数据存储方案选择:ES、HBase、Redis、MySQL与MongoDB的应用场景分析
一、概述
1.1 背景
在当今数据驱动的时代,选择合适的数据存储技术对于构建高效、可靠的信息系统至关重要。随着数据量的爆炸式增长和处理需求的多样化,市场上涌现出了各种数据存储解决方案,每种技术都有其独特的优势和适用场景。Elasticsearch (ES)、HBase、Redis、MySQL和MongoDB是当前最流行和广泛使用的数据存储技术之一。它们分别代表了不同类型的数据管理系统:从关系型数据库到NoSQL数据库,从文本搜索引擎到键值存储系统。这些技术的选择和应用直接影响到数据的存储效率、访问速度、扩展性和系统的整体性能。因此,深入理解这些技术的特点及其最佳应用场景,对于设计和实施高性能的数据管理解决方案至关重要。本文旨在探讨ES、HBase、Redis、MySQL和MongoDB这五种技术的核心特性和优势,通过分析它们在不同应用场景下的表现,为技术选型提供指导和建议。
1.2 多样化的数据存储技术
尽管DB-Engines数据库排名不能直接体现数据库的安装数量,但当某个数据库在特定时间内变得越来越受欢迎时,其在排名中的位置通常能反映出它在更广泛范围内的使用情况。以下是2024年5月份的DB-Engines数据库排名列表。
二、数据存储选型核心要素
- 实际业务场景:这是最重要的因素之一,一定要了解业务需求,识别业务场景的特点。如业务类型(在线或离线)、数据冷热程度、数据读写的特点以及数据的增长方式等场景。如果在选择存储方案时没有充分考虑这些场景特点,可能会导致无法满足业务需求、存储成本急剧上升等问题,并可能需要付出高昂代价来进行不停机的数据迁移和代码重构。
- 数据规模:数据规模是另一个关键因素。如果您的数据量很小,那么选择一个轻量级的数据库可能就足够了。但是,如果您的数据量非常大,那么您可能需要选择一个能够处理大数据的数据库,比如Hadoop。
- 性能:这也是非常重要的因素之一。需要评估中间件的读写速度、吞吐量以及响应时间等性能指标,确保其能够满足您的业务需求。
- 可扩展性:随着业务的增长,您可能需要增加更多的服务器来处理更大的数据量和更高的并发请求。因此,选择具有良好水平扩展性和垂直扩展性的中间件非常重要。
- 成本效益:总体拥有成本(TCO)是另一个关键考虑因素。您需要评估硬件、软件许可证、维护和支持费用等因素,并确保所选中间件能够提供良好的性价比。
- 技术掌控度:团队对某种特定技术的熟悉程度也是选择中间件的重要因素。盲目使用不熟悉的存储技术可能会导致资源浪费或线上故障(如Redis大KEY问题或HBase的热点访问)。如果团队已经熟悉某种技术,那么使用这种技术可能会更加高效,并且可以避免一些潜在的问题。
- 查询复杂度:如果您的应用程序需要复杂的查询操作,那么选择一个具有强大查询功能的数据库可能是更好的选择。
还有一些其他因素,如可靠性、安全性、备份和恢复策略等。不讲业务场景、不考虑数据规模的选型都是耍流氓,在实际应用中,需要综合考虑这些因素,并根据具体的业务场景进行权衡。
三、常见数据库选型
选择合适的数据库需基于需求和应用场景,了解不同数据库类型的优缺点及最佳实践是关键。以下是一些常见的数据库类型及其适用场景。
3.1 关系数据库
以MySQL为代表的关系型数据库。常用于在线业务(OLTP)场景,对于强事务有较好支持。

优点:
- 容易理解,大家基本上都用得比较熟
- 事务特性
- 配套成熟(备份恢复、数据订阅、数据同步等)
- 服务极度稳定
缺点:
- 不易水平扩展
- 大表表结构变更复杂
- schema扩展很不方便
- 全文检索能力弱
- 复杂分析、统计能力弱
最佳实践:
- 索引设计
- 避免n+1轮询
- 避免深分页
- 单表千万数据量级考虑分库分表
- 冷热数据要归档
- 不直接处理统计、分析型操作
应用场景:
- 适用于大多数中小型项目
- 后台管理型系统:如运营系统,数据量少,并发量小,首选关系型数据库
3.2 K-V存储
K-V存储的全称是Key-Value存储,其中Key是数据的标识,类似关系数据库中的主键,Value就是具体的数据。K-V存储是以键值对形式存储的非关系型数据库,是最简单、最容易理解也是大家最熟悉的一种NoSql。
Redis是其中的代表,典型用于缓存场景。

优点:
- 数据基于内存,读写效率高
- KV型数据,时间复杂度为O(1),查询速度快
缺点:
- 查询方式单一
- 内存有限,且非常昂贵
- 由于存储是基于内存的,会有丢失数据的风险(有持久化存储方案)
最佳实践:
- 合理控制kv大小,避免大key
- 避免热点key
- 设置合理的TTL
- 注意缓存雪崩、穿透、击穿问题
- 不要用于消息队列,异常情况无法堆积消息
- 不要将redis作为数据库使用,可能会丢数据
应用场景:
- 缓存:Redis可以将热点数据存储在内存中,提高服务的访问速度。
- 实时统计:Redis 支持高效的计数器和集合操作,可以用于实现实时统计功能。
- 分布式锁:用于多个节点之间的协调。
- 会话存储:存储web会话信息。
- 排行榜:Redis 的有序集合可以用于实现排行榜功能。
3.3 列式数据库
一般用于海量数据存储、不需要复杂查询的场景。
HBase是代表产品。

优点:
- 动态列调整,不受表结构困扰
- 海量数据存储,PB 级别数据
- 横向扩展方便,且支持廉价存储扩展,成本低,适用于无法预估存储量的海量数据
缺点:
- Hadoop生态产品,组件依赖多,没有云托管产品,运维能力要求比较高
- Rowkey设计需要一定经验,避免热点
- 只支持行级事务
最佳实践:
- 适用于行数多,但单个kv数据量小(1M以下)
- 特别注意Rowkey设计,避免热点。
- 大value(10M以上)禁止存入HBase,考虑对象存储
- 表创建时必须预分区
- 表的列族数量不得超过 2 个
应用场景:
- 海量数据存储:与Hadoop结合,适用于PB级别的数据。
- 时间序列数据:适用于存储与时间有关的数据。
- 内容管理系统和归档系统:适用于大量数据和高写入吞吐量。
- 实时随机读取:提供对大数据集的快速随机读取。
3.4 搜索引擎
搜索型NoSql顾名思义主要是用在搜索场景下的。传统的关系型数据库通过索引来达到快速查询的目的,但是在全文搜索的业务场景下,索引也无能为力,搜索型NoSql正是为了补足这个场景诞生的。
ElasticSearch是其中的代表产品。

优点:
- 支持分词场景、全文搜索,这是区别于关系型数据库最大特点
- 支持条件查询,支持聚合操作,适合数据分析
- 在集群环境下可以方便横向扩展,可承载PB级别的数据
缺点:
- 低延迟,写入数据一般不能立马查询到(可以设置实时,但ES性能下降10倍)
- 硬件性能要求高
- 并发查询不足
最佳实践:
- 核心在线应用强依赖ES需要考虑可行的降级方案
- 禁止使用单索引多type
- ES成本较高,因此建议仅数据库加速、全文检索情况下使用es
- ES中仅存储索引字段,通过id回查数据库,不要全量数据存储ES
- 根据节点数量设置合理的分片数量、分片大小
- ES的JVM垃圾收集器适合G1
应用场景:
- 全文搜索:提供高速、高可用的搜索功能,如网站搜索、企业内部搜索等。
- 复杂查询:可以快速响应大规模数据的复杂搜索请求。
- 日志数据分析:常与Logstash和Kibana一同使用,组成ELK堆栈,帮助企业监控和优化业务。
- 应用性能监控:Elasticsearch可以用于监控系统,收集和分析各种指标数据,以便实时了解系统状态。
3.5 文档数据库
文档型 NoSql 指的是将半结构化数据存储为文档的一种 NoSql,通常以 JSON 或者 XML 格式存储数据。
MongoDB是其中的代表产品。

优点:
- 没有预定义的字段,扩展字段容易
- 相较于关系型数据库,读写性能优越
- 分片集群易水平扩展
缺点:
- 文档结构过于灵活,可能导致不易维护
- 客户端控制力强,对开发、优化上有一定要求
最佳实践:
- 选择合理的片键
- 建立合适的索引
- 正确使用写关注设置(Write Concern)
- 正确使用读选项设置(Read Preference)
- 正确使用更新语句(局部更新、防止大量更新集中在一条数据内)
应用场景:
- 灵活的模式设计:适用于需要快速迭代和变化的数据模型。
- 地理空间数据:提供内置的地理空间索引和查询功能。
3.6 几种数据库对比小结
| 支持情况 | Redis | MySQL | Elasticsearch | HBase | MongoDB |
| 数据规模 | 低 | 中 | 较大 | 海量 | 较大 |
| 查询性能 | 极高 | 低 | 低 | 低 | 中 |
| 写入速度 | 极快 | 低 | 低 | 较快 | 中 |
| 复杂查询 | 较差 | 好 | 极好 | 较差 | 好 |
| 事务 | 弱 | 强 | 弱 | 弱 | 弱 |
四、一些场景和方案参考
上述列出了常见数据库的优缺点,下面结合不同场景做一下常规选型方案参考。
4.1 主要场景和方案
互联网业务的主要场景,是采用mysql进行数据存储。为了扛住高并发场景,缓存也不可缺失。因此,最主要的方案就是 MySQL + Redis。
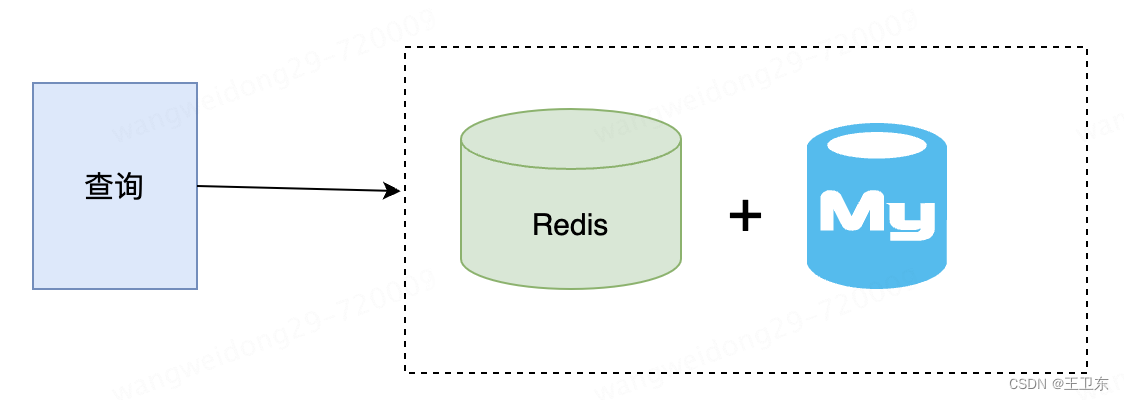
适用于主要场景:
- MySQL满足事务性要求
- Redis抗热点
五、总结
在业务开发中,选择合适的数据库存储方案至关重要,因为不同的数据库技术具有各自的优势和局限。为了提高业务开发效率并降低使用成本,我们应该根据具体的业务需求来选择最合适的数据库存储方案。对于复杂业务场景,采用混合存储策略,结合多种数据库的优势,以实现更高效的存储和管理。
除了Elasticsearch、HBase、Redis、MySQL和MongoDB等广泛使用的技术外,市场上还存在许多专为特定场景设计的优秀数据库,如ClickHouse、Doris、TiDB、Hive、Neo4j、OceanBase,其中Doris和ClickHouse在在线分析处理(OLAP)领域展现出卓越性能;TiDB则在处理需要高度一致性的在线事务处理(OLTP)和在线分析处理(OLAP)的场景中表现优异;而Neo4j作为图数据库,在处理复杂的关系和网络分析方面无与伦比。随着技术的不断进步和业务需求的日益复杂,未来可能还会有更多专为特定场景设计的数据库技术问世。企业和开发者需要不断学习和适应这些新技术,以确保能够充分利用数据的潜力,推动业务的持续创新和发展。

相关文章:
数据存储方案选择:ES、HBase、Redis、MySQL与MongoDB的应用场景分析
一、概述 1.1 背景 在当今数据驱动的时代,选择合适的数据存储技术对于构建高效、可靠的信息系统至关重要。随着数据量的爆炸式增长和处理需求的多样化,市场上涌现出了各种数据存储解决方案,每种技术都有其独特的优势和适用场景。Elasticsear…...

数组理论基础
1. **数组定义**: - 数组是存放在连续内存空间上的相同类型数据的集合。 2. **数组特性**: - 数组下标从0开始。 - 数组的内存空间地址是连续的。 3. **数组操作**: - 数组可以通过下标索引快速访问元素。 - 数组元素的删除…...

FlinkCDC 数据同步优化及常见问题排查
【面试系列】Swift 高频面试题及详细解答 欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏: 欢迎关注微信公众号:野老杂谈 ⭐️ 全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、…...

手把手edusrc漏洞挖掘和github信息收集
0x1 前言 这里主要还是介绍下新手入门edusrc漏洞挖掘以及在漏洞挖掘的过程中信息收集的部分哈!(主要给小白看的,大佬就当看个热闹了)下面的话我将以好几个不同的方式来给大家介绍下edusrc入门的漏洞挖掘手法以及利用github信息收…...
linux系统中的各种命令的解释和帮助(含内部命令、外部命令)
目录 一、说明 二、命令详解 1、帮助命令的种类 (1)help用法 (2)--help用法 2、如何区别linux内部命令和外部命令 三、help和—help 四、man 命令 1、概述 2、语法和命令格式 (1)man命令的格式&…...

Gemma轻量级开放模型在个人PC上释放强大性能,让每个桌面秒变AI工作站
Google DeepMind团队最近推出了Gemma,这是一个基于其先前Gemini模型研究和技术的开放模型家族。这些模型专为语言理解、推理和安全性而设计,具有轻量级和高性能的特点。 Gemma 7B模型在不同能力领域的语言理解和生成性能,与同样规模的开放模型…...
Git使用中遇到的问题(随时更新)
问题1.先创建本地库,后拉取远程仓库时上传失败的问题怎么解决? 操作主要步骤: step1 设置远程仓库地址: $ git remote add origin gitgitee.com:yourAccount/reponamexxx.git step2 推送到远程仓库: $ git push -u origin "master&qu…...

php 跨域问题
设置header <?php $origin isset($_SERVER[HTTP_ORIGIN])? $_SERVER[HTTP_ORIGIN]:;$allow_originarray(http://www.aaa.com,http://www.bbb.com, ); if( $origin in $allow_origin ){header("Access-Control-Allow-Origin:".$origin);header("Access-Co…...

【leetcode52-55图论、56-63回溯】
图论 回溯...
2024 年江西省研究生数学建模竞赛题目 A题交通信号灯管理---完整文章分享(仅供学习)
问题: 交通信号灯是指挥车辆通行的重要标志,由红灯、绿灯、黄灯组成。红灯停、绿灯行,而黄灯则起到警示作用。交通信号灯分为机动车信号灯、非机动车信号灯、人行横道信号 灯、方向指示灯等。一般情况下,十字路口有东西向和南北向…...
日志可视化监控体系ElasticStack 8.X版本全链路实战
目录 一、SpringBoot3.X整合logback配置1.1 log4j、logback、self4j 之间关系 1.2 SpringBoot3.X整合logback配置 二、日志可视化分析ElasticStack 2.1为什么要有Elastic Stack 2.2 什么是Elastic Stack 三、ElasticSearch8.X源码部署 四、Kibana源码部署 五、LogSta…...

【LinuxC语言】定义线程池结果
文章目录 前言任务结构体线程池定义总结前言 在并发编程中,线程池是一种非常重要的设计模式。线程池可以有效地管理和控制线程的数量,避免线程频繁创建和销毁带来的性能开销,提高系统的响应速度。在Linux环境下,我们可以使用C语言来实现一个简单的线程池。 线程池的主要组…...

uniapp分包
分包是为了优化小程序的下载和启动速度 小程序启动默认下载主包并启动页面,当用户进入分包时,才会下载对应的分包,下载完进行展示。 /* 在manifest.json配置下添加optimization,开启分包优化 */ "mp-weixin" : {/**分包…...
Python 生成Md文件带超链 和 PDF文件 带分页显示内容
software.md # -*- coding: utf-8 -*- import os f open("software.md", "w", encoding"utf-8") f.write(内部测试版2024 MD版\n) for root, dirs, files in os.walk(path): dax os.path.basename(root)if dax "":print("空白…...

行业模板|DataEase旅游行业大屏模板推荐
DataEase开源数据可视化分析工具于2022年6月发布模板市场(https://templates-de.fit2cloud.com),并于2024年1月新增适用于DataEase v2版本的模板分类。模板市场旨在为DataEase用户提供专业、美观、拿来即用的大屏模板,方便用户根据…...

this.$refs[tab.$attrs.id].scrollIntoView is not a function
打印this.$refs[tab.$attrs.id].scrollIntoView 在控制台看到的是一个undefined 是因为this.$refs[tab.$attrs.id] 不是一个dom 是一个vuecomponent 如图所示: 所以我用的这个document.querySelector(.${tab.$attrs.id})获取dom document.querySelector(.${tab.$attrs.id})…...

【AI是在帮助开发者还是取代他们?】AI与开发者:合作与创新的未来
目录 前言一、AI工具现状(一)GitHub Copilot(二)TabNine 二、AI对开发者的影响(一)影响和优势(二)新技能和适应策略(三)保持竞争力的策略 三、AI开发的未来&a…...
【SpringBoot Web框架实战教程(开源)】01 使用 pom 方式创建 SpringBoot 第一个项目
导读 这是一系列关于 SpringBoot Web框架实战 的教程,从项目的创建,到一个完整的 web 框架(包括异常处理、拦截器、context 上下文等);从0开始,到一个可以直接运用在生产环境中的web框架。而且所有源码均开…...

Boosting【文献精读、翻译】
Boosting Bhlmann, P., & Yu, B. (2009). Boosting. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1), 69–74. doi:10.1002/wics.55 摘要 在本文中,我们回顾了Boost方法,这是分类和回归中最有效的机器学习方法之一。虽然我们也讨…...

保姆级教程|如何配置ROS1主从机
在机器人开发经常遇到使用两个板子通信问题,比如一个板子跑底层的运动控制,一个板子跑定位导航。为了确保两个板子之间的ROS通信流畅,我们需要在两个板子的.bashrc文件中添加必要的环境变量配置。首先,确保你的 /etc/hosts 文件中…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...