14-41 剑和诗人15 - RLAIF 大模型语言强化培训

介绍
大型语言模型 (LLM) 在自然语言理解和生成方面表现出了巨大的能力。然而,这些模型仍然存在严重的缺陷,例如输出不可靠、推理能力有限以及缺乏一致的个性或价值观一致性。
为了解决这些限制,研究人员采用了一种名为“人工智能反馈强化学习”(RLAIF)的新技术。在 RLAIF 中,人工智能系统会对其自身行为和输出提供反馈,从而通过强化学习过程完善和提高自身。当应用于 LLM 时,RLAIF 提供了一种有趣的途径来灌输有益的行为,提高模型的安全性和可靠性。
为了介绍这一点,首先,我将讨论这项技术背后的主要动机和期望。接下来,我将深入研究所涉及的技术细节和算法。最后,我将调查 RLAIF 在价值对齐、意图分类和对话一致性等领域的一些最新和最有前景的应用。
到最后,您将深入了解人工智能安全和 LLM 研究前沿的这一关键进步。这里描述的技术前景广阔,但也面临着巨大的挑战和悬而未决的问题。总的来说,RLAIF 代表了一个令人兴奋的新方向,可以克服迄今为止困扰 LLM 的稳健性和可靠性问题。
大模型语言 (LLM) 中 RLAIF 背后的动机
在深入探讨技术细节之前,首先值得探讨一下 RLAIF 为何如此吸引 LLM 研究人员。哪些关键问题推动了其发展,它提供了哪些理想的特性?有几个主要卖点使 RLAIF 成为一条有希望的前进之路:
提高可靠性和稳健性
LLM 的一个长期问题是输出不可靠。细微畸形的输入可能会触发自信但明显不正确或无意义的响应。研究人员推测,GPT-4/LLaMA-2/Gemini 1.5 等模型中参数的规模会导致虚假统计模式的脆弱过度放大。RLAIF 为模型提供了一种系统途径,以确定其输出何时不足并相应地进行改进。通过提供有关故障和不良行为的反馈,RLAIF 可以潜在地增强跨边缘情况的稳健性。
提高透明度和可解释性
随着 LLM 功能越来越强大,用户越来越需要了解系统行为、限制和故障模式。然而,像 GPT-4 这样的系统的内部运作非常复杂,甚至连开发人员都很难解释为什么输出会以这种方式出现。通过形式化反馈渠道,RLAIF 为更透明和可解释的系统奠定了基础。模型可以更好地表达其优势、劣势以及产生响应的总体过程。
为有益行为搭建支架
人工智能伦理学的一个长期愿景是,从头开始可扩展地为模型灌输有益的目标和价值观。RLAIF 代表 LLM 朝着这一目标迈出了一步。反馈和强化过程引导系统远离不良行为,转向符合人类价值观的更具建设性的行为。早期工作探索了价值观一致、真实性和无毒性的技术。随着 RLAIF 的成熟,希望预训练模型能够通过这一自我完善过程从根本上实现稳定性和完整性。
迈向安全递归自我完善之路
在更先进的未来,人工智能系统可能会进行递归式自我改进 (RSI)——快速迭代地增强自身智能。虽然 RSI 有望带来巨大的好处,但不受控制的 RSI 也有可能大规模地产生有害行为。RLAIF 通过将增强植根于外部反馈和首选结果,为自我改进提供了一个“安全”的框架。如果模型能够进行稳健的自我反思并将成长引导到有用性上,那么 RLAIF 系统理论上可以安全地扩展到非凡的能力。
这四个激励人心的愿望强调了为什么 RLAIF 在 LLM 圈子中受到极大欢迎。它准确地攻击了阻碍可靠采用的失败模式,如脆弱性和意外伤害。然而,在实现这一有希望的潜力之前,研究人员必须解决一系列技术挑战,以形式化有效的学习框架。下一节将探讨成功应用 RLAIF 所涉及的这些算法细节。
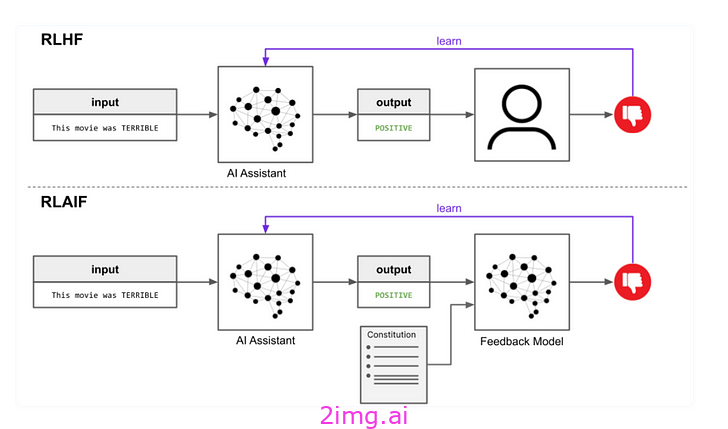
将 RLAIF 应用于 LLMS 的技术基础
强化学习在人工智能领域有着悠久的历史,其根基是马尔可夫决策过程和动态规划等公式。研究人员必须创造性地采用这些技术,以体现 RLAIF 对现代 LLM 的优势。本节将介绍当前支撑 RLAIF 系统的关键技术要素和算法。我将重点介绍直觉,并将严格的数学细节留给外部参考。核心要素包括:
- 定义适当的行动和奖励
- 用于提供反馈的数据集
- 建筑变革引发的自我反思
- 优化程序而非偏好
- 信用分配的挑战
理解这些部分构成了在 LLM 中成功安装 RLAIF 的算法基础。研究人员以这些元素为基础,瞄准更多应用目标,如真实性和避免伤害。后面的部分将重点介绍一些最有前景的方向。不过,首先,让我们为技术基础建立直觉。
定义适当的行动和奖励
任何强化学习设置都需要明确定义两个关键元素:代理可以采取的一组操作,以及提供对这些操作的反馈的奖励信号。在游戏和机器人等典型应用中,这些定义很简单。例如,下棋的代理会选择动作,并接收胜利和失败作为反馈。
然而,将强化学习应用于 LLM 会使清晰地形式化动作和奖励变得更加棘手。像 GPT-3 这样的模型可以在开放式环境中生成自由格式的文本。研究人员必须将这一巨大的可能性空间提炼为易于优化的编码行为。
早期的方法直接关注文本输出本身,设计奖励来塑造语法、长度、关键词等生成属性。然而,对原始文本输出进行操作会受到感知混叠挑战和优化环境中的稀疏性的影响。更有效的框架利用元学习让模型为自己提供行为反馈。例如,系统不是直接评估文本属性,而是对其输出执行辅助预测或分类任务,判断它们是否实现了预期目标。常见的辅助任务包括毒性检测、事实性预测、一致性检查和真诚性分析。然后,强化信号优化模型,使输出与这些次要空间中声明的目标保持一致。本质上,研究人员将部分偏好学习外包给中间的自我监督步骤。
此外,架构可以提供额外的信号作为有益行为的辅助奖励,例如承认无知并在适当的时候要求澄清。总体而言,创造性的辅助任务设计对于将有效的强化算法移植到 LLM 中仍然至关重要。如果不仔细考虑塑造行为空间,就会出现不稳定、博弈和不良行为。奖励黑客仍然是一个始终存在的挑战,需要主动进行工程设计以进行调整。
用于提供反馈的数据集
在确定了行动和奖励之后,RLAIF 系统还需要大量数据集来提供反馈。在标准强化学习中,与环境的在线交互提供了体验式监督。但对于 LLM,出于效率方面的考虑,需要大规模离线语料库。研究人员利用三个主要来源:
- 标记数据集:评估行为的(文本、标签)对的集合,例如有害评论分类器和事实注释。
- 自监督任务:比较模型样本的辅助生成目标,例如通过自洽进行诚意预测。
- 人类偏好:人类判断比较模型输出,得出一致结论,使系统更受欢迎。
这些来源为强化优化提供了核心数据。前两个来源具有便利性和可扩展性,可以根据所需标准自动对行为进行评分。然而,它们也受到数据集偏差、博弈激励和分布漂移的影响。第三个来源提供了更可靠和更通用的信号,但面临着费用和个人偏好差异的挑战。最先进的框架将这三个来源的数据集融合在一起,获得互补的优势。这有助于消除在单独依赖任何单一来源时出现的不准确性和差距。
建筑变革引发的自我反思
不过,除了数据和奖励之外,有效优化 RLAIF 还带来了架构复杂性。LLM 包含数十亿个参数,因此很难通过标准策略梯度强化直接更新权重。更可行的方法是采用元学习公式,其中较小的控制器通过操纵温度、top-k 截断和 logit 掩码等超参数来学习塑造行为。这些方法提供了更简单、更具体的接口。
此外,在大规模神经网络中,呈现精细的信用分配仍然很棘手。有希望的方向指向双编码器架构,该架构将模型分为行为生成器和批评者。生成器产生动作,而批评者提供辅助判断以指导改进。一些框架甚至利用具有不同组件的三元组结构进行生成、评级和比较。这些自我反思的设置缓解了不稳定性并提高了透明度,类似于同时拥有左脑和右脑系统如何启发人类认知。架构变化通过暴露自我监督渠道,实现了更清晰的强化学习。
优化程序而非偏好
一旦辅助任务将强化信号形式化,RLAIF 系统就会采用算法过程来实现学习,包括:
- 策略梯度方法:更新影响生成行为的超参数以增加奖励
- 人类偏好:直接优化以匹配人类判断的分布
- 对抗性目标:通过对立损失来惩罚不需要的文本属性
- 约束优化:分层惩罚或约束以强制实施有益行为
- 合作逆向强化学习:从演示中推断出积极的一致目标
这些优化框架对模型动态进行了有针对性的改变,以达到预期目标。策略梯度技术因其简单性而广受欢迎,而对抗和约束方法则允许更直接的控制。通过偏好学习,比较人类样本仍然是校准的黄金标准。而逆向强化学习有望推断出一般价值外推器。
但总体而言,没有一种单一的程序可以普遍适用。实践者会根据具体用例和行为标准混合使用。下一节将更具体地介绍其中一些应用设置。不过在此之前,还有一个核心挑战值得讨论:大型网络中的信用分配问题。
信用分配的挑战
对于 RLAIF 来说,最难攻克的障碍或许在于如何让信号穿过庞大的神经结构。在 GPT-4/LLaMA-2 等模型中,考虑到跨层和模块的划分,细微的调整往往无法产生有意义的效果。本质上,优化被规模淹没了。所有学习都依赖于精确的信用分配——准确识别需要更新哪些参数才能实现目标。在 LLM 中,在数十亿个权重中隔离因果链被证明是艰巨的任务。
更明确的信用分配主要有两种途径:
- 注意机制:注意层关注输入输出相关性,提供一些归因。例如,系数将有毒触发词精确定位为优化目标。
- 模块化架构:将模型分解为半独立组件,可以实现更好的隔离和干预。混合搭配替换,然后扩展更改。
通过量化显著性,注意力被证明是有希望的,即使仍然是一个模糊的镜头。模块化设计最终可能会实现更强大的形式化,类似于大脑如何跨区域定位功能。但总体而言,信用分配仍然是一个核心技术障碍。所有其他算法都依赖于准确地将行为归因于模型片段,这在拜占庭神经连接中很困难。
了解了这些核心概念后,我们现在可以探索更多具体的应用,让 RLAIF 发挥影响力。接下来的部分将重点介绍三个针对价值一致性的关键有前景的方向。
综上所述,我们介绍了大模型语言课程中人工智能反馈强化学习背后的基本动机和技术基础。关键点包括:
- RLAIF 在可靠性、可解释性、价值一致和安全的自我完善等方面做出了诱人的承诺,而这些承诺在其他方面都不太稳定。
- 应用 RLAIF 需要制定适当的模型行动和强化奖励、收集反馈数据集、设计透明的批评者并开发优化方案。
- 尽管采用注意力机制和模块化结构的新兴方法有所帮助,但在大规模神经网络中实现明确的信用分配仍然是一个障碍。
在建立了这些算法基础之后,本文的第 2 部分将重点介绍将 RLAIF 带入有益的 LLM 的实际影响的具体用例。我们将重点关注价值一致性、真实性和一致性方面的进展作为驱动示例。
RLAIF 在 LLM 中的现代应用
到目前为止,我们介绍了大模型语言 (LLM) 中实现人工智能反馈强化学习 (RLAIF) 的基本动机和技术要素。在建立这些基础之后,我们现在探索展示具体进展的当代应用。
研究人员积极地在可靠性、可解释性和价值一致性等众多目标上测试 RLAIF。在本节中,我重点介绍了三个特别有前景的方向:
- 价值取向学习
- 真实性和事实一致性
- 会话连贯性
这些领域展示了之前讨论的算法与有效功能的集成。尽管范围不完整且狭窄,但它们为有益的 LLM 实现更广泛的愿望提供了宝贵的途径。让我们深入分析每个领域。
价值取向学习
RLAIF 最雄心勃勃的愿景或许在于价值观协调——塑造模型目标和偏好,使其与人类道德和乐于助人的精神可靠地保持一致。直接优化道德的尝试因复杂的规范问题和博弈动态而失败。RLAIF 提供了一种通过迭代反馈来规避这些问题的方法。
该领域的关键技术包括:
- 偏好学习:将系统暴露给成对的人类判断,比较模型响应。反馈引导生成更受青睐的样本。
- 合作逆向强化学习:调整奖励模型以匹配人类示例。这旨在推断助手,而不仅仅是直接模仿。
- 宪法优化:在基础系统之上分层设定总体目标,通过诚实、能力和仁慈等原则进行定义。
这些方法共同灌输了亲社会行为的发展轨迹。实验表明,诚实、非暴力和非毒性等概念可以通过 RLAIF 机制衡量。希望在于将这些受约束的目标引导到诚信的一般外推器中。
虽然规模和规范挑战仍然存在,但价值协调构成了最雄心勃勃的 RLAIF 应用。围绕人类偏好构建更具表现力的宪法规范提出了一个活跃的研究问题。即使是像真诚和不伤害这样的狭隘例子也被证明是有价值的,而且是可以实现的。
真实性和事实一致性
除了抽象值之外,RLAIF 还可以优化真实性和事实准确性。不可靠的幻觉反映了不受控制的 LLM 的一大缺陷。与人类的社会学习相比,训练制度不足以保证一致性。
这里值得注意的 RLAIF 架构包括:
- 对抗性真实性规则:惩罚来自外部检测器的事实不准确信号以促进诚实。
- 真实性作为环境约束:塑造奖励以捕捉欺骗和真诚的倾向。
- 自我反思信念追踪:对过去的主张保持不断发展的信心估计,促进确认或自我纠正。
这些模型既能反映事实性,也能反映说真话的倾向。到目前为止,收益仍然局限于狭隘的话题和对话背景。一旦超出分布范围,复合趋势就会趋向于不诚实或不准确,从而困扰后续互动。
然而,内在完整性的可衡量改进是有希望的。有了足够的数据广度和反馈信号的有效集中,RLAIF 为准确、诚实的人工智能助手带来了希望。围绕信心和证据来源加强可信度指标将是关键。用于表征可靠性和欺骗性的元学习也提供了自我监督信号。
总体而言,灌输诚实性可以弥补现有 LLM 版本的一个严重缺陷。RLAIF 提供了缓解无休止幻觉的工具,这对于问责至关重要。但围绕更广泛能力的复杂性经济学带来了持续的挑战。
会话连贯性
最后一个主要应用领域是会话连贯性和一致性。非结构化对话带来了独特的障碍,任性的语境漂移让人难以理解和沮丧。RLAIF 再次通过反馈渠道提供了潜在的监督。
这里采用的关键方法:
- 对话评估电路:批评编码器-解码器结构,对各个回合中的对话流程进行评分。
- 连贯性作为环境约束:塑造奖励以捕捉完整性、清晰度和凝聚力的语言属性。
- 意图分类作为辅助任务:基于主题建模和命名实体链预测语义连续性。
本质上,这些方法通过优化反馈回路来保持对话的正常进行。基于连贯性的奖励可以实现稳定的参与。从架构上分离评论者可以提供评分函数的透明度、可解释性和迁移学习。
事实证明,在交流过程中保持一致的个性和怪癖也是可能的。与表达的个人资料信号保持一致会过滤符合定义特征的行为。个人资料参数会引发进一步的优化维度。
此处的研究仍处于探索阶段,但通过 RLAIF 指导,明确定义的对话流程似乎是可行的。这有效地缩小了上下文范围,同时还允许可定制的体验。应用集成为功能性带来了下一个里程碑。
走向 RLAIF 及其对 AI 未来的意义
RLAIF 所取得的进展代表着朝着开发符合人类价值观并能安全自我改进的 AI 系统迈出了重要一步。随着 RLAIF 技术的成熟,它们有朝一日可能会催生出普遍有用且可靠的 AI 助手。这样的系统将通过提供广泛可访问的知识、自动化和建议,同时尊重人类的偏好,对社会产生深远影响。这里重点介绍的研究方向正在为实现这一未来愿景奠定算法基础。还有很多工作要做,但 RLAIF 是一条非常有希望的前进道路。这些努力的成果可以使 AI 更加有益,同时解决紧迫的大规模安全挑战和意外危害。因此,理解和推进 RLAIF 对于机器学习和人类价值观交汇处未来更光明的可能性至关重要。

相关文章:
14-41 剑和诗人15 - RLAIF 大模型语言强化培训
介绍 大型语言模型 (LLM) 在自然语言理解和生成方面表现出了巨大的能力。然而,这些模型仍然存在严重的缺陷,例如输出不可靠、推理能力有限以及缺乏一致的个性或价值观一致性。 为了解决这些限制,研究人员采用了一种名为“人工…...

每日一题~oj(贪心)
对于位置 i来说,如果 不选她,那她的贡献是 vali-1 *2,如果选他 ,那么她的贡献是 ai. 每一个数的贡献 是基于前一个数的贡献 来计算的。只要保证这个数的前一个数的贡献是最优的,那么以此类推下去,整体的val…...

成人高考报名条件及收费标准详解
成人高考报名条件及收费标准详解 您想通过成人高考改变自己的命运,但不知道报名条件和收费标准?本文将为您详细介绍成人高考报名条件和收费标准,并为您提供专业的成人教育服务。 深圳成人高考www.shenzhixun.com 成人高考报名条件 成人高考…...
openmetadata1.3.1 自定义连接器 开发教程
openmetadata自定义连接器开发教程 一、开发通用自定义连接器教程 官网教程链接: 1.https://docs.open-metadata.org/v1.3.x/connectors/custom-connectors 2.https://github.com/open-metadata/openmetadata-demo/tree/main/custom-connector (一&…...

PostgreSQL 如何优化存储过程的执行效率?
文章目录 一、查询优化1. 正确使用索引2. 避免不必要的全表扫描3. 使用合适的连接方式4. 优化子查询 二、参数传递1. 避免传递大对象2. 参数类型匹配 三、减少数据量处理1. 限制返回结果集2. 提前筛选数据 四、优化逻辑结构1. 分解复杂的存储过程2. 避免过度使用游标 五、事务处…...

普中51单片机:数码管显示原理与实现详解(四)
文章目录 引言数码管的结构数码管的工作原理静态数码管电路图开发板IO连接图代码演示 动态数码管实现步骤数码管驱动方式电路图开发板IO连接图真值表代码演示1代码演示2代码演示3 引言 数码管(Seven-Segment Display)是一种常见的显示设备,广…...
web缓存代理服务器
一、web缓存代理 web代理的工作机制 代理服务器是一个位于客户端和原始(资源)服务器之间的服务器,为了从原始服务器取得内容,客户端向代理服务器发送一个请求,并指定目标原始服务器,然后代理服务器向原始…...

容器:queue(队列)
以下是关于queue容器的总结 1、构造函数:queue [queueName] 2、添加、删除元素: push() 、pop() 3、获取队头/队尾元素:front()、back() 4、获取栈的大小:size() 5、判断栈是否为空:empty() #include <iostream> #include …...

探索 WebKit 的后台同步新纪元:Web Periodic Background Synchronization 深度解析
探索 WebKit 的后台同步新纪元:Web Periodic Background Synchronization 深度解析 随着 Web 应用逐渐成为我们日常生活中不可或缺的一部分,用户对应用的响应速度和可靠性有了更高的期待。Web Periodic Background Synchronization API(周期…...

ctfshow web入门 web338--web344
web338 原型链污染 comman.js module.exports {copy:copy };function copy(object1, object2){for (let key in object2) {if (key in object2 && key in object1) {copy(object1[key], object2[key])} else {object1[key] object2[key]}}}login.js var express …...

mupdf加载PDF显示中文乱码
现象 加载PDF显示乱码,提示非嵌入字体 non-embedded font using identity encoding调式 在pdf-font.c中加载字体 调试源码发现pdf文档的字体名字居然是GBK,估计又是哪个windows下写的pdf生成工具生成pdf 字体方法: static pdf_font_desc * load_cid…...

常用的限流工具Guava RateLimiter 或Redisson RRateLimiter
在分布式系统和高并发场景中,限流是一个非常常见且重要的需求。以下是一些常用的限流工具和库,包括它们的特点和使用场景: 1. Guava RateLimiter Google 的 Guava 库中的 RateLimiter 是一个简单且高效的限流工具,适用于单节点应…...
和循环神经网络(RNN) 的区别与联系)
卷积神经网络(CNN)和循环神经网络(RNN) 的区别与联系
卷积神经网络(CNN)和循环神经网络(RNN)是两种广泛应用于深度学习的神经网络架构,它们在设计理念和应用领域上有显著区别,但也存在一些联系。 ### 卷积神经网络(CNN) #### 主要特点…...

Unity【入门】场景切换和游戏退出及准备
1、必备知识点场景切换和游戏退出 文章目录 1、必备知识点场景切换和游戏退出1、场景切换2、鼠标隐藏锁定相关3、随机数和自带委托4、模型资源的导入1、模型由什么构成2、Unity支持的模型格式3、如何指导美术同学导出模型4、学习阶段在哪里获取模型资源 2、小项目准备工作需求分…...

Python 函数递归
以下是一个使用递归计算阶乘的 Python 函数示例 : 应用场景: 1. 动态规划问题:在一些需要逐步求解子问题并利用其结果的动态规划场景中,递归可以帮助直观地表达问题的分解和求解过程。 2. 遍历具有递归结构的数据:如递…...
如何配置 MyBatis 实现打印可执行的 SQL 语句)
MyBatis(27)如何配置 MyBatis 实现打印可执行的 SQL 语句
在开发过程中,打印可执行的SQL语句对于调试和性能优化是非常有帮助的。MyBatis提供了几种方式来实现SQL语句的打印。 1. 使用日志框架 MyBatis可以通过配置其内部使用的日志框架(如Log4j、Logback等)来打印SQL语句。这是最常用的方法。 Lo…...

3.js - 裁剪平面(clipIntersection:交集、并集)
看图 代码 // ts-nocheck// 引入three.js import * as THREE from three// 导入轨道控制器 import { OrbitControls } from three/examples/jsm/controls/OrbitControls// 导入lil.gui import { GUI } from three/examples/jsm/libs/lil-gui.module.min.js// 导入tween import …...

在5G/6G应用中实现高性能放大器的建模挑战
来源:Modelling Challenges for Enabling High Performance Amplifiers in 5G/6G Applications {第28届“集成电路和系统的混合设计”(Mixed Design of Integrated Circuits and Systems)国际会议论文集,2021年6月24日至26日,波兰洛迪} 本文讨…...

Perl 数据类型
Perl 数据类型 Perl 是一种功能丰富的编程语言,广泛应用于系统管理、网络编程、GUI 开发等领域。在 Perl 中,数据类型是编程的基础,决定了变量存储信息的方式以及可以对这些信息执行的操作。本文将详细介绍 Perl 中的主要数据类型࿰…...

网络协议 -- IP、ICMP、TCP、UDP字段解析
网络协议报文解析及工具使用介绍 1. 以太网帧格式及各字段作用 -------------------------------- | Destination MAC Address (48 bits) | -------------------------------- | Source MAC Address (48 bits) …...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...