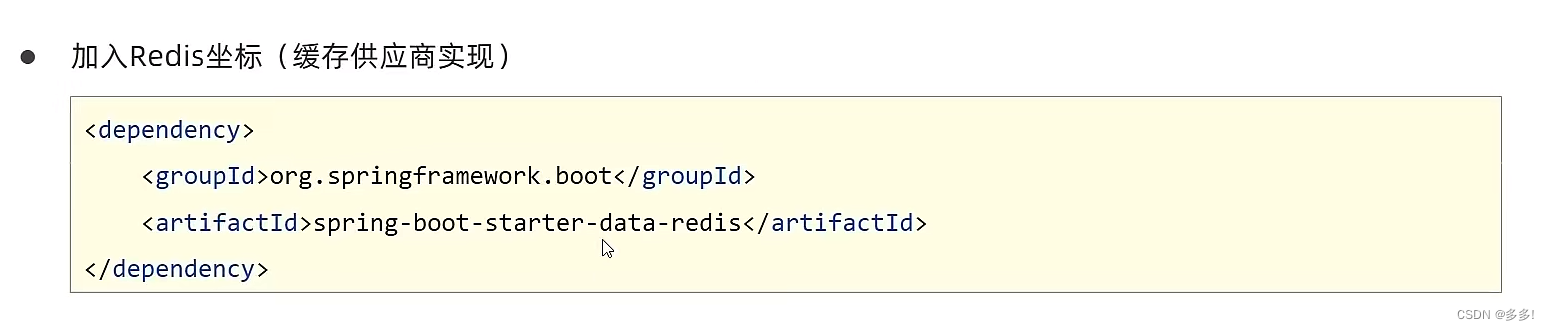
SpringBoot配置第三方专业缓存技术Redis
Redis缓存技术 Redis(Remote Dictionary Server)是一个开源的内存中数据结构存储系统,通常用作数据库、缓存和消息中间件。它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的功能和灵活的…...
以及使用)
javascript的toFixed()以及使用
toFixed() 是 JavaScript 中数字类型(Number)的一个方法,用来将数字转换为指定小数位数的字符串表示形式。 使用方式和示例: let num 123.45678; let fixedNum num.toFixed(2); console.log(fixedNum); // 输出 "123.46&qu…...

软件功能测试和性能测试包括哪些测试内容?又有什么联系和区别?
软件功能测试和性能测试是保证软件质量和稳定性的重要手,无论是验证软件的功能正确性,还是评估软件在负载下的性能表现,这些测试都是必不可少的。 一、软件功能测试 软件功能测试是指对软件的各项功能进行验证和确认,确保软件…...
从工具产品体验对比spark、hadoop、flink
作为一名大数据开发,从工具产品的角度,对比一下大数据工具最常使用的框架spark、hadoop和flink。工具无关好坏,但人的喜欢有偏好。 目录 评价标准1 效率2 用户体验分析从用户的维度来看从市场的维度来看从产品的维度来看 3 用户体验的基本原则…...

【软件设计】详细设计说明书(word原件,项目直接套用)
软件详细设计说明书 1.系统总体设计 2.性能设计 3.系统功能模块详细设计 4.数据库设计 5.接口设计 6.系统出错处理设计 7.系统处理规定 软件全套资料:本文末个人名片直接获取或者进主页。...
优缺点,以及适用场景)
java本地缓存(map,Guava,echcache,caffeine)优缺点,以及适用场景
前言 在高并发系统环境下,jvm本地缓存扮演着至关重要的角色,合理的应用能够使系统响应迅速,提高用户体验感,而分布式缓存redis则存在着网络io,以及流量消耗问题,需要和本地缓存搭配使用,才能使…...

Monica
在 《long long ago》中,我论述了on是一个刚出生的孩子的脐带连接在其肚子g上的形象,脐带就是long的字母l和字母n,l表脐带很长,n表脐带曲转冗余和连接之性,on表一,是孩子刚诞生的意思,o是身体&a…...

国产数据库中读写分离实现机制
在数据库高可用架构下会存在1主多备的部署,备节点可以根据业务场景分发一部分流量以充分利用资源,并减轻主库的压力,因此在数据库的功能上需要读写分离来实现。 充分利用备节点的资源,提升业务的吞吐量;防止运维等非业…...

kubernetes部署dashboard
kubernetes部署dashboard 1. 简介 Dashboard 是基于网页的 Kubernetes 用户界面。 你可以使用 Dashboard 将容器应用部署到 Kubernetes 集群中,也可以对容器应用排错,还能管理集群资源。 你可以使用 Dashboard 获取运行在集群中的应用的概览信息&#…...

FPGA早鸟课程第二弹 | Vivado 设计静态时序分析和实际约束
在FPGA设计领域,时序约束和静态时序分析是提升系统性能和稳定性的关键。社区推出的「Vivado 设计静态时序分析和实际约束」课程,旨在帮助工程师们掌握先进的设计技术,优化设计流程,提高开发效率。 课程介绍 关于课程 权威认证&…...

STM32项目分享:家庭环境监测系统
目录 一、前言 二、项目简介 1.功能详解 2.主要器件 三、原理图设计 四、PCB硬件设计 1.PCB图 2.PCB板打样焊接图 五、程序设计 六、实验效果 七、资料内容 项目分享 一、前言 项目成品图片: 哔哩哔哩视频链接: https://www.bilibili.…...

华为HCIP Datacom H12-821 卷5
1.单选题 下列哪种工具不能被 route-policy 的 apply 子句直接引用? A、IP-Prefix B、tag C、community D、origin 正确答案: A 解析: 因route-policy工具中, apply 后面跟的是路由的相关属性。 但是ip-prefix是用来匹配路由的工具。 2.单选题...

Mongodb数据库基本操作
本文为在命令行模式下Mongodb数据库的基本操作整理。 目录 数据库操作 创建数据库 查看所有数据 查看当前数据库 删除数据库 断开连接 查看命令api 集合操作 查看当前数据库下集合 创建集合 删除当前数据库中的集合 文档操作 插入文档 insertOne()方法 insertMa…...

【机器学习】基于Softmax松弛技术的离散数据采样
1.引言 1.1.离散数据采样的意义 离散数据采样在深度学习中起着至关重要的作用,它直接影响到模型的性能、泛化能力、训练效率、鲁棒性和解释性。 首先,采样方法能够有效地平衡数据集中不同类别的样本数量,使得模型在训练时能够更均衡地学习…...
.NET+Python量化【1】——环境部署和个人资金账户信息查询
前言:量化资料很少,.NET更少。那我就来开个先河吧~ 以下是使用QMT进行量化开发的环境部署和基础信息获取有关操作。 1、首先自己申请券商的QMT权限,此步骤省略。 2、登陆QMT,选择极简模式,或者独立交易模式之类的。会进…...

洛谷 P10584 [蓝桥杯 2024 国 A] 数学题(整除分块+杜教筛)
题目 思路来源 登录 - Luogu Spilopelia 题解 参考了两篇洛谷题解,第一篇能得出这个式子,第二篇有比较严格的复杂度分析 结合去年蓝桥杯洛谷P9238,基本就能得出这题的正确做法 代码 #include<bits/stdc.h> #include<iostream&g…...
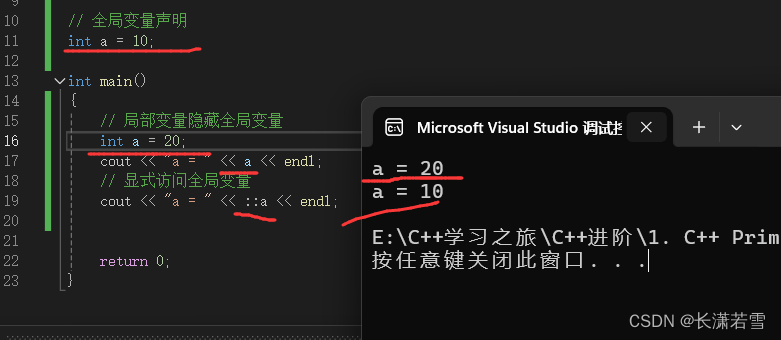
深入讲解C++基础知识(一)
目录 一、基本内置类型1. 类型的作用2. 分类3. 整型3.1 内存描述及查询3.2 布尔类型 —— bool3.3 字符类型 —— char3.4 其他整型 4. 有符号类型和无符号类型5. 浮点型6. 如何选择类型7. 类型转换7.1 自动类型转换7.2 强制类型转换7.3 类型转换总结 8. 类型溢出8.1 注意事项 …...

Python爬虫实战:批量下载网站图片
1.获取图片的url链接 首先,打开百度图片首页,注意下图url中的index 接着,把页面切换成传统翻页版(flip),因为这样有利于我们爬取图片! 对比了几个url发现,pn参数是请求到的数量。…...

使用 JavaScript 获取电池状态
在现代的移动设备和笔记本电脑上,了解电池状态是一项非常有用的功能。使用 JavaScript 可以轻松地获取电池的充电状态、电量百分比等信息。本文将介绍如何使用 JavaScript 访问这些信息,并将其显示在网页上。 1. HTML 结构 首先,我们需要一…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...