Java启动jar设置内存分配详解
在微服务架构越来越盛行的情况下,我们通常一个系统都会拆成很多个小的服务,但是最终部署的时候又因为没有那么多服务器只能把多个服务部署在同一台服务器上,这个时候问题就来了,服务器内存不够,这个时候我们就需要对每个服务的内存开始精细分配,以达到充分利用每一台服务器的目的
首先来看一下我们用来启动 jar 包的常用命令
nohup java -Xms512m -Xmx512m -Xmn256m -Xss512k -server -XX:+HeapDumpOnOutOfMemoryError -jar your-application.jar > output.log 2>&1 &
下面我们来一点点的解析这行命令
nohup:
在后台运行命令并忽略挂起信号(这个应该都知道没什么好说的)。
-Xms512m:
含义:设置 JVM 初始堆内存大小为 512MB。
作用:JVM 启动时分配的初始内存大小,确保在应用程序启动时有足够的内存。
-Xmx512m:
含义:设置 JVM 最大堆内存大小为 512MB。
作用:JVM 运行过程中可以使用的最大内存限制,防止应用程序占用过多的系统内存。
-Xmn256m:
含义:设置新生代内存大小为 256MB。
作用:控制新生代(Young Generation)的大小,新生代用于存放新创建的对象。适当调整可以影响垃圾回收的频率和性能。
-Xss512k:
含义:设置每个线程的栈大小为 512KB。
作用:控制每个线程的栈内存大小。如果应用程序创建大量线程或有深度递归调用,需要适当调整该值。
-server:
含义:启用 JVM 的服务器模式。
作用:服务器模式针对长期运行的服务器应用程序进行了优化,包括更高级的编译优化和垃圾回收策略。
-XX:+HeapDumpOnOutOfMemoryError:
含义:在发生内存溢出错误(OutOfMemoryError)时生成堆转储文件。
作用:当应用程序由于内存不足而崩溃时,生成堆转储文件(heap dump),便于后续进行内存分析和调试。
知道了这些参数的含义以及作用,在使用的过程中还有些地方需要注意
调整堆内存大小:根据应用程序的实际内存需求,调整 -Xms 和 -Xmx的值。通常,初始堆大小(-Xms)和最大堆大小(-Xmx)应该设置为相同,以避免 JVM在运行过程中调整堆大小带来的开销。
-Xms1024m -Xmx1024m
新生代内存调整:新生代(-Xmn)的大小应该根据应用程序对象的生命周期进行调整。一般来说,新生代应占堆内存的 1/3 到1/4。
-Xmn512m
垃圾回收器选择:不同的垃圾回收器适用于不同类型的应用程序。常见的垃圾回收器有 G1、CMS 和 Parallel GC。可以根据应用程序的特点选择合适的垃圾回收器。
G1 垃圾回收器(适合具有低延迟要求的应用程序)
-XX:+UseG1GC
CMS 垃圾回收器(适合需要短暂停顿时间的应用程序)
-XX:+UseConcMarkSweepGC
并行垃圾回收器(适合高吞吐量要求的应用程序)
-XX:+UseParallelGC
元空间大小调整:调整元空间(Metaspace)大小,避免频繁的元空间扩展。
-XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m
垃圾回收日志:启用垃圾回收日志,以便于调试和优化垃圾回收。
-Xlog:gc*:file=gc.log:time,level,tags
线程栈大小调整:根据应用程序的线程使用情况调整线程栈大小。
-Xss1m
启用类数据共享
-XX:+UseAppCDS
启用自适应大小线程池:
-XX:+UseAdaptiveSizePolicy
综合一下就是下面这条命令
nohup java -Xms1024m -Xmx1024m -Xmn512m -Xss1m -server -XX:+HeapDumpOnOutOfMemoryError -XX:+UseG1GC -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -Xlog:gc*:file=gc.log:time,level,tags -jar your-application.jar > output.log 2>&1 &
接着我们再来说一下简洁版的启动命令
nohup java -jar your-application.jar &
在没有指定任何 JVM 参数的情况下,使用 nohup java -jar your-application.jar & 启动 Java 应用程序时,JVM将使用默认的内存设置。这些默认值通常取决于 JVM 的版本、操作系统以及系统的可用内存。以下是一些默认设置的概述:
堆内存:
默认初始堆大小(-Xms):通常为物理内存的 1/64,但不超过 1GB。
默认最大堆大小(-Xmx):通常为物理内存的 1/4,但不超过32GB。
新生代内存:
新生代大小(-Xmn):默认情况下,新生代的大小会根据堆大小动态调整。
线程栈大小:
默认线程栈大小(-Xss):这取决于操作系统和 JVM 实现。通常在 Linux 上为 1MB,Windows 上为 320KB。
垃圾回收器:
JVM 会选择默认的垃圾回收器,这通常是并行垃圾回收器(Parallel GC),具体取决于 JVM 的版本。
元空间:
默认情况下,元空间(Metaspace)大小会动态调整。
这个呢大家也可以直接在服务器上查看
java -XX:+PrintFlagsFinal -version
也可以在程序运行时查看
public static void main(String[] args) {Runtime runtime = Runtime.getRuntime();long maxMemory = runtime.maxMemory();long allocatedMemory = runtime.totalMemory();long freeMemory = runtime.freeMemory();System.out.println("Max Memory: " + maxMemory / 1024 / 1024 + " MB");System.out.println("Allocated Memory: " + allocatedMemory / 1024 / 1024 + " MB");System.out.println("Free Memory: " + freeMemory / 1024 / 1024 + " MB");}
我这个就是本机默认的,明显有些大了
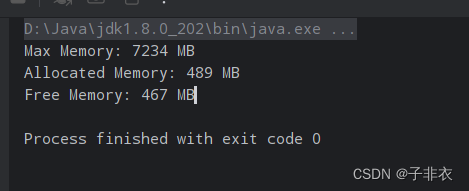
好了,合理分配内存,节约服务器空间从你我做起
相关文章:
Java启动jar设置内存分配详解
在微服务架构越来越盛行的情况下,我们通常一个系统都会拆成很多个小的服务,但是最终部署的时候又因为没有那么多服务器只能把多个服务部署在同一台服务器上,这个时候问题就来了,服务器内存不够,这个时候我们就需要对每…...

Feign Client超时时间设置不生效问题
在使用Feign Client时,可以通过两种方式来设置超时时间: 针对整个Feign Client设置超时时间 可以在Feign Client的配置类中通过修改Request.Options对象来设置超时时间。Request.Options对象有两个属性,connectTimeoutMillis用于设置连接超…...

Haproxy部署Web群集
概论 HAProxy是可提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,是免费、快速并且可靠的一种解决方案。HAProxy非常适用于并发大(并发达1w以上)web站点,这些站点通常又需要会话保持或七层处理。HAProxy的运行模式使得它可以…...
C++STL梳理
CSTL标准手册: https://cplusplus.com/reference/stl/ https://cplusplus.com/reference/vector/vector/at/ 1、STL基础 1.1、STL基本组成(6大组件13个头文件) 通常认为,STL 是由容器、算法、迭代器、函数对象、适配器、内存分配器这 6 部分构成&…...

找出1000以内的所有的完数
完数的概念:完数(Perfect Number)是一个正整数,它等于除了它本身以外所有正因子之和。例如,6的因子有1、2、3和6,其中1236,所以6是一个完数。 #include <stdio.h> // 函数用于计算一个数…...

3110. 字符串的分数
给你一个字符串 s 。一个字符串的 分数 定义为相邻字符 ASCII 码差值绝对值的和。 请你返回 s 的 分数 。 示例 1: 输入:s "hello" 输出:13 解释: s 中字符的 ASCII 码分别为:h 104 ,e 1…...

Mybatis MySQL allowMultiQueries 一次性执行多条语句
在JDBC 增加参数allowMultiQueries jdbc:mysql://localhost:3306/abc?&allowMultiQueriestrue <insert id"addRi" parameterType"java.util.List">DELETE FROM sys_ri WHERE sr_id #{roId} AND sr_fion_id #{fod};INSERT into sys_rVALUES&…...

Kubernates容器化JVM调优笔记(内存篇)
Kubernates容器化JVM调优笔记(内存篇) 先说结论背景思路方案 先说结论 1、首先如果是JDK8,需要使用JDK8_191版本以上,才支持容器化环境和以下参数,否则就更新到JDK10以上,选择对应的镜像构建就行了 2、在容…...

Elasticsearch Scroll 报错entity content is too long
2024-06-24 15:22:01:568 ERROR [task-31] (ScrollFetcherProduceAction.java:129) 访问ES出错org.apache.http.ContentTooLongException: entity content is too long [112750110] for the configured buffer limit [104857600]at org.elasticsearch.client.HeapBufferedAsync…...

Vue iview输入框change事件replace正则替换不生效问题的解决。
// 需求:输入座机号只允许输入数字和"-" onChange(e){this.$nextTick(()>{this.phone e.target.value.replace(/[^0-9-]/g, );}) } 解决:添加**this.$nextTick**即可...

Prestashop跨境电商独立站,外贸B2C网站完整教程
Prestashop是一款来自法国专业的开源电商CMS(内容管理系统)平台,和wordpress一样比较轻量,适合中小网站。Prestashop跨境电商独立站在国内并不是很流行,不过国外是非常火的,从各大平台的Prestashop主题数量就可以看得出来。 最有…...

常用算法及参考算法 (1)累加 (2)累乘 (3)素数 (4)最大公约数 (5)最值问题 (6)迭代法
常用算法及参考算法 (1)累加 (2)累乘 (3)素数 (4)最大公约数 (5)最值问题 (6)迭代法 1. 累加 #include <stdio.h>int main() {…...
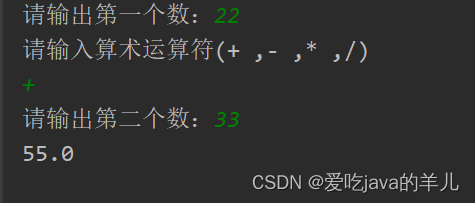
java简易计算器(多种方法)
parseDouble() 方法属于 java.lang.Double 类。它接收一个字符串参数,其中包含要转换的数字表示。如果字符串表示一个有效的 double,它将返回一个 double 值。 应用场景 parseDouble() 方法在以下场景中非常有用: 从用户输入中获取数字&a…...

spring的bean定义和扫描规则
1、bean的基本定义 在Spring框架中,Bean是一个核心概念,它是Spring IoC(Inverse of Control,控制反转)容器管理的一个对象实例。简单来说,Bean就是由Spring容器初始化、配置和管理的对象。这些对象可以是J…...
软件工程体系概念
软件工程 软件工程是应用计算机科学、数学及 管理科学等原理开发软件的工程。它借鉴 传统工程的原则、方法,以提高质量,降 低成本为目的。 一、软件生命周期 二、软件开发模型 1.传统模型 瀑布模型、V模型、W模型、X 模型、H 模型 (1)瀑布模型 瀑布…...
史上最全整合nacos单机模式整合哈哈哈哈哈
Nacos 是阿里巴巴推出的一个新开源项目,它主要是一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。 Nacos提供了一组简单易用的特性集,帮助用户快速实现动态服务发现、服务配置、服务元数据及流量管理。 Nacos 的关键特性包括&#x…...

Python xml.dom.minidom 读取XML元素
哈喽,大家好,我是木头左! 什么是 XML? XML(可扩展标记语言)是一种用于描述数据结构和交换数据的标记语言。它被广泛用于 Web 应用程序中,用于存储和传输数据。XML 具有自描述性,因此可以很容易地理解和处理。 Python 中的 xml.dom.minidom Python 提供了一个内置的库…...

【Python/Pytorch 】-- K-means聚类算法
文章目录 文章目录 00 写在前面01 基于Python版本的K-means代码02 X-means方法03 最小二乘法简单理解04 贝叶斯信息准则 00 写在前面 时间演变聚类算法:将时间演变聚类算法用在去噪上,基本思想是,具有相似信号演化的体素具有相似的模型参数…...

【Eureka】介绍与基本使用
Eureka介绍与基本使用 一个简单的Eureka服务器的设置方法:1 在pom.xml中添加Eureka服务器依赖:2 在application.properties或application.yml中添加Eureka服务器配置:3 创建启动类,使用EnableEurekaServer注解启用Eureka服务器&am…...
SpringBoot+Vue集成富文本编辑器
1.引入 我们常常在各种网页软件中编写文档的时候,常常会有富文本编辑器,就比如csdn写博客的这个页面,包含了富文本编辑器,那么怎么实现呢?下面来详细的介绍! 2.安装wangeditor插件 在Vue工程中,…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...