CentOS7环境Maxwell的安装及使用
目录
Maxwell的安装
下载安装包
解压安装包
配置环境变量
启用MySQL Binlog
创建Maxwell所需数据库和用户
配置Maxwell
Maxwell的使用
启动Kafka集群
Maxwell启停
Maxwell启停脚本
MySQL数据准备
Kafka开启消费者
全量数据同步
增量数据同步
启动Kafka消费者
修改数据
添加数据
删除数据
查询数据
Maxwell是用Java编写的MySQL变更数据抓取软件。 它会实时监控MySQL数据库的数据变更操作(insert、update、delete),并将变更数据以 JSON 格式发送给 Kafka、Kinesi等流数据处理平台。
Maxwell的安装
因为MySQL安装在node3机器(安装MySQL8),就近原则,所以Maxwell也安装在node3中。
下载安装包
官网下载安装包,下载版本如下:
maxwell-1.29.2.tar.gz
注意:Maxwell-1.30.0及以上版本不再支持JDK1.8。
解压安装包
[hadoop@node3 installfile]$ tar -zxvf maxwell-1.29.2.tar.gz -C ~/soft
配置环境变量
[hadoop@node3 installfile]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#MAXWELL_HOME export MAXWELL_HOME=/home/hadoop/soft/maxwell-1.29.2 export PATH=$PATH:$MAXWELL_HOME/bin
让环境变量生效
source /etc/profile
启用MySQL Binlog
MySQL的Binlog默认是未开启的,如需捕获更新操作,需要先进行开启Binlog。
修改MySQL配置文件/etc/my.cnf
[hadoop@node3 installfile]$ sudo vim /etc/my.cnf
增加如下配置
server-id = 1 log-bin=mysql-bin binlog_format=row binlog-do-db=gmall binlog-do-db=test
配置项解释:
#数据库id server-id = 1 #启动binlog,该参数的值会作为binlog的文件名 log-bin=mysql-bin #binlog类型,maxwell要求为row类型 binlog_format=row #启用binlog的数据库,需根据实际情况作出修改,如果需要开启多个数据库,直接再添加新的binlog-do-db设置行 binlog-do-db=gmall
MySQL Binlog类型:
-
Statement-based:基于语句,Binlog会记录所有写操作的SQL语句,包括insert、update、delete等。
优点:节省空间
缺点:有可能造成数据不一致,例如insert语句中包含now()函数。
-
Row-based:基于行,Binlog会记录每次写操作后被操作行记录的变化。
优点:保持数据的绝对一致性。
缺点:占用较大空间。
-
mixed:混合模式,默认是Statement-based,如果SQL语句可能导致数据不一致,就自动切换到Row-based。
Maxwell要求Binlog采用Row-based类型。
重启MySQL服务
[hadoop@node3 installfile]$ sudo systemctl restart mysqld
创建Maxwell所需数据库和用户
Maxwell需要在MySQL中存储其运行过程中的所需的一些数据,包括Binlog同步的断点位置(Maxwell支持断点续传)等等,故需要在MySQL为Maxwell创建数据库及用户。
1)创建数据库
[hadoop@node3 installfile]$ mysql -uroot -p000000 ... 省略若干输出 ... msyql> CREATE DATABASE maxwell;
2)创建Maxwell用户并赋予其必要权限
mysql> CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell'; mysql> GRANT ALL ON maxwell.* TO 'maxwell'@'%'; mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
配置Maxwell
1)基于模板配置文件复制得到Maxwell配置文件
[hadoop@node3 installfile]$ cd ~/soft/maxwell-1.29.2 [hadoop@node3 maxwell-1.29.2]$ ls bin config.properties.example lib log4j2.xml README.md config.md kinesis-producer-library.properties.example LICENSE quickstart.md [hadoop@node3 maxwell-1.29.2]$ cp config.properties.example config.properties
2)修改Maxwell配置文件
[hadoop@node3 maxwell-1.29.2]$ vim config.properties
配置如下
#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
# 目标Kafka集群地址
kafka.bootstrap.servers=node2:9092,node3:9092,node4:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=topic_db# MySQL相关配置
host=node3
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true# 过滤gmall中的z_log表数据,该表是日志数据的备份,无须采集
filter=exclude:gmall.z_log
# 指定数据按照主键分组进入Kafka不同分区,避免数据倾斜
producer_partition_by=primary_keyMaxwell的使用
启动Kafka集群
若Maxwell发送数据的目的地为Kafka集群,则需要先确保Kafka集群为启动状态。
开启Kafka集群 (Kafka集群安装)所有机器(node2、node3、node4),然后在任意一台机器执行如下命令:
[hadoop@node2 ~]$zk.sh start [hadoop@node2 ~]$kf.sh start
Maxwell启停
1)启动Maxwell
maxwell --config $MAXWELL_HOME/config.properties --daemon
操作
[hadoop@node3 maxwell-1.29.2]$ maxwell --config $MAXWELL_HOME/config.properties --daemon Redirecting STDOUT to /home/hadoop/soft/maxwell-1.29.2/bin/../logs/MaxwellDaemon.out Using kafka version: 1.0.0 [hadoop@node3 maxwell-1.29.2]$ jps 1785 Maxwell 1839 Jps [hadoop@node3 maxwell-1.29.2]$
2)停止Maxwell
ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
操作
[hadoop@node3 maxwell-1.29.2]$ ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9
[hadoop@node3 maxwell-1.29.2]$ jps
1891 Jps
[hadoop@node3 maxwell-1.29.2]$
Maxwell启停脚本
创建并编辑Maxwell启停脚本
[hadoop@node3 maxwell-1.29.2]$ cd ~/bin [hadoop@node3 bin]$ vim mxw.sh
脚本内容如下
#!/bin/bashMAXWELL_HOME=/home/hadoop/soft/maxwell-1.29.2status_maxwell(){result=`ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l`return $result
}start_maxwell(){status_maxwellif [[ $? -lt 1 ]]; thenecho "启动Maxwell"$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemonelseecho "Maxwell正在运行"fi
}stop_maxwell(){status_maxwellif [[ $? -gt 0 ]]; thenecho "停止Maxwell"ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9elseecho "Maxwell未在运行"fi
}case $1 instart )start_maxwell;;stop )stop_maxwell;;restart )stop_maxwellstart_maxwell;;
esac注意:MAXWELL_HOME需要根据实际情况修改。
赋予权限
[hadoop@node3 bin]$ chmod 777 mxw.sh
启动Maxwell
[hadoop@node3 bin]$ mxw.sh start
查看进程
[hadoop@node3 bin]$ jps 1988 Jps 1942 Maxwell
停止Maxwell
[hadoop@node3 bin]$ mxw.sh stop
查看进程
[hadoop@node3 bin]$ jps 2015 Jps
MySQL数据准备
进入mysql命令行,执行如下命令
create database test; use test; create table stu (id int, name varchar(100), age int); insert into stu values(1,"张三",18); insert into stu values(1,"李四",20);
Kafka开启消费者
在node2、node3、node4集群任意一台执行如下消费者命令,这里在node2执行
kafka-console-consumer.sh --bootstrap-server node2:9092 --topic topic_db
全量数据同步
Maxwell提供了bootstrap功能来进行历史数据的全量同步,命令如下:
[hadoop@node3 bin]$ mxw.sh start [hadoop@node3 bin]$ maxwell-bootstrap --database test --table stu --config $MAXWELL_HOME/config.properties
kafka消费者输出如下
{"database":"test","table":"stu","type":"bootstrap-start","ts":1719415852,"data":{}}
{"database":"test","table":"stu","type":"bootstrap-insert","ts":1719415852,"data":{"id":1,"name":"张三","age":18}}
{"database":"test","table":"stu","type":"bootstrap-insert","ts":1719415852,"data":{"id":1,"name":"李四","age":20}}
{"database":"test","table":"stu","type":"bootstrap-complete","ts":1719415852,"data":{}}
格式化后如下:
{"database": "test","table": "stu","type": "bootstrap-start","ts": 1719415852,"data": {}
} {"database": "test","table": "stu","type": "bootstrap-insert","ts": 1719415852,"data": {"id": 1,"name": "张三","age": 18}
} {"database": "test","table": "stu","type": "bootstrap-insert","ts": 1719415852,"data": {"id": 1,"name": "李四","age": 20}
} {"database": "test","table": "stu","type": "bootstrap-complete","ts": 1719415852,"data": {}
}
(1)第一条type为bootstrap-start和最后一条type为bootstrap-complete的数据,是bootstrap开始和结束的标志,不包含数据,中间的type为bootstrap-insert的数据才包含数据。
(2)一次bootstrap输出的所有记录的ts都相同,为bootstrap开始的时间(系统时间)。
增量数据同步
启动Kafka消费者
kafka-console-consumer.sh --bootstrap-server node2:9092 --topic topic_db
修改数据
将李四的id改为2
update stu set id=2 where name="李四";
kafka消费者输出
{"database":"test","table":"stu","type":"update","ts":1719416255,"xid":2595,"commit":true,"data":{"id":2,"name":"李四","age":20},"old":{"id":1}}
格式化输出
{"database": "test","table": "stu","type": "update","ts": 1719416255,"xid": 2595,"commit": true,"data": {"id": 2,"name": "李四","age": 20},"old": {"id": 1}
}
添加数据
例如:添加一条王五的数据
insert into stu values(3,"王五",23);
kafka消费者输出
{"database":"test","table":"stu","type":"insert","ts":1719416370,"xid":2853,"commit":true,"data":{"id":3,"name":"王五","age":23}}
格式化输出
{"database": "test","table": "stu","type": "insert","ts": 1719416370,"xid": 2853,"commit": true,"data": {"id": 3,"name": "王五","age": 23}
}
删除数据
delete from stu where id=3;
kafka消费者输出
{"database":"test","table":"stu","type":"delete","ts":1719416588,"xid":3339,"commit":true,"data":{"id":3,"name":"王五","age":23}}
格式化输出
{"database": "test","table": "stu","type": "delete","ts": 1719416588,"xid": 3339,"commit": true,"data": {"id": 3,"name": "王五","age": 23}
}
查询数据
select * from stu;
kafka消费者无新增的输出
可以看到,Maxwell可以监听到MySQL开启Binlog数据库的增、删、改操作。
完成!enjoy it!
相关文章:

CentOS7环境Maxwell的安装及使用
目录 Maxwell的安装 下载安装包 解压安装包 配置环境变量 启用MySQL Binlog 创建Maxwell所需数据库和用户 配置Maxwell Maxwell的使用 启动Kafka集群 Maxwell启停 Maxwell启停脚本 MySQL数据准备 Kafka开启消费者 全量数据同步 增量数据同步 启动Kafka消费者 …...

python环境变量
目录 python环境变量 python-opencv cuda cudnn pytorch pycharm 激活ok了 pyqt5 labelimg notepad gpu-z python 3.6或3.7 标注,文件路径不能有 python环境变量 import os import syscurrent_dir = os.path.dirname(os.path.abspath(__file__))paths = [os.path.abspath(…...
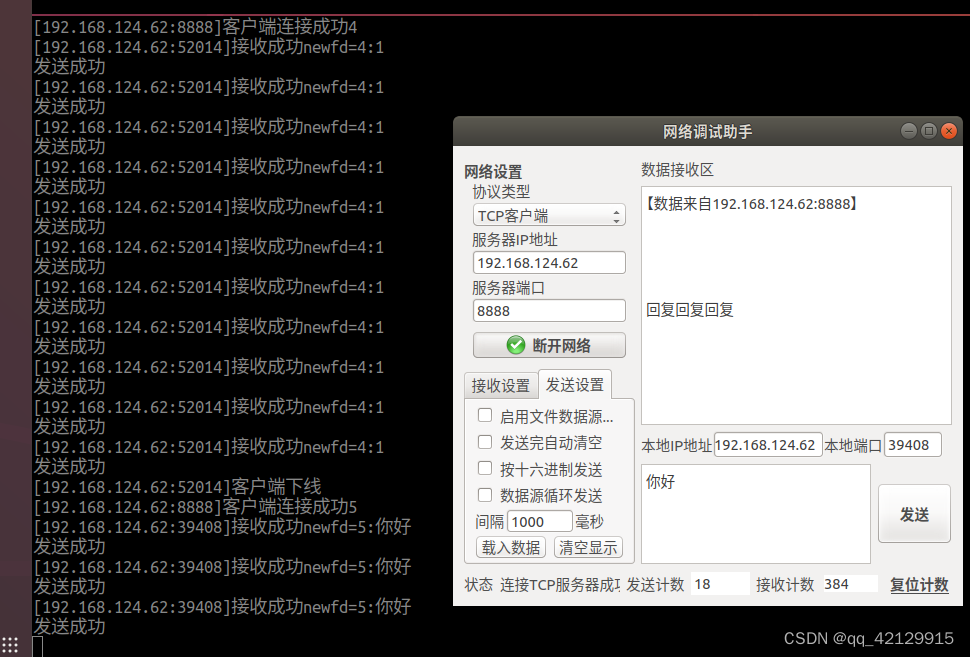
用进程和线程完成TCP进行通信操作及广播和组播的通信
进程 代码 #include <stdio.h>#include <sys/types.h>#include <sys/socket.h>#include <netinet/in.h>#include <arpa/inet.h>#include <string.h>#include <unistd.h>#include <stdlib.h>#include <signal.h>#includ…...
浅谈Tomcat
文章目录 一、什么是Tomcat?二、Tomcat的下载安装三、使用tomcat访问资源 一、什么是Tomcat? Tomcat 就是一个 HTTP 服务器。 前面我们聊了HTTP服务器,像我们在网页输入URL,其实就是在给人家的HTTP服务器发送请求,既…...

C++精解【7】
文章目录 eigen矩阵初始化多维矩阵矩阵和向量size固定大小or 动态大小Matrix类六个模板参数初始化向量元素类型 参考文献 eigen 矩阵初始化 多维矩阵 数组 MatrixXi a { // construct a 2x2 matrix{1, 2}, // first row{3, 4} // second row }; Matrix<do…...

堆箱子00
题目链接 堆箱子 题目描述 注意点 将箱子堆起来时,下面箱子的宽度、高度和深度必须大于上面的箱子 解答思路 初始想到深度优先遍历,最后超时了参照题解使用动态规划,先将盒子从小到大进行排序,dp[i]存储的是到第i个箱子时堆箱…...

Linux 命令:iftop
1. 写在前面 本文主要介绍 Linux iftop(Interface TOP) 命令:iftop 是一款小巧、免费且功能强大的网卡实时流量监控工具。监控指定网卡的实时流量、端口连接信息、反向解析 IP 等,还可以精确显示本机网络流量及网络内各主机和本机…...
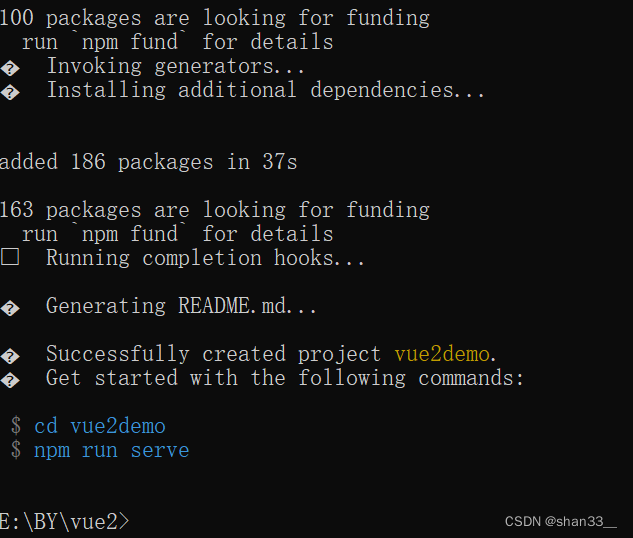
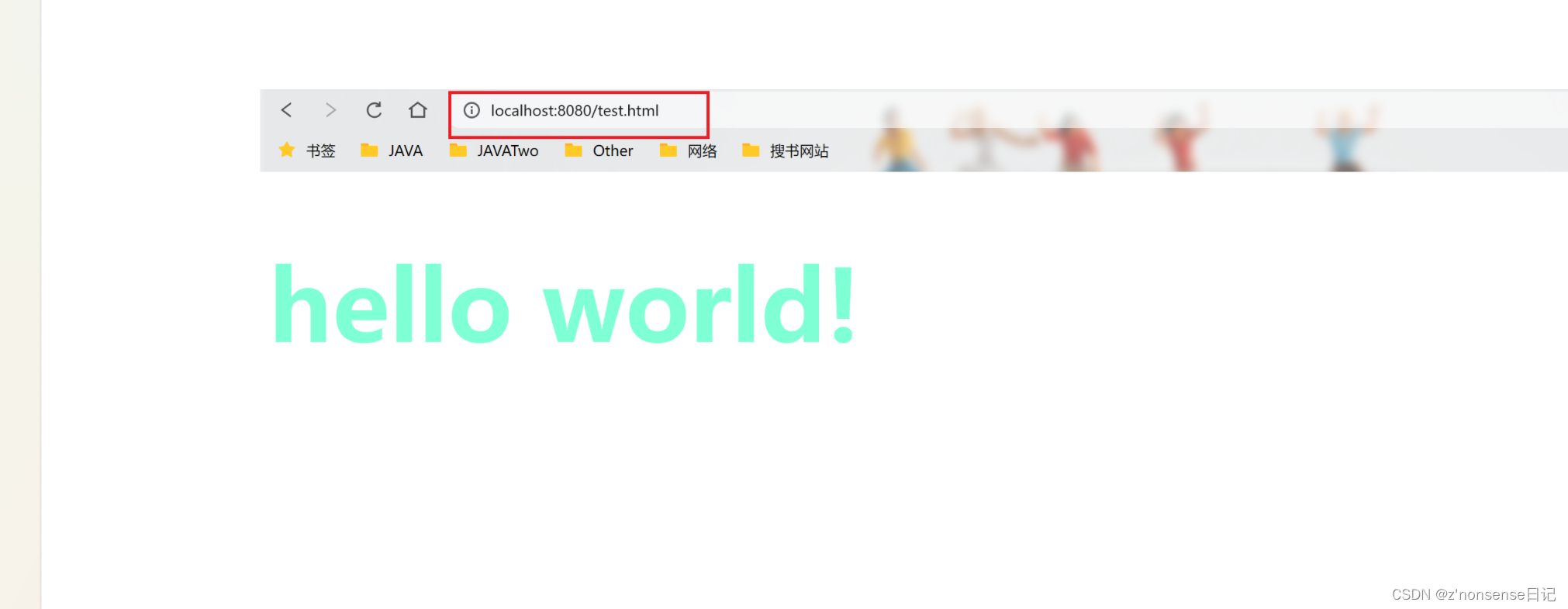
web学习笔记(六十九)vue2
目录 1. vue2创建脚手架项目 2.vue2如何关闭eslint 1. vue2创建脚手架项目 (1)在cmd窗口输入npm install -g vue/cli命令行,快速搭建脚手架。 (2) 创建vue2项目 (3) 选择配置项目,…...

JavaScript全解:从基础到高级,掌握每一个知识点
引言: JavaScript是一种广泛使用的脚本语言,主要用于Web浏览器,但近年来也扩展到了服务器端(Node.js)和其他领域。它允许开发者创建交互式的网页,处理数据,控制用户界面,甚至构建完…...

RabbitMQ的Direct交换机
Direct交换机 BindingKey 在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange。 在Direct模型下: 队列与交换机的绑定&a…...

2024.6.26 待学习知识点
OOALV https://www.cnblogs.com/BruceKing/p/11447499.html " 取工单的组件 lt_aufnr CORRESPONDING #( lt_out MAPPING aufnr aufnr EXCEPT * ). ABAP POPUP_TO_CONFIRM 弹出框函数 CLASS-EVENTS CLASS-METHODS main. CLASS-METHODS raise_event_EXIT_COMMAND IMPOR…...

【LeetCode】每日一题:相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据 保证 整个链式结构中不存在环。 注意,函数返回结果后&am…...
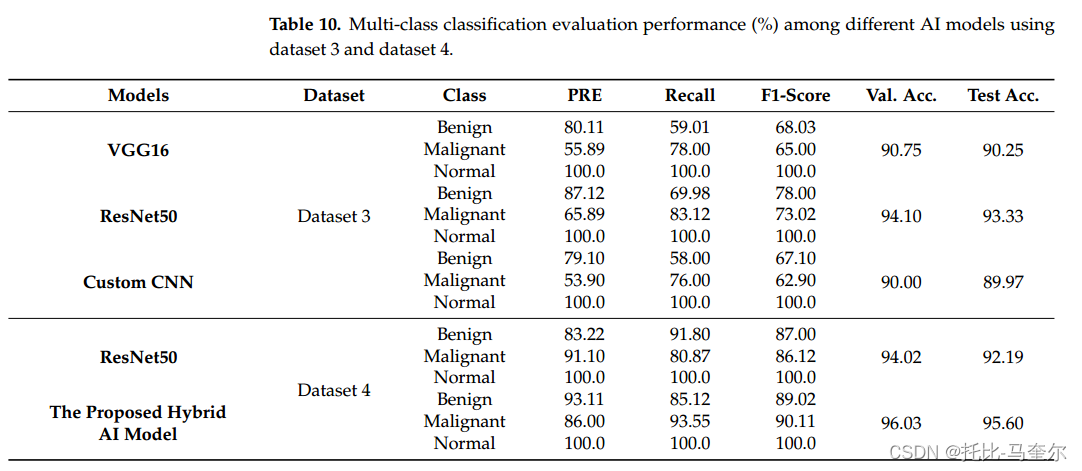
6.26.1 残差卷积变压器编码器的混合工作流程用于数字x线乳房x光片乳腺癌分类
基于残差卷积网络和多层感知器变压器编码器(MLP)的优势,提出了一种新型的混合深度学习乳腺病变计算机辅助诊断(CAD)系统。利用骨干残差深度学习网络创建深度特征,利用Transformer根据自注意力机制对乳腺癌进行分类。所提出的CAD系统具有识别两种情况乳腺…...

[leetcode]avoid-flood-in-the-city 避免洪水泛滥
. - 力扣(LeetCode) class Solution { public:vector<int> avoidFlood(vector<int>& rains) {vector<int> ans(rains.size(), 1);set<int> st;unordered_map<int, int> mp;for (int i 0; i < rains.size(); i) {i…...
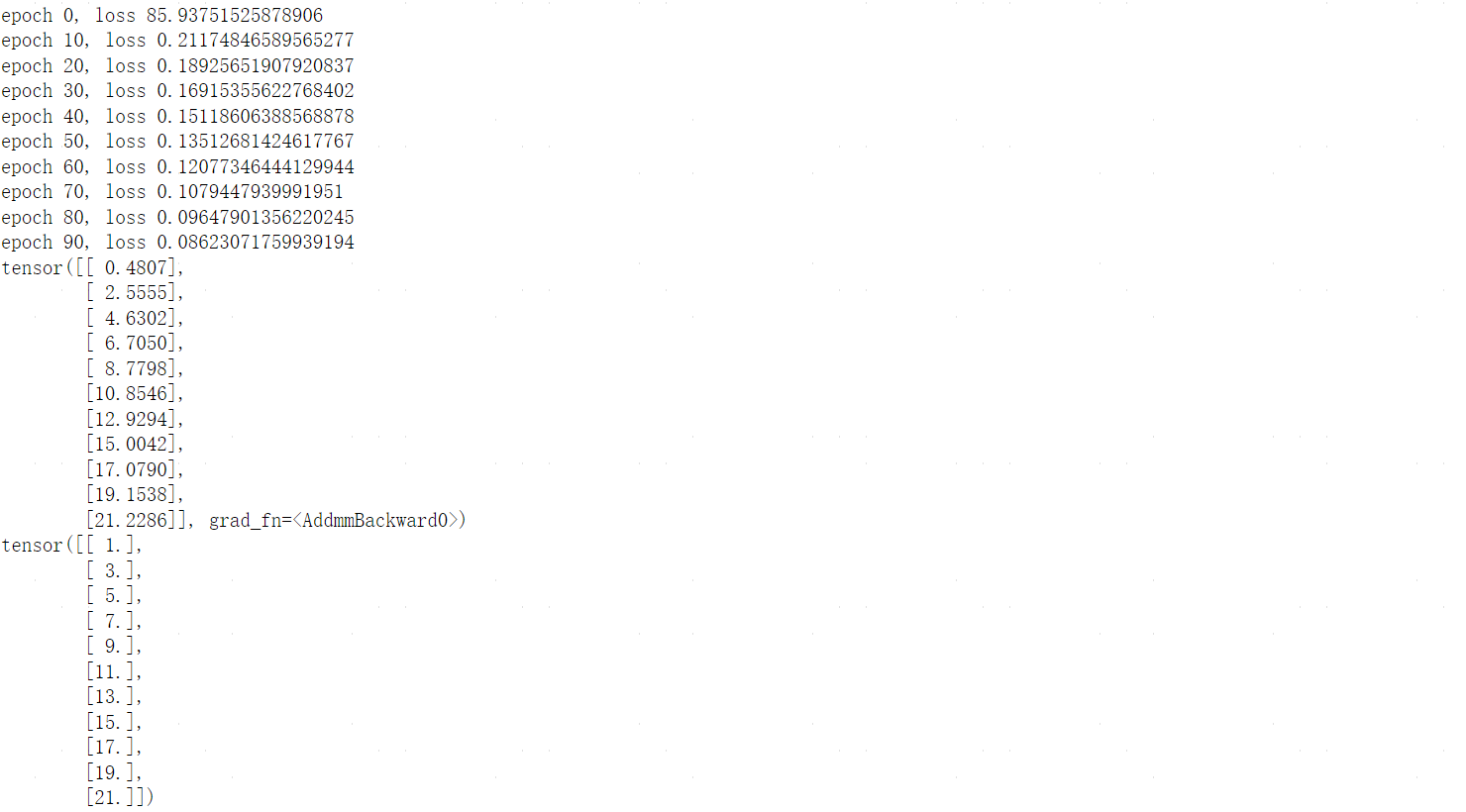
Pytorch基础
文章目录 零、tensorboard0.1基本使用案例 一、数据结构:Tensor1.1数据类型1.2Tensor的创建方式1.3张量的基本运算1.4张量的属性 二、数据集加载器DataLoaders2.0前置知识2.0.1torch.scatter()、torch.scatter_() 2.1官方案例2.1.1从TorchVision加载数据集2.1.2迭代…...

嵌入技术Embedding
嵌入(Embedding)是一种将高维数据映射到低维空间的技术,广泛应用于自然语言处理(NLP)、计算机视觉和推荐系统等领域。嵌入技术的核心思想是将复杂的数据表示为低维向量,使其在这个低维空间中保留尽可能多的…...

Pandas中的数据转换[细节]
今天我们看一下Pandas中的数据转换,话不多说直接开始🎇 目录 一、⭐️apply函数应用 apply是一个自由度很高的函数 对于Series,它可以迭代每一列的值操作: 二、⭐️矢量化字符串 为什么要用str属性 替换和分割 提取子串 …...

vue2面试题——路由
1. 路由的模式和区别 路由的模式:history,hash 区别: 1. 表象不同 history路由:以/为结尾,localhost:8080——>localhost:8080/about hash路由:会多个#,localhost:8080/#/——>localhost:…...

【AI应用探讨】—朴素贝叶斯应用场景
目录 文本分类 推荐系统 信息检索 生物信息学 金融领域 医疗诊断 其他领域 文本分类 垃圾邮件过滤:朴素贝叶斯被广泛用于垃圾邮件过滤任务,通过邮件中的文本内容来识别是否为垃圾邮件。例如,它可以基于邮件中出现的单词或短语的概率来…...
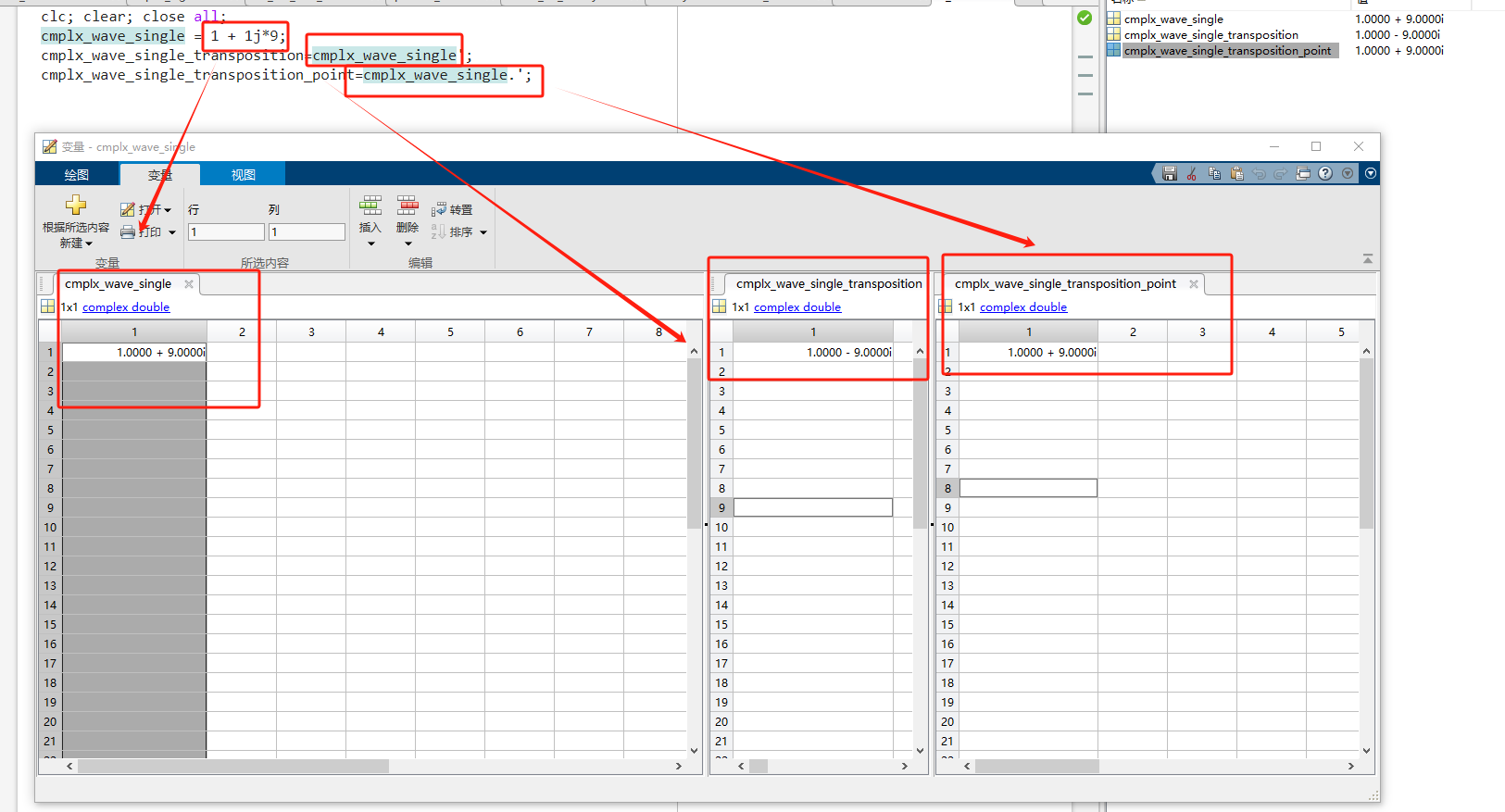
使用matlab的大坑,复数向量转置!!!!!变量区“转置变量“功能(共轭转置)、矩阵转置(默认也是共轭转置)、点转置
近期用verilog去做FFT相关的项目,需要用到matlab进行仿真然后和verilog出来的结果来做对比,然后计算误差。近期使用matlab犯了一个错误,极大的拖慢了项目进展,给我人都整emo了,因为怎么做仿真结果都不对,还…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

微信小程序之bind和catch
这两个呢,都是绑定事件用的,具体使用有些小区别。 官方文档: 事件冒泡处理不同 bind:绑定的事件会向上冒泡,即触发当前组件的事件后,还会继续触发父组件的相同事件。例如,有一个子视图绑定了b…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...