ChatGPT前传
文章目录
- 前言
- GPT概述
- GPT-1代
- GPT-1 学习目标和概念介绍
- GPT-1 训练数据集
- GPT-1 模型结构和应用细节
- GPT-1 效果性能和总结
- GPT-2代
- GPT-2 学习目标和概念介绍
- GPT-2 训练数据集
- GPT-2 模型结构和应用细节
- GPT-2 性能效果和总结
- GPT-3代
- GPT-3 学习目标和概念介绍
- GPT-3 训练数据集
- GPT-3 模型结构和应用细节
- GPT-3 性能效果和总结
- GPT-3 局限性和更广泛的影响
- 结束语
- Reference
前言
对于目前火热的ChatGPT,总是想多聊些,那就写点其前身的知识点吧。
GPT概述
GPT(Generative Pre-trained Transformer)是OpenAI公司开发的关于自然语言处理的语言模型。这类模型在知识问答、文本摘要等方面的效果超群,更牛逼的是这居然都是无监督学习出来的模型。在很多任务上,GPT模型甚至不需要样本微调,就能在理解和执行效果上获得比当时最好的监督学习模型更好的性能。
我们就此捋一下GPT三代的历程:
- GPT-1 Improving Lanugage Understanding by Generative Pre-training
- GPT-2 Language Models are UnsupervisedMultitask Learners
- GPT-3 Language Models are Few Shot Learners
提前假设大家都是了解NLP的术语和Transformer结构的,不清楚的可以自行补充知识。
咱们一篇一篇地捋一捋,分别搞清楚基本目标和概念、训练的数据集、模型结构和应用、效果和评估,也就差不多了。先上个一揽子对比图,快乐下。
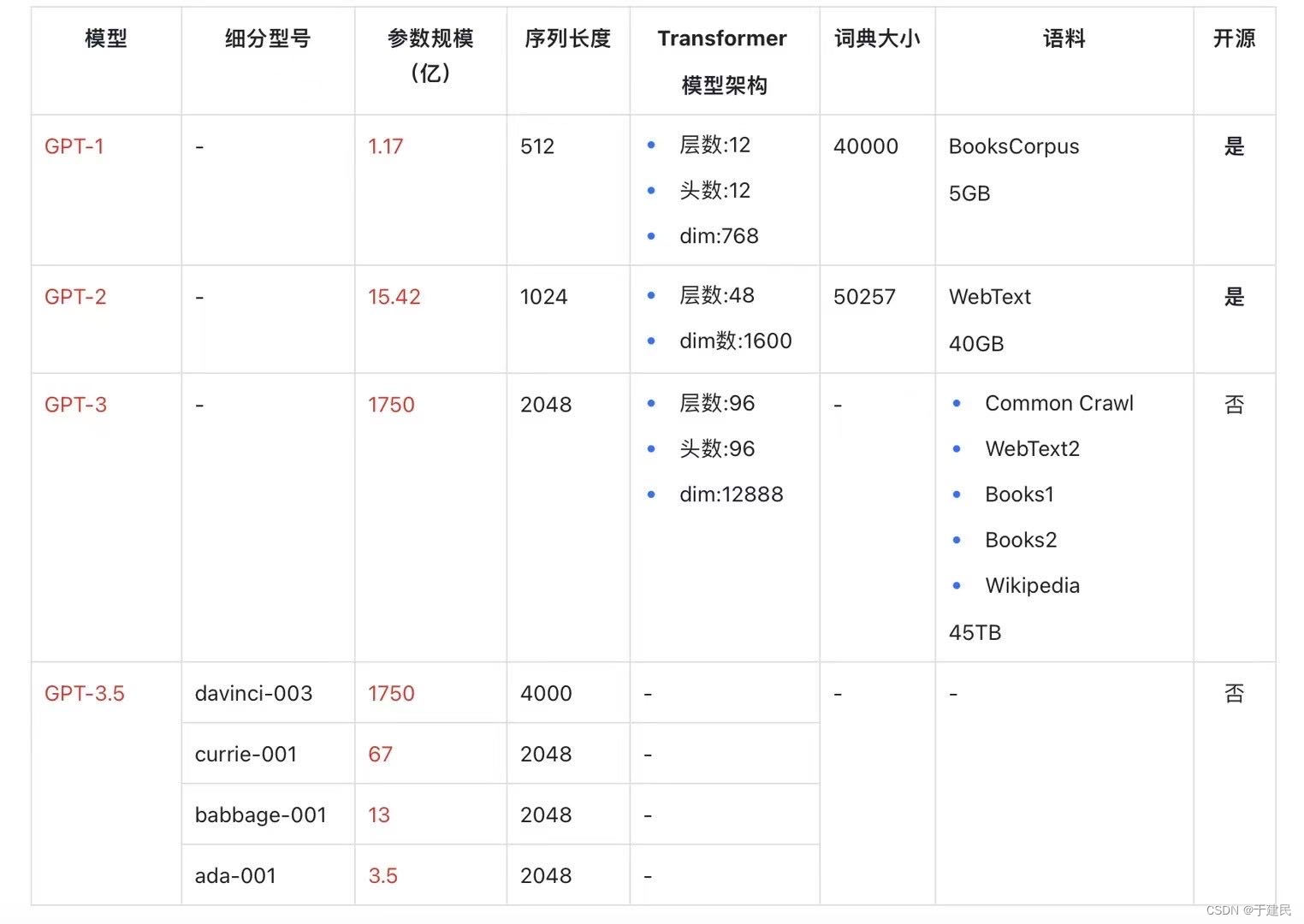
GPT-1代
在此之前,大部分SOTA的NLP模型都是在特定任务上做有监督训练的,比如情感分类、文本含义等。通常来说,有监督是天然带有如下两个缺陷:
- 需要大量的标签数据来学习特定的任务,而这个打标签的过程是漫长而消耗财力的。
- 特定任务专项训练,也带来了没法向其他任务场景迁移和拓展的问题。
而这篇文章,提出了一个思路:用无标签数据来学习生成模型,然后根据下游任务做微调使用,比如像是分类、情感分析等。
无监督学习作为有监督微调模型的预训练目标,因此被称为生成预训练。
Unsupervised learning served as pre-training objective for supervised fine-tuned models, hence the name Generative Pre-training.
GPT-1 学习目标和概念介绍
- 无监督语言模型(Pre-training)目标如下:
L1(T)=∑ilogP(ti∣ti−k,...,ti−1;θ)L_1(T)=\sum_i log P(t_i|t_{i-k},...,t_{i-1}; \theta)L1(T)=i∑logP(ti∣ti−k,...,ti−1;θ)
其中T表示时间序列下数据{t1,...,tn}\{t_1,...,t_n\}{t1,...,tn},k表示时间窗口尺寸,θ\thetaθ表示自然语言的参数。 - 有监督微调学习,最大似然估计,目标如下:
L2(D)=∑x,ylogP(y∣x1,...,xn)L_2(D)=\sum_{x,y} log P(y|x_1,...,x_n)L2(D)=x,y∑logP(y∣x1,...,xn)
D表示带标签的训练数据集,{x1,...,xn}\{x_1,...,x_n\}{x1,...,xn}是输入特征。
本文又构造了一个带辅助的学习目标,用来给有监督微调学习来用,以更快收敛且能得到更好的概括性(这里是通常直接最大化L2(D)L_2(D)L2(D),但论文里专门设计了带有辅助的学习目标来作为优化目标,如下)。
L3(D)=L2(D)+λL1(D)L_3(D)=L_2(D) + \lambda L_1(D)L3(D)=L2(D)+λL1(D)
这里的L1(D)L_1(D)L1(D)是辅助学习目标,λ\lambdaλ是超参,一般设为0.5,表示辅助学习目标对整体学习目标的贡献度。
下游任务的训练时,会在transformer层之后增加一层线性和softmax层,以此来学习下游任务。 - 特定任务的输入转换。为了最小化地修改模型结构,微调时会将下游任务的输入转换成有序序列,修改如下:
a. 在输入序列首尾增加起始和结束字符。
b. 在样本的不同部分之间,增加切分符,以表示输入的有序性。比如问答类任务,多个选项间就增加了切分符。
GPT-1 训练数据集
GPT-1使用BooksCorpus语料集。该语料包括大约7000本没出版过的书籍,能够学到一些市面上不可见的数据信息。而这类信息不太可能在下游任务中出现。另外,该语料还包括大量的连续文本,能够给模型提供了学习大范围独立性的可能性。
GPT-1 模型结构和应用细节
GPT-1模型使用了12层解码器,自注意机制的transformer结构。跟Transformer的原始结构是保持一致的。遮挡能够帮助模型扩大视野,学习到双侧信息。应用细节如下:
- 无监督训练
- 使用了大约4万个合并之后的字节对编码词表
- 输入token使用768维词向量表示,位置向量也同时在训练时候进行学习。
- 使用了12层自注意层,每层有12个Attention-Heads。
- 对位置前置层,有3072维的状态值来表达其信息。
- Adam优化器,学习率设置为2.5e-4。
- 正则化的部分,注意力、残差、向量dropout技术都用到了,其中dropout比例0.1,L2正则用在了非Bias参数上。
- GELU作为激活函数。
- 模型训练参数:epoch=100 ,batch=64,seq_len=512,模型共有117M的参数。
- 有监督调优
- 在下游任务上进行大约epoch=3轮的有监督微调。预训练已经学到了足够丰富的信息,这里只需要很少的轮次训练微调即可。
- 大部分预训练的超参都无需微调,直接使用。
什么是字节对编码
GPT-1 效果性能和总结
在对比的12个专项SOTA的有监督模型学习任务中,GPT-1有9项是表现优异的。
GPT-1 performed better than specifically trained supervised state-of-the-art models in 9 out of 12 tasks the models were compared on.
另一个牛逼的地方是该模型在各项任务上的zero-shot优异表现。论文里指出该模型在不同的NLP任务上,像是问题回答、主题解析、情感分析等,都经过了zero-shot的效果评估。
GPT-1证明了一条路径是行得通的,即语言模型可以作为有效的预训练目标,从而提升其泛化性。这也为后序语言模型在大模型的邪路上狂奔提供了坚实的试验基础。GPT-1表明了迁移学习+微调的可行性,粗暴地展示了生成预训练的力量美,其他模型只需要通过更大的数据集和更多的参数,来解锁释放其巨大潜力即可。
GPT-2代
GPT-2就是利用更大的数据集和更多参数,来不断提升模型性能。其主要提升和术语概念如下:
GPT-2 学习目标和概念介绍
- 任务调整。语言模型的通用目标是P(output∣input)P(output|input)P(output∣input)。GPT-2为了能够使用同一个无监督模型来学习多任务,做了调整P(output∣input,task)P(output|input, task)P(output∣input,task)。此处修改称之为任务微调,模型对不同任务做相同输入而产生不同输出。有的模型在架构级别实现任务调节,在架构级上提供输入和任务,注意与此处要区分开。
- zero-shot学习和zero-shot任务迁移。一个非常有意思的GPT-2能力是零样本任务迁移能力,零样本学习是零样本任务迁移的一个特例,即没有提供任何样本,模型直接根据指令来理解任务。不需要像GPT-1那样来调整序列作微调,GPT-2直接接受输入然后理解自然语言任务然再给出答案。
GPT-2 训练数据集
为了能够搞到高质量的数据集,论文作者们爬取了Reddit平台数据的高赞文章。最终大概有40GB文本数据,来自8百万文章,称之为WebText,比BookCorpus要更大。该训练数据集剔除了Wikipedia文档,但测试集中包含有Wikipedia文档。
GPT-2 模型结构和应用细节
GPT-2有15亿参数,比GPT-1大10倍有余(117M参数),与GPT-1的主要区别如下:
- GPT-2有48层,并且词向量是1600维的。
- 更大的词表字典,有50256个词。
- 更大的batch尺寸(512),更大的上下文窗口(1024个词)。
- 每个模块的输入层的Layer Normalization被去掉了,在最后的自注意模块上增加了一个Layer Normalization层。
- 初始化时,残差层的权重设置为1/N1/\sqrt{N}1/N,其中N是残差层的数量。
作者分别训练了117M,345M,762M,1.5B大小参数的模型,每个模型依次比前一个模型要更低模糊性。这表明语言模型在同样语料上的模糊性(perplexity),要随着参数的增加而降低。因此,最大的模型也在各项下游任务上具有最好的效果表现。
GPT-2 性能效果和总结
GPT-2在很多下游任务上做了评估,比如阅读理解、内容总结、语言翻译、问题回答等。
- GPT-2在8项语言类任务上作zero shot时,能够提升其中7项SOTA效果。
- 儿童书籍数据集被用来评估模型在名词、介词、命名实体上的效果。GPT-2提升了通用名词和实体命名任务的最优效果大概7%。
- LAMBADA数据集被用来评估模型在确定长范围上的独立性和句子最后单词预测效果。GPT-2降低了模糊性从99.8到8.6,并且也显著提升了准确率。
- GPT-2在4项基线阅读理解任务的zero shot情况中有3项是效果显著的。
- 法语翻译成英语的任务中,GPT-2仅以zero shot模式就比大部分无监督模型要更好,但是比不上SOTA的效果。
- GPT-2暂时不能胜任文本总结类任务,它的效果稍次于分类模型。
GPT-2表明,在使用更多参数在更大的训练集上学习,可以有效提升语言模型能力来理解任务,并能够以zero shot模式下提升SOTA效果。论文指出,随着模型能力的提升,效果增加呈现log线性趋势。而语言模型的模糊性,则没有饱和的趋势,仍然随着参数的增加而持续下降。这表明GPT-2的尺寸仍然可以更大,来进一步降低模糊性并提升语言理解能力。
GPT-3代
为追求更大更强,OpenAI训练了拥有1750亿参数的GPT-3模型。这一模型比微软Turing NLG语言模型还要大10倍,比GPT-2大100倍。终于在大模型的邪路上越走越远了。鉴于其以超大规模的参数在更大规模语料上的训练学习,GPT-3以zero-shot和few-shot模式在下游任务上表现优异。不仅如此,还具有了写作能力,并与人类写作难以区分。更令人惊叹的是,它还可以执行从未明确训练过的即时任务,比如数字求和、编写SQL查询语代码、解读句子单词、编写React和JavaScript代码等。简直强到没朋友的那种。
GPT-3 学习目标和概念介绍
- 情境学习(In-context Learning)。大语言模型通过文本训练数据来提升自己的模式识别能力和其他能力。在学习根据已知文本预测下个词的主要任务时,语言模型也开始识别语料中的模式来降低学习损失。之后,这一能力有助于zero shot任务迁移。当被提供了很少样本,或者描述做什么的时候,语言模型匹配到了样本模式(通过过往相似数据和知识学习到的)来完成任务。这是语言模型的强大能力,可以通过模型参数数量来不断提升。
- few-shot, one-shot, zero-shot setting。如前所讨论,few/one/zero shot 设定是零样本任务迁移的特殊情况。在few-shot中,模型可知任务描述和少量样本;在one-shot中,模型只能得知一个样本;在zero-shot中,模型啥样本也获取不到。随着模型能力的提升,few/one/zero-shot下的模型能力都得到了提升。
GPT-3 训练数据集
GPT-3在5个不同的语料集上训练,每个语料集都有一个权重。高质量的数据集采样更多,模型在其上训练更多轮次。这五个数据集分别为Common Crawl, WebText2, Books1, Books2 和Wikipedia。
GPT-3 模型结构和应用细节
GPT-3与GPT-2的模型结构一致,只有很少的区别如下:
- GPT-3有96层,每一层有96个Attention heads。
- 词向量的尺寸从1600变为12888。
- 上下文窗口尺寸也从1024变为2048。
- Adam优化器的参数β1=0.9;β2=0.05;ϵ=10−8\beta_1=0.9;\beta_2=0.05;\epsilon=10^{-8}β1=0.9;β2=0.05;ϵ=10−8
- 使用了交替稠密和局部带状稀疏注意力模式。
GPT-3 性能效果和总结
GPT-3比在数据集LAMBADA和PennTreeBank上训练的SOTA模型效果要好(在few/zero-shot模式下)。对其他数据集,则不能击败SOTA,但是能提升zeor-shot下的SOTA效果。GPT-3在闭卷问答、模式解析、翻译等任务中也变现不错,经常打平或超过最先进的微调模型。对大部分任务而言,该模型通常在few-shot下表现要好于 one/zero-shot模式下。
除了传统NLP任务评估之外,该模型还在算数假发、单词解读、新闻生成、学习和使用新词等综合任务上进行了评估。诸如此类的任务,模型效果也在随着参数增加而提升,模型也在few-shot下表现要好于one/zero-shot模式。
GPT-3 局限性和更广泛的影响
GPT-3的缺陷也在论文中讨论,并给出了进一步提升的地方。
- 尽管GPT-3能够产生高质量的文本,但在长句子下回失去连贯性且会不断重复片段。在某些任务中,GPT-3表现一般,比如自然语言推理(一个句子是否暗指另一个句子),完形填空,一些阅读理解任务等。论文指出,GPT模型的单向性是造成这类问题的大概原因,并建议训练双向模型以解决此类问题。
- 另外一个局限性,GPT-3使用通用语言建模目标,每个token的权重均等,缺少面向任务/目标预测的概念。为解决这类问题,论文提出了一些方法,比如增强学习目标,使用强化学习来微调模型,添加其他模式等。
- 其他GPT-3的局限性,包括大模型的复杂而昂贵的推理过程,模型和生成结果的低可解释性,不确定性(什么有助于模型实现其few-shot学习行为)。
- 除了上述局限性,GPT-3还存在着各种潜在风险,比如类人类文本生成能力的滥用-网络钓鱼、垃圾邮件、误导信息传播、其他欺诈行为。模型会受限于其训练语料的偏见,生成的内容也会具有性别、民族、种族和总监的偏见。因此,要非常谨慎小心地使用模型并且监督其生成的文本内容。
结束语
本文总结了3篇GPT相关的文章,作为ChatGPT的前传出现在这里,是想让大家在了解ChatGPT的时候,对其前期的技术积累有个基本的概要了解。想要了解更多,还是建议大家看论文本身。
Reference
- [1] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.
- [2] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. and Sutskever, I., 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8), p.9.
- [3] Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 (2020).
- [4] Rei, M., 2017. Semi-supervised multitask learning for sequence labeling. arXiv preprint arXiv:1704.07156.
- [5] Waswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I., 2017. Attention is all you need. In NIPS.
有个发表论文时,作者与编辑交流修改意见的网站
相关文章:
ChatGPT前传
文章目录前言GPT概述GPT-1代GPT-1 学习目标和概念介绍GPT-1 训练数据集GPT-1 模型结构和应用细节GPT-1 效果性能和总结GPT-2代GPT-2 学习目标和概念介绍GPT-2 训练数据集GPT-2 模型结构和应用细节GPT-2 性能效果和总结GPT-3代GPT-3 学习目标和概念介绍GPT-3 训练数据集GPT-3 模…...

我的十年编程路 2020年篇
我出生在1990年,2020年到来的时候,我完成了一项成就:奔三。同时,也开启了新的征程:奔四。 2020年的春节是在广州的丈母娘家度过的,春节后大概是初五,或者是初六,我和媳妇就返回天津…...

力扣-SQL【入门】
https://leetcode.cn/study-plan/sql/?progressxhqm4sjh 目录选择595. 大的国家1757. 可回收且低脂的产品584. 寻找用户推荐人183. 从不订购的客户排序 & 修改1873. 计算特殊奖金627. 变更性别196. 删除重复的电子邮箱选择 595. 大的国家 # Write your MySQL query state…...
Vue中组件到底是什么
1.先说结论: Vue中组件本质是一个名为VueComponent的构造函数,且不是程序员定义的,是Vue.extend生成的。 2.我们使用组件时发生了什么? 比如定义了一个school,然后在页面上使用它 我们只需要写 < school/ > 或< school &…...

不同时间间隔数据对统计结果的影响
目录摘要1. 实测数据来源2. 数据分析方法3 结果分析3.1 波况分析摘要 采用不同的波浪观测方法所获得的波浪数据的时间间隔不一致,其数据的准确性须进行分析。基于大埕湾逐时周年波浪观测数据,截取不同时间间隔的波浪数据,采用统计和相关分析…...

hudi系列-数据写入方式及使用场景
hudi支持多种数据写入方式:insert、bulk_insert、upsert、boostrap,我们可以根据数据本身属性(append-only或upsert)来选择insert和upsert方式,同时也支持对历史数据的高效同步并嫁接到实时流程。 这里的使用技术组合为flink + hudi-0.11 upsert 这是hudi默认的写入方式,…...

C # FileStream文件流
本章讲述:FileStream类的基本功能,以及简单示例; 1、引用命名空间:using System.IO; 2、注意:使用IO操作文件时,要注意流关闭和释放问题! 强力推荐:将创建文件流对象的过程写在usi…...
Go语言中的保留字和运算符详解
前言 🏠个人主页:我是沐风晓月 🧑个人简介:大家好,我是沐风晓月,双一流院校计算机专业,阿里云博客专家 😉😉 💕 座右铭: 先努力成长自己ÿ…...
C语言基础)
Linux编译之(1)C语言基础
Linux编译之C语言基础 Author:Once Day Date:2023年3月11日 漫漫长路,才刚刚开始… 1.概述 在Linux下开发多源文件的C代码文件,是一定要了解Makefile的,虽然现在构建工具很多,但学习的一开始࿰…...
CPU平均负载高问题定位分析
一、Linux操作系统CPU平均负载 1.1什么是CPU平均负载 1.2 怎么查看平均负载数值 二、Linux操作系统CPU使用率和平均负载区别 CPU使用率和平均负载区别 三、阿里云Linux操作系统CPU压测环境准备 3.1 核心命令应用场景 3.2 模拟生产环境出现的多种问题环境准备 分析工具安…...

Python蓝桥杯训练:基本数据结构 [二叉树] 中
Python蓝桥杯训练:基本数据结构 [二叉树] 中 文章目录Python蓝桥杯训练:基本数据结构 [二叉树] 中一、[翻转二叉树](https://leetcode.cn/problems/invert-binary-tree/)二、[对称二叉树](https://leetcode.cn/problems/symmetric-tree/)三、[二叉树的最…...
 – UDS 协议)
读取 DTC 信息服务 (0x19) – UDS 协议
总目录链接>> AutoSAR入门和实战系列总目录 0x19读取 DTC 信息服务概述 读取 DTC 信息服务在 UDS 协议中用于从车辆或特定 ECU 或节点读取 DTC。UDS 协议的主要任务之一是故障诊断。每当车辆发生任何故障时,与该故障相对应的诊断故障代码(DTC&a…...

Hive 分区表新增字段 cascade
背景 在以前上线的分区表中新加一个字段,并且要求添加到指定的位置列。 模拟测试 加 cascade 操作 创建测试表 create table if not exists sqltest.table_add_column_test(org_col1 string comment 原始数据1,org_col2 string comment 原始数据2 ) comment 增…...

【Java版oj】day08两种排序方法、最小公倍数
目录 一、两种排序方法 (1)原题再现 (2)问题分析 (3)完整代码 二、最小公倍数 (1)原题再现 (2)问题分析 (3)完整代码 一、两种…...

FinOps,从概念到落地 | UGeek大咖说第一期直播回顾(上)
2023年2月28日,由优维科技联合FinOps产业推进方阵举办了第1期「UGeek大咖说-极致用云共济FinOps」线上直播活动,来自中国信通院及美图公司技术专家共同带来了一场精彩的技术视听盛宴。 直 播 背 景 目前,许多以“上云”为数字化转型路径的企…...

k8s java程序实现kubernetes Controller Operator 使用CRD 学习总结
k8s java程序实现kubernetes Controller & Operator 使用CRD 学习总结 大纲 原理Controller 与 Operator自定义资源定义 CRD ( CustomResourceDefinition)kubernetes-client使用java fabric8io/kubernetes-client操作k8s 原生资源使用java abric8io/kubernetes-clientt操…...
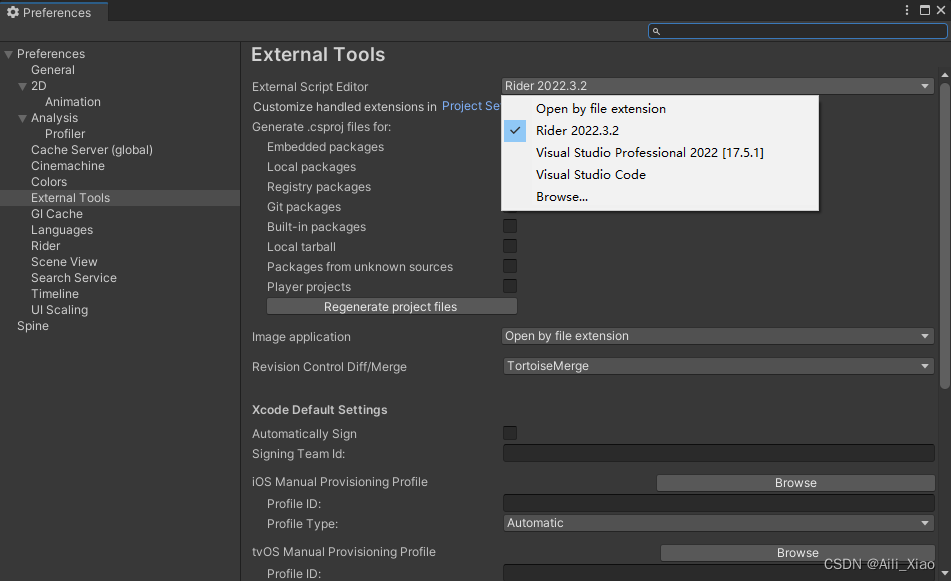
Unity笔记:修改代码执行的默认打开方式
使用 External Tools 偏好设置可设置用于编写脚本、处理图像和进行源代码控制的外部应用程序。 External Script Editor:选择 Unity 应使用哪个应用程序来打开脚本文件。Unity 会自动将正确的参数传递给内置支持的脚本编辑器。Unity 内置支持 Visual Studio Commun…...

Linux IPC:匿名管道 与 命名管道
目录一、管道的理解二、匿名管道三、命名管道四、管道的通信流程五、管道的特性进程间通信方式有多种,本文介绍的是管道,管道分为匿名管道和命名管道。 一、管道的理解 生活中的管道用来传输资源,例如水、石油之类的资源。而进程间通信的管道…...

阿里研发工程师JAVA暑期实习一面
文章目录先说一下我自己的情况面试过程总结先说一下我自己的情况 我就读于湖南大学,软件工程专业,现在大三下 很巧的是,我在大二的时候就在相同的时间面过相同的部门和相同的岗位,所以我没有做笔试就直接让我去面试了。我当时还纳…...
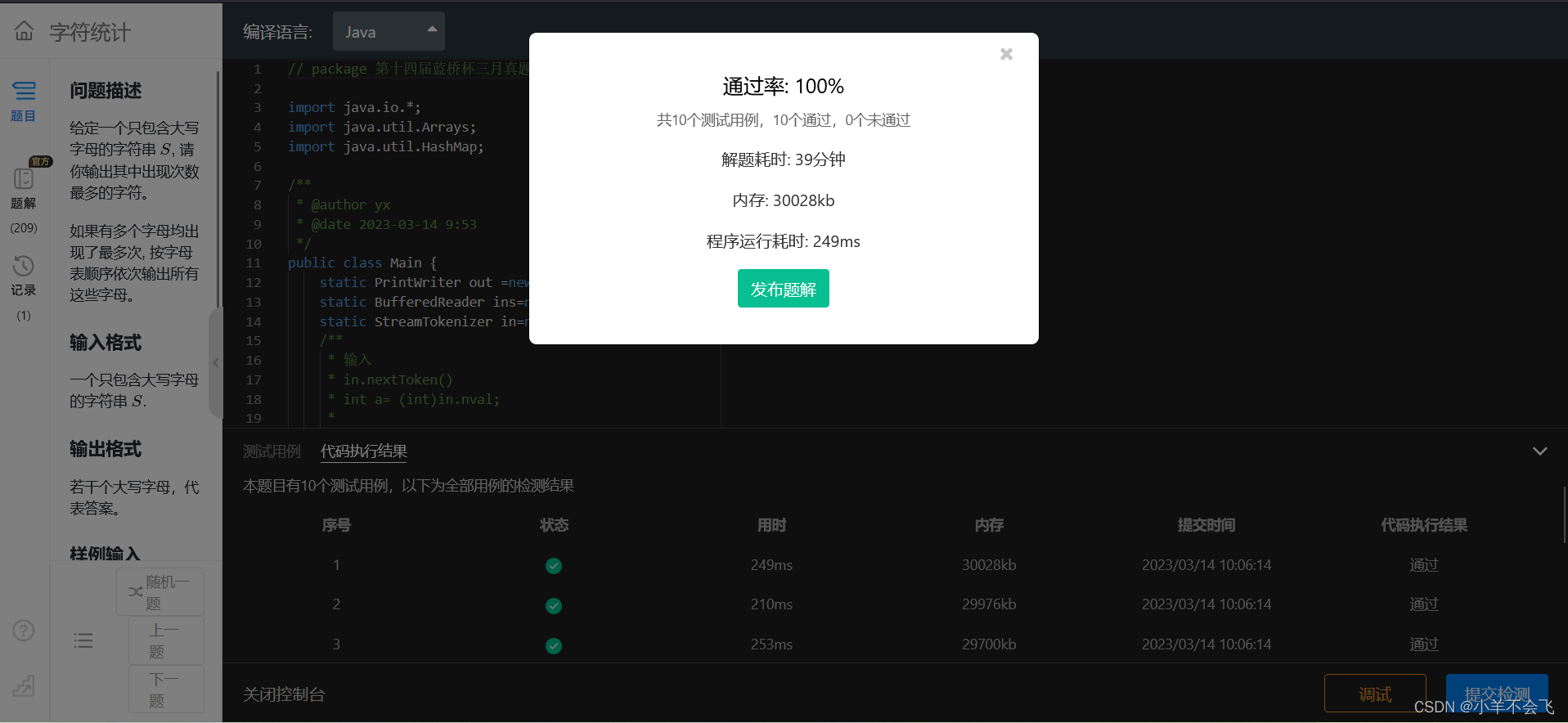
第十四届蓝桥杯三月真题刷题训练——第 11 天
目录 第 1 题:卡片 题目描述 运行限制 第 2 题:路径_dpgcd 运行限制 第 3 题:字符统计 问题描述 输入格式 输出格式 样例输入 样例输出 评测用例规模与约定 运行限制 第 4 题:费用报销 第 1 题:卡片 题…...
上快速部署GCC的三种‘懒人’方法)
告别源码编译:在ARM服务器(如华为云鲲鹏)上快速部署GCC的三种‘懒人’方法
在ARM服务器上高效部署GCC的三大实战方案 当你在华为云鲲鹏或AWS Graviton等ARM架构服务器上搭建开发环境时,是否曾被繁琐的GCC源码编译过程困扰?本文将分享三种经过实战验证的快速部署方案,帮助你在aarch64架构的Linux系统中,用最…...

小程序开发实战:解决openid获取失败之invalid code错误解析
1. 为什么会出现invalid code错误? 最近在开发小程序时,不少小伙伴都遇到了获取openid失败的问题,错误提示是"invalid code",错误码40029。这个问题看似简单,但背后隐藏着几个关键点需要理解。 首先我们要明…...
)
OpenClaw环境搭建:Mac系统下龙虾智能体快速部署教程(M1/M2芯片适配)
OpenClaw环境搭建:Mac系统下龙虾智能体快速部署教程(M1/M2芯片适配)📚 本章学习目标:深入理解OpenClaw环境搭建的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《…...

3步实现百度网盘链接解析:Baiduwp-PHP工具全功能实践指南
3步实现百度网盘链接解析:Baiduwp-PHP工具全功能实践指南 【免费下载链接】baiduwp-php A tool to get the download link of the Baidu netdisk / 一个获取百度网盘分享链接下载地址的工具 项目地址: https://gitcode.com/gh_mirrors/ba/baiduwp-php Baiduw…...

别只调AE了!Sensor调试中那些容易被忽略的‘暗坑’:电源噪声、镜头匹配与Raw图分析实战
别只调AE了!Sensor调试中那些容易被忽略的‘暗坑’:电源噪声、镜头匹配与Raw图分析实战 当工程师们成功点亮一颗新的图像传感器(Sensor)并完成基础AE配置后,往往容易陷入一种"能出图即达标"的思维定式。然而…...

DeepSeek-OCR效果展示:中英文混排+数学公式+跨页表格精准还原
DeepSeek-OCR效果展示:中英文混排数学公式跨页表格精准还原 1. 引言:当文档解析遇到真正的挑战 你有没有遇到过这样的场景? 一份技术文档,里面既有中文说明,又有英文术语,中间还夹杂着复杂的数学公式&am…...

vRealize Operations Manager 巡检报告深度定制:从默认模板到贴合你业务的实际仪表板
vRealize Operations Manager 巡检报告深度定制:从默认模板到贴合你业务的实际仪表板 在虚拟化环境管理中,一份好的巡检报告不仅是技术状态的快照,更是连接IT运维与业务决策的桥梁。许多资深运维团队都面临这样的困境:默认生成的巡…...

脉冲电解射流加工喷射装置设计【 任务书 论文 CAD图纸 开题报告 外文翻译】
脉冲电解射流加工喷射装置是精密加工领域的关键设备,其核心作用在于通过高压脉冲电解液与高速射流的协同作用,实现复杂曲面或微细结构的定向蚀除。该装置集流体力学、电化学及精密控制技术于一体,通过优化电解液喷射参数与脉冲电源特性&#…...

薄膜型声学超材料在汽车NVH中的应用:COMSOL仿真全流程解析
薄膜型声学超材料在汽车NVH优化中的COMSOL仿真实践 汽车NVH(噪声、振动与声振粗糙度)性能直接影响驾乘体验,而传统吸隔声材料在低频段往往表现不佳。薄膜型声学超材料通过局域共振机制打破了质量定律限制,为200-1000Hz频段的噪声…...
参数详解与典型应用场景)
图像处理避坑指南:Pillow的ImageOps.expand()参数详解与典型应用场景
图像处理避坑指南:Pillow的ImageOps.expand()参数详解与典型应用场景 在数字图像处理领域,边界填充是最基础却最容易出错的环节之一。许多开发者在使用Pillow库时,往往对ImageOps.expand()函数掉以轻心,直到项目上线才发现图像边缘…...