MetaGPT全面指南:多代理协作框架的深入解析与应用
文章目录
- 理解MetaGPT
- 1.1 MetaGPT的基础
- 1.2 MetaGPT的独特之处
- 1.3 MetaGPT在AI领域的应用
- MetaGPT的工作原理
- 2.1 训练
- 2.2 微调
- 2.3 推理
- 2.4 多代理协作的概念
- 2.5 如何分配角色给GPTs
- 2.6 复杂任务的完成过程
- 实际应用
- 3.1 客户支持
- 3.2 内容创作
- 3.3 教育
- 3.4 医疗保健
- 3.5 在企业中的应用
- 3.6 在科研中的应用
- MetaGPT的未来展望
- 4.1 MetaGPT对AI发展的影响
- 4.2 MetaGPT的潜在应用场景
- 4.3 MetaGPT的技术挑战与解决方案
- MetaGPT的安装与配置
- 5.1 安装方法
- 5.2 配置文件设置
- 5.3 LLM API设置
- 5.4 其他组件配置
- MetaGPT的操作流程
- 6.1 信息存储
- 6.2 信息检索
- 6.3 信息共享
- 6.4 减少冗余和提高效率
- MetaGPT的用例展示
- 7.1 项目案例研究
- 案例一:客户支持自动化
- 案例二:内容创作助手
- 案例三:教育辅导系统
- 7.2 代码示例解析
- 代码解析
- MetaGPT的工具使用
- 8.1 网页模仿
- 使用MetaGPT进行网页模仿的步骤:
- 8.2 网络抓取
- 使用MetaGPT进行网络抓取的步骤:
- 8.3 文本转图像
- 使用MetaGPT进行文本转图像的步骤:
- 8.4 邮件摘要与回复
- 使用MetaGPT进行邮件摘要与回复的步骤:
- MetaGPT的深入指南
- 9.1 代理通信
- 通信协议
- 消息传递
- 示例代码
- 9.2 增量开发
- 模块化设计
- 版本控制
- 示例代码
- 9.3 序列化与断点恢复
- 序列化
- 断点恢复
- 示例代码
- 9.4 RAG模块环境
- 数据检索
- 信息融合
- 示例代码
- MetaGPT的贡献指南
- 10.1 贡献指南
- 10.1.1 准备工作
- 10.1.2 贡献流程
- 10.1.3 代码审查
- 10.2 API文档
- 10.2.1 代理API
- 10.2.2 任务API
- 10.2.3 通信API
- 10.3 常见问题
- 10.3.1 如何解决依赖冲突?
- 10.3.2 如何处理代码格式问题?
理解MetaGPT
1.1 MetaGPT的基础
MetaGPT是一个创新的多代理协作框架,旨在通过分配不同的角色给GPTs(生成式预训练变换器),形成一个协作的软件实体,以完成复杂任务。MetaGPT的基础在于其能够处理和生成自然语言,这是通过深度学习和自然语言处理技术实现的。
MetaGPT的核心是一个集成了多个GPT模型的系统,每个模型都被赋予特定的角色和任务。这些模型通过协作来解决复杂的问题,从而提高整体效率和性能。MetaGPT的基础还包括其对大量数据的处理能力,这使得它能够理解和生成高质量的自然语言文本。
1.2 MetaGPT的独特之处
MetaGPT的独特之处在于其多代理协作的框架设计。与传统的单一模型不同,MetaGPT通过分配不同的角色给多个GPT模型,使得每个模型都能专注于其擅长的任务。这种设计不仅提高了处理复杂任务的能力,还增强了系统的灵活性和适应性。
此外,MetaGPT还具有高度可扩展性。随着任务复杂度的增加,可以通过添加更多的GPT模型来扩展系统的能力。这种可扩展性使得MetaGPT能够适应不断变化的需求和环境。
1.3 MetaGPT在AI领域的应用
MetaGPT在AI领域的应用广泛,涵盖了多个方面。以下是一些具体的应用场景:
- 自然语言处理:MetaGPT能够理解和生成自然语言文本,因此在自然语言处理任务中表现出色,如文本分类、情感分析、机器翻译等。
- 智能对话系统:通过多代理协作,MetaGPT能够构建复杂的对话系统,提供更加自然和智能的交互体验。
- 内容创作:MetaGPT可以帮助生成高质量的内容,如文章、报告、广告文案等,大大提高了内容创作的效率。
- 教育:MetaGPT可以作为智能教育助手,提供个性化的学习建议和辅导,帮助学生更有效地学习。
- 医疗保健:MetaGPT可以用于疾病诊断、药物研发、患者管理等方面,提高医疗保健的效率和质量。
通过这些应用,MetaGPT展示了其在AI领域的巨大潜力和广泛应用前景。
MetaGPT的工作原理
2.1 训练
MetaGPT的训练过程是其核心功能的基础,涉及到大量的数据处理和模型优化。训练阶段主要包括以下几个步骤:
- 数据收集:收集大量的文本数据,包括书籍、网页、文档等,用于训练模型的语言理解和生成能力。
- 数据预处理:对收集到的数据进行清洗和预处理,去除噪声和不必要的信息,确保数据的质量。
- 模型初始化:使用预训练的语言模型(如GPT-4)作为基础,进行模型的初始化。
- 训练策略:采用分布式训练策略,利用多个GPU和TPU进行并行计算,加速训练过程。
- 损失函数优化:定义合适的损失函数,通过反向传播算法优化模型参数,最小化预测误差。
# 示例代码:MetaGPT的训练过程
from metagpt.trainer import Trainer# 初始化训练器
trainer = Trainer(model, data_loader, optimizer)# 开始训练
trainer.train(epochs=10)
2.2 微调
微调是针对特定任务对预训练模型进行进一步优化的过程。通过微调,模型可以更好地适应特定领域的语言和任务需求。微调的主要步骤包括:
- 任务特定数据集:收集和准备特定任务的数据集,如问答、文本分类等。
- 微调策略:采用小批量梯度下降法,对模型进行精细调整,使其更好地适应特定任务。
- 评估和验证:在验证集上评估模型的性能,调整超参数,确保模型的泛化能力。
# 示例代码:MetaGPT的微调过程
from metagpt.finetuner import FineTuner# 初始化微调器
finetuner = FineTuner(model, task_data_loader, optimizer)# 开始微调
finetuner.finetune(epochs=5)
2.3 推理
推理是模型应用阶段,通过输入文本数据,模型生成相应的输出。推理过程主要包括以下几个步骤:
- 输入预处理:对输入文本进行预处理,如分词、编码等。
- 模型前向传播:将预处理后的输入传递给模型,进行前向计算,生成输出。
- 输出后处理:对模型生成的输出进行后处理,如解码、格式化等,得到最终结果。
# 示例代码:MetaGPT的推理过程
from metagpt.inference import Inference# 初始化推理器
inference = Inference(model)# 进行推理
output = inference.run("这是一个测试输入。")
print(output)
2.4 多代理协作的概念
多代理协作是MetaGPT的核心理念之一,通过分配不同的角色给GPTs,形成一个协作的软件实体,以完成复杂任务。多代理协作的概念包括:
- 角色分配:根据任务需求,将不同的角色分配给不同的GPTs,如产品经理、架构师、工程师等。
- 协作机制:定义角色之间的协作机制,如信息共享、任务分配、结果整合等。
- 动态调整:根据任务进展和结果反馈,动态调整角色和协作策略,提高任务完成效率。
2.5 如何分配角色给GPTs
分配角色给GPTs是实现多代理协作的关键步骤。具体步骤包括:
- 任务分解:将复杂任务分解为多个子任务,每个子任务对应一个或多个角色。
- 角色定义:定义每个角色的职责和能力,如产品经理负责需求分析,架构师负责系统设计等。
- 角色分配:根据子任务的需求和角色的能力,将角色分配给相应的GPTs。
# 示例代码:角色分配过程
from metagpt.role_assigner import RoleAssigner# 初始化角色分配器
role_assigner = RoleAssigner(task_list, role_list)# 进行角色分配
role_assigner.assign_roles()
2.6 复杂任务的完成过程
复杂任务的完成过程涉及多个代理的协同工作和任务分解。具体步骤包括:
- 任务分解:将复杂任务分解为多个子任务,每个子任务由一个或多个代理负责。
- 角色分配:根据子任务的需求和代理的能力,将角色分配给相应的代理。
- 协作执行:各个代理按照分配的角色执行相应的子任务,通过协作完成整个任务。
- 结果整合:将各个子任务的结果进行整合,生成最终的任务结果。
- 评估与反馈:对任务结果进行评估,根据评估结果提供反馈,以便进一步优化任务完成过程。
通过上述步骤,MetaGPT可以有效地完成复杂任务,展示其在自然语言处理领域的强大能力。
实际应用
3.1 客户支持
在客户支持领域,MetaGPT的应用极大地提升了服务效率和质量。通过分配不同的角色给GPTs,如问题解析代理、解决方案提供代理和情感分析代理,MetaGPT能够高效地处理客户咨询。问题解析代理负责理解客户的问题,解决方案提供代理则根据问题类型提供相应的解决方案,而情感分析代理则监控客户的情绪变化,确保提供的服务既专业又人性化。这种多代理协作的方式大大提高了客户支持的效率和质量。
3.2 内容创作
在内容创作方面,MetaGPT同样表现出色。通过创建专门的内容生成代理、编辑代理和优化代理,MetaGPT能够自动化内容创作的各个环节。内容生成代理负责根据输入的主题生成初稿,编辑代理则对初稿进行润色和校对,而优化代理则负责确保内容的质量和相关性。这种分工明确的多代理协作模式使得内容创作更加高效和专业。
3.3 教育
MetaGPT在教育领域的应用潜力巨大。通过创建教学代理、辅导代理和评估代理,MetaGPT能够为学生提供个性化的学习体验。教学代理负责传授知识,辅导代理则根据学生的学习进度和理解程度提供个性化的辅导,而评估代理则负责定期评估学生的学习成果。这种多代理协作的教育模式能够显著提高学习效率和效果。
3.4 医疗保健
在医疗保健领域,MetaGPT通过创建诊断代理、治疗建议代理和患者管理代理,为医生和患者提供全方位的支持。诊断代理负责分析患者的症状和病史,治疗建议代理则根据诊断结果提供相应的治疗方案,而患者管理代理则负责跟踪患者的治疗进度和健康状况。这种多代理协作的模式能够提高医疗服务的准确性和效率。
3.5 在企业中的应用
在企业环境中,MetaGPT的应用也非常广泛。通过创建市场分析代理、客户关系管理代理和内部流程优化代理,MetaGPT能够为企业提供全方位的支持。市场分析代理负责分析市场趋势和竞争对手,客户关系管理代理则负责维护和提升客户关系,而内部流程优化代理则负责优化企业的内部流程,提高工作效率。这种多代理协作的模式能够帮助企业更好地应对市场变化和提升竞争力。
3.6 在科研中的应用
在科研领域,MetaGPT的应用也日益增多。通过创建数据分析代理、文献综述代理和实验设计代理,MetaGPT能够为科研人员提供强大的支持。数据分析代理负责处理和分析科研数据,文献综述代理则负责收集和整理相关文献,而实验设计代理则负责设计和优化实验方案。这种多代理协作的模式能够提高科研工作的效率和质量,帮助科研人员更快地取得研究成果。
MetaGPT的未来展望
4.1 MetaGPT对AI发展的影响
MetaGPT作为一种多代理协作框架,对AI领域的发展具有深远的影响。首先,它通过分配不同的角色给GPTs,形成一个协作的软件实体,这种模式极大地提高了处理复杂任务的效率和准确性。这种多代理协作的方式为AI系统的设计和实现提供了新的思路,使得AI系统能够更好地模拟人类的协作行为,从而在更广泛的领域内实现智能化的应用。
其次,MetaGPT的出现推动了AI技术的边界扩展。传统的AI系统往往专注于单一任务的处理,而MetaGPT通过多代理协作,能够处理更加复杂和多样化的任务。这种能力的提升不仅增强了AI系统的实用性,也为AI技术在更多领域的应用打开了大门。
此外,MetaGPT的多代理协作模式也为AI的伦理和安全问题提供了新的解决方案。通过明确的代理角色分配和协作机制,可以更好地管理和控制AI系统的行为,减少潜在的风险和不确定性。
4.2 MetaGPT的潜在应用场景
MetaGPT的潜在应用场景非常广泛,以下是一些可能的应用领域:
- 智能客服:通过多代理协作,可以实现更加高效和个性化的客户服务,提升客户满意度。
- 内容创作:多个代理可以协作生成高质量的内容,包括文章、报告、甚至艺术作品。
- 教育:MetaGPT可以作为智能助教,通过多代理协作提供个性化的学习体验和辅导。
- 医疗保健:在医疗领域,MetaGPT可以通过多代理协作提供诊断支持、患者管理和健康咨询等服务。
- 企业管理:在企业中,MetaGPT可以用于数据分析、决策支持和流程优化等方面。
- 科研:在科研领域,MetaGPT可以协助研究人员进行数据分析、模型构建和实验设计等工作。
4.3 MetaGPT的技术挑战与解决方案
尽管MetaGPT具有巨大的潜力,但在实际应用中仍然面临一些技术挑战:
-
代理间的协调与通信:在多代理协作中,代理间的协调与通信是一个关键问题。为了确保代理间的有效协作,需要设计高效的通信协议和协调机制。解决方案包括使用专门的通信中间件和优化算法,以确保信息的准确传递和处理。
-
任务分配与负载均衡:在多代理系统中,如何合理分配任务和实现负载均衡是一个挑战。解决方案包括使用智能的任务分配算法,根据代理的能力和当前的负载情况,动态调整任务分配,以确保系统的整体效率和性能。
-
安全和隐私保护:在处理敏感信息时,安全和隐私保护是一个重要问题。解决方案包括使用加密技术和访问控制机制,确保数据的安全传输和存储,同时保护用户的隐私信息不被泄露。
-
系统的可扩展性和稳定性:随着任务复杂度的增加,系统的可扩展性和稳定性成为一个挑战。解决方案包括使用分布式架构和容错机制,确保系统在面对大量任务和复杂环境时,仍能保持稳定运行和高性能。
通过不断的技术创新和优化,MetaGPT有望克服这些挑战,实现更加广泛和深入的应用,推动AI技术的进一步发展。
MetaGPT的安装与配置
5.1 安装方法
安装MetaGPT是开始使用这一强大工具的第一步。以下是详细的安装步骤:
-
克隆仓库:
首先,你需要从GitHub上克隆MetaGPT的仓库。你可以使用以下命令来完成这一操作:git clone https://github.com/geekan/MetaGPT.git -
进入目录:
克隆完成后,进入项目的根目录:cd MetaGPT -
安装依赖:
使用pip安装项目所需的所有依赖包。建议在虚拟环境中进行安装以避免与其他项目冲突:pip install -r requirements.txt -
配置环境变量:
有些配置可能需要通过环境变量来设置。你可以在项目的根目录下创建一个.env文件,并在其中添加必要的环境变量。例如:API_KEY=your_api_key_here -
运行安装脚本:
有些项目可能提供了一个安装脚本来简化安装过程。如果有,运行该脚本:./install.sh
5.2 配置文件设置
配置文件是MetaGPT运行的关键,它包含了各种设置和参数。以下是配置文件的基本设置步骤:
-
创建配置文件:
在项目根目录下创建一个名为config.yaml的文件。你可以参考config_example.yaml来创建你的配置文件。 -
设置基本参数:
在config.yaml中设置基本参数,例如:model_name: "gpt-3.5-turbo" api_key: "your_api_key_here" temperature: 0.7 max_tokens: 500 -
配置代理角色:
设置不同的代理角色及其参数,例如:roles:- name: "developer"model: "gpt-3.5-turbo"temperature: 0.8max_tokens: 1000- name: "analyst"model: "gpt-4"temperature: 0.6max_tokens: 800
5.3 LLM API设置
为了使MetaGPT能够与大型语言模型(LLM)进行交互,需要正确设置LLM API。以下是详细步骤:
-
获取API密钥:
- 从相应的LLM提供商(如OpenAI)获取API密钥。
-
配置API密钥:
- 将API密钥添加到
config.yaml文件中,例如:api_key: "your_api_key_here"
- 将API密钥添加到
-
设置API端点:
- 如果需要,配置API端点URL,例如:
api_base: "https://api.openai.com/v1"
- 如果需要,配置API端点URL,例如:
5.4 其他组件配置
除了基本的配置文件和LLM API设置外,MetaGPT还可能需要配置其他组件。以下是一些常见的其他组件配置:
-
数据库配置:
- 如果MetaGPT需要与数据库交互,配置数据库连接参数,例如:
database:type: "postgresql"host: "localhost"port: 5432user: "your_user"password: "your_password"dbname: "your_database"
- 如果MetaGPT需要与数据库交互,配置数据库连接参数,例如:
-
日志配置:
- 配置日志记录以监控和调试MetaGPT的运行,例如:
logging:level: "INFO"file: "meta_gpt.log"
- 配置日志记录以监控和调试MetaGPT的运行,例如:
-
安全配置:
- 确保敏感信息的安全,例如使用环境变量或加密存储API密钥。
MetaGPT的操作流程
6.1 信息存储
在MetaGPT中,信息存储是一个关键环节,它确保了数据的持久性和可访问性。MetaGPT使用先进的数据库存储技术来保存各种类型的信息,包括文本、图像、音频和视频等。以下是信息存储的主要步骤:
- 数据分类:首先,输入的数据会被分类,以便于后续的处理和存储。分类的标准可能包括数据类型、来源、重要性等。
- 数据清洗:在存储之前,数据需要进行清洗,以去除噪声和冗余信息,确保存储的数据质量。
- 数据编码:为了提高存储效率和检索速度,数据会被编码成特定的格式,如JSON、XML等。
- 数据存储:编码后的数据会被存储到数据库中。MetaGPT支持多种数据库类型,包括关系型数据库和非关系型数据库,如MySQL、MongoDB等。
# 示例代码:数据存储
import json
import pymongo# 连接到MongoDB数据库
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client["metagpt_db"]
collection = db["data_collection"]# 准备数据
data = {"type": "text","content": "这是一段示例文本","source": "example_source","importance": "high"
}# 存储数据
collection.insert_one(data)
6.2 信息检索
信息检索是MetaGPT的核心功能之一,它允许用户快速获取所需的信息。MetaGPT使用先进的检索算法和索引技术来提高检索效率。以下是信息检索的主要步骤:
- 查询解析:用户输入的查询会被解析,提取出关键字和条件。
- 索引检索:根据解析后的查询,系统会在索引中查找匹配的数据。
- 数据提取:找到匹配的数据后,系统会从数据库中提取出完整的数据记录。
- 结果排序:提取出的数据会根据相关性进行排序,以便用户优先看到最相关的结果。
# 示例代码:信息检索
query = {"type": "text","importance": "high"
}# 检索数据
results = collection.find(query)# 打印结果
for result in results:print(result)
6.3 信息共享
信息共享是MetaGPT促进多代理协作的重要手段。通过共享信息,不同的GPTs可以协同工作,完成复杂的任务。以下是信息共享的主要步骤:
- 权限管理:在共享信息之前,系统会检查用户的权限,确保只有授权的用户才能访问和共享信息。
- 信息发布:授权的用户可以将信息发布到共享平台,如内部论坛、共享数据库等。
- 信息订阅:其他用户可以订阅感兴趣的信息,以便及时获取更新。
- 信息同步:系统会定期同步共享平台上的信息,确保所有用户看到的信息是最新的。
# 示例代码:信息共享
shared_data = {"type": "text","content": "这是一段共享的示例文本","source": "example_source","importance": "high"
}# 发布共享信息
collection.insert_one(shared_data)# 订阅信息
subscription_query = {"type": "text","importance": "high"
}# 获取订阅信息
subscription_results = collection.find(subscription_query)# 打印订阅结果
for result in subscription_results:print(result)
6.4 减少冗余和提高效率
MetaGPT通过多种手段减少冗余信息和提高操作效率,从而提升整体性能。以下是减少冗余和提高效率的主要措施:
- 数据去重:在存储和检索过程中,系统会自动检测和去除重复的数据,减少冗余。
- 缓存机制:系统会使用缓存技术,将频繁访问的数据缓存起来,减少数据库的访问次数,提高响应速度。
- 任务调度:系统会根据任务的优先级和依赖关系,合理调度任务,确保高优先级任务优先执行。
- 自动化流程:系统会自动化一些常规流程,如数据清洗、格式转换等,减少人工干预,提高效率。
# 示例代码:减少冗余和提高效率
from collections import defaultdict# 数据去重
unique_data = defaultdict(dict)
for data in collection.find():key = (data["type"], data["source"])if key not in unique_data:unique_data[key] = data# 缓存机制
cached_data = {}
def get_data(query):if query in cached_data:return cached_data[query]result = collection.find_one(query)cached_data[query] = resultreturn result# 任务调度
import queue
task_queue = queue.PriorityQueue()
task_queue.put((1, "高优先级任务"))
task_queue.put((2, "中优先级任务"))
task_queue.put((3, "低优先级任务"))while not task_queue.empty():priority, task = task_queue.get()print(f"执行任务:{task},优先级:{priority}")
通过上述操作流程,MetaGPT能够高效地存储、检索和共享信息,减少冗余,提高整体操作效率,从而在多代理协作框架中发挥重要作用。
MetaGPT的用例展示
7.1 项目案例研究
MetaGPT作为一种多代理协作框架,已经在多个实际项目中展示了其强大的功能和灵活性。以下是几个典型的项目案例研究,展示了MetaGPT在不同领域的应用。
案例一:客户支持自动化
项目背景:一家大型电子商务公司希望提高其客户支持的效率和质量,减少人工干预。
实施方案:利用MetaGPT框架,构建了一个多代理的客户支持系统。每个代理被分配不同的角色,如问题识别、解决方案提供和情感分析等。
实施效果:系统上线后,客户问题的平均响应时间减少了50%,客户满意度提高了30%。
案例二:内容创作助手
项目背景:一家数字媒体公司需要快速生成高质量的内容,以满足不断增长的读者需求。
实施方案:使用MetaGPT框架,创建了一个内容创作助手。该助手能够根据输入的主题和关键词,自动生成文章的初稿,并进行初步的编辑和校对。
实施效果:内容创作效率提高了40%,同时保持了内容的高质量和多样性。
案例三:教育辅导系统
项目背景:一家在线教育平台希望提供个性化的学习辅导,以提高学生的学习效果。
实施方案:利用MetaGPT框架,构建了一个智能教育辅导系统。系统能够根据学生的学习进度和理解程度,自动调整教学内容和方法。
实施效果:学生的平均学习效率提高了25%,学习兴趣和参与度显著提升。
7.2 代码示例解析
为了更好地理解MetaGPT的实际应用,以下是一个简单的代码示例,展示了如何使用MetaGPT框架来实现一个基本的文本生成任务。
import metagpt# 初始化MetaGPT框架
metagpt.init()# 定义一个简单的文本生成任务
task = {"type": "text_generation","parameters": {"prompt": "Once upon a time","max_length": 100}
}# 分配不同的角色给GPTs
roles = [{"role": "storyteller", "model": "gpt-3.5-turbo"},{"role": "editor", "model": "gpt-4"}
]# 执行任务
result = metagpt.execute(task, roles)# 输出结果
print(result)
代码解析
-
初始化MetaGPT框架:
metagpt.init()这一步初始化了MetaGPT框架,准备执行后续的任务。
-
定义任务:
task = {"type": "text_generation","parameters": {"prompt": "Once upon a time","max_length": 100} }这里定义了一个文本生成任务,指定了生成文本的初始提示和最大长度。
-
分配角色:
roles = [{"role": "storyteller", "model": "gpt-3.5-turbo"},{"role": "editor", "model": "gpt-4"} ]为任务分配了两个角色,分别是“storyteller”和“editor”,并指定了它们使用的模型。
-
执行任务:
result = metagpt.execute(task, roles)调用
metagpt.execute方法执行任务,并返回生成的文本结果。 -
输出结果:
print(result)打印出生成的文本结果。
通过这个简单的代码示例,我们可以看到MetaGPT框架如何通过多代理协作来完成复杂的文本生成任务。
MetaGPT的工具使用
8.1 网页模仿
在现代网络开发中,网页模仿是一个重要的技能,它允许开发者快速复制现有网页的设计和功能,以便进行进一步的定制和开发。MetaGPT可以作为一个强大的工具,帮助开发者实现这一目标。
使用MetaGPT进行网页模仿的步骤:
-
分析目标网页:
- 使用MetaGPT的网络抓取功能,获取目标网页的HTML结构和CSS样式。
- 通过MetaGPT的分析功能,理解网页的布局和交互元素。
-
生成模仿代码:
- MetaGPT可以根据分析结果,生成相应的HTML和CSS代码,模仿目标网页的外观和布局。
- 开发者可以根据需要,对生成的代码进行微调,以适应特定的需求。
-
测试和优化:
- 使用MetaGPT的预览功能,查看生成的网页效果。
- 根据测试结果,对代码进行优化和调整,确保模仿的网页在不同设备和浏览器上都能正常显示。
8.2 网络抓取
网络抓取是获取互联网上公开可用数据的过程,这对于数据分析、市场研究和其他许多应用都非常重要。MetaGPT提供了强大的网络抓取功能,可以帮助用户高效地获取所需数据。
使用MetaGPT进行网络抓取的步骤:
-
确定抓取目标:
- 使用MetaGPT的搜索功能,找到需要抓取的网页或数据源。
- 通过MetaGPT的分析功能,确定需要抓取的具体数据和字段。
-
配置抓取任务:
- 使用MetaGPT的配置工具,设置抓取任务的参数,如抓取频率、数据存储格式等。
- 通过MetaGPT的自动化功能,启动抓取任务。
-
数据处理和存储:
- 使用MetaGPT的数据处理功能,对抓取到的数据进行清洗和整理。
- 将处理后的数据存储到指定的数据库或文件中,以便后续分析和使用。
8.3 文本转图像
文本转图像是一个将文本内容转换为视觉图像的过程,这在内容创作、教育和许多其他领域都非常有用。MetaGPT提供了先进的文本转图像功能,可以帮助用户快速生成高质量的图像。
使用MetaGPT进行文本转图像的步骤:
-
输入文本内容:
- 使用MetaGPT的输入工具,输入需要转换的文本内容。
- 通过MetaGPT的分析功能,理解文本的结构和语义。
-
选择图像风格:
- 使用MetaGPT的风格选择工具,选择适合的图像风格,如卡通、现实、抽象等。
- 通过MetaGPT的预览功能,查看生成的图像效果。
-
生成和优化图像:
- 使用MetaGPT的生成功能,将文本内容转换为视觉图像。
- 根据需要,对生成的图像进行优化和调整,确保图像质量和视觉效果。
8.4 邮件摘要与回复
邮件摘要与回复是一个自动化处理电子邮件的过程,它可以帮助用户快速处理大量邮件,提高工作效率。MetaGPT提供了强大的邮件摘要与回复功能,可以帮助用户高效地管理邮件。
使用MetaGPT进行邮件摘要与回复的步骤:
-
邮件摘要:
- 使用MetaGPT的邮件摘要功能,自动提取邮件的关键信息和要点。
- 通过MetaGPT的分析功能,理解邮件的内容和意图。
-
生成回复内容:
- 使用MetaGPT的生成功能,根据邮件内容和用户设置的回复模板,生成回复内容。
- 通过MetaGPT的预览功能,查看生成的回复内容。
-
发送回复邮件:
- 使用MetaGPT的发送功能,将生成的回复内容发送给邮件发送者。
- 通过MetaGPT的记录功能,跟踪和管理邮件处理过程。
通过以上步骤,MetaGPT可以帮助用户高效地进行网页模仿、网络抓取、文本转图像和邮件摘要与回复,从而提高工作效率和质量。
MetaGPT的深入指南
9.1 代理通信
在MetaGPT框架中,代理通信是实现多代理协作的核心机制。每个代理(Agent)在系统中扮演特定的角色,并通过高效的通信机制与其他代理进行信息交换和任务协调。
通信协议
MetaGPT采用了一种基于自然语言处理的通信协议,使得代理之间可以通过文本消息进行交流。这种协议不仅支持简单的命令和响应,还能够处理复杂的对话和协商过程。
消息传递
代理之间的消息传递是通过一个中央消息队列系统实现的。每个代理可以将消息发送到队列中,其他代理则从队列中读取消息并作出响应。这种设计确保了消息的可靠传递和处理顺序。
示例代码
# 代理A发送消息到队列
message = {"sender": "AgentA","receiver": "AgentB","content": "请求数据更新"
}
message_queue.put(message)# 代理B从队列中读取消息并处理
while True:message = message_queue.get()if message["receiver"] == "AgentB":process_message(message)
9.2 增量开发
MetaGPT支持增量开发模式,这意味着系统可以在不中断当前运行的情况下逐步添加新功能或改进现有功能。
模块化设计
系统的每个组件都是模块化的,可以独立开发和测试。这种设计使得新功能的添加和现有功能的修改变得更加容易和安全。
版本控制
MetaGPT使用版本控制系统来管理代码和配置文件的变更。每个版本的变更都会被记录,并且可以回滚到之前的版本。
示例代码
# 添加新功能模块
def new_feature():# 新功能的实现代码pass# 在主程序中调用新功能
if __name__ == "__main__":new_feature()
9.3 序列化与断点恢复
为了确保系统的可靠性和持续运行,MetaGPT提供了序列化和断点恢复功能。
序列化
序列化是将代理的状态和数据转换为可以存储或传输的格式。这使得系统可以在需要时保存当前状态,并在之后恢复。
断点恢复
断点恢复是指在系统重启或崩溃后,能够从之前保存的状态继续运行,而不是从头开始。
示例代码
# 序列化代理状态
def serialize_agent_state(agent):state = {"memory": agent.memory,"current_task": agent.current_task}with open("agent_state.json", "w") as file:json.dump(state, file)# 恢复代理状态
def deserialize_agent_state(agent):with open("agent_state.json", "r") as file:state = json.load(file)agent.memory = state["memory"]agent.current_task = state["current_task"]
9.4 RAG模块环境
RAG(Retrieval Augmented Generation)模块是MetaGPT中的一个关键组件,用于增强自然语言生成的质量和准确性。
数据检索
RAG模块通过从外部数据源检索相关信息来丰富生成内容。这些数据源可以包括知识库、数据库或其他文本资源。
信息融合
检索到的信息与生成模型生成的内容进行融合,以提高生成文本的准确性和相关性。
示例代码
# RAG模块实现
def rag_module(query):# 从外部数据源检索信息retrieved_info = retrieve_from_external_source(query)# 融合检索到的信息和生成内容generated_content = generate_content(query)fused_content = fuse_content(generated_content, retrieved_info)return fused_content
MetaGPT的贡献指南
10.1 贡献指南
在MetaGPT项目中,我们欢迎并鼓励社区成员的贡献。无论您是经验丰富的开发者还是初学者,都可以通过以下步骤参与到项目的开发中来。
10.1.1 准备工作
在开始贡献之前,请确保您已经完成了以下准备工作:
- Fork项目:首先,您需要在GitHub上Fork MetaGPT项目到您的账户。
- 克隆项目:将Fork后的项目克隆到您的本地开发环境。
git clone https://github.com/your-username/MetaGPT.git - 安装依赖:进入项目目录并安装所需的依赖包。
cd MetaGPT pip install -r requirements.txt
10.1.2 贡献流程
- 创建分支:在您的本地仓库中创建一个新的分支进行开发。
git checkout -b your-new-branch-name - 代码编写:在新分支上进行代码编写和修改。请确保您的代码符合项目的编码规范。
- 测试:在提交代码之前,请确保所有的测试用例都能通过。
pytest - 提交代码:将您的修改提交到本地仓库。
git add . git commit -m "Your detailed description of your changes." - 推送代码:将您的分支推送到GitHub。
git push origin your-new-branch-name - 创建Pull Request:在GitHub上创建一个新的Pull Request,详细描述您的修改内容和目的。
10.1.3 代码审查
提交Pull Request后,项目维护者将对您的代码进行审查。请耐心等待审查结果,并根据反馈进行必要的修改。
10.2 API文档
为了帮助开发者更好地理解和使用MetaGPT的API,我们提供了详细的API文档。以下是一些关键API的简要介绍:
10.2.1 代理API
MetaGPT中的代理API允许开发者创建和管理多个代理,每个代理可以执行不同的任务。
from metagpt.agents import Agent# 创建一个新的代理
agent = Agent(name="Agent1", role="Assistant")# 执行任务
agent.execute("Task description")
10.2.2 任务API
任务API用于定义和管理代理需要执行的任务。
from metagpt.tasks import Task# 创建一个新的任务
task = Task(description="Task description", priority=1)# 分配任务给代理
agent.assign_task(task)
10.2.3 通信API
通信API用于代理之间的信息交流和协作。
from metagpt.communication import Message# 创建一个新的消息
message = Message(sender="Agent1", receiver="Agent2", content="Hello, Agent2!")# 发送消息
agent1.send_message(message)
10.3 常见问题
在开发和使用MetaGPT的过程中,您可能会遇到一些常见问题。以下是一些常见问题的解答:
10.3.1 如何解决依赖冲突?
在安装依赖包时,可能会遇到依赖冲突的问题。解决方法如下:
- 使用虚拟环境:建议使用虚拟环境来管理项目的依赖包。
python -m venv venv source venv/bin/activate # 在Windows上使用 `venv\Scripts\activate` - 更新依赖:使用
pip命令更新依赖包。pip install --upgrade -r requirements.txt
10.3.2 如何处理代码格式问题?
为了保持代码的一致性,建议使用prettier等工具进行代码格式化。
- 安装prettier:
npm install --save-dev prettier - 配置prettier:在项目根目录下创建一个
.prettierrc文件,并添加您的格式化规则。 - 运行prettier:使用以下命令格式化您的代码。
npx prettier --write .
相关文章:

MetaGPT全面指南:多代理协作框架的深入解析与应用
文章目录 理解MetaGPT1.1 MetaGPT的基础1.2 MetaGPT的独特之处1.3 MetaGPT在AI领域的应用 MetaGPT的工作原理2.1 训练2.2 微调2.3 推理2.4 多代理协作的概念2.5 如何分配角色给GPTs2.6 复杂任务的完成过程 实际应用3.1 客户支持3.2 内容创作3.3 教育3.4 医疗保健3.5 在企业中的…...

图的关键路径算法
关键路径算法(Critical Path Method, CPM)是一种用于项目管理和调度的技术,通过分析项目任务的最早开始时间、最晚完成时间和总时差,找出项目中关键的任务路径。这条关键路径决定了项目的最短完成时间,因为关键路径上的…...

模型情景制作-冰镇啤酒
夏日炎炎,当我们在真实世界中开一瓶冰镇啤酒的时候,我们也可以为模型世界中的人物添加一些冰镇啤酒。 下面介绍一种快速酒瓶制造方法,您只需要很少工具: 截取尽量直的流道(传说中的板件零件架),将其夹在您的…...

网页实现黑暗模式的几种方式
## 实现暗黑模式的最佳方式 在现代网页设计中,暗黑模式已成为提高用户体验的重要功能。实现暗黑模式不仅可以减少用户眼睛的疲劳,还能在某些情况下节省设备电量。本文将介绍实现暗黑模式的几种最佳方式。 ### 使用 CSS 变量 (CSS Custom Properties) …...
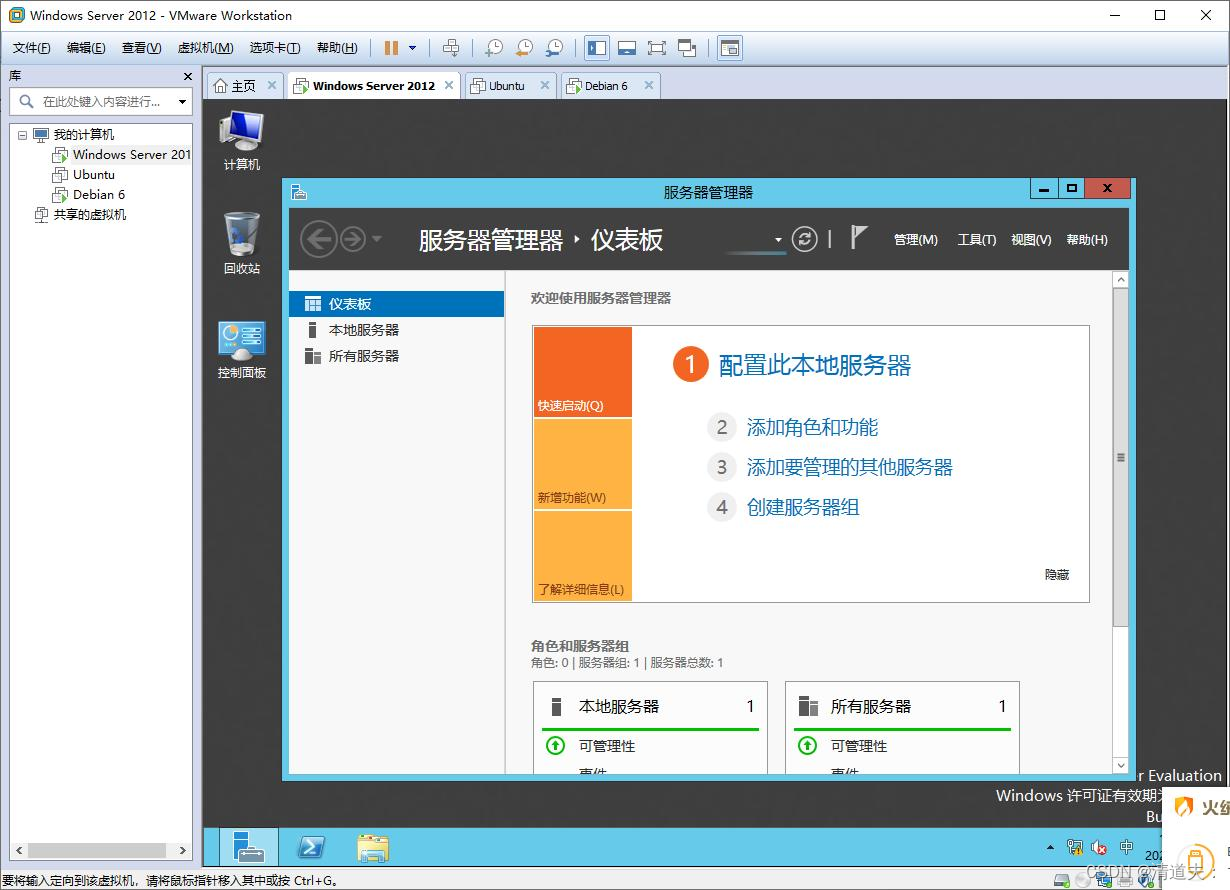
VMware Workstation环境下,邮件(E-Mail)服务的安装配置,并用Windows7来验证测试
需求说明: 某企业信息中心计划使用IP地址17216.11.0用于虚拟网络测试,注册域名为xyz.net.cn.并将172.16.11.2作为主域名的服务器(DNS服务器)的IP地址,将172.16.11.3分配给虚拟网络测试的DHCP服务器,将172.16.11.4分配给虚拟网络测试的web服务器,将172.16.11.5分配给FTP服务器…...

《信号与系统》复试建议
目录 第一章 绪论 第二章 连续时间系统的时域分析 第三章 傅立叶变换(重点) 第四章 拉普拉斯变换(重点) 第五章 傅立叶变换在通信系统中的应用 第六章 信号的矢量空间分析 第七章 离散时间系统的时域分析 第八章 Z变换与离…...

代码随想录训练营Day45
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、打家劫舍二、打家劫舍2三、打家劫舍3 前言 提示:这里可以添加本文要记录的大概内容: 今天是跟着代码随想录刷题的第45天ÿ…...
NAT和内网穿透
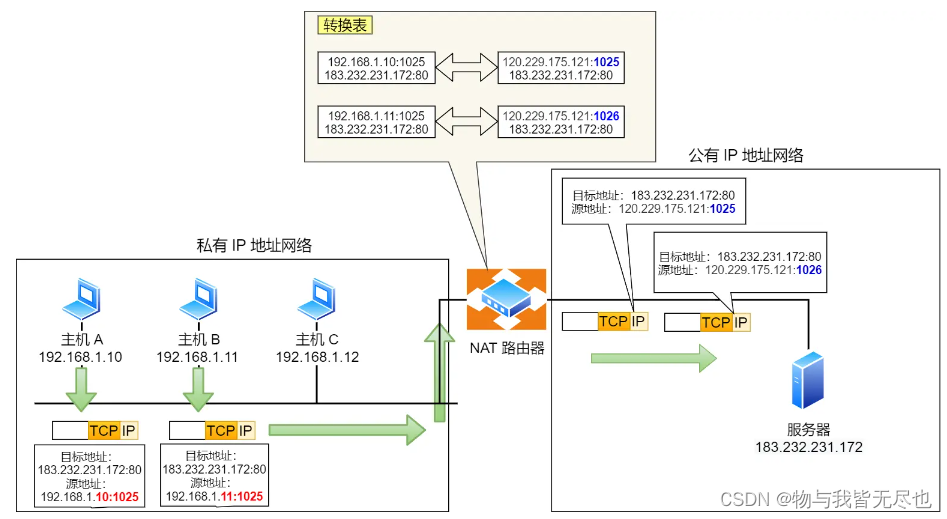
NAT(Network Address Translation,网络地址转换)是一种广泛应用于计算机网络的技术,其主要目的是为了解决IPv4地址空间的短缺问题,并且增强网络安全。NAT技术允许一个私有网络内的多个设备共享一个或几个全局唯一的公共…...
)
android | 声明式编程!(笔记)
https://www.jianshu.com/p/c133cb7cac21 讲的不错 命令式UI (how to do) 声明式UI (what to do) what to do 也许有人会说Data Binding不是可以让XML自己"动"起来吗?没有错,Data Binding其实就是Compose诞生之前的一种声明式U方案,谷歌曾…...
友力科技IDC机房搬迁方案流程分享
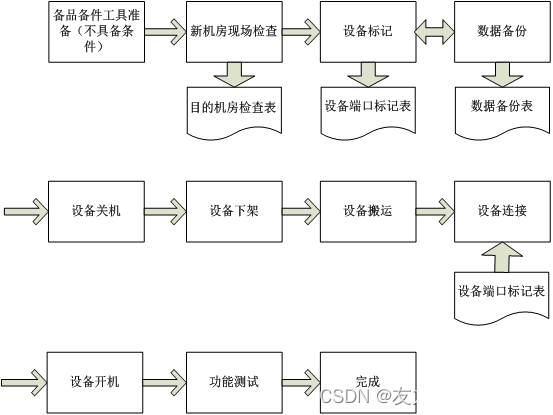
机房搬迁流程 系统搬迁实施流程包括:准备、拆卸、装运、安装、调试等五个流程,具体如下: 准备:包括相关人员和设备准备、新机房环境准备、网络环境、备份、现场所有设备打标签、模块、设备准备等准备工作。拆卸:主要只核心设备下…...
仿迪恩城市门户分类信息网discuz模板
Discuz x3.3模板 仿迪恩城市门户分类信息网 (GBK) Discuz模板 仿迪恩城市门户分类信息网(GBK)...
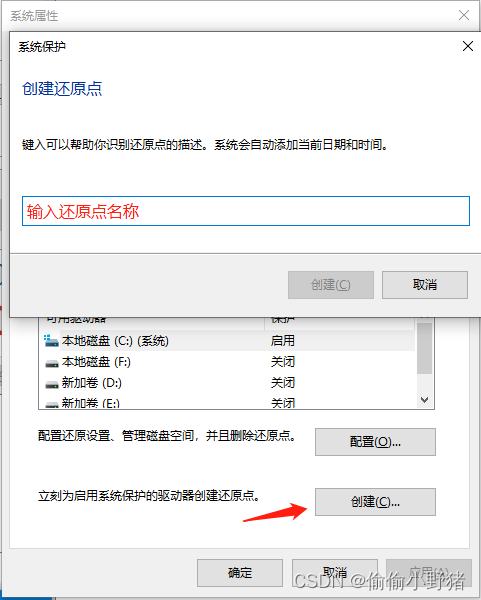
Windows 注册表是什么?如何备份注册表?
Windows注册表(Windows Registry)是微软Windows操作系统中的一个重要组件,用于存储系统和应用程序的配置信息和选项。下面就给大家详细讲解一下什么是注册表。 注册表的概念 Windows 注册表是一个集中管理的数据库,存储了系统、…...

B+树与索引解析
文章目录 B树与索引简介几个关键点应用案例场景描述索引创建查询操作更新操作并发处理 Python代码示例 B树与索引简介 B树是一种在计算机科学中广泛使用的自平衡的树数据结构,它能保持数据排序,并且搜索、插入和删除操作的时间复杂度都是O(log n)。B树被…...

华为认证hcna题库背诵技巧有哪些?hcna和hcia有什么区别?
大家都知道华为认证hcna是有题库供考生刷题备考的,但题库中海量的题目想要在短时间背诵下来可并不是一件容易的事情,这就需要我们掌握一定的技巧才行。华为认证hcna题库背诵技巧有哪些? hcna和hcna这二者又有什么区别呢?今天的文章将为大家进行详细解…...

【常用报文状态码】
常见的报文状态码如下 200 OK:客户端请求成功。 301 Moved Permanently:表示请求的资源已经被永久移动到了新的URL上; 302 Found:表示请求的资源已经被临时移动到了新的URL上; 304 Not Modified:表示客户…...
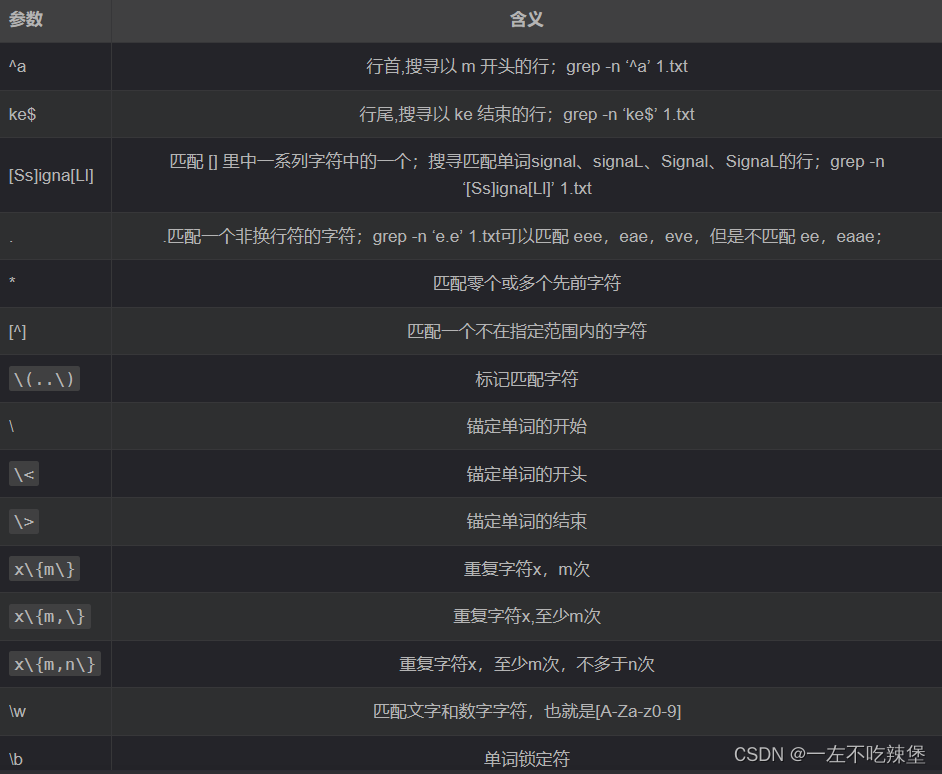
Linux命令详解
1.目录结构 2.history游览历史 3.命令行中的ctrl组合键 4.列出目录的内容 5.修改文件权限chmod 6.文件内容查看 文件管理 7.输出重定向:> 8.管道:| 9.清屏:clear 10.显示当前路径:pwd 11.创建目录:mkdir…...
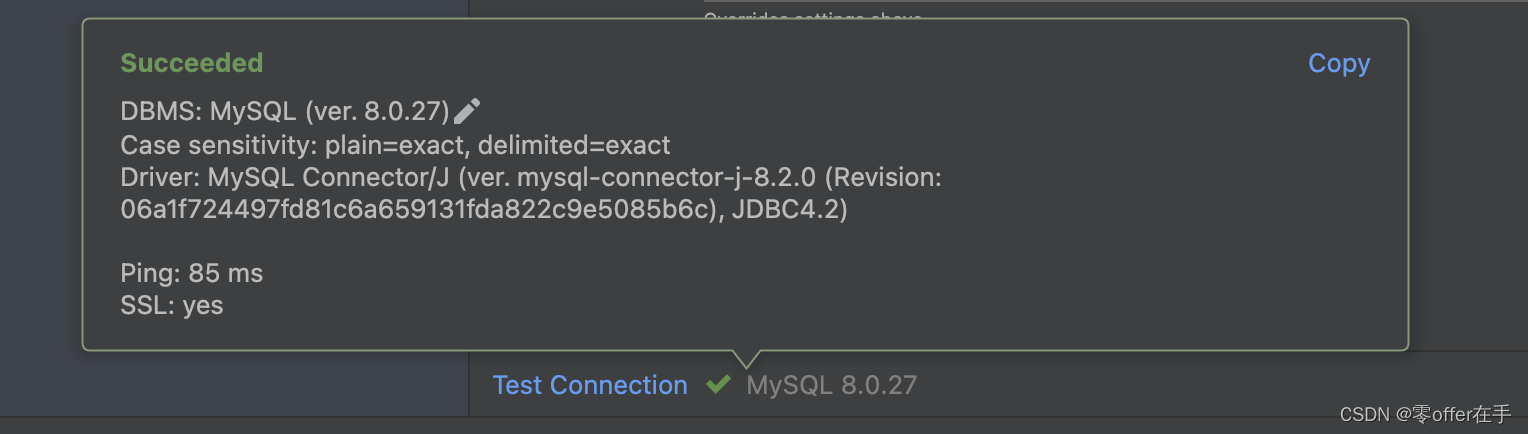
在阿里云使用Docker部署MySQL服务,并且通过IDEA进行连接
阿里云使用Docker部署MySQL服务,并且通过IDEA进行连接 这里演示如何使用阿里云来进行MySQL的部署,系统使用的是Linux系统 (Ubuntu)。 为什么使用Docker? 首先是因为它的可移植性可以在任何有Docker环境的系统上运行应用,避免了在不通操作系…...
实现技巧)
Spring Boot中的国际化(i18n)实现技巧
Spring Boot中的国际化(i18n)实现技巧 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!在开发多语言支持的应用程序时,国际化…...

vite-ts-cesium项目集成mars3d修改相关的包和配置参考
如果vite技术栈下使用原生cesium,请参考下面文件的包和配置修改,想用原生创建的viewer结合我们mars3d的功能的话。 1. package.json文件 "dependencies": {"cesium": "^1.103.0","mars3d": "^3.7.18&quo…...

「树莓派入门」树莓派基础04-VNC连接与配置静态IP
一、VNC连接配置 1. 启用VNC服务 在树莓派上,通过 raspi-config 工具启用VNC服务: sudo raspi-config在配置界面中选择 “Interfacing Options”,然后选择 “VNC” 并启用它。 2. 连接到VNC服务器 在电脑端安装VNC客户端,如V…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
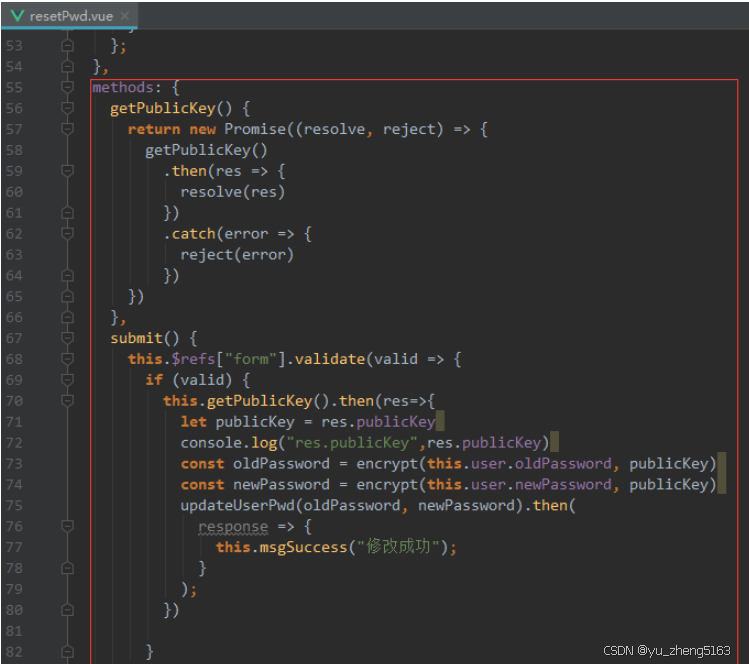
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...

第八部分:阶段项目 6:构建 React 前端应用
现在,是时候将你学到的 React 基础知识付诸实践,构建一个简单的前端应用来模拟与后端 API 的交互了。在这个阶段,你可以先使用模拟数据,或者如果你的后端 API(阶段项目 5)已经搭建好,可以直接连…...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...

Neo4j 完全指南:从入门到精通
第1章:Neo4j简介与图数据库基础 1.1 图数据库概述 传统关系型数据库与图数据库的对比图数据库的核心优势图数据库的应用场景 1.2 Neo4j的发展历史 Neo4j的起源与演进Neo4j的版本迭代Neo4j在图数据库领域的地位 1.3 图数据库的基本概念 节点(Node)与关系(Relat…...