Python序列化和反序列化
一.序列化和反序列化
在Python中,序列化(Serialization)和反序列化(Deserialization)是处理对象数据的过程,主要用于对象的存储或网络传输。
序列化(Serialization)
序列化是将Python对象转换成一个字节流(或称为序列化后的表示)的过程,这个字节流可以被写入磁盘文件或通过网络发送。序列化使得对象的状态信息能够被保存,之后可以在需要的时候恢复对象。pickle.dump(obj, file, [,protocol]) 函数就是执行序列化的操作,各参数意义如下:
obj:要被序列化的Python对象。file:文件对象,表示序列化后的数据将被写入的文件或类文件对象(如BytesIO)。protocol(可选):指定序列化使用的协议版本,默认值是 pickle.HIGHEST_PROTOCOL,不同的协议影响了生成的字节流的兼容性和效率。
反序列化(Deserialization)
反序列化则是将之前序列化得到的字节流恢复成原来的Python对象的过程。这使得从磁盘文件读取或网络接收的数据能再次成为可操作的对象。对应的,pickle.load(file) 函数用于执行反序列化,参数意义如下:
file:文件对象,从该文件中读取之前序列化的数据并恢复成Python对象。
例子:
假设我们有一个简单的Python对象,我们可以通过以下步骤进行序列化和反序列化:
序列化示例:
import pickledata = {'name': 'Alice', 'age': 30}
with open('example.pickle', 'wb') as handle:pickle.dump(data, handle, protocol=pickle.HIGHEST_PROTOCOL)反序列化示例:
import picklewith open('example.pickle', 'rb') as handle:data_loaded = pickle.load(handle)
print(data_loaded) # 输出: {'name': 'Alice', 'age': 30}通过序列化和反序列化,我们可以轻松地存储复杂的数据结构或在网络间传递这些数据,这对于长期存储、数据交换或分布式计算等场景非常有用。但需要注意的是,pickle模块不是安全的,不应该用来序列化不可信的数据,因为它可以执行任意代码。
pickle序列化实例
下面是使用 pickle 进行序列化和反序列化的两个简单示例。
示例 1: 序列化与反序列化一个简单列表
序列化过程:
import pickle# 需要被序列化的简单Python对象 - 一个列表
my_list = [1, 'apple', 3.14]# 打开一个文件用于写入序列化后的数据
with open('example_pickle_list.pkl', 'wb') as handle:# 使用pickle的dumps或dump方法进行序列化# dump直接写入文件句柄,dumps则返回一个bytes对象pickle.dump(my_list, handle, protocol=pickle.HIGHEST_PROTOCOL)在此过程中,my_list 这个包含整数、字符串和浮点数的列表被转换成一个字节流,并存储到 example_pickle_list.pkl 文件中。
反序列化过程:
import pickle# 打开之前存储的文件以读取并反序列化数据
with open('example_pickle_list.pkl', 'rb') as handle:# 使用pickle的loads或load方法进行反序列化# load直接从文件句柄读取并还原对象,loads则从bytes对象还原loaded_list = pickle.load(handle)print(loaded_list) # 输出: [1, 'apple', 3.14]通过 pickle.load(),我们能够从二进制文件中恢复出原始的 Python 列表对象。
示例 2: 序列化与反序列化自定义类的对象
假设有一个简单的自定义类 Person:
class Person:def __init__(self, name, age):self.name = nameself.age = agedef __repr__(self):return f"Person(name='{self.name}', age={self.age})"序列化过程:
import pickle# 创建一个Person对象
person_instance = Person("Alice", 30)# 序列化Person对象到文件
with open('example_pickle_person.pkl', 'wb') as person_file:pickle.dump(person_instance, person_file, protocol=pickle.HIGHEST_PROTOCOL)反序列化过程:
import pickle# 反序列化解回Person对象
with open('example_pickle_person.pkl', 'rb') as person_file:loaded_person = pickle.load(person_file)print(loaded_person) # 输出: Person(name='Alice', age=30)在这个例子中,即使 Person 类是一个自定义类,pickle 也能够成功地序列化其实例,并在之后正确地反序列化回原始对象状态。
序列化之后的数据形式
使用 pickle 序列化数据后,原始的 Python 对象会被转换成一个二进制格式的字节流。这个字节流包含了对象的类型信息、属性及其值,以及可能的引用信息,以便能够完全重建原始对象。由于它是二进制格式,直接查看时不会像文本格式那样直观易读。
如果你尝试打印出 pickle.dumps() 方法处理后的结果,你会看到类似下面这样的输出,显示为字节序列:
b'\x80\x04\x95\x16\x00\x00\x00\x00\x00\x00\x00\x8c\x08__main__\x94\x8c\x06Person\x94\x93\x94)\x81\x94}\x94(\x8c\x04name\x94\x8c\x05Alice\x94\x8c\x03age\x94K\x1eub.' 这段二进制数据中包含了Python解释器如何重建对象的指令。每个字节或字节序列代表了特定的含义,比如对象类型、字符串长度、整数值等。例如,\x80\x04 是 pickle 协议版本的标识,\x95\x16 可能指示全局名称查找,\x8c 引入了一个字符串,后面跟着字符串长度和内容,\x94 表示结束,\x93 开始构建一个新对象,等等。
由于这些信息对人类来说难以直接解读,通常我们不会直接查看或编辑这些序列化后的数据,而是依赖 pickle.load() 或 pickle.loads() 来自动解析这些字节流,恢复成原始的 Python 对象。
二.序列化的实现原理
Python中的pickle模块实现序列化和反序列化的原理主要是通过对象的递归分析及构造。以下是其工作流程的基本概述:
序列化过程(dump)
-
检查对象类型:当
pickle.dump()被调用时,pickle首先检查要序列化的对象类型。Python的基本数据类型(如整数、浮点数、字符串等)有预定义的序列化方式。对于复杂类型(如列表、字典、自定义类的实例等),则需要更复杂的处理。 -
递归处理:对于复杂对象,
pickle会递归地进入对象的每个元素,对它们进行同样的检查和序列化过程。这意味着如果一个对象包含其他对象,这些内部对象也会被序列化。 -
生成二进制流:对于每种类型,
pickle使用一种特定的编码方案将其转换为一系列的字节。这个过程包括类型标识符、对象的属性或元素值等信息。例如,一个字典会被编码为它的键值对序列,每个键值对又进一步被序列化。 -
写入文件或字节流:最终的字节流按照指定的协议格式编码后,被写入到文件或其他输出流中。协议决定了如何编码类型信息和数据,不同的协议版本提供了向前或向后的兼容性。
反序列化过程(load)
-
读取二进制流:当使用
pickle.load()从文件或字节流读取时,首先读取并解析字节流中的类型标识符和数据。 -
重建对象:根据解析出的类型标识符,
pickle会创建相应的Python对象,并根据字节流中的数据填充对象的属性或内容。对于复杂对象,这一过程也是递归进行的,先创建容器对象,然后在其内部重建子对象。 -
处理引用:在序列化复杂数据结构时,如果对象之间存在循环引用或重复引用,
pickle会通过引用计数或ID映射来处理这些情况,确保反序列化后的对象结构与原始结构一致。 -
返回对象:一旦所有对象都被正确重建,
pickle.load()会返回最顶层的对象,即原始数据的完全复制品。
安全性考虑
虽然pickle功能强大,但由于它能够执行任意的Python代码(特别是在处理自定义类和其他可执行代码时),因此使用非可信来源的数据进行反序列化可能存在安全风险。因此,在处理外部输入的数据时,推荐使用更安全的序列化库,如json或yaml,或者确保有适当的安全措施来验证和清理数据。
三.为什么需要用到序列化
序列化在软件开发和系统设计中扮演着重要角色,主要有以下几个原因:
-
数据持久化:当程序运行时,内存中的数据是暂时的,程序关闭后数据就会丢失。序列化允许我们将这些数据转换为可以存储在磁盘上的格式,如文件,从而实现数据的持久保存。这样,即使程序重启或系统关闭,之前的状态和数据仍然可以恢复。
-
跨平台/进程通信:在分布式系统或多个程序之间交换数据时,序列化是必需的。通过将对象转换为通用的格式(如JSON、XML或二进制流),可以在不同语言编写的系统之间轻松共享数据,因为这些格式是跨平台理解的。
-
网络传输:在进行网络通信时,如通过HTTP请求或RPC(远程过程调用),数据需要被序列化成适合网络传输的格式。这不仅包括基本类型,还包括复杂对象结构,确保接收方能够准确无误地重建发送方的意图。
-
缓存和复制:序列化有助于实现数据缓存,比如将计算结果序列化后存储,以便下次直接使用而无需重新计算。同时,在分布式系统中,对象的序列化可以用来辅助数据复制,确保数据的一致性。
-
可移植性和兼容性:序列化使得应用程序状态或配置可以轻松地在不同环境之间迁移,无论是不同版本的同一程序,还是完全不同系统之间的数据交换,都提高了软件的灵活性和可维护性。
-
批处理和任务队列:在需要将任务分解并通过消息队列分发时,任务及其所需的数据常常需要被序列化,以便在队列中存储和传输,然后在另一个进程中反序列化并处理。
综上所述,序列化是现代软件开发中不可或缺的技术,它简化了数据存储、传输和交换的复杂性,增强了系统的灵活性和可靠性。
相关文章:

Python序列化和反序列化
一.序列化和反序列化 在Python中,序列化(Serialization)和反序列化(Deserialization)是处理对象数据的过程,主要用于对象的存储或网络传输。 序列化(Serialization) 序列化是将Pyth…...

Stream toArray 好过collect
toArray 比collect 更好用,这样就不需要判断Null。 if(_user.getUserRole()!null) {_user.setRole(_roleList.stream().filter(_e->_e.getRoleId()_user.getUserRole()).toArray(Role[]::new)[0]); } if(_user.getUserRole()!null) {_user.setRole(_roleList.s…...

qt/c++/mysql教务管理系统
简介 qt/c/mysql教务管理系统 学生端,教师端,管理员端 演示 qt/c/mysql教务管理系统 源码获取 printf("白嫖勿扰,需要的加v%s","ywj17347418171");...

Echarts公共方法
Vue引入Echarts install 1.安装Echartsnpm install echarts --save 2.项目全局引入形式--#main.js 全局引入形式import * as echarts from "echarts"Vue.prototype.$echarts echarts 公共方法JS /*** author: wangjie* description: 通用echarts图表封装* date: …...
)
鸿蒙学习(二)
文章目录 1、弹窗2、走马灯(实现轮播图效果)3、注解6、多选框、单选框7、Stack8、TextTimer9、DatePicker 1、弹窗 显示提示信息或者用于用户交互 导入模块 prompt 接口 showToast:显示toast showDialog:显示对话框 showContextMenu:显示上下文菜单 sh…...

企业机构营销目前106短信群发还有用吗?此文告诉你该如何抉择!
在当今竞争激烈的企业营销环境中,106短信群发平台依然是众多企业机构青睐的营销工具之一。尽管互联网技术的发展带来了多样化的沟通方式,但106短信群发凭借其直达性强、成本低廉、覆盖广泛等优势,仍然保持着不错的营销效果。然而,…...

DJYGUI AI低代码图形编程开发平台:开启嵌入式软件图形编程新纪元
在科技高速发展的当今时代,软件开发行业对创新和高效的需求日益增长。DJYGUI AI低代码图形编程开发平台的出现,为智能屏、物联屏、串口屏等嵌入式显示设备领域带来了全新的机遇。该平台由都江堰操作系统 AI 代码自动生成平台研发,具有显著的优…...
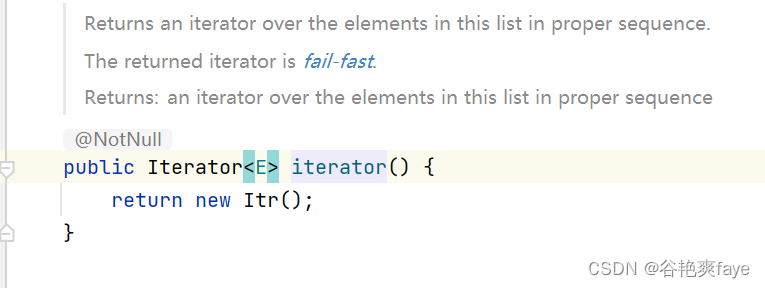
为什么不能在foreach中删除元素
文章目录 快速失败机制(fail-fast)for-each删除元素为什么报错原因分析逻辑分析 如何正确的删除元素remove 后 breakfor 循环使用 Iterator 总结 快速失败机制(fail-fast) In systems design, a fail-fast system is one which i…...

python学习-tuple及str
为什么需要元组 定义元组 元组的相关操作 元组的相关操作 - 注意事项 元组的特点 字符串 字符串的下标(索引) 同元组一样,字符串是一个:无法修改的数据容器。 如果必须要修改字符串,只能得到一个新的字符串ÿ…...
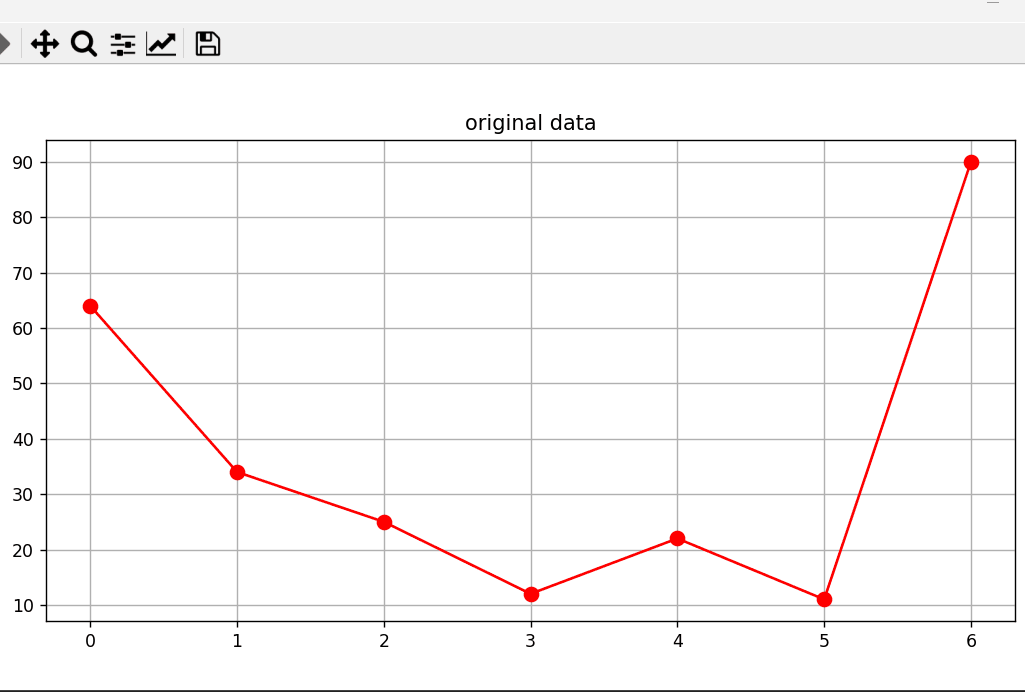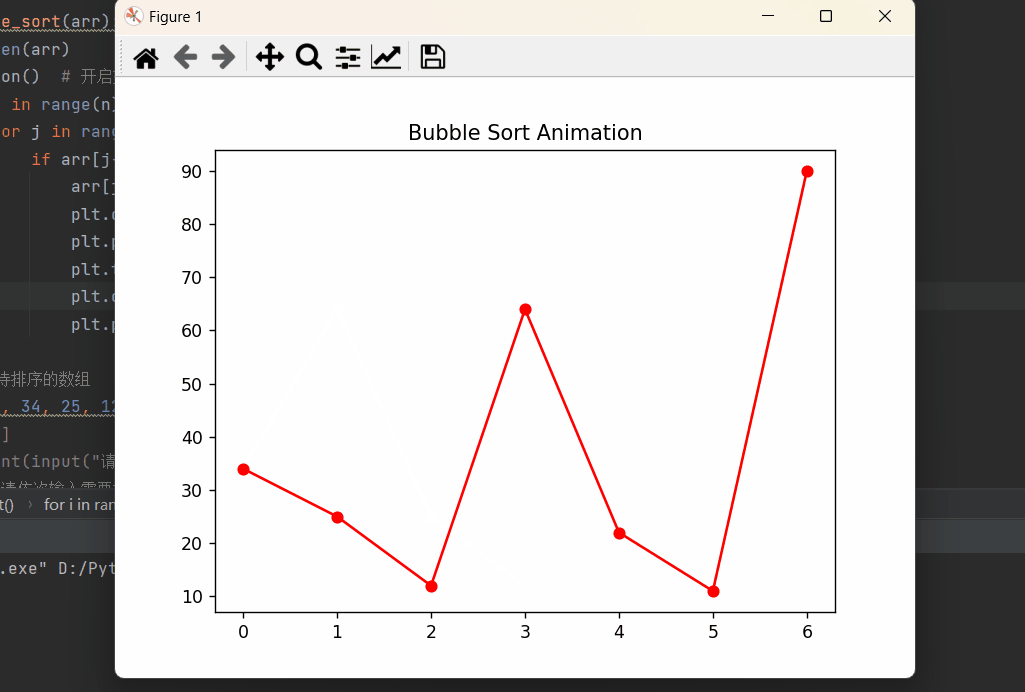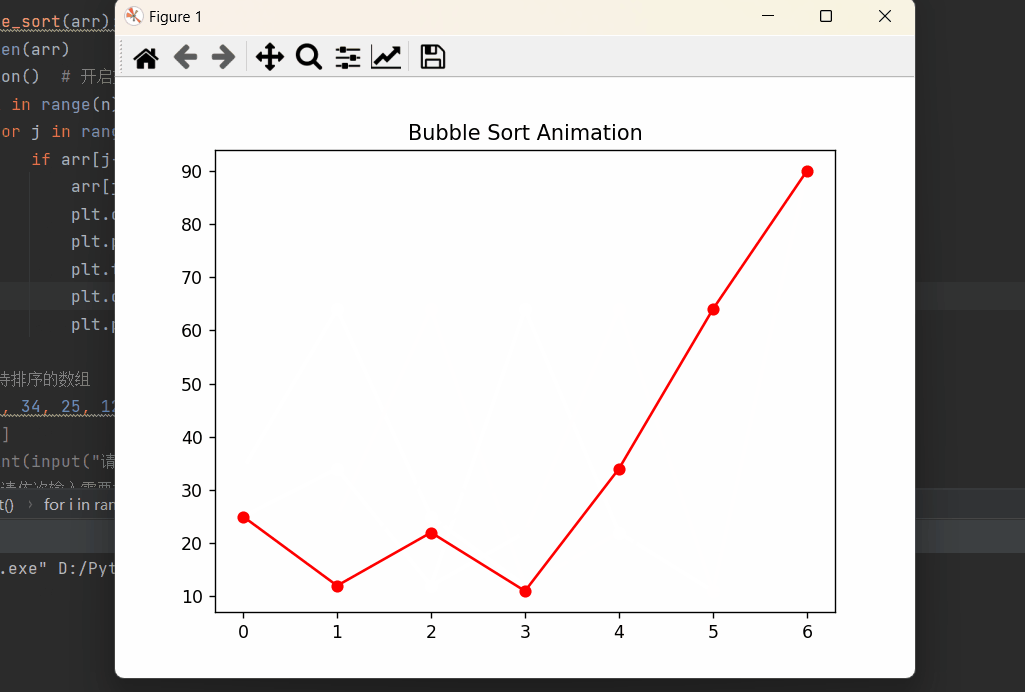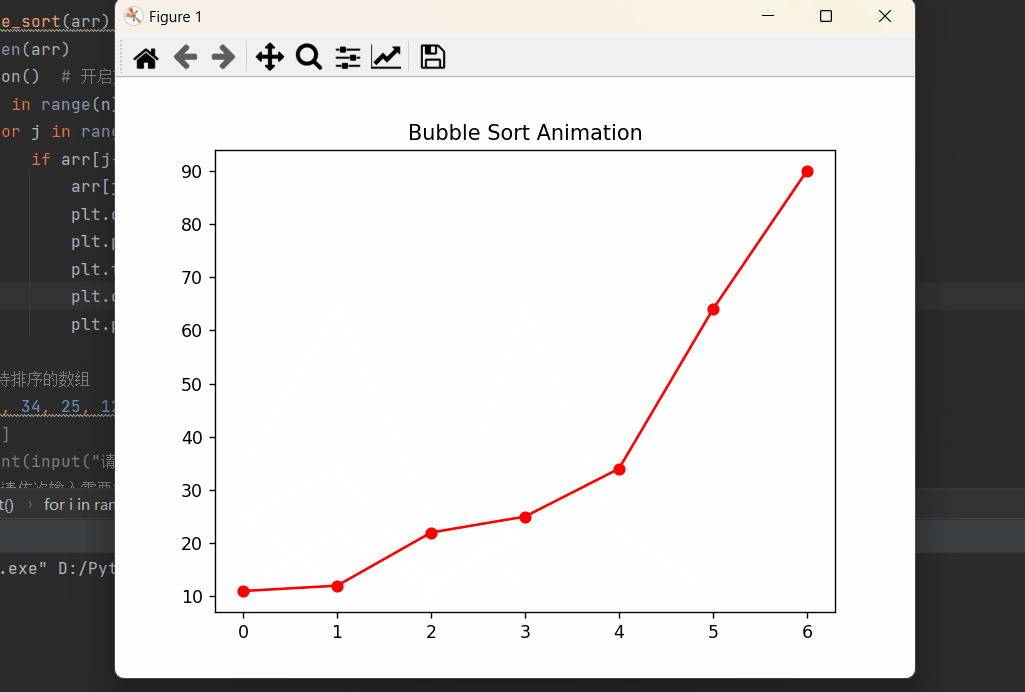
Python深度理解系列之【排序算法——冒泡排序】
读者大大们好呀!!!☀️☀️☀️ 👀期待大大的关注哦❗️❗️❗️ 🚀欢迎收看我的主页文章➡️木道寻的主页 文章目录 🔥前言🚀冒泡排序python实现算法实现图形化算法展示 ⭐️⭐️⭐️总结 🔥前…...

边界框在目标检测中的作用与应用
目标检测是计算机视觉领域的核心任务之一,旨在从图像或视频中识别和定位感兴趣的目标。边界框(Bounding Box)是目标检测中常用的一种表示方法,用于确定目标在图像中的确切位置。本文将详细探讨边界框的概念、它在目标检测中的角色…...

linux 环境报错:Peer reports incompatible or unsupported protocol version
出现问题的原因: curl 不兼容或不支持的协议版本。 解决方案: yum update -y nss curl libcurl如此继续之前的操作即可。...

深入解析:Java爬虫的本质是什么?
深入解析:Java爬虫的本质是什么? 引言: 随着互联网的快速发展,获取网络数据已成为许多应用场景中的重要需求。而爬虫作为一种自动化程序,能够模拟人类浏览器的行为,从网页中提取所需信息,成为了…...

【Matlab 六自由度机器人】机器人动力学之推导拉格朗日方程(附MATLAB机器人动力学拉格朗日方程推导代码)
【Matlab 六自由度机器人】机器人动力学概述 近期更新前言正文一、拉格朗日方程的推导1. 单自由度系统2. 单连杆机械臂系统3. 双连杆机械臂系统 二、MATLAB实例推导1. 机器人模型的建立2. 动力学代码 总结参考文献 近期更新 【汇总】 【Matlab 六自由度机器人】系列文章汇总 …...
线下生鲜蔬果店做小程序有什么方法
生鲜蔬果是生活所需,大小商家众多,零售批发各种经营模式,小摊贩或是超市门店都有着目标客户或准属性群体。竞争和获客转化也促进着商家寻找客源和加快线上进程。 尤其是以微信社交为主的私域场景,普客/会员都需要精细化管理营收和…...

几种linux开机自启脚本的方法
几种linux开机自启脚本的方法 1. 脚本添加到init.d目录中2. 创建服务service(推荐)3. /etc/profile & /etc/profile.d(不推荐)4. /etc/rc.local 本文以启动jenkins节点为例,需要持久连接,实现开机自启 …...
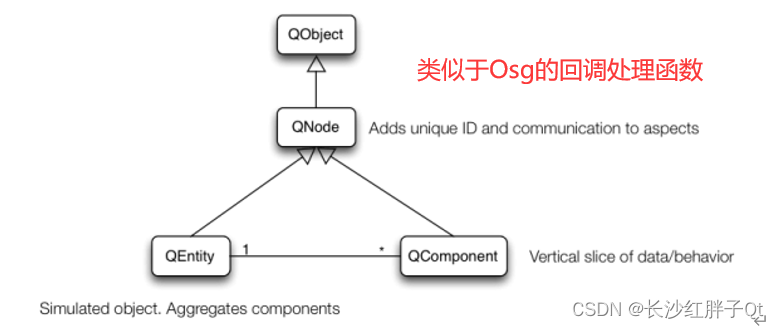
Qt开发笔记:Qt3D三维开发笔记(一):Qt3D三维开发基础概念介绍
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://blog.csdn.net/qq21497936/article/details/140059315 长沙红胖子Qt(长沙创微智科)博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、O…...
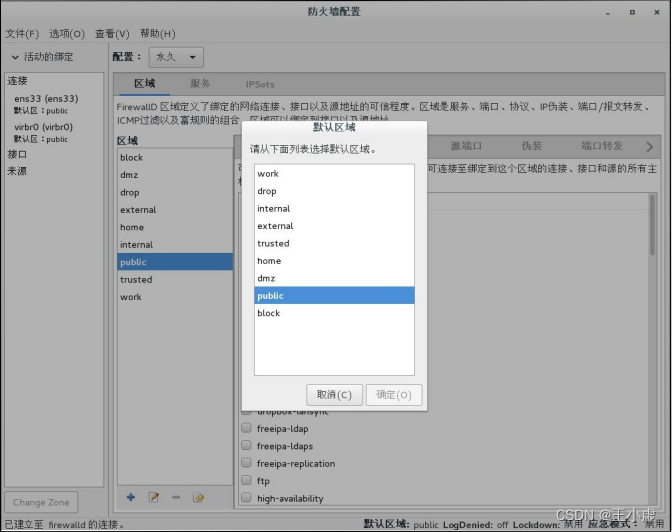
Firewalld 防火墙基础
Firewalld 防火墙基础 一、Firewalld概述firewalld 简介firewalld 和 iptables 的关系firewalld 与 iptables service 的区别 二、Firewalld 网络区域区域介绍Firewalld数据处理流程 三、Firewalld 防火墙的配置方法firewall-config 图形工具“区域”选项卡“服务”选项卡改变防…...
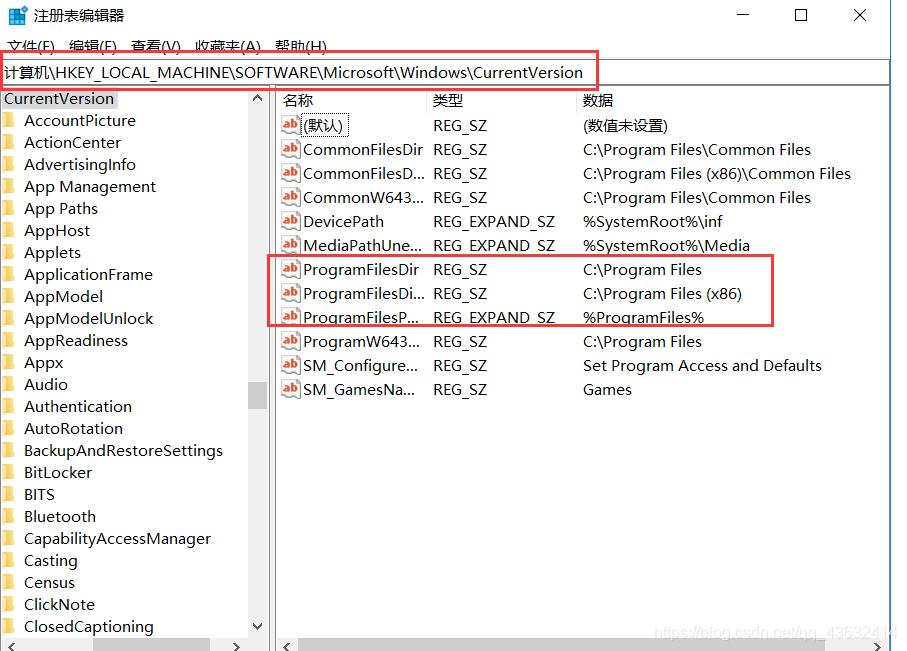
针对 Windows 10 的功能更新,版本 22H2 - 错误 0xc1900204
最近想帮女朋友生win11发现她电脑安装更新总是卡到安装%10这里失败 原来是安装路径被修改过了,改回c盘 win R → 输入regedit 计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion...
goframe框架规范限制(but it should be named with “Res“ suffix like “XxxRes“)
背景: 首页公司最近要启动一个项目,公司主要业务是用java开发的,但是目前这个方向的项目,公司要求部署在主机上,就是普通的一台电脑上,电脑配置不详,还有经常开关机,所以用java面临…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

SkyWalking 10.2.0 SWCK 配置过程
SkyWalking 10.2.0 & SWCK 配置过程 skywalking oap-server & ui 使用Docker安装在K8S集群以外,K8S集群中的微服务使用initContainer按命名空间将skywalking-java-agent注入到业务容器中。 SWCK有整套的解决方案,全安装在K8S群集中。 具体可参…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...
)
安卓基础(aar)
重新设置java21的环境,临时设置 $env:JAVA_HOME "D:\Android Studio\jbr" 查看当前环境变量 JAVA_HOME 的值 echo $env:JAVA_HOME 构建ARR文件 ./gradlew :private-lib:assembleRelease 目录是这样的: MyApp/ ├── app/ …...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...
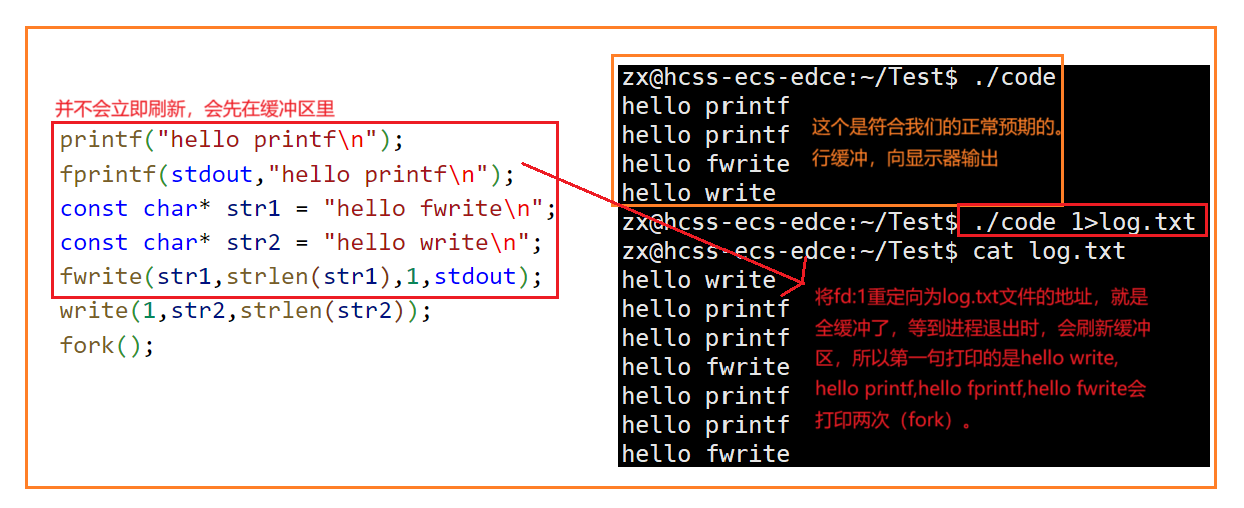
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...
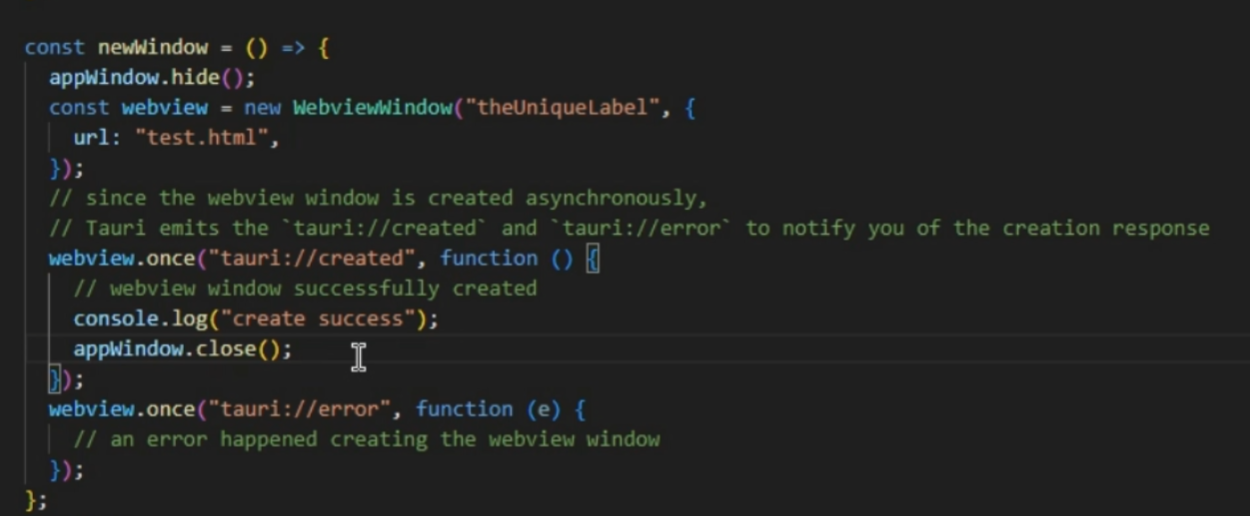
Tauri2学习笔记
教程地址:https://www.bilibili.com/video/BV1Ca411N7mF?spm_id_from333.788.player.switch&vd_source707ec8983cc32e6e065d5496a7f79ee6 官方指引:https://tauri.app/zh-cn/start/ 目前Tauri2的教程视频不多,我按照Tauri1的教程来学习&…...