Hadoop版本演变、分布式集群搭建
Hadoop版本演变历史
Hadoop发行版非常的多,有华为发行版、Intel发行版、Cloudera Hadoop(CDH)、Hortonworks Hadoop(HDP),这些发行版都是基于Apache Hadoop衍生出来的。
目前Hadoop经历了三个大的版本。

hadoop1.x:HDFS+MapReduce
hadoop2.x:HDFS+YARN+MapReduce
hadoop3.x:HDFS+YARN+MapReduce

在Hadoop1.x中,分布式计算和资源管理都是MapReduce负责的,从Hadoop2.x开始把资源管理单独拆分出来了,YARN是一个公共的资源管理平台,在它上面不仅仅可以跑MapReduce程序,还可以跑很多其他的程序,例如:Spark、Flink等计算框架都是支持在YARN上面执行的,并且在实际工作中也都是在YARN上面执行,只要程序满足YARN的规则即可。
Hadoop3.x的架构并没有发生什么变化,但是它在其他细节方面做了很多优化,常见的包括:
- 最低Java版本要求从Java7变为Java8;
- 在Hadoop 3中,HDFS支持纠删码,纠删码是一种比副本存储更节省存储空间的数据持久化存储方法,使用这种方法,相同容错的情况下可以比之前节省一半的存储空间
HDFS Erasure Coding - Hadoop 2中的HDFS最多支持两个NameNode,一主一备,而Hadoop 3中的HDFS支持多个NameNode,一主多备;
HDFS High Availability Using - MapReduce任务级本地优化,MapReduce添加了映射输出收集器的本地化实现的支持。对于密集型的洗牌操作(shuffle-intensive)jobs,可以带来30%的性能提升,
Task level native optimization - 修改了多重服务的默认端口,Hadoop2中一些服务的端口和Hadoop3中是不一样的
Hadoop 3和2之间的主要区别在于新版本提供了更好的优化和可用性
参考官网
Hadoop三大核心组件
Hadoop主要包含三大组件:HDFS+MapReduce+YARN
- HDFS负责海量数据的分布式存储
- MapReduce是一个计算模型,负责海量数据的分布式计算
- YARN主要负责集群资源的管理和调度

分布式集群安装
左边这一个是主节点,右边的两个是从节点,hadoop集群是支持主从架构的。

一主两从的hadoop集群,环境准备:三个节点
bigdata01 192.168.182.100
bigdata02 192.168.182.101
bigdata03 192.168.182.102
下载安装包
hadoop官网下载地址
版本hadoop3.2.0

配置基础环境
设置静态ip、hostname、host、firewalld、ssh免密码登录、安装JDK与环境变量、集群节点之间时间同步
设置静态ip
# 主节点 IPADDR=192.168.182.100
# 从节点 IPADDR=192.168.182.101、IPADDR=192.168.182.102
[root@localhost ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="9a0df9ec-a85f-40bd-9362-ebe134b7a100"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.182.100
GATEWAY=192.168.182.2
DNS1=192.168.182.2# 重启网络服务
[root@bigdata01 ~]# service network restart
Restarting network (via systemctl): [ OK ]
[root@bigdata01 ~]# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope host valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000link/ether 00:0c:29:9c:86:11 brd ff:ff:ff:ff:ff:ffinet 192.168.182.100/24 brd 192.168.182.255 scope global noprefixroute ens33valid_lft forever preferred_lft foreverinet6 fe80::c8a8:4edb:db7b:af53/64 scope link noprefixroute valid_lft forever preferred_lft forever设置临时主机名和永久主机名hostname
# 临时主机名
# 主节点 bigdata01
# 从节点 bigdata02、bigdata03
[root@bigdata01 ~]# hostname bigdata01
[root@bigdata01 ~]# vi /etc/hostname
bigdata01配置永久主机名与静态ip映射,在/etc/hosts文件中配置ip和主机名(hostname)的映射关系,把下面内容追加到/etc/hosts中,不能删除/etc/hosts文件中的已有内容!
# 主节点 bigdata01
# 从节点 bigdata02、bigdata03
[root@bigdata01 ~]# vi /etc/hosts
192.168.182.100 bigdata01配置/etc/hosts
因为需要在主节点远程连接两个从节点,所以需要让主节点能够识别从节点的主机名,使用主机名远程访问,默认情况下只能使用ip远程访问,想要使用主机名远程访问的话需要在节点的/etc/hosts文件中配置对应机器的ip和主机名信息。
所以在这里我们就需要在bigdata01的/etc/hosts文件中配置下面信息,最好把当前节点信息也配置到里面,这样这个文件中的内容就通用了,可以直接拷贝到另外两个从节点
# 在bigdata01的/etc/hosts文件中配置ip与hostname映射
[root@bigdata01 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03# 在bigdata02的/etc/hosts文件中配置ip与hostname映射
[root@bigdata02 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03# 在bigdata03的/etc/hosts文件中配置ip与hostname映射
[root@bigdata03 ~]# vi /etc/hosts
192.168.182.100 bigdata01
192.168.182.101 bigdata02
192.168.182.102 bigdata03关闭防火墙
# 临时关闭防火墙
[root@bigdata01 ~]# systemctl stop firewalld
# 永久关闭防火墙
[root@bigdata01 ~]# systemctl disable firewalld[root@bigdata02 ~]# systemctl disable firewalld[root@bigdata03 ~]# systemctl disable firewalldssh免密码登录
ssh 是secure shell,安全的shell,通过ssh可以远程登录到远程linux机器。
不管是几台机器的集群,启动集群中程序的步骤都是一样的,都是通过ssh远程连接去操作,就算是一台机器,它也会使用ssh自己连自己。
在启动集群的时候只需要在一台机器上启动就行,然后hadoop会通过ssh连到其它机器,把其它机器上面对应的程序也启动起来,使用ssh连接其它机器的时候会发现需要输入密码,所以现在需要实现ssh免密码登录。
# ssh连接主节点
[root@bigdata01 ~]# ssh bigdata01
The authenticity of host 'bigdata01 (fe80::c8a8:4edb:db7b:af53%ens33)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes【第一次使用这个主机名需要输入yes】
Warning: Permanently added 'bigdata01,fe80::c8a8:4edb:db7b:af53%ens33' (ECDSA) to the list of known hosts.
root@bigdata01's password: 【这里需要输入密码】ssh登录原理
ssh这种安全/加密的shell,使用的是非对称加密.
加密有两种,对称加密和非对称加密。
非对称加密的解密过程是不可逆的,比较安全。非对称加密会产生秘钥,秘钥分为公钥和私钥,在这里公钥是对外公开的,私钥是自己持有的。
ssh通信过程:
1、第一台机器会把自己的公钥给到第二台机器;
2、当第一台机器要给第二台机器通信时,第一台机器会给第二台机器发送一个随机的字符串;
3、第二台机器会使用公钥对这个字符串加密,同时第一台机器会使用自己的私钥也对这个字符串进行加密,然后也传给第二台机器;
4、这时第二台机器就有了两份加密的内容,一份是自己使用公钥加密的,一份是第一台机器使用私钥加密传过来的;
5、公钥和私钥是通过一定的算法计算出来的,这时第二台机器就会对比这两份加密之后的内容是否匹配。如果匹配,第二台机器就会认为第一台机器是可信的,就允许登录。如果不相等 就认为是非法的机器。

RSA(Rivest-Shamir-Adleman)是一种非对称加密算法,公钥和私钥成对生成并可以用于加密和解密。工作原理:
- 密钥生成:用户选择两个大素数p和q,并计算它们的乘积n=pq,这将是公钥的一部分。然后,计算欧拉函数φ(n)=(p-1)(q-1),选取一个与φ(n)互质的整数e(通常为一个小于φ(n)且大于1的整数),公钥包含n和e。私钥则包含n和d(满足d*e ≡ 1 mod φ(n)),这样任何知道d的人都可以解密。
- 加密:使用接收者的公钥(n和e)进行加密。消息被转换为数字m,通过取模运算(m^e) mod n得到密文c。
- 解密:只有拥有私钥的人才能解密,使用私钥中的d,通过计算(c^d) mod n得到原始消息m。
# 使用rsa对ssh加密
# 执行这个命令以后,需要连续按 4 次回车键回到 linux 命令行才表示这个操作执行结束,在按回车的时候不需要输入任何内容。[root@bigdata01 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:I8J8RDun4bklmx9T45SRsKAu7FvP2HqtriYUqUqF1q4 root@bigdata01
The key's randomart image is:
+---[RSA 2048]----+
| o . |
| o o o . |
| o.. = o o |
| +o* o * o |
|..=.= B S = |
|.o.o o B = . |
|o.o . +.o . |
|.E.o.=...o |
| .o+=*.. |
+----[SHA256]-----+# 执行以后会在~/.ssh目录下生产对应的公钥和私钥文件[root@bigdata01 ~]# ll ~/.ssh/
total 12
-rw-------. 1 root root 1679 Apr 7 16:39 id_rsa
-rw-r--r--. 1 root root 396 Apr 7 16:39 id_rsa.pub# 在bigdata01上执行
[root@bigdata01 ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 在主节点 bigdata01机器上执行下面命令,将公钥信息拷贝到从节点bigdata02
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata02:~/
The authenticity of host 'bigdata02 (192.168.182.101)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'bigdata02,192.168.182.101' (ECDSA) to the list of known hosts.
root@bigdata02's password:
authorized_keys 100% 396 506.3KB/s 00:00 # # 在主节点 bigdata01机器上执行下面命令,将公钥信息拷贝到从节点bigdata03
[root@bigdata01 ~]# scp ~/.ssh/authorized_keys bigdata03:~/
The authenticity of host 'bigdata03 (192.168.182.102)' can't be established.
ECDSA key fingerprint is SHA256:uUG2QrWRlzXcwfv6GUot9DVs9c+iFugZ7FhR89m2S00.
ECDSA key fingerprint is MD5:82:9d:01:51:06:a7:14:24:a9:16:3d:a1:5e:6d:0d:16.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'bigdata03,192.168.182.102' (ECDSA) to the list of known hosts.
root@bigdata03's password:
authorized_keys 100% 396 606.1KB/s 00:00# 在bigdata02上执行
[root@bigdata02 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys# 在bigdata03上执行
[root@bigdata03 ~]# cat ~/authorized_keys >> ~/.ssh/authorized_keys
# 验证bigdata01免密登陆bigdata02
[root@bigdata01 ~]# ssh bigdata02
Last login: Tue Apr 7 21:33:58 2020 from bigdata01
[root@bigdata02 ~]# exit
logout
Connection to bigdata02 closed.# # 验证bigdata01免密登陆bigdata03
[root@bigdata01 ~]# ssh bigdata03
Last login: Tue Apr 7 21:17:30 2020 from 192.168.182.1
[root@bigdata03 ~]# exit
logout
Connection to bigdata03 closed.
[root@bigdata01 ~]# 没必要实现从节点之间互相免密登录,因为在启动集群的时候只有主节点需要远程连接其它节点。
安装jdk及环境变量
# 解压jdk安装包
[root@bigdata01 ~]# cd /data/soft
[root@bigdata01 soft]# tar -zxvf jdk-8u202-linux-x64.tar.gz# 重命名为jdk1.8
[root@bigdata01 soft]# mv jdk1.8.0_202 jdk1.8# 配置环境变量 JAVA_HOME
[root@bigdata01 soft]# vi /etc/profile
.....
export JAVA_HOME=/data/soft/jdk1.8
export PATH=.:$JAVA_HOME/bin:$PATH# 验证
[root@bigdata01 soft]# source /etc/profile
[root@bigdata01 soft]# java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
集群节点之间时间同步
集群只要涉及到多个节点的就需要对这些节点做时间同步,如果节点之间时间不同步相差太多,会应该集群的稳定性,甚至导致集群出问题。
使用ntpdate -u ntp.sjtu.edu.cn实现时间同步
# 默认是没有ntpdate命令的,需要使用yum在线安装
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn
-bash: ntpdate: command not found# 安装ntpdate
[root@bigdata01 ~]# yum install -y ntpdate
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile* base: mirrors.cn99.com* extras: mirrors.cn99.com* updates: mirrors.cn99.com
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
Resolving Dependencies
--> Running transaction check
---> Package ntpdate.x86_64 0:4.2.6p5-29.el7.centos will be installed
--> Finished Dependency ResolutionDependencies Resolved===============================================================================Package Arch Version Repository Size
===============================================================================
Installing:ntpdate x86_64 4.2.6p5-29.el7.centos base 86 kTransaction Summary
===============================================================================
Install 1 PackageTotal download size: 86 k
Installed size: 121 k
Downloading packages:
ntpdate-4.2.6p5-29.el7.centos.x86_64.rpm | 86 kB 00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transactionInstalling : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1 Verifying : ntpdate-4.2.6p5-29.el7.centos.x86_64 1/1 Installed:ntpdate.x86_64 0:4.2.6p5-29.el7.centos Complete!# 执行ntpdate -u ntp.sjtu.edu.cn 确认是否可以正常执行
[root@bigdata01 ~]# ntpdate -u ntp.sjtu.edu.cn7 Apr 21:21:01 ntpdate[5447]: step time server 185.255.55.20 offset 6.252298 sec# 建议把这个同步时间的操作添加到linux的crontab定时器中,每分钟执行一次
[root@bigdata01 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn# 在bigdata02和bigdata03节点上配置时间同步
[root@bigdata02 ~]# yum install -y ntpdate
[root@bigdata02 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn[root@bigdata03 ~]# yum install -y ntpdate
[root@bigdata03 ~]# vi /etc/crontab
* * * * * root /usr/sbin/ntpdate -u ntp.sjtu.edu.cn集群中三个节点的基础环境就都配置完毕了,接下来就需要在这三个节点中安装Hadoop了。
安装Hadoop
1、把hadoop-3.2.0.tar.gz安装包上传到/data/soft目录下
# 把hadoop-3.2.0.tar.gz安装包上传到/data/soft
[root@bigdata01 soft]# ll
total 527024
-rw-r--r--. 1 root root 345625475 Jul 19 2019 hadoop-3.2.0.tar.gz
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
2、解压hadoop安装包
# 在bigdata01上解压hadoop安装包
[root@bigdata01 soft]# tar -zxvf hadoop-3.2.0.tar.gz
3、修改hadoop相关配置文件
- hadoop-env.sh,在文件末尾增加环境变量信息;
- core-site.xml,fs.defaultFS属性中的主机名需要和主节点的主机名或者静态ip保持一致;
- hdfs-site.xml文件,把hdfs中文件副本的数量设置为2,因为现在集群中有两个从节点,dfs.namenode.secondary.http-address设置为secondaryNamenode进程所在的节点信息;
- mapred-site.xml,设置mapreduce使用的资源调度框架yarn;
- yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单,还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点
- workers文件,增加所有从节点的主机名,一个一行
- start-dfs.sh,stop-dfs.sh,添加hdfs的datanode、namenode用户
HDFS_DATANODE_USER、HDFS_DATANODE_SECURE_USER、HDFS_NAMENODE_USER、HDFS_NAMENODE_USER、HDFS_SECONDARYNAMENODE_USER; - start-yarn.sh,stop-yarn.sh,添加yarn的resourcemaneger、nodemanger用户
YARN_RESOURCEMANAGER_USER、HADOOP_SECURE_DN_USER、YARN_NODEMANAGER_USER;
# 修改hadoop相关配置文件
[root@bigdata01 soft]# cd hadoop-3.2.0/etc/hadoop/# 首先修改hadoop-env.sh文件,在文件末尾增加环境变量信息
[root@bigdata01 hadoop]# vi hadoop-env.sh
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop# 修改core-site.xml文件
# 注意fs.defaultFS属性中的主机名需要和主节点的主机名或者静态ip保持一致
[root@bigdata01 hadoop]# vi core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://bigdata01:9000</value></property><property><name>hadoop.tmp.dir</name><value>/data/hadoop_repo</value></property>
</configuration># 修改hdfs-site.xml文件
# 把hdfs中文件副本的数量设置为2,最多为2,因为现在集群中有两个从节点
# secondaryNamenode进程所在的节点信息
[root@bigdata01 hadoop]# vi hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.secondary.http-address</name><value>bigdata01:50090</value></property>
</configuration># 修改mapred-site.xml
# 设置mapreduce使用的资源调度框架
[root@bigdata01 hadoop]# vi mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration># 修改yarn-site.xml,设置yarn上支持运行的服务和环境变量白名单
# 注意,针对分布式集群在这个配置文件中还需要设置resourcemanager的hostname,否则nodemanager找不到resourcemanager节点。
[root@bigdata01 hadoop]# vi yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><property><name>yarn.resourcemanager.hostname</name><value>bigdata01</value></property>
</configuration># 修改workers文件
# 增加所有从节点的主机名,一个一行
[root@bigdata01 hadoop]# vi workers
bigdata02
bigdata03# 修改启动脚本# 修改start-dfs.sh,stop-dfs.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 hadoop]# cd /data/soft/hadoop-3.2.0/sbin
[root@bigdata01 sbin]# vi start-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root[root@bigdata01 sbin]# vi stop-dfs.sh
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root# 修改start-yarn.sh,stop-yarn.sh这两个脚本文件,在文件前面增加如下内容
[root@bigdata01 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root[root@bigdata01 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root4、把bigdata01节点上将修改好配置的安装包拷贝到其他两个从节点
[root@bigdata01 sbin]# cd /data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata02:/data/soft/
[root@bigdata01 soft]# scp -rq hadoop-3.2.0 bigdata03:/data/soft/
5、格式化HDFS
# 在bigdata01节点上格式化HDFS
[root@bigdata01 soft]# cd /data/soft/hadoop-3.2.0
[root@bigdata01 hadoop-3.2.0]# bin/hdfs namenode -format
# 如果在后面的日志信息中能看到这一行,则说明namenode格式化成功。
common.Storage: Storage directory /data/hadoop_repo/dfs/name has been successfully formatted.
6、启动集群
# 在主节点 bigdata01上执行下面命令
[root@bigdata01 hadoop-3.2.0]# sbin/start-all.sh
Starting namenodes on [bigdata01]
Last login: Tue Apr 7 21:03:21 CST 2020 from 192.168.182.1 on pts/2
Starting datanodes
Last login: Tue Apr 7 22:15:51 CST 2020 on pts/1
bigdata02: WARNING: /data/hadoop_repo/logs/hadoop does not exist. Creating.
bigdata03: WARNING: /data/hadoop_repo/logs/hadoop does not exist. Creating.
Starting secondary namenodes [bigdata01]
Last login: Tue Apr 7 22:15:53 CST 2020 on pts/1
Starting resourcemanager
Last login: Tue Apr 7 22:15:58 CST 2020 on pts/1
Starting nodemanagers
Last login: Tue Apr 7 22:16:04 CST 2020 on pts/1# 验证
# 在bigdata01上查看java进程,是否存在NameNode、ResourceManager、SecondaryNameNode
[root@bigdata01 hadoop-3.2.0]# jps
6128 NameNode
6621 ResourceManager
6382 SecondaryNameNode# 在bigdata02上查看java进程,是否存在NodeManager、DataNode
[root@bigdata02 ~]# jps
2385 NodeManager
2276 DataNode
# 在bigdata03上查看java进程,是否存在NodeManager、DataNode
[root@bigdata03 ~]# jps
2326 NodeManager
2217 DataNode# 停止集群
# 在主节点bigdata01上执行停止命令
[root@bigdata01 hadoop-3.2.0]# sbin/stop-all.sh
Stopping namenodes on [bigdata01]
Last login: Tue Apr 7 22:21:16 CST 2020 on pts/1
Stopping datanodes
Last login: Tue Apr 7 22:22:42 CST 2020 on pts/1
Stopping secondary namenodes [bigdata01]
Last login: Tue Apr 7 22:22:44 CST 2020 on pts/1
Stopping nodemanagers
Last login: Tue Apr 7 22:22:46 CST 2020 on pts/1
Stopping resourcemanager
Last login: Tue Apr 7 22:22:50 CST 2020 on pts/1具体安装详情说明可查阅Hadoop官网
Hadoop的客户端节点
在实际工作中不建议直接连接集群中的节点来操作集群,直接把集群中的节点暴露给普通开发人员是不安全的,建议在业务机器上安装Hadoop,只需要保证业务机器上的Hadoop的配置和集群中的配置保持一致即可,这样就可以在业务机器上操作Hadoop集群了,此机器就称为是Hadoop的客户端节点,Hadoop的客户端节点可能会有多个,理论上是我们想要在哪台机器上操作hadoop集群就可以把这台机器配置为hadoop集群的客户端节点。

相关文章:
Hadoop版本演变、分布式集群搭建
Hadoop版本演变历史 Hadoop发行版非常的多,有华为发行版、Intel发行版、Cloudera Hadoop(CDH)、Hortonworks Hadoop(HDP),这些发行版都是基于Apache Hadoop衍生出来的。 目前Hadoop经历了三个大的版本。 hadoop1.x:HDFSMapReduce hadoop2.x…...

【Qt C++实现绘制仪表盘】
要在Qt C中绘制仪表盘,您可以使用QChart、QSeries、QBarSeries、QPointSeries等类。以下是一个简单的示例,演示如何使用这些类创建一个绘图仪表盘: #include <QApplication> #include <QChart> #include <QChartView> #in…...

一文看懂LLaMA 2:大型多模态模型的新里程碑
一文看懂LLaMA 2:大型多模态模型的新里程碑 LLaMA 2是OpenAI继GPT-3之后推出的又一重磅模型,它不仅在文本生成方面有所突破,而且在图像处理和语音识别等领域也展现出了令人印象深刻的能力。本文将全面介绍LLaMA 2的背景、技术细节、应用场景…...

基于Spring Boot构建淘客返利平台
基于Spring Boot构建淘客返利平台 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天我们将讨论如何基于Spring Boot构建一个淘客返利平台。 淘客返利平台通过…...
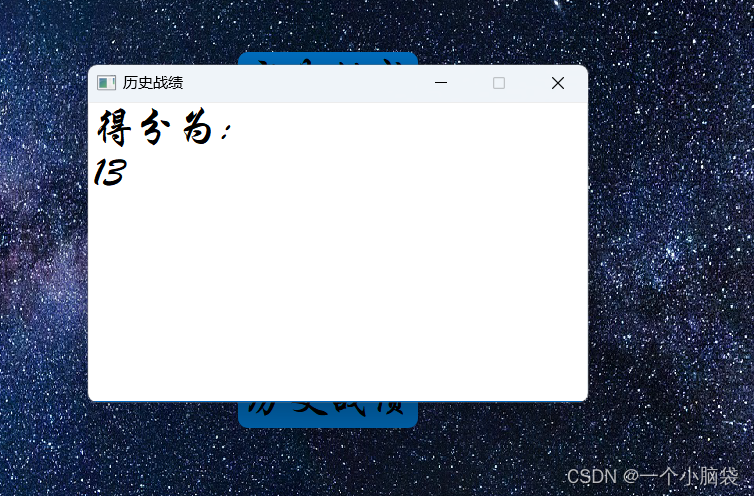
Qt—贪吃蛇项目(由0到1实现贪吃蛇项目)
用Qt实现一个贪吃蛇项目 一、项目介绍二、游戏大厅界面实现2.1完成游戏大厅的背景图。2.2创建一个按钮,给它设置样式,并且可以跳转到别的页面 三、难度选择界面实现四、 游戏界面实现五、在文件中写入历史战绩5.1 从文件里提取分数5.2 把贪吃蛇的长度存入…...

Java导出Excel并邮件发送
一、导出Excel 添加maven依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>3.10-FINAL</version></dependency><dependency><groupId>org.apache.poi</groupI…...
【课程总结】Day12:YOLO的深入了解
前言 在【课程总结】Day11(下):YOLO的入门使用一节中,我们已经了解YOLO的使用方法,使用过程非常简单,训练时只需要三行代码:引入YOLO,构建模型,训练模型;预测…...

保护隐私,释放智能:使用LangChain和Presidio构建安全的AI问答系统
保护隐私,释放智能:使用LangChain和Presidio构建安全的AI问答系统 在人工智能(AI)飞速发展的今天,AI问答系统已经成为企业与客户互动的重要工具。然而,随之而来的个人数据隐私问题也日益凸显。如何在不泄露…...

【高考志愿】自动化
目录 一、专业概述 二、课程设计 三、就业前景与方向 四、志愿填报 五、自动化专业排名 一、专业概述 高考志愿自动化专业选择,无疑是迈向现代化工业与科技发展的一把金钥匙。自动化专业,作为现代工程领域的重要支柱,融合了计算机、电子…...

技巧类题目
目录 技巧类题目 136 只出现一次的数字 191 位1的个数 231. 2 的幂 169 多数元素 75 颜色分类 (双指针) 287. 寻找重复数 136 只出现一次的数字 给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均…...
)
Vue3自定义指令参数修饰符值(3)
自定义指令参数修饰符值 在vue3中我们如何获取自定义的参数的内容,并根据业务来修改展示的内容呢,需要依靠mounted方法中的bindings参数来获取。 参考实例 directives/unit.js文件 export default function directiveUnit(app){app.directive("unit",{…...

HTML(23)——垂直对齐方式
垂直对齐方式 属性名:vertical-align 属性值效果baseline基线对齐(默认)top顶部对齐middle居中对齐bottom底部对齐 默认情况下浏览器对行内块,行内标签都按文字处理,默认基线对齐 导致图片看起来会偏上,文字偏下。 示例&#…...

linux查看二进制文件
在Linux中,查看二进制文件可以使用hexdump或xxd命令。 例如,要查看一个名为example.bin的二进制文件的内容,可以使用以下命令之一: 使用hexdump: bash hexdump -C example.bin使用xxd: bash xxd exam…...

营销翻车,杜国楹出面道歉,小罐茶的“大师作”故事仓皇结尾
“小罐茶,大师作”,这句slogan曾一度在央视平台长时间、高密度播放,成为家喻户晓的广告词,也打响了小罐茶品牌的名号。但同时,市场上关于“大师作”真实性的质疑也从未停息。 就在6月25日小罐茶十二周年发布会上&#…...

linux server下人脸检测与识别服务程序的系统架构设计
一、绪论 1.1 定义 1.2 研究背景及意义 1.3 相关技术综述 二、人脸检测与识别技术概述 2.1 人脸检测原理与算法 2.2 人脸识别技术及方法 2.3 人脸识别过程简介 三、人脸检测与识别服务程序的系统架构 3.1 系统架构设计 3.2 技术实现流程 四、后续设计及经验瞎谈 4.…...
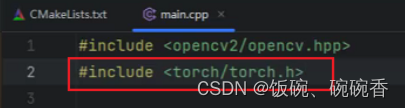
安装CLion配置opencv和torch环境
配置操作如图,源码见底部附录部分 安装CLion 官网下载 创建项目 设置环境 调整类型为release 配置opencv和项目 编译环境 编译后 重启CLion 测试opencv环境 测试代码 运行main.cpp显示图片 测试torch环境 没标红表示配置成功 附件 CMakeList.txt cmake_mi…...

[leetcode]number-of-longest-increasing-subsequence
. - 力扣(LeetCode) class Solution { public:int findNumberOfLIS(vector<int> &nums) {int n nums.size(), maxLen 0, ans 0;vector<int> dp(n), cnt(n);for (int i 0; i < n; i) {dp[i] 1;cnt[i] 1;for (int j 0; j < i…...

[MYSQL] MYSQL库的操作
前言 本文主要介绍MYSQL里 库 的操作 请注意 : 在MYSQL中,命令行是不区分大小写的 1.创建库 create database [if not exists] database_name [charsetutf8 collateutf8_general_ci] ...] create database 是命名语法,不可省略[if not exists] 如果不存在创建,如果存在跳过…...

数字黄金 vs 全球计算机:比特币与以太坊现货 ETF 对比
撰文:Andrew Kang 编译:J1N,Techub News 本文来源香港Web3媒体:Techub News 比特币现货 ETF 的通过为许多新买家打开了进入加密货币市场的大门,让他们可以在投资组合中配置比特币。但以太坊现货 ETF 的通过…...

互联网直播/点播技术与平台创新应用:视频推拉流EasyDSS案例分析
随着互联网技术的快速发展,直播/点播平台已成为信息传播和娱乐的重要载体。特别是在电视购物领域,互联网直播/点播平台与技术的应用,不仅为用户带来了全新的购物体验,也为商家提供了更广阔的营销渠道。传统媒体再一次切实感受到了…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

LeetCode - 394. 字符串解码
题目 394. 字符串解码 - 力扣(LeetCode) 思路 使用两个栈:一个存储重复次数,一个存储字符串 遍历输入字符串: 数字处理:遇到数字时,累积计算重复次数左括号处理:保存当前状态&a…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...
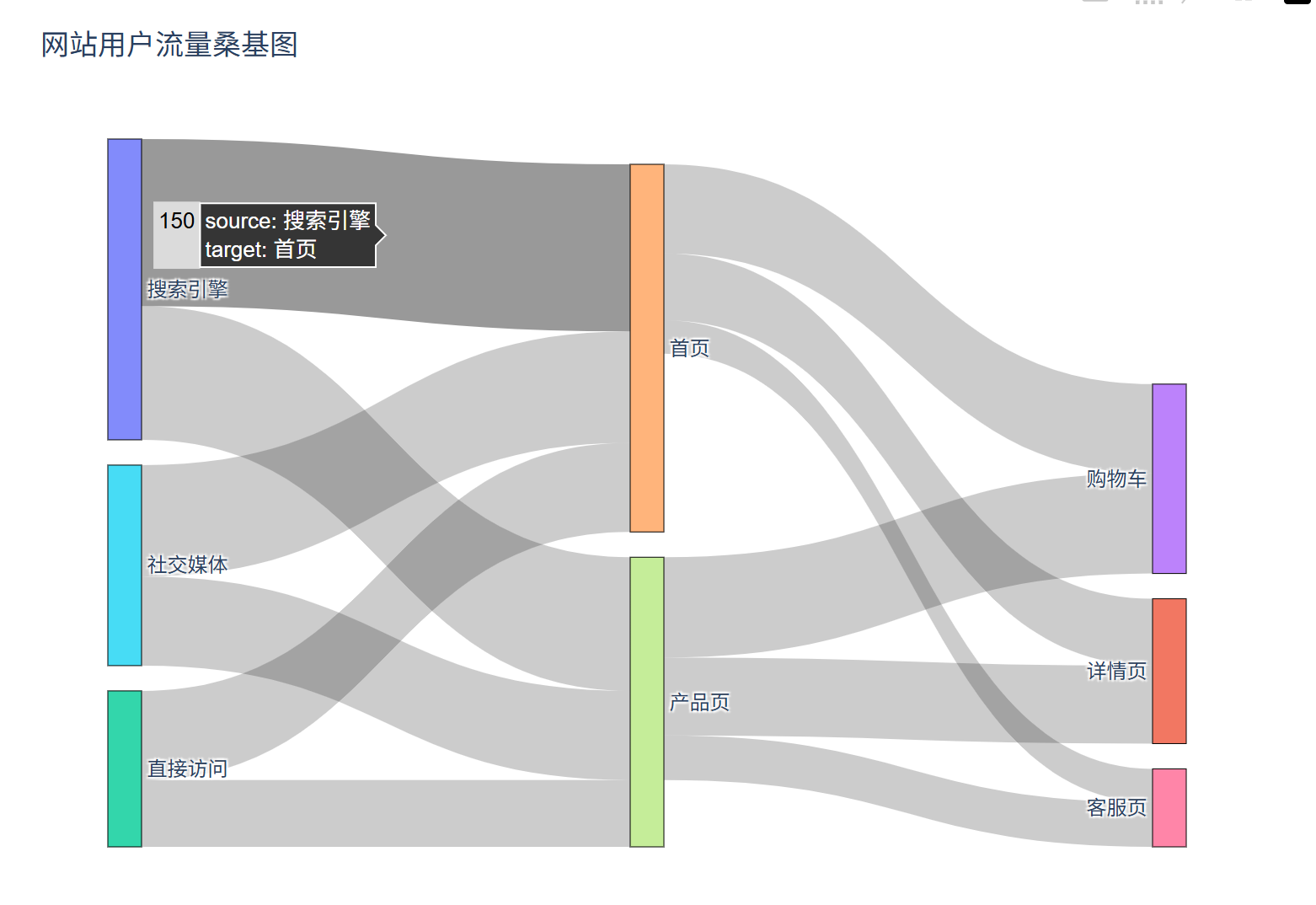
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...

MySQL体系架构解析(三):MySQL目录与启动配置全解析
MySQL中的目录和文件 bin目录 在 MySQL 的安装目录下有一个特别重要的 bin 目录,这个目录下存放着许多可执行文件。与其他系统的可执行文件类似,这些可执行文件都是与服务器和客户端程序相关的。 启动MySQL服务器程序 在 UNIX 系统中,用…...