AudioLM音频生成模型
GPT-4o (OpenAI)
AudioLM(Audio Language Model)是一种生成音频的深度学习模型。它可以通过学习语言模型的结构来生成连贯和高质量的音频信号。这类模型通常应用于语音合成、音乐生成和音频内容生成等领域。以下是一些与AudioLM相关的核心概念和技术细节:
1. **模型架构**:
- AudioLM通常包含多个组件,如音频编码器、解码器和变换器。这些组件共同作用以捕捉音频信号的时域和频域特征。
2. **预处理**:
- 输入的音频数据通常会进行预处理步骤,如音频剪辑、采样率转换和归一化。
3. **特征提取**:
- 利用卷积神经网络(CNN)或者变换器网络提取音频数据的特征。
4. **语言模型**:
- 像GPT或Transformer这样的语言模型可以用于理解和生成音频数据的序列结构。
5. **训练**:
- 训练AudioLM需要大量的音频数据,这些数据可以是语音、音乐或者其他形式的音频。
- 通常采用监督学习或自监督学习的方法进行训练。
以下是一个简化的AudioLM音频生成模型的概述和示例代码(以Python和深度学习框架,如PyTorch为例):
### 模型架构示例
import torch
import torch.nn as nn
import torchaudioclass AudioEncoder(nn.Module):def __init__(self):super(AudioEncoder, self).__init__()self.conv1 = nn.Conv1d(1, 32, kernel_size=3, stride=1, padding=1)self.conv2 = nn.Conv1d(32, 64, kernel_size=3, stride=1, padding=1)self.pool = nn.MaxPool1d(2)def forward(self, x):x = self.pool(torch.relu(self.conv1(x)))x = self.pool(torch.relu(self.conv2(x)))return xclass AudioDecoder(nn.Module):def __init__(self):super(AudioDecoder, self).__init__()self.deconv1 = nn.ConvTranspose1d(64, 32, kernel_size=3, stride=2, padding=1, output_padding=1)self.deconv2 = nn.ConvTranspose1d(32, 1, kernel_size=3, stride=2, padding=1, output_padding=1)def forward(self, x):x = torch.relu(self.deconv1(x))x = torch.sigmoid(self.deconv2(x))return xclass AudioLM(nn.Module):def __init__(self):super(AudioLM, self).__init__()self.encoder = AudioEncoder()self.decoder = AudioDecoder()self.transformer = nn.Transformer(d_model=64, nhead=8, num_encoder_layers=6)def forward(self, x):x = self.encoder(x)x = self.transformer(x, x)x = self.decoder(x)return x# 示例模型实例化
model = AudioLM()### 训练和生成音频示例
# 假设我们有一个音频数据集
dataset = ... # 你的音频数据集
dataloader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)# 优化器和损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()# 训练循环
for epoch in range(num_epochs):for audio in dataloader:optimizer.zero_grad()output = model(audio)loss = criterion(output, audio)loss.backward()optimizer.step()print(f'Epoch {epoch+1}, Loss: {loss.item()}')# 生成音频示例
with torch.no_grad():noise = torch.randn(1, 1, 16000) # 假设我们生成一秒钟的音频(采样率16kHz)generated_audio = model(noise)这只是一个示意性的模型示例,实际的AudioLM可能会更复杂并包含更多的细节和优化。这些例子旨在展示音频生成模型的一般工作流程和核心组件。实际应用中,可能需要对模型结构、损失函数和训练流程做进一步的调整和优化。

Claude3 Opus
对于AudioLM音频生成模型,您可以使用以下步骤进行构建和训练:
1. 数据准备:
- 收集音频数据集,并将其转换为适当的音频格式(例如.wav)。
- 准备标签或文本对应于每个音频样本的文本数据。
2. 模型选择:
- 考虑使用DeepSpeech或Tacotron等现有的音频生成模型作为基础模型。
- 或者,您可以使用现有的语音识别模型,如ASR模型,作为生成模型的基础。
3. 数据处理:
- 使用所选模型的要求对音频数据和文本数据进行处理和预处理。
- 将音频数据转换为模型可接受的音频表示形式,如声谱图(Spectrogram)或梅尔频谱图(Mel Spectrogram)。
- 将文本数据转换为模型可以理解的输入形式,如字符级别的标记序列或音节级别的标记序列。
4. 模型构建:
- 基于选定的模型,使用适当的深度学习框架(如TensorFlow、PyTorch、MindSpore等)构建音频生成模型。
- 在模型中使用适当的循环神经网络(如LSTM、GRU)或卷积神经网络结构,并根据需要增加注意力机制。
5. 模型训练:
- 划分训练集和验证集,并将数据提供给模型进行训练。
- 定义合适的损失函数,如CTC Loss(对于音频转录任务)或MSELoss(对于音频合成任务)。
- 使用合适的优化器(如Adam、SGD)和学习率调度器,通过迭代优化模型参数。
6. 模型评估:
- 使用验证集评估模型的性能和生成结果的质量。
- 使用相应的评估指标(如WER、MOS等)进行性能评估和比较。
7. 模型推理:
- 使用训练好的模型进行音频生成。
- 提供输入音频或文本,模型将生成对应的音频输出。
请注意,以上步骤只是一个大致的指导,实际实现过程可能因所选模型和目标任务而有所不同。在实践中,您可能还需要调整和优化模型参数、数据预处理流程以及训练和推理的特定细节。
另外,请确保您对音频生成任务和所选模型有一定的理解,并遵循合适的伦理和法律准则,特别是在涉及敏感内容的情况下。
希望这些步骤对您构建和训练音频生成模型有所帮助。如果您有其他问题,请随时提问!

GPT-3.5 (OpenAI)
AudioLM是一种语音合成模型,可用于生成自然语音或合成谈话音频。它基于深度神经网络,使用语音合成技术,可以听起来非常逼真。下面是一个简单的使用方法:
1. 数据准备
首先,你需要准备一些音频语言模型(AudioLM)的数据。这些数据可以是音频波形,也可以是音频特征向量,如Mel频谱或MFCC(梅尔频率倒谱系数)。你可以使用自己的数据集,也可以使用开源数据集,例如LJSpeech、VCTK等。
2. 数据预处理
你需要将音频数据转换为计算机可以处理的格式。通常情况下,你需要将音频波形转换为Mel频谱或MFCC特征向量。使用Python中的Librosa或PyTorch中的torchaudio库,可以很容易地将音频数据转换为Mel频谱或MFCC特征向量。
3. 准备模型
你需要选择一个合适的预训练的AudioLM模型,或者自己训练一个,然后初始化该模型并加载已训练的参数。预训练的模型通常可以从开源平台、论文或软件包中获取。
4. 模型推理
选定合适的模型后,你可以使用该模型生成音频波形。输入某个文本或特征向量,输出相应的音频波形。根据需要生成的音频长度,你可以在模型的输出上重复这个过程,直到达到所需的长度为止。
5. 合成音频
模型生成的音频波形一般是以数字形式存储的,你需要将其转换为音频文件,如mp3、wav等,以供播放和使用。使用Python中的音频库,如PyDub或SoundFile,可以很容易地将数字音频转换为音频文件。

文心一言
AudioLM音频生成模型是谷歌研究团队推出的一种具有创新性的音频生成技术。以下是关于AudioLM音频生成模型的详细介绍:
- 模型概述:
- AudioLM是一个高质量的音频生成框架,它通过将输入的音频映射到一系列离散的标记,并将音频生成任务转化为语言建模任务,从而实现了音频的高效生成。
- 该模型结合了深度学习、语言建模和音频处理等领域的最新技术,旨在生成长期一致性和高质量的音频。
- 技术特点:
- 混合分词方案:AudioLM采用了一种混合的分词方案,通过预训练的掩膜语言模型的离散化激活和神经音频编解码器产生的离散代码,实现了在音频生成质量和长期结构之间的平衡。
- 无需文本标注:AudioLM可以在没有任何文字标注或注释的情况下,通过大量无监督数据训练,生成句法和语义上合理的语音延续,同时还保持说话人身份和韵律。
- 多功能性:除了生成语音外,AudioLM还能生成连贯的钢琴音乐,其旋律、和声、音调和节奏都与提示一致。
- 应用场景:
- 虚拟助理:AudioLM可以生成自然流畅的语音,为虚拟助理提供高质量的语音交互体验。
- 内容创作:在音频内容创作领域,AudioLM可以生成各种风格的音乐、声音效果等,为创作者提供更多灵感和选择。
- 无障碍技术:通过AudioLM生成的语音,可以帮助视障人士更好地获取信息,提升生活质量。
- 教育与培训:在教育领域,AudioLM可以生成各种教学音频,为学生提供更加丰富多样的学习体验。
- 性能优势:
- 高保真度:AudioLM生成的音频质量高,保真度好,几乎与人类真实语音无法区分。
- 多样性与灵活性:AudioLM可以生成多种风格和类型的音频,满足用户不同的需求。
- 自适应能力:该模型具有较强的自适应能力,可以适应不同的应用场景和用户需求。
- 未来发展:
- AudioLM作为音频生成技术的未来方向之一,将不断融合新技术、新应用,推动音频生成技术的进一步发展。
- 未来的研究将关注于如何提高AudioLM的实时生成能力、跨语言音频生成能力等方面,以满足更多实际应用的需求。
综上所述,AudioLM音频生成模型是一种具有创新性、高性能的音频生成技术,将在未来的音频处理和应用领域发挥重要作用。

deepseek
AudioLM 是一个先进的音频生成模型,它能够根据给定的文本描述生成相应的音频内容。这个模型通常结合了自然语言处理和音频信号处理的技术,以确保生成的音频与文本内容相匹配,并且听起来自然流畅。
AudioLM 的工作流程通常包括以下几个步骤:
-
文本理解:模型首先解析输入的文本,理解其含义和情感色彩。
-
音频特征提取:根据文本内容,模型提取相关的音频特征,如音调、节奏、音量等。
-
音频合成:使用提取的特征,模型生成相应的音频波形。
-
后处理:对生成的音频进行必要的后处理,如降噪、均衡等,以提高音频质量。
AudioLM 的应用非常广泛,包括但不限于:
-
语音合成:生成自然语言的语音输出,适用于有声书、语音助手等。
-
音乐创作:根据文本描述生成音乐片段,辅助音乐创作。

Kimi
AudioLM是一个音频生成模型,它使用深度学习技术来生成逼真的音频信号。这类模型通常基于生成对抗网络(GANs)、变分自编码器(VAEs)或Transformer架构,能够学习音频数据的分布,并生成新的音频样本。以下是一些关于AudioLM音频生成模型的关键点:
-
数据预处理:在训练之前,原始音频数据通常需要进行预处理,如归一化、分割和特征提取。
-
模型架构:AudioLM模型可能采用多种架构,包括但不限于CNN、RNN、LSTM、GRU或Transformer,以捕捉音频数据的时间序列特征。
-
生成机制:模型使用学习到的特征表示来生成新的音频样本,这可能涉及到随机噪声的注入和逐步生成音频波形。
-
训练过程:训练AudioLM模型需要大量的音频数据,以及对模型的持续迭代和优化。
-
评估指标:生成音频的质量可以通过多种指标评估,如频率响应、波形相似度或主观听觉测试。
-
应用场景:AudioLM模型可以应用于音乐合成、语音合成、声音效果生成、音频数据增强等领域。
-
技术挑战:生成高质量的音频需要模型能够捕捉音频信号的复杂结构和细微差别,这在技术上是一个挑战。
-
开源实现:一些AudioLM模型可能是开源的,允许研究人员和开发者下载、修改和重新训练。
-
伦理和法律问题:音频生成技术可能引发伦理和法律问题,如深度伪造(deepfakes)和版权问题,需要谨慎使用。
-
未来趋势:随着技术的进步,AudioLM模型可能会变得更加先进,生成更逼真和多样化的音频内容。
请注意,由于AudioLM不是一个特定的、广泛认可的模型名称,上述内容是基于音频生成模型的一般性描述。如果你指的是某个具体的模型或项目,请提供更多的上下文或详细信息,以便给出更准确的介绍。

讯飞星火
AudioLM是一种革命性的音频生成模型,它结合了深度学习和自然语言处理的技术,能够生成高质量、逼真的音频内容。
AudioLM模型是位于音频生成技术前沿的一个典型代表。它运用了Transformer架构,这是一种最初为处理序列数据如文本而设计的模型结构,但已被成功地应用于处理音频数据。AudioLM通过学习大量的音频样本,掌握音频的时序结构和内容信息。其核心机制是自注意力机制(Self-Attention Mechanism),这一机制使得模型能够捕捉到音频信号中的长距离依赖关系,从而生成连贯且自然的音频序列。
AudioLM的工作机制主要分为预处理、建模和生成三个阶段。在预处理阶段,原始音频数据转换成适合模型训练的格式,如梅尔频谱(Mel Spectrogram)。在建模阶段,通过自注意力机制学习音频数据的内在结构和特征。在生成阶段,模型根据给定的条件生成新的音频内容。
AudioLM可应用于多种场景。在语音合成方面,AudioLM能把文字输入转化为流畅自然的语音输出,适用于文本到语音系统。在音乐创作领域,它通过分析已有的音乐数据学习不同音乐风格的特点,并根据创意生成新的旋律和节奏。此外,AudioLM还能用于音频修复,修复受损或噪音干扰的音频,恢复其清晰度和质量。在交互式娱乐应用中,如视频游戏和虚拟现实,AudioLM能生成逼真的音效和背景音乐,提升用户的沉浸感和体验。
尽管AudioLM展示了强大的能力,但它也面临一些挑战。首先,这种模型需要大量的计算资源进行训练和推理,可能限制了它在资源受限设备上的部署。其次,随着生成内容的逼真度越来越高,可能会引发伦理和社会问题,如虚假信息传播和隐私侵犯。此外,生成的音频内容可能涉及版权问题,特别是在音乐和语音合成领域,这需要确保生成内容的合法性。
总的来说,AudioLM作为一种先进的音频生成模型,不仅推动了音频生成技术的进步,也为相关行业带来了新的机遇和挑战。它的出现使得音频内容的创造更加高效和多样化,同时也带来了对计算资源、版权、伦理和社会影响等方面的新挑战。

通义千问
AudioLM是Google研发的一种先进的音频生成模型,它展现了在音乐和语音合成方面的强大能力。以下是关于AudioLM的一些关键特点和功能:
-
音乐生成:AudioLM能够生成与给定风格或片段一致的高质量、连贯的音乐。这意味着,只要给模型一个简短的音乐提示,它就能够继续创作出与之风格相似的音乐,无论是复杂的钢琴曲还是其他类型的音乐,其生成的结果往往难以与原作区分开来。
-
语音合成:除了音乐,AudioLM还能生成类似真人的语音。给定一个语音片段作为输入,它可以生成与之语调、情感相匹配的连贯语音,进一步展示了其在音频合成领域的广泛适用性。
-
无需转录或标记:与一些需要音频数据转录或额外标签的模型不同,AudioLM直接从原始音频中学习,简化了数据处理流程,提高了模型的灵活性和泛化能力。
-
基于语言模型的方法:尽管被称作“音频语言模型”,AudioLM借鉴了文本语言模型的原理,将音频序列量化成离散的tokens(类似于文本中的单词),再通过预测下一个token来生成音频序列,这种做法使得模型能够理解和生成长时相关的音频结构。
-
与PaLM的融合:在某些应用中,如AudioPaLM,AudioLM被与Google的大型语言模型PaLM结合,形成了一个多模态系统。这样的结合不仅能够处理文本,还能理解和生成语音,支持语音识别和语音翻译等功能,极大地扩展了模型的应用范围。
-
技术突破:AudioLM的成功在于它能够在没有文本或其他形式的辅助信息的情况下,仅凭音频输入就能生成高度逼真的音频内容,这是之前的技术难以达到的。这反映了深度学习在处理非结构化数据,如音频信号方面取得的重要进展。
综上所述,AudioLM代表了音频生成领域的一个重要里程碑,其在音乐创作、语音合成以及跨模态交互方面的潜力,为创意产业和人工智能研究开辟了新的可能性。

腾讯元宝
- 1. AudioLM - GitHub Pages
- 2. AudioLM: a Language Modeling Approach to Audio Generation - arXiv.org
- 3. AudioLM:一种音频生成的语言建模方法
- 4. 【Audio Generation】AudioLM: a Language Modeling ...
- 5. 谷歌AudioLM :通过歌曲片段生成后续的音乐_知乎
- 6. 音频生成 | 论文笔记 | AudioLM
AudioLM是一种用于高质量音频生成的框架,它通过将输入音频映射到离散标记序列,并将音频生成视为该表示空间中的语言建模任务。以下是关于AudioLM的详细介绍:
AudioLM的工作原理
AudioLM结合了自监督音频模型w2v-BERT和SoundStream神经编解码器,分别用于提取语义标记和声学标记。这些标记捕获音频的局部依赖性和全局长期结构,同时允许对长序列进行建模。通过这种方式,AudioLM能够在保持音频质量的同时,生成自然连贯的音频延续1234。
AudioLM的应用场景
- 语音生成:AudioLM能够生成语法和语义上合理的语音延续,同时保持说话人身份和韵律1234。
- 音乐生成:除了语音,AudioLM还能够生成连贯的钢琴音乐延续,展示了其扩展到音乐领域的能力1234。
AudioLM的研究进展
尽管搜索结果中没有直接提供AudioLM的最新研究进展,但根据其设计和应用,可以推测该领域的研究正在不断发展,探索更多的音频生成可能性。
总的来说,AudioLM是一个强大的音频生成框架,它结合了先进的音频处理和语言建模技术,为音频生成领域带来了新的可能性。
相关文章:
AudioLM音频生成模型
GPT-4o (OpenAI) AudioLM(Audio Language Model)是一种生成音频的深度学习模型。它可以通过学习语言模型的结构来生成连贯和高质量的音频信号。这类模型通常应用于语音合成、音乐生成和音频内容生成等领域。以下是一些与AudioLM相关的核心概念和技术细…...

Shardingsphere-Proxy 5.5.0数据迁移
Shardingsphere-Proxy 5.5.0数据迁移 Shardingsphere系列目录:背景配置集群部署搭建Zookeeper修改shardingsphere-proxy配置重启shardingsphere-proxy 执行数据迁移连接代理数据库实例(Navicate)应用代理数据库注册目标分片数据库存储单元注销…...

c语言中的for循环
在C语言中,for循环是控制结构之一,用于多次执行一段代码。其具体用法如下: 语法 for (初始化表达式; 条件表达式; 更新表达式) {// 循环体 }参数说明 初始化表达式:在循环开始前执行一次,用于初始化循环控制变量。条…...
方法)
大模型微调(finetune)方法
lora adapter prefix-tuning p-tuning prompt-tuning 大模型微调后灾难行遗忘 1、主流解决大模型微调后灾难行遗忘的方法是在微调过程中加入通用的指令数据。 2、自我蒸馏方法主要是通过模型本身对任务数据进行生成引导,构建自我蒸馏数据集,改变任务数…...

Bootstrap 5 卡片
Bootstrap 5 卡片 Bootstrap 5 是一个流行的前端框架,它提供了一套丰富的组件和工具,用于快速开发响应式和移动设备优先的网页。在 Bootstrap 5 中,卡片(Card)是一个非常重要的组件,用于展示内容,如文本、图片、列表等。卡片组件具有高度的灵活性和可定制性,可以轻松地…...
【ONLYOFFICE 8.1】的安装与使用——功能全面的 PDF 编辑器、幻灯片版式、优化电子表格的协作
🔥 个人主页:空白诗 文章目录 一、引言二、ONLYOFFICE 简介三、安装1. Windows/Mac 安装2. 文档开发者版安装安装前准备使用 Docker 安装使用 Linux 发行版安装配置 ONLYOFFICE 文档开发者版集成和开发 四、使用1. 功能全面的 PDF 编辑器PDF 查看和导航P…...

「51媒体」浙江地区媒体邀约
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 媒体宣传加速季,100万补贴享不停,一手媒体资源,全国100城线下落地执行。详情请联系胡老师。 浙江地区的媒体邀约资源丰富多样,涵盖了电视台…...

2-18 基于matlab的关于联合对角化盲源分离算法的二阶盲识别(SOBI)算法
基于matlab的关于联合对角化盲源分离算法的二阶盲识别(SOBI)算法。通过联合对角化逼近解混矩阵。构建的四组信号,并通过认为设置添加噪声比例,掩盖信号信息。通过SOBI算法实现了解混。程序已调通,可直接运行。 2-18联合…...

C++中常用的标志库
标准库 C标准库是一个强大的工具集,它包含了一组丰富的类和函数,可以帮助开发者进行各种操作,如输入输出、字符串操作、数据结构管理、算法实现等。以下是一些常用的C标准库及其使用方法。 1. 输入输出库 <iostream> 用于标准输入输…...

近期计算机领域的热点技术
随着科技的飞速发展,计算机领域的新技术、新趋势层出不穷。本文将探讨近期计算机领域的几个热点技术趋势,并对它们进行简要的分析和展望。 一、人工智能与机器学习 人工智能(AI)和机器学习(ML)是近年来计算…...

HarmonyOS Next 系列之可移动悬浮按钮实现(六)
系列文章目录 HarmonyOS Next 系列之省市区弹窗选择器实现(一) HarmonyOS Next 系列之验证码输入组件实现(二) HarmonyOS Next 系列之底部标签栏TabBar实现(三) HarmonyOS Next 系列之HTTP请求封装和Token…...

如何获得更高质量的回答-chatgpt
在与技术助手如ChatGPT进行交互时,提问的方式直接影响到你获得的答案质量。以下是几个关键的提问技巧,可以帮助你在与ChatGPT的互动中获得更有效的回答: 1. 清晰明了的问题 技巧:确保问题清晰明了,避免含糊不清或模糊的…...
ASP.NET Core 6.0 使用 Log4Net 和 Nlog日志中间件
前言 两年前,浅浅的学过 .NET 6,为啥要记录下来,大概是为了以后搭架子留下引线,还有抛砖引玉。 1. 环境准备 下载 建议使用 Visual Studio 2022 开发版 官网的下载地址:Visual Studio 2022 IDE - 适用于软件开发人员的编程工具借助 Visual Studio 设计,具有自动完成…...

使用Spring Boot实现与ActiveMQ的消息队列集成
使用Spring Boot实现与ActiveMQ的消息队列集成 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 消息队列在现代分布式系统中扮演着至关重要的角色,…...
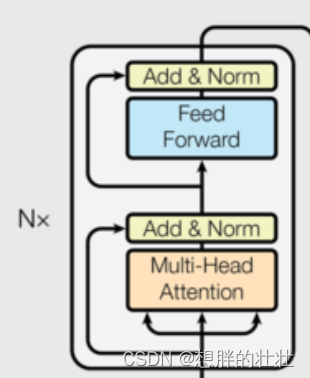
深度学习 - Transformer 组成详解
整体结构 1. 嵌入层(Embedding Layer) 生活中的例子:字典查找 想象你在读一本书,你不认识某个单词,于是你查阅字典。字典为每个单词提供了一个解释,帮助你理解这个单词的意思。嵌入层就像这个字典…...
ONLYOFFICE 8.1编辑器桌面应用程序来袭——在线全面测评
目录 ✈下载✈ 👀界面👀 👊功能👊 🧠幻灯片版式的重大改进🧠 ✂无缝切换文档编辑、审阅和查看模式✂ 🎵在演示文稿中播放视频和音频文件🎵 🤗版本 8.1:…...

《Windows API每日一练》6.4 程序测试
前面我们讨论了鼠标的一些基础知识,本节我们将通过一些实例来讲解鼠标消息的不同处理方式。 本节必须掌握的知识点: 第36练:鼠标击中测试1 第37练:鼠标击中测试2—增加键盘接口 第38练:鼠标击中测试3—子窗口 第39练&…...
[C#]基于opencvsharp实现15关键点人体姿态估计
数据集 正确选择数据集以对结果产生适当影响也是非常必要的。在此姿势检测中,模型在两个不同的数据集即COCO关键点数据集和MPII人类姿势数据集上进行了预训练。 1. COCO:COCO关键点数据集是一个多人2D姿势估计数据集,其中包含从Flickr收集的…...

lambda-map.merge
map.merge 结论: 1.当前传入的 key ,value biFunction 2.如果之前map不存在则直接put(当前key,当前value) 3.如果之前map已经有了,老value与 当前value 进入function处理后再 put(当前key,处理后的value)...

pppd 返回错误码 含义
错误码 00: pppd已经断开,或者已经成功建立连接后请求方又中 断了。 01: 发成了一个严重错误,例如系统调用失败或者访问非法内存。 02: 处理给定操作是检测到错误,例如使用两个互斥的操作。 03:…...

统信UOS桌面系统高效运维:从入门到精通的命令行指南
1. 为什么你需要掌握统信UOS命令行? 第一次接触统信UOS桌面系统时,很多人都会被它精美的图形界面吸引。但真正用过一段时间后,你会发现图形界面虽然友好,但在处理批量操作、远程管理、自动化任务时效率远不如命令行。我刚开始用U…...

如何快速合并B站缓存视频?BilibiliCacheVideoMerge完整解决方案指南
如何快速合并B站缓存视频?BilibiliCacheVideoMerge完整解决方案指南 【免费下载链接】BilibiliCacheVideoMerge 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCacheVideoMerge 你是否遇到过这样的困扰:在B站缓存了喜欢的视频准备离线观…...

3步突破语言壁垒:学术研究者的PDF翻译效率工具
3步突破语言壁垒:学术研究者的PDF翻译效率工具 【免费下载链接】zotero-pdf2zh PDF2zh for Zotero | Zotero PDF中文翻译插件 项目地址: https://gitcode.com/gh_mirrors/zo/zotero-pdf2zh 学术文献翻译是科研工作者日常研究中的重要环节,但传统翻…...

OpCore-Simplify:突破性自动化黑苹果配置工具,让OpenCore EFI生成从8小时缩短到30分钟
OpCore-Simplify:突破性自动化黑苹果配置工具,让OpenCore EFI生成从8小时缩短到30分钟 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simpli…...

快马平台AI助力:十分钟搭建技能学习交互原型
最近在尝试做一个技能学习平台的快速原型,发现用InsCode(快马)平台可以大大缩短开发时间。作为一个非专业前端开发者,我记录下这个十分钟搭建原型的实践过程,希望能给有类似需求的朋友一些参考。 项目构思与框架搭建 首先明确原型需要包含的五…...

GEMMA-3像素站保姆级教程:一键部署,体验90年代复古AI界面
GEMMA-3像素站保姆级教程:一键部署,体验90年代复古AI界面 1. 前言:像素与AI的奇妙碰撞 想象一下,当你童年的红白机游戏界面遇上了最前沿的多模态AI技术,会擦出怎样的火花?GEMMA-3像素站正是这样一个充满创…...
)
别再手动调API了!用Spring Boot + WebClient一键集成Dify智能体(附完整代码)
别再手动调API了!用Spring Boot WebClient一键集成Dify智能体(附完整代码) 在当今快节奏的开发环境中,手动编写重复的API调用代码不仅效率低下,还容易引入错误。对于使用Dify平台的Java开发者来说,如何将智…...

Windows用户也能玩转Luckfox Pico:从驱动安装到ADB配置全攻略
Windows用户玩转Luckfox Pico:从驱动安装到ADB配置实战指南 对于习惯了Windows环境的开发者来说,初次接触Luckfox Pico这类嵌入式开发板时,往往会遇到各种跨平台适配问题。本文将手把手带你解决Windows系统下的驱动安装、ADB配置等核心痛点&…...

当你紧张的时候看一下这个
https://blog.csdn.net/geniusChinaHN/article/details/159845569...

PlugY插件:暗黑破坏神2单机模式的终极增强指南
PlugY插件:暗黑破坏神2单机模式的终极增强指南 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 还在为暗黑破坏神2单机模式的种种限制而烦恼吗?…...