6.26.1 残差卷积变压器编码器的混合工作流程用于数字x线乳房x光片乳腺癌分类
基于残差卷积网络和多层感知器变压器编码器(MLP)的优势,提出了一种新型的混合深度学习乳腺病变计算机辅助诊断(CAD)系统。利用骨干残差深度学习网络创建深度特征,利用Transformer根据自注意力机制对乳腺癌进行分类。所提出的CAD系统具有识别两种情况乳腺癌的能力:情景A(二元分类)和情景B(多重分类)。数据收集和预处理、斑块图像创建和分割以及基于人工智能的乳房病变识别都是执行框架的组成部分,在这两种情况下都得到了一致的应用。提出的人工智能模型的有效性与三个独立的深度学习模型进行了比较:自定义CNN, VGG16和ResNet50。
利用CBIS-DDSM和DDSM两个数据集来构建和测试所提出的CAD系统。测试数据的五重交叉验证用于评估性能结果的准确性。所建议的混合CAD系统取得了令人鼓舞的评估结果,在二元和多类别预测挑战中,总体准确率分别为100%和95.80%。
乳房x线摄影技术是诊断早期乳腺癌的最佳方式。在乳腺癌早期,将癌细胞组织与乳腺组织区分开来并不是一件简单的工作,特别是对于乳腺致密的女性。例如,图1显示了6例个体病例的乳房x线照片。良性和恶性病例均取自乳腺造影筛查数字数据库(CBIS-DDSM)数据集的拓展乳腺成像子集,而正常病例取自乳腺造影筛查数据库(DDSM)数据集。
一些乳腺病例的组织强度高,特征多样,放射科医生很难用肉眼区分正常组织和异常组织。在这种情况下,假阳性率会增加,导致乳房图像的错误分类。
在之前的工作[4]中,利用一阶和高阶放射学特征构建了基于CAD的基于乳腺x光片的深度信念网络(DBN)。结果表明,这些特征对疾病预测是有用和可信的。一些有趣的研究如[6-8]显示了影像学放射学特征与复发风险、预后和分子表型之间的关系的重要性,这有助于预测乳腺图像中的恶性概率。
1. 文章贡献
提出了一种新的混合ResNet与变压器编码器(Transformer Encoder)框架,用于从x射线乳房x线摄影数据集自动预测乳腺癌。采用深度学习的ResNet作为骨干网络进行深度特征提取,采用带多层感知器(MLP)的TE对乳腺癌进行分类。
提出一种全面的计算机辅助诊断(CAD)系统,将乳腺癌分为两种情况:二元分类(正常与异常)和多重分类(正常与良性与恶性)。
使用自定义CNN、VGG16和ResNet50三种AI模型与所提出的AI模型在二元和多类分类场景下的性能对比研究。
提出了一种自适应自动图像处理分割三角形算法,用于创建自适应阈值,从整个乳房x光片中提取感兴趣区域(roi)。与传统的二值阈值分割算法相比,该算法能更好地分割边界区域。
增强处理应用于增加图像补丁的数量,以克服过拟合问题,并创建一个足够大的数据集来训练和测试所提出的模型。
创建4个不同补丁大小的异常数据集:256 × 256、400 × 400和512 × 512。当使用较大的贴片尺寸时,所提出的模型记录了最好的结果。
2. 相关工作
2.1 深度学习分类
近年来,深度学习在乳腺癌的医学应用在病灶分割、检测和分类等领域得到了广泛关注[9]。为了提高基于二元或多重分类情况的乳腺癌诊断率,已经探索和开发了几种深度学习模型。与以往的研究一样,使用深度学习YOLO预测器来区分乳房x线照片上的良恶性病例[9-13]。al - antari等[9]提出了一种基于YOLO预测器的深度学习识别框架,用于乳腺图像的检测和分类,以区分良恶性病例。YOLO主要用于从整个乳房x光片中检测乳房肿瘤,分类时使用了三种分类器,分别是Regular前馈CNN、ResNet-50和InceptionResNet-V2。
InceptionResNet-V2分类器的性能最好,DDSM数据集的准确率为97.50%,INbreast数据集的准确率为95.32%。然而,由于微钙化是一种不同的现象,需要不同的检测技术,作者只关注了乳房肿块的检测,而没有关注微钙化问题[14]。
Hamed等[10]使用YOLO分类器通过提出三种检测和分类乳腺癌的过程来识别乳腺图像的良恶性。总体分类性能达到了总体准确率的89.5%。Hamed等[11]也利用基于yolov4的CAD系统识别良性和恶性病变,同时使用Inception、ResNet、VGG等不同的特征提取器将局部病变分类为良性或恶性。基于YOLO-V4模型提出的模型优于其他分类器,在质量位置检测上准确率达到98%,而ResNet的最佳分类准确率为95%。
Aly等[12]使用YOLOv3分类器检测良性肿块和癌性肿块,使用ResNet和Inception模型提取重要特征。所提出的模型能够检测出89.4%的肿块,其中良恶性肿块的识别准确率分别达到94.2%和84.6%。尽管YOLO检测器可以有效地对输入图像进行预测,但很难检测到微钙化物体的小聚类[15]。
CNN技术也被用于乳腺癌的检测和分类[16-25]。Kooi等[16]将基于CNN的CADe系统与依赖手工图像特征的传统CADe系统进行了比较。最终结果表明,基于cnn的CADe系统在低灵敏度下优于传统的CADe系统,而在高灵敏度下两种系统的结果相同。基于cnn的CADe系统的AUC为0.929,参考CADe系统的AUC为0.91。
Xi等人[17]提出了CNN模型,利用计算机辅助检测对乳房x线摄影图像中的钙化和肿块进行分类和定位。根据作者的研究结果,VGGNet具有最好的总体分类准确率,得分为92.53%。Hou等人[18]提出了一项研究,使用基于一类半监督模型的深度卷积自编码器检测乳房x线摄影中的钙化。在验证阶段,该模型的AUROC达到0.959%,AUPRC达到0.676%。该模型检测钙化病变的灵敏度为75%,每张图像的假阳性率为2.5%。根据作者的发现,更先进的模型或更大的数据集并没有提高检测性能。
[19]应用图像纹理属性提取方法和CNN分类器开发了乳腺癌自主识别系统。采用均匀流形逼近和投影(UMAP)对提取的特征进行最小化。该模型在乳腺图像分析学会(MIAS)数据集采集的图像上能够区分正常和异常图像,特异性和准确性分别达到97.8%和98%,在DDSM数据集的图像上,特异性和准确性分别达到98.3%和97.9%。
Pillai等[20]使用VGG16深度学习模型在乳房x光检查中诊断乳腺癌。该模型优于AlexNet、EfficientNet和GoogleNet模型,准确率为75.46%。Mahmood等[21]开发了一种新的基于深度学习的卷积神经网络(ConvNet),大大减少了诊断乳腺癌组织的人为错误。在乳腺肿块分类中,该模型的训练准确率为0.98%,测试准确率为0.97%,灵敏度为0.99,AUC为0.99。
另一项研究使用CNN模型进行特征提取,使用支持向量机(SVM)进行分类阶段[22]。采用了多种深度特征步长融合和主成分分析(PCA)。使用MIAS和INbreast两个数据集,所提出的模型在两个数据集上的分类准确率分别达到97.93%和96.646%。采用主成分分析法,减少了计算量和执行时间;然而,分类性能并没有得到提高。
Gaona和Lakshminarayanan[23]使用了一种CNN模型,该模型利用DenseNet架构对乳房x线摄影图像中的乳腺肿瘤进行检测、分割和分类。 本工作获得的性能矩阵灵敏度为99%,特异性为94%,AUC为97%,准确度为97.7%。
Shen等[24]研究了一组基于CBIS-DDSM数据集乳房x线照片的乳腺癌检测深度学习算法,涉及单个模型和四个模型。在独立检测中,最佳单模型的AUC为88%,而四模型平均的AUC为91%,特异性为80.1%,敏感性为86.1%。此外,还使用了另一个数据集INbreast,其中最佳的单一模型在独立测试中每张图像的AUC为95%,而四模型平均将AUC提高到98%,灵敏度为86.7%,特异性为96.1%。
相比之下,为了避免早期图像质量下降,Roy等[25]使用卷积神经网络(CNN)和连接分量分析(CCA)进行恶性乳腺分割,没有进行任何预处理。采用k均值(KM)和模糊c均值(FCM)对采集到的图像进行分割。采用所建议的混合方法,获得的最佳准确率为90%。最后,[26]中的作者提出了一个基于AlexNet、VGG和GoogleNet的框架,利用单变量技术降低提取特征的维数,提取INbreast数据集上乳房x光片的基本特征。该模型的精密度为98.98%,特异度为98.99%,灵敏度为98.06%,准确度为98.50%。
2.2 Vision Transformer进行图像分类
视觉转换器(vision transformer, ViT)原理被用作一种分类系统,通过将图像划分为固定大小的小块,将其线性拼接为矢量序列,在传统的转换编码器中进行处理[27]。最近,一组研究人员使用该技术来识别良性和恶性病例,即Gheflati等人基于两个乳腺超声数据集检测了纯预训练视觉变压器模型和混合预训练视觉变压器模型的性能[28],证明了使用视觉变压器技术在超声检查中自动检测乳腺肿块的重要性。
另一项工作使用CNN模块提取局部特征,而使用ViT模块识别多个区域之间的全局特征并改进相关的局部特征[29]。混合模型的准确率为90.77%,召回率为90.73%,特异性为85.58%,F1评分为90.73%。
[30]的作者提出了一种基于vit的半监督学习模型,利用超声和组织病理学数据集,其结果优于CNN基线模型(VGG19, ResNet101, DenseNet201)。该模型达到了96.29%的高精度,f1得分为96.15%,准确率达到95.29%。
3. 材料和方法
本文提出了一种基于残差卷积网络和带多层感知器的变压器编码器的混合计算机辅助诊断方法。残差卷积网络作为主干网络用于深度特征生成,TE基于自关注机制用于分类。所提出的深度学习模型需要完成几个步骤,以提高乳房x光照片中乳腺癌检测的准确性,如图2所示。首先,采集到的医学图像采用DICOM格式;为了简单起见,使用内部MATLAB (Mathworks Inc., Boston, MA, USA)代码将这些图像转换为TIFF。然后进行预处理,去除不需要的伪影,增强分割后的乳房图像的边界。然后,进行标记、补丁图像和增强处理。最后,使用生成的patch图像对所提出的AI模型进行训练和测试。

3.1 数据获取和图像收集
使用两个标准的乳房图像数据集来开发和评估所提出的深度学习CAD系统。本研究使用了乳腺筛查数字数据库(DDSM)[31]和DDSM的乳腺成像子集(CBISDDSM)数据集[32]。CBIS-DDSM数据集由放射科医师修订;因此,在CBIS-DDSM中删除了DDSM中一些错误或可疑的诊断图像,使得该数据集适合用于良性或恶性图像。两个数据集都有左右乳房图像的颅尾侧(CC)和中外侧斜位(MLO)视图,这意味着每个病例(即患者)有四个视图:左右乳房序列的两个MLO视图和两个CC视图。
CBIS-DDSM数据集包含1566名患者的6671张乳房图像。实际上,CBIS-DDSM数据集是DDSM原始数据集的修改和标准化版本,仅包含异常病例(即良性和恶性),而原始DDSM数据集包含2620张扫描乳房x光片图像,包括正常、良性和恶性病例。在这项工作中,最终创建的数据集共有4091张乳房图像,包括从DDSM收集的正常病例和从CBIS-DDSM收集的异常病例。每个类别的图像总数定义为998个正常图像,461个良性图像和431个恶性图像。随机将生成的数据集分成80%用于训练,10%用于验证,10%用于测试。这些分割是分层的,以确保训练组、验证组和测试组在每个类中所占的比例相同。来自同一患者的不同MLO和CC视图保存在相同的训练、验证或测试集中,以避免任何准确性偏差并建立可靠的CAD系统。
两个数据集中的所有乳房x光照片都由放射科专家注释,因为它们是公开的[31,32]。与文献一样,领域研究人员总是将原始注释乳腺图像的标签分配到其从该图像提取的patch roi中[4,9,33]。因此,从数据集元数据中获取图像的标签,并为创建的补丁保留标签。例如,如果原始图像具有恶性标签,则提取的补丁图像具有相同的恶性标签,以此类推。此外,这两个数据集都有每个患者的一些信息,包括乳房密度、左乳或右乳、图像视图、异常、异常类型、钙质类型、钙质分布、评估、病理和细微信息[31,32,34]。
3.2 数据准备和预处理
乳房x光照片是DICOM格式的。在使用乳房x线照片之前,使用MIRCODICOM软件[35]将收集到的所有图像转换为TIFF格式。
之所以选择TIFF格式,是因为它能够以无损格式保存DICOM图像,并且可以用于高质量的存档目的[36,37]。将DICOM图像转换为TIFF格式后,进行预处理步骤。在预处理步骤中,去除不需要的伪影特征,然后对乳房图像的边界进行平滑处理。为了从每张乳房x射线照片中去除不需要的伪影,使用了图像阈值分割技术[38,39],这是一种图像处理分割技术,用于将乳房x射线衰减像素与背景像素分离。事实上,这样的过程被用来将彩色或灰度图像转换为二值格式,以便在整个乳房x光片中轻松区分不同的区域。在阈值处理过程中,将每个图像像素值与阈值进行比较;如果像素值小于阈值,则变为0(黑色区域或背景);否则,它将变为最大值(白色区域)。
阈值技术有不同的操作类型,如THRESH_BINARY、THRESH_OTSU和THRESH_TRIANGLE,这些操作类型可以由OpenCV库提供[38,39]。THRESH_BINARY是一种简单的阈值分割技术,它依赖于定义的自适应阈值对图像进行相应的分割,而THRESH_OTSU是基于Ostu的阈值分割技术,自动计算阈值对乳房和背景区域进行分割[38,39]。为了达到消除乳房x光检查中不需要的信息的目标,进行了一项全面的调查研究。实验中,发现THRESH_TRIANGLE是最好的[38-40]。三角形算法检查直方图的形状,例如寻找谷、峰和其他直方图形状方面[40]。该算法取决于三个步骤来执行。首先,定义并绘制直方图的最大值bmax和最小值bmin在灰度轴上的直线。其次,估计绘制的直线与直方图中和
之间的所有点之间的垂直欧氏距离d。最后,根据直方图与定义线之间的最大距离选择阈值,生成二值或掩码图像,如图3b-d所示。

数据预处理,提取整个乳房感兴趣区域(ROI),并使用自定义内置图像处理技术去除不需要的信息。(a)原始乳房x线照片,(b)使用THRESH_OTSU算子生成的图像二值掩码,(c)使用THRESH_BINARY算子生成的图像二值掩码,(d)使用THRESH_TRIANGLE算子生成的图像二值掩码,以及(e)应用处理技术后对应的乳房图像
在将胸部图像与黑色背景分离方面,THRESH_TRIANGLE算子优于其他算子,如图3d所示。虽然THRESH_TRIANGLE算子的分割面积比THRESH_BINARY大,但在对Mask图像进行平滑处理后,在不损失乳房图像边界的情况下,可以得到一个很好的分割区域。在获得乳房图像的掩模后,利用形态学图像处理技术,通过“morphologyEx”函数对乳房的边界进行平滑处理,平滑去除乳房x线照片的噪声[38]。通过“connectedComponentsWithStats”函数[38],使用连接分量分析(CCA)技术选择最大的对象,该方法通常可以使用连接分量标记对二值图像中的blobs进行更详细的过滤。最后,为了构建没有不良伪影的乳房图像的ROI,应用“bitwise and”函数将原始图像与其关联的最终二值掩模图像相乘,如图3e所示。
3.3 创建补丁
为了获得更准确的学习过程,深度学习模型是基于乳房病变区域而不是使用整个乳房x光片进行训练的。众所周知,与乳腺肿瘤大小相比,乳腺图像的尺寸非常大,因此训练期间的权值微调过程必须只关注肿瘤区域,以获得更准确的深度学习参数(即网络权值和偏差)[33]。在之前的研究中,由于缺乏这样一个精确的基于补丁的CBIS-DDSM数据集[9,13,33],因此采用了先前的乳房病变检测程序,从输入的整张乳房x光片中自动提取乳房病变。然而,在此过程中,为了从整个乳房x光片中生成补丁图像,采用了补丁提取和增强两种方法。第一种方法从DDSM数据集中提取正常补丁,第二种方法从CBIS-DDSM数据集中提取异常良性和恶性补丁。
对于正常的补丁提取,需要依次进行如下步骤:
- 对从DDSM收集的每张图像进行数据预处理后,最终分割后的图像(或称为“分割图像”)准备好了,可以进行下一步操作,即创建一组块。
- 从每个图像创建一组256 × 256的补丁。计算所创建补丁的上阈值、下阈值、平均值和方差。这些tiles是从分割图像中选取的,可能覆盖了图像中的不同区域,包括乳腺组织、异常区域(如肿块、钙化点等)以及可能的背景区域。
对于不正常的补丁提取,需要依次进行如下步骤:
Step 1: 图像预处理
- 在从CBIS-DDSM数据集中收集的每个图像上应用数据预处理步骤。
- 经过预处理后,分割的图像准备用于创建一组块。
Step 2: 使用已裁剪的补丁图像
- CBIS-DDSM数据集中的原始乳腺X光图像包含由放射科医生审查过的良性和恶性肿块的已裁剪补丁图像。
- 这些已裁剪的补丁图像被直接使用来创建512 × 512像素大小的切片。
- 选择512 × 512像素大小是因为已裁剪的补丁图像的大小各不相同,有的小于这个大小,有的大于这个大小。
Step 3: 对小于512 × 512像素的补丁进行零填充
- 如果已裁剪的补丁图像小于512 × 512像素,这个补丁会被放在一个512 × 512像素的切片中,起始位置为(0,0)。
- 接着,自动应用零填充(zero padding)过程,以维持所需的固定大小512 × 512像素。
Step 4: 对大于512 × 512像素的补丁进行分割
- 如果已裁剪的补丁图像大于512 × 512像素,会创建多个切片。
- 切片从左上角开始,沿着水平方向从左到右,以及沿着垂直方向从上到下创建。
- 这个过程是为了避免对生成的异常补丁进行下采样(down-sampling)。
Step 5: 将每个切片分割成256 × 256像素的tiles
- 经过上述步骤后得到的每个512 × 512像素的切片会被进一步分割成两个256 × 256像素的tiles。
应用这两个程序后,共创建了15790个补丁图像,其中正常补丁8860个,异常补丁6930个,其中恶性补丁3348个,良性补丁3582个。该数据集用于训练和测试所提出的深度学习CAD系统。所有正常的斑块存放在一个文件夹中,异常的斑块也存放在另外两个文件夹中:一个文件夹为良性,一个文件夹为恶性。所有生成的补丁文件名对于正常文件使用' PatientID_View_Side_Tile_Tile-Number.tif '格式,对于异常文件使用' PatientID_View_Side_Cropped_CroppedNumber.tif '格式。
 3.4 数据分割
3.4 数据分割
本研究考虑了所有在CBIS-DDSM数据集中有乳腺肿块的患者,而正常病例则从DDSM数据集中收集。针对场景A(二元分类问题)和场景B(多类分类问题),采用两种策略对生成的补丁进行分割。对于场景A(二元分类),生成的数据集如表1所示。
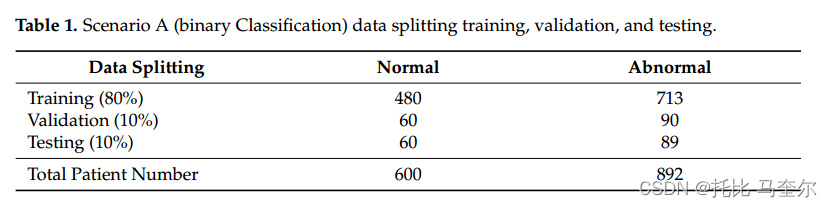 遵循第二种策略为场景B(多类分类)准备数据集。表2显示了每一组的数据分布:训练、测试和验证。
遵循第二种策略为场景B(多类分类)准备数据集。表2显示了每一组的数据分布:训练、测试和验证。

3.5 迁移补丁
应用补丁创建过程后,生成的两个文件夹(命名为“X”和“Y”)保存所有补丁。还使用已创建的具有患者id的CSV文件指导此过程,以便将每个补丁传输到目标文件夹:train、val或test文件夹。为了使用第一种策略创建数据集,创建了三个文件夹:train、val和test文件夹,它们分别被命名为“Tr”、“Va”和“Te”。在每个文件夹中,创建了两个名为“Normal”和“Abnormal”的文件夹。
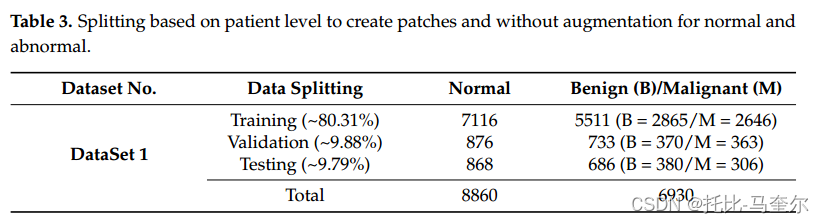
为了将“X”和“Y”中的所有补丁转移到“Tr”、“Va”和“Te”文件夹的子文件夹中,读取每个补丁的文件名;如果表1中的患者id列表中存在此名称,则使用行名(“Training”名称表示将文件传输到“Tr”文件夹)和列名将该文件传输到正确的子文件夹(“Normal”,“Abnormal”)来复制该补丁。第一个数据集是在没有应用增强过程的情况下创建的,如表3所示。
3.6 数据增强
数据增强的过程仅在基于患者水平分割数据集后应用于训练集。在训练和测试过程中,增强过程对于创建平衡数据集和消除过拟合非常重要。增强补丁的标签必须与原始补丁图像保持一致。依赖以下步骤来创建两个数据集:
步骤1:为了扩大训练集的数量,必须通过基于NumPy函数“flip”应用flip来创建新的补丁。根据两个返回值,分别在垂直和水平方向上进行两次翻转[41](1:执行翻转;0:取消翻转)来自一个名为binomial的NumPy函数,该函数负责根据二项分布绘制样本[42]。二项分布(BD)由

步骤二:在原点周围使用不同角度进行旋转:[5◦,10◦,15◦,20◦]。
表3中正常斑块数量为7116个,恶性斑块2646个,良性斑块2865个。首先,为了增加具有额外补丁的良性案例,该过程依赖于从第一个补丁文件开始到最后一个补丁文件,为良性文件夹中的每个补丁创建新的类似补丁来增加原始补丁。这个步骤重复了几次,直到良性文件夹中的文件总数达到7116。每个补片在补片过程中,应用步骤1和补片步骤2的角度[5◦,10◦,15◦,20◦],其中每个补片应用第一圈5◦角度,第二圈10◦角度,以此类推。同样的程序也适用于为恶性病例制作额外的贴片。
具体来说,对于每个补丁,首先应用步骤1,然后在步骤2中使用了[5°, 10°, 15°, 20°]这四个角度。这意味着每个补丁首先被旋转5°,然后再次应用相同的增强过程但这次旋转10°,依此类推,直到所有四个角度都被应用。
表4展示了在增强过程后的最终数据集。

256 × 256的patch图像不足以区分良性和恶性病例,因为一些重要的特征在patch之间被划分。因此,对patch的创建进行了修改,创建了新的patch图像(400 × 400和512 × 512),而没有进行增强,增强会取到更大尺寸的良性和恶性特征,不同的是,可疑区域的ROI被分割成400 × 400或512 × 512的切片,而不是将每个区域分割成更小的补丁。表5总结了使用400 × 400和512 × 512补丁大小时新创建的数据集。提高了整体精度,特别是512 × 512补丁大小。
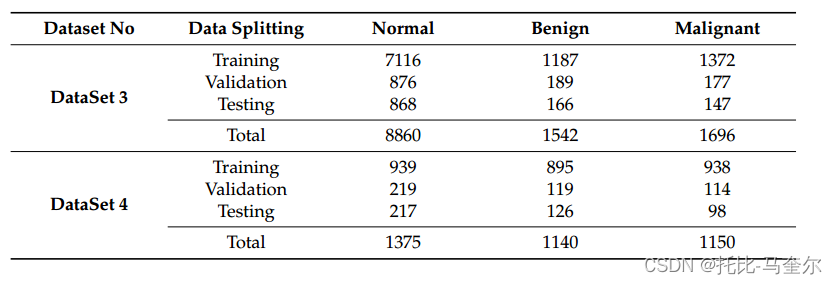
根据患者水平进行分割,创建(400 × 400, 512 × 512)块,对正常、良性和恶性病例进行增强
3.7 推荐的深度学习模型
首先,一个深度学习模型是由使用改进的深度卷积神经网络(CNN)模型,而第二个模型主要依赖于基于迁移学习原理的预训练VGG16。在迁移学习的基础上,利用预训练的ResNet50模型。最后,基于这些模型应用Vision Transformer (ViT),因此,一些实验是单独基于这三个模型进行的,另一些实验是使用ViT技术与ResNet50模型一起进行的。
3.8 自定义CNN模型
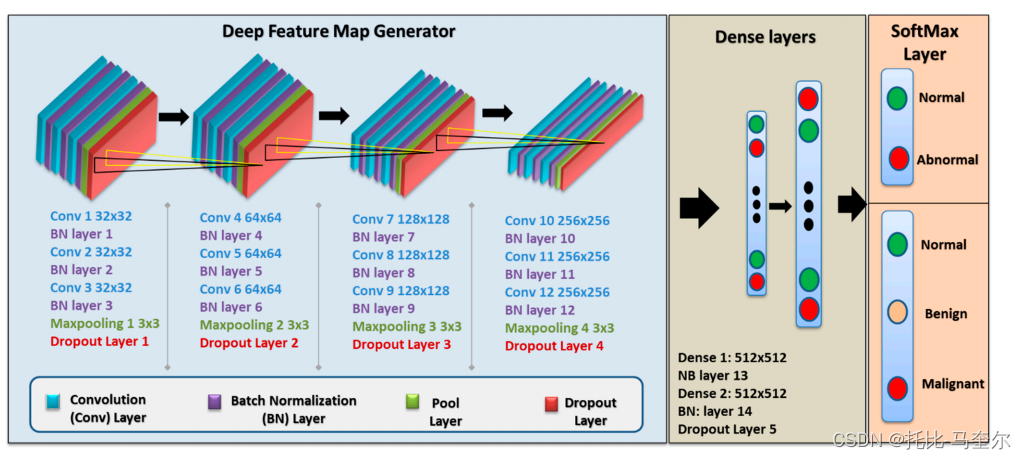
本文的改进模型是通过使用改进的深度卷积神经网络(CNN)模型来实现的,该模型在一组乳房x光片斑块上进行训练,将其分类为正常或异常病例。
最终的自定义CNN模型包括一个VGG (Visual Geometry Group)序列型结构,该结构有五个块,每个块包含三个带有小3 × 3滤波器的卷积层,一个最大池化层,最后是一个dropout层。该模型在每一层之后都进行了批归一化处理,具有正则化效果,加快了收敛速度。应用于每个卷积层的滤波器为3 × 3,激活函数为ReLU, ' same '用于填充,' he_uniform '用于内核初始化,保证输出的特征映射具有相同的宽度和高度。该模型在所有层中实现的stride和padding值分别为1和0, dropout率为25%。采用随机梯度下降法,即Adam优化器,这是一种依赖于一阶和二阶矩自适应估计的方法[43]。
常用的 padding 方式有“valid”和“same”。其中,“valid”意味着不进行任何 padding,而“same”意味着进行足够的 padding,使得输出特征图的空间维度与输入特征图相同(不考虑深度或通道数)
“He uniform”是一种常用的初始化方法,基于ReLU(或类似的)激活函数,并根据输入和输出神经元的数量来设置权重的初始值。使用“He uniform”或其他合适的初始化方法可以帮助神经网络在训练过程中更快地收敛,并可能提高最终的性能。
3.9 基于人工智能的VGG16模型
VGG16是一个广泛参与计算机视觉和机器学习领域分类任务的CNN。实现了基于ImageNet数据集的预训练VGG16模型,但去除了该模型中的分类层。因此,对于达到最佳性能的二元分类和多重分类,增加了两个新的分类层。对于二值分类,该模型的分类层分为两个块:每个块由一个具有512个神经元的常规层组成,然后分别添加Batch Normalization层和dropout层,dropout率为50%。最后,多重分类中的分类层有三个块:每个块有一个4090个神经元的常规层,然后分别添加Batch Normalization层和dropout层,dropout层的dropout率为50%
3.10 基于人工智能的ResNet50模型
ResNet-50是一个50层深度卷积神经网络,已经应用于图像识别任务。与预训练的VGG16模型一样,本文基于ImageNet数据集对ResNet50模型进行训练,并删除了分类层;因此,使用与VGG16模型相同的配置,在该模型中添加了两个用于二元分类的块和三个用于多重分类的块。VGG16包含1.38亿个参数,而ResNet50有2550万个参数,加上ResNet50中应用的配置,使其运行速度更快。
3.10 基于人工智能的混合ResNet和Transformer Encoder
ViT-b16模型将输入图像的16 × 16个二维块线性组合成一维向量,送入由多头自注意(MSA)和多层感知器(MLP)块组成的变压器编码器,如图2所示。MSA用于寻找单个输入序列中每个patch与所有其他patch之间的关系,它采用缩放后的点积注意力,可由式(2)计算:
表示乘积
的方差,其均值为零。此外,乘积可以通过除以标准差
进行归一化。通过SoftMax函数将缩放后的点积转换为注意力分数。
多层感知器层(MLP)块被设计为三个块:每个块由高斯误差线性单元(GELU) 40、90个神经元的非线性层、批处理归一化和dropout层组成,其中所有dropout层的丢弃率为50%。
4. 实验结果及讨论
4.1 场景A:二元分类:正常与异常
对于二值分类,采用自定义CNN、VGG16、ResNet50和混合(ResNet50 + ViT)模型进行比较。使用ImageNet对VGG16和ResNet50的深度学习模型进行预训练。基于迁移学习策略,研究使用了预训练的权重。除了VGG16模型中从17开始的层(' block5_conv3 ')到输出层是可训练的,其他所有层都是不可训练的,而ResNet50模型中从143开始的层(' conv5_block1_1_conv ')到最后一层是只能训练的。为了比较四种模型的最终结果,所有模型上的分类层都是相同的,使用的优化器是Adam。此外,输出层或分类层使用了不同的单元,但当单元数为512时,准确率最高。学习速率为0.0001,每个模型的epoch数为25。在这种情况下,进行了两种类型的实验来比较四种模型的整体性能:一种依赖于单一测试而不应用k-fold交叉验证技术,而第二种实验主要依赖于5-fold交叉验证技术。
首先,混合模型的总体准确率达到100%,优于所有其他模型,而VGG16记录的数值最低,如表7所示。此外,ResNet50错误地将一个异常斑块预测为正常,而VGG16有6个错误预测,自定义CNN模型只有4个错误预测,混合模型实现了最优值,基于混淆矩阵如图6所示。
 4.2 场景B:多分类:正常、良性、恶性
4.2 场景B:多分类:正常、良性、恶性
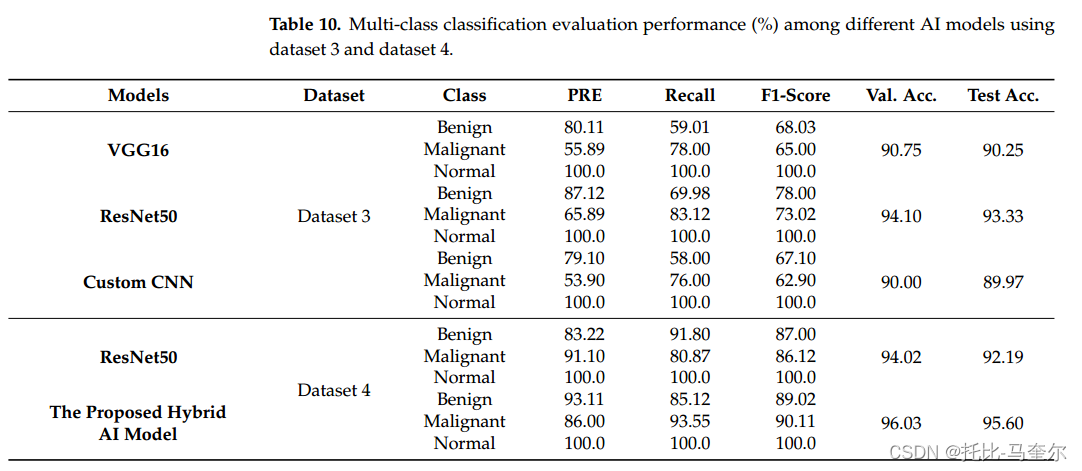
相关文章:
6.26.1 残差卷积变压器编码器的混合工作流程用于数字x线乳房x光片乳腺癌分类
基于残差卷积网络和多层感知器变压器编码器(MLP)的优势,提出了一种新型的混合深度学习乳腺病变计算机辅助诊断(CAD)系统。利用骨干残差深度学习网络创建深度特征,利用Transformer根据自注意力机制对乳腺癌进行分类。所提出的CAD系统具有识别两种情况乳腺…...

[leetcode]avoid-flood-in-the-city 避免洪水泛滥
. - 力扣(LeetCode) class Solution { public:vector<int> avoidFlood(vector<int>& rains) {vector<int> ans(rains.size(), 1);set<int> st;unordered_map<int, int> mp;for (int i 0; i < rains.size(); i) {i…...
Pytorch基础
文章目录 零、tensorboard0.1基本使用案例 一、数据结构:Tensor1.1数据类型1.2Tensor的创建方式1.3张量的基本运算1.4张量的属性 二、数据集加载器DataLoaders2.0前置知识2.0.1torch.scatter()、torch.scatter_() 2.1官方案例2.1.1从TorchVision加载数据集2.1.2迭代…...

嵌入技术Embedding
嵌入(Embedding)是一种将高维数据映射到低维空间的技术,广泛应用于自然语言处理(NLP)、计算机视觉和推荐系统等领域。嵌入技术的核心思想是将复杂的数据表示为低维向量,使其在这个低维空间中保留尽可能多的…...

Pandas中的数据转换[细节]
今天我们看一下Pandas中的数据转换,话不多说直接开始🎇 目录 一、⭐️apply函数应用 apply是一个自由度很高的函数 对于Series,它可以迭代每一列的值操作: 二、⭐️矢量化字符串 为什么要用str属性 替换和分割 提取子串 …...

vue2面试题——路由
1. 路由的模式和区别 路由的模式:history,hash 区别: 1. 表象不同 history路由:以/为结尾,localhost:8080——>localhost:8080/about hash路由:会多个#,localhost:8080/#/——>localhost:…...

【AI应用探讨】—朴素贝叶斯应用场景
目录 文本分类 推荐系统 信息检索 生物信息学 金融领域 医疗诊断 其他领域 文本分类 垃圾邮件过滤:朴素贝叶斯被广泛用于垃圾邮件过滤任务,通过邮件中的文本内容来识别是否为垃圾邮件。例如,它可以基于邮件中出现的单词或短语的概率来…...
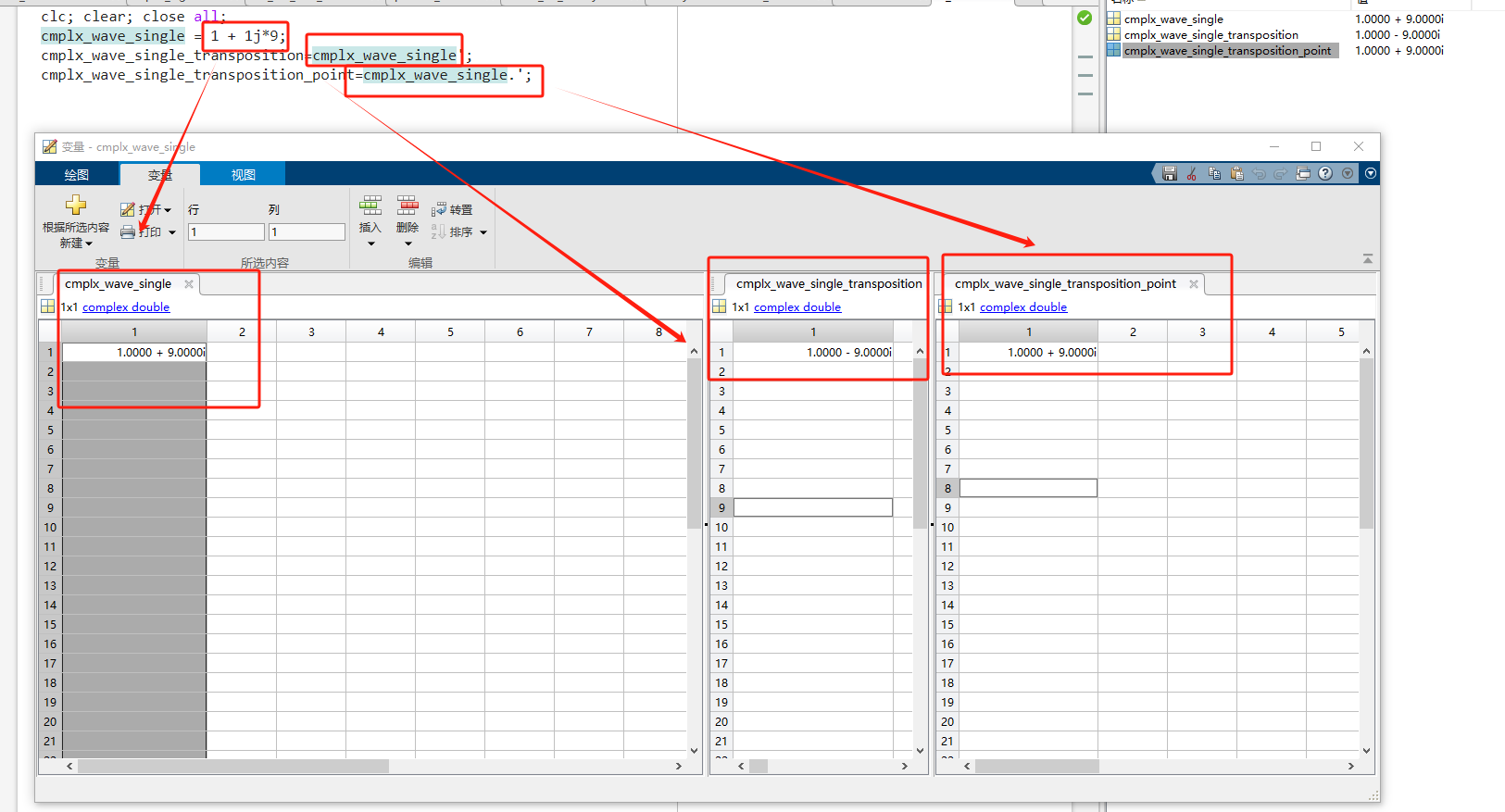
使用matlab的大坑,复数向量转置!!!!!变量区“转置变量“功能(共轭转置)、矩阵转置(默认也是共轭转置)、点转置
近期用verilog去做FFT相关的项目,需要用到matlab进行仿真然后和verilog出来的结果来做对比,然后计算误差。近期使用matlab犯了一个错误,极大的拖慢了项目进展,给我人都整emo了,因为怎么做仿真结果都不对,还…...

昇思25天学习打卡营第8天|保存与加载
1. 学习内容复盘 1.1 保存与加载 上一章节主要介绍了如何调整超参数,并进行网络模型训练。在训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调(fine-tune)和后续的模型推理与部署,本章…...

【vueUse库Animation模块各函数简介及使用方法】
vueUse库是一个专门为Vue打造的工具库,提供了丰富的功能,包括监听页面元素的各种行为以及调用浏览器提供的各种能力等。其中的Browser模块包含了一些实用的函数,以下是这些函数的简介和使用方法: vueUse库Sensors模块各函数简介及使用方法 vueUseAnimation函数1. useInter…...
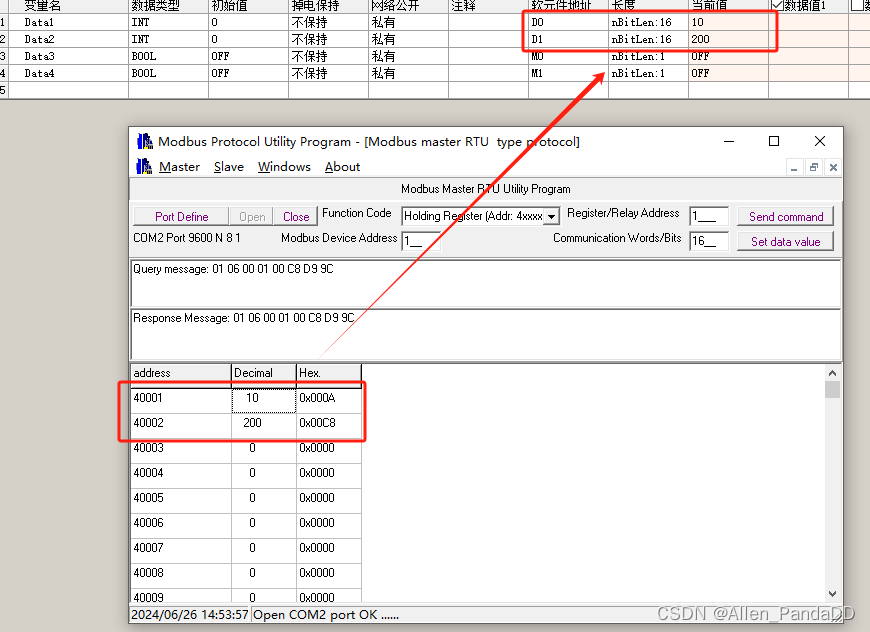
汇川H5u小型PLC作modbusRTU从站设置及测试
目录 新建工程COM通讯参数配置协议选择协议配置 查看手册Modbus地址对应关系仿真测试 新建工程 新建一个H5U工程,不使用临时工程 系列选择H5U即可 COM通讯参数配置 协议选择 选择ModbusRTU从站 协议配置 端口号默认不可选择 波特率这里使用9600 数据长度&…...
基于Java的多元化智能选课系统-计算机毕业设计源码040909
摘 要 多元化智能选课系统使用Java语言的Springboot框架,采用MVVM模式进行开发,数据方面主要采用的是微软的Mysql关系型数据库来作为数据存储媒介,配合前台技术完成系统的开发。 论文主要论述了如何使用JAVA语言开发一个多元化智能选课系统&a…...
idea使用maven打包报错GBK不可映射字符
方法一:设置环境变量 打开“控制面板” > “系统和安全” > “系统”。点击“高级系统设置”。在“系统属性”窗口中,点击“环境变量”。在“系统变量”部分,点击“新建”,创建一个新的变量: 变量名:…...

解决Linux系统Root不能远程SSH登录
问题描述 在使用Linux主机或者开发板的时候远程SSH一直登录不上Root账户,只能登录其他账户。 问题解决 使用文本编辑器修改SSH的配置文件sshd_config。这个文件通常位于/etc/ssh/目录下。 sudo nano /etc/ssh/sshd_config在sshd_config文件中,找到Pe…...
【java】【控制台】【javaSE】 初级java家教管理系统控制台命令行程序项目
更多项目点击👆👆👆完整项目成品专栏 【java】【控制台】【javaSE】 初级java家教管理系统控制台命令行程序项目 获取源码方式项目说明:功能点数据库涉及到: 项目文件包含:项目运行环境 :截图其…...
(2024)豆瓣电影TOP250爬虫详细讲解和代码
(2024)豆瓣电影TOP250爬虫详细讲解和代码 爬虫目的 获取 https://movie.douban.com/top250 电影列表的所有电影的属性。并存储起来。说起来很简单就两步。 第一步爬取数据第二步存储 爬虫思路 总体流程图 由于是分页的,要先观察分页的规…...

am62x芯片安全类型确认(HS-SE, HS-FS or GP)
文章目录 芯片安全类型设置启动方式获取串口信息下载脚本运行脚本示例sk-am62x板卡参考芯片安全类型 AM62x 芯片有三个安全级别。 • GP:通用版本 • HS-FS:高安全性 - 现场安全型 • HS-SE:高安全性 - 强制安全型 在SD卡启动文件中,可以查看到, 但板上的芯片,到底是那…...

高通安卓12-在源码中查找应用的方法
1.通过搜索命令查找app 一般情况下,UI上看到的APP名称会在xml文件里面定义出来,如 搜索名字为WiGig的一个APP 执行命令 sgrep "WiGig" 2>&1|tee 1.log 将所有的搜索到的内容打印到log里面 Log里面会有一段内容 在它的前面是这段内…...

民用无人驾驶航空器运营合格证怎么申请
随着科技的飞速发展,无人机已经从遥不可及的高科技产品飞入了寻常百姓家。越来越多的人想要亲自操纵无人机,探索更广阔的天空。但是,飞行无人机可不是简单的事情,你需要先获得无人机许可证,也就是今天所要讲的叫民用无…...

[SD必备知识18]修图扩图AI神器:ComfyUI+Krita加速修手抽卡,告别低效抽卡还原光滑细腻双手,写真无需隐藏手势
🌹大家好!我是安琪!感谢大家的支持与鼓励。 krita-ai-diffusion简介 在AIGC图像生成领域的迅猛发展下,当前的AI绘图工具如Midjourney、Stable Diffusion都能够近乎完美的生成逼真富有艺术视觉效果的图像质量。然而,针…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...