「Python 基础」常用模块
文章目录
- 1. 内建模块
- datetime
- collections
- namedtuple()
- deque
- defaultdict
- OrderedDict
- ChainMap
- Counter
- base64
- struct
- hashlib
- 摘要算法
- 摘要的应用
- hmac
- itertools
- contextlib
- \_\_enter\_\_ 和 \_\_exit\_\_
- @contextmanager
- closing
- urllib
- GET
- POST
- Handler
- XML
- DOM
- SAX
- HTMLParser
- 2. 第三方模块
- Pillow
- requests
- chardet
- psutil
- 3. 图形界面模块
- Tkinter
- turtle
1. 内建模块
内建模块,无需安装和配置即可使用;
datetime
处理日期和时间的模块;
# 前一个 datetime 是模块,后一个是类
from datetime import datetime
now()
>>> datetime.now()
datetime.datetime(2020, 11, 22, 10, 42, 2, 59763)
datetime()
>>> dt = datetime(2020, 11, 22, 10, 30)
>>> dt
datetime.datetime(2020, 11, 22, 10, 30)
timestamp
1970 年 1 月 1 日 00:00:00 UTC+00:00 时区的时刻为epoch time(新纪元时间),当前时间是相对于epoch time的秒数,称为timestamp;
timestamp的值与时区无关;
>>> dt = datetime(2020, 11, 22, 10, 30)
# datetime 转 timestamp
>>> t = dt.timestamp()
# timestamp 转 datetime 本地时间
>>> dt = datetime.fromtimestamp(t)
# timestamp 转 datetime utc 时间
>>> dt_utc = datetime.utcfromtimestamp(t)
strptime()
str转datetime 时间格式;
>>> cday = datetime.strptime('2020-11-22 10:20:20', '%Y-%m-%d %H:%M:%S')
strftime()
datetime 转 str;
>>> datetime.now().strftime('%a,%b %d %H:%M')
'Sun,Nov 22 11:38'
timedelta
>>> from datetime import timedelta
# 减 2天 2 小时
>>> datetime.now() - timedelta(days=2, hours=2)
datetime.datetime(2020, 11, 20, 9, 41, 8, 544137)
timezone
通过 timedelta 创建 timezone;
>>> from datetime import timezone
# 创建时区 UTC+8:00
>>> tz_utc_8 = timezone(timedelta(hours=8))
>>> dt = datetime.now()
# 强制设置时区 为 UTC+8
>>> dt = dt.replace(tzinfo=tz_utc_8)
datetime.datetime(2020, 11, 22, 12, 4, 41, 559771, tzinfo=datetime.timezone(datetime.timedelta(seconds=28800)))
时区转换
utcnow() 可以获得当前 UTC 时间,给 UTC 时间设置好时区后,利用 astimezone() 可以转换任意时区的时间;
>>> utc_now = datetime.utcnow().replace(tzinfo=timezone.utc)
>>> utc_8_now = utc_now.astimezone(timezone(timedelta(hours=8)))
>>> utc_9_now = utc_8_now.astimezone(timezone(timedelta(hours=9)))
不是必须从 UTC+0:00 时区转换到其他时区,任何带有时区的时间都可以正确的转换;
collections
内建模块集合;
namedtuple()
namedtuple() 可以用来创建一个 tuple 对象,并规定 tuple 元素的个数,从而使用属性而不是索引的方式应用元素;
>>> rom collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p[0]
1
Point 对象是 tuple 对象的子类;
deque
实现来高效插入和删除(相对 list,list 是线性存储)的双向列表;
>>> from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
append 和 pop 操作列表的末尾;
appendleft 和 popleft 操作列表的开头;
defaultdict
含默认值的dict,与dict的使用相同;
>>> from collections import defaultdict
# 默认值使用函数设置
>>> dd = defaultdict(lambda :'N/A')
>>> dd['key']
'N/A'
OrderedDict
以Key插入的顺序排序的dict;
>>> OrderedDict(a=1, b=2, c=3)
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
FIFO
from collections import OrderedDictclass LastUpdatedOrderedDict(OrderedDict):def __init__(self, capacity):super(LastUpdatedOrderedDict, self).__init__()self._capacity = capacitydef __setitem__(self, key, value):containKey = 1 if key in self else 0print(len(self))if len(self) - containKey >= self._capacity:last = self.popitem(last=False)print('remove:', last)if containKey:del self[key]print('set:', (key, value))else:print('add:', (key, value))OrderedDict.__setitem__(self, key, value)
ChainMap
将多个dict对象串起来,在查找的时候,实际按照内部dict顺序一次查找;
from argparse import Namespace
from collections import ChainMap
import os, argparsedefauts = {'user': 'guest', 'color': 'red'}parser = argparse.ArgumentParser()
parser.add_argument('-u', '--user')
parser.add_argument('-c', '--color')
namespace = parser.parse_args()
command_line_args = {k: v for k, v in vars(namespace).items() if v}
# 查找时,现在 command_line_args 中查找,如果没有,再在 os.environ 查找,最后时 defaults
combined_args = ChainMap(command_line_args, os.environ, defauts)print('color=%s' % combined_args['color'])
print('user=%s' % combined_args['user'])
Counter
计数器,实际也是一个dict子类;
from collections import Counter
c = Counter# 手动统计
for ch in 'programing':c[ch]=c[ch]+1# 自动添加
c.update('hello')
base64
Base64是一种任意二进制到文本字符串的编码方法,常用于小段URL,Cookie,数字签名等;
对二进制数据,每 3 字节一组,按没 6 bit 分为 4 组,从 64 个预设好的字符找到对应编码,不足 3 字节的末尾加一个或两个\x00,再在编码后的末尾加上 1 或 2 个=标记,解码时自动去掉;
>>> import base64
>>> base64.b64encode(b'binary\x00string')
b'YmluYXJ5AHN0cmluZw=='
>>> base64.b64decode(b'YmluYXJ5AHN0cmluZw==')
b'binary\x00string'
# 对比 urlsafe,将 + 和 / 分别变成 - 和 _
>>> base64.b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd++//'
>>> base64.urlsafe_b64encode(b'i\xb7\x1d\xfb\xef\xff')
b'abcd--__'
>>> base64.urlsafe_b64decode(b'abcd--__')
b'i\xb7\x1d\xfb\xef\xff'
url中=也需要去掉;
struct
用来处理bytes与其他二进制数据的转换;
>>> n = 10240099
>>> b1 = (n & 0xff000000) >> 24
>>> b2 = (n & 0xff0000) >> 16
>>> b3 = (n & 0xff00) >> 8
>>> b1 = (n & 0xff)
>>> bs = bytes([b1, b2, b3, b4])
>>> bs
b'\x00\x9c@c'
>>> import struct
>>> struct.pack('>I', 10240099)
b'\x00\x9c@c'
>>> struct.unpack('>I', b'\x00\x9c@c')
10240099
-
>,表示字节顺序是 big-endian,即网络序,I表示 4 字节无符号整数; -
struct模块定义的数据类型
hashlib
摘要算法
又叫哈希算法,散列算法,通过一个函数,把任意长度的数据转换成一个长度固定的数据串(通常是 16 进制字符串);
>>> import hashlib
>>> md5 = hashlib.md5()
# 可分多次调用 update
>>> md5.update('how to use md5 in '.encode('utf-8'))
>>> md5.update('python hashlib?'.encode('utf-8'))
# 提取 16 进制摘要
>>> print(md5.hexdigest())
d26a53750bc40b38b65a520292f69306
sha1、sha256、sha512的调用方式与md5完全一致,它们更加安全,但更慢,所得摘要更长;
碰撞
两个不同的数据通过某个摘要算法得到了相同的摘要,叫做碰撞,这是有可能的(因为任何摘要算法都是把无限的数据集合映射到有限的集合中);
摘要的应用
用于生成密文的口令存储于数据库;
经过混入salt和唯一且不可修改的ID,再求哈希值,这样存储会更安全;
摘要算法不是用来加密的,因为无法反推明文,只是用于防篡改的;
hmac
Keyed-Hashing for Message Authentication;
通过标准的算法,把key混入计算过程;
>>> import hmac
>>> message = b'hello world'
>>> key = b'secret'
>>> h = hmac.new(key, message, digestmod='MD5')
# 如果 message 很长,可以分多次调用 h.update(msg)
>>> h.hexdigest()
'78d6997b1230f38e59b6d1642dfaa3a4'
itertools
用于操作迭代对象的函数;
count(n)
创建一个无限迭代器,起始于n,每次加 1;
import itertools
# 自然数
natuals = itertools.count(1)
cycle(list)
创建一个无限迭代器,无限重复传入的序列;
# 无限重复'A','B','C'
cs = itertools.cycle('ABC')
repeat(item)
创建一个无限迭代器,无限重复传入的一个元素,第二个参数可以限定重复的次数;
ns = itertools.repeat(123, 3)
takewhile()
传入一个筛选函数,用来截取子序列;
与filter不同,当函数条件第一次不满足后,不再继续迭代;
调用所得是一个 itertools.takewhile 迭代对象;
>>> ns = itertools.takewhile(lambda x: x<=10, natuals)
>>> list(ns)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
chain()
将一组迭代对象串联起来;
cn = itertools.chain('ABC', 'XYZ')
groupby()
把相邻的重复元素调出分到一组,group是itertools._grouper迭代对象;
>>> for key, group in itertools.groupby('aaabbbccaaa', lambda c: c.upper()):
... print(key, list(group))
...
A ['a', 'a', 'a']
B ['b', 'b', 'b']
C ['c', 'c']
A ['a', 'a', 'a']
可以传入一个函数座位第二参数,元素通过函数处理后再作用于groupby;
圆周率
def pi(N):' 计算pi的值 '# step 1: 创建一个奇数序列: 1, 3, 5, 7, 9, ...natuals = itertools.count(1)odd = filter(lambda x: x % 2 > 0, natuals)# step 2: 取该序列的前N项: 1, 3, 5, 7, 9, ..., 2*N-1.odd = itertools.takewhile(lambda x: (x + 1) // 2 <= N, odd)# step 3: 添加正负符号并用4除: 4/1, -4/3, 4/5, -4/7, 4/9, ...items = map(lambda x: (4 / (x if (((x + 1) // 2) % 2 > 0) else (0 - x))),odd)# step 4: 求和:return sum(items)
contextlib
只要实现了上下文管理,任何对象都可以使用with语句;
__enter__ 和 __exit__
class Query(object):def __init__(self, name):self.name = namedef __enter__(self):print('begin')return selfdef __exit__(self, exc_type, exc_value, traceback):if exc_type:print('Error')else:print('End')def query(self):print('query info about %s...' % self.name)with Query('bob') as q:q.query()
使用with语句时,自动调用 __enter__ 和 __exit__;
@contextmanager
class Query2(object):def __init__(self, name):self.name = namedef query(self):print('query info about %s...' % self.name)@contextmanager
def create_query(name):print('begin')q = Query2(name)yield qprint('end')with create_query('bob') as q:q.query()
with语句会先执行yield之前的语句,yield调用会执行with语句内部的语句,最后执行yield之后的语句;
closing
closing是一个经过@contextmanager装饰的generator;
@contextmanager
def closing(thing):try:yield thingfinally:thing.close()
针对 Python 中读写资源使用完一定要正确关闭的问题,更简单的方式是使用 closing;
from contextlib import closing
from urllib.request import urlopen
# closing 将 没有实现上下文管理的对象变为上下文对象
with closing(urlopen('https://www.python.org')) as page:for line in page:print(line)
urllib
用于操作URL;
GET
from urllib import requestreq = request.Request('http://dict.youdao.com/w/odd/#keyfrom=dict2.top')
# 模拟 iphone OS 8.0 发起请求
req.add_header('User-Agent','Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25'
)
with request.urlopen(req) as f:data = f.read()print('status:', f.status, f.reason)for k, v in f.getheaders():print(f'{k}: {v}')print('data:'.data.decode('utf-8'))
POST
email = 'aaa.foxmail.com'
pwd = 'xxxxxx'
login_data = parse.urlencode([('username', email), ('password', pwd), ('entry', 'mweibo'),('client_id', ''), ('savestate', '1'), ('ec', ''),('pagerefer','https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])req = request.Request('https://passport.weibo.cn/sso/login')
# Origin 说明请求从哪里发起的,包括,且仅仅包括协议和域名
req.add_header('Origin', 'https://passport.weibo.cn')
# User-Agent 表示 HTTP 客户端程序的信息
req.add_header('User-Agent','Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25'
)
# Referer 表示 请求中 URI 的原始获取方
req.add_header('Referer','https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F'
)# data 参数以 bytes 传入
with request.urlopen(req, data=login_data.encode('utf-8')) as f:print('Status:', f.status, f.reason)for k, v in f.getheaders():print('%s: %s' % (k, v))print('Data:', f.read().decode('utf-8'))
Handler
通过代理访问;
proxy_handler = urllib.request.ProxyHandler({'http': 'http://www.example.com:3128/'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', 'host', 'username', 'password')
opener = urllib.request.build_opener(proxy_handler, proxy_auth_handler)
with opener.open('http://www.example.com/login.html') as f:pass
XML
DOM
把整个XML读入内存,解析为树,占内存大,解析慢;
SAX
流模式,占内存小,解析块,需要自己处理事务;
from xml.parsers.expat import ParserCreateclass DefaultSaxHandler(object):def start_element(self, name, attrs):print('sax:start_element: %s, attrs: %s' % (name, str(attrs)))def end_element(self, name):print('sax:end_element: %s' % name)def char_data(self, text):print('sax:char_data: %s' % text)xml = r'''<?xml version="1.0"?>
<ol><li><a href="/python">Python</a></li><li><a href="/ruby">Ruby</a></li>
</ol>
'''handler = DefaultSaxHandler()
parser = ParserCreate()
parser.StartElementHandler = handler.start_element
parser.EndElementHandler = handler.end_element
# 可能会被分为多次调用,需要在 EndElementHandler 处合并
parser.CharacterDataHandler = handler.char_data
parser.Parse(xml)
通过 start 找到需要的节点,把节点数据保存起来,在 end 处对数据合并并做处理;
HTMLParser
编写搜索引擎,先爬取目标网页,然后解析页面,获取内容;
HTML是XML的子集,是不严谨的XML;
解析HTML的方式与SAX解析XML类似,自定义继承自HTMLParser的类,实现相关事件的相应;
from html.parser import HTMLParserclass MyHTMLParser(HTMLParser):def handle_starttag(self, tag, attrs):print('<%s>' % tag)def handle_endtag(self, tag):print('</%s>' % tag)def handle_startendtag(self, tag, attrs):print('<%s/>' % tag)def handle_data(self, data):print(data)def handle_comment(self, data):print('<!--', data, '-->')def handle_entityref(self, name):print('&%s;' % name)def handle_charref(self, name):print('&#%s;' % name)parser = MyHTMLParser()
parser.feed('''<html>
<head></head>
<body>
<!-- test html parser --><p>Some <a href=\"#\">html</a> HTML tutorial...<br>END</p>
</body></html>''')
feed()可以分多次调用;
2. 第三方模块
PyPI
the Python Package Index,所有第三方模块都会在此注册;
Pillow
官方文档
$ pip install pillow
操作图片
from PIL import Image, ImageFilter# 打开一个jpg图像文件,注意是当前路径:
im = Image.open('test.jpg')
# 获得图像尺寸:
w, h = im.size
print('Original image size: %sx%s' % (w, h))
# 缩放到50%:
im.thumbnail((w//2, h//2))
print('Resize image to: %sx%s' % (w//2, h//2))
# 把缩放后的图像用jpeg格式保存:
im.save('thumbnail.jpg', 'jpeg')# 应用模糊滤镜:
im2 = im.filter(ImageFilter.BLUR)
im2.save('blur.jpg', 'jpeg')
绘图
from PIL import Image, ImageDraw, ImageFont, ImageFilterimport random# 随机字母:
def rndChar():return chr(random.randint(65, 90))# 随机颜色1:
def rndColor():return (random.randint(64, 255), random.randint(64, 255), random.randint(64, 255))# 随机颜色2:
def rndColor2():return (random.randint(32, 127), random.randint(32, 127), random.randint(32, 127))# 240 x 60:
width = 60 * 4
height = 60
image = Image.new('RGB', (width, height), (255, 255, 255))
# 创建Font对象,可以根据操作系统提供绝对路径
font = ImageFont.truetype('Arial.ttf', 36)
# 创建Draw对象:
draw = ImageDraw.Draw(image)
# 填充每个像素:
for x in range(width):for y in range(height):draw.point((x, y), fill=rndColor())
# 输出文字:
for t in range(4):draw.text((60 * t + 10, 10), rndChar(), font=font, fill=rndColor2())
# 模糊:
image = image.filter(ImageFilter.BLUR)
image.save('code.jpg', 'jpeg')
requests
比urllib方便丰富的网络资源访问模块;
$ pip install requests
import requests
r = requests.get('https://www.douban.com/')
# 返回状态码
r.status_code
# 返回内容
r.text
# 带参请求,传一个 dict 给 params
r = requests.get('https://www.douban.com/search', params={'q': 'python', 'cat': '1001'})
# 获取编码
r.encoding
# 获取 bytes 对象的响应内容
r.content
# 直接获取 JSON 类型的响应内容
r.json()
# 需要传入 HTTP Header 时,传入一个 dict 给 headers
r = requests.get('https://www.douban.com/', headers={'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit'})
# POST 请求只需将 get 变为 post,data 参数以 dict 传入
r = requests.post('https://accounts.douban.com/login', data={'form_email': 'abc@example.com', 'form_password': '123456'})
# 默认使用 application/x-www-form-urlencoded 对 POST 数据编码,如需传递 JSON 数据,可直接使用 json 传入
r = requests.post(url, json={'key': 'value'})# 上传文件
upload_files = {'file': open('report.xls', 'rb')}
r = requests.post(url, files=upload_files)# 响应头
r.headers
# 获取指定 cookie
r.cookies['ts']# 以 dict 传入 cookies
r = requests.get(url, cookies={'token':'xxxxxx', 'status': 'working'})# 2.5秒后超时
r = requests.get(url, timeout=2.5)
chardet
对未知编码的 bytes 进行编码猜测(通过特征字符的判断);
pip install chardet
>>> chardet.detect(b'Hello world')
{'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
psutil
process and system utilities,跨平台系统监控模块;
pip install psutil
CPU
import psutil
# CPU逻辑数量
psutil.cpu_count()
# CPU物理核心
psutil.cpu_count(logical=False)
# CPU的用户/系统/空闲时间
psutil.cpu_times()
# CPU 使用率
psutil.cpu_percent(interval=1, percpu=True)
Memory
# 物理内存信息
psutil.virtual_memory()
# 交换区信息
psutil.swap_memory()
Disk
# 磁盘分区信息
psutil.disk_partitions()
# 磁盘使用情况
psutil.disk_usage('/')
# 磁盘 IO
psutil.disk_io_counters()
Network
# 获取网络读写字节/包的个数
psutil.net_io_counters()
# 获取网络接口信息
psutil.net_if_addrs()
# 获取网络接口状态
psutil.net_if_stats()
网络连接信息
psutil.net_connections()
process
# 所有进程ID
psutil.pids()
# 获取指定进程ID=3776,其实就是当前Python交互环境
p = psutil.Process(3776)
# 进程名称
p.name()
# 进程exe路径
p.exe()
# 进程工作目录
p.cwd()
# 进程启动的命令行
p.cmdline()
# 父进程ID
p.ppid()
# 父进程
p.parent()
# 子进程列表
p.children()
# 进程状态
p.status()
# 进程用户名
p.username()
# 进程创建时间
p.create_time()
# 进程终端
p.terminal()
# 进程使用的CPU时间
p.cpu_times()
# 进程使用的内存
p.memory_info()
# 进程打开的文件
p.open_files()
# 进程相关网络连接
p.connections()
# 进程的线程数量
p.num_threads()
# 所有线程信息
p.threads()
# 进程环境变量
p.environ()
# 结束进程
p.terminate()
# 模拟 ps 命令效果,查看当前所有进程状态
psutil.test()
3. 图形界面模块
Tkinter
Tkinter 封装了访问 Tk 的接口,Tk 是一个图形库,使用 Tcl 语言开发,支持多操作系统,Tk 会调用操作系统提供本地 GUI 接口;
复杂的 GUI 用操作系统原生语言或库编写;
from tkinter import *
import tkinter.messagebox as messageboxclass Application(Frame):def __init__(self, master=None):Frame.__init__(self, master)self.pack()self.createWidgets()def createWidgets(self):self.nameInput = Entry(self)# 将 widget 加到父容器self.nameInput.pack()# 点击触发 helloself.alertButton = Button(self, text='Hello', command=self.hello)self.alertButton.pack()def hello(self):name = self.nameInput.get() or 'world'messagebox.showinfo('Message', 'Hello, %s' % name)app = Application()
# 设置窗口标题
app.master.title('Hello World')
# 主消息循环
app.mainloop()
turtle
Turtle graphics,一种流行的玩具编程方式,详见 官方文档;
def draw_star(x, y):pu()goto(x, y)pd()# set heading: 0seth(0)for i in range(5):fd(40)rt(144)for x in range(0, 250, 50):draw_star(x, 0)done()
- 上一篇:「Python 基础」进程与线程
- 专栏:《Python 基础》
PS:感谢每一位志同道合者的阅读,欢迎关注、评论、赞!
相关文章:

「Python 基础」常用模块
文章目录1. 内建模块datetimecollectionsnamedtuple()dequedefaultdictOrderedDictChainMapCounterbase64structhashlib摘要算法摘要的应用hmacitertoolscontextlib\_\_enter\_\_ 和 \_\_exit\_\_contextmanagerclosingurllibGETPOSTHandlerXMLDOMSAXHTMLParser2. 第三方模块Pi…...

Java【二叉搜索树和哈希表】详细图解 / 模拟实现 + 【Map和Set】常用方法介绍
文章目录前言一、二叉搜索树1、什么是二叉搜索树2、模拟实现二叉搜索树2.1, 查找2.2, 插入2.3, 删除3、性能分析二、模型三、哈希表1、什么是哈希表1.1, 什么是哈希冲突1.2, 避免, 解决哈希冲突1.2.1, 避免: 调节负载因子1.2.2, 解决1: 闭散列(了解)1.2.3, 解决2: 开散列/哈希桶…...

如何用 C 语言实现文本特征提取?
文本特征提取是一种将文本转换为数字或向量表示的技术,它是自然语言处理中的重要步骤。以下是一些用 C 语言实现文本特征提取的基本方法:基于词袋模型的特征提取词袋模型是一种将文本表示为单词频率的方法,可以通过以下步骤实现:将…...

ESD静电保护器件分类简介及场景应用
文章目录 1. ESD介绍1.1 ESD简介1.2 ESD产生原理1.3 ESD危害2. 器件级ESD模型2.1 人体模型(HBM)2.2 机器模型(MM)2.3 带电器件模型(CDM)3. 系统级ESD模型3.1 介绍3.2 防护器件分类简介3.2.1 TVS二极管3.2.2 MLCC陶瓷电容3.2.3 ESD抑制管3.2.4 MOV压敏电阻3.2.5 比较4. ES…...

硅谷银行倒闭的几点启示
摘要:本文从公开资料分析一下硅谷银行对信息科技行业的我们有一些什么启示。硅谷银行“拔网线”了,想创业的您,该注意了。1.硅谷银行是谁我们从其官网的说明来看看。The financial partner of the innovation economy.(翻译成中文…...

【AWS入门】IAM基本应用-2023/3/4
目录IAM概述根用户和IAM用户参考IAM概述 IAM(Identity Access Management)是身份和访问管理服务,要访问AWS服务和资源,就要使用IAM进行身份验证和授权。当我们通过控制台,CLI,或API访问AWS服务时,都需要通…...

RabbitMQ系列(1)--RabbitMQ简介
1、RabbitMQ概念RabbitMQ是一个消息中间件,不对消息进行处理,只对消息做接收、存储和转发。2、RabbitMQ四大核心概念(1)生产者产生数据发送信息的程序(2)交换机交换机是RabbitMQ中一个非常重要的部件,接收来着生产者的消息并把消息推送到队列…...
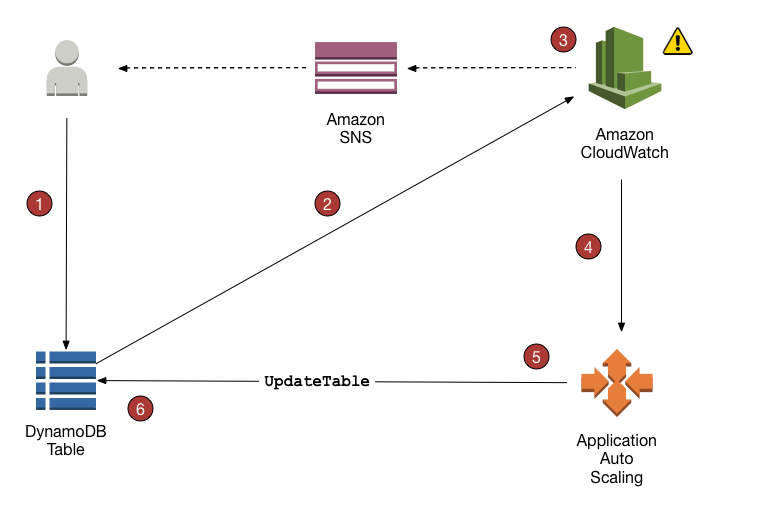
aws dynamodb 使用awsapi和PartiQL掌握dynamodb的CRUD操作
总结一下 dynamodb通常和java等后端sdk结合使用使用的形式可以是api或partiql语法调用dynamodb的用法不难,更重要的是维护成本,所需的服务集成,技术选型等和大数据结合场景下有独特优势 之后可能再看看java sdk中DynamoDBMapper的写法&…...
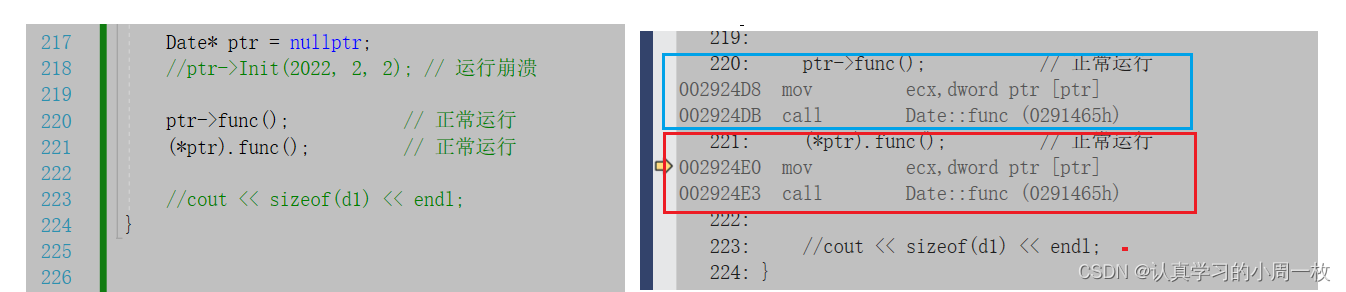
【C++学习】类和对象(上)
前言: 由于之前电脑“嗝屁”了,导致这之前一直没有更新博客,今天才拿到电脑,在这里说声抱歉。接下来就进入今天的学习,在之前我们已经对【C】进行了初步的认识,有了之前的知识铺垫,今天我们将来…...

一文带你深入理解【Java基础】· Java反射机制(下)
写在前面 Hello大家好, 我是【麟-小白】,一位软件工程专业的学生,喜好计算机知识。希望大家能够一起学习进步呀!本人是一名在读大学生,专业水平有限,如发现错误或不足之处,请多多指正࿰…...
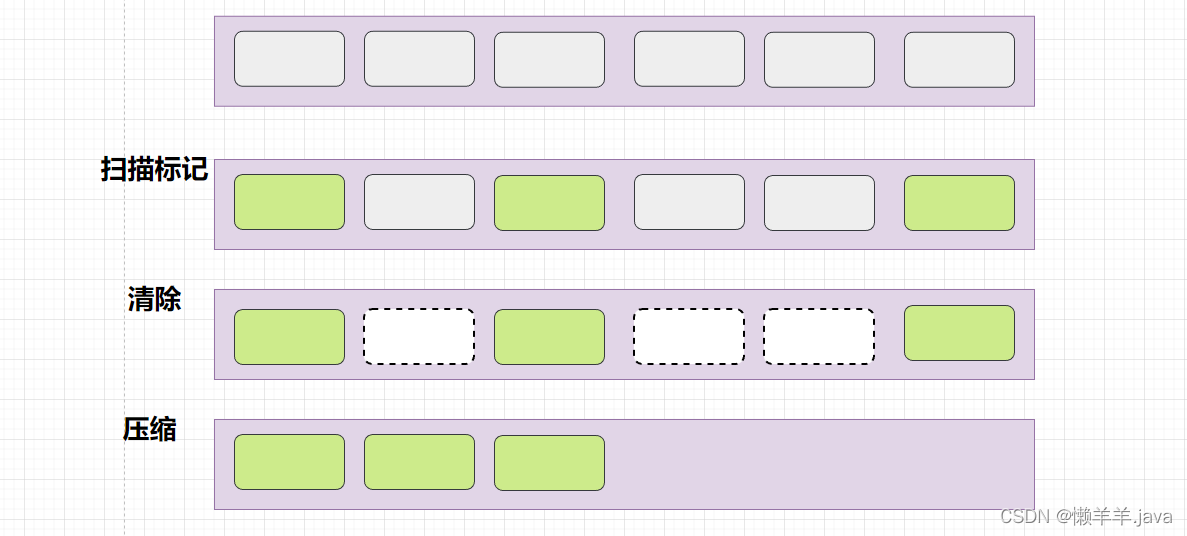
JVM的几种GC
GC JVM在进行GC时,并不是对这三个区域统一回收。大部分时候,回收都是新生代~ 新生代GC(minor GC): 指发生在新生代的垃圾回收动作,因为Java对象大多都具备朝生夕灭的特点,所以minor GC发生得非…...
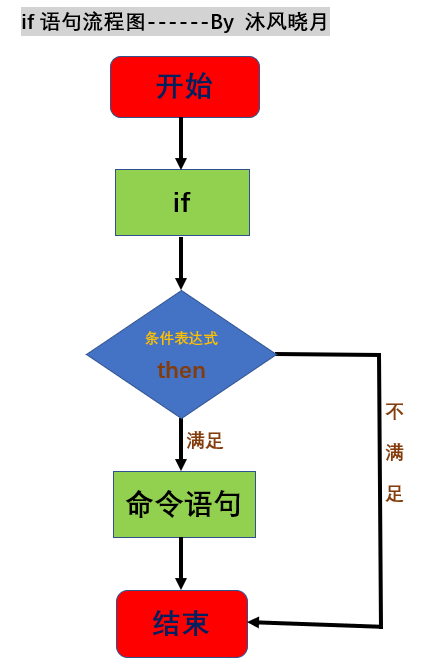
掌握Shell脚本的if语句,让你的代码更加精准和高效
前言 大家好,我是沐风晓月,本文首发于csdn, 作者: 我是沐风晓月。 文章收录于 我是沐风晓月csdn专栏 【系统架构实战】专栏中的【shell脚本入门到精通】专栏。 本专栏从零基础带你层层深入,学会shell脚本,不是梦。 &…...

音质好的蓝牙耳机有哪些?音质最好的蓝牙耳机排行
说起当代人外出必备是数码产品,蓝牙耳机肯定存在。不管是听歌还是追剧,蓝牙耳机在音质上的表现也是越来越好了。下面,我来给大家推荐几款音质好的蓝牙耳机,一起来看看吧。 一、南卡小音舱蓝牙耳机 参考价:259 蓝牙版…...

一次Android App NDK崩溃问题的分析及解决
文章目录小结NDK崩溃的问题通过logcat查看崩溃日志提取tombstone的记录通过ndk-stack来输出日志取得的日志分析并解决分析使用add2line定位具体报错的行数解决参考小结 最近碰一次Android App NDK崩溃的问题,这个NE(Native Exception)是从ND…...
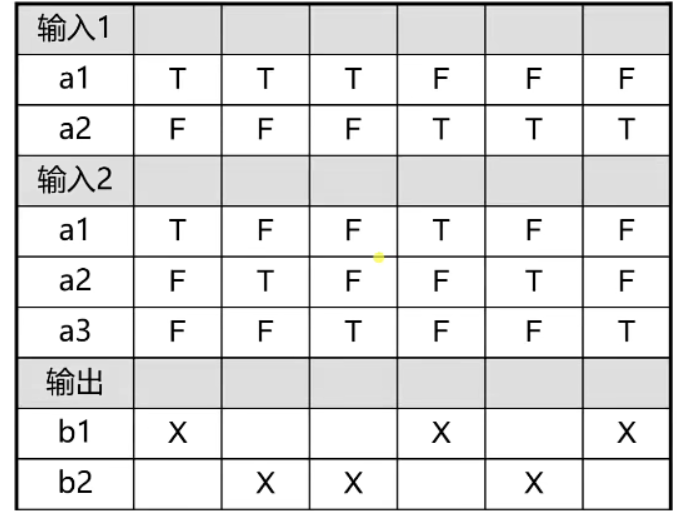
因果图判定表法
因果图&判定表法 在了解了等价类和边界值比较适宜搭档的测试用例方法之后 接下来我们来了解另外一队就是因果图和判定表 因果图会产生判定表法 因果图法 等价类划分法和边界值分析方法都是着重考虑输入条件而不考虑输入条件的各种组合、输入条件之间的相互制约关系。例…...

Oracle 数据库相关信息清单列表
Oracle 数据库相关信息清单列表 一、设置Oracle安装目录 Oracle基目录(ORACLE_BASE):D:\databases\oracle\oracle_11g\app\Administrator 软件位置(ORACLE_HOME):D:\databases\oracle\oracle_11g\app\Administrator\product\11.2.0\dbhome_1 数据库文件位置:D:\databa…...

射频资料搜集--推荐几个网站和链接
https://picture.iczhiku.com/resource/eetop/wHKYFQlDTRRShCcc.pdfhttps://picture.iczhiku.com/resource/eetop/wHKYFQlDTRRShCcc.pdfVCO pulling的资料 模拟滤波器与电路设计手册 - 射频微波仿真 - RF技术社区 Practical RF Amplifier Design Using the Available Gain Pr…...

B1048 数字加密
decription 本题要求实现一种数字加密方法。首先固定一个加密用正整数 A,对任一正整数 B,将其每 1 位数字与 A 的对应位置上的数字进行以下运算:对奇数位,对应位的数字相加后对 13 取余——这里用 J 代表 10、Q 代表 11、K 代表 …...

Qt使用FFmpeg播放视频
一、使用场景 因为项目中需要加载MP4播放开机视频,而我们的设备所使用的架构为arm架构,其中缺乏一些多媒体库。安装这些插件库比较麻烦,所以最终决定使用FFmpeg播放视频。 二、下载编译ffmpeg库 2.1 下载源码 源码下载路径:http…...
Win32 ListBox控件
Win32 ListBox控件 创建ListBox控件 创建窗口函数 HWND CrateWindowEx(DWORD dwExStyle , // 窗口的扩展风格,基本没用LPCTSTR lpClassName, // 已经注册的窗口类名称LPCTSTR lpWindowName, // 窗口标题栏的名字DWORD dwStyle, // 窗口的基本风格int x, // 左上角水平坐标int …...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...