Hive 分区表新增字段 cascade
背景
在以前上线的分区表中新加一个字段,并且要求添加到指定的位置列。
模拟测试
加 cascade 操作
- 创建测试表
create table if not exists sqltest.table_add_column_test(org_col1 string comment '原始数据1',org_col2 string comment '原始数据2'
)
comment '增加分区表字段的测试表'
partitioned by (dt string comment '分区日期')
;
- 插入测试数据
insert into table sqltest.table_add_column_test partition(dt='20230313') values ('org_col1_0313','org_col2_0313');
insert into table sqltest.table_add_column_test partition(dt='20230314') values ('org_col1_0314','org_col2_0314');
- 查看现有数据
select * from table_add_column_test;
+---------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | 20230313 |
| org_col1_0314 | org_col2_0314 | 20230314 |
+---------------------------------+---------------------------------+---------------------------+--+
- 官网添加列的语法
ALTER TABLE table_name [PARTITION partition_spec] -- (Note: Hive 0.14.0 and later)ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)[CASCADE|RESTRICT] -- (Note: Hive 1.1.0 and later)
注意: Hive 1.1.0 中有 CASCADE|RESTRICT 子句。ALTER TABLE ADD|REPLACE COLUMNS CASCADE命令修改表元数据的列,并将相同的更改级联到所有分区元数据。RESTRICT 是默认值,即不修改元数据。
- 增加一列,指定增加到原始的两列中间
先添加一列(注意: 必须添加cascade关键字,不然不会刷新旧分区数据,关键字cascade能修改元数据)
alter table sqltest.table_add_column_test add columns (added_column string comment '新添加的列') cascade;
查看数据
+---------------------------------+---------------------------------+-------------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.org_col2 | table_add_column_test.added_column | table_add_column_test.dt |
+---------------------------------+---------------------------------+-------------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | NULL | 20230313 |
| org_col1_0314 | org_col2_0314 | NULL | 20230314 |
+---------------------------------+---------------------------------+-------------------------------------+---------------------------+--+
再对列进行排序(注意: 必须添加 cascade 关键字,不然不会刷新旧分区数据,关键字 cascade 能修改元数据)
alter table sqltest.table_add_column_test change column added_column added_column string after org_col1 cascade;
再查看数据(注意: 虽然列名顺序变了,但 HDFS 文件内容并没有变化,所以结果第二列还是有数据,第三列没数据)
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | NULL | 20230313 |
| org_col1_0314 | org_col2_0314 | NULL | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
- 重刷旧分区数据(将以前第二列放到第三列位置,现第二列为新数据)
insert overwrite table sqltest.table_add_column_test partition(dt='20230313') select org_col1, 'added_col_0313', added_column from sqltest.table_add_column_test where dt = '20230313';
insert overwrite table sqltest.table_add_column_test partition(dt='20230314') select org_col1, 'added_col_0314', added_column from sqltest.table_add_column_test where dt = '20230314';
查看数据(旧分区数据有更新)
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | added_col_0313 | org_col2_0313 | 20230313 |
| org_col1_0314 | added_col_0314 | org_col2_0314 | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
不加 cascade 操作(针对已有分区数据)
- 删除表
drop table if exists sqltest.table_add_column_test;
- 创建测试表
create table if not exists sqltest.table_add_column_test(org_col1 string comment '原始数据1',org_col2 string comment '原始数据2'
)
comment '增加分区表字段的测试表'
partitioned by (dt string comment '分区日期')
;
- 插入测试数据
insert into table sqltest.table_add_column_test partition(dt='20230313') values ('org_col1_0313','org_col2_0313');
insert into table sqltest.table_add_column_test partition(dt='20230314') values ('org_col1_0314','org_col2_0314');
- 添加列(不加关键字 cascade)
alter table sqltest.table_add_column_test add columns (added_column string comment '新添加的列');alter table sqltest.table_add_column_test change column added_column added_column string after org_col1;
查看数据
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | org_col2_0313 | NULL | 20230313 |
| org_col1_0314 | org_col2_0314 | NULL | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
- 重刷旧分区数据
insert overwrite table sqltest.table_add_column_test partition(dt='20230313') select org_col1, 'added_col_0313', added_column from sqltest.table_add_column_test where dt = '20230313';
insert overwrite table sqltest.table_add_column_test partition(dt='20230314') select org_col1, 'added_col_0314', added_column from sqltest.table_add_column_test where dt = '20230314';
- 查看数据(旧分区没有变化)
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| table_add_column_test.org_col1 | table_add_column_test.added_column | table_add_column_test.org_col2 | table_add_column_test.dt |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
| org_col1_0313 | added_col_0313 | NULL | 20230313 |
| org_col1_0314 | added_col_0314 | NULL | 20230314 |
+---------------------------------+-------------------------------------+---------------------------------+---------------------------+--+
相关文章:

Hive 分区表新增字段 cascade
背景 在以前上线的分区表中新加一个字段,并且要求添加到指定的位置列。 模拟测试 加 cascade 操作 创建测试表 create table if not exists sqltest.table_add_column_test(org_col1 string comment 原始数据1,org_col2 string comment 原始数据2 ) comment 增…...

【Java版oj】day08两种排序方法、最小公倍数
目录 一、两种排序方法 (1)原题再现 (2)问题分析 (3)完整代码 二、最小公倍数 (1)原题再现 (2)问题分析 (3)完整代码 一、两种…...

FinOps,从概念到落地 | UGeek大咖说第一期直播回顾(上)
2023年2月28日,由优维科技联合FinOps产业推进方阵举办了第1期「UGeek大咖说-极致用云共济FinOps」线上直播活动,来自中国信通院及美图公司技术专家共同带来了一场精彩的技术视听盛宴。 直 播 背 景 目前,许多以“上云”为数字化转型路径的企…...

k8s java程序实现kubernetes Controller Operator 使用CRD 学习总结
k8s java程序实现kubernetes Controller & Operator 使用CRD 学习总结 大纲 原理Controller 与 Operator自定义资源定义 CRD ( CustomResourceDefinition)kubernetes-client使用java fabric8io/kubernetes-client操作k8s 原生资源使用java abric8io/kubernetes-clientt操…...
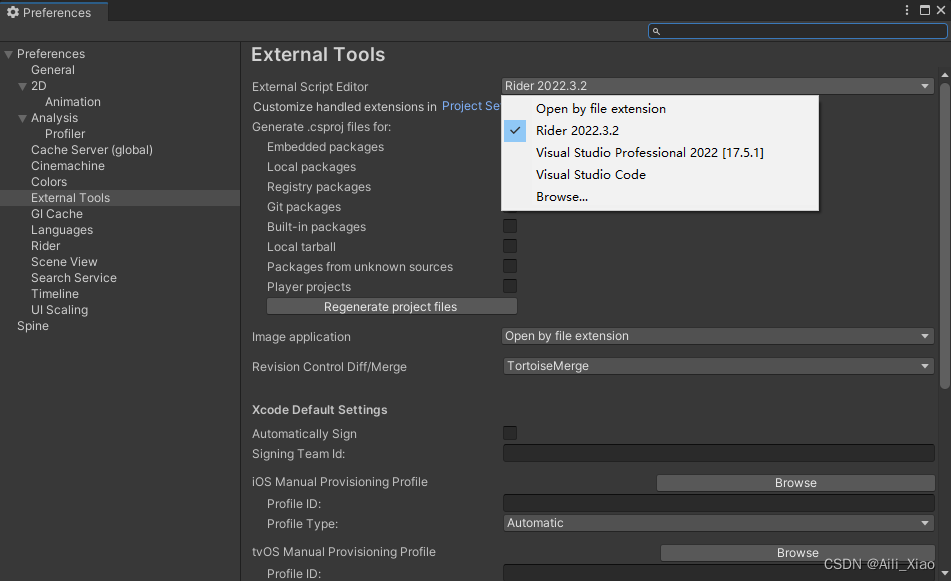
Unity笔记:修改代码执行的默认打开方式
使用 External Tools 偏好设置可设置用于编写脚本、处理图像和进行源代码控制的外部应用程序。 External Script Editor:选择 Unity 应使用哪个应用程序来打开脚本文件。Unity 会自动将正确的参数传递给内置支持的脚本编辑器。Unity 内置支持 Visual Studio Commun…...

Linux IPC:匿名管道 与 命名管道
目录一、管道的理解二、匿名管道三、命名管道四、管道的通信流程五、管道的特性进程间通信方式有多种,本文介绍的是管道,管道分为匿名管道和命名管道。 一、管道的理解 生活中的管道用来传输资源,例如水、石油之类的资源。而进程间通信的管道…...

阿里研发工程师JAVA暑期实习一面
文章目录先说一下我自己的情况面试过程总结先说一下我自己的情况 我就读于湖南大学,软件工程专业,现在大三下 很巧的是,我在大二的时候就在相同的时间面过相同的部门和相同的岗位,所以我没有做笔试就直接让我去面试了。我当时还纳…...
第十四届蓝桥杯三月真题刷题训练——第 11 天
目录 第 1 题:卡片 题目描述 运行限制 第 2 题:路径_dpgcd 运行限制 第 3 题:字符统计 问题描述 输入格式 输出格式 样例输入 样例输出 评测用例规模与约定 运行限制 第 4 题:费用报销 第 1 题:卡片 题…...
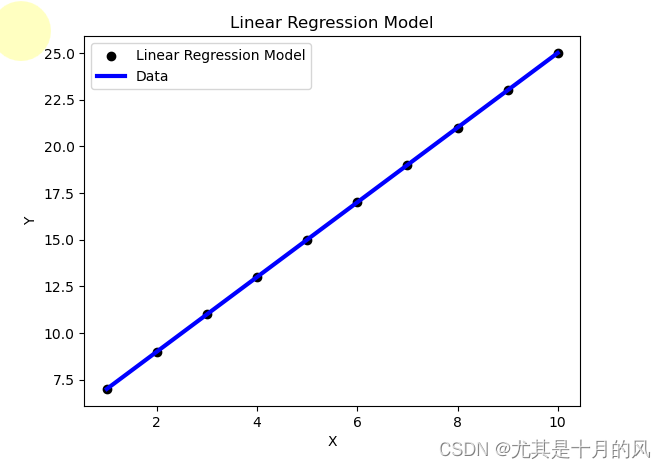
机器学习入门——线性回归
线性回归什么是线性回归?回归分析:线性回归:回归问题求解单因子线性回归简单实例评估模型表现可视化模型展示多因子线性回归什么是线性回归? 回归分析: 根据数据,确定两种或两种以上变量间相互依赖的定量…...
)
Microsoft Word 远程代码执行漏洞(CVE-2023-21716)
本文转载于: https://mp.weixin.qq.com/s?__bizMzI5NTUzNzY3Ng&mid2247485476&idx1&sneee5c7fd1c4855be6441b8933b10051e&chksmec535547db24dc516d013d3d76097e985aaad7f10f82f15b4e355a97af75fd333acdab6232af&mpshare1&scene23&srci…...
SharedPreferences存储及测试)
Android kotlin 系列讲解(数据篇)SharedPreferences存储及测试
文章目录 一、什么是SharedPreferences1、将数据存储到SharedPreferences中2、从SharedPreferences中读取数据二、登录使用SharedPreferences一、什么是SharedPreferences SharedPreferences是使用键值对的方式来存储数据的。也就是说,当保存一条数据的时候,需要给这条数据提…...
一文了解Web Worker
一、概述 众所周知,JavaScript最初设计是运行在浏览器中的,为了防止多个线程同时操作DOM带来的渲染冲突问题,所以JavaScript执行器被设计成单线程。但是随着前端技术的发展,JavaScript要处理的工作也越来越复杂,当我们…...
接口文档包含哪些内容?怎么才能写好接口文档?十年测试老司机来告诉你
目录 接口文档结构 参数说明 示例 错误码说明 语言基调通俗易懂 及时更新与维护 总结 那么我们该如何写好一份优秀的接口文档呢? 接口文档结构 首先我们要知道文档结构是什么样子的。接口文档应该有清晰明确的结构,以便开发人员能快速定位自己需…...
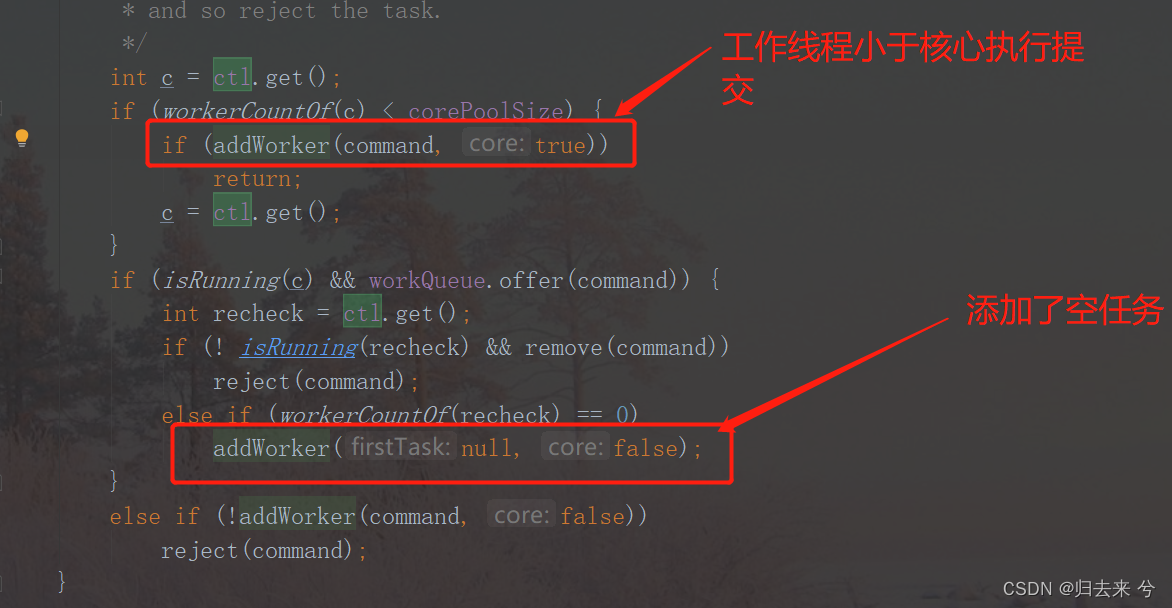
java面试八股文之------Java并发夺命23问
java面试八股文之------Java并发夺命23问👨🎓1.java中线程的真正实现方式👨🎓2.java中线程的真正状态👨🎓3.如何正确停止线程👨🎓4.java中sleep和wait的区别👨…...

CANoe中使用CAPL刷写流程详解(Trace图解)(CAN总线)
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...

【MySQL】002 -- 日志系统:一条SQL更新语句是如何执行的
此文章为《MySQL 实战 45 讲》的学习笔记,其课程链接可参见:MySQL实战45讲_MySQL_数据库-极客时间 目录 一、日志系统 1、重做日志:redo log(引擎层) 2、归档日记:binlog(Server层) …...
)
C++---背包模型---数字组合(每日一道算法2023.3.14)
注意事项: 本题是"动态规划—01背包"的扩展题,优化思路不多赘述,dp思路会稍有不同,下面详细讲解。 题目: 给定 N个正整数 A1,A2,…,AN,从中选出若干个数,使它们的和为 M,…...
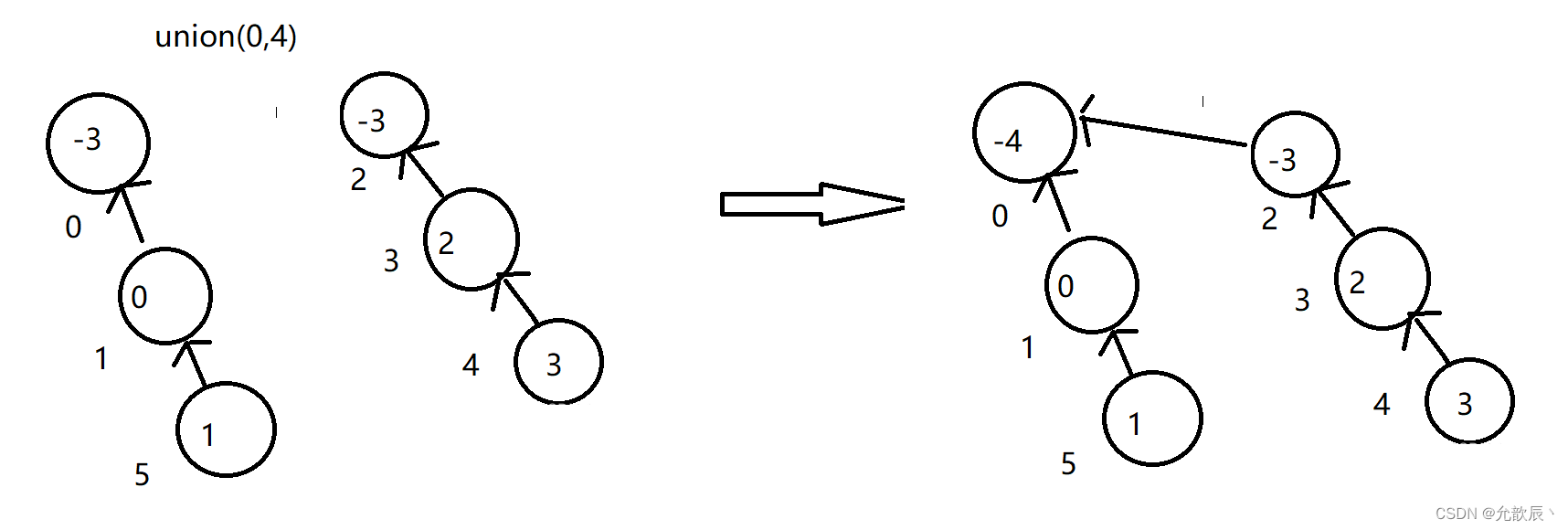
并查集(不相交集)详解
目录 一.并查集 1.什么是并查集 2.并查集的基本操作 3.并查集的应用 4.力扣上的题目 二.三大操作 1.初始化 2.查找 3.合并 三.省份数量 1.题目描述 2.问题分析 3.代码实现 四.冗余连接 1.题目描述 2.问题分析 3.代码实现 一.并查集 1.什么是并查集 并查集&…...

10个最频繁用于解释机器学习模型的 Python 库
文章目录什么是XAI?可解释性实践的步骤技术交流1、SHAP2、LIME3、Eli54、Shapash5、Anchors6、BreakDown7、Interpret-Text8、aix360 (AI Explainability 360)9、OmniXAI10、XAI (eXplainable AI)XAI的目标是为模型的行为和决定提供有意义的解释,本文整理…...

final关键字:我偏不让你继承
哈喽,小伙伴们大家好,我是兔哥呀,今天就让我们继续这个JavaSE成神之路! 这一节啊,咱们要学习的内容是Java所有final关键字。 之前呢,我们学习了继承,这大大提高了代码的灵活性和复用性。但是总…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

Redis相关知识总结(缓存雪崩,缓存穿透,缓存击穿,Redis实现分布式锁,如何保持数据库和缓存一致)
文章目录 1.什么是Redis?2.为什么要使用redis作为mysql的缓存?3.什么是缓存雪崩、缓存穿透、缓存击穿?3.1缓存雪崩3.1.1 大量缓存同时过期3.1.2 Redis宕机 3.2 缓存击穿3.3 缓存穿透3.4 总结 4. 数据库和缓存如何保持一致性5. Redis实现分布式…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...