stack、queue和priority_queue
 目录
目录
一、栈(stack)
1.stack的使用
2.容器适配器
3.stack的模拟实现
二、队列(queue)
1.queue的使用
2.queue的模拟实现
三、双端队列(deque)
1.vector,list的优缺点
2.认识deque
四、priority_queue-优先级队列
1.priority_queue的使用
2.priority_queue的模拟实现
3.仿函数
一、栈(stack)
1.stack的使用
stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
相信stack的使用大家都已经熟悉了,下面的所有接口也都很好理解:

测试代码:
#include<iostream>
#include<stack>
using namespace std;void test()
{stack<int> s;s.push(1);s.push(2);s.push(3);s.push(4);while (!s.empty()){cout << s.top() << " ";s.pop();}
}int main()
{test()return 0;
}2.容器适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。简单而言,就是将一个类设计为另一个类的封装。
比如说,下面的stack和queue的实现就是一个很好的例子。
设计模式的使用将提高软件系统的开发效率和软件质量,节省开发成本。有助于初学者深入理解面向对象思想,设计模式使设计方案更加灵活,方便后期维护修改。
3.stack的模拟实现
我们之前提到过代码的复用,既然已经有现成的东西了,我为什么不用呢?
stack在我们看来是一个容器,数据只能后进先出,这个容器可以是vector,也可以是list甚至更多的数据结构。也就是说我们如果以vector作为stack的底层数据结构,stack的尾插就可以使用vector的push_back(),尾删就可以使用vector的pop_back()。以vector作为stack的底层数据结构也是一样的,只是使用了list的接口,这就是一种适配器的模式。
stack是一个模板类,有两个模板参数,T标识存储的数据类型,container表示实现stack的底层数据结构。
stack我们更常用vector作为被封装的类
#pragma once
#include<vector>
#include <list>namespace my_stack
{template<class T, class container = deque<T>>class stack{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}const T& top(){return _con.back();}bool empty(){return _con.empty();}size_t size(){return _con.size();}private:container _con;};
}二、队列(queue)
1.queue的使用
队列也是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素。

queue的接口也差不多:

测试代码:
#include<iostream>
#include<queue>
using namespace std;void test()
{queue<int> q;q.push(1);q.push(2);q.push(3);q.push(4);while (!s.empty()){cout << s.front() << " ";q.pop();}
}int main()
{test()return 0;
}2.queue的模拟实现
依然是代码的复用,不过这次是先进先出。
queue我们更常用list作为被封装的类
#pragma once
#include<vector>
#include<list>namespace my_queue
{template<class T, class container = deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& top(){return _con.back();}bool empty(){return _con.empty();}size_t size(){return _con.size();}private:container _con;};
}三、双端队列(deque)
在stack和deque中都有一个缺省的被封装的类以实现适配器,这个缺省值为什么既不是vector也不是list,而是deque呢?最主要的原因还是vector,list各有其优缺点。
1.vector,list的优缺点
vector
优缺点:支持随机访问,但是头部和中部的插入删除效率低,并且还需要扩容操作。
list
优缺点:list在任何地方插入删除效率都很高,但是链表不支持随机访问,且CPU高速缓存命中率低(CPU在访问内存时往往是取一块较大的内存,然后再其中找对应的数据位置,链表开辟的每一个节点的地址位置时不确定的,所以相比于连续的vector,缓存的命中率低)
而deque这个类是一个缝合怪,它既有vector的随机访问,也有list的高效率插入删除。所以对于这里选择deque最好。
2.认识deque
(1)底层原理
我们再cplusplus网站中可以查看deque:
deque - C++ Reference (cplusplus.com)
这是deque实现的思路:
deque是由中控和一段一段的buffer数组组成的,也就是说deque并不是完全连续的空间,它是由一段一段这样的buffer数组通过算法拼接而成,而所谓中控其实是一个指针数组,每一个元素都保存着各个buffer的数组指针。我们可以大致理解为C语言中的二维数组或者C++的vector>。

它的头尾插大概是这样的:
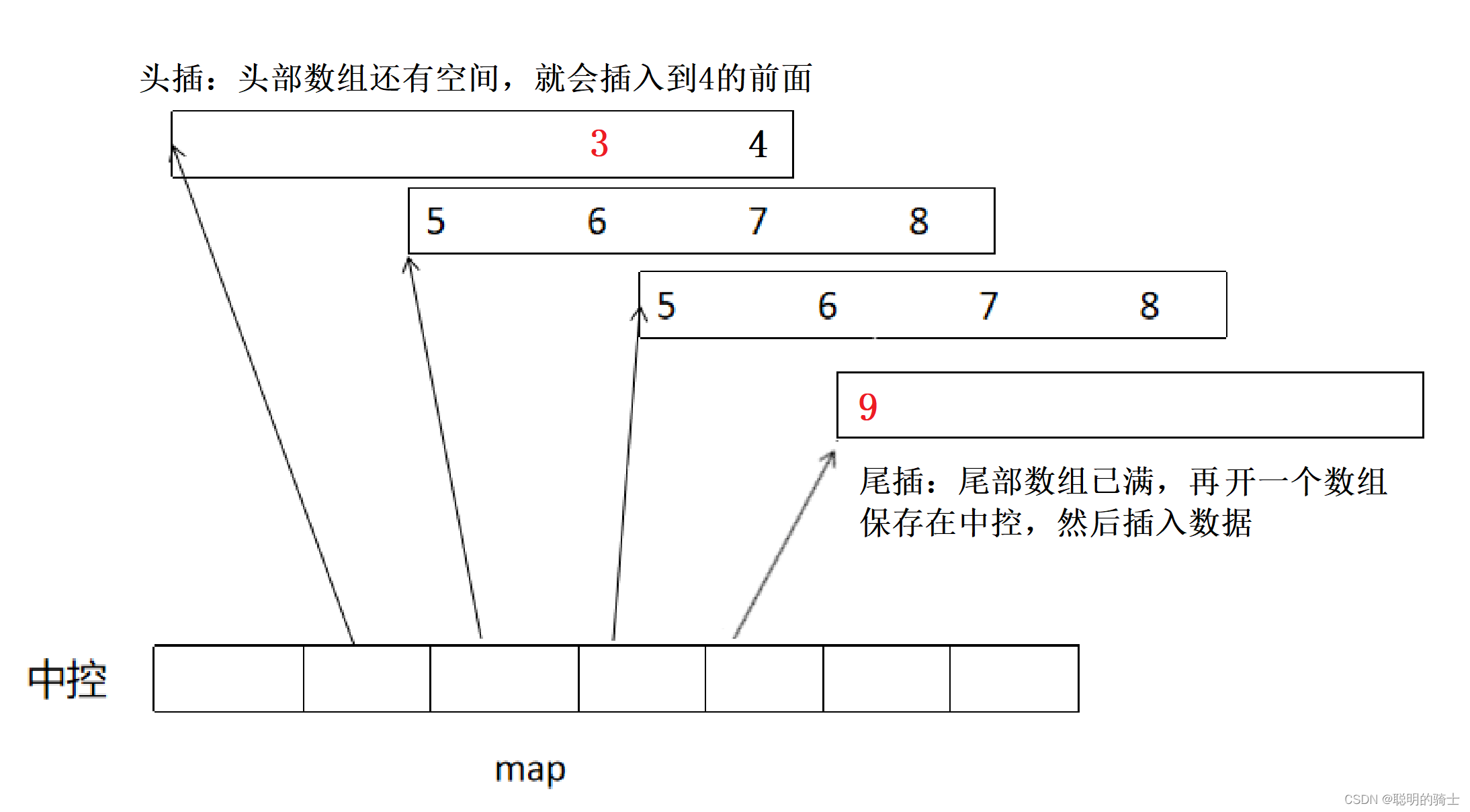
查找也是一样,先在map找buffer,再在buffer找数据。
我们可以很明显地发现它的下标访问相比vector一定是复杂而又缓慢的。当deque在中间插入数据时,它挪动数据的算法可就比vector复杂多了,与list相比的消耗就更大了。
(2)迭代器
由于deque的迭代器设计也很复杂,所以deque不适合遍历操作。在遍历时,deque的迭代器要频繁地检测其是否移动到数组buffer的的边界,这就导致它的访问效率很低下。而在现实中,遍历操作的使用是很频繁的,所以需要线性结构时,大多数情况下都会考虑vector和list,deque的应用很少,而我们目前能看到的一个就是:在STL中作为stack和queue的底层数据结构。
我们大致看一下它的迭代器的实现:
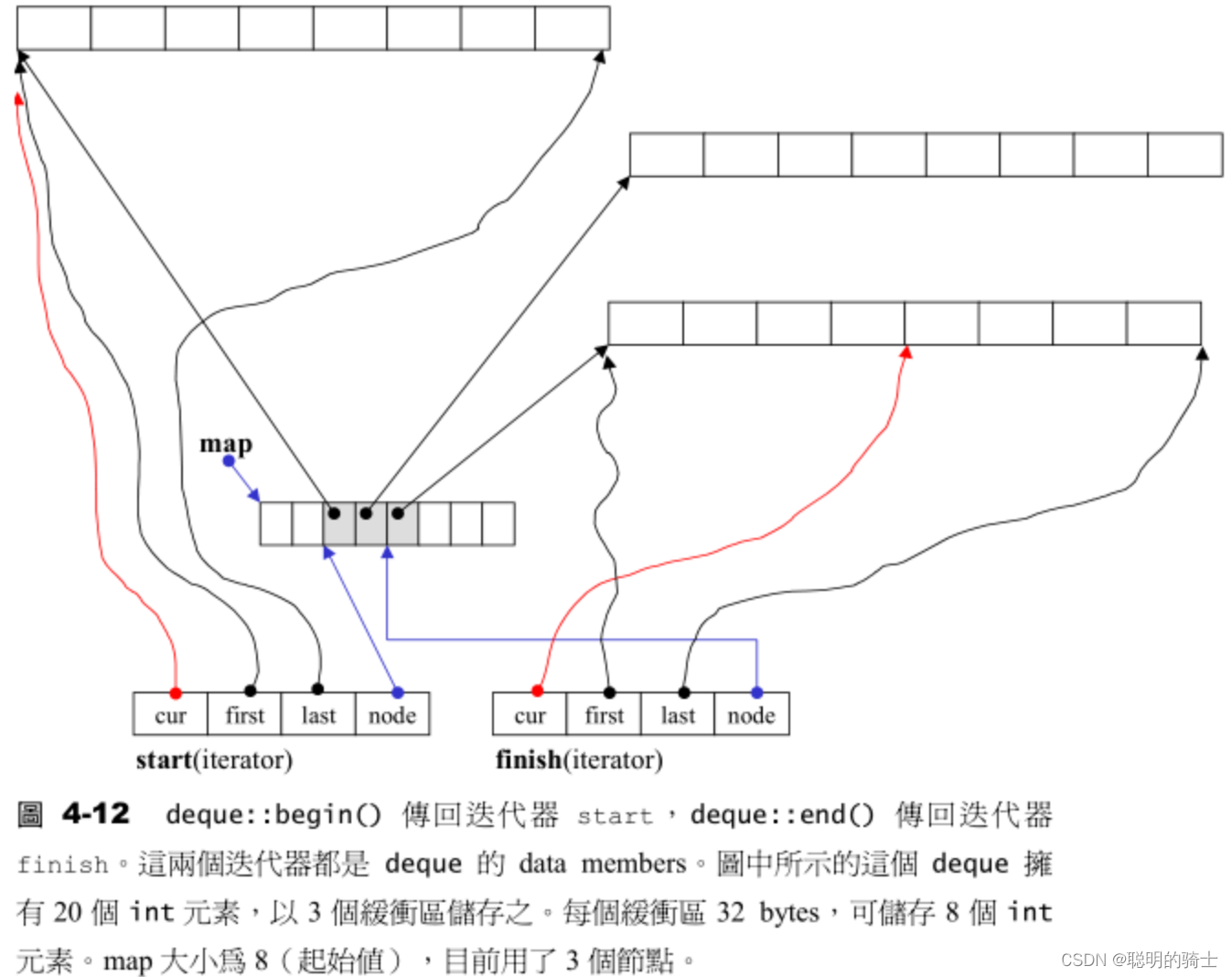
deque的维护需要两个迭代器,分别是start和finsh。因为deque更多时候是作为stack和queue的底层默认容器来使用的,所以一般deque是不需要在中间插入数据的,那么有了分别指向数据头尾的start和finsh就可以很好地处理头插与尾插。迭代器中的frist和last指向buffer的头尾,如果buffer满了,就可以通过node链接到map主控再新开辟buffer。其中的头部和尾部数据获取top()和back()就通过start的cur和finish的cur控制。
总的来说,deque虽然集成了vector和list的优点,但它也不是完美的,而在写代码中我们大部分时间都会追求极致,它也就很少用到了。
四、priority_queue-优先级队列
优先级队列(priority_queue)虽然叫队列,但它不满足先进先出的条件,优先级队列会保证每次出队列的元素是队列所有元素中优先级最高的那个元素,这个优先级可以通过元素的大小等进行定义。比如定义元素越大(或越小)优先级越高,那么每次出队,都是将当前队列中最大(最小)的那个元素出队,它的底层其实就是一个堆,也就是二叉树的结构。
1.priority_queue的使用
priority_queue的使用来说也是比较简单的,接口也比较少。

测试代码:
#include<iostream>
using namespace std;
void test()
{priority_queue<int> p;p.push(7);p.push(1);p.push(9);p.push(2);p.push(3);p.push(4);while (!p.empty()){cout << p.top() << " ";p.pop();}
}
int main()
{test();return 0;
}2.priority_queue的模拟实现
我这里建的是小堆,大堆也是同理,如果不记得向上向下调整,可以看这里:
(6条消息) 二叉树详解_聪明的骑士的博客-CSDN博客
template<typename T, class container = vector<T>>
class priority_queue
{
public:template<class iterator>priority_queue(iterator first, iterator last)//建堆:_con(first, last){for (size_t i = (_con.size() - 1 - 1) / 2; i >= 0; --i)//所有节点的父节点全部向下调整,size()减1得到尾下标,再减1除2得到父节点{adjust_down(i);}}void adjust_down(size_t parent){size_t min_child = parent * 2 + 1;while (min_child < _con.size()){if (min_child + 1 < _con.size() && _con[min_child] > _con[min_child + 1]){minchild++;}if (_con[min_child] < _con[parent]){std::swap(_con[min_child], _con[parent]);parent = min_child;min_child = parent * 2 + 1;}elsebreak;}}void adjust_up(size_t child){size_t parent = (child - 1) / 2;while (parent >= 0){if (_con[parent] > _con[child]){std::swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}elsebreak;}}void push(const T& x){_con.push_back(x);_con.adjust_up(_cons.size() - 1);}void pop(){assert(!_con.empty());std::swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);}const T& top(){return _con[0];}const empty() const{return _con.empty();}size_t size() const{return _con.size();}private:container _con;
};3.仿函数
(1)什么是仿函数
仿函数(functor),就是使一个类的使用看上去像一个函数。本质就是在类中实现一个()的重载函数,这个类就有了类似函数的行为,就成为一个仿函数类了。
namespace function
{template<class T>class less{public:bool operator()(const T& x, const T& y){return x < y;}};template<class T>class more{public:bool operator()(const T& x, const T& y){return x > y;}};
}
int main()
{function::less<int> lessFunc;//创建一个变量if (lessFunc(3, 2))//用变量也可以达到函数的效果cout << "yes" << endl;elsecout << "no" << endl;return 0;
}(2)仿函数的使用
我们写一个插入排序
namespace sort
{template<class T>void insert_sort(T* arr, size_t size){int i = 1;for (i = 1; i < size; ++i){int j = i;while (j > 0){if (arr[j - 1] < arr[j]){std::swap(arr[j - 1], arr[j]);--j;}elsebreak;}}}
}排序一个数组
int main()
{int arr[10] = { 9,8,7,6,5,4,3,2,1,0 };sort::insert_sort<int>(arr, sizeof(arr) / sizeof(arr[0]));for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){printf("%d ", arr[i]);}
}
//结果:0 1 2 3 4 5 6 7 8 9我们发现,如果我们想把数组排为降序,那么就要改变底层代码中的arr[j - 1] < arr[j]变为arr[j - 1] > arr[j],再大部分情况下,使用者都是不能看到代码的实现的,使用者也就不能更改为排降序。那么我们是否可以通过加一个函数指针来实现呢?
template
void insert_sort(T* arr, size_t size, bool (*ptr)(int, int))
函数指针最直观的特点就是它太不直观了,阅读性很低,而且这个函数还要传递更多的参数。
所以我们为什么部添加一个仿函数的模板参数来实现升降序的控制呢?
我们修改一下,就可以正常运行了:
template<class T, typename compare>
void insert_sort(T* arr, size_t size, typename compare)
{int i = 1;for (i = 1; i < size; ++i){int j = i;while (j > 0){if (compare(arr[j - 1], arr[j])){std::swap(arr[j - 1], arr[j]);--j;}else{break;}}}
}void test_insertSort()
{func::less<int> lessFunc;int arr[] = { 9,8,7,6,5,4,3,2,1,0 };insert_sort(arr, sizeof(arr) / sizeof(arr[0]), lessFunc);for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++){printf("%d ", arr[i]);}
}int main()
{test_insertSort();return 0;
}在比较内置类型时,可以直接使用大于小于号,而比较自定义类型的大小,我们可以通过大于小于的重载确定类型比较大小的方式。但是如果传递的参数是指针类型,我们传指针大部分时候都是为了比较指针指向的数据,如果只是比较指针的数值本身,就失去比较的意义了。
那么对于指针的比较就不应该沿用之前的比较方式,所以我们创建一个struct(类-默认公共类),然后通过函数模板的调用,实现了比较非自定义变量指针的大小,相当于堆指针的特殊化处理。
#include <iostream>
#include <queue>
#include <functional>using namespace std;class Date
{
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}private:int _year;int _month;int _day;
};struct PDateLess
{bool operator()(const Date* d1, const Date* d2){return *d1 < *d2;}
};struct PDateGreater
{bool operator()(const Date* d1, const Date* d2){return *d1 > *d2;}
};void TestPriorityQueue()
{// 大堆,需要用户在自定义类型中提供<的重载priority_queue<Date> q1;q1.push(Date(2018, 10, 29));q1.push(Date(2018, 10, 28));q1.push(Date(2018, 10, 30));cout << q1.top() << endl;// 如果要创建小堆,需要用户提供>的重载priority_queue<Date, vector<Date>, greater<Date>> q2;q2.push(Date(2018, 10, 29));q2.push(Date(2018, 10, 28));q2.push(Date(2018, 10, 30));cout << q2.top() << endl;// 大堆priority_queue<Date*, vector<Date*>, PDateLess> q3;q3.push(new Date(2018, 10, 29));q3.push(new Date(2018, 10, 28));q3.push(new Date(2018, 10, 30));cout << *q3.top() << endl;// 小堆priority_queue<Date*, vector<Date*>, PDateGreater> q4;q4.push(new Date(2018, 10, 29));q4.push(new Date(2018, 10, 28));q4.push(new Date(2018, 10, 30));cout << *q4.top() << endl;
}int main()
{TestPriorityQueue();return 0;
}相关文章:
stack、queue和priority_queue
目录 一、栈(stack) 1.stack的使用 2.容器适配器 3.stack的模拟实现 二、队列(queue) 1.queue的使用 2.queue的模拟实现 三、双端队列(deque) 1.vector,list的优缺点 2.认识deque 四…...
面试题(二十二)消息队列与搜索引擎
2. 消息队列 2.1 MQ有什么用? 参考答案 消息队列有很多使用场景,比较常见的有3个:解耦、异步、削峰。 解耦:传统的软件开发模式,各个模块之间相互调用,数据共享,每个模块都要时刻关注其他模…...
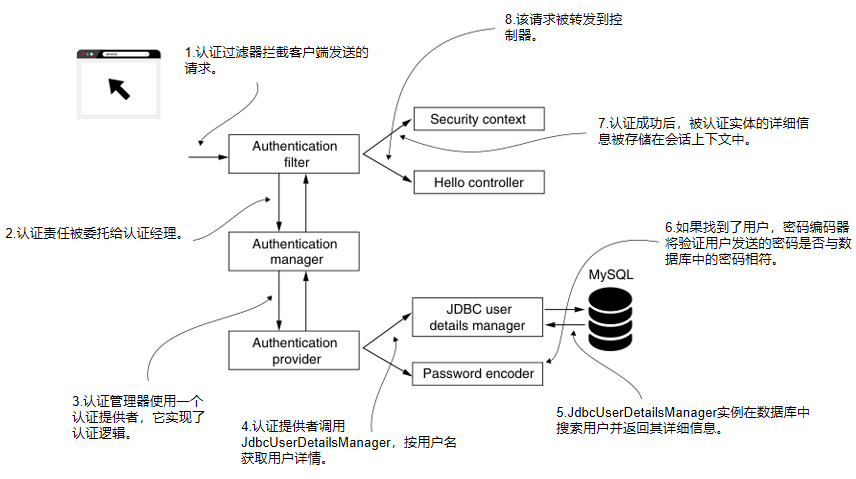
Spring Security in Action 第三章 SpringSecurity管理用户
本专栏将从基础开始,循序渐进,以实战为线索,逐步深入SpringSecurity相关知识相关知识,打造完整的SpringSecurity学习步骤,提升工程化编码能力和思维能力,写出高质量代码。希望大家都能够从中有所收获&#…...

Java面试——maven篇
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

基于微信小程序的游戏账号交易小程序
文末联系获取源码 开发语言:Java 框架:ssm JDK版本:JDK1.8 服务器:tomcat7 数据库:mysql 5.7/8.0 数据库工具:Navicat11 开发软件:eclipse/myeclipse/idea Maven包:Maven3.3.9 浏览器…...
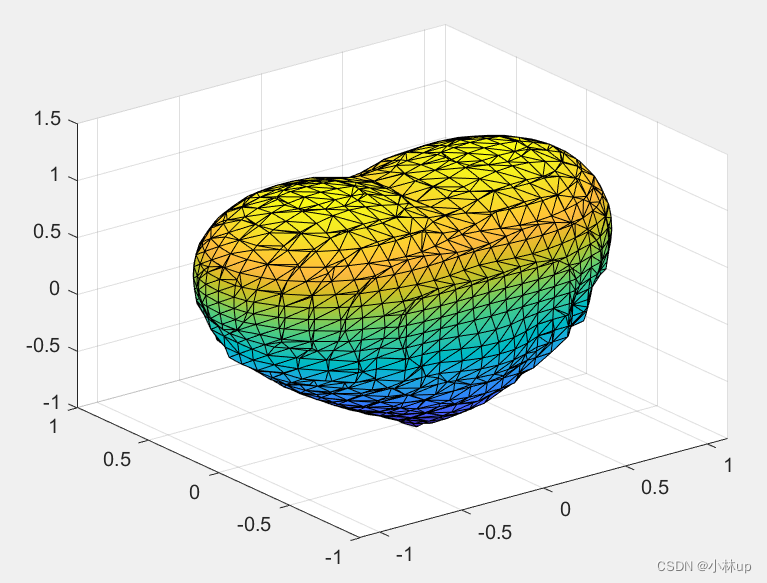
Matlab绘制隐函数总结-二维和三维
1.二维隐函数 二维隐函数满足f(x,y)0f(x,y)0f(x,y)0,这里无法得到yf(x)yf(x)yf(x)的形式。不能通过普通函数绘制。 我们要关注的是使用fplot函数和fimplicit函数。 第1种情况:基本隐函数 基本的隐函数形式形如: x2y22x2(x2y2)12x^{2}y^{…...

如何直观地理解傅立叶变换?频域和时域的理解
如何直观地理解傅立叶变换 傅里叶变换连续形式的傅立叶变换如何直观地理解傅立叶变换?一、傅里叶级数1.1傅里叶级数的三角形式1.2 傅里叶级数的复指数形式二、傅里叶变换2.1一维连续傅里叶变换三、频谱和功率谱3.1频谱的获得3.2频谱图的特征3.3频谱图的组成频域(frequency do…...
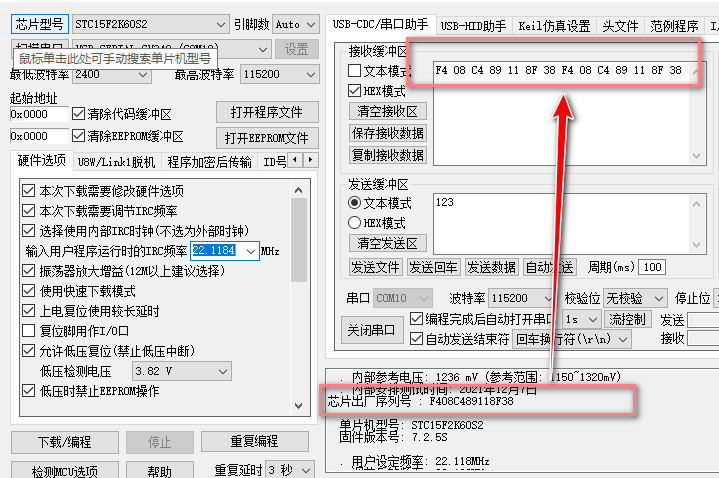
STC15读取内部ID示例程序
STC15读取内部ID示例程序🎉本案例基于STC15F2K60S2为验证对象。 📑STC15 ID序列介绍 STC15系列STC最新一代STC15系列单片机出厂时都具有全球唯一身份证号码(ID号)。最新STC15系列单片机的程序存储器的最后7个字节单元的值是全球唯一ID号,用…...
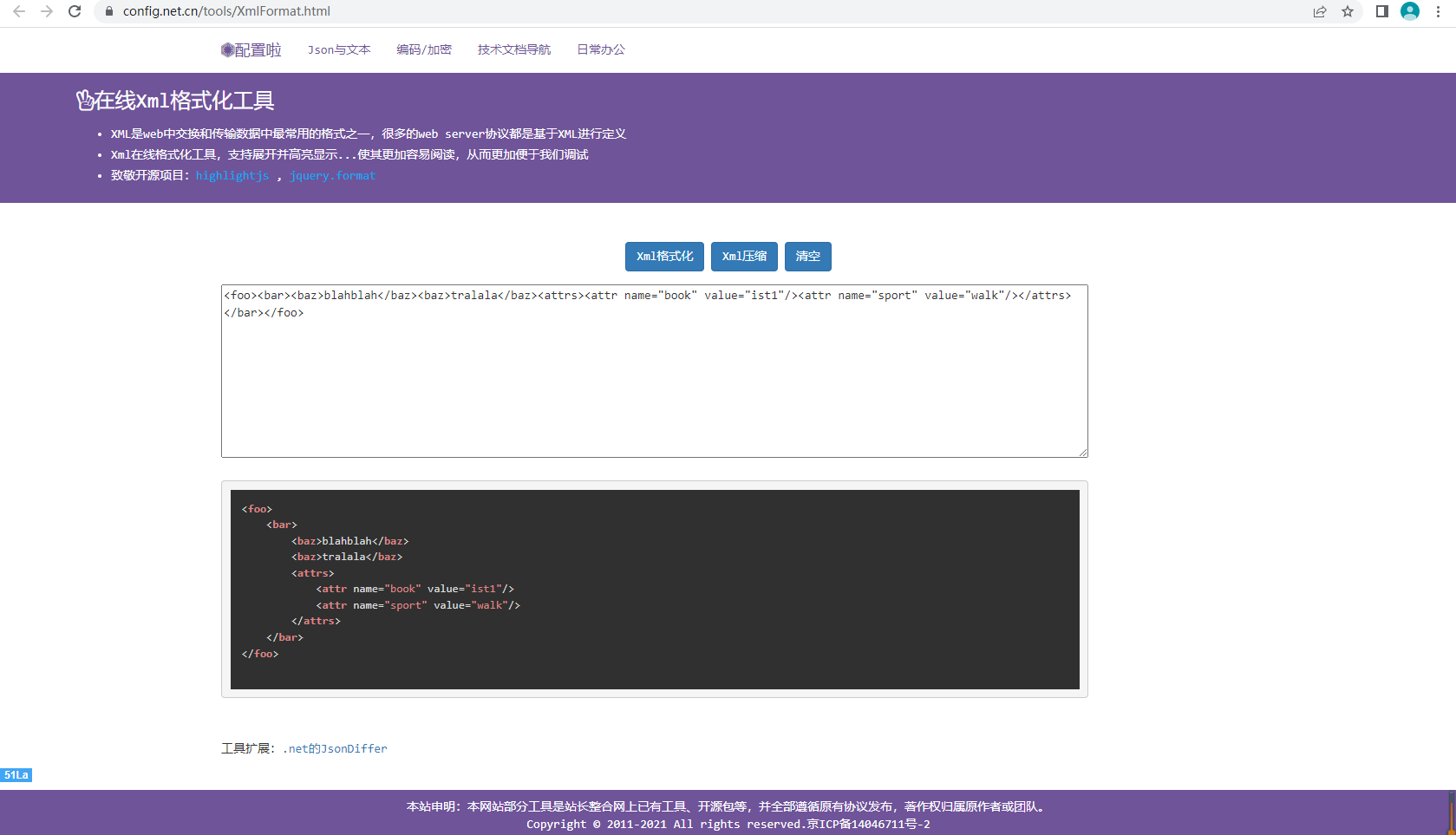
Xml格式化与高亮显示
具体请参考:Xml格式化与高亮显示...

【GlobalMapper精品教程】045:空间分析工具(2)——相交
GlobalMapper提供的空间分析(操作)的方法有:交集、并集、单并集、差异、对称差集、相交、重叠、接触、包含、等于、内部、分离等,本文主要讲述相交工具的使用。 文章目录 一、实验数据二、符号化设置三、相交运算四、结果展示五、心灵感悟一、实验数据 加载配套实验数据(…...
4年外包终上岸,我只能说这类公司能不去就不去..
我大学学的是计算机专业,毕业的时候,对于找工作比较迷茫,也不知道当时怎么想的,一头就扎进了一家外包公司,一干就是4年。现在终于跳槽到了互联网公司了,我想说的是,但凡有点机会,千万…...
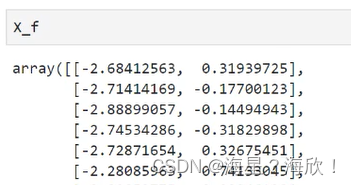
sklearn降维算法1 - 降维思想与PCA实现
目录1、概述1.1 维度概念2、PCA与SVD2.1 降维实现2.2 重要参数n_components2.2.1 案例:高维数据的可视化2.2.2 最大似然估计自选超参数2.2.3 按信息量占比选超参数1、概述 1.1 维度概念 shape返回的结果,几维几个方括号嵌套 特征矩阵特指二维的 一般来…...

「期末复习」线性代数
第一章 行列式 行列式是一个数,是一个结果三阶行列式的计算:主对角线的乘积全排列与对换逆序数为奇就为奇排列,逆序数为偶就为偶排列对换:定理一:一个排列的任意两个元素对换,排列改变奇偶性(和…...
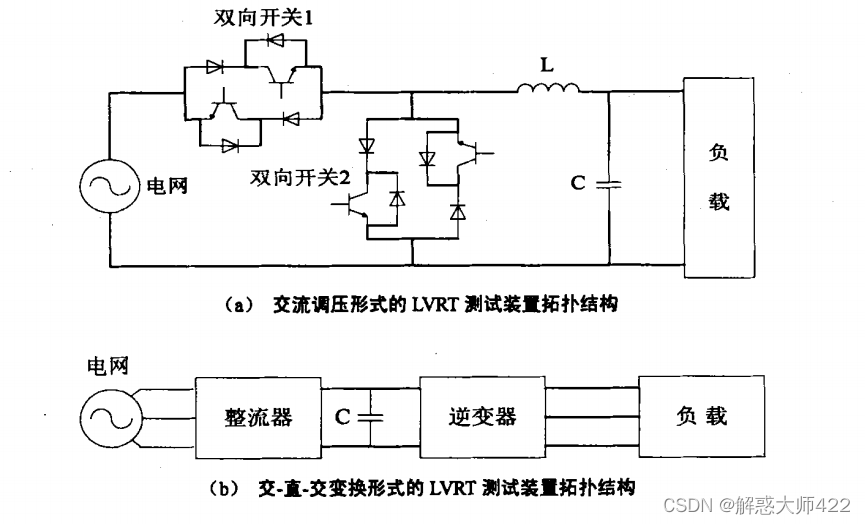
伏并网低电压穿越技术
国内光伏并网低电压穿越要求 略: 低电压穿越方法 当前,光伏电站实现低电压穿越可通过两种方式,即增加硬件设备或者改变控制策略。本节对基于储能设备、基于无功补偿设备、基于无功电流电压支撑控制策略三种实现LVRT的典型方法进行介绍。 …...
opencv的环境搭建
大家好,我是csdn的博主:lqj_本人 这是我的个人博客主页: lqj_本人的博客_CSDN博客-微信小程序,前端,python领域博主lqj_本人擅长微信小程序,前端,python,等方面的知识https://blog.csdn.net/lbcyllqj?spm1011.2415.3001.5343哔哩哔哩欢迎关注…...

C++智能指针
c11的三个智能指针 unique_ptr独占指针,用的最多 shared_ptr记数指针,其次 weak_ptr,shared_ptr的补充,很少用 引用他们要加上头文件#include unique_ptr独占指针: 1.只能有一个智能指针管理内存 2.当指针超出作用域…...
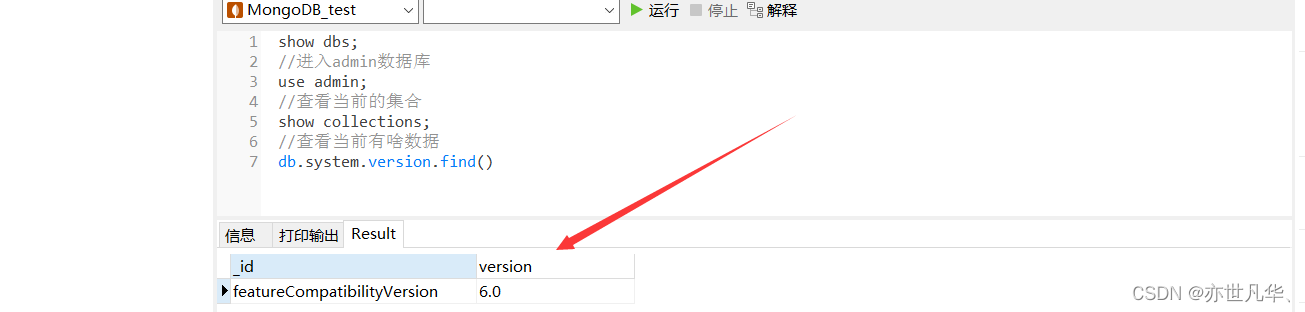
MongoDB--》MongoDB数据库以及可视化工具的安装与使用—保姆级教程
目录 数据库简介 MongoDB数据库的安装 MongoDB数据库的启动 MongoDB数据库环境变量的配置 MongoDB图形化管理工具 数据库简介 在使用MongoDB数据库之前,我们应该要知道我们使用它的原因: 在数据库当中,有常见的三高需求: Hi…...

JAVA 基础题
1. 面向对象有哪些特征?答:继承、封装、多态2. JDK与JRE的区别是什么?答:JDK是java开发时所需环境,它包含了Java开发时需要用到的API,JRE是Java的运行时环境,JDK包含了JRE,他们是包含…...

Flutter desktop端多屏幕展示问题处理
目前越来越多的人用Flutter来做桌面程序的开发,很多应用场景在Flutter开发端还不是很成熟,有些场景目前还没有很好的插件来支持,所以落地Flutter桌面版还是要慎重。 下面来说一下近期我遇到的一个问题,之前遇到一个需要双屏展示的…...

每天10个前端小知识 【Day 9】
👩 个人主页:不爱吃糖的程序媛 🙋♂️ 作者简介:前端领域新星创作者、CSDN内容合伙人,专注于前端各领域技术,成长的路上共同学习共同进步,一起加油呀! ✨系列专栏:前端…...

Linux文件搜索新标杆:FSearch高效检索工具全攻略
Linux文件搜索新标杆:FSearch高效检索工具全攻略 【免费下载链接】fsearch A fast file search utility for Unix-like systems based on GTK3 项目地址: https://gitcode.com/gh_mirrors/fs/fsearch 在Linux系统中,面对日益增长的文件数据&#…...

MAA助手跨平台部署与自动化实践指南
MAA助手跨平台部署与自动化实践指南 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址: https://gitcode.com/GitHub_Trending/ma/…...
)
SAP PP顾问必看:手把手教你用增强PPCO0001实现CO02工单变更记录(附完整ABAP代码)
SAP PP顾问实战:深度解析PPCO0001增强实现CO02工单变更审计 在制造业SAP实施项目中,生产工单的变更追踪一直是合规审计的重点难点。当用户通过CO02事务码修改工单时,标准系统提供的变更记录功能存在明显局限——既无法满足精细审计需求&…...
)
python 文件管理库 Path 解析(详细基础)
1 Path库能做什么: Path库是python常见的文件操作库(以对象形式操作文件路径),可以进行以下操作: 文件路径的拼接(example: test / Your_path / files ) 文件地址的提取(提取名称、…...

KK-HF Patch技术指南:从安装到优化的完整解决方案
KK-HF Patch技术指南:从安装到优化的完整解决方案 【免费下载链接】KK-HF_Patch Automatically translate, uncensor and update Koikatu! and Koikatsu Party! 项目地址: https://gitcode.com/gh_mirrors/kk/KK-HF_Patch 价值定位:为什么选择KK-…...

2025届毕业生推荐的五大AI辅助论文神器推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 想要降低AIGC(人工智能生成内容)检测率,要从文本特征着手…...

新手入门指南:在快马平台上学习openclaw升级命令的基础与实践
今天想和大家分享一下我在学习openclaw升级命令时的一些心得。作为一个刚接触命令行工具的新手,一开始看到那些复杂的参数和选项确实有点懵,但通过InsCode(快马)平台的实践,我发现其实掌握起来并没有想象中那么难。 认识openclaw的基本概念 …...

WSL配置文件路径全解析:从.wslconfig到wsl.conf
1. WSL配置文件基础:为什么需要它们? 如果你刚开始使用Windows Subsystem for Linux(WSL),可能会对两种配置文件感到困惑:全局的.wslconfig和本地的wsl.conf。这两种文件就像是WSL世界的"遥控器"…...

为什么你的Windows桌面需要Rainmeter?5个终极个性化定制秘籍
为什么你的Windows桌面需要Rainmeter?5个终极个性化定制秘籍 【免费下载链接】rainmeter Desktop customization tool for Windows 项目地址: https://gitcode.com/gh_mirrors/ra/rainmeter 想象一下,你的Windows桌面是否还停留在默认的蓝色背景和…...

私有化部署Qwen3-VL:30B:内网穿透技术实现远程访问
私有化部署Qwen3-VL:30B:内网穿透技术实现远程访问 1. 引言 企业内部部署大模型已经成为AI应用的新趋势,特别是对于Qwen3-VL:30B这样的多模态大模型,私有化部署既能保证数据安全,又能提供稳定的服务性能。但在实际部署过程中&am…...