第九章:Java集合
第九章:Java集合
9.1:Java集合框架概述
数组、集合都是对多个数据进行存储(内存层面,不涉及持久化)操作的结构,简称Java容器。
-
数组存储多个数据方面的特点
- 一旦初始化以后,其长度就确定了。
- 数组一旦定义好,其元素的类型也就确定了。我们也就只能操作指定类型的数据了。
-
数组在存储多个数据方面的缺点
- 一旦初始化以后,其长度就不可修改。
- 数组中提供的方法非常有限,对于添加、删除、插入数据等操作,非常不便,同时效率不搞。
- 获取数据中实际元素的个数的需求,数组没有现成的属性或方法可用。
- 数组存储数据的特点:有序、可重复。对于无序、不可重复的需求,不能满足。
-
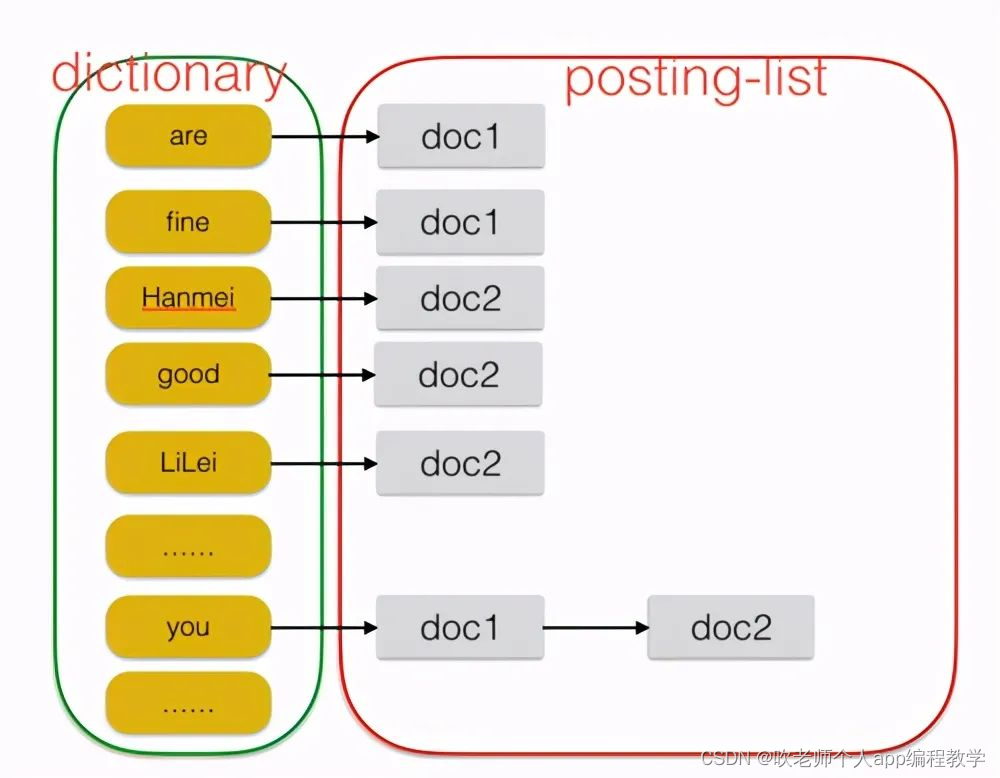
Java集合可分为Collection和Map两种体系-
Collection接口:单列数据,定义了存储一组对象的方法的集合。List:元素有序,可重复的集合。Set:元素无序,不可重复的集合。

-
Map接口:双列数据,保存具有映射关系key - value对的集合。

-
9.2:Collection接口方法
-
add(Object obj):将元素obj添加到集合中。 -
addAll(Collection coll):将coll集合中的元素添加到当前的集合中。 -
int size():获取添加的元素的个数。 -
void clear():清空集合元素。 -
isEmpty():判断当前集合是否为空。Collection coll = new ArrayList();coll.add("AA"); coll.add("BB"); coll.add(123);//自动装箱 coll.add(new Date());System.out.println(coll.size());//4Collection coll1 = new ArrayList(); coll1.add(456); coll1.add("CC"); coll.addAll(coll1);System.out.println(coll.size());//6coll.clear();System.out.println(coll.isEmpty());// true -
boolean contains(Object obj):判断当前集合是否包含obj。 -
boolean containsAll(Collection c):判断形参c中的所有元素是否都存在于当前集合中。Collection coll = new ArrayList();coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(false);boolean contains = coll.contains(123); System.out.println(contains); // true System.out.println(coll.contains(new String("Tom"))); // trueCollection coll1 = Arrays.asList(123,4567); System.out.println(coll.containsAll(coll1)); // false注意:如果判断的对象是自定义类,则需要重写
equals()方法。 -
boolean remove(Object obj):从当前集合中移除obj元素。 -
boolean removeAll(Collection coll):从当前集合中移除coll中所有的元素。Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(false);coll.remove(1234); System.out.println(coll); // [123, 456, Tom, false]Collection coll1 = Arrays.asList(123,456); coll.removeAll(coll1); System.out.println(coll); // [Tom, false] -
boolean retainAll(Collection c):获取当前集合和C集合的交集,并返回给当前集合。Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(false);Collection coll1 = Arrays.asList(123,456,789); coll.retainAll(coll1); System.out.println(coll); // [123, 456] -
boolean equals(Object obj):想要返回true,需要当前集合和形参集合的元素的相同。Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Jerry",20)); coll.add(new String("Tom")); coll.add(false);Collection coll1 = new ArrayList(); coll1.add(456); coll1.add(123); coll1.add(new Person("Jerry",20)); coll1.add(new String("Tom")); coll1.add(false);System.out.println(coll.equals(coll1)); // false -
Object[] toAttay():转成对象数组。 -
hashCode():返回对象的哈希值。 -
iterator():返回Iterator接口的实例,用于遍历集合。Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(false);System.out.println(coll.hashCode()); // -1579892151Object[] arr = coll.toArray(); for(int i = 0;i < arr.length;i++){System.out.print(arr[i] + "\t"); // 123 456 Tom false }
9.3:Iterator迭代器接口
Iterator对象称为迭代器(设计模式的一种),主要用于遍历Collection集合中的元素。
GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元素,而有不需暴露该对象的内部细节。迭代器模式,就是为容器而生。
-
内部方法
-
hasNext():判断是否还有下一个元素。 -
next():指针下移,将下移以后集合位置上的元素返回。Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(false);Iterator iterator = coll.iterator();while(iterator.hasNext()){System.out.print(iterator.next() + "\t"); // 123 456 Tom false }说明:
Iterator仅用于遍历集合,Iterator本身并不提供承装对象的能力。如果需要创建Itertor对象,则必须有一个被迭代的集合。- 集合对象每次调用
iterator()方法到得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。 - 在调用
next()方法之前必须要调用hasNext()进行检测。若不调用,且下一条记录记录无效,直接调用next()会抛出NoSuchElementException异常。
-
remove():可以在遍历的时候,删除集合中的元素。此方法不同于集合直接调用remove()。Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new String("Tom")); coll.add(false);Iterator iterator = coll.iterator(); while(iterator.hasNext()) {Object obj = iterator.next();if("Tom".equals(obj)) {iterator.remove();} }iterator = coll.iterator(); while(iterator.hasNext()) {System.out.print(iterator.next() + "\t"); // 123 456 false }说明:
Iterator可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove方法,不是集合对象的remove方法。- 如果还为调用
next()或在上一次调用next方法之后已经调用remove方法,再调用remove都会报IllegalStateException。
-
-
使用
foreach循环遍历集合元素Java 5.0提供了foreach循环迭代访问Collection和数组。- 遍历操作不需要获取
Collection或数组的长度,无需使用索引访问元素。 - 遍历集合的底层调用
Iterator完成操作。 foreach还可以用来遍历数组。
Collection coll = new ArrayList(); coll.add(123); coll.add(456); coll.add(new Person("Jerry", 20)); coll.add(new String("Tom")); coll.add(false); //for(集合元素的类型 局部变量 : 集合对象) for(Object obj: coll) {System.out.println(obj); }
9.4:List接口
List集合类中元素有序,且可重复,集合中的每个元素都有其对应的顺序索引。JDK API中List接口的实现类常用的有:ArrayList、LinkedList、Vector。
-
ArrayList源码分析作为
List接口的主要实现类,线程不安全的,效率高,底层使用Object[]存储。-
JDK 7情况下// 空参构造器,底层创建了长度是10的Object[]数组 public ArrayList() {this(10); }// 添加操作 public boolean add(E e) {ensureCapacityInternal(size + 1);elementData[size++] = e;return true; } // 判断索引是否超出Object[]的长度 private void ensureCapacityInternal(int minCapacity) {modCount++;if (minCapacity - elementData.length > 0)grow(minCapacity); } // 超出长度进行扩容,且扩容为原来容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中 private void grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity); }说明:建议开发中使用带参的构造器:
ArrayList list = new ArrayList(int capacity) -
JDK 8情况下private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; // 空参构造器,对Object[] 进行初始化 public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; }// 添加操作 public boolean add(E e) {ensureCapacityInternal(size + 1);elementData[size++] = e;return true; } // 判断是不是第一次进行添加操作 private void ensureCapacityInternal(int minCapacity) {if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);}ensureExplicitCapacity(minCapacity); } // 判断索引是否超出Object[]的长度 private void ensureExplicitCapacity(int minCapacity) {modCount++;if (minCapacity - elementData.length > 0)grow(minCapacity); } // 超出长度进行扩容,且扩容为原来容量的1.5倍,同时需要将原有数组中的数据复制到新的数组中 private void grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + (oldCapacity >> 1);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity); }
总结:
jdk7中的ArrayList的对象创建类似于单例的饿汉式,而jdk8中的ArrayList的对象创建类似于单例的懒汉式,延迟了数组的创建,节省内存。 -
-
LinkedList的源码分析对于频繁的插入、删除操作,使用此类效率比
ArrayList高,底层使用双向链表存储。transient Node<E> first; transient Node<E> last;// Node定义,体现了LinkedList的双向链表的说法 private static class Node<E> {E item;Node<E> next;Node<E> prev;Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;} } -
Vector源码分析作为
List接口的古老实现类,线程安全的,效率低,底层使用Object[]数组存储。// 空参构造器,底层创建了长度是10的Object[]数组 public Vector() {this(10); } // 添加操作 public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true; } // 判断索引是否超出Object[]的长度 private void ensureCapacityHelper(int minCapacity) {if (minCapacity - elementData.length > 0)grow(minCapacity); } // 超出长度进行扩容,且扩容为原来容量的2倍,同时需要将原有数组中的数据复制到新的数组中 private void grow(int minCapacity) {int oldCapacity = elementData.length;int newCapacity = oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity);if (newCapacity - minCapacity < 0)newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)newCapacity = hugeCapacity(minCapacity);elementData = Arrays.copyOf(elementData, newCapacity); } -
List接口方法void add(int index, Object ele):在index位置插入ele元素。boolean addAll(int index, Collection eles):从index位置开始将eles中的素有元素添加进来。Object get(int index):获取指定index位置的元素。
ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); list.add(new Person("Tom", 12)); list.add(456); System.out.println(list); // [123, 456, AA, Person{name='Tom', age=12}, 456]list.add(1, "BB"); System.out.println(list); // [123, BB, 456, AA, Person{name='Tom', age=12}, 456]List list1 = Arrays.asList(1, 2, 3); list.addAll(list1); System.out.println(list.size()); // 9System.out.println(list.get(0)); // 123int indexOf(Object obj):返回obj在集合中首次出现的位置,集合中没有则返回-1。int lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置,集合中没有则返回-1。Object remove(int index):移除指定的index位置的元素,并返回此元素。Object set(int index, Object ele):设置指定index位置的元素为ele。List subList(int formIndex, int toIndex):返回从fromIndex到toIndex位置的子集合。
ArrayList list = new ArrayList(); list.add(123); list.add(456); list.add("AA"); list.add(new Person("Tom", 12)); list.add(456);int index = list.indexOf(4567); System.out.println(index); // -1System.out.println(list.lastIndexOf(456)); // 4Object obj = list.remove(0); System.out.println(obj); // 123 System.out.println(list); // [456, AA, Person{name='Tom', age=12}, 456]list.set(1, "CC"); System.out.println(list); // [456, CC, Person{name='Tom', age=12}, 456]List subList = list.subList(2, 4); System.out.println(subList); // [Person{name='Tom', age=12}, 456] System.out.println(list); // [456, CC, Person{name='Tom', age=12}, 456]
9.5:Set接口
Set接口存储无序的、不可重复的数据。set接口没有提供额外的方法。JDK API中Set接口的实现类常用的有:HashSet、LinkedHashSet、TreeSet。
无序性:不等于随机性。存储的数据在底层数组中并非按照数组索引的顺序添加,而是根据数据的哈希值决定的。
不可重复性:保证添加的元素按照equals()判断时,不能返回true。即:相同的元素只能添加一个。
-
HashSet作为
Set接口的主要实现类:线程不安全的,可以存储null值。-
添加元素的过程
- 我们向
HashSet中添加元素a,首先调用元素a所在类的hashCode()方法,计算机元素a的哈希值,此哈希值接着通过某种算法计算出HashSet底层数组中的存放位置(即为:索引位置)。 - 判断数组此位置上是否已经有元素。
- 如果此位置上没有其他元素,则元素a添加成功。
- 如果此位置上有其他元素b(或以链表形式存在的多个元素),则比较元素a与元素b的
hash值。 - 如果
hash值不相同,则元素a添加成功, - 如果
hash值相同,进而需要调用元素a所在类的equals()方法。 equals()返回true,元素a添加失败。equals()返回false,则元素a添加成功。
注意:对于索引位置已有元素然后还添加成功的而已,元素a与已经存在指定索引位置上数据以链表的方式存储。
jdk 7:元素a放到数组中,指向原来的元素。jdk 8:原来的元素在数组中,指向元素a。

- 我们向
-
-
LinkedHashSet 作为
HashSet的子类,遍历其内部数据时,可以按照添加的顺序遍历。在添加数据还维护了两个引用,记录此数据前一个数据和后一个数据,对于频繁的遍历操作,LinkedHashSet效率高于HashSet。

-
TreeSet-
TreeSet底层使用红黑树结构存储数据。 -
向
TreeSet中添加的数据,要求是相同的对象。 -
TreeSet可以确保集合元素处于排序状态。就必须得实现Comparable或者Comparator。 -
在比较两个对象是否相同的标准为:
compareTo()或者compare()返回0,不再是equals()。
-
9.6:Map接口
map与Collection并列存在。用于保存具有映射关系的数据。Map存储的是双列数据,存储key-value对的数据。Map中的**key用Set来存放,不允许重复**,即同一个Map对象所对应的类,须重写hashCode()和equals()方法。Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。
-
HashMap作为
Map的主要实现类:线程不安全,效率高,能存储null的key和value。-
Map结构的理解Map中的key:无序的、不可重复的,使用Set存储所有的key。Map中的value:无序的、可重复的,使用Collection存储所有的value。Map中的entry:key-value构成了一个Entry对象。无序的,不可重复的,使用Set存储所有的entry。
-
HashMap的底层实现原理-
jdk 7HashMap map = new HashMap(); // 实例化以后,底层创建了长度是16的一维数组Entry[] table map.put(key1, value1);- 首先,调用
key1所在类的hashCode()计算key1哈希值,此哈希值经过某种算法计算以后,得到在Entry数组中的存在位置。 - 如果此位置上的数据为空,此时的
key1-value添加成功。 - 如果此位置上的数据不为空,比较
key1和已经存在的一个或多个数据的哈希值。 - 如果
key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功。 - 如果
key1的哈希值和已经存在的某一个数据key2-value2的哈希值相同,继续比较,调用key1所在类类的equals(key2)方法。 - 如果
equals()返回false,此时key-value添加成功。 - 如果
equals()返回true,使用value1替换value2。
// HashMap的默认容量 static final int DEFAULT_INITIAL_CAPACITY = 16; // HashMap的默认加载因子 static final float DEFAULT_LOAD_FACTOR = 0.75f; // 扩容的临界值(容量 * 加载因子) final float loadFactor;// 空参构造器 public HashMap() {this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); } // 初始化数组 public HashMap(int initialCapacity, float loadFactor) {// 不执行此处3个ifif (initialCapacity < 0) // 最大容量是不是小于0throw new IllegalArgumentException("Illegal initial capacity: "+initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY) // 最大容量是不是超出范围initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor)) // 扩容临界值是不是小于0,或者没有初始化throw new IllegalArgumentException("Illegal load factor: " + loadFactor);int capacity = 1;// capacity循环完为16while (capacity < initialCapacity)capacity <<= 1;// this.loadFactor = 0.75this.loadFactor = loadFactor;// threshold = 12threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);// 初始化Entry数组的长度为16table = new Entry[capacity];useAltHashing = sun.misc.VM.isBooted() &&(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);init(); }// 添加数据方法 public V put(K key, V value) {// 判断key是否为nullif (key == null)return putForNullKey(value);// 获取key的哈希值int hash = hash(key);// 获取在table数组中存放的位置int i = indexFor(hash, table.length);// 看table数组位置上是否有数据for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;// 判断哈希值是否相等,如果相等判断equals是否为trueif (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(hash, key, value, i);return null; } // 判断table是否需要扩容,如果需要扩容,则长度扩容2倍 void addEntry(int hash, K key, V value, int bucketIndex) {if ((size >= threshold) && (null != table[bucketIndex])) {resize(2 * table.length);hash = (null != key) ? hash(key) : 0;bucketIndex = indexFor(hash, table.length);}createEntry(hash, key, value, bucketIndex); } // 把数据添加到HashMap中 void createEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<>(hash, key, value, e);size++; } - 首先,调用
-
jdk 8new HashMap():底层没有创建一个长度为16的数组。jdk 8底层的数组是:Node[],而非Entry[]。- 首次调用
put()方法时,底层创建长度为16的数组。 jdk 8中底层结构:数组+链表(七上八下)+红黑树。- 当数组中的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 < 64时,此时此索引位置上的数据改为使用红黑树存储。
static final float DEFAULT_LOAD_FACTOR = 0.75f; tatic final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // Bucket中链表长度大于该默认值,转为红黑树 static final int TREEIFY_THRESHOLD = 8; // 桶中的Node被数化时最小的hash表容量 static final int MIN_TREEIFY_CAPACITY = 64;// 空参构造器 public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; }// 添加数据方法 public V put(K key, V value) {return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;// 判断是否为第一次添加数据if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;// 判断添加数据在数组的位置是否为空if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;// 判断数组不为空的位置第一个元素与添加元素哈希值是否相等,如果相等判断equals是否为trueif (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode) // 判断数据是否为红黑树的方式存储e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {// 判断数组不为空的位置后面是否还有元素if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1)// 把链表变为红黑树存储treeifyBin(tab, hash);break;}// 判断数组不为空的位置里的元素与添加元素哈希值是否相等// 如果相等判断equals是否为trueif (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 看是否有元素的哈希值一样与equals方法也为trueif (e != null) {V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null; } // 第一次添加数据或者扩容 final Node<K,V>[] resize() {Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length;int oldThr = threshold;int newCap, newThr = 0;// 此if执行elseif (oldCap > 0) { .....} else if (oldThr > 0){ .....} else {// newCap = 16, newThr = 12newCap = DEFAULT_INITIAL_CAPACITY;newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);}// 此if不执行if (newThr == 0) { .... }// threshold = 12threshold = newThr;// 初始化table数组,长度为16@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];table = newTab;// 此if不执行if (oldTab != null) { ..... }return newTab; }final void treeifyBin(Node<K,V>[] tab, int hash) {int n, index; Node<K,V> e;// 链表长度大于8并且小于64if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)resize();else if ((e = tab[index = (n - 1) & hash]) != null) {TreeNode<K,V> hd = null, tl = null;do {TreeNode<K,V> p = replacementTreeNode(e, null);if (tl == null)hd = p;else {p.prev = tl;tl.next = p;}tl = p;} while ((e = e.next) != null);if ((tab[index] = hd) != null)hd.treeify(tab);} }
-
-
-
LinkedHashMap
LinkedHashMap是HashMap的子类。 保证在遍历
map元素时,可以按照添加的顺序实现遍历。在原有的HashMap底层结构基础上,添加了一对指针,指向前一个和后一个元素。对于频繁的遍历操作,此类执行效率高于HashMap。final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {if ((p = tab[i = (n - 1) & hash]) == null)// LinkedHashMap重写了newNode方法tab[i] = newNode(hash, key, value, null);else { ... } } // 重写的newNode方法 Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);linkNodeLast(p);return p; } // LinkedHashMap中的Entry static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);} } -
Map接口的常用方法Object put(Object key, Object value):将指定key-value添加到(或修改)当前map对象中。void putAll(Map m):将m中的所有key-value对存放到当前map中。Object remove(Object key):移除指定key的key-value对,并返回value。void clear():清空当前map中的所有数据。
Map map = new HashMap(); map.put("AA", 123); map.put(45, 123); map.put("BB", 56);map.put("AA", 87); System.out.println(map); // {AA=87, BB=56, 45=123}Map map1 = new HashMap(); map1.put("CC", 123); map.put("DD", 123); map.putAll(map1); System.out.println(map); // {AA=87, BB=56, DD=123, CC=123, 45=123}Object value = map.remove("CC"); System.out.println(value); // 123 System.out.println(map); // {AA=87, BB=56, DD=123, 45=123}map.clear(); System.out.println(map.size()); // 0 System.out.println(map); // {}Object get(Object key):获取指定key对应的value。boolean containsKey(Object key):是否包含指定的key。boolean containsValue(Object value):是否包含指定的value。int size():返回map中key-value对的个数。boolean isEmpty():判断当前map是否为空、boolean equals(Object obj):判断当前map和参数对象Object是否相等。
Map map = new HashMap(); map.put("AA", 123); map.put(45, 123); map.put("BB", 56); System.out.println(map.get(45)); // 123boolean isExist = map.containsKey("BB"); System.out.println(isExist); // trueisExist = map.containsValue(123); System.out.println(isExist); // truemap.clear(); System.out.println(map.isEmpty()); // trueSet keySet():返回所有key构成的Set集合。Collection values():返回所有value构成的Collection集合。Set entrySet():返回所有key-value对构成的Set集合。
Map map = new HashMap(); map.put("AA", 123); map.put(45, 1234); map.put("BB", 56);Set set = map.keySet(); Iterator iterator = set.iterator(); while(iterator.hasNext()) {System.out.print(iterator.next() + "\t"); // AA BB 45 } System.out.println();Collection values= map.values(); for(Object obj: values) {System.out.print(obj + "\t"); // 123 56 1234 } System.out.println();Set entrySet = map.entrySet(); Iterator iterator1 = entrySet.iterator(); while(iterator1.hasNext()) {Object obj = iterator1.next();Map.Entry entry = (Map.Entry) obj;System.out.print(entry.getKey() + "-" + entry.getValue() + "\t"); // AA-123 BB-56 45-1234 } System.out.println();Set keySet = map.keySet(); Iterator iterator2 = keySet.iterator(); while(iterator2.hasNext()) {Object key = iterator2.next();Object value = map.get(key);System.out.print(key + "=" + value + "\t"); // AA=123 BB=56 45=1234 } -
TreeMap-
保证按照添加的
key-value对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序。 -
TreeSet底层使用红黑树结构存储数据。‘ -
TreeMap的key必须实现Comparable或者Comparator接口。 -
TreeMap判断两个key相等的标准:两个key通过compareTo()方法或者compare()方法返回0。
-
-
PropertiesProperties的父类是Hashtable,是古老的实现类,线程安全的,效率低,不能存储null的key和value。Properties常用来处理配置文件。key和value都是String类型。Properties pros = new Properties(); pros.load(new FileInputStream("jdbc.properties")); String user = pros.getProperty("user"); System.out.println(user);
9.7:Collections工具类
Collections是一个操作Set、List、Map等集合的工具类。
-
排序操作
reverse(List):反转List中元素的顺序。shuffle(List):对List集合元素进行随机排序。sort(List):根据元素的自然顺序对指定List集合元素按升序排序。sort(List, Comparator):根据指定的Comparator产生的顺序对List集合元素进行排序。swap(List, int, int):将指定list集合中的i处元素和j处元素进行交换。
-
查找、替换
-
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素。 -
Object max(Collection, Comparator):根据Comparator指定的顺序,返回给定集合中的最大元素。 -
Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素。 -
Object min(Collection, Comparator):根据Comparator指定的顺序,返回给定集合中的最小元素。 -
int frequency(Collection, Object):返回指定集合中指定元素的出现次数。 -
void copy(List dest, List src):将src中的内容复制到dest中。注意:
dest的长度要大于等于src的长度,不然会报错。 -
boolean replaceAll(List list, Object oldVal, Object newVal):使用新值替换List对象的所有旧值。
Collections类中提供了多个synchronizedXxx()方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题。 -
-
EnumerationEnumeration接口是Iterator迭代器的"古老版本"。Enumeration stringEnum = new StringTokenizer("a-b*c-d-e-g", "-"); while(stringEnum.hasMoreElements()){Object obj = stringEnum.nextElement();System.out.print(obj + "\t"); // a b*c d e g }
相关文章:
第九章:Java集合
第九章:Java集合 9.1:Java集合框架概述 数组、集合都是对多个数据进行存储(内存层面,不涉及持久化)操作的结构,简称Java容器。 数组存储多个数据方面的特点 一旦初始化以后,其长度就确定了。数组一旦定义好ÿ…...

嵌入式学习笔记——STM32的USART通信概述
文章目录前言常用通信协议分类及其特征介绍通信协议通信协议分类1.同步异步通信2.全双工/半双工/单工3.现场总线/板级总线4. 串行/并行通信5. 有线通信、无线通信STM32通信协议的配置方式使用通信协议控制器实现使用IO口模拟的方式实现STM32串口通信概述什么是串口通信STM32F40…...
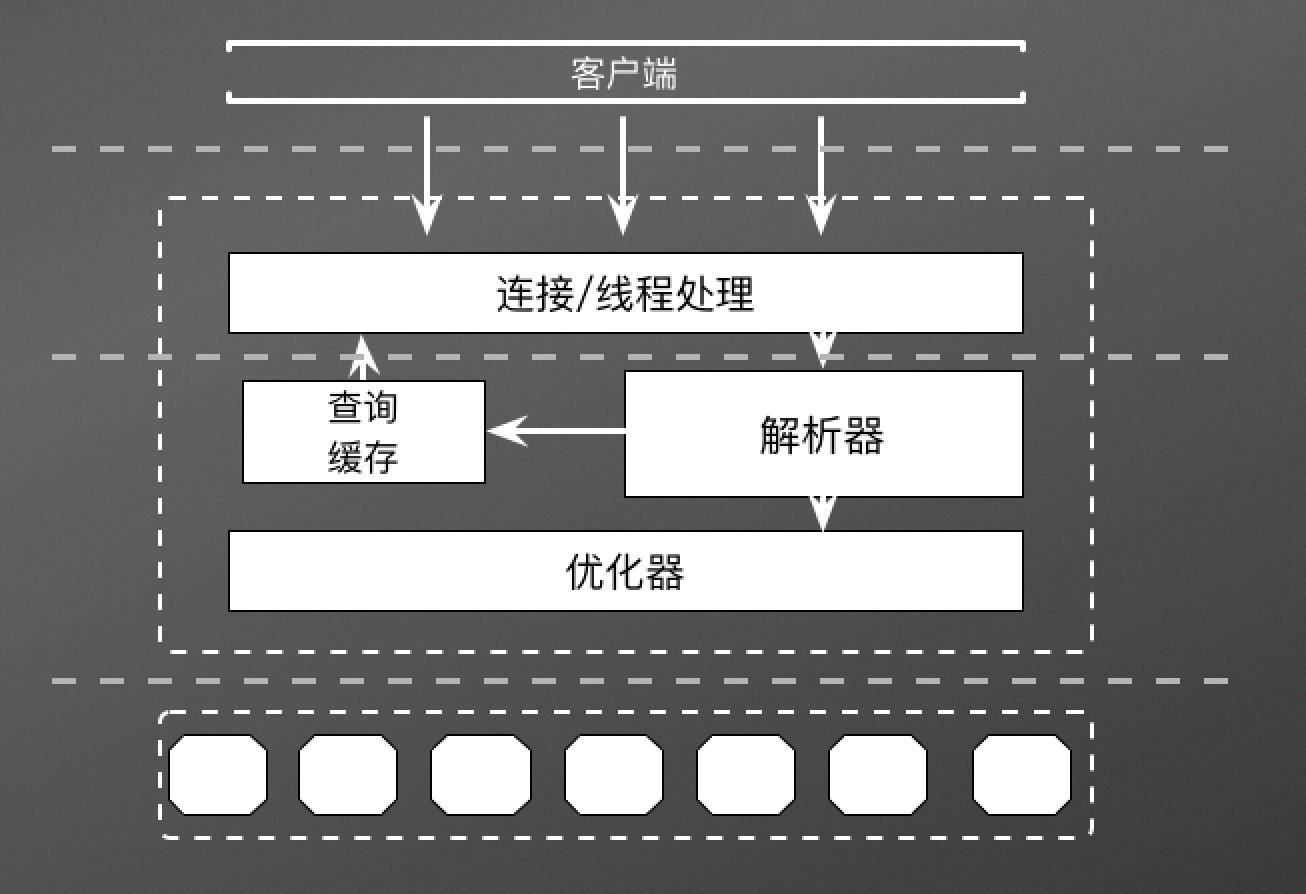
MySQL性能优化
MySQL性能调优 存储数据类型优化 尽量避免使用 NULL尽量使用可以的最小数据类型。但也要确保没有低估需要存储的范围整型比字符串操作代价更低使用 MySQL 内建的数据类型(比如date、time、datetime),比用字符串更快 基本数据类型 数字 整数…...

C语言/动态通讯录
本文使用了malloc、realloc、calloc等和内存开辟有关的函数。 文章目录 前言 二、头文件 三、主界面 四、通讯录功能函数 1.全代码 2.增加联系人 3.删除联系人 4.查找联系人 5.修改联系人 6.展示联系人 7.清空联系人 8.退出通讯录 总结 前言 为了使用通讯录时,可以…...

我用Compose做了一个地图轮子OmniMap
一、前言 半年前,我发布过一篇介绍:Compose里面如何使用地图,比如高德地图 的文章,原本是没有想造什么轮子的✍️ 闲来无事,有一天看到了评论区留言让我把源码地址分享出来,我感觉我太懒了,后来…...
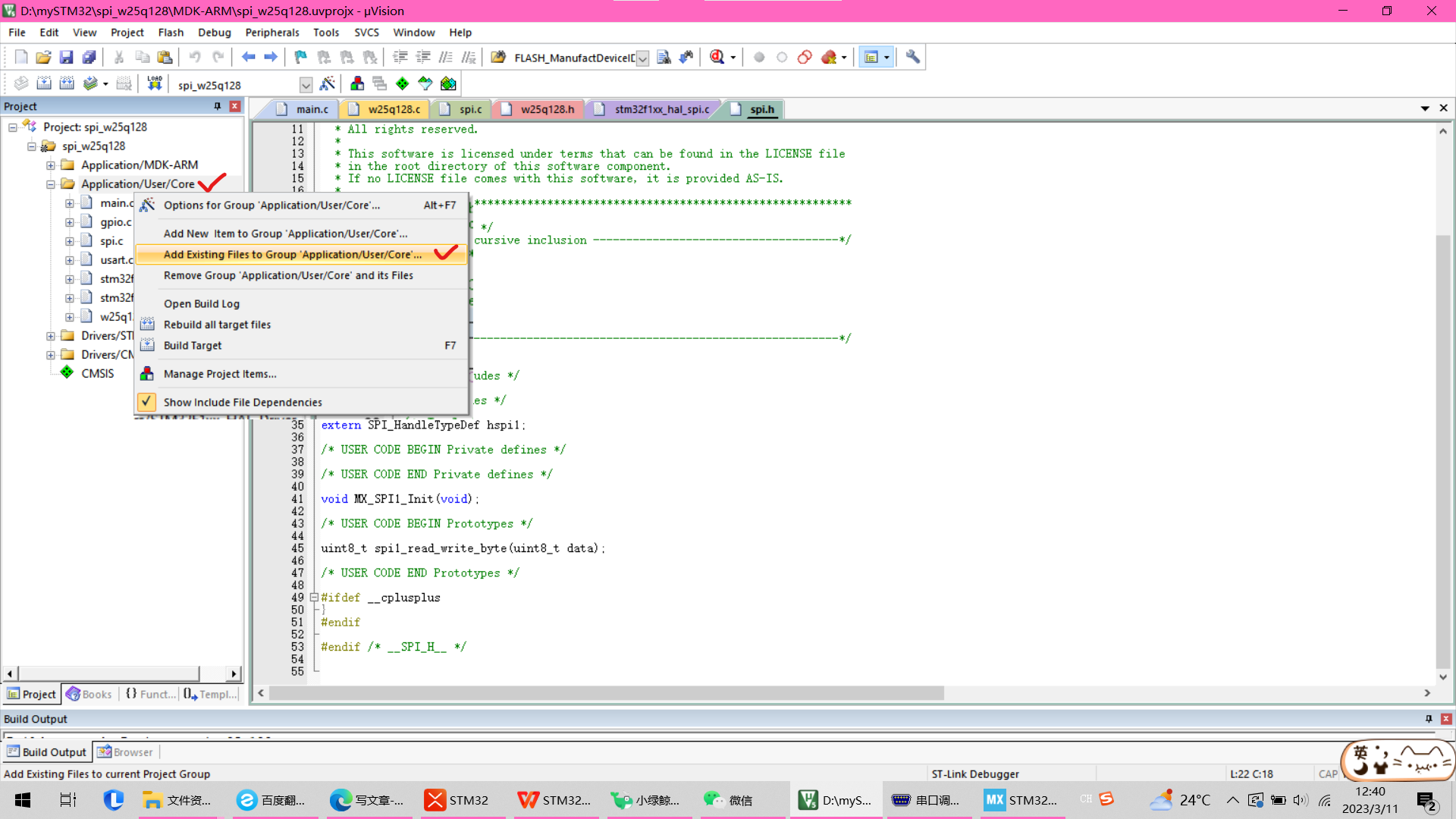
STM32之SPI
SPISPI介绍SPI是串行外设接口(Serial Peripherallnterface)的缩写,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同时为PCB的布局上节省空间,提供方便…...

02 深度学习环境搭建
1、查看对应版本关系 详细见:https://blog.csdn.net/qq_41946216/article/details/129476095?spm1001.2014.3001.5501此案例环境使用 CUDA 11.7、Pytouch1.12.1、Miniconda3_py38(含Python3.8) 2. 安装Anaconda 或 Miniconda 本案例重点一为Miniconda准 2.1 安…...
PHP导入大量CSV数据的方法分享
/** * @description 迭代器读取csv文件 * @param $strCsvPath * @return \Generator */ public static function readPathCsvFile($strCsvPath) { if ($handle = fopen($strCsvPath, r)) { while (!feof($handle)) { yield fgetcsv($handle); } …...

代码看不懂?ChatGPT 帮你解释,详细到爆!
偷个懒,用ChatGPT 帮我写段生物信息代码如果 ChatGPT 给出的的代码不太完善,如何请他一步步改好?网上看到一段代码,不知道是什么含义?输入 ChatGPT 帮我们解释下。生信宝典 1: 下面是一段 Linux 代码,请帮…...

【MyBatis】篇三.自定义映射resultMap和动态SQL
MyBatis整理 篇一.MyBatis环境搭建与增删改查 篇二.MyBatis查询与特殊SQL 篇三.自定义映射resultMap和动态SQL 篇四.MyBatis缓存和逆向工程 文章目录1、自定义映射P1:测试数据准备P2:字段和属性的映射关系P3:多对一的映射关系P4:一对多的映射关系2、动态SQL2.1 IF标签2.2 w…...
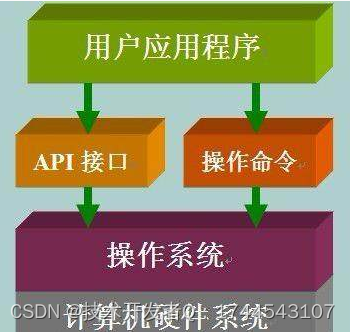
什么是API?(详细解说)
编程资料时经常会看到API这个名词,网上各种高大上的解释估计放倒了一批初学者。初学者看到下面这一段话可能就有点头痛了。 API(Application Programming Interface,应用程序编程接口)是一些预先定义的函数,目的是提供应用程序与开…...

比cat更好用的命令!
大家好,我是良许。 作为程序员,大家一定对 cat 这个命令不陌生。它主要的功能就是用来显示文本文件的具体内容。 但 cat 命令两个很重大的缺陷:1. 不能语法高亮输出;2. 文本太长的话无法翻页输出。正是这两个不足,使…...
MySQL、HBase、ElasticSearch三者对比
1、概念介绍 MySQL:关系型数据库,主要面向OLTP,支持事务,支持二级索引,支持sql,支持主从、Group Replication架构模型(本文全部以Innodb为例,不涉及别的存储引擎)。 HBas…...

Vue+ElementUI+Vuex购物车
最完整最能理解的Vuex版本的购物车购物车是最经典的小案例。Vuex代码:import Vue from vue import Vuex from vuex import $http from ../request/http Vue.use(Vuex)const store new Vuex.Store({state:{shopList:[],},mutations:{setShopCarList(state,payload)…...

Android 录屏 实现
https://lixiaogang03.github.io/2021/11/02/Android-%E5%BD%95%E5%B1%8F/ https://xie.infoq.cn/article/dd40cd5d753c896225063f696 视频地址: https://time.geekbang.org/dailylesson/detail/100056832 概述 在视频会议、线上课堂、游戏直播等场景下&#x…...

【CSAPP】家庭作业2.55~2.76
文章目录2.55*2.56*2.57*2.58**2.59**2.60**位级整数编码规则2.61**2.62***2.63***2.64*2.65****2.66***2.67**2.68**2.69***2.70**2.71*2.72**2.73**2.74**2.75***2.76*2.55* 问:在你能访问的不同的机器上,编译show_bytes.c并运行代码,确定…...

Python操作MySQL数据库详细案例
Python操作MySQL数据库详细案例一、前言二、数据准备三、建立数据库四、处理和上传数据五、下载数据六、完整项目数据和代码一、前言 本文通过案例讲解如何使用Python操作MySQL数据库。具体任务为:假设你已经了解MySQL和知识图谱标注工具Brat,将Brat标注…...
:AXI_CAN的使用)
MicroBlaze系列教程(8):AXI_CAN的使用
文章目录 @[toc]CAN总线概述AXI_CAN简介MicroBlaze硬件配置常用函数使用示例波形实测参考资料工程下载本文是Xilinx MicroBlaze系列教程的第8篇文章。 CAN总线概述 **CAN(Controller Area Network)**是 ISO 国际标准化的串行通信协议,是由德国博世(BOSCH)公司在20世纪80年代…...

网络安全领域中八大类CISP证书
CISP注册信息安全专业人员 注册信息安全专业人员(Certified Information Security Professional),是经中国信息安全产品测评认证中心实施的国家认证,对信息安全人员执业资质的认可。该证书是面向信息安全企业、信息安全咨询服务…...
stm32学习笔记-5EXIT外部中断
5 EXIT外部中断 [toc] 注:笔记主要参考B站 江科大自化协 教学视频“STM32入门教程-2023持续更新中”。 注:工程及代码文件放在了本人的Github仓库。 5.1 STM32中断系统 图5-1 中断及中断嵌套示意图 中断 是指在主程序运行过程中,出现了特定…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

CVE-2020-17519源码分析与漏洞复现(Flink 任意文件读取)
漏洞概览 漏洞名称:Apache Flink REST API 任意文件读取漏洞CVE编号:CVE-2020-17519CVSS评分:7.5影响版本:Apache Flink 1.11.0、1.11.1、1.11.2修复版本:≥ 1.11.3 或 ≥ 1.12.0漏洞类型:路径遍历&#x…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

Unity中的transform.up
2025年6月8日,周日下午 在Unity中,transform.up是Transform组件的一个属性,表示游戏对象在世界空间中的“上”方向(Y轴正方向),且会随对象旋转动态变化。以下是关键点解析: 基本定义 transfor…...