【自然语言处理系列】探索NLP:使用Spacy进行分词、分句、词性标注和命名实体识别,并以《傲慢与偏见》与全球恐怖活动两个实例文本进行分析
本文深入探讨了scaPy库在文本分析和数据可视化方面的应用。首先,我们通过简单的文本处理任务,如分词和分句,来展示scaPy的基本功能。接着,我们利用scaPy的命名实体识别和词性标注功能,分析了Jane Austen的经典小说《傲慢与偏见》,识别出文中的主要人物和地点。最后,我们将这些文本分析技术应用于全球恐怖活动的数据集中,揭示了不同恐怖组织在全球各地的活动分布。文章展示了如何用scaPy进行复杂的文本挖掘和数据分析,为研究和政策制定提供见解。
目录
一、文本处理-分词和分句
二、词性标注
三、命名体识别
四、名字实体识别------以Jane Austen 的小说《傲慢与偏见》为例
五、恐怖袭击分析(实例)
Spacy是一个先进的自然语言处理(NLP)库,设计用于帮助开发者构建处理大量文本数据的应用程序。Spacy的主要优势在于其优秀的性能和可扩展性,使其能够支持快速的文本处理任务,如分词、词性标注、命名实体识别和依赖关系解析等。此外,Spacy还提供了预训练的统计模型和Word Embeddings,这使得它在学术和工业界NLP项目中是一个非常受欢迎的选择。由于这些功能,Spacy在处理多语言文本数据时显得尤为出色,被广泛应用于各种NLP和机器学习项目中。
一、文本处理-分词和分句
# 导入工具包和英文模型
import spacy
nlp = spacy.load("en_core_web_sm")#读进英文模型doc = nlp('Weather is good, very windy and sunny. We have no classes in the afternoon.')
# 分词
for token in doc:print (token)
#分句
for sent in doc.sents:print (sent)
二、词性标注
for token in doc:print ('{}-{}'.format(token,token.pos_))
三、命名体识别
首先,它将文本 "I went to Paris where I met my old friend Jack from uni." 传递给 nlp() 函数,该函数将文本处理成一个文档对象。然后,通过遍历文档对象的实体(ent),打印出每个实体及其对应的标签(label)。
import spacy
nlp = spacy.load("en_core_web_sm")#读进英文模型
doc_2 = nlp("I went to Paris where I met my old friend Jack from uni.")
for ent in doc_2.ents:print ('{}-{}'.format(ent,ent.label_))#label就是指它是什么类型的![]()
from spacy import displacy
doc = nlp('I went to Paris where I met my old friend Jack from uni.')
displacy.render(doc,style='ent',jupyter=True)
四、名字实体识别------以Jane Austen 的小说《傲慢与偏见》为例
本小节通过使用 spaCy 库进行自然语言处理 (NLP) 来分析 Jane Austen 的小说《傲慢与偏见》中出现的人物名称,以及每个人物名称出现的频次。首先,定义了一个名为 read_file 的函数,用于读取文本文件的内容。该函数通过 open 函数打开文件,并调用 read 函数来读取文件的内容。接下来,加载了 spaCy 的英文语言模型 nlp,并将小说文本 text 传递给 nlp 函数进行实例化。然后,使用列表推导式,遍历processed_text.sents,将每个句子存储在sentences列表中。接下来,定义了一个名为 find_person 的函数,用于查找文本中出现的人物名称及其频次。该函数首先创建了一个空的 Counter 对象 c,然后遍历文本中所有的实体 (ent),如果实体的标签是 PERSON,则将其 lemma(词干形式)加入到 Counter 对象 c 中,并增加计数器的值。最后,调用 find_person 函数,将整个文本传递给该函数,并打印出人物名称及其出现的频次。输出结果将是一个列表,列表中包含了出现频次最多的 10 个人物名称及其出现的频次。
def read_file(file_name):with open(file_name, 'r') as file:return file.read()
# 加载文本数据
text = read_file('./data/pride_and_prejudice.txt')#《傲慢与偏见》这篇小说
processed_text = nlp(text)#将text实例化一下
sentences = [s for s in processed_text.sents]
print (len(sentences))
# sentences[:5]
from collections import Counter,defaultdict
def find_person(doc):c = Counter()for ent in processed_text.ents:if ent.label_ == 'PERSON':c[ent.lemma_]+=1return c.most_common(10)
print (find_person(processed_text))
五、恐怖袭击分析(实例)
本小节主要目的是分析一组关于恐怖主义的文章,并统计常见恐怖组织与特定地点之间的关联频率。在处理了名为data/rand-terrorism-dataset.txt的文本文件后,代码首先使用spacy的英文模型将文本转换为小写并识别其中的实体。实体包括人名(PERSON)、组织名(ORG)和地点(GPE)。接着,定义了两个列表:common_terrorist_groups包含了一些常见的恐怖组织名称,而common_locations则包含了一些常见的地点名称。在处理每行文本时,代码会找出文章中提到的恐怖组织和地点,并将它们与预定义的常见恐怖组织和地点列表进行匹配。如果文章中的某个实体同时出现在这两个列表中,那么这个实体和地点的组合就会被记录下来,并在location_entity_dict字典中进行计数。最后,使用pandas库,将location_entity_dict转换为一个DataFrame对象,名为location_entity_df。这个数据框的每一行代表一个恐怖组织,每一列代表一个地点,而单元格中的值表示该恐怖组织与该地点共同出现的次数。
# 导入工具包和英文模型
import spacy
nlp = spacy.load("en_core_web_sm")#读进英文模型
def read_file_to_list(file_name): with open(file_name, 'r') as file: return file.readlines()
terrorism_articles = read_file_to_list('data/rand-terrorism-dataset.txt')
#read_file_to_list函数将文本文件按行分割成了一个列表
terrorism_articles_nlp = [nlp(art.lower()) for art in terrorism_articles]
common_terrorist_groups = [ 'taliban', 'al-qaeda', 'hamas', 'fatah', 'plo', 'bilad al-rafidayn'
] common_locations = [ 'iraq', 'baghdad', 'kirkuk', 'mosul', 'afghanistan', 'kabul', 'basra', 'palestine', 'gaza', 'israel', 'istanbul', 'beirut', 'pakistan'
]
location_entity_dict = defaultdict(Counter) for article in terrorism_articles_nlp: article_terrorist_groups = [ent.lemma_ for ent in article.ents if ent.label_=='PERSON' or ent.label_ =='ORG']#人或者组织 article_locations = [ent.lemma_ for ent in article.ents if ent.label_=='GPE'] terrorist_common = [ent for ent in article_terrorist_groups if ent in common_terrorist_groups] locations_common = [ent for ent in article_locations if ent in common_locations] for found_entity in terrorist_common: for found_location in locations_common: location_entity_dict[found_entity][found_location] += 1
import pandas as pd location_entity_df = pd.DataFrame.from_dict(dict(location_entity_dict),dtype=int)
location_entity_df = location_entity_df.fillna(value = 0).astype(int)
location_entity_df 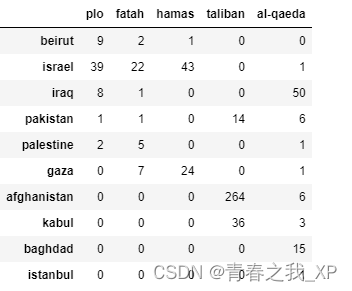

import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12, 10))
hmap = sns.heatmap(location_entity_df, annot=True, fmt='d', cmap='YlGnBu', cbar=False,square=False,annot_kws={"fontsize": 18})# 添加信息
plt.title('Global Incidents by Terrorist group',fontsize=20)
plt.xticks(rotation=30,fontsize=15)
plt.yticks(rotation=30,fontsize=15)
plt.show()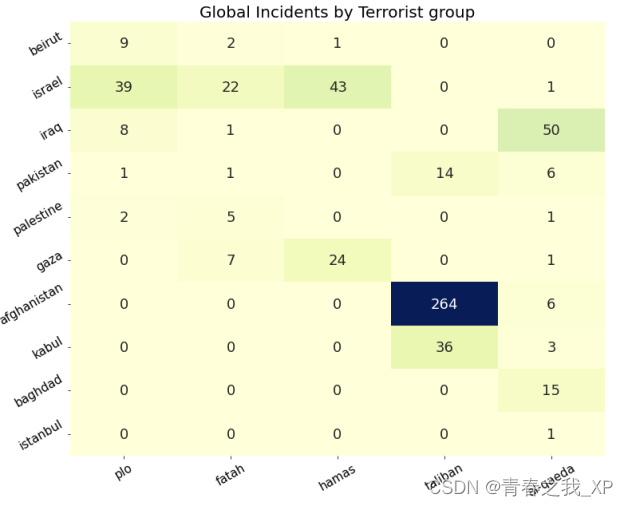
从上图,可以看出,塔利班(Taliban)在阿富汗(afghanistan)地区进行的恐怖袭击次数最多,为264次。
相关文章:
【自然语言处理系列】探索NLP:使用Spacy进行分词、分句、词性标注和命名实体识别,并以《傲慢与偏见》与全球恐怖活动两个实例文本进行分析
本文深入探讨了scaPy库在文本分析和数据可视化方面的应用。首先,我们通过简单的文本处理任务,如分词和分句,来展示scaPy的基本功能。接着,我们利用scaPy的命名实体识别和词性标注功能,分析了Jane Austen的经典小说《傲…...

【Rust】function和methed的区别
文章目录 functionmethedAssociated Functions 参考资料 一句话总结: function和methed很多都是相同的。 不同点在于: methed定义在结构体里面,并且它的第一个参数肯定是self,代表结构体实例。方法需要用实例名.方法名调用当然结…...

python基础语法 003-4 数据类型集合
1 集合 1.1 什么是集合 什么是集合?ANS:集合set是一个无序的不重复元素序列集合怎么表示?ANS: {} , 用逗号隔开打印元组类型,type()一个元素的集合怎么表示?:ANS:存储多种类型{"a", 1} """…...

Vue如何引用组件
在 Vue.js 中,你可以通过几种方式引用组件: 全局注册 在 main.js 或你的主入口文件中,你可以使用 Vue.component() 方法来全局注册一个组件。这意味着这个组件可以在你的 Vue 应用的任何地方使用。 import MyComponent from ./components/…...

vue3中省市区联动在同一个el-form-item中咋么设置rules验证都不为空的效果
在开发中出现如下情况,在同一个el-form-item设置了省市区三级联动的效果 <el-form-item label"地区" prop"extraProperties.Province"><el-row :gutter"20"><el-col :span"12"><el-select v-model&qu…...
如何集成CppCheck到visual studio中
1.CPPCheck安装 在Cppcheck官方网站下载最新版本1.70,官网链接:http://cppcheck.sourceforge.net/ 安装Cppcheck 2.集成步骤 打开VS,菜单栏工具->外部工具->添加,按照下图设置,记得勾选“使用输出窗口” 2.…...

GWO-CNN-SVM,基于GWO灰狼优化算法优化卷积神经网络CNN结合支持向量机SVM数据分类(多特征输入多分类)
GWO-CNN-SVM,基于GWO灰狼优化算法优化卷积神经网络CNN结合支持向量机SVM数据分类(多特征输入多分类) 1. GWO灰狼优化算法 灰狼优化算法(Grey Wolf Optimizer, GWO)是一种启发式优化算法,模拟了灰狼群体的社会行为,包…...

Go-知识测试-工作机制
Go-知识测试-工作机制 生成test的maintest的main如何启动case单元测试 runTeststRunnertesting.T.Run 示例测试 runExamplesrunExampleprocessRunResult 性能测试 runBenchmarksrunNtesting.B.Run 在 Go 语言的源码中,go test 命令的实现主要在 src/cmd/go/internal…...

【小程序静态页面】猜拳游戏大转盘积分游戏小程序前端模板源码
猜拳游戏大转盘积分游戏小程序前端模板源码, 一共五个静态页面,首页、任务列表、大转盘和猜拳等五个页面。 主要是通过做任务来获取积分,积分可以兑换商品,也可用来玩游戏;通过玩游戏既可能获取奖品或积分也可能会消…...

JupyterServer配置
1. 安装jupyter pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple --default-timeout1000 2. 生成配置 jupyter notebook --generate-config 3. 修改配置,设置密码 获取密码的方式:命令行输入python后,用以下方式获…...
:MINIMIZING FLOPS TO LEARN EFFICIENT SPARSE REPRESENTATIONS)
信息检索(57):MINIMIZING FLOPS TO LEARN EFFICIENT SPARSE REPRESENTATIONS
MINIMIZING FLOPS TO LEARN EFFICIENT SPARSE REPRESENTATIONS 摘要1 引言2 相关工作3 预期 FLOPS 次数4 我们的方法5 实验6 结论 发布时间(2020) 最小化 Flop 来学习高效的稀疏表示 摘要 1)学习高维稀疏表示 2)FLOP 集成到损失…...

Python 面试【中级】
欢迎莅临我的博客 💝💝💝,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...
[Open-source tool]Uptime-kuma的簡介和安裝於Ubuntu 22.04系統
[Uptime Kuma]How to Monitor Mqtt Broker and Send Status to Line Notify Uptime-kuma 是一個基於Node.js的開軟軟體,同時也是一套應用於網路監控的開源軟體,其利用瀏覽器呈現直觀的使用者介面,如圖一所示,其讓使用者可監控各種…...

【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 灰度图像恢复(100分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 …...

leetcode494. 目标和
1.思想方法 2.代码 class Solution { public int findTargetSumWays(int[] nums, int target) {int sum 0;for(int num : nums)sum num;if(sum < Math.abs(target) || (targetsum)%2 ! 0)return 0;int x (targetsum) / 2,n nums.length;//基于滚动数组的方法int[] dp…...

数据结构简介
在容器的基础之上,java引入了数据结构的概念。数据结构可以简单地理解成是一个以特定的布局方式来存储数据的容器。但是我个人觉得这种理解方式不太合理,根据我们学的数据结构的内容,我更倾向于数据结构是数据在容器中的布局方式,…...
PyScript:在浏览器中释放Python的强大
PyScript:Python代码,直接在网页上运行。- 精选真开源,释放新价值。 概览 PyScript是一个创新的框架,它打破了传统编程环境的界限,允许开发者直接在浏览器中使用Python语言来创建丰富的网络应用。结合了HTML界面、Pyo…...

巴黎成为欧洲AI中心 大学开始输出AI创始人
来自Dealroom 的数据显示,在欧洲和以色列AI创业公司中,法国的AI创业公司资金最充裕。Mistral、Owkin、Hugging Face等法国企业已经融资23亿美元,比英国、德国AI创业公司都要多。 一名大学生走出校门凭借聪明才智和一个黄金点子成为富豪&#…...
完全离线的本地问答模型LocalGPT如何实现无公网IP远程连接提问
文章目录 前言环境准备1. localGPT部署2. 启动和使用3. 安装cpolar 内网穿透4. 创建公网地址5. 公网地址访问6. 固定公网地址 前言 本文主要介绍如何本地部署LocalGPT并实现远程访问,由于localGPT只能通过本地局域网IP地址端口号的形式访问,实现远程访问…...

【算法专题--栈】栈的压入、弹出序列 -- 高频面试题(图文详解,小白一看就懂!!)
目录 一、前言 二、题目描述 三、解题方法 💧栈模拟法💧-- 双指针 ⭐ 解题思路 ⭐ 案例图解 四、总结与提炼 五、共勉 一、前言 栈的压入、弹出序列 这道题,可以说是--栈专题--,最经典的一道题,也是在…...

TensorRT加速HY-Motion:NVIDIA推理性能提升方案
TensorRT加速HY-Motion:NVIDIA推理性能提升方案 1. 项目背景与价值 HY-Motion 1.0作为业界领先的文生3D动作生成模型,凭借其十亿级参数的Diffusion Transformer架构,在动作生成质量和指令遵循能力方面达到了新的高度。然而,如此…...

主流信道模型对比:从COST207到WINNER II的多场景性能解析
1. 信道模型的前世今生:为什么我们需要这么多标准? 第一次接触信道模型时,我也被各种COST、WINNER之类的缩写搞晕了。这就像去超市买酱油,发现货架上摆着生抽、老抽、海鲜酱油、薄盐酱油...其实它们都是为了解决不同场景下的调味需…...

Unity 2018 + Facebook SDK 7.15.1避坑指南:从崩溃解决到完整功能实现
Unity 2018与Facebook SDK 7.15.1深度适配实战手册 当老牌游戏引擎遇上社交巨头的SDK,版本兼容性问题往往成为开发者的噩梦。本文将带您深入探索Unity 2018与Facebook SDK 7.15.1这对"经典组合"的适配之道,从环境搭建到功能实现,完…...

谱聚类实战:如何让声纹模型自动分辨一段录音里有几个人说话?
谱聚类在声纹识别中的应用:如何自动判断录音中的说话人数量 想象一下,你手头有一段长达两小时的会议录音,里面有五位不同声线的参与者交替发言。作为开发者,你需要设计一个系统,不仅能识别每个人的声音特征,…...

OpenClaw+Phi-3-vision-128k-instruct:电商商品截图自动比价系统
OpenClawPhi-3-vision-128k-instruct:电商商品截图自动比价系统 1. 为什么需要自动化比价系统 作为一个经常网购的技术爱好者,我发现自己花在比价上的时间越来越多。每次看到心仪的商品,都要手动打开多个电商平台,截图保存价格信…...

如何选择适合你的Python Web服务器:uvicorn与gunicorn深度对比
1. 为什么需要关注Web服务器选择? 当你用Python开发完一个Web应用后,最后一步就是把它部署上线。这时候你会发现,直接运行python app.py这种方式根本撑不住几个用户访问。我刚开始做项目时就犯过这个错误,结果上线当天服务器就直接…...

SDS011传感器驱动开发:嵌入式PM2.5/PM10检测实战指南
1. SDS011传感器库技术解析:嵌入式系统中的PM2.5/PM10颗粒物检测实践指南1.1 项目定位与工程价值SDS011是由中国Nova Fitness公司推出的低成本、高可靠性激光散射式颗粒物传感器,专为环境空气质量监测设计。该传感器可同时输出PM2.5和PM10质量浓度数据&a…...

Jupyter notebook学习容易忘的点
数字数字计算符合常识选择run selected cell就能运行单个块字符串字符串也能计算转义字符\n 表示换行\t 表示tab\\ 表示\ 斜杠本身...

告别卡顿:在Windows10上通过QEMU与WHPX硬件加速高效部署Ubuntu20.04开发环境
1. 为什么选择QEMUWHPX方案? 很多开发者都遇到过这样的困境:在Windows系统上运行Linux虚拟机时,要么性能拉胯到让人抓狂,要么配置复杂得让人望而却步。我之前用VMware跑Ubuntu时,光是开个浏览器就能让CPU飙到100%&…...

深入解析epoll:高并发网络编程核心技术
1. 理解高并发场景下的网络通信挑战在现代网络服务中,处理大量并发连接是一个常见需求。想象一个即时通讯服务器需要同时维持上百万用户的TCP连接,但实际活跃用户(正在收发消息的)可能只有几百个。传统做法如select/poll需要每次将…...