Interview preparation--elasticSearch倒排索引原理
搜索引擎应该具备哪些要求
- 查询速度快
- 优秀的索引结构设计
- 高效率的压缩算法
- 快速的编码和解码速度
- 结果准确
- ElasiticSearch 中7.0 版本之后默认使用BM25 评分算法
- ElasticSearch 中 7.0 版本之前使用 TP-IDF算法
倒排索引原理
- 当我们有如下列表数据信息,并且系统数据量达到10亿,100亿级别的时候,我们系统该如何去解决查询速度的问题。
- 数据库选择—mysql, sybase,oracle,mongodb,唯一加速查询的方法是添加索引
索引
- 无论哪一种存储引擎的索引都是如下几个特点
- 帮助快速检索
- 以数据结构为载体
- 以文件的形式落地
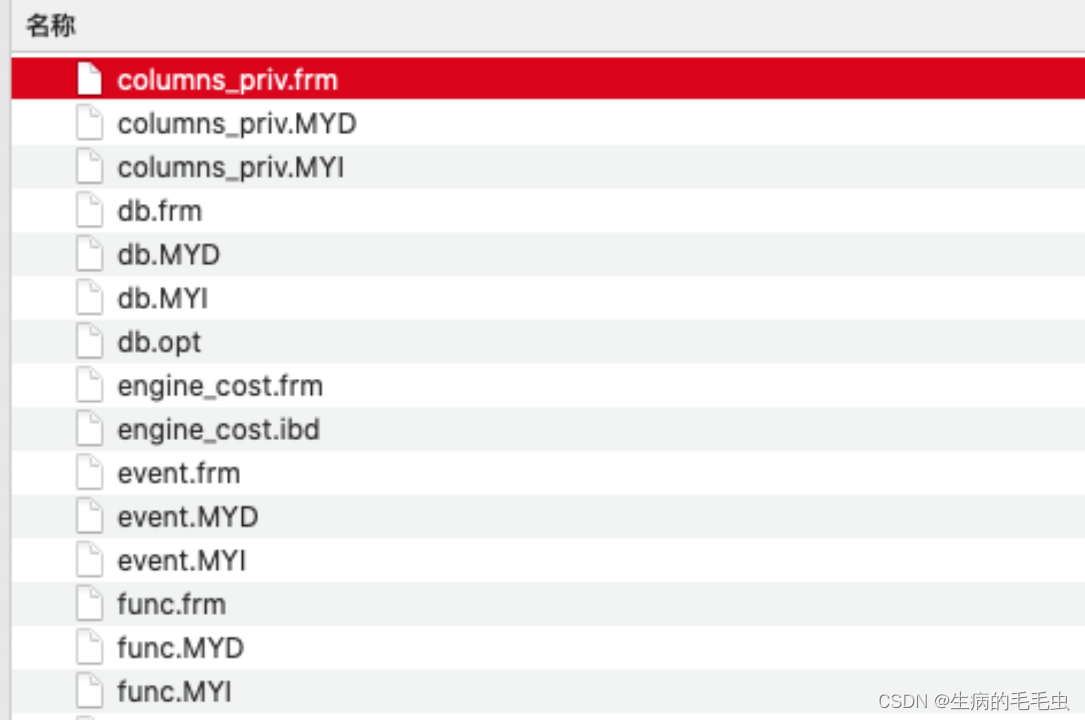
- 如下图中mysql的文件形式,其中的idb文件就是使用innodb存储引擎来实现数据存储生成的文件,其他后缀的文件是其他存储引擎生成的,因此无论什么引擎,索引方式,数据结构最终都是要落文件的
- 传统数据库的基本结构如下:

- MySql包括Server层和存储引擎层:Server层包括,连接器,查询缓存,分析器,优化器,执行器
- 连接器:负责和客户端建立连接
- 查询缓存:MySql获取到查询请求后,会先查询缓存,如果之前已经执行过一样的语句结果会以Key-value的形式存储到内存中,key是查询语句,value是查询结果。缓存明中的话可以很快完成查询,但是大多是情况不能明中,不建议用缓存,因为缓存失效非常频繁,任何对表的更新都会让缓存晴空,所以对一个进程更改的表而言,查询缓存基本不可用,除非是一张配置表。可以通过配置来决定释放开启查询缓存,并且MySql8.0 之间删除了查询缓存功能
- 分析器:词法分析,识别语句中表名,列名,语法分析,判断Sql是否满足MySql语法
- 优化器:在有多个索引的情况下,决定使用哪个索引,或者多表联合查询的时候,表的连接顺序这么执行等
- 执行器:执行器先判断权限,有权限才会去调用存储引擎对应的查询接口,默认InnoDB
数据载体 mongodb & mysql
- 以为mongodb为案例,索引数据存储的结构如下
-
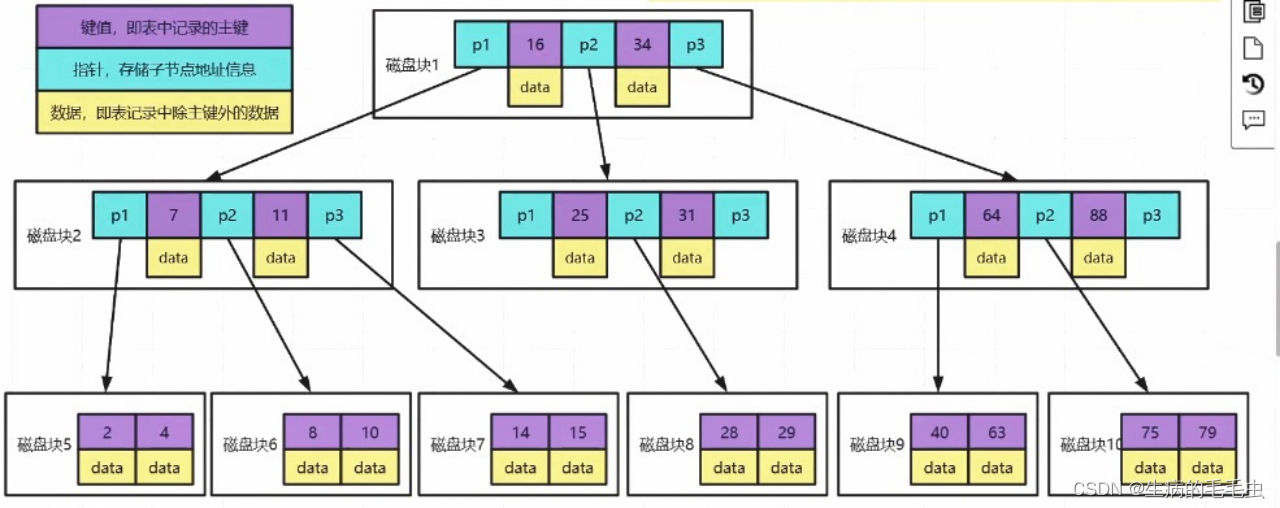
Mongodb索引使用的是B树:B树是多叉平衡查找树,包括以下几个结构特性
- 左子树数据小于跟数据,右子树数据大于根节点数据
- 左右子树高度差不大于1
- 每个节点可以有N个字节的,N>2
-
B树的每个节点都存放 索引 & 数据,数据遍布整个树结构,搜索可能在非叶子结点结束,最好情况是O(1)
-
B树存在的问题:
- 紫色部分存储数据的主键信息,蓝色存储的是指针指向下一个节点,黄色部分是存储的主键对应的数据Data。因此Data是在节点中占比最大的一部分数据,他可能有1M或者更大的一个数据体
- 假设我们一个节点的大小是固定的M,在Mysql中最小的数据逻辑单元是数据页,一个数据页是16KB,如果Data越大,M所能容纳的Data个数就越小,如果需要存储更多的数据则需要更多的节点,B树为了承载更多的节点的同时满足结构特性就需要更多的分叉,因此就导致树的深度更大,每一个层级都意味着一次IO操作导致IO次数更多
-
以为Mysql为案例分析:
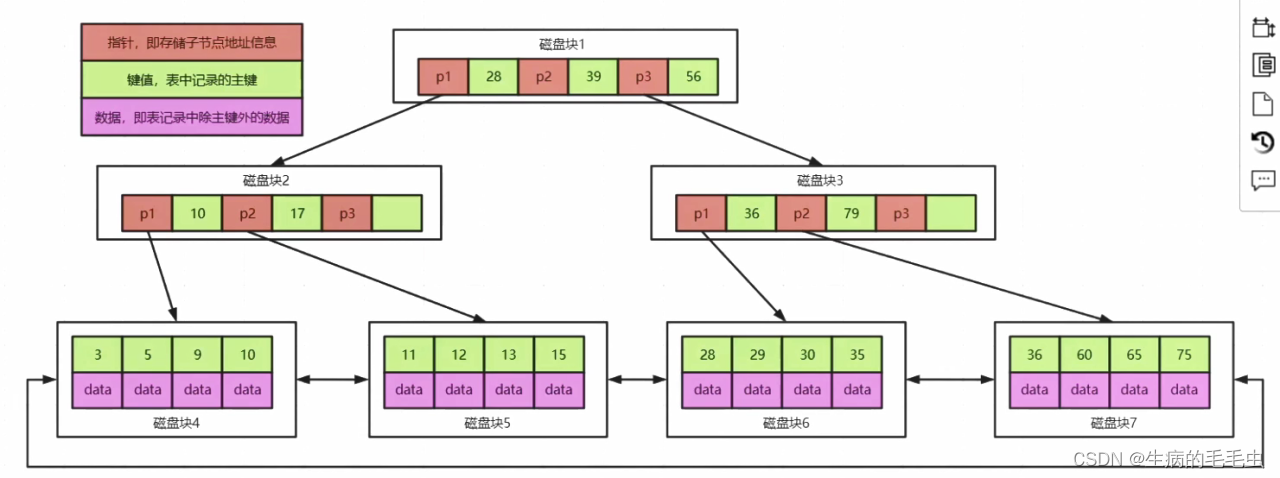
- Mysql中innoDB 使用的索引结构是B+树,
- B+ 树是B树的变种,区别在于:
- 叶子结点保存了完整的索引 & 数据,非叶子结点只保存索引值,因此他的查询时间固定为logn
- 叶子结点中有指向下一个叶子结点的指针,叶子结点类似一个双向链表
- 因为叶子结点有完整数据,并且有双链表结构,因此我们在范围查询的时候能有效提升查询效率。
- 数据都在子节点上,因此非叶子节点就能容纳更多的索引信息,这样就增加了同一个节点的出度,减少了数据Data信息,同一个节点就能容纳更多的其他类型数据信息,因此能用更少的节点来承载索引数据,节点的减少导致树的深度更低,查询的IO次数就变少了。
倒排索引数据结构
- 对如上两个索引结构的分析,我们能看到MySql 无法解决大数据索引问题:
- 第一点:索引往往字段很长,如果使用B+trees,树可能很深,IO很可怕
- 第二点:索引可能会失效
- 第三点:查询准确度差,
- 有如下案例,有1亿条数据的商品信息,我们需要对其中的product字段进行查询,而且是文本信息查询,例如“小米”这个字段查询,那么有如下查询语句:
select * from product where brand like "%小米 NFC 手机%"
-
第一点说明:以上查询语句,我们需要在product上建索引, MySql上使用的B+树,因为文本的信息量特别的大,导致所需要的节点就更多N个16KB(MySql索引中如果一个数据行的大小超过了页的大小16KB,MySQL 会将该行的部分数据存储在行溢出页中。这意味着数据行会被分割,一部分存储在索引页中,而溢出的部分存储在单独的溢出页中),节点数的增加,导致树深度增大查询IO次数增加

-
第二点说明:“%小米 NFC 手机%” 查询中用了左匹配的方式去查询,会导致索引失效,这样导致全表扫描。
-
第三点说明:“小米 NFC 手机%” 去掉左匹配,走索引的方式,则会只查询"小米 NFC 手机"开头的,这样就会导致结果不准确
ElascitSearch索引解决方案
- 对product字段进行分词拆分,得到如下一个词项 与id的匹配关系如下

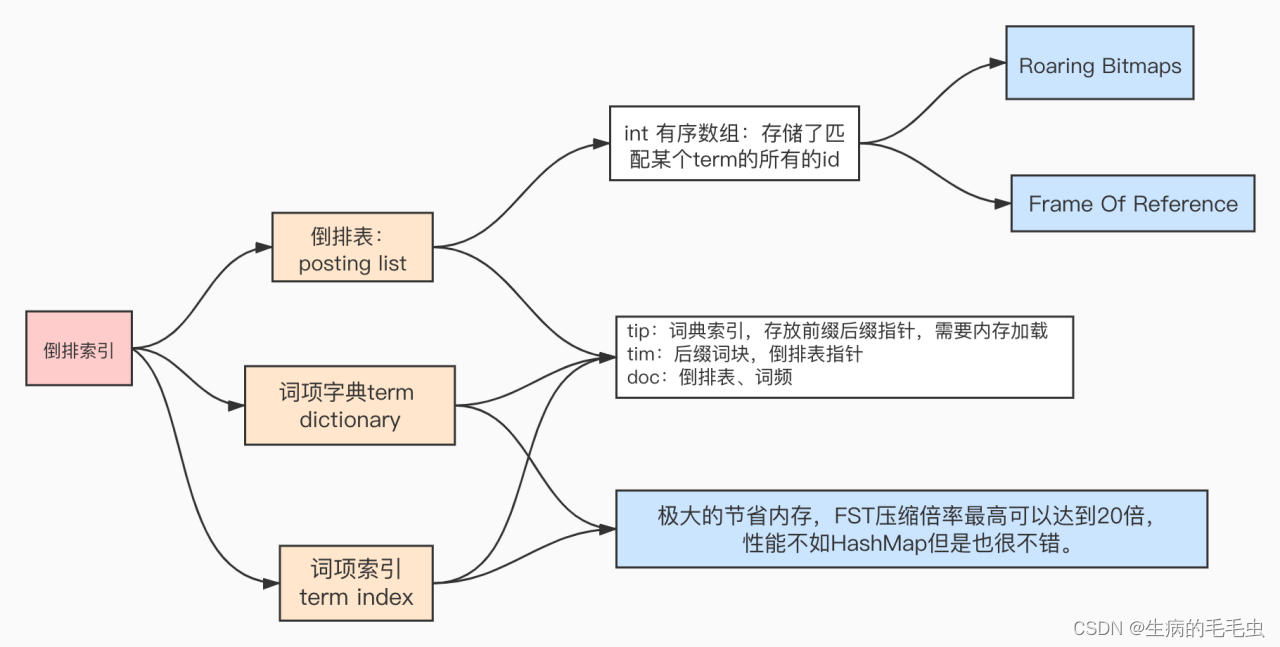
Posting List (倒排表)
- 索引系统通过扫描文章中的每一个词,对其创建索引,指明在文章中出现的次数和位置,当用户查询时,索引系统过就会根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式,利用如上表可以快速完成全文检索
- 在为属性(product)构建倒排索引后,此时,本类别中包含了所有文档中所有字段的一个 分词(term) 文档id对应关系的字典信息,通过倒排索引我们可以迅速找到符合条件的文档,例如“手机” 在文档 1,2,3 中。
Term Dictionary(前缀树)
- 当我们进行Elasticsearch查询,为了能快速找到某个term在倒排表中的位置,ElasticSearch 将类型中所有的term进行排序,然后通过二分法查找term,时间复杂度能达到 logN的查找效率,就像通过字典查找一样,这就是Term Dictionary,整个是二级辅助索引
Term Index(前缀索引)
- 同时参照 B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,将term Dictionary这个构建的Mapping存放在内存中。但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,因此整个ElasticSearch的数据结构如下图
压缩算法
- 倒排表生成后,可能存在如表中,小米关键字匹配到的文档id有 100W个 int类型的有序数组,如果直接存储这个数据的那么需要4Byte * 100w =4MB 的存储空间,因此存储的时候需要用到一定的压缩算法来进行数据压缩
FOR (Frame Of Reference)压缩算法:
- 假设我们获取到的压缩表数组id是[1,2,3,4,5,…100W] 每一个数据占用的存储空间是 4Byte, 总共是100W * 4Byte = 100W * 4 * 8 bit
- 通过计算相邻数据差值 得到数组2 [1,1,1,1,1,1, ,1],总共有100W个1, 这样我们可以将每一个数据用一个bit 来存储,这样就只需要 100W * 1bit 相比于原来 数据 缩小了 32 倍
- 如下图:

-
当然以上是一个特殊的案例,我们用一个相对正常一点的数组来重新计算
-
原数组:[73,300,302,332,343,372] 总共 6*4Byte = 24Byte
-
差值数组:[73,227,2,30,11,29]。我们得到如下结论。 64 < 73 < 128, 128 < 227 < 256, 1<2<4, 16 < 30<32, 8<11<16, 16 < 29 <32,
-
以上数据我们就依然用bit位的存储方式,我们用以上数组中最大的数字所需要的bit位来计算,也就是227 ,用256 来存储 2 8 , 也就是8个bit位每个数字,得到如下
-
[73,227,2,30,11,29]。需要的存储。6 * 8bit = 48bit
-
但是我们发现还是可以有优化空间,比如 2 其实只需要一个bit位即可,因此我们将大数,小数再次做一次分组 [73, 227] 最大28 es中会做一个记录,记录此处数组占用的是8bit。, [2, 30,11,29] 最大25 同样es中做记录此处占用5bit,进一步缩小存储空间。
-
计算整个的存储空间:
- [73, 227] 部分。 8bit - 给es记录存储空间大小是8bit。数字占用 8bit * 2 总共。 8bit * 3 = 3Byte
- [2, 30,11,29] 部分。 8bit - 给es记录存储空间大小是5bit, 数字占用 5bit * 4 总共。8 bit + 20bit = 4Byte
- 因此总共也就7 Byte的空间占用
-
如下图:

RBM压缩(Roaring bitmaps)
-
有了FOR算法,而且针对于同一种数据结构为什么还需要RBM算法,因为以上数据中案例数组都是比较稠密的数组,也就是他们的差值都是比较小的值,如果有如下数组
-
[1000W, 2000W, 3000W, 4000W, 5000W] 每个数都上千万,差值也是千万级别,这样用FOR算法就没有任何意义了。
-
RBM 案例讲解,有如下案例[1000, 62101, 131385, 132052, 191173, 196658]
-
第一步,我们将数字用二进制表示 ,例如。196658 转二进制是 0000 0000 0000 0011 0000 0000 0011 0010
-
第二步,将二进制分为高16 位: 0000 0000 0000 0011 转十进制是 2,底16位 0000 0000 0011 0010 转十进制是50
-
通过以上步骤我们得到196658 的表示方式(2, 50)
-
也可以通过计算方式得到这两个数字 196658 / 216 得到的值是2, 余数是 50 ,这种计算方式得到我们的推测结果,并且得到的所有数字都小于 2 16= 65536
-
我们将以上数组表示为 [(0,1000), (0,62101), (2,313), (2,980), (2,60101), (2,50)]
-
第三步:用一个container的数据结构来存储以上得到的数据表,
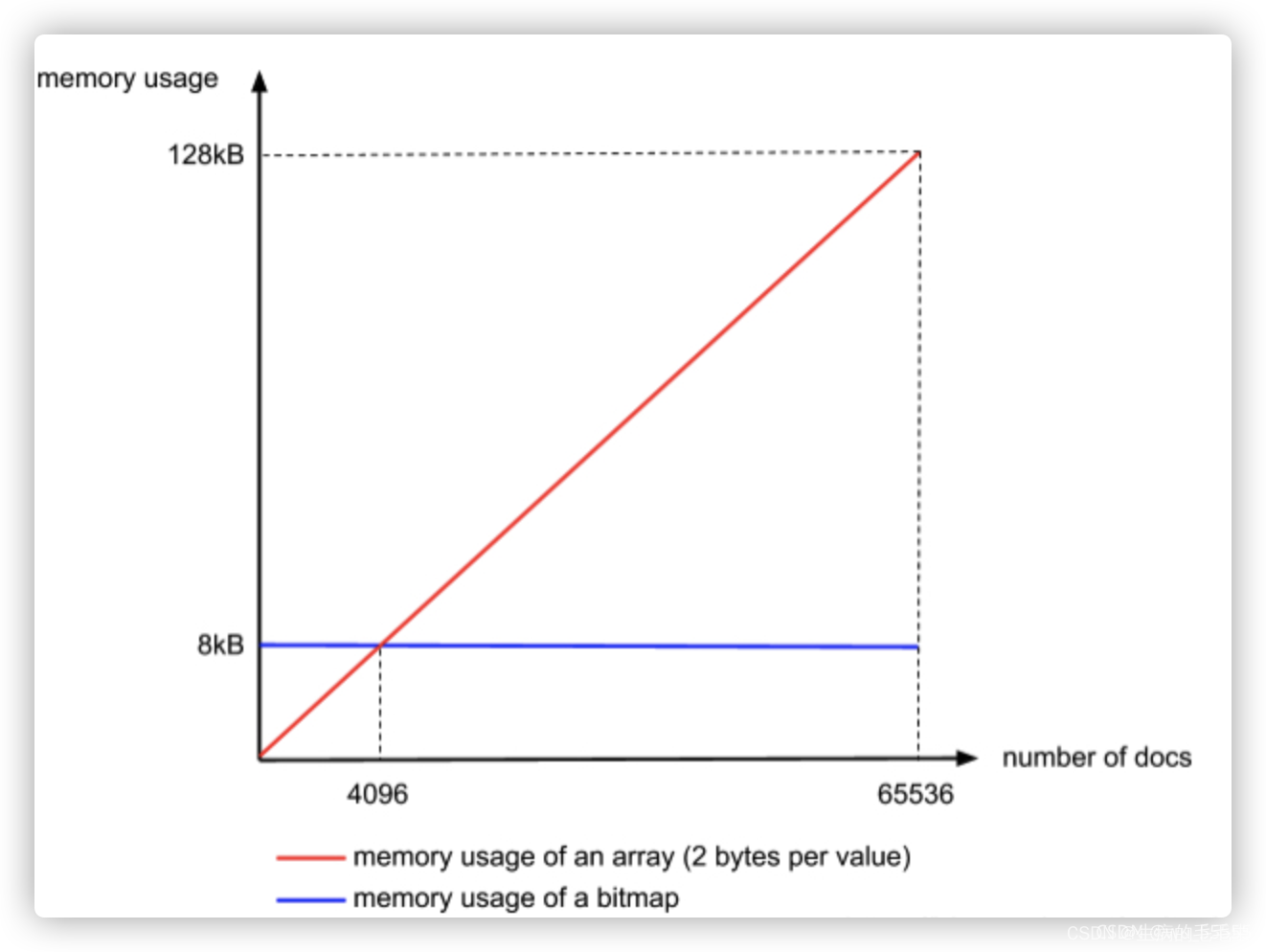
| short[] 数组存储 第一个数字 | Array,bitmap,run 存储第二个数字的组合 |
|---|---|
| 0 | 1000. 62101 |
| 2 | 313,980, 60101,50 |
| 。。。。 | 。。。。 |
- 我们将数字以第一个数字为基准做group by 聚合,得到一个表
- RBM的存储方式有三种 ArrayContainer,BitMapContainer,RunContainer 三种
- ArrayContainer存储short 类型的数组,short类型,最大是216 正好可以存储下所有数据的极限,而第一个位置中的数字,最大也就是65535,因为我们通过X/65535 X最大也就是232 因此,最多也就是。65535个行,同样一个Array最多也是存储65536个id,计算总存储占用
- short 2Byte = 16bit, 总共有65536个。65536* 2Byte / 1024 = 128KB,因此一个行的数据最多存储128KB
- BitMapContainer存储位图,存储的数据必须是不一样的数据,因为避免冲突,bitmap每一位不为0 的位都代表当前位的数据存在,比如第10位 1,表示数组中存在1 ,因此如果有数组[1,2,3,4,5,6,7], bitMap对应的就是7个bit位
- 如果65536 个数字都是不一样的,那么用一个 65536 个bit位置的bitMap存储即可,总共 65536 bit / 8 / 1024 = 8KB
- 缺点是必须每个数字不一样
- RunContainer存储:按照如上思路如果存在如下特殊的数组[1,2,3,4,5,…100W] ,那么可以表示为(1, 100W)压缩到极致,比例取决于连续数字的多少
- 安以上三种算法,有如下图表示

Term Dictionary & Term Index
- 构建好倒排表之后,就又能力快速找到某个term对于的文档id,然后通过id查找磁盘上的segment,新的问题产生了,加入又1亿数据,那么term可能又上百万,挨个便利就炸了
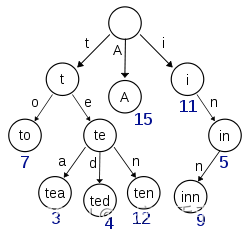
- ElasticSearch为了快速找到对应term,讲term按数组排序,排序后二分查找,以logN的查询时间复杂度完成查询,这样就构建了一个类似如下的term Dictionary
[aaa, aba, abb,abc, allen, .... ,sara,sarb,sarc,....selena.....]
- 即使是logN的时间复杂的,在存在磁盘操作的情况 + 大数据量情况也是非常慢的,如果讲term dictionary加载到内存,十万级别的数据量可能就把内存沾满了,因此需要另外一个更晓的数据来对term dictionary进行替代到内存中进行查询,他就是 term index
- 构建term index 过程: 便利所有 term dictionary 中的数据,按字符拆分,构建成b-tree,例如aaa 构建成 a-a-a,其他分支依然按字符拆分,如下图
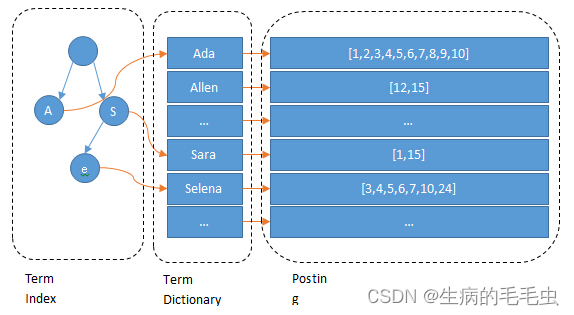
- 以上前缀表中不会包含所有的term信息,它包含的是term的前缀信息,例如 aaa,aab,aac 都存在aa前缀,通过term index可以快速地定位到term dictionary的某个offset,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。如下图:
FST 压缩算法
- 假设我们要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map<string, integer=“”>,大家找到自己的位置对应入座就好了,但从内存占用少的角度看可以用FST来进行压缩后在存储到内存。如下图
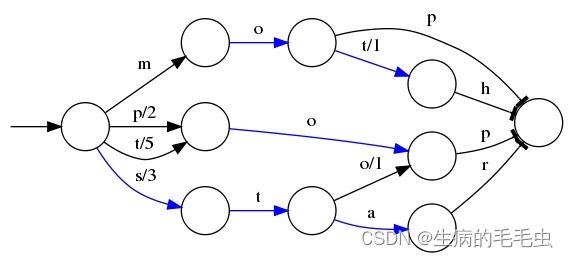
- O表示一种状态
- –>表示状态的变化过程,上面的字母/数字表示状态变化和权重
- 将单词分成单个字母通过⭕️和–>表示出来,0权重不显示。如果⭕️后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
- FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
相关文章:
Interview preparation--elasticSearch倒排索引原理
搜索引擎应该具备哪些要求 查询速度快 优秀的索引结构设计高效率的压缩算法快速的编码和解码速度 结果准确 ElasiticSearch 中7.0 版本之后默认使用BM25 评分算法ElasticSearch 中 7.0 版本之前使用 TP-IDF算法 倒排索引原理 当我们有如下列表数据信息,并且系统…...
配置bond0的mac地址为指定子网卡的mac地址)
银河麒麟高级服务器操作系统V10SP2(X86)配置bond0的mac地址为指定子网卡的mac地址
银河麒麟高级服务器操作系统V10SP2(X86)配置bond0的mac地址为指定子网卡的mac地址 一 系统环境二 删除和备份原有配置2.1 down掉bond02.2 备份之前的bond配置到/root/bak2.3 删除bond配置(网卡文件根据实际情况变化) 三 新建bond0…...

python中不同维度的Tensor向量为何可以直接相加——广播机制
文章目录 广播机制示例解释广播机制如何工作代码示例输出解释广播机制的本质 在矩阵加法中,如果两个张量的形状不同,但其中一个张量的形状可以通过广播机制扩展到与另一个张量的形状相同,则可以进行加法操作。广播机制在深度学习框架…...

38.MessageToMessageCodec线程安全可被共享Handler
handler被注解@Sharable修饰的。 这样的handler,创建一个实例就够了。例如: ByteToMessageCodec的子类不能被@Sharable修饰 如果自定义类是MessageToMessageCodec的子类就是线程共享的,可以被@Sharable修饰的 package com.xkj.protocol;import com.xkj.message.Message; i…...

Linux中的全局环境变量和局部环境变量
Linux中的全局环境变量和局部环境变量 一、全局环境变量二、局部环境变量三、 设置全局环境变量 bash shell用一个叫作环境变量 (environment variable)的特性来存储有关shell会话和工作环境的信息(这也是它们被称作环境变量的原 因ÿ…...
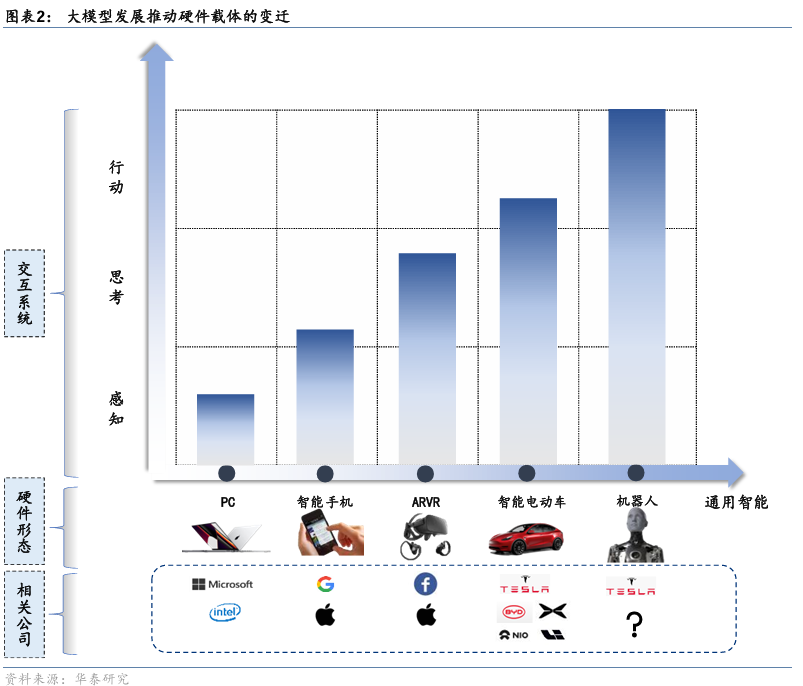
【研究】AI大模型需要什么样的硬件?
关注AI大模型 x 硬件的两条思路 从22年11月OpenAI推出ChatGPT至今,我们看到Chatbot应用的能力不断增强,从最初的文字问答,迅速向具有自主记忆、推理、规划和执行的全自动能力的AI Agent发展。我们认为端侧智能是大模型发展的重要分支。建议投…...

人工智能--自然语言处理NLP概述
欢迎来到 Papicatch的博客 目录 🍉引言 🍈基本概念 🍈核心技术 🍈常用模型和方法 🍈应用领域 🍈挑战和未来发展 🍉案例分析 🍈机器翻译中的BERT模型 🍈情感分析在…...
基于Java微信小程序火锅店点餐系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟感兴趣的可以先收藏起来,还…...

SpringCloud_GateWay服务网关
网关作用 Gateway网关是我们服务的守门神,所有微服务的统一入口。 网关的核心功能特性: 请求路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务&a…...

使用Dropout大幅优化PyTorch模型,实现图像识别
大家好,在机器学习模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络时,过拟合具体表现在模型训练数据损失函数较小,预测准确率较高,但是在测…...

Vue3中的常见组件通信(超详细版)
Vue3中的常见组件通信 概述 在vue3中常见的组件通信有props、mitt、v-model、 r e f s 、 refs、 refs、parent、provide、inject、pinia、slot等。不同的组件关系用不同的传递方式。常见的撘配形式如下表所示。 组件关系传递方式父传子1. props2. v-model3. $refs4. 默认…...
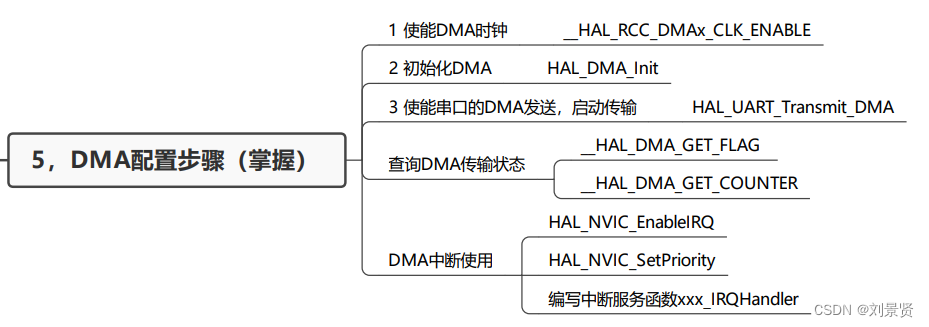
Stm32的DMA的学习
一,介绍 二,DMA框图 三,DMA通道 四,相关HAL库函数 五,配置DMA 六,Stm32CubeMX配置 【13.1】减少CPU传输负载 DMA直接存储器访问—Kevin带你读《STM32Cube高效开发教程基础篇》_哔哩哔哩_bilibili...
)
应用安全(补充)
Nessus是目前全世界最多人使用的系统漏洞扫描与分析软件。NMAP是一个网络连接端扫描软件,用来扫描网上电脑开放的网络连接端。X-SCAN安全漏洞扫描工具AppScan是IBM的一款web安全扫描工具,可以利用爬虫技术进行网站安全渗透测试,根据网站入口自…...

鸿蒙开发Ability Kit(程序框架服务):【FA模型切换Stage模型指导】 app和deviceConfig的切换
app和deviceConfig的切换 为了便于开发者维护应用级别的属性配置,Stage模型将config.json中的app和deviceConfig标签提取到了app.json5中进行配置,并对部分标签名称进行了修改,具体差异见下表。 表1 配置文件app标签差异对比 配置项FA模型…...

通过命令行配置调整KVM的虚拟网络
正文共:1234 字 20 图,预估阅读时间:2 分钟 在上篇文章中(最小化安装的CentOS7部署KVM虚拟机),我们介绍了如何在最小化安装的CentOS 7系统中部署KVM组件和相关软件包。因为没有GUI图形界面,我们…...

Apache POI操作excel
第1部分:引言 1.1 Apache POI简介 Apache POI是一个开源的Java库,用于处理Microsoft Office文档。自2001年首次发布以来,它已经成为Java社区中处理Office文档事实上的标准。Apache POI支持HSSF(用于旧版本的Excel格式࿰…...

Python错误集锦:faker模块生成xml文件时提示:`xml` requires the `xmltodict` Python library
原文链接:http://www.juzicode.com/python-error-faker-exceptions-unsupportedfeature-xml-requires-the-xmltodict-python-library 错误提示: faker模块生成xml文件时提示: xml requires the xmltodict Python library Traceback (most r…...

Vue3-尚硅谷笔记
1. Vue3简介 2020年9月18日,Vue.js发布版3.0版本,代号:One Piece(n 经历了:4800次提交、40个RFC、600次PR、300贡献者 官方发版地址:Release v3.0.0 One Piece vuejs/core 截止2023年10月,最…...

RockChip Android12 System之MultipleUsers
一:概述 System中的MultipleUsers不同于其他Preference采用system_dashboard_fragment.xml文件进行加载,而是采用自身独立的xml文件user_settings.xml加载。 二:Multiple Users 1、Activity packages/apps/Settings/AndroidManifest.xml <activityandroid:name="S…...

第12天:前端集成与Django后端 - 用户认证与状态管理
第12天:前端集成与Django后端 - 用户认证与状态管理 目标 整合Django后端与Vue.js前端,实现用户认证和应用状态管理。 任务概览 设置Django后端用户认证。创建Vue.js前端应用。使用Vuex进行状态管理。实现前端与后端的用户认证流程。 详细步骤 1. …...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...
动态规划-1035.不相交的线-力扣(LeetCode)
一、题目解析 光看题目要求和例图,感觉这题好麻烦,直线不能相交啊,每个数字只属于一条连线啊等等,但我们结合题目所给的信息和例图的内容,这不就是最长公共子序列吗?,我们把最长公共子序列连线起…...

深入解析 ReentrantLock:原理、公平锁与非公平锁的较量
ReentrantLock 是 Java 中 java.util.concurrent.locks 包下的一个重要类,用于实现线程同步,支持可重入性,并且可以选择公平锁或非公平锁的实现方式。下面将详细介绍 ReentrantLock 的实现原理以及公平锁和非公平锁的区别。 ReentrantLock 实现原理 基本架构 ReentrantLo…...

OpenHarmony标准系统-HDF框架之I2C驱动开发
文章目录 引言I2C基础知识概念和特性协议,四种信号组合 I2C调试手段硬件软件 HDF框架下的I2C设备驱动案例描述驱动Dispatch驱动读写 总结 引言 I2C基础知识 概念和特性 集成电路总线,由串网12C(1C、12C、Inter-Integrated Circuit BUS)行数据线SDA和串…...