Gemma轻量级开放模型在个人PC上释放强大性能,让每个桌面秒变AI工作站
Google DeepMind团队最近推出了Gemma,这是一个基于其先前Gemini模型研究和技术的开放模型家族。这些模型专为语言理解、推理和安全性而设计,具有轻量级和高性能的特点。

在Gemma模型推出之前,现有语言模型存在一些挑战和局限性,主要体现在这些模型在理解语言、进行推理以及确保输出内容的安全性方面,并没有达到很高的水平。它们在处理一些需要深层次理解或创造性思维的任务时,可能无法给出非常准确或有用的答案。而且很多现有的大型模型对计算资源的要求很高,这导致它们在个人电脑或移动设备等资源受限的环境中难以运行。这限制了这些模型的普及和应用范围,因为不是每个人都能访问到高端的计算硬件。随着语言模型被用于生成各种文本内容,如何确保这些内容的安全性和符合道德标准成为了一个重要问题。一些现有模型可能没有很好地解决这个问题,有时可能会生成一些不恰当或有潜在危害的内容。
针对这些挑战,Gemma模型的设计考虑了提高性能、优化部署效率和加强安全性。Gemma利用了最新的研究成果和技术,以期在语言理解和推理方面达到更高的水平,并且能够在各种设备上运行,包括个人电脑和移动设备。Gemma在开发过程中采取了一系列措施来确保生成内容的安全性和可靠性,比如使用自动化技术和人工反馈来细致调整模型的行为。Gemma模型的关键特点如下:
- 两种规模: 提供Gemma 2B和Gemma 7B两种规模,每种规模都有预训练和指令调整(instruction-tuned)的变体。
- 负责任的生成式AI工具包: 提供创建更安全AI应用的指导和工具。
- 跨框架支持: 为JAX、PyTorch和通过原生Keras 3.0的TensorFlow提供推理和监督式微调(SFT)的工具链。
- 易于部署: 模型可以在笔记本电脑、工作站或Google Cloud上运行,并可在Vertex AI和Google Kubernetes Engine (GKE)上轻松部署。
- 性能优化: 模型针对NVIDIA GPU和Google Cloud TPU等多AI硬件平台进行了优化,确保行业领先的性能。
架构
Gemma模型最初由Vaswani等人在2017年提出,因其出色的处理序列数据的能力而广受欢迎。它在8192个token的上下文长度上进行训练,这个长度足以捕捉到复杂的语言结构和上下文信息,从而使得模型能够更好地理解和生成语言。
在核心参数方面,Gemma模型采用了一些创新的技术来提升性能和效率。模型引入了多查询注意力机制,这是一种注意力分配方式,它允许模型在处理信息时更加灵活。对于7B参数的模型,设计者选择了多头注意力,这是一种并行处理多个注意力查询的方法,能够增强模型处理复杂信息的能力。而对于规模较小的2B参数模型,则采用了多查询注意力,这在小规模模型中已被证明同样有效,有助于模型在资源受限的情况下保持较好的性能。
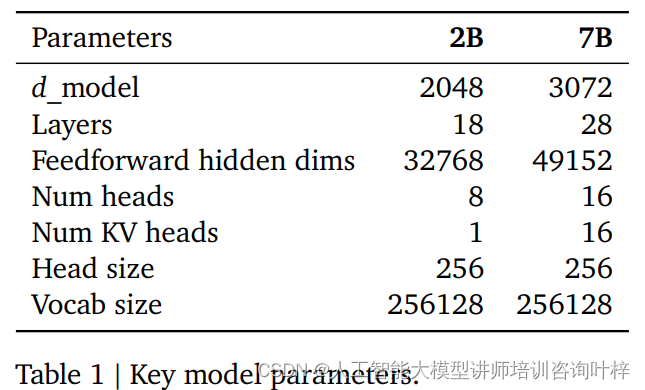
位置编码是transformer模型中的关键组成部分,它使得模型能够理解单词在句子中的位置。Gemma模型采用了旋转位置嵌入(RoPE),这是一种新颖的位置编码方式,与传统的绝对位置编码相比,它通过旋转机制能够更有效地表达位置信息。RoPE还在输入和输出之间共享嵌入,这种做法不仅减少了模型的参数数量,还有助于模型在不同任务之间迁移知识。
激活函数在神经网络中扮演着至关重要的角色,它为模型引入了非线性,使得模型能够学习和模拟复杂的函数映射。Gemma模型采用了GeGLU激活函数的近似版本,这是一种改进的激活机制,相比于传统的ReLU激活函数,GeGLU能够更有效地捕捉数据中的复杂特征。
为了稳定训练过程,Gemma模型使用了RMSNorm,这是一种归一化技术,它对每个transformer子层的输入进行归一化处理。这种归一化有助于防止训练过程中的梯度爆炸或消失问题,从而使得模型能够更稳定地学习,并提高最终性能。
训练
Google DeepMind选择使用TPUv5e作为训练的核心硬件,TPUv5e是一种特别为机器学习任务设计的高性能张量处理单元。与传统的CPU和GPU相比,TPU专为优化计算性能和能源效率而设计,尤其适合于处理大规模的深度学习模型。
在Gemma模型的训练中,TPUv5e被部署在一个复杂的2D网络结构中,每个pod包含256个芯片。这种配置允许模型在多个芯片上并行处理数据,极大地提高了计算速度和处理能力。对于7B参数的模型,训练过程使用了16个pods,这意味着总共有4096个TPUv5e芯片被用于训练,这是一个非常庞大的计算资源,能够处理和训练具有数十亿参数的复杂模型。
对于较小的2B参数模型,预训练过程则使用了2个pods,共计512个TPUv5e芯片。尽管使用的芯片数量较少,但这仍然是一个相当大的计算规模,足以支持模型的快速预训练。
在训练过程中,模型分片和数据复制技术被用来进一步提高效率。模型分片是指将模型的不同部分分布到不同的芯片上进行处理,这样可以并行地更新模型的参数,加速训练过程。数据复制则是在不同的芯片上复制数据,确保每个芯片都有独立的数据副本进行计算,这有助于减少数据传输的延迟,提高计算效率。
Gemma模型的训练还借助了Jax和Pathways的编程范式。Jax是一个用于高性能机器学习研究的Python库,它允许研究人员以一种简洁和高效的方式表达复杂的神经网络模型。Pathways则是一个用于构建和部署大规模机器学习应用的框架,它提供了一种简化的开发流程,使得处理像Gemma这样的大型模型变得更加容易。
Gemma模型的预训练涉及到使用大量的文本数据来训练模型,以便模型能够理解和生成自然语言。在这个过程中,Gemma模型使用了来自网络文档、数学和代码领域的数据,这些数据主要是英文的。具体来说,2B参数的模型被训练了3万亿个token,而7B参数的模型则训练了6万亿个token,这样的数据量为模型提供了丰富的语言信息和模式。
与Gemini模型不同,Gemma模型在设计时并没有采用多模态技术,也就是说,它没有结合文本之外的其他类型的数据,如图像或视频。此外,Gemma也没有专门针对多语言任务进行训练,这与一些旨在实现多语言理解最先进的性能的模型有所区别。Gemma模型的设计选择反映了DeepMind团队专注于英文文本数据,以实现在特定领域的深度理解和生成能力。
在预训练数据的选择和处理上,Gemma模型的团队采取了谨慎的措施。他们对数据集进行了过滤,目的是减少模型可能生成不良或不安全话语的风险。这包括去除那些可能引发争议或不适当的内容,确保模型在生成文本时能够符合安全和道德标准。
预训练过程中特别注意了个人身份信息和其他敏感数据的过滤。这是因为数据中的个人信息如果被模型学习并在未来生成的文本中使用,可能会引发隐私泄露和安全问题。通过过滤掉这些敏感信息,Gemma模型旨在保护用户的隐私,并遵守数据保护的相关法律法规。
过滤过程不仅涉及到简单的规则和启发式方法,还可能包括更复杂的模型驱动的分类器,这些分类器能够识别并排除有害或低质量的内容。此外,为了进一步确保模型的安全性和可靠性,过滤后的数据还会经过详尽的评估和测试,以检查是否存在潜在的问题。
指令调整
在Gemma模型的开发过程中,指令调整是一个关键步骤,旨在提升模型对用户指令的理解和执行能力。这个过程主要通过两种方法实现:监督式微调(SFT)和基于人类反馈的强化学习(RLHF)。

在SFT阶段,Gemma模型接受了大量文本合成的英语提示响应对的训练。这些数据对由基础模型生成的可能响应和测试模型生成的实际响应组成。通过这种方式,模型学习如何根据给定的指令生成更加准确和有用的回答。SFT的目的是通过直接的监督学习,让模型更好地掌握如何遵循指令和生成合适的输出。
SFT阶段还包括了对模型输出的人类评估。在这一过程中,人类评估员会根据模型生成的回答质量和相关性提供反馈。这些反馈被用来进一步指导和优化模型,使其更符合人类的偏好和期望。
RLHF阶段则采用了一种更为互动的方法来提升模型性能。在这个阶段,模型的表现通过人类提供偏好来评估,即人类评估员会对比模型生成的不同回答,并选择他们认为更好的一个。这些偏好信息被用来训练一个奖励模型,该模型能够捕捉到人类对模型输出的满意度。然后,这个奖励模型指导Gemma模型通过强化学习算法进行优化,以生成更符合人类期望的输出。
在指令调整过程中,数据的质量和安全性至关重要。过滤机制被用来清除那些可能包含个人信息、不安全内容或有毒输出的数据。确保了模型在训练过程中不会被不良数据影响,同时也保护了用户的隐私和安全。

过滤还涉及到去除错误的自我识别数据,即那些可能导致模型错误理解自身身份或功能的信息。此外,任何重复的例子也会被过滤掉,以避免模型过度拟合特定的数据模式,从而影响其泛化能力。
评估
Gemma模型的评估不仅涵盖了自动化的基准测试,还包括了人类评估研究,以确保模型的实际应用能够满足用户的期望和需求。
在自动化基准测试方面,Gemma模型接受了广泛的测试,包括物理推理、社会推理、问题回答、编程、数学、常识推理、语言建模、阅读理解等多个领域。例如,在数学问题解决方面,Gemma模型在GSM8K和MATH基准测试中表现出色,显示出其强大的分析和解决问题的能力。此外,在编程任务的MBPP基准测试中,Gemma模型也超越了其他开放模型,显示了其在代码生成和理解方面的高超技巧。
人类偏好评估是评估过程中的另一个重要部分。Gemma模型的最终版本被提交给人类评估员,与现有的其他模型如Mistral v0.2 7B Instruct模型进行了比较。在一系列约1000个提示的测试中,这些提示旨在让模型执行创意写作任务、编程和遵循指令,Gemma 7B IT模型以61.2%的正面胜率胜过Mistral v0.2 7B Instruct,而Gemma 2B IT模型的胜率为45%。在测试基本安全协议的约400个提示中,Gemma 7B IT模型的胜率为63.5%,Gemma 2B IT模型的胜率为60.1%。
为了确保评估的全面性和公正性,Gemma模型的评估使用了与Gemini模型相同的方法论,并尽可能地模仿了Mistral技术报告中的评估方法。这些评估包括了ARC、CommonsenseQA、Big Bench Hard和AGI Eval等基准测试。由于许可限制,Gemma模型无法在LLaMA-2上运行评估,因此只能引用之前报告的指标。
在安全性方面,Gemma模型同样进行了严格的测试。通过与类似规模的开放模型进行比较,Gemma 1.1 IT模型在多个标准安全基准测试中的表现出色,在6个测试中胜过竞争对手。此外,Gemma模型在人类并行评估中也展现出了优势。
为了评估模型对训练数据的记忆能力,Gemma模型还经过了记忆评估测试。测试结果显示,Gemma模型对英文网络内容的记忆率相当低,这表明模型并没有简单地记忆训练数据,而是能够进行更深入的理解和推理。

通过这些综合评估,Gemma模型证明了自己在各种任务中的高性能和可靠性,同时也展示了其在安全性和抗记忆性方面的优势。这些评估结果为Gemma模型的进一步开发和应用提供了坚实的基础,并为用户提供了对其性能和能力的深入了解。
技术报告:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
使用地址:https://ai.google.dev/gemma
相关文章:
Gemma轻量级开放模型在个人PC上释放强大性能,让每个桌面秒变AI工作站
Google DeepMind团队最近推出了Gemma,这是一个基于其先前Gemini模型研究和技术的开放模型家族。这些模型专为语言理解、推理和安全性而设计,具有轻量级和高性能的特点。 Gemma 7B模型在不同能力领域的语言理解和生成性能,与同样规模的开放模型…...
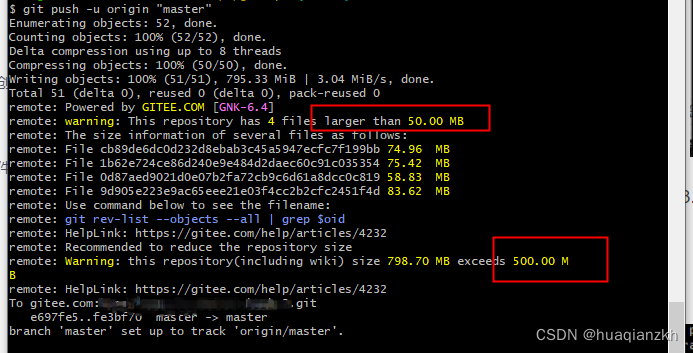
Git使用中遇到的问题(随时更新)
问题1.先创建本地库,后拉取远程仓库时上传失败的问题怎么解决? 操作主要步骤: step1 设置远程仓库地址: $ git remote add origin gitgitee.com:yourAccount/reponamexxx.git step2 推送到远程仓库: $ git push -u origin "master&qu…...

php 跨域问题
设置header <?php $origin isset($_SERVER[HTTP_ORIGIN])? $_SERVER[HTTP_ORIGIN]:;$allow_originarray(http://www.aaa.com,http://www.bbb.com, ); if( $origin in $allow_origin ){header("Access-Control-Allow-Origin:".$origin);header("Access-Co…...

【leetcode52-55图论、56-63回溯】
图论 回溯...
2024 年江西省研究生数学建模竞赛题目 A题交通信号灯管理---完整文章分享(仅供学习)
问题: 交通信号灯是指挥车辆通行的重要标志,由红灯、绿灯、黄灯组成。红灯停、绿灯行,而黄灯则起到警示作用。交通信号灯分为机动车信号灯、非机动车信号灯、人行横道信号 灯、方向指示灯等。一般情况下,十字路口有东西向和南北向…...
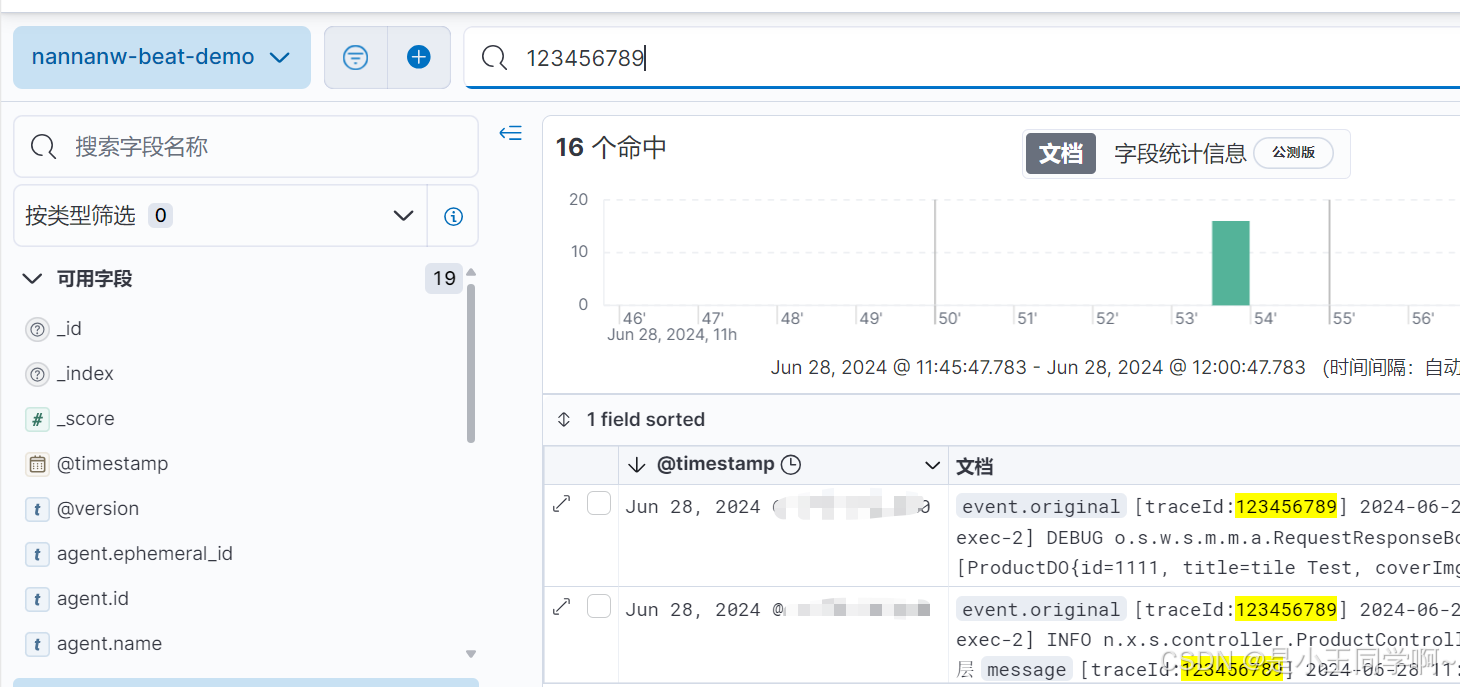
日志可视化监控体系ElasticStack 8.X版本全链路实战
目录 一、SpringBoot3.X整合logback配置1.1 log4j、logback、self4j 之间关系 1.2 SpringBoot3.X整合logback配置 二、日志可视化分析ElasticStack 2.1为什么要有Elastic Stack 2.2 什么是Elastic Stack 三、ElasticSearch8.X源码部署 四、Kibana源码部署 五、LogSta…...

【LinuxC语言】定义线程池结果
文章目录 前言任务结构体线程池定义总结前言 在并发编程中,线程池是一种非常重要的设计模式。线程池可以有效地管理和控制线程的数量,避免线程频繁创建和销毁带来的性能开销,提高系统的响应速度。在Linux环境下,我们可以使用C语言来实现一个简单的线程池。 线程池的主要组…...

uniapp分包
分包是为了优化小程序的下载和启动速度 小程序启动默认下载主包并启动页面,当用户进入分包时,才会下载对应的分包,下载完进行展示。 /* 在manifest.json配置下添加optimization,开启分包优化 */ "mp-weixin" : {/**分包…...
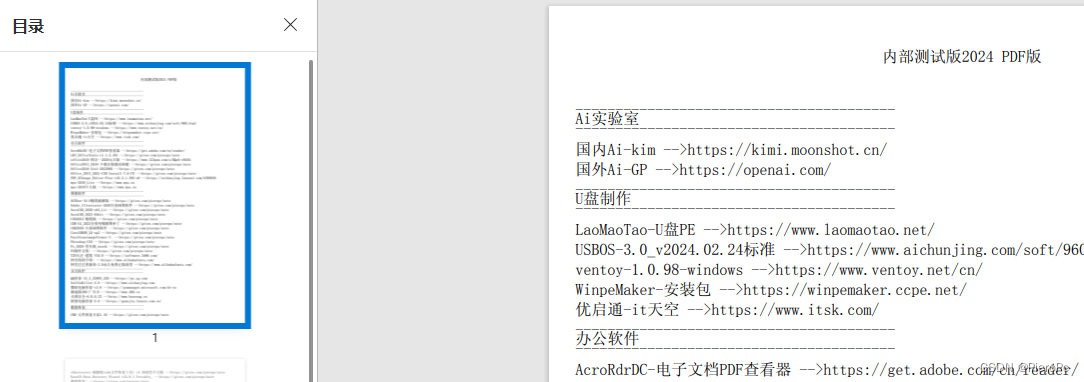
Python 生成Md文件带超链 和 PDF文件 带分页显示内容
software.md # -*- coding: utf-8 -*- import os f open("software.md", "w", encoding"utf-8") f.write(内部测试版2024 MD版\n) for root, dirs, files in os.walk(path): dax os.path.basename(root)if dax "":print("空白…...

行业模板|DataEase旅游行业大屏模板推荐
DataEase开源数据可视化分析工具于2022年6月发布模板市场(https://templates-de.fit2cloud.com),并于2024年1月新增适用于DataEase v2版本的模板分类。模板市场旨在为DataEase用户提供专业、美观、拿来即用的大屏模板,方便用户根据…...

this.$refs[tab.$attrs.id].scrollIntoView is not a function
打印this.$refs[tab.$attrs.id].scrollIntoView 在控制台看到的是一个undefined 是因为this.$refs[tab.$attrs.id] 不是一个dom 是一个vuecomponent 如图所示: 所以我用的这个document.querySelector(.${tab.$attrs.id})获取dom document.querySelector(.${tab.$attrs.id})…...

【AI是在帮助开发者还是取代他们?】AI与开发者:合作与创新的未来
目录 前言一、AI工具现状(一)GitHub Copilot(二)TabNine 二、AI对开发者的影响(一)影响和优势(二)新技能和适应策略(三)保持竞争力的策略 三、AI开发的未来&a…...
【SpringBoot Web框架实战教程(开源)】01 使用 pom 方式创建 SpringBoot 第一个项目
导读 这是一系列关于 SpringBoot Web框架实战 的教程,从项目的创建,到一个完整的 web 框架(包括异常处理、拦截器、context 上下文等);从0开始,到一个可以直接运用在生产环境中的web框架。而且所有源码均开…...

Boosting【文献精读、翻译】
Boosting Bhlmann, P., & Yu, B. (2009). Boosting. Wiley Interdisciplinary Reviews: Computational Statistics, 2(1), 69–74. doi:10.1002/wics.55 摘要 在本文中,我们回顾了Boost方法,这是分类和回归中最有效的机器学习方法之一。虽然我们也讨…...

保姆级教程|如何配置ROS1主从机
在机器人开发经常遇到使用两个板子通信问题,比如一个板子跑底层的运动控制,一个板子跑定位导航。为了确保两个板子之间的ROS通信流畅,我们需要在两个板子的.bashrc文件中添加必要的环境变量配置。首先,确保你的 /etc/hosts 文件中…...
及其Python 和 MATLAB 实现)
贝叶斯优化算法(Bayesian Optimization)及其Python 和 MATLAB 实现
贝叶斯优化算法(Bayesian Optimization)是一种基于贝叶斯统计理论的优化方法,通常用于在复杂搜索空间中寻找最优解。该算法能够有效地在未知黑盒函数上进行优化,并在相对较少的迭代次数内找到较优解,因此在许多领域如超…...

NLP - 基于bert预训练模型的文本多分类示例
项目说明 项目名称 基于DistilBERT的标题多分类任务 项目概述 本项目旨在使用DistilBERT模型对给定的标题文本进行多分类任务。项目包括从数据处理、模型训练、模型评估到最终的API部署。该项目采用模块化设计,以便于理解和维护。 项目结构 . ├── bert_dat…...

数据库备份和还原
一、备份 备份类型 1.完全备份 全备份是指对整个数据集进行完整备份。每次备份都会复制所有选定的数据,无论这些数据是否发生了变化。 2.增量备份 增量备份是指仅备份自上次备份(无论是全备份还是增量备份)以来发生变化的数据。它记录了…...
谷粒商城-个人笔记(集群部署篇一)
前言 学习视频:Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强学习文档: 谷粒商城-个人笔记(基础篇一)谷粒商城-个人笔记(基础篇二)谷粒商城-个人笔记(基础篇三)谷粒商城-个人笔记(高级篇一)谷粒商城-个…...

Linux环境下的字节对齐现象
在Linux环境下,字节对齐是指数据在内存中的存储方式。字节对齐是为了提高内存访问的效率和性能。 在Linux中,默认情况下,结构体和数组的成员会进行字节对齐。具体的对齐方式可以通过编译器选项来控制。 在使用C语言编写程序时,可…...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...