Java8新特性:Stream流处理使用总结
一. 概述
- Stream流是Java8推出的、批量处理数据集合的新特性,在java.util.stream包下。
- 结合着Java8同期推出的另一项新技术:行为参数化(包括函数式接口、Lambda表达式、方法引用等),Java语言吸收了函数式编程的语法特点,使得程序员能十分便捷地编写处理集合数据的逻辑代码
- 提高了开发效率的同时,代码可阅读性也大大加强
因此有必要整理下Stream流的常用操作,以备后续处理集合类数据时快速查询和使用
二. 流的概念
- 概念:从某些源生成的、支持对其中元素批量进行数据处理操作的元素序列
- 集合可以看做是为相同类型数据存储或访问而设计的一种数据结构或者API类,而流可以看做是对相同类型数据的计算及处理而设计一种API类
- 当一个流被创建出来后,其内部数据是不可更改的,它不像集合那样有对其中元素增删改的操作
三. 流的使用
流的处理,分为中间操作和终端操作两大部分:
- 中间操作方法的返回结果为流本身,因此可以将多个中间操作串联在一起,形成一个操作链
- 终端操作的返回结果为其他类型的对象,比如List等。一个流,只可以执行一次终端操作,执行完成后流便不可以被再使用
- 一个流,实际上只执行一次遍历,此次遍历是在代码执行到终端操作时才执行。在中间操作链中,只是定义了每个操作步骤的具体内容,并没有真正的对其中元素执行遍历方法。
四. API
0. 准备工作:数据源
以下我们创建一个personList的List<Person>对象,后续我们会反复利用这个对象生成流,来练习Stream的方法效果。Person类中保存了每个作家的姓名name、年纪age、朝代dynasty、作品集literature
//为成员变量personList赋值personList = List.of(new Person("李白", 61, "唐", List.of("将进酒", "行路难")),new Person("杜甫", 59, "唐", List.of("登高", "茅屋为秋风所破歌")),new Person("苏轼", 64, "宋", List.of("水调歌头·明月几时有")),new Person("王勃", 27, "唐", List.of("滕王阁序")),new Person("李清照", 71, "宋", List.of("如梦令")));@Datapublic class Person {String name; //姓名int age; //年纪String dynasty; //朝代List<String> literature; //作品public Person(String name, int age, String dynasty, List<String> literature) {this.name = name;this.age = age;this.dynasty = dynasty;this.literature = literature;}}1. 创建流
创建流有四种常见的方式:
- Stream.of()
- Stream.iterate()
- Stream.generate()
- List.stream()转化
以下为一些创建的示例:
/*** 创建流*/public void create() {//方法一:Stream.of() Stream.empty()Stream<String> stringStream = Stream.of("a", "b"); //建立一个流,其中有a、b两个元素Stream<String> empty = Stream.empty(); //建一个空Stream流,空流的泛型可以指定任何类//方法二:用迭代Stream.iterate()方法。 可以创造无限流,这里限制10条:0 2 4 6 8 10 12 14 16 18Stream<Integer> numStream = Stream.iterate(0, n -> n + 2).limit(10);//打印查看结果numStream.forEach(i -> System.out.print(i + " "));System.out.println();//iterate()方法的重载方法,包括三个入参;三入参很像for循环的写法,中间的谓词判断为false时,迭代中断IntStream intStream = IntStream.iterate(0, n -> n < 100, n -> n + 4);intStream.forEach(i -> System.out.print(i + " "));System.out.println();//方法三:用generate来生成Stream<Double> generate = Stream.generate(Math::random).limit(5);generate.forEach(System.out::println);/*注意generate尽量在无状态(流中的任意两项没有某种关联)下使用。在有状态时慎用,可能因并发导致前后数据关系出问题;*///以下是一个有状态应用的例子IntSupplier fib = new IntSupplier() {private int pre = 0; //保存状态的值,此处是对象的一个成员变量@Overridepublic int getAsInt() {int now = pre + 2;pre = now;return now;}};//若并发调用,则可能会出现错乱List<Integer> parallelList = IntStream.generate(fib).parallel().limit(10000).boxed().collect(toList());//打印观察数据,发现日志顺序并没有按照顺序,而是可能出现一片2XXX,紧接着一片1XXXX,又接着一片6XXX,可见多线程下是并行执行,顺序不可保证parallelList.stream().sequential().forEach(System.out::println);//方法四:通过list等传统集合数据做转化Stream<Person> personStream = personList.stream();}
2. 中间操作
a. filter()
filter()需传入一个 谓词格式(T-> boolean) 的入参,以此谓词来判断流中每个元素的条件,如返回为true则保留,false则舍弃
/*** 过滤年龄小于60岁的名人*/public void filter() {List<Person> filterPersonList = personList.stream().filter(person -> person.getAge() < 60).collect(Collectors.toList());//输出:[Person(name=杜甫, age=59, dynasty=唐, literature=[登高, 茅屋为秋风所破歌]), Person(name=王勃, age=27, dynasty=唐, literature=[滕王阁序])]System.out.println(filterPersonList);}
b. map()
map()方法入参类型为 Function(T-> R) , 流会对其中元素T依次执行此入参方法,转换为类型为R的返回结果。执行map()后,流由原来的Stream<T> 变成了Stream<R>
/*** 将原list映射为另一个list,这里是List<Person> -> List<String>*/public void map() {List<String> nameList = personList.stream().map(person -> person.getName()).collect(Collectors.toList());//输出为:[李白, 杜甫, 苏轼, 王勃, 李清照]System.out.println(nameList);}
- 转换后的R可以是任意类型。对于返回值为int、float等基本类型数据,则会转换为他们的封装Box类:Integer、Float,成为
Stream<Integer>、Stream<Float>流。 - 但如果后续又要进行sum()/avg()等运算操作,则流内部又不得不进行静默拆箱,将前一步封装好的Integer再拆箱还原为int基本类型后才能计算。此番反复无谓的拆箱装箱需要浪费不小的计算资源。
- 因此Java额外提供了针对基本类型数据不需要装箱拆箱的特别流:IntStream/FloatStream等。可以将这种流视为一种特别的流:
Stream<int>/Stream<float> - 用mapToInt()/mapToFloat()等方法,可转换为此类型
/*** 数据流的映射*/public void map2() {IntStream intStream = personList.stream()
// .map(person -> person.getAge()) //这里的类型是Stream<Integer>,如果后续是reduce等对数字处理的方法,则会导致隐形拆箱再装箱,耗费资源.mapToInt(person -> person.getAge()); //直接是IntStream类型,没有拆箱装箱开销//提供一些计算方法,因不需要拆箱装箱所以效率很高int sum = intStream.sum();//输出为:282System.out.println(sum);}
c. flatmap()
- flatmap()也传一个Function,但这个Function的类型为
T->Stream<R>,返回是一个Stream流。这样每个对象都会返回一个Stream流,如果换成map()的话,返回结果则为一个嵌套的Stream流:Stream<Stream<R>>,是流的流 - flatMap()可以将每个元素返回的流
Stream<R>,归并其中的元素,最终压缩整合成一个流Stream<R>
/*** 将每个人的作品扁平化为一个新的List*/public void flatMap1() {List<String> literatureList = personList.stream().flatMap(person -> person.getLiterature().stream()) //将作品的list取出来转换为Stream,然后用flatMap进行扁平化,合并为一个大的Stream.collect(Collectors.toList());//输出为:[将进酒, 行路难, 登高, 茅屋为秋风所破歌, 水调歌头·明月几时有, 滕王阁序, 如梦令]System.out.println(literatureList);}/*** 复杂案例:将每个人的作品跟作者合为一个List<String>, 扁平化为一个新的List*/public void flatMap2() {List<List<String>> literatureList = personList.stream()//3. 最后用flatMap进行扁平化,合并为一个大的Stream.flatMap(person -> person.getLiterature().stream() //1:此处返回一个Stream<String> 每个作家作品的流.map(literature -> { //2:通过map,将上面的Stream<String>转换为Stream<List<String>>流,每个list有两个对象,为[作家姓名:作品]return Arrays.asList(person.getName(), literature); //将作者姓名及作品名称组成一个新的数组})).collect(Collectors.toList());//输出为:[[李白, 将进酒], [李白, 行路难], [杜甫, 登高], [杜甫, 茅屋为秋风所破歌], [苏轼, 水调歌头·明月几时有], [王勃, 滕王阁序], [李清照, 如梦令]]System.out.println(literatureList);}
d. distinct()
distinct()会对流元素进行去重
/*** 对列表中的朝代进行去重*/public void distinct() {List<String> distinctDynastyList = personList.stream().map(person -> person.getDynasty()).distinct() //去重,如果不去重本例输出为:[唐, 唐, 宋, 唐, 宋].collect(Collectors.toList());//输出:[唐, 宋]System.out.println(distinctDynastyList);}
e. 切片
切片为从流中取部分子集,主要方法有:
- limit(n) 传入long类型参数,截取原Stream的前n项
- drop(n) 与limit()正好相反,是舍弃前n项,保留n+1项以后的数据
- takewhile()传一个谓词,通过谓词判断true或false,连续取满足条件true的项,直到遇到第一个false的停止,并舍弃自此之后的项
- dropwhile()正好与takewhile()相反,舍弃连续满足条件true的项,直到遇到第一个false的,并从此取之后的数据
/*** 截取前n项*/public void limit() {List<Person> subPersonList = personList.stream().limit(2) //取前两项.collect(Collectors.toList());//输出:[Person(name=李白, age=61, dynasty=唐, literature=[将进酒, 行路难]), Person(name=杜甫, age=59, dynasty=唐, literature=[登高, 茅屋为秋风所破歌])]System.out.println(subPersonList);}/*** 舍弃前n项*/public void skip() {List<Person> subPersonList = personList.stream().skip(4) //取前4项.collect(Collectors.toList());//输出:[Person(name=李清照, age=71, dynasty=宋, literature=[如梦令])]System.out.println(subPersonList);}/*** 切片取前若干项*/public void takewhile() {List<Person> subPersonList = personList.stream().takeWhile(person -> person.getAge() > 30) //取年纪大于30的人,直到遇到第一个年纪小于30的停止.collect(Collectors.toList());System.out.println(subPersonList);//输出:[Person(name=李白, age=61, dynasty=唐, literature=[将进酒, 行路难]), Person(name=杜甫, age=59, dynasty=唐, literature=[登高, 茅屋为秋风所破歌]), Person(name=苏轼, age=64, dynasty=宋, literature=[水调歌头·明月几时有])]}/*** 切片取后若干项*/public void dropWhile() {List<Person> subPersonList = personList.stream().dropWhile(person -> person.getAge() > 30) //舍弃前半部分的年纪大于30的人,直到遇到第一个年纪小于30的,开始取后面的数.collect(Collectors.toList());//输出:[Person(name=王勃, age=27, dynasty=唐, literature=[滕王阁序]), Person(name=李清照, age=71, dynasty=宋, literature=[如梦令])]System.out.println(subPersonList);}
f. 查找判断
查找判断包括判断流中元素是否满足某个条件,以及取出某个想要的值,主要用到的有:
- anyMatch() 检查流中是否匹配有至少一个匹配谓词的执行结果,只要有一个满足,则返回为true
- noneMatch() 检查流中是否一个都没有匹配谓词的执行结果,只有全部都不满足,才会返回true
- findAny() 找出满足要求的某个值,不一定是第一个匹配的,速度会比较快
- findFirst() 找出第一个匹配要求的值
/*** 检查流中是否匹配有至少一个匹配谓词的执行结果*/public void anyMatch() {boolean result = personList.stream().anyMatch(person -> person.getAge() == 27);//若上式为"== 30", 输出为:false (任意一个都没有匹配) 若为 "== 27", 输出为:true(匹配到了王勃)System.out.println(result);}/*** 检查流中是否一个都没有匹配谓词的执行结果*/public void noneMatch() {boolean result = personList.stream().noneMatch(person -> person.getAge() == 30);//输出为:trueSystem.out.println(result);}/*** 找出任意一个匹配的结果(比findFirst执行快,更能并行处理)*/public void findAny() {Optional<Person> any = personList.stream().filter(person -> person.getDynasty() == "唐").findAny();//输出为:Person(name=李白, age=61, dynasty=唐, literature=[将进酒, 行路难])if (any.isPresent()) {System.out.println(any.get());} else {System.out.println("不存在");}}/*** 找出第一个匹配的结果*/public void findFirst() {Optional<Person> first = personList.stream().filter(person -> person.getDynasty() == "宋").findFirst();//输出为:Person(name=苏轼, age=64, dynasty=宋, literature=[水调歌头·明月几时有])if (first.isPresent()) {System.out.println(first.get());} else {System.out.println("不存在");}}
3. 终端操作
a. reduce()
reduce()可以将流中的元素,依次按照方法入参的逻辑进行聚合计算,得到一个结果。具体使用方式参考以下实例:
/*** reduce()聚合*/public void reduce() {//用reduce求和,从初始值逐个进行累加,最终得到所有值的sum数据Integer sumAge = personList.stream().map(person -> person.getAge()) //先取年纪,组成新List.reduce(0, (a, b) -> a + b); //首参数为初始值,第二个参数为BiOperator(T,T)->T,本例为(int, int) -> int//输出:282System.out.println(sumAge);Optional<Integer> sumAge2 = personList.stream().map(person -> person.getAge()) //先取年纪,组成新List.reduce((a, b) -> a + b); //无初始值的方案,默认使用流的第一项作为初始值,返回结果可能为null,所以为Opetion类型//输出:Optional[282]System.out.println(sumAge2);//求最大值Optional<Integer> sumAge3 = personList.stream().map(person -> person.getAge()) //先取年纪,组成新List.reduce(Integer::max); //可以直接用方法引用,只要保证方法本身是BiOperator类型即可//输出:Optional[71]System.out.println(sumAge3);}
b. collect()
collect()可传入java.util.stream.Collector的实现类,来定义对流中的元素数据做何种聚合处理。java本身也提供了很多常用的Collector实现类或工厂方法,可以拿来主义的直接使用,比如之前见到的toList()方法,就是工厂方法:java.util.stream.Collectors.toList(),返回了一个CollectorImpl对象,实现了将流Stream中的元素转换为List的终端操作。
除此之外还有很多Collector工程类,下面做一些介绍
1)统计相关
/*** 各种统计*/private void statistics() {//对年龄进行加总,跟Stream的sum()或reduce()加年纪一个效果,但不会装箱拆箱Integer sumAge = personList.stream().collect(summingInt(Person::getAge)); //summingInt()方法可将Stream中的int元素进行累加System.out.println(sumAge);//平均值Double avgAge = personList.stream().collect(averagingInt(Person::getAge));//打印:56.4System.out.println(avgAge);//summarizingInt()可以返回一个多维度统计的结果对象IntSummaryStatistics collect = personList.stream().collect(summarizingInt(Person::getAge));//打印:IntSummaryStatistics{count=5, sum=282, min=27, average=56.400000, max=71}System.out.println(collect);//maxBy()可以返回按某种条件判断得到的某个T元素,本例为返回年纪最大的人Optional<Person> maxPerson = personList.stream().collect(maxBy(Comparator.comparing(Person::getAge)));//打印:Optional[Person(name=李清照, age=71, dynasty=宋, literature=[如梦令])]System.out.println(maxPerson);}
2)joining()聚合拼装字符串
/*** 将流中的每个对象,调用toString()方法串联起来形成一个string字符串*/private void joining() {String jsonString = personList.stream().map(Person::getName).collect(Collectors.joining());//打印:李白杜甫苏轼王勃李清照System.out.println(jsonString);//可加间隔参数String jsonString2 = personList.stream().map(Person::getName).collect(Collectors.joining(","));//打印:李白,杜甫,苏轼,王勃,李清照System.out.println(jsonString2);}
2)reducing() 聚合方法
聚合reducing(),是更原始的collect方法,很多Stream的聚合方法、Collector接口方法的底层,都是利用reducing方法来实现逻辑
/*** reducing实例*/private void reducing() {Integer maxAge = personList.stream().collect(Collectors.reducing(0, //初始值,类型为TPerson::getAge, //流中对象的取值,返回类型也为TMath::max)); //BiOperator类型的方法入参,为(T, T) -> TSystem.out.println(maxAge);}
3)groupingBy() 聚合方法
groupingBy()方法可以接收一个参数,按照此参数的计算,将原Stream分成不同的group组
private void groupingBy1() {Map<String, List<Person>> listMap = personList.stream().collect(Collectors.groupingBy(Person::getDynasty)); //按朝代进行分组//{唐=[Person(name=李白, age=61, dynasty=唐, literature=[将进酒, 行路难]),// Person(name=杜甫, age=59, dynasty=唐, literature=[登高, 茅屋为秋风所破歌]),// Person(name=王勃, age=27, dynasty=唐, literature=[滕王阁序])],// 宋=[Person(name=苏轼, age=64, dynasty=宋, literature=[水调歌头·明月几时有]),// Person(name=李清照, age=71, dynasty=宋, literature=[如梦令])]}System.out.println(listMap);}
为了在分组后对子组数据进行更复杂的操作,groupingBy()方法提供了可传入两个参数的重载方法。第一个参数还是用来分组的参数,第二个分组为一个Collector对象,可通过这个Collector对象,对每个组中的子数据集进行后续的计算,整个方法就可以变得很灵活
/*** groupingBy()复杂用法*/private void groupingBy2() {//按朝代进行分组,然后挑选出来作品数量大于1的作家Map<String, List<Person>> groupFilter = personList.stream().collect(Collectors.groupingBy(Person::getDynasty,filtering(person -> person.getLiterature().size() > 1, toList()))); //过滤作品数量大于1//{唐=[Person(name=李白, age=61, dynasty=唐, literature=[将进酒, 行路难]), Person(name=杜甫, age=59, dynasty=唐, literature=[登高, 茅屋为秋风所破歌])],// 宋=[]}/* 可以看到宋朝作为一个分类保留下来了,虽然内容为空 */System.out.println(groupFilter);//按朝代进行分组,然后将value转换为名字的数据集合Map<String, List<String>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getDynasty,mapping(Person::getName, toList())));//{唐=[李白, 杜甫, 王勃], 宋=[苏轼, 李清照]}System.out.println(group2);//按朝代进行分组,然后将作品flatmap到一个流中Map<String, List<String>> group3 = personList.stream().collect(Collectors.groupingBy(Person::getDynasty,flatMapping(item -> item.getLiterature().stream(), toList())));//{唐=[将进酒, 行路难, 登高, 茅屋为秋风所破歌, 滕王阁序], 宋=[水调歌头·明月几时有, 如梦令]}System.out.println(group3);//按朝代分组,再统计各组数量Map<String, Long> group4 = personList.stream().collect(Collectors.groupingBy(Person::getDynasty,Collectors.counting()));//{唐=3, 宋=2}System.out.println(group4);//按朝代分组,再按年龄条件取各组最大值,注意Value是Optional<Person>原对象Map<String, Optional<Person>> groupByMaxAge = personList.stream().collect(Collectors.groupingBy(Person::getDynasty,maxBy(Comparator.comparing(Person::getAge))));//{唐=Optional[Person(name=李白, age=61, dynasty=唐, literature=[将进酒, 行路难])], 宋=Optional[Person(name=李清照, age=71, dynasty=宋, literature=[如梦令])]}System.out.println(groupByMaxAge);//通过collectingAndThen()方法,对对象做额外的处理Map<String, Person> groupByMaxAge2 = personList.stream().collect(Collectors.groupingBy(Person::getDynasty,collectingAndThen( //多加个collectingAndThen(),对Optional做额外的get操作maxBy(Comparator.comparing(Person::getAge)), Optional::get)));//{唐=Person(name=李白, age=61, dynasty=唐, literature=[将进酒, 行路难]), 宋=Person(name=李清照, age=71, dynasty=宋, literature=[如梦令])}System.out.println(groupByMaxAge2);}
因为第二个入参为Collector类对象,而groupingBy()本身也是Collector对象工厂方法,因此可以进行循环嵌套,进行多级分组
private void multiGroupingBy() {//先按朝代、再按作品数量进行分组, 取了作家姓名Map<String, Map<Integer, List<String>>> mulGroup = personList.stream().collect(Collectors.groupingBy(Person::getDynasty,Collectors.groupingBy(person -> person.getLiterature().size(),mapping(Person::getName, toList()))));//{唐={1=[王勃], 2=[李白, 杜甫]}, 宋={1=[苏轼, 李清照]}}System.out.println(mulGroup);}总结:
groupingBy()的第二个参数,还可以传一个Collector,子Collector的操作对象为分组之后的每个组下的子Stream,这样就实现了嵌套,可以将前面学过的reducing、mapping、filtering等方法都用在嵌套中
除此之外,还有一种针对boolean类型的特殊分类:partitionBy()
private void partitionBy() {//partitioningBy(), 一种groupingBy的特例,第一个参数为一个谓词,将数组分为false和true两部分Map<Boolean, List<String>> partitioningBy = personList.stream().collect(partitioningBy(item -> item.getAge() > 60,mapping(Person::getName, toList())));//{false=[杜甫, 王勃], true=[李白, 苏轼, 李清照]}System.out.println(partitioningBy);}
相关文章:

Java8新特性:Stream流处理使用总结
一. 概述 Stream流是Java8推出的、批量处理数据集合的新特性,在java.util.stream包下。结合着Java8同期推出的另一项新技术:行为参数化(包括函数式接口、Lambda表达式、方法引用等),Java语言吸收了函数式编程的语法特…...

Java基准测试工具JMH高级使用
去年,我们写过一篇关于JMH的入门使用的文章:Java基准测试工具JMH使用,今天我们再来聊一下关于JMH的高阶使用。主要我们会围绕着以下几点来讲: 对称并发测试非对称并发测试阻塞并发测试Map并发测试 关键词 State 在很多时候我们…...
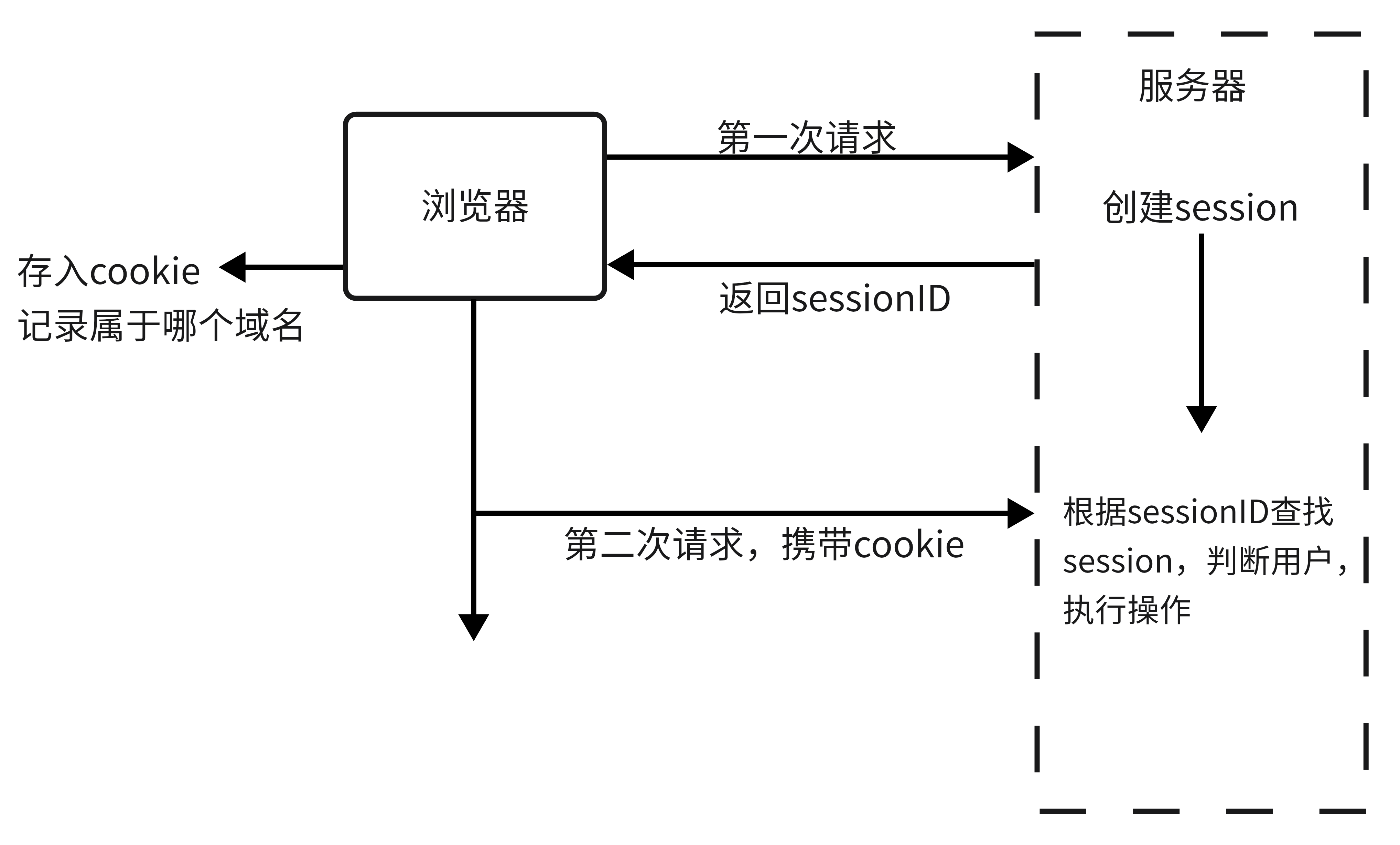
问心 | 再看token、session和cookie
什么是cookie HTTP Cookie(也叫 Web Cookie或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。 什么是session Session 代表着服务器和客户端一次会话…...

Ubuntu 安装 CUDA and Cudnn
文章目录0 查看 nvidia驱动版本1 下载Cuda2 下载cudnn参考:0 查看 nvidia驱动版本 nvidia-smi1 下载Cuda 安装之前先安装 gcc g gdb 官方:https://developer.nvidia.com/cuda-toolkit-archive,与驱动版本进行对应,我这里是12.0…...
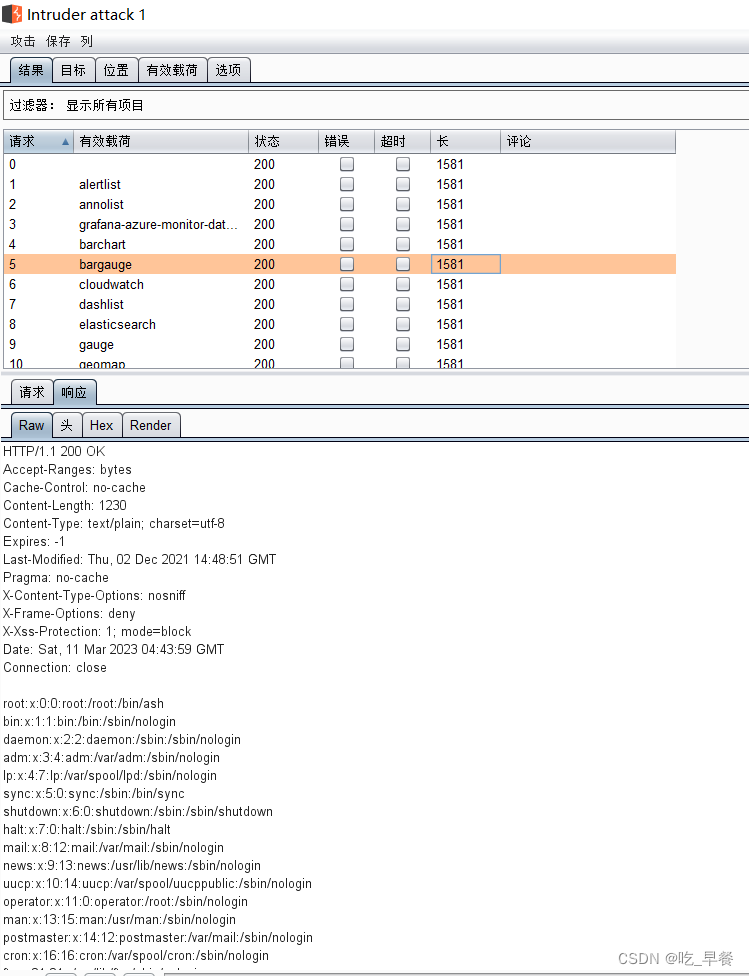
【漏洞复现】Grafana任意文件读取(CVE-2021-43798)
docker环境搭建 #进入环境 cd vulhub/grafana/CVE-2021-43798#启动环境,这个过程可能会有点慢,保持网络通畅 docker-compose up -d#查看环境 docker-compose ps直接访问虚拟机 IP地址:3000 目录遍历原理 目录遍历原理:攻击者可以通过将包含…...

磨金石教育摄影技能干货分享|春之旅拍
春天来一次短暂的旅行,你会选择哪里呢?春天的照片又该如何拍呢?看看下面的照片,或许能给你答案。照片的构图很巧妙,画面被分成两部分,一半湖泊,一半绿色树林。分开这些的是一条斜向的公路&#…...
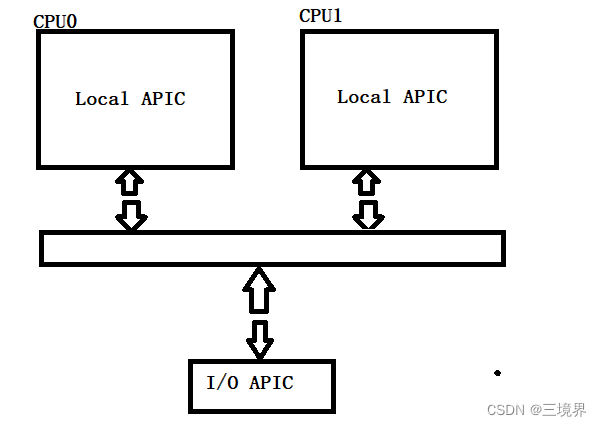
中断以及 PIC可编程中断控制器
1 中断分为同步中断(中断)和异步中断(异常) 1.1 中断和异常的不同 中断由IO设备和定时器产生,用户的一次按键会引起中断。异步。 异常一般由程序错误产生或者由内核必须处理的异常条件产生。同步。缺页异常ÿ…...
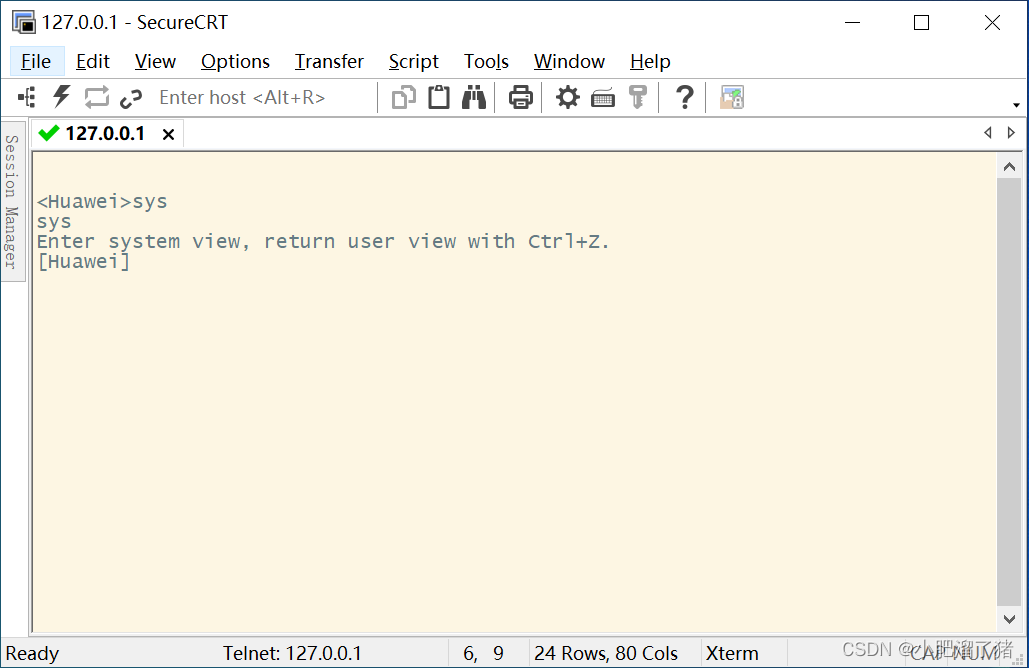
SecureCRT 安装并绑定ENSP设备终端
软件下载链接链接:https://pan.baidu.com/s/1WFxmQgaO9bIiUTwBLSR4OA?pwd2023 提取码:2023 CRT安装:软件可以从上面链接进行下载,下载完成后解压如下:首先双击运行scrt-x64.8.5.4 软件,进行安装点击NEXT选…...

ESP32设备驱动-TCS3200颜色传感器驱动
TCS3200颜色传感器驱动 1、TCS3200介绍 TCS3200 和 TCS3210 可编程彩色光频率转换器在单个单片 CMOS 集成电路上结合了可配置的硅光电二极管和电流频率转换器。 输出是方波(50% 占空比),其频率与光强度(辐照度)成正比。 满量程输出频率可以通过两个控制输入引脚按三个预…...
< JavaScript小技巧:Array构造函数妙用 >
文章目录👉 Array构造函数 - 基本概念👉 Array函数技巧用法1. Array.of()2. Array.from()3. Array.reduce()4. (Array | String).includes()5. Array.at()6. Array.flat()7. Array.findIndex()📃 参考文献往期内容 💨今天这篇文章…...
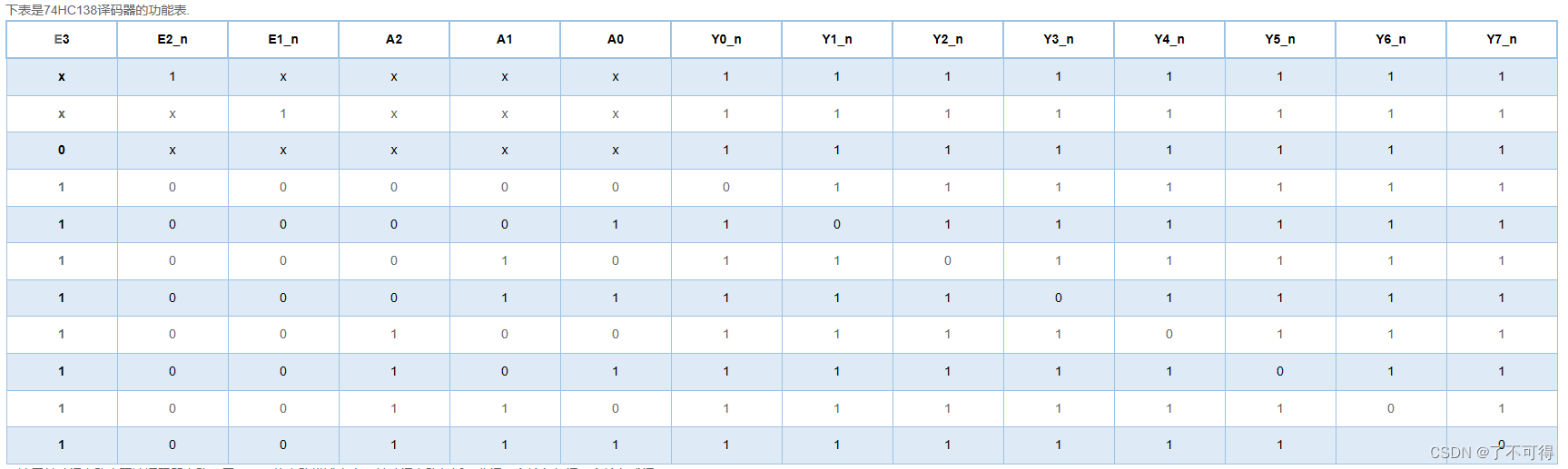
【17】组合逻辑 - VL17/VL19/VL20 用3-8译码器 或 4选1多路选择器 实现逻辑函数
VL17 用3-8译码器实现全减器 【本题我的也是绝境】 因为把握到了题目的本质要求【用3-8译码器】来实现全减器。 其实我对全减器也是不大清楚,但是仿照对全加器的理解,全减器就是低位不够减来自低位的借位 和 本单元位不够减向后面一位索要的借位。如此而已,也没有很难理解…...

2023年全国最新二级建造师精选真题及答案19
百分百题库提供二级建造师考试试题、二建考试预测题、二级建造师考试真题、二建证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 37.下列纠纷中,属于劳动争议范围的有()。 A.因劳动保护发生的纠纷 B.家庭与家政…...
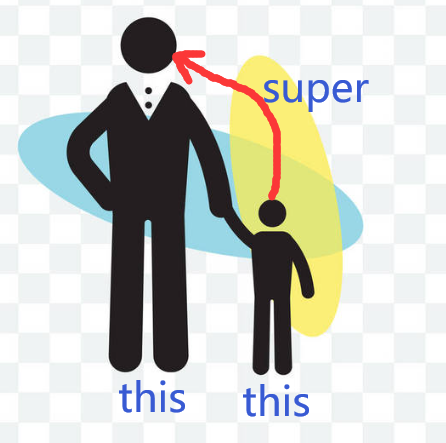
Java中的 this 和 super
1 this 关键字 1.1 this 访问本类属性 this 代表对当前对象的一个引用 所谓当前对象,指的是调用当前类中方法或属性的那个对象this只能在方法内部使用,表示对“调用方法的那个对象”的引用this.属性名,表示本对象自己的属性 当对象的属性和…...

ESP32设备驱动-红外寻迹传感器驱动
红外寻迹传感器驱动 1、红外寻迹传感器介绍 红外寻迹传感器具有一对红外线发射管与接收管,发射管发射出一定频率的红外线,当检测方向遇到障碍物(反射面)时,红外线反射回来被接收管接收,经过比较器电路处理之后,输出接口会输出一个数字信号(低电平或高电平,取决于电路…...

初识BFC
初识BFC 先说如何开启BFC: 1.设置display属性:inline-block,flex,grid 2.设置定位属性:absolute,fixed 3.设置overflow属性:hidden,auto,scroll 4.设置浮动…...

随想录二刷Day17——二叉树
文章目录二叉树9. 二叉树的最大深度10. 二叉树的最小深度11. 完全二叉树的节点个数12. 平衡二叉树二叉树 9. 二叉树的最大深度 104. 二叉树的最大深度 思路1: 递归找左右子树的最大深度,选择最深的 1(即加上当前层)。 class So…...
Weblogic管理控制台未授权远程命令执行漏洞复现(cve-2020-14882/cve-2020-14883)
目录漏洞描述影响版本漏洞复现权限绕过漏洞远程命令执行声明:本文仅供学习参考,其中涉及的一切资源均来源于网络,请勿用于任何非法行为,否则您将自行承担相应后果,本人不承担任何法律及连带责任。 漏洞描述 Weblogic…...
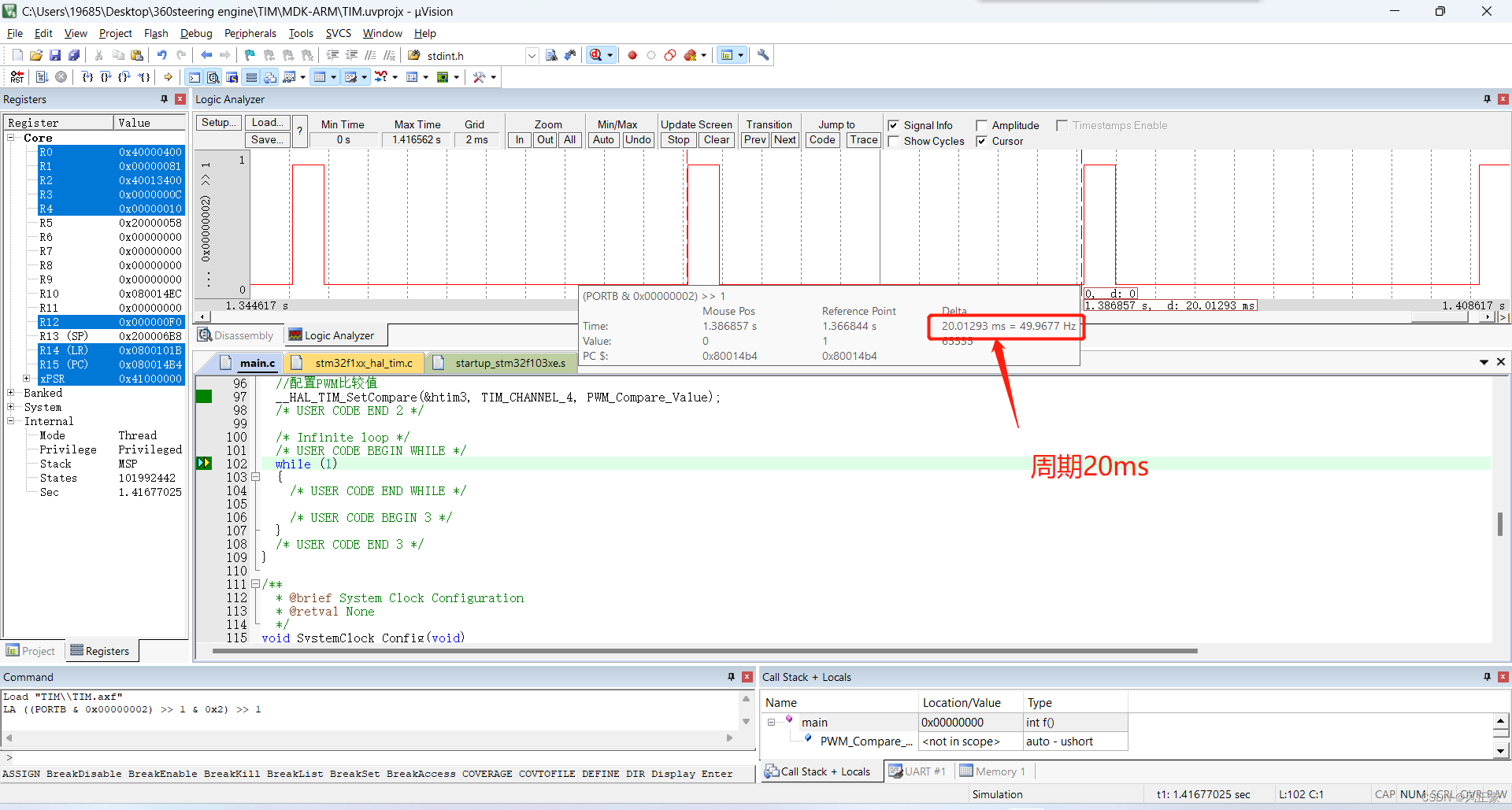
STM32F103CubeMX定时器
前言定时器作为最重要的内容之一,是每一位嵌入式软件工程师必备的能力。STM32F103的定时器是非常强大的。1,他可以用于精准定时,当成延时函数来使用。不过个人不建议这么使用,因为定时器很强大,这么搞太浪费了。如果想…...
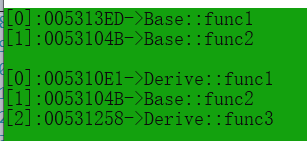
多态且原理
多态 文章目录多态多态的定义和条件协变(父类和子类的返回值类型不同)函数隐藏和虚函数重写的比较析构函数的重写关键字final和override抽象类多态的原理单继承和多继承的虚函数表单继承下的虚函数表多继承下的虚函数表多态的定义和条件 定义࿱…...
 创建动态库)
动态库(二) 创建动态库
文章目录创建动态库设计动态库ABI兼容动态符号的可见性示例控制符号可见性通过-fvisibility通过strip工具删除指定符号创建动态库 在Linux中创建动态库通过如下过程完成: gcc -fPIC -c first.c second.c gcc -shared first.o second.o -o libdynamiclib.so 按照Li…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...