Boosting【文献精读、翻译】
Boosting
Bühlmann, P., & Yu, B. (2009). Boosting. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1), 69–74. doi:10.1002/wics.55
摘要
在本文中,我们回顾了Boost方法,这是分类和回归中最有效的机器学习方法之一。虽然我们也讨论了边际观点(margin point of view),但主要采用梯度下降的视角。文章特别介绍了分类中的 AdaBoost 和回归中的各种 L2Boosting 版本。同时,我们还为实践者提供了如何选择基础(弱)学习器和损失函数的建议,并给出了相关软件的使用指引。
Boosting 是一种现代统计方法,起源于20世纪90年代中期的机器学习,用于分类和回归。在过去几年中,Boosting 在理解和建模实际数据方面取得了显著进展。Boosting 被成功应用于许多领域,包括文本挖掘、图像分割、语言翻译、生物信息学、神经科学和金融等。
Boosting 具有以下几个特点:
- 集成方法:通过线性组合多个“弱学习器”形成的集成方法。
- 优化相关:与优化(通常是凸的)梯度下降(迭代)算法密切相关。这个特性与其他机器学习方法如 bagging 和随机森林共享。
- 提前停止:通过提前停止来实现正则化,这将正则化与数值优化结合,使得 Boosting 非常独特。
- 数据加权:Boosting 会根据前一次迭代的结果重新加权数据样本,这是因为损失函数梯度的形式导致的,尽管这一特点并非所有 Boosting 变体都具有,但在原始的 AdaBoost 算法中是非常重要的。
Kearns 和 Valiant 在“可能近似正确”(probably approximately correct,PAC)学习的框架中提出了一个猜想,即 一个成功率稍高于50%的弱分类器可以通过 Boosting 转化为一个强分类器 ,使得新的分类器训练误差趋于零,并且在多项式时间内完成计算。
在他的获奖麻省理工学院计算机科学论文中,回答了这一问题,并且 Freund 和 Schapire 设计了第一个实用的 Boosting 算法 AdaBoost,用于二分类问题。
Breiman 通过从 梯度下降 的角度重新推导出 AdaBoost,将 AdaBoost 与优化紧密联系起来。他基于边际(即真实标签 y ∈ { − 1 , 1 } y \in \{-1, 1\} y∈{−1,1} 与预测值 f f f 的乘积 y f yf yf)的指数损失函数进行了推导。这一联系进一步被 Friedman 等人和 Mason 等人发展。
在统计学界,通过对不同损失函数的广义 AdaBoost 和通过不同的梯度下降方法,衍生出了许多 Boosting 变体。最著名的包括分类中的 LogitBoost 和回归中的 L2Boosting。
机器学习社区的另一研究方向则集中在边际视角(the margin view point)下的 AdaBoost,最近的研究强调了 AdaBoost 的集成和重新加权方面。
Boosting 的理论分析由理论统计学和理论机器学习社区共同发展。统计学家研究了如贝叶斯一致性和模型选择一致性,以及提前停止时各种 Boosting 方法的 Minimax 收敛率;而机器学习学者则研究了 Boosting 的算法收敛性和通过边际分布和模型类的复杂性测量及样本大小对 AdaBoost 泛化误差的上界。
这些理论分析的一个重要见解是,Boosting 过程的复杂性并不是迭代次数的简单线性函数。例如,在一个简单的回归案例中,复杂性随着迭代次数的增加而以指数递减的方式增长—— 复杂性上界由噪声方差决定,并且随着迭代次数增加,增加的复杂量变得极小 。这部分解释了 AdaBoost 的 抗过拟合特性 。
最终,AdaBoost 和其他所有 Boosting 方法都会过拟合,但在分类问题中,由于评估0-1损失函数的鲁棒性以及 Boosting 复杂性的缓慢增加,这个过程可能会持续很长时间。大多数理论研究都是在独立同分布(i.i.d.)假设下进行的,但也有一些研究对平稳数据源(stationary data sources)进行了推广。
本文主要从梯度下降的角度回顾 Boosting 算法。我们将特别介绍 AdaBoost、LogitBoost 和 L2Boosting 算法。在简要讨论边际视角之后,我们将讨论损失函数、基础学习器和停止规则的选择。
梯度下降的角度
我们从梯度下降的角度描述 Boosting 算法,特别是介绍用于分类的 AdaBoost 和 LogitBoost(对应于不同的损失函数 L L L )以及用于回归的各种版本的 L2Boosting(对应于 L 2 L2 L2 损失函数)。最后,我们简要提及从经验损失(empirical loss)到惩罚经验损失(penalized empirical loss)如回归中的 Lasso 的 Boosting 泛化。
L 2 L2 L2 损失函数,也叫均方误差 (Mean Squared Error, MSE),是机器学习和统计中常用的一种衡量模型预测误差的方法。它通过计算预测值与实际值之间差值的平方,然后取这些平方误差的平均值来表示。具体公式如下:
L 2 损失 = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 L2 \text{ 损失} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 L2 损失=n1i=1∑n(yi−y^i)2
其中:
- y i y_i yi 是第 i i i 个实际值
- y ^ i \hat{y}_i y^i 是第 i i i 个预测值
- n n n 是样本数量
L 2 L2 L2 损失函数惩罚大的误差,使得模型更关注较大的偏差。
假设我们观察到 ( X 1 , Y 1 ) , … , ( X n , Y n ) (X1, Y1), \ldots, (Xn, Yn) (X1,Y1),…,(Xn,Yn),其中 X i ∈ R p Xi \in \mathbb{R}^p Xi∈Rp 表示一个 p p p 维预测变量, Y i Y_i Yi 表示一个单变量响应(univariate response),例如在回归中取值于 R \mathbb{R} R 或在二分类中取值于 { − 1 , + 1 } \{-1, +1\} {−1,+1} 。
接下来,我们用 X ( j ) X^{(j)} X(j) 表示向量 X ∈ R p X \in \mathbb{R}^p X∈Rp 的第 j j j 个分量。我们通常假设对 ( X i , Y i ) (Xi, Yi) (Xi,Yi) 是独立同分布(i.i.d.)或来自平稳过程(stationary process)。目标是估计回归函数 F ( x ) = E [ Y ∣ X = x ] F(x) = \mathbb{E}[Y|X = x] F(x)=E[Y∣X=x] 或找到分类器 sign ( F ( x ) ) \text{sign}(F(x)) sign(F(x)),其中 F ( x ) : R p → R F(x): \mathbb{R}^p \rightarrow \mathbb{R} F(x):Rp→R 。
通过实值损失函数(real-valued loss function)评估估计性能,意思是我们想最小化期望损失或风险:
E [ L ( Y , F ( X ) ) ] , (2) \mathbb{E}[L(Y, F(X))], \tag{2} E[L(Y,F(X))],(2)
基于数据 ( X i , Y i ) ( i = 1 , . . . , n ) (Xi, Yi)(i = 1, ..., n) (Xi,Yi)(i=1,...,n)。假设损失函数 L L L 在第二个参数上是平滑和凸的,因此可以应用梯度方法。
通过在基础学习器上的函数梯度下降最小化经验损失函数可以得到 Boosting 算法。
n − 1 ∑ i = 1 n L ( Y i , F ( X i ) ) , (3) n^{-1} {\textstyle \sum_{i = 1}^{n}} L(Y_i , F(X_i)), \tag{3} n−1∑i=1nL(Yi,F(Xi)),(3)
基础学习器的形式为 h ( x , θ ^ ) ( x ∈ R p ) h(x, \hat{\theta})(x \in \mathbb{R}^p) h(x,θ^)(x∈Rp) ,其中 θ ^ \hat{\theta} θ^ 是有限或无限维度的估计参数。
例如,基础学习器可以是树桩, θ ^ \hat{\theta} θ^ 描述分裂的轴、分裂点和两个终端节点的拟合值。基于数据拟合基础学习器是基础学习器的一部分。
Boosting 方法论通常基于用户确定的基础过程或弱学习器,并在修改后的数据上反复使用它们,这些数据通常是先前迭代的输出。最终的 Boosting 过程采用基础过程的线性组合的形式。具体来说,给定一个基础学习器 h ( x , θ ) h(x, \theta) h(x,θ),Boosting 可以作为损失函数 L L L 上的函数梯度下降来推导。
Boosting(梯度下降视角)
- 从 F 0 ( x ) = 0 F_0(x) = 0 F0(x)=0 开始。
- 给定 F m − 1 ( x ) F_{m−1}(x) Fm−1(x),设
( β m , h ( x , θ ^ m ) ) ) = arg min β ∈ R , θ ∑ i = 1 n L ( Y i , F m − 1 ( X i ) + β h ( x , θ ) ) 。 (\beta_m, h(x, \hat{\theta}_m))) = \argmin_{\beta \in \mathbb{R}, \theta} \sum_{i=1}^n L(Y_i, F_{m−1}(X_i) + \beta h(x, \theta))。 (βm,h(x,θ^m)))=β∈R,θargmini=1∑nL(Yi,Fm−1(Xi)+βh(x,θ))。
- 设
F m ( x ) = F m − 1 ( x ) + β m h ( x , θ ^ m ) 。 F_m(x) = F_{m−1}(x) + \beta_m h(x, \hat{\theta}_m)。 Fm(x)=Fm−1(x)+βmh(x,θ^m)。
- 当 m = M m = M m=M 时停止。
AdaBoost 分类器为 sign ( F M ( x ) ) \text{sign}(F_M(x)) sign(FM(x)) 。
分类
在二分类中, y ∈ { − 1 , + 1 } y \in \{-1, +1\} y∈{−1,+1} ,最常用的损失是 0-1 损失。即,对于分类器 sign ( F ( x ) ) ∈ { − 1 , + 1 } \text{sign}(F(x)) \in \{-1, +1\} sign(F(x))∈{−1,+1} ,如果 x x x 的标签是 y ∈ { − 1 , + 1 } y \in \{-1, +1\} y∈{−1,+1},则 0-1 损失可以写成边际(margin) y F ( x ) yF(x) yF(x) 的函数:
0-1 损失是一种简单的损失函数,主要用于分类问题。它表示预测是否正确的损失,即当预测错误时损失为1,预测正确时损失为0。具体公式如下:
0 − 1 损失 = { 1 , 如果预测错误 0 , 如果预测正确 0-1 \text{ 损失} = \begin{cases} 1, & \text{如果预测错误} \\ 0, & \text{如果预测正确} \end{cases} 0−1 损失={1,0,如果预测错误如果预测正确
例如,如果模型预测结果与实际结果不一致,损失为1;如果一致,损失为0。
L 01 ( y , F ( x ) ) = I { y F ( x ) < 0 } 。 L_{01}(y, F(x)) = I \{yF(x) < 0\}。 L01(y,F(x))=I{yF(x)<0}。
很容易看出,指数损失函数
L exp ( y , F ( x ) ) = exp ( − y F ( x ) ) L_{\text{exp}}(y, F(x)) = \exp (-yF(x)) Lexp(y,F(x))=exp(−yF(x))
是 L 01 L_{01} L01 的上界,其总体最小化器是对数几率比的一半:
F ( x ) = 1 2 log P ( Y = 1 ∣ X = x ) P ( Y = − 1 ∣ X = x ) 。 F(x) = \frac{1}{2} \log \frac{P(Y = 1|X = x)}{P(Y =−1|X = x)}。 F(x)=21logP(Y=−1∣X=x)P(Y=1∣X=x)。
例如,在 AdaBoost 中,弱或基础学习器是一个将给定训练数据集映射到训练误差低于随机猜测(小于50%)的分类器的过程。常用的是基于树的分类器。AdaBoost 通过以加法方式改进当前拟合,以最小化基础学习器上的经验指数损失函数(作用于修改后的数据集)和乘数。
AdaBoost
- 从 F 0 ( x ) = 0 F_0(x) = 0 F0(x)=0 开始;
- 给定 F m − 1 ( x ) F_{m−1}(x) Fm−1(x),设
w i ( m ) = exp ( − Y i F m − 1 ( X i ) ) , (9) w_i^{(m)} = \exp(-Y_i F_{m−1}(X_i)), \tag{9} wi(m)=exp(−YiFm−1(Xi)),(9)
h ( x , θ ^ m ) = arg min θ ∑ i = 1 n w i ( m ) I { Y i ≠ h ( X i , θ ) } , (10) h(x, \hat{\theta}_m) = \argmin_{\theta} \sum_{i=1}^n w_i^{(m)} I \{Y_i \ne h(X_i, \theta)\}, \tag{10} h(x,θ^m)=θargmini=1∑nwi(m)I{Yi=h(Xi,θ)},(10)
并记 h ( ⋅ , θ ^ m ) h(\cdot, \hat{\theta}_m) h(⋅,θ^m) 的关联误差为
err m = ∑ i = 1 w i ( m ) I { Y i ≠ h ( X i , θ ^ m ) } ∑ i = 1 w i ( m ) 。 \text{err}_m = \frac{\sum_{i=1} w_i^{(m)} I \{Y_i \ne h(X_i, \hat{\theta}_m)\}}{\sum_{i=1} w_i^{(m)}}。 errm=∑i=1wi(m)∑i=1wi(m)I{Yi=h(Xi,θ^m)}。
进一步设
β m = 1 2 log 1 − err m err m 。 \beta_m = \frac{1}{2} \log \frac{1 - \text{err}_m}{\text{err}_m}。 βm=21logerrm1−errm。
- 设
F m ( x ) = F m − 1 ( x ) + β m h ( x , θ ^ m ) 。 F_m(x) = F_{m−1}(x) + \beta_m h(x, \hat{\theta}_m)。 Fm(x)=Fm−1(x)+βmh(x,θ^m)。
- 当 m = M m = M m=M 时停止。
- AdaBoost 分类器为 y = sign ( F M ( x ) ) y = \text{sign}(F_M(x)) y=sign(FM(x)) 。
显然,AdaBoost 算法的两个关键输入是基础学习器 h ( ⋅ , θ ) h(\cdot, \theta) h(⋅,θ) 的选择和 M 的停止规则。在许多实证研究中,已经有效地使用了树桩或八节点树(eight-node trees)作为基础学习器。停止迭代 M 作为正则化参数。当数据集较大时,可以使用测试数据集或交叉验证来找到这样的 M。当 M 趋于无穷大时,已证明 AdaBoost 估计器收敛于线性组合基础学习器集合上经验指数损失的最小化。
换句话说,AdaBoost 算法通过不断调整和组合基础学习器,使得最终的组合模型在训练数据上的指数损失最小化。也就是说,当算法的迭代次数足够多时,AdaBoost 找到的模型是所有可能的基础学习器线性组合中,使经验指数损失(在训练数据上的损失)最小的那个模型。
八节点树是一种决策树,每个树最多有八个终端节点(或叶子节点)。决策树是一种基于树结构的模型,用于分类或回归任务。每个节点根据特定特征对数据进行分割,直到到达叶子节点,叶子节点代表最终的分类或预测值。八节点树具体指最多有八个这样的叶子节点。
正则化参数是一种控制模型复杂度的参数,用于防止模型过拟合。过拟合是指模型在训练数据上表现很好,但在新数据上表现不佳。正则化通过在损失函数中添加额外的惩罚项来限制模型的复杂度,惩罚项通常是模型参数的大小。
常见的正则化方法包括:
- L1 正则化(Lasso):惩罚模型参数的绝对值之和。
- L2 正则化(Ridge):惩罚模型参数的平方和。
正则化参数决定了惩罚项的权重。例如,在 L2 正则化中,损失函数变为:
L 2 损失 = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 + λ ∑ j = 1 p θ j 2 L2 \text{ 损失} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 + \lambda \sum_{j=1}^p \theta_j^2 L2 损失=n1i=1∑n(yi−y^i)2+λj=1∑pθj2
其中 λ \lambda λ 就是正则化参数, θ j \theta_j θj 是模型的参数。通过调整 λ \lambda λ 的值,我们可以控制正则化的强度,从而平衡模型的拟合能力和复杂度。
我们将进一步讨论基础过程的选择和一些 M 的停止规则。
LogitBoost
如果损失函数是具有逻辑链函数(log-likelihood)的逻辑模型的负对数似然函数,我们得到损失函数
log ( 1 + exp ( − y F ) ) , \log(1 + \exp(-yF)), log(1+exp(−yF)),
- 当 y F ≤ 0 yF \leq 0 yF≤0 时, exp ( − y F ) ≥ 1 \exp(-yF) \geq 1 exp(−yF)≥1,因此 1 + exp ( − y F ) ≥ 2 1 + \exp(-yF) \geq 2 1+exp(−yF)≥2 ,所以:
log 2 ( 1 + exp ( − y F ) ) ≥ log 2 ( 2 ) = 1 \log_2(1 + \exp(-yF)) \geq \log_2(2) = 1 log2(1+exp(−yF))≥log2(2)=1
或等效地
L logit ( y , F ) = log 2 ( 1 + exp ( − y F ) ) , L_{\text{logit}}(y, F) = \log_2(1 + \exp(-yF)), Llogit(y,F)=log2(1+exp(−yF)),
它作为边际 y F yF yF 的 0-1 损失函数的上界。此外, L logit L_{\text{logit}} Llogit 的期望损失由与指数损失函数中相同的函数最小化。
在多类情况下,可以使用多项式模型中的对数似然函数应用梯度下降算法,以获得多类 Boosting 算法。然而,通常在实践中,使用一对多的方法将多类问题转化为多个二分类问题,这样就可以应用 AdaBoost 或 LogitBoost。
回归:平方误差损失下的 Boosting
在回归中,一个自然的损失函数是平方误差损失。使用这个损失函数时,我们得到 L2Boosting。应用带平方损失的梯度下降 Boosting 算法时,最终会重复拟合基础学习器的残差。同样地,L2Boosting 是经验平方误差风险 1 n ∑ i = 1 n ( Y i − F ( X i ) ) 2 \frac{1}{n} \sum_{i=1}^{n}(Y_i - F(X_i))^2 n1∑i=1n(Yi−F(Xi))2(相对于 F ( ⋅ ) F(\cdot) F(⋅) )的“受约束”最小化过程,得到一个估计器 F ^ ( ⋅ \hat{F}(\cdot F^(⋅ )。
经验风险最小化的正则化再次隐含地通过基础程序的选择和算法约束(如早停或某些惩罚边界)实现。
L2Boosting(使用基础程序 h ( ⋅ , θ ) h(\cdot, \theta) h(⋅,θ) )
- 从 F 0 = 0 F_0 = 0 F0=0 开始。
- 给定 F m − 1 ( x ) F_{m-1}(x) Fm−1(x),计算残差 U i = Y i − F m − 1 ( X i ) U_i = Y_i - F_{m-1}(X_i) Ui=Yi−Fm−1(Xi)( i = 1 , . . . , n i = 1, ..., n i=1,...,n )。将基础程序拟合到当前残差:
h ( x , θ ^ m ) = arg min θ ∑ i = 1 n ( U i − h ( X i , θ ) ) 2 , h(x, \hat{\theta}_m) = \arg\min_{\theta} \sum_{i=1}^{n} (U_i - h(X_i, \theta))^2, h(x,θ^m)=argθmini=1∑n(Ui−h(Xi,θ))2, - F m ( x ) = F m − 1 ( x ) + β m h ( x , θ ^ m ) , F_m(x) = F_{m-1}(x) + \beta_m h(x, \hat{\theta}_m), Fm(x)=Fm−1(x)+βmh(x,θ^m),
其中线搜索(line search)结果给出 β m ≡ 1 \beta_m \equiv 1 βm≡1 。 - 在 m = M m = M m=M 时停止, F M ( x ) F_M(x) FM(x) 是回归函数的最终估计器。
如前所述,除了基础学习器 B B B 外,迭代次数 M M M 是 L2Boosting 的主要调优参数。可以通过交叉验证来估计 Boosting 迭代次数。或者,也可以使用某些模型选择标准来绕过交叉验证,从而节省计算时间。
当基础程序只选择所有 p p p 个变量中的一个预测变量(特征)时,梯度下降变成坐标方向梯度下降(coordinatewise gradient descent)。例如,对于逐步平滑样条(component-wise smoothing spline)基础程序,它拟合最小化残差平方和的预测变量,Boosting 估计器得到了一个加性模型拟合。另一个广泛使用的程序是逐步线性最小二乘法,得到线性模型拟合。
L2Boosting:线性模型的坐标方向下降
- 从 F 0 = 0 F_0 = 0 F0=0 开始。
- 给定 F m − 1 ( x ) F_{m-1}(x) Fm−1(x),计算残差 U i = Y i − F m − 1 ( X i ) U_i = Y_i - F_{m-1}(X_i) Ui=Yi−Fm−1(Xi)( i = 1 , . . . , n i = 1, ..., n i=1,...,n)。令 X i ( j ) X_i^{(j)} Xi(j) 为 X i ∈ R p X_i \in \mathbb{R}^p Xi∈Rp 的第 j j j 个分量,
j ^ m = arg min j = 1 , . . . , p ∑ i = 1 n ( U i − β ^ m X i ( j ) ) 2 , (18) \hat{j}_m = \arg\min_{j=1,...,p} \sum_{i=1}^{n} (U_i - \hat{\beta}_m X_i^{(j)})^2, \tag{18} j^m=argj=1,...,pmini=1∑n(Ui−β^mXi(j))2,(18)
β ^ m = arg min β ∑ i = 1 n ( U i − β X i ( j ^ m ) ) 2 , (19) \hat{\beta}_m = \arg\min_{\beta} \sum_{i=1}^{n} (U_i - \beta X_i^{(\hat{j}_m)})^2, \tag{19} β^m=argβmini=1∑n(Ui−βXi(j^m))2,(19) - F m ( x ) = F m − 1 ( x ) + β ^ m x ( j ^ m ) , F_m(x) = F_{m-1}(x) + \hat{\beta}_m x^{(\hat{j}_m)}, Fm(x)=Fm−1(x)+β^mx(j^m),
- 在 m = M m = M m=M 时停止, F M ( x ) F_M(x) FM(x) 是线性回归函数的最终估计器。
Friedman 通过使用 ν ⋅ h ( ⋅ , θ ) \nu \cdot h(\cdot, \theta) ν⋅h(⋅,θ)(其中 0 < ν ≤ 1 0 < \nu \leq 1 0<ν≤1 )缩减基础学习器来引入 L2Boosting 的收缩。经验表明,只要 ν \nu ν 较小,步长 ν \nu ν 的选择并不重要;我们通常使用 ν = 0.1 \nu = 0.1 ν=0.1 。
文献中将 L2Boosting 的一个相关版本称为 e-L2Boosting:
e-L2Boosting
将所有预测变量归一化到相同的尺度,并令 β ^ m \hat{\beta}_m β^m 具有固定的“步长” ν > 0 \nu > 0 ν>0,但其符号取决于所选 X ( j ^ m ) X^{(\hat{j}_m)} X(j^m) 与当前残差向量 U U U 之间的相关性,即,
β ^ m ≡ ν ⋅ sign ( corr ( U , X ( j ^ m ) ) ) . (21) \hat{\beta}_m \equiv \nu \cdot \text{sign}(\text{corr}(U, X^{(\hat{j}_m)})). \tag{21} β^m≡ν⋅sign(corr(U,X(j^m))).(21)
当 m = 2 m = 2 m=2 且 ν = 1 \nu = 1 ν=1 时,L2Boosting 已经由 Tukey 提出,名为“twicing”。在参考文献中,e-L2Boosting 也称为前向逐步拟合。研究表明,它与 L1 惩罚最小二乘法 Lasso 相连,并且通常具有 Lasso 的稀疏性。实际上,Lasso 和 e-L2Boosting 通过 Blasso 算法相连,该算法包含 e-L2Boosting 步骤(前向步骤)和适当选择的后向步骤,其中预测变量可以从拟合函数中移除。
除了 L1 惩罚最小二乘法外,还可以采用 L0 惩罚最小二乘法,尽管后者在计算上不便且难以求解。这与 SparseBoosting 相关,后者使用 AIC、BIC 或 gMDL 等信息准则,而文献推荐 gMDL 以实现整体预测性能和稀疏性。最近,Zhang 结合前向和后向步骤来最小化 L0 惩罚最小二乘法,而 Friedman 和 Popescu 设计了一种梯度方向正则化算法,该算法不一定来自显式的惩罚函数。
分类中的边际观点(MARGIN POINT)
Schapire 等人[9] 提出了通过提升边际分布来解释 AdaBoost 有效性的新方法。值得注意的是,边际(margin)是支持向量机方法和理论中的一个关键概念。这项工作引发了机器学习社区对 AdaBoost 的一系列推广,通过最大化不同版本的边际,例如,产生了 LPBoost[32]、SoftBoost[33] 和熵正则化的 LPBoost[14]。
9. Schapire R, Freund Y, Bartlett P, Lee W. Boosting the margin: a new explanation for the effectiveness of voting methods. Ann Stat 1998, 26:1651–1686.
32. Demiriz A, Bennett K, Shawe-Taylor J. Linear programming boosting via column generation. JMach Learn Res 2002, 46:225–254
33. Warmuth M, Glocer K, R ̈ atsch G. (2008a), Boosting algorithms for maximizing the soft margin. In: Platt J, Koller D, Singer Y, Roweis S, eds. Advances in Neural Information Processing Systems 20. Boston: MIT Press; 2000, 1585–1592.
14. Warmuth M, Glocer K, Vishwanathan S. Entropy regularized LP Boost. In: Freund Y, Gy ̈ orfi L, Tur ́ an G, Zeugmann T, eds. Advanced Lectures on Machine Learning, Lecture Notes in Computer Science. NewYork: Springer; 2008b, 256–271.
在这些基于边际的算法中,有些算法被认为是“修正性的”,因为它们仅根据前一次迭代的结果进行重新加权,而另一些算法是“完全修正性的”,因为它们在重新加权时考虑了所有先前迭代的结果。
一些研究(使用 C4.5 或径向基函数作为基础学习器)表明,这些基于边际的方法在分类准确性方面与 AdaBoost 相似或略有提高(也可能比 LogitBoost 更好)。在参考文献[14] 的计算速度比较研究中,发现 LPBoost 是最快的,熵正则化(entropy regularized)的 LPBoost 略慢,而 SoftBoost 最慢。这些算法依赖于凸优化中的原对偶公式,其中已知 SoftBoost 和熵正则化的 LPBoost 有一些收敛速度分析。
实际应用中的 Boosting 问题
目前我们所知道的 Boosting 方法包含三个要素:损失函数、基础学习器和停止规则。要在实际中应用 Boosting,需要对这三个组件进行选择。类似于应用任何其他方法,这些选择通常是主观的,取决于实践者的熟悉程度、软件的可用性或计算实施的时间。然而,根据我们和他人在各种问题中使用 Boosting 的经验,以下是一些关于这些选择的经验法则建议。
损失函数
在分类中,AdaBoost 和 LogitBoost 是最受欢迎的损失函数选择,其中 LogitBoost 的表现略好于 AdaBoost。
在基于边际(margin-based)的 AdaBoost 变形中,LPBoost 似乎是一个不错的选择[14]。
- Warmuth M, Glocer K, Vishwanathan S. Entropy regularized LP Boost. In: Freund Y, Gy ̈ orfi L, Tur ́ an G, Zeugmann T, eds. Advanced Lectures on Machine Learning, Lecture Notes in Computer Science. NewYork: Springer; 2008b, 256–271.
在回归中,L2Boosting 和其收缩版本 e-L2Boosting 经常被使用。可以说,更稳健的损失函数和基础程序应该被使用[34],但在实践中,它们并不常见,可能是由于可用软件的原因。
基础学习器
从高层次来看,关于基础学习器选择的传统智慧是应该使用“弱”学习器或在复杂性(complexity)方面简单的程序。这使得 Boosting 方法能够通过迭代拟合过程自适应地建立起适合特定问题的 Boosting 复杂性(complexity)。
例如,在 L2Boosting 中,如果从强学习器如投影追逐(projection pursuit)开始,即使在第二步 Boosting 也无法纠正早期迭代的过拟合。
在分类中,使用 Boosting(AdaBoost 或其推广)的最常用基学习器是 CART 或 C4.5(即基于树的分类器)。在许多问题中使用了树桩(stumps),稍强一些的学习器是具有适中节点数的树,例如八节点树。
在回归中,使用小步长的坐标下降版本 L2Boosting 和 e-L2Boosting 已经变得流行,用于高维线性和加性建模(additive modeling)。
提前停止规则
如果目标是预测,通常选择在测试集上表现或交叉验证作为提前停止规则。
如果样本量相对于拟合复杂度较大,单个测试集通常就足够了。相反,如果样本量相对于拟合复杂度较小,单个测试集的想法就不准确,应该使用交叉验证。
然而,交叉验证的预测误差具有很大的方差,因此可能不可靠。基于模型选择标准如 AIC(或 AICc)、BIC 或 gMDL 的一些替代方法存在。其想法是使用一个可能有偏的估计预测误差,其方差比交叉验证误差更小。
此外,与交叉验证相比,计算成本可能减少很多倍,因此对于非常大的数据集,由于计算节省,这些基于模型的预测误差估计也很理想。
R 中的软件
R 包 mboost 提供了许多具体版本的梯度下降 Boosting 算法,包括停止规则的选择。此外,mboost 允许使用者特定的损失函数 L 进行 Boosting 拟合。参考文献[35] 提供了关于 Boosting 的综述,包括使用 mboost 的示例。
- B ̈ uhlmann P, Hothorn T. Boosting algorithms: regularization, prediction and model fitting (with discussion). Stat Sci 2007, 22:477–505
相关文章:

Boosting【文献精读、翻译】
Boosting Bhlmann, P., & Yu, B. (2009). Boosting. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1), 69–74. doi:10.1002/wics.55 摘要 在本文中,我们回顾了Boost方法,这是分类和回归中最有效的机器学习方法之一。虽然我们也讨…...

保姆级教程|如何配置ROS1主从机
在机器人开发经常遇到使用两个板子通信问题,比如一个板子跑底层的运动控制,一个板子跑定位导航。为了确保两个板子之间的ROS通信流畅,我们需要在两个板子的.bashrc文件中添加必要的环境变量配置。首先,确保你的 /etc/hosts 文件中…...
及其Python 和 MATLAB 实现)
贝叶斯优化算法(Bayesian Optimization)及其Python 和 MATLAB 实现
贝叶斯优化算法(Bayesian Optimization)是一种基于贝叶斯统计理论的优化方法,通常用于在复杂搜索空间中寻找最优解。该算法能够有效地在未知黑盒函数上进行优化,并在相对较少的迭代次数内找到较优解,因此在许多领域如超…...

NLP - 基于bert预训练模型的文本多分类示例
项目说明 项目名称 基于DistilBERT的标题多分类任务 项目概述 本项目旨在使用DistilBERT模型对给定的标题文本进行多分类任务。项目包括从数据处理、模型训练、模型评估到最终的API部署。该项目采用模块化设计,以便于理解和维护。 项目结构 . ├── bert_dat…...

数据库备份和还原
一、备份 备份类型 1.完全备份 全备份是指对整个数据集进行完整备份。每次备份都会复制所有选定的数据,无论这些数据是否发生了变化。 2.增量备份 增量备份是指仅备份自上次备份(无论是全备份还是增量备份)以来发生变化的数据。它记录了…...
谷粒商城-个人笔记(集群部署篇一)
前言 学习视频:Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强学习文档: 谷粒商城-个人笔记(基础篇一)谷粒商城-个人笔记(基础篇二)谷粒商城-个人笔记(基础篇三)谷粒商城-个人笔记(高级篇一)谷粒商城-个…...

Linux环境下的字节对齐现象
在Linux环境下,字节对齐是指数据在内存中的存储方式。字节对齐是为了提高内存访问的效率和性能。 在Linux中,默认情况下,结构体和数组的成员会进行字节对齐。具体的对齐方式可以通过编译器选项来控制。 在使用C语言编写程序时,可…...
没有调用memcpy却报了undefined reference to memcpy错误
现象 在第5行出现了,undefined reference to memcpy’ 1 static void printf_x(unsigned int val) 2{ 3 char buffer[32]; 4 const char lut[]{0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F}; 5 char *p buffer; 6 while (val || p buffer) { 7 *(p) …...

import和require的区别
import是ES6标准中的模块化解决方案,require是node中遵循CommonJS规范的模块化解决方案。 后者支持动态引入,也就是require(${path}/xx.js),前者目前不支持,但是已有提案。 前者是关键词,后者不是。 前者是编译时加…...

白骑士的Python教学高级篇 3.3 数据库编程
系列目录 上一篇:白骑士的Python教学高级篇 3.2 网络编程 SQL基础 Structured Query Language (SQL) 是一种用于管理和操作关系型数据库的标准语言。SQL能够执行各种操作,如创建、读取、更新和删除数据库中的数据(即CRUD操作)&a…...

macOS 安装redis
安装Redis在macOS上通常通过Homebrew进行,Homebrew是macOS上一个流行的包管理器。以下是安装Redis的步骤: 一 使用Homebrew安装Redis 1、安装Homebrew(如果尚未安装): 打开终端(Terminal)并执…...
【AIGC评测体系】大模型评测指标集
大模型评测指标集 (☆)SuperCLUE(1)SuperCLUE-V(中文原生多模态理解测评基准)(2)SuperCLUE-Auto(汽车大模型测评基准)(3)AIGVBench-T2…...

工厂模式之简单工厂模式
文章目录 工厂模式工厂模式分为工厂模式的角色简单工厂模式案例代码定义一个父类,三个子类定义简单工厂客户端使用输出结果 工厂模式 工厂模式属于创造型的模式,用于创建对象。 工厂模式分为 简单工厂模式:定义一个简单工厂类,根…...

2.(vue3.x+vite)调用iframe的方法(vue编码)
1、效果预览 2.编写代码 (1)主页面 <template><div><button @click="sendMessage">调用iframe,并发送信息...

实战项目——用Java实现图书管理系统
前言 首先既然是管理系统,那咱们就要实现以下这几个功能了--> 分析 1.首先是用户分为两种,一个是管理员,另一个是普通用户,既如此,可以定义一个用户类(user),在定义管理员类&am…...

利用DeepFlow解决APISIX故障诊断中的方向偏差问题
概要:随着APISIX作为IT应用系统入口的普及,其故障定位能力的不足导致了在业务故障诊断中,APISIX常常成为首要的“嫌疑对象”。这不仅导致了“兴师动众”式的资源投入,还可能使诊断方向“背道而驰”,从而导致业务故障“…...

sqlalchemy获取数据条数
1、sqlalchemy获取数据条数 在SQLAlchemy中,你可以使用count()函数来获取数据表中的记录条数。 from sqlalchemy import create_engine, MetaData, Table# 数据库连接字符串 DATABASE_URI = dialect+driver://username:password@host:port/database# 创建引擎 engine = crea…...
SpringBoot的自动配置核心原理及拓展点
Spring Boot 的核心原理几个关键点 约定优于配置: Spring Boot 遵循约定优于配置的理念,通过预定义的约定,大大简化了 Spring 应用程序的配置和部署。例如,它自动配置了许多常见的开发任务(如数据库连接、Web 服务器配…...

用随机森林算法进行的一次故障预测
本案例将带大家使用一份开源的S.M.A.R.T.数据集和机器学习中的随机森林算法,来训练一个硬盘故障预测模型,并测试效果。 实验目标 掌握使用机器学习方法训练模型的基本流程;掌握使用pandas做数据分析的基本方法;掌握使用scikit-l…...
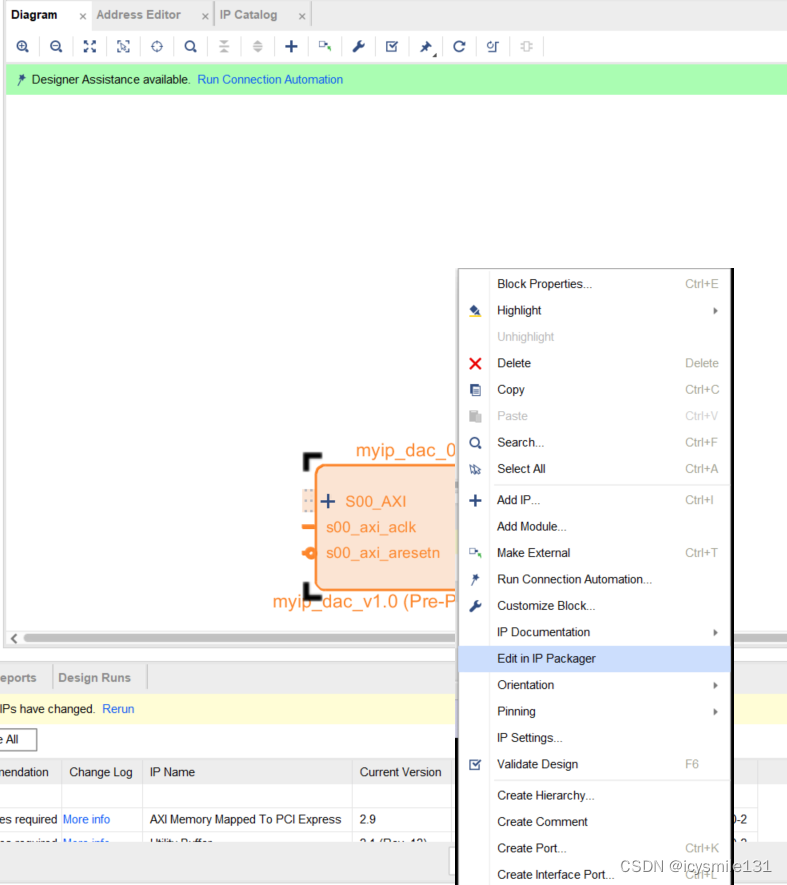
24位DAC转换的FPGA设计及将其封装成自定义IP核的方法
在vivado设计中,为了方便的使用Block Desgin进行设计,可以使用vivado软件把自己编写的代码封装成IP核,封装后的IP核和原来的代码具有相同的功能。本文以实现24位DA转换(含并串转换,使用的数模转换器为CL4660)为例,介绍VIVADO封装IP核的方法及调用方法,以及DAC转换的详细…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

《我看见的世界:李飞飞自传》第1-6章阅读笔记:从移民少女到AI教母的“看见“之旅
前言 当我们谈论人工智能时,我们谈论的是算法、数据、算力,是那些冰冷的代码和复杂的模型。但在《我看见的世界:李飞飞自传》中,李飞飞用她独特的视角告诉我们:AI的本质,是人类对"看见"世界的渴望…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...

BiliRoamingX:彻底解决B站体验限制的完整增强方案
BiliRoamingX:彻底解决B站体验限制的完整增强方案 【免费下载链接】BiliRoamingX-integrations BiliRoamingX integrations and patches powered by ReVanced. 项目地址: https://gitcode.com/gh_mirrors/bi/BiliRoamingX-integrations 你是否曾为B站的内容区…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

Burp抓包失败的五大隐形墙与HTTPS解密断裂点排查指南
1. 这不是Burp用得不对,是环境链路断在了你没看见的地方“Burp抓不到包”——这句话我过去三年里听开发、测试、刚转安全的新人说了不下两百遍。但真正打开Burp一看,Proxy标签页里空空如也,连个localhost:8080的请求都没有,十有八…...

前馈补偿技术:用数字预失真驯服放大器非线性失真
1. 项目概述:用前馈补偿驯服放大器失真在音频发烧友和硬件工程师的圈子里,追求“高保真”几乎是一种信仰。我们总希望从扬声器里传出的声音,是录音现场或音乐制作人意图的完美复刻,纤毫毕现,不带一丝杂质。然而&#x…...

茉莉花插件:如何让中文文献管理效率提升300%
茉莉花插件:如何让中文文献管理效率提升300% 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献的元数据抓…...