ExVideo: 提升5倍性能-用于视频合成模型的新型后调谐方法
| 标题:ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning |
|---|
| 作者: Zhongjie Duan; Wenmeng Zhou; Cen Chen; Yaliang Li; Weining Qian |
| DOI: 10.48550/arXiv.2406.14130 |
| 摘要: Recently, advancements in video synthesis have attracted significant attention. Video synthesis models such as AnimateDiff and Stable Video Diffusion have demonstrated the practical applicability of diffusion models in creating dynamic visual content. The emergence of SORA has further spotlighted the potential of video generation technologies. Nonetheless, the extension of video lengths has been constrained by the limitations in computational resources. Most existing video synthesis models can only generate short video clips. In this paper, we propose a novel post-tuning methodology for video synthesis models, called ExVideo. This approach is designed to enhance the capability of current video synthesis models, allowing them to produce content over extended temporal durations while incurring lower training expenditures. In particular, we design extension strategies across common temporal model architectures respectively, including 3D convolution, temporal attention, and positional embedding. To evaluate the efficacy of our proposed post-tuning approach, we conduct extension training on the Stable Video Diffusion model. Our approach augments the model’s capacity to generate up to $5\times$ its original number of frames, requiring only 1.5k GPU hours of training on a dataset comprising 40k videos. Importantly, the substantial increase in video length doesn’t compromise the model’s innate generalization capabilities, and the model showcases its advantages in generating videos of diverse styles and resolutions. We will release the source code and the enhanced model publicly. |
| GitHub: https://github.com/modelscope/DiffSynth-Studio |
📜 研究核心
⚙️ 内容
该研究的核心在于开发了一种创新的后调优方法——ExVideo,它致力于克服当前视频扩散模型在生成长时间视频方面的限制。ExVideo的设计目标是增强现有模型的功能,使之在不大幅增加训练成本的前提下,能够输出更长的视频序列。
该方法巧妙地利用了3D卷积、时间注意力和位置嵌入等常见时间模型结构的扩展策略,确保了在视频长度显著增加的同时,模型依旧能保持其在不同风格和分辨率视频生成上的泛化性能。通过在Stable Video Diffusion模型上的扩展训练,ExVideo证明了其能够使模型生成帧数最多提升至原视频5倍的能力,并且只需1,500 GPU小时的训练量,这在4万个视频组成的数据库上得到了验证。
💡 创新点
-
参数高效性:ExVideo提出了一种新的后调优策略,使得在不对整个模型进行大规模重训的情况下,仅通过对模型中时序相关组件的微调,就能够显著增强其生成更长视频片段的能力。这种方法大大降低了对计算资源的需求,仅需1.5k GPU小时就能将视频生成帧数提高至原模型的5倍。
-
多架构兼容性:该策略设计了针对不同时间模型架构(如3D卷积、时间注意力和位置嵌入)的扩展策略,这使得它能够广泛应用于多种现有的视频合成模型,提高了方法的通用性和适用范围。
-
视频连贯性和质量保障:ExVideo不仅提升了视频长度,而且确保了生成视频的视觉质量和叙事连贯性,避免了常见的视频连贯性问题,如错误累积导致的图像断裂现象,这是通过精细的模型调整实现的。
-
泛化能力不受损:即使视频长度显著增加,ExVideo的模型依然能保持其在生成不同风格和分辨率视频方面的优势,证明了模型在扩展视频长度的同时,其内在的泛化能力并未被削弱。
🧩 不足
-
基础模型限制:ExVideo增强的视频扩散模型仍然受限于其基础模型的固有局限。例如,尽管能够生成更长的视频序列,但在合成高质量的人像方面表现不佳,经常出现帧不完整或人像失真的情况。这意味着对于需要高度精确的人脸或人体动作合成的应用场景,当前解决方案可能不尽理想。
-
资源约束:研究团队指出,由于资源限制,他们未能独立预训练一个大型的视频合成基础模型。这意味着模型的潜力可能还未完全释放,且对于未来进一步提升模型性能,可能需要更多计算资源或更高效的训练策略。
-
长期视频理解能力:尽管ExVideo在生成较长视频方面有所突破,但当前的视频合成模型普遍缺乏对长期视频连贯性的理解和处理能力。这意味着在生成长视频时,模型可能会累积误差,影响视频的整体连贯性和叙事逻辑,特别是在没有额外优化措施的情况下。
-
版权与数据来源:尽管使用了如OpenSora等公开数据集来规避版权问题,但这些数据集的视频质量和多样性可能仍有限制,可能无法完全代表实际应用场景中的全部复杂性和多样性,这可能会影响模型的泛化能力。
-
技术挑战:尽管采用了多项工程优化措施(如参数冻结、混合精度训练、梯度检查点、Flash Attention及深度加速库),以应对扩展视频序列训练中的计算资源挑战,但这些技术手段可能仍有优化空间,尤其是在处理极端长视频或高分辨率视频时。
🔁 研究内容
💧 数据
使用了一个包含40,000个视频的大型数据集进行实验,数据集包含多样化的风格和分辨率,确保了模型训练的广泛适用性。
👩🏻💻 方法
扩展时序模块:后调优策略
- 目标与动机
-
目标:使现有的视频合成模型能够生成更长的视频,而不需要从头开始训练或大幅增加计算资源消耗。
-
动机:尽管视频合成技术取得了显著进步,但大多数模型受限于计算资源,只能生成较短的视频片段。ExVideo旨在克服这一限制,同时维持模型的泛化能力和生成多样风格、分辨率视频的优势。
- 3D卷积层的保留与利用
-
原理与保留:3D卷积层是视频处理中常用的一种技术,它可以捕获空间和时间维度上的特征。先前研究表明,即使不经过微调,3D卷积层也能自适应地处理不同尺度的数据,因此ExVideo方法选择直接保留模型中原有的3D卷积层结构。
-
优势:保留这些层可以保持模型对不同视频分辨率和时序长度的广泛适应性,无需对这些基础层做重大改动,减少了模型调整的复杂度。
- 时间注意力模块的微调
-
策略:受到大型语言模型中时间注意力机制扩展应用于更长序列的启发,ExVideo对时间注意力层的参数进行了微调。通过这种微调,增强了模型处理更长视频序列的能力。
-
效果:这种调整使得模型能够更好地捕捉和利用长序列中的上下文依赖,从而提高生成视频的连贯性和复杂性。
- 可训练位置嵌入的引入
-
问题:原始的静态位置嵌入或固定的可训练嵌入在面对更长视频时可能不再适用。
-
解决方案:引入了扩展的可训练位置嵌入,这些嵌入参数以循环模式初始化,与预训练模型的位置嵌入配置相兼容,从而能适应更长的视频序列。
-
附加策略:在位置嵌入层之后添加了一个恒等3D卷积层,其核心初始化为恒等矩阵,其余参数初始化为零。这个层旨在学习长期的视频特征,同时在训练初期保持视频表示的不变性,以维护与原始计算过程的一致性。
- 总体架构调整
-
适应性修改:所有修改都是适应性的,确保了预训练模型原有的泛化能力得以保留。在训练扩展模块时,模型外部的参数被固定,以此来降低内存使用,提高训练效率。
-
优化效率:考虑到注意力操作的计算复杂度随序列长度增加呈二次增长,ExVideo采取的策略在不显著增加计算负担的前提下,提高了模型处理长视频序列的能力。
综上所述,ExVideo通过针对性地调整时序模块,即优化3D卷积层、微调时间注意力机制并引入改进的位置嵌入策略,实现了在不牺牲模型原有特性的基础上,有效扩展视频合成模型生成视频长度的目标。这种方法不仅提升了模型的实用性,还为视频合成技术的发展开辟了新的方向。
🔬 实验
本文主要介绍了作者在视频合成模型方面所做的研究和实验。首先,作者对现有的视频合成模型进行了分类,并提出了三种常见的时空模块架构:3D卷积、时空注意力和位置编码。然后,作者提出了一种扩展时空模块的方法,以提高模型的生成能力。最后,作者通过多个实验验证了他们的方法的有效性,并与其他现有模型进行了比较。
第一个实验是针对文本到视频合成的任务。作者将现有的文本到图像模型与视频合成模型相结合,可以轻松地开发出集成管道,将文本描述转换为视频。在这个任务中,作者使用了Stable Diffusion 3作为基础帧生成器,并展示了该模型能够从高质量的图像中生成流畅的运动过渡,即使训练数据集中不包括某些风格(如平面动漫和像素艺术)也是如此。这个实验的结果表明,扩展后的Stable Video Diffusion模型保留并扩展了原始模型的一般化能力。
第二个实验是为了展示模型学习过程中的动态变化。作者展示了在训练过程中,模型生成的视频如何从只有结构完整性逐渐发展成为具有复杂运动的能力。这个实验的结果表明,模型能够在长时间的学习过程中理解场景的深度和空间关系。
第三个实验是为了测试模型在不同分辨率下的性能。作者展示了模型在常见宽高比下能够成功生成更高分辨率的视频。这个实验的结果表明,模型不仅具有强大的泛化能力和鲁棒性,而且经过后调优后能够进一步提高其性能。
最后一个实验是对模型与其他现有模型的比较。作者选择了多种不同的视频合成模型,包括AnimateDiff、LaVie、ModelScopeT2V等,并将其结果与扩展后的Stable Video Diffusion模型进行了比较。结果显示,大多数现有模型通常只能生成少量的运动,而扩展后的Stable Video Diffusion模型则具有更强的生成能力,能够生成更复杂的运动。这表明扩展后的模型具有更高的生成性能。
📜 结论
-
视频质量与连贯性:ExVideo不仅成功扩展了视频长度,而且保证了生成视频的质量和叙事连贯性,没有因视频长度的增加而牺牲这些关键指标。
-
泛化能力:模型在生成不同风格和分辨率的视频时仍然表现出色,表明其内在的泛化能力未受损害
🤔 个人总结
文章优点
该论文提出了一种名为ExVideo的视频合成模型增强技术,通过后调优的方式扩展了现有视频合成模型的时间范围,从而实现了更长的视频生成。该方法在Stable Video Diffusion模型上进行了验证,并成功将生成帧数从25帧扩展到128帧,同时保持了原始模型的生成能力。此外,该方法还具有内存效率高、可与其他开源技术集成等优点。
方法创新点
该论文的主要贡献在于提出了ExVideo技术,这是一种基于后调优的方法,可以有效地扩展现有视频合成模型的时间范围。与传统的训练方法相比,这种方法不需要大量的计算资源,可以在有限的计算资源下实现更长的视频生成。此外,该方法还可以无缝地与文本到图像模型集成,进一步提高了其应用价值。
未来展望
虽然ExVideo技术已经取得了一些进展,但仍然存在一些限制。例如,该方法仍受到基础模型的限制,无法准确合成人类肖像。因此,在未来的研究中,需要开发更加先进的基础模型来提高视频合成的质量。此外,还需要更多的数据集和更强大的计算资源来支持这种技术的发展。
相关文章:

ExVideo: 提升5倍性能-用于视频合成模型的新型后调谐方法
标题:ExVideo: Extending Video Diffusion Models via Parameter-Efficient Post-Tuning作者: Zhongjie Duan; Wenmeng Zhou; Cen Chen; Yaliang Li; Weining QianDOI: 10.48550/arXiv.2406.14130摘要: Recently, advancements in video synthesis have attracted s…...
Grid 之 Column)
laravel Dcat Admin 入门应用(三)Grid 之 Column
Dcat Admin 是一个基于 Laravel-admin 二次开发而成的后台构建工具,只需很少的代码即可构建出一个功能完善的高颜值后台系统。支持页面一键生成 CURD 代码,内置丰富的后台常用组件,开箱即用,让开发者告别冗杂的 HTML 代码。 larav…...

掌握Llama 2分词器:填充、提示格式及更多
目录 简介Llama 2分词器基础为分词器设置填充添加特殊标记使用BOS和EOS标记进行分词定义填充标记训练中使用填充标记高级功能:掩码标记Llama的提示格式结论 简介 在语言模型领域,时间变化迅速。自Llama 2发布已经有几个月了,但关于其分词器…...
pdf合并,pdf合并成一个pdf,pdf合并在线网页版
在处理pdf文件的过程中,有时我们需要将多个pdf文件合并成一个pdf文件。作为一名有着丰富计算机应用经验的技术博主,我将为您详细介绍如何将多个pdf文件合并成一个pdf文件。 pdf合并方法:使用, “轻云处理pdf官网” 打开 “轻云处…...
算法基础--------【图论】
图论(待完善) DFS:和回溯差不多 BFS:进while进行层序遍历 定义: 图论(Graph Theory)是研究图及其相关问题的数学理论。图由节点(顶点)和连接这些节点的边组成。图论的研究范围广泛,涉及路径、…...

x86和x64架构的区别及应用
x86和x64架构的区别及应用 大家好,我是免费搭建查券返利机器人省钱赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿! 在计算机硬件和软件领域,x86和x64是两种常见的处理器架构。它们在计算能…...

2024年度总结:不可错过的隧道IP网站评估推荐
随着网络技术的飞速发展,隧道IP服务成为了许多企业和个人在进行网络活动时的得力助手。作为专业的测评团队,我们经过一整年的深入研究和测试,为大家带来了三款备受瞩目的隧道IP网站推荐——品易HTTP、极光HTTP和一G代理。接下来,我…...

Linux下VSCode的安装和基本使用
应用场景:嵌入式开发。 基本只需要良好的编辑环境,能支持文件搜索和跳转,就挺OK的。 之所以要在Linux下安装,是因为在WIN11上安装后,搜索功能基本废了,咋弄都弄不好,又不方便重装win系统&#x…...
C# 实现websocket双向通信
🎈个人主页:靓仔很忙i 💻B 站主页:👉B站👈 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:C# 🤝希望本文对您有所裨益,如有不足之处ÿ…...

Spring Boot结合FFmpeg实现视频会议系统视频流处理与优化
在构建高效稳定的视频会议系统时,实时视频流的处理和优化是开发者面临的核心挑战之一。这不仅仅是简单的视频数据传输,更涉及到一系列复杂的技术问题,需要我们深入分析和有效解决。 高并发与实时性要求: 视频会议系统通常需要支持多人同时进行视频通话,这就意味着系统需要…...

扫扫地,搞搞卫生 ≠ 车间5S管理
在制造业的日常运营中,车间管理是一项至关重要的工作,它直接关系到生产效率、产品质量以及员工的工作环境。然而,许多人常常将简单的“扫扫地,搞搞卫生”等同于车间5S管理,这种误解不仅可能导致管理效果不佳࿰…...
)
ES(笔记)
es就是json请求体代替字符串查询 dsl查询和过滤,一个模糊查询,一个非模糊查询 must,should 做模糊查询的,里面都是match,根据查询内容进行匹配,filter过滤,term词元查询,就是等值查…...
开箱即用的fastposter海报生成器
什么是 fastposter ? fastposter 海报生成器是一款快速开发海报的工具。只需上传一张背景图,在对应的位置放上组件(文字、图片、二维码、头像)即可生成海报。 点击代码直接生成各种语言 SDK 的调用代码,方便快速开发。 软件特性&…...

力扣每日一题 6/28 动态规划/数组
博客主页:誓则盟约系列专栏:IT竞赛 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ 2742.给墙壁刷油漆【困难】 题目: 给你两个长度为 n 下标从 0…...

[数据集][目标检测]游泳者溺水检测数据集VOC+YOLO格式8275张4类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):8275 标注数量(xml文件个数):8275 标注数量(txt文件个数):8275 标注…...
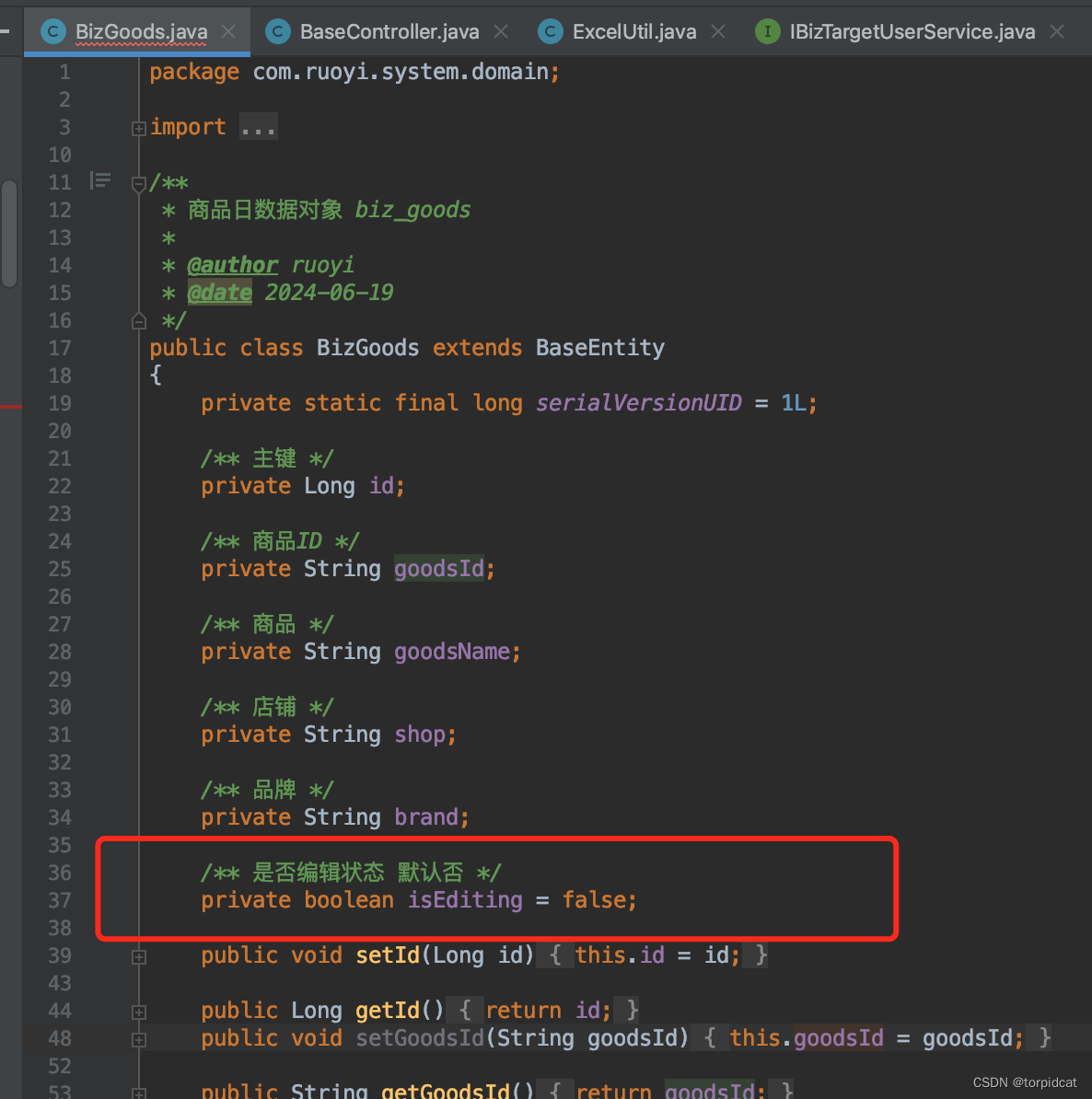
若依 ruoyi 分离版 vue 简单的行内编辑实现
需要实现的效果:双击文本 - 修改文本 - 保存修改。 原码:仅文本显示文字内容 <el-table-column label"商品" align"center" prop"goodsName" width"200" v-if"columns[1].visible" /> 实现…...

【工具】API文档生成DocFX
文章目录 总述示例第一步:安装 DocFX第二步:初始化项目第三步:编辑配置文件第四步:编写文档第五步:生成文档第六步:预览文档第七步:部署文档 总述 DocFX 是一个由微软开发的开源文档生成工具&a…...

在 JavaScript 中处理异步操作和临时事件处理程序
关键技术和设计总结 使用 Promise 和 then 进行异步操作: 我们通过使用 Promise 来处理异步操作,确保操作按顺序执行。在 getReportListByCurrentTime 函数中,返回一个 Promise 对象,保证在数据加载完成后调用 resolve,以便可以在…...
)
[Cocos Creator] v3.8开发知识点记录(持续更新)
问题:从 cc 里找不到宏定义 CC_PREVIEW 等。 解决方案:找不到就自己定义,将 declare const CC_PREVIEW; 添加到需要的ts文件里。参考:creator3d 找不到宏定义如 CC_EDITOR,CC_PREVIEW,CC_JSB - Creator 3.x…...

Excel_VBA编程
在Excel中,VBA(Visual Basic for Applications)是一种强大的工具,可以用来自动化各种任务。下面介绍一些常用的VBA函数和程序结构: 常用函数 MsgBox:用于显示消息框。 MsgBox "Hello, World!"In…...
)
告别官方包!手把手教你从Gitee源码编译kkFileView v4.4.0(附Maven打包避坑点)
从源码到部署:深度解析kkFileView v4.4.0全流程编译实战 在企业级文档处理场景中,kkFileView作为一款开箱即用的文件预览解决方案,其源码编译能力往往被大多数开发者忽视。本文将打破常规安装包依赖,带你深入源码编译的全链路过程…...
)
FPGA开发实战——常见错误排查与优化技巧(持续更新)
1. Vivado仿真与PR Flow冲突问题实战解析 第一次用Vivado做PR(Partial Reconfiguration)项目时,我兴冲冲地点开仿真按钮,结果弹出一个让人崩溃的报错:"ERROR [Common 17-69] Command failed. Simulation for PR F…...

智能号码定位引擎:企业级地理信息快速响应解决方案
智能号码定位引擎:企业级地理信息快速响应解决方案 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_mirrors…...
结合深度神经网络(DNN)进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 还请多多点一下)
项目介绍 MATLAB实现基于Q-learning-DNN Q学习算法(Q-learning)结合深度神经网络(DNN)进行无人机三维路径规划的详细项目实例(含模型描述及部分示例代码) 还请多多点一下
MATLAB实现基于Q-learning-DNN Q学习算法(Q-learning)结合深度神经网络(DNN)进行无人机三维路径规划的详细项目实例 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序&…...

3大突破!GenUI重构Flutter界面开发范式
3大突破!GenUI重构Flutter界面开发范式 【免费下载链接】genui 项目地址: https://gitcode.com/gh_mirrors/genui1/genui GenUI是一个革命性的Flutter库,它通过AI驱动的动态界面生成技术,彻底改变了传统UI开发流程。作为连接自然语言…...

Notepad--终极指南:5分钟掌握国产跨平台文本编辑器的完整解决方案
Notepad--终极指南:5分钟掌握国产跨平台文本编辑器的完整解决方案 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-…...

终极指南:如何用虚拟手柄驱动解锁Windows游戏新玩法
终极指南:如何用虚拟手柄驱动解锁Windows游戏新玩法 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾梦想过用键盘鼠标玩主机游戏&#x…...

从零搭建中文资源媒体中心:Kodi中文插件库完全指南
从零搭建中文资源媒体中心:Kodi中文插件库完全指南 【免费下载链接】xbmc-addons-chinese Addon scripts, plugins, and skins for XBMC Media Center. Special for chinese laguage. 项目地址: https://gitcode.com/gh_mirrors/xb/xbmc-addons-chinese 你是…...

OpenClaw深度沟通渠道-全景深度解构
OpenClaw深度沟通渠道-全景深度解构OpenClaw的渠道(Channels)是其“交互层”的核心,是用户意图与AI执行力的唯一交汇点。选择渠道,就是选择将AI能力注入您数字生活的哪个场景。以下分析将超越简单列表,深入每个渠道的技…...

OpenClaw日志分析技巧:GLM-4.7-Flash任务执行问题定位
OpenClaw日志分析技巧:GLM-4.7-Flash任务执行问题定位 1. 为什么需要关注OpenClaw日志 上周我在尝试用GLM-4.7-Flash模型自动处理一批技术文档时,遇到了一个诡异现象:任务明明显示执行成功,但最终输出文件却是空的。这个经历让我…...