离线数据仓库
1 数据仓库建模
1.1 建模工具
PowerDesigner/SQLYog/EZDML…
1.2 ODS层
(1)保持数据原貌不做任何修改,起到备份数据的作用。
(2)数据采用压缩,减少磁盘存储空间(例如:压缩采用LZO,压缩比是100g数据压缩完10g左右)
(3)创建分区表,防止后续的全表扫描
1.3 DWD层
DWD层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
(1)选择业务过程
在业务系统中,如果业务表过多,挑选感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。如果小公司业务表比较少,建议选择所有业务线。
(2)声明粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
典型的粒度声明如下:
① 订单当中的每个商品项作为下单事实表中的一行,粒度为每次
② 每周的订单次数作为一行,粒度为每周。
③ 每月的订单次数作为一行,粒度为每月。
如果在DWD层粒度就是每周或者每月,那么后续就没有办法统计细粒度的指标了。所有建议采用最小粒度。
(3)确定维度
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。 例如:时间维度、用户维度、地区维度等常见维度。
(4)确定事实
“事实”指的是业务中的度量值,例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
通过以上步骤,结合数仓的业务事实可以得出业务总线矩阵表。业务总线矩阵的原则,主要是根据维度表和事实表之间的关系,如果两者有关联则使用√标记。
业务总线矩阵表示例:
| 时间 | 用户 | 地区 | 商品 | 优惠券 | 活动 | 编码 | 度量值 | |
|---|---|---|---|---|---|---|---|---|
| 订单 | √ | √ | √ | √ | 件数/金额 | |||
| 订单详情 | √ | √ | √ | 件数/金额 | ||||
| 支付 | √ | √ | √ | 次数/金额 | ||||
| 加购 | √ | √ | √ | 件数/金额 | ||||
| 收藏 | √ | √ | √ | 个数 | ||||
| 评价 | √ | √ | √ | 个数 | ||||
| 退款 | √ | √ | √ | 件数/金额 | ||||
| 优惠券领用 | √ | √ | √ | 个数 |
维度退化:
根据维度建模中的星型模型思想,将维度进行退化。 例如下图所示:地区表和省份表退化为地区维度表,商品表、品类表、spu表、商品三级分类、商品二级分类、商品一级分类表退化为商品维度表,活动信息表和活动规则表退化为活动维度表。
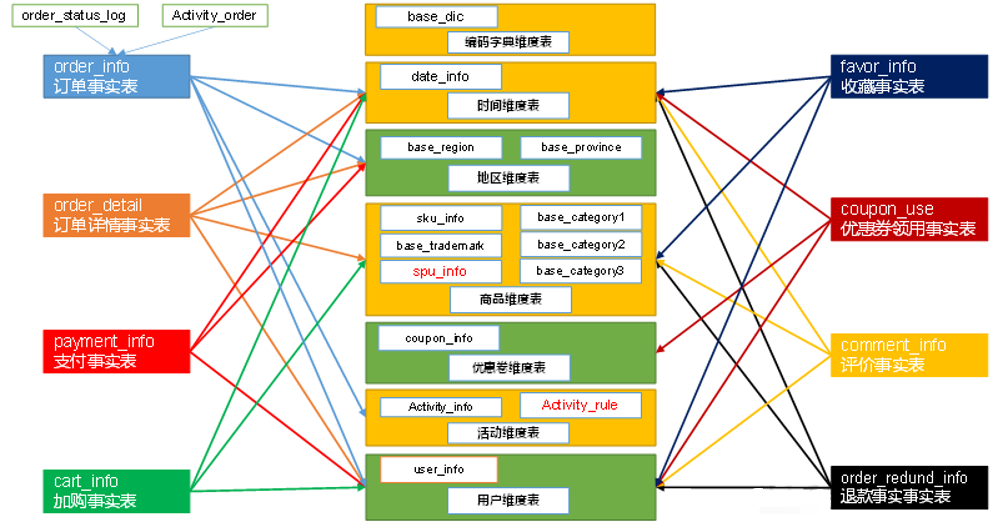
至此,数仓的维度建模已经完毕,DWS、DWT和ADS和维度建模已经没有关系了。
DWS和DWT都是建宽表,宽表都是按照主题去建。主题相当于观察问题的角度。对应着维度表。
1.3.1 数据清洗
① 空值去除
② 过滤核心字段无意义的数据,比如订单表中订单id为null,支付表中支付id为空
③ 将用户行为宽表和业务表进行数据一致性处理
select case when a is null then b else a end as JZR,...
from A
④ 对手机号、身份证号等敏感数据脱敏
1.3.2 清洗的手段
HQL、MR、SparkSQL、Kettle、Python
1.3.3 维度退化
对业务数据传过来的表进行维度退化和降维。(商品一级二级三级、省市县、年月日)
商品表、spu表、品类表、商品一级分类、二级分类、三级分类=》商品表
省份表、地区表=》地区表
1.3.4 存储格式
数据压缩:LZO,BZip,Snappy…
列式存储:textFile,ORC,Parquet,一般企业里使用ORC或者Parquet,因为是列式存储,且压缩比非常高,所以相比于textFile,查询速度快,占用硬盘空间少
1.4 DWS层
DWS层统计各个主题对象的当天行为,服务于DWT层的主题宽表。如图所示,DWS层的宽表字段,是站在不同维度的视角去看事实表,重点关注事实表的度量值,通过与之关联的事实表,获得不同的事实表的度量值。
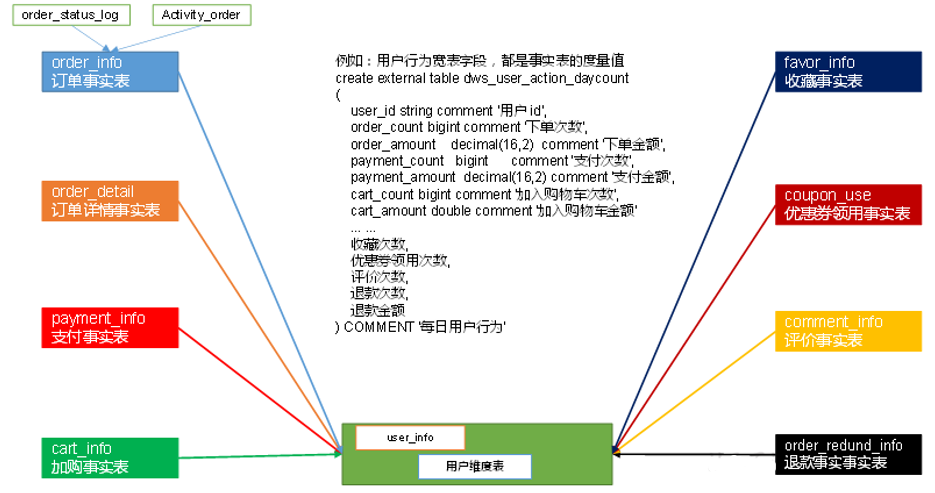
用户行为宽表,商品宽表,访客宽表、活动宽表、优惠卷、地区表等。
用户行为宽表示例:
评论、打赏、收藏、关注–商品、关注–人、点赞、分享、好价爆料、文章发布、活跃、签到、补签卡、幸运屋、礼品、金币、电商点击、gmv
CREATE TABLE `app_usr_interact`(`stat_dt` date COMMENT '互动日期', `user_id` string COMMENT '用户id', `nickname` string COMMENT '用户昵称', `register_date` string COMMENT '注册日期', `register_from` string COMMENT '注册来源', `remark` string COMMENT '细分渠道', `province` string COMMENT '注册省份', `pl_cnt` bigint COMMENT '评论次数', `ds_cnt` bigint COMMENT '打赏次数', `sc_add` bigint COMMENT '添加收藏', `sc_cancel` bigint COMMENT '取消收藏', `gzg_add` bigint COMMENT '关注商品', `gzg_cancel` bigint COMMENT '取消关注商品', `gzp_add` bigint COMMENT '关注人', `gzp_cancel` bigint COMMENT '取消关注人', `buzhi_cnt` bigint COMMENT '点不值次数', `zhi_cnt` bigint COMMENT '点值次数', `zan_cnt` bigint COMMENT '点赞次数', `share_cnts` bigint COMMENT '分享次数', `bl_cnt` bigint COMMENT '爆料数', `fb_cnt` bigint COMMENT '好价发布数', `online_cnt` bigint COMMENT '活跃次数', `checkin_cnt` bigint COMMENT '签到次数', `fix_checkin` bigint COMMENT '补签次数', `house_point` bigint COMMENT '幸运屋金币抽奖次数', `house_gold` bigint COMMENT '幸运屋积分抽奖次数', `pack_cnt` bigint COMMENT '礼品兑换次数', `gold_add` bigint COMMENT '获取金币', `gold_cancel` bigint COMMENT '支出金币', `surplus_gold` bigint COMMENT '剩余金币', `event` bigint COMMENT '电商点击次数', `gmv_amount` bigint COMMENT 'gmv', `gmv_sales` bigint COMMENT '订单数')
PARTITIONED BY ( `dt` string)
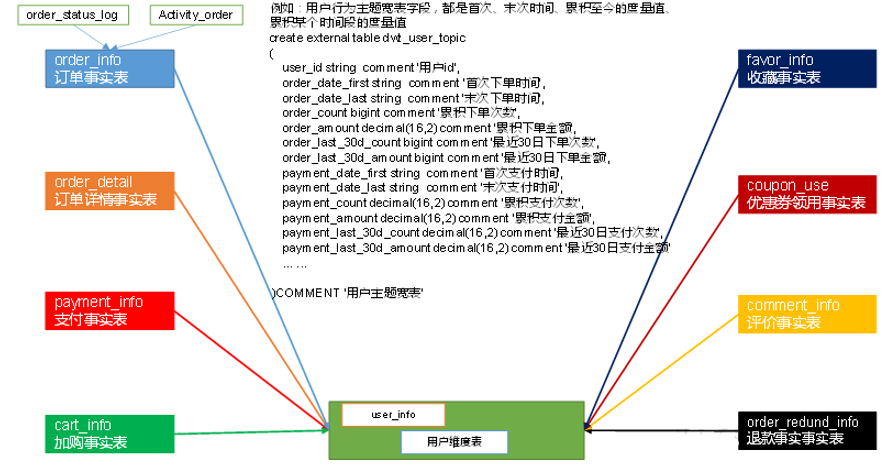
1.5 DWT层
以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建主题对象的全量宽表。
DWT层主题宽表都记录什么字段?
如图所示,每个维度关联的不同事实表度量值以及首次、末次时间、累积至今的度量值、累积某个时间段的度量值。
1.6 ADS层
分别对设备主题、会员主题、商品主题和营销主题进行指标分析,其中营销主题是用户主题和商品主题的跨主题分析案例。
指标示例:日活、月活、周活、留存、留存率、新增(日、周、年)、转化率、流失、回流、七天内连续3天登录(点赞、收藏、评价、购买、加购、下单、活动)、连续3周(月)登录、GMV、复购率、复购率排行、点赞、评论、收藏、领优惠卷人数、使用优惠卷人数、沉默、值不值得买、退款人数、退款率 topn 热门商品

2 维度表和事实表
2.1 维度表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
2.2 事实表
事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、件数、金额等),例如,订单事件中的下单金额。
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键、通常具有两个和两个以上的外键、外键之间表示维表之间多对多的关系。
2.2.1 事务型事实表
以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量更新。
2.2.2 周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。
2.2.3 累积型快照事实表
累计快照事实表用于跟踪业务事实的变化。例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。
| 订单id | 用户id | 下单时间 | 打包时间 | 发货时间 | 签收时间 | 订单金额 |
|---|---|---|---|---|---|---|
| 3-8 | 3-8 | 3-9 | 3-10 |
3 同步策略

4 关系型数据库范式理论(ER建模)
三范式:
1NF:属性不可再分割(例如不能存在5台电脑的属性,坏处:表都没法用)
2NF:不能存在部分函数依赖(例如主键(学号+课名)–>成绩,姓名,但学号–》姓名,所以姓名部分依赖于主键(学号+课名),所以要去除,坏处:数据冗余)
3NF:不能存在传递函数依赖(学号–》宿舍种类–》价钱,坏处:数据冗余和增删异常)
MySQL关系模型:关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。
Hive 维度模型:维度模型主要应用于OLAP系统中,因为关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以HIVE把相关各种表整理成两种:事实表和维度表两种。所有维度表围绕着事实表进行解释。
5 数据模型
星型模型(一级维度表)
雪花(多级维度)
星座模型(星型模型+多个事实表)
6 拉链表 (数据仓库中如何创建拉链表?)
拉链表处理的业务场景:主要处理缓慢变化维的业务场景(用户表、订单表)。
7 即席查询数据仓库

Kylin: T+1
Impala: CDH
Presto: Apache版本框架
8 权限管理
Ranger或Sentry
CDH cloudmanager-》sentry
HDP ambari=>ranger
① 用户认证kerberos(张三、李四、王五)
② 表级别权限(张三、李四)
③ 字段级别权限(李四)
9 可视化报表工具
Echarts(百度开源)
Kibana(开源)
Tableau(功能强大的收费软件)
Superset(功能一般免费)
QuickBI(阿里云收费的离线)
DataV(阿里云收费的实时)
suga(百度,收费)
10 集群监控工具
Zabbix+ Grafana
Prometheus&Grafana监控
睿象云
11 元数据管理(Atlas血缘系统)
insert into table ads_userselect id, name from dwt_user
依赖关系能够做到:表级别和字段级别
用处:作业执行失败,评估他的影响范围。 主要用于表比较多的公司。
12 数据质量监控(Griffin)
12.1 监控原则
12.1.1 单表数据量监控
一张表的记录数在一个已知的范围内,或者上下浮动不会超过某个阈值
-
SQL结果:var 数据量 = select count(*)from 表 where 时间等过滤条件
-
报警触发条件设置:如果数据量不在[数值下限, 数值上限], 则触发报警
-
同比增加:如果((本周的数据量 - 上周的数据量)/上周的数据量*100)不在 [比例下线,比例上限],则触发报警
-
环比增加:如果((今天的数据量 - 昨天的数据量)/昨天的数据量*100)不在 [比例下线,比例上限],则触发报警
-
报警触发条件设置一定要有。如果没有配置的阈值,不能做监控
12.1.2 单表空值检测
某个字段为空的记录数在一个范围内,或者占总量的百分比在某个阈值范围内
-
目标字段:选择要监控的字段,不能选“无”
-
SQL结果:var 异常数据量 = select count(*) from 表 where 目标字段 is null
-
单次检测:如果(异常数据量)不在[数值下限, 数值上限],则触发报警
12.1.3 单表重复值检测
一个或多个字段是否满足某些规则
-
目标字段:第一步先正常统计条数;select count(*) form 表;
-
第二步,去重统计;select count(*) from 表 group by 某个字段
-
第一步的值和第二步不的值做减法,看是否在上下线阀值之内
-
单次检测:如果(异常数据量)不在[数值下限, 数值上限], 则触发报警
12.1.4 单表值域检测
一个或多个字段没有重复记录
-
目标字段:选择要监控的字段,支持多选
-
检测规则:填写“目标字段”要满足的条件。其中$1表示第一个目标字段,$2表示第二个目标字段,以此类推。上图中的“检测规则”经过渲染后变为“delivery_fee = delivery_fee_base+delivery_fee_extra”
-
阈值配置与“空值检测”相同
12.1.5 跨表数据量对比
主要针对同步流程,监控两张表的数据量是否一致
-
SQL结果:count(本表) - count(关联表)
-
阈值配置与“空值检测”相同
12.2 数据质量实现
数据质量的高低代表了该数据满足数据消费者期望的程度,这种程度基于他们对数据的使用预期,只有达到数据的使用预期才能给予管理层正确的决策参考。数据质量管理作为数据仓库的一个重要模块,主要可以分为数据的健康标准量化、监控和保障。
12.2.1 数据质量标准分类
① 数据完整性: 数据不存在大量的缺失值、不缺少某一日期/部门/地点等部分维度的数据,同时在ETL过程当中应保证数据的完整不丢失。验证数据时总数应符合正常规律时间推移,记录数总数的增长符合正常的趋势。
② 数据一致性: 数仓各层的数据,应与上一层保持数据一致,最终经过数据清洗转化(ETL)的宽表/指标能和数据源保持一致。
12.2.2 数据质量管理解决方案
① 可以通过Shell命令和Hive脚本的方式,通过验证增量数据的记录数、全表空值记录数、全表记录数是否在合理的范围之内,以及验证数据来源表和目标表一致性,确定当日的数据是否符合健康标准,达到数据质量的监控与管理。
② 数据质量之Griffin,Griffin有着较为严重的版本依赖;Apache Griffin是一个开源的大数据数据质量解决方案,它支持批处理和流模式两种数据质量检测方式,可以从不同维度度量数据资产,从而提升数据的准确度和可信度。例如:离线任务执行完毕后检查源端和目标端的数据数量是否一致,源表的数据空值等。
13 数据治理
包括:数据质量管理、元数据管理、权限管理(ranger sentry)、数仓
2019年下半年 国家出了一本白皮书,要求给政府做的数仓项目,要具备如下功能:
数据治理是一个复杂的系统工程,涉及到企业和单位多个领域,既要做好顶层设计,又要解决好统一标准、统一流程、统一管理体系等问题,同时也要解决好数据采集、数据清洗、数据对接和应用集成等相关问题。
数据治理实施要点主要包含数据规划、制定数据标准、整理数据、搭建数据管理工具、构建运维体系及推广贯标六大部分,其中数据规划是纲领、制定数据标准是基础、整理数据是过程、搭建数据管理工具是技术手段、构建运维体系是前提,推广贯标是持续保障。
14 数据中台
传统IT企业,项目的物理结构都可分为“前台”和“后台”这两部分,所谓前台即包括各种和用户直接交互的界面,比如web页面,手机app;也包括服务端各种实时响应用户请求的业务逻辑,比如商品查询、订单系统等等;后台并不直接面向用户,而是面向运营人员的配置管理系统,比如商品管理、物流管理、结算管理。后台为前台提供了一些简单的配置。

传统项目痛点–重复造轮子:

14.1 各家中台架构示例
1)SuperCell公司

2)阿里巴巴提出了“大中台,小前台”的战略

3)华为提出了“平台炮火支撑精兵作战”的战略

14.2 中台具体划分
1)业务中台

2)技术中台

3)数据中台

4)算法中台

14.3 中台使用场景
① 从0到1的阶段,没有必要搭建中台。(从0到1的创业型公司)
② 从1到N的阶段,适合搭建中台。(当企业有了一定规模)
③ 从N到N+1的阶段,搭建中台势在必行。
15 数据湖
数据湖(Data Lake)是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。
hudi、iceberg、Data Lake
目前,Hadoop是最常用的部署数据湖的技术,所以很多人会觉得数据湖就是Hadoop集群。数据湖是一个概念,而Hadoop是用于实现这个概念的技术。
| 数据仓库 | 数据湖 |
|---|---|
| 主要处理历史的、结构化的数据,而且这些数据必须与数据仓库事先定义的模型吻合。 | 能处理所有类型的数据,如结构化数据,非结构化数据,半结构化数据等,数据的类型依赖于数据源系统的原始数据格式。非结构化数据(语音、图片、视频等) |
| 数据仓库分析的指标都是产品经理提前规定好的。按需分析数据。(日活、新增、留存、转化率) | ①根据海量的数据,挖掘出规律,反应给运营部门。②从海量的数据中找寻规律。拥有非常强的计算能力用于处理数据。③数据挖掘 |
16 数据埋点
收费的埋点:神策 https://mp.weixin.qq.com/s/Xp3-alWF4XHvKDP9rNWCoQ
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点三种。
代码埋点是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
17 电商8类基本指标








18 直播指标






相关文章:
离线数据仓库
1 数据仓库建模 1.1 建模工具 PowerDesigner/SQLYog/EZDML… 1.2 ODS层 (1)保持数据原貌不做任何修改,起到备份数据的作用。 (2)数据采用压缩,减少磁盘存储空间(例如:压缩采用LZO&…...
【前端】Vue项目:旅游App-(23)detail:房东介绍、热门评论、预定须知组件
文章目录目标过程与代码房东介绍landlord热门评论HotComment预定须知Book效果总代码修改或添加的文件detail.vuedetail-book.vuedetail-hotComment.vuedetail-landlord.vue参考本项目博客总结:【前端】Vue项目:旅游App-博客总结 目标 根据detail页面获…...

JUC并发编程与源码分析
一、本课程前置知识及要求说明 二、线程基础知识复习 三、CompletableFuture 四、说说Java"锁"事 8锁案例原理解释: 五、LockSupport与线程中断 六、 Java内存模型之JMM 七、volatile与JMM 八、CAS 九、原子操作类之18罗汉增强 十、聊聊ThreadLocal 十一、Java对…...
Spark09: Spark之checkpoint
一、checkpoint概述 checkpoint,是Spark提供的一个比较高级的功能。有时候,我们的Spark任务,比较复杂,从初始化RDD开始,到最后整个任务完成,有比较多的步骤,比如超过10个transformation算子。而…...

《剑指offer》:数组部分
一、数组中重复的数字题目描述:在一个长度为n的数组里的所有数字都在0到n-1的范围内。 数组中某些数字是重复的,但不知道有几个数字是重复的。也不知道每个数字重复几次。请找出数组中任意一个重复的数字。 例如,如果输入长度为7的数组{2,3,1…...
基于微信小程序图书馆座位预约管理系统
开发工具:IDEA、微信小程序服务器:Tomcat9.0, jdk1.8项目构建:maven数据库:mysql5.7前端技术:vue、uniapp服务端技术:springbootmybatis本系统分微信小程序和管理后台两部分,项目采用…...
)
剑指 Offer Day1——栈与队列(简单)
本专栏将记录《剑指 Offer》的刷题,传送门:https://leetcode.cn/study-plan/lcof/。 目录剑指 Offer 09. 用两个栈实现队列剑指 Offer 30. 包含min函数的栈剑指 Offer 09. 用两个栈实现队列 原题链接:09. 用两个栈实现队列 class CQueue { pu…...
详解Python正则表达式中group与groups的用法
在Python中,正则表达式的group和groups方法是非常有用的函数,用于处理匹配结果的分组信息。 group方法是re.MatchObject类中的一个函数,用于返回匹配对象的整个匹配结果或特定的分组匹配结果。而groups方法同样是re.MatchObject类中的函数&am…...

Spring面试重点(三)——AOP循环依赖
Spring面试重点 AOP 前置通知(Before):在⽬标⽅法运行之前运行;后置通知(After):在⽬标⽅法运行结束之后运行;返回通知(AfterReturning):在⽬标…...
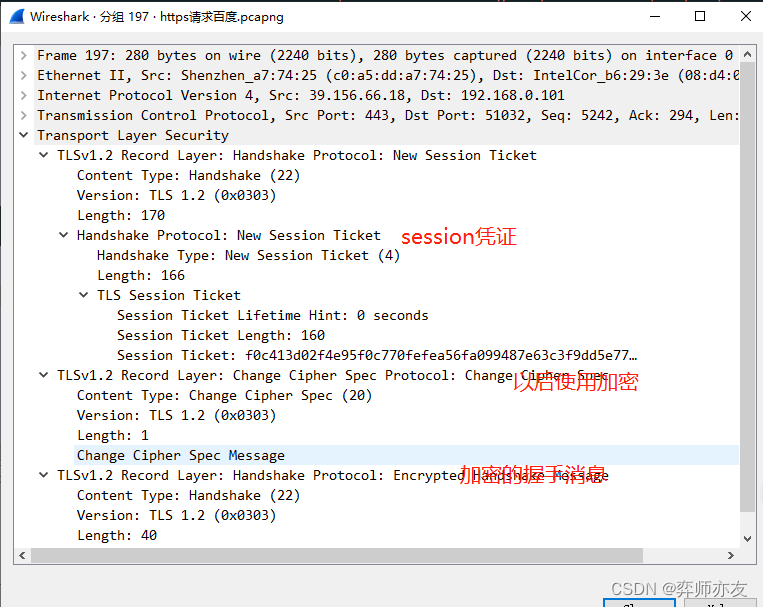
计算机网络之HTTP04ECDHE握手解析
DH算法 离散读对数问题是DH算法的数学基础 (1)计算公钥 (2)交换公钥,并计算 对方公钥^我的私钥 mod p 离散对数的交换幂运算交换律使二者算出来的值一样,都为K k就是对称加密的秘钥 2. DHE算法 E&#…...
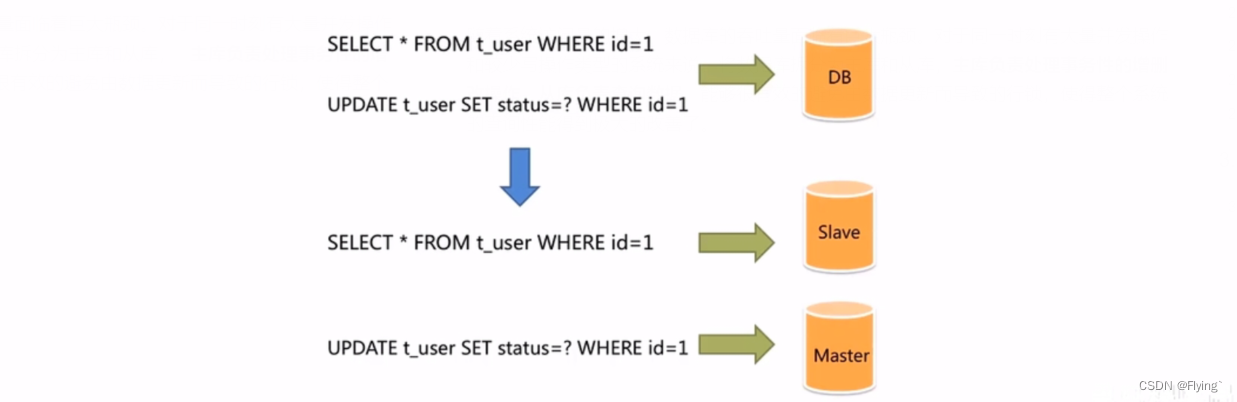
【MySQL数据库】主从复制原理和应用
主从复制和读写分离1. 主从复制的原理2. 主从复制的环境配置2.1 准备好数据库服务器2.2 配置master2.3 配置slave2.4 测试3. 主从复制的应用——读写分离3.1 读写分离的背景3.2 Sharding-JDBC介绍3.3 Sharding-JDBC使用步骤1. 主从复制的原理 MySQL主从复制是一个异步的过程&a…...
复现随记~
note(美团2022) 比较简单的越界漏洞,堆本身并没有什么漏洞,而且保护并没全开,所以逆向思维。必然是ROP类而非指针类,故我们着重注意unsigned int等无符号数前后是否不一致 int __fastcall edit(__int64 a1) {int idx; // [rsp14…...
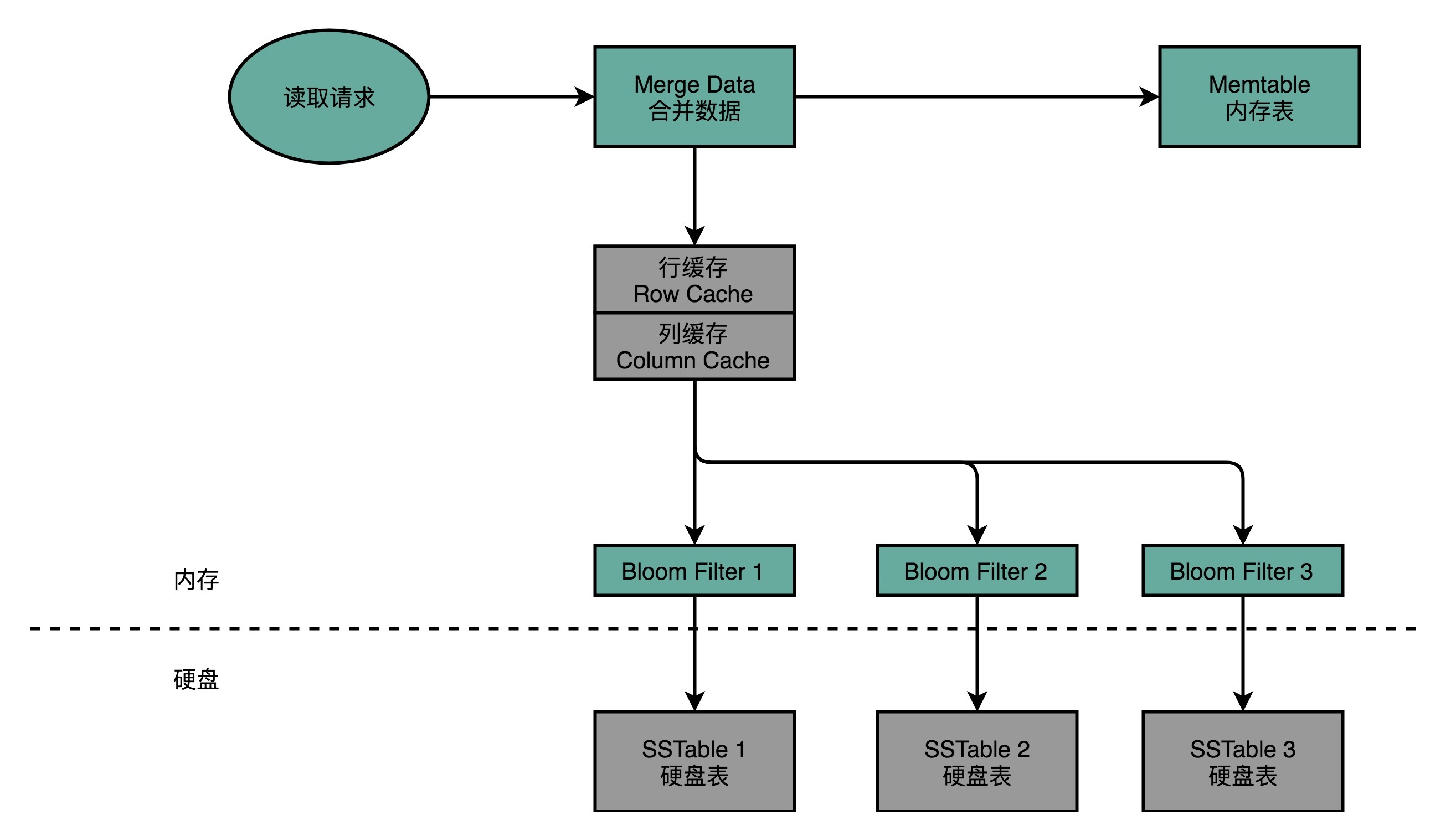
【计组】设计大型DMP系统--《深入浅出计算机组成原理》(十四)
目录 一、DMP:数据管理平台 二、MongoDB 真的万能吗 三、关系型数据库:不得不做的随机读写 (一)Cassandra:顺序写和随机读 1、Cassandra 的数据模型 2、Cassandra 的写操作 3、Cassandra 的读操作 (…...

66 使用注意力机制的seq2seq【动手学深度学习v2】
66 使用注意力机制的seq2seq【动手学深度学习v2】 深度学习学习笔记 学习视频:https://www.bilibili.com/video/BV1v44y1C7Tg/?spm_id_from…top_right_bar_window_history.content.click&vd_source75dce036dc8244310435eaf03de4e330 在机器翻译时,…...
)
NextJS(ReactSSR)
pre-render: 预渲染 1. 静态化 发生的时间:next build 1). 纯静态化 2). SSG: server static generator getStaticProps: 当渲染组件之前会运行 生成html json //该函数只可能在服务端运行 //该函数运行在组件渲染之前 //该函数只能在build期间运…...

JointBERT代码复现详解【上】
BERT for Joint Intent Classification and Slot Filling代码复现【上】 源码链接:JointBERT源码复现(含注释) 一、准备工作 源码架构 data:存放两个基准数据集;model:JointBert模型的实现;…...
进程间通信(上)
进程间通信(上)背景进程间通信目的进程间通信发展进程间通信分类管道什么是管道匿名管道实例代码简单的匿名管道实现一个父进程控制单个子进程完成指定任务父进程控制一批子进程完成任务(进程池)用fork来共享管道站在文件描述符角…...
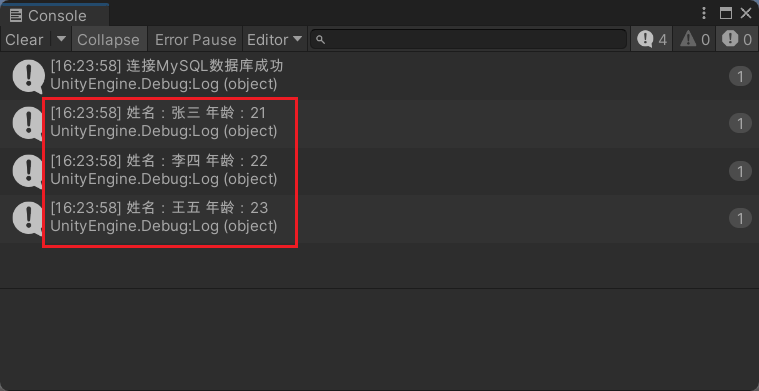
【Unity3D】Unity 3D 连接 MySQL 数据库
1.Navicat准备 test 数据库,并在test数据库下创建 user 数据表,预先插入测试数据。 2.启动 Unity Hub 新建一个项目,然后在Unity编辑器的 Project视图 中,右击新建一个 Plugins 文件夹将连接 MySQL的驱动包 导入(附加驱…...
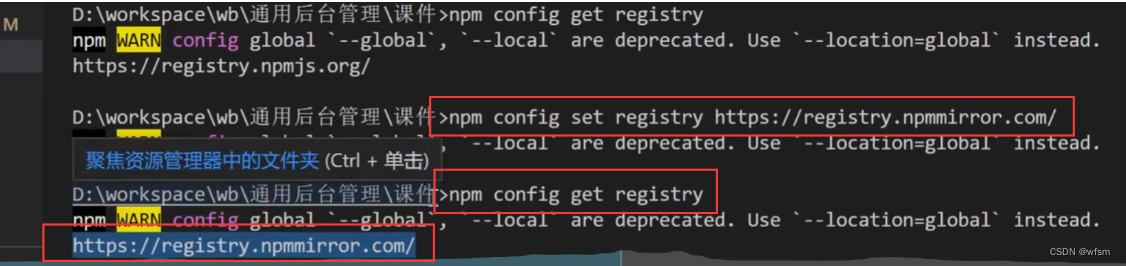
vue通用后台管理系统
用到的js库 遇到的问题 vuex和 localStorage区别 vuex在内存中,localStorage存在本地localStorage只能存储字符串类型数据,存储对象需要JSON.stringify() 和 parse()…读取内存比读取硬盘速度要快刷新页面vuex数据丢失,localStorage不会vuex…...
IDEA设置只格式化本次迭代变更的代码
趁着上海梅雨季节,周末狠狠更新一下。平常工作在CR的时候,经常发现会有新同事出现大量代码变更行..一看原因竟是在格式化代码时把历史代码也格式化掉了这样不仅坑了自己(覆盖率问题等),也可能会影响原始代码责任到人&a…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...