阶段三:项目开发---大数据开发运行环境搭建:任务4:安装配置Spark集群
任务描述
知识点:安装配置Spark
重 点: 安装配置Spark
难 点:无
内 容:
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
本任务主要内容是安装配置Spark,并搭建Spark HA高可用架构。
任务指导
安装Spark集群主要包括以下步骤:
1、下载Spark安装包,在各节点中安装部署spark集群
2、配置整合
3、启动并测试
注:Spark的运行方式分为三种,这里使用在工作中最常用的方式 Spark on YARN,将Spark托管到YARN上运行
任务实现
1. 下载Spark
可以从官方网站下载合适的版本。当前环境已经提供了安装包,存放在 /opt/software目录下。
2. 在node1节点上安装Spark
- 解压安装Spark
[root@node1 ~]# cd /opt/software/
[root@node1 software]# tar -xzf spark.tar.gz -C /opt/module/- 配置Spark环境变量,修改系统配置文件/etc/profile。
输入【# vim /etc/profile】命令,编辑/etc/profile文件,增加如下内容:
export SPARK_HOME=/opt/module/spark/
export PATH=$PATH:$SPARK_HOME/bin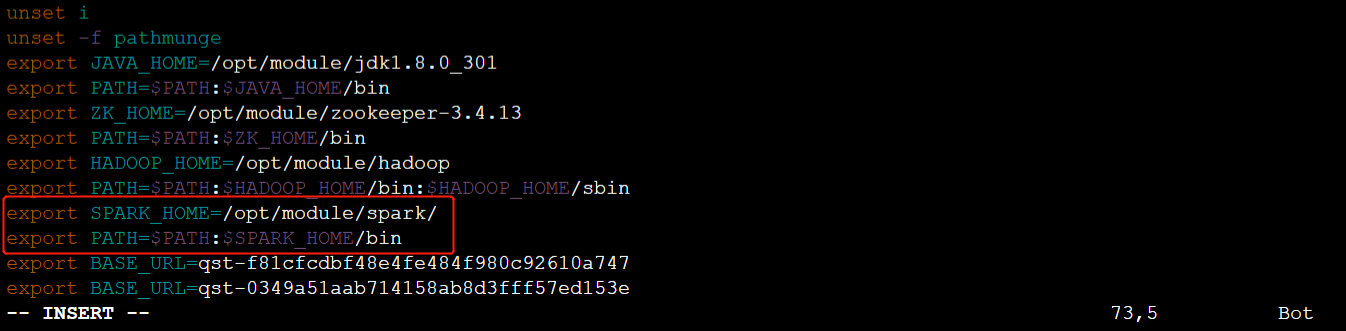
- 使用【source /etc/profile】命令使配置文件生效
[root@node1 software]# source /etc/profile- 进入/opt/module/spark/conf 配置文件夹
[root@node1 software]# cd $SPARK_HOME/conf- 配置spark-env.sh文件,配置过程如下:
使用【cp】命令,从spark-env.sh.template模板文件复制并创建spark-env.sh文件
[root@node1 conf]# cp spark-env.sh.template spark-env.sh然后使用【 vim spark-env.sh】命令编辑该文件
[root@node1 conf]# vim spark-env.sh添加如下内容:
export JAVA_HOME=/opt/module/jdk1.8.0_301
export HADOOP_CONF_DIR=/opt/module/hadoop/etc/hadoop
3. 将node1节点上的Spark分别都拷贝到node2、node3节点上
- 将配置好的Spark复制到其他节点对应位置上,通过scp命令发送。
[root@node1 conf]# scp -rq /opt/module/spark node2:/opt/module/
[root@node1 conf]# scp -rq /opt/module/spark node3:/opt/module/- 将配置好的环境变量/etc/profile复制到其他节点对应位置上,通过scp命令发送。
[root@node1 conf]# scp -rq /etc/profile node2:/etc/
[root@node1 conf]# scp -rq /etc/profile node3:/etc/4. Spark配置的常见问题
- Spark相关命令比较灵活,这里使用【 spark-shell --master yarn】进行测试,代码指定将Spark托管到YARN上
- 由于YARN调度机制的问题,Spark的资源无法被正确申请,所以需要修改Hadoop中的yarn-site.xml
- 进入node1的Hadoop配置目录
[root@node1 ~]# cd $HADOOP_HOME/etc/hadoop- 使用【vim】命令修改yarn-site.xml文件
[root@node1 hadoop]# vim yarn-site.xml - 在yarn-site.xml文件的<configuration>标签内,添加如下配置
<property>
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>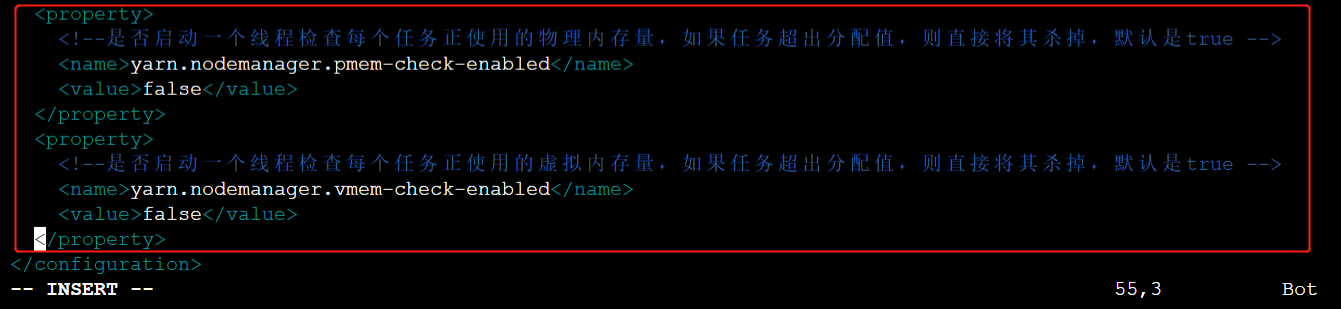
- 修改完成后将更新的yarn-site.xml文件分发至node2、node3的Hadoop配置文件目录中
[root@node1 hadoop]# scp yarn-site.xml node2:/opt/module/hadoop/etc/hadoop/
[root@node1 hadoop]# scp yarn-site.xml node3:/opt/module/hadoop/etc/hadoop/
- 在node1节点上,重启YARN集群
[root@node1 hadoop]# stop-yarn.sh
[root@node1 hadoop]# start-yarn.sh5. 测试Spark
- 在node1节点上,首先上传一个文件至HDFS目录
[root@node1 ~]# cd $HADOOP_HOME/
[root@node1 hadoop]# hdfs dfs -put README.txt /- 进入Spark Shell
[root@node1 hadoop]# spark-shell --master yarn
- 在Spark客户端执行如下代码,实现对HDFS上的 README.txt 文件的内容进行词频统计(即,统计每个单词在文档中出现的总次数),并将统计的结果保存到HDFS上的 /result目录下。
scala> sc.textFile("hdfs://node1:9000/README.txt").flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey((a,b) => a+b).saveAsTextFile("hdfs://node1:9000/result")- 输入【:quit】退出 Spark Shell
scala> :quit- 观察HDFS的/result目录中的数据,如果可以查看到词频统计的结果,则说明集群运行正常
[root@node1 hadoop]# hadoop fs -ls /result
[root@node1 hadoop]# hadoop fs -cat /result/part*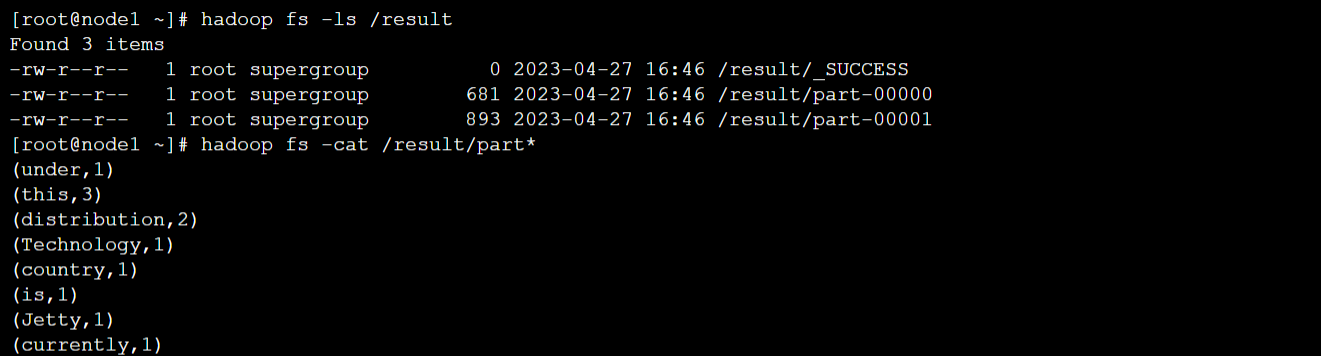
相关文章:
阶段三:项目开发---大数据开发运行环境搭建:任务4:安装配置Spark集群
任务描述 知识点:安装配置Spark 重 点: 安装配置Spark 难 点:无 内 容: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop …...

SDIO CMD 数据部分 CRC 计算规则
使用的在线 crc 计算工具网址:http://www.ip33.com/crc.html CMD CRC7 计算 如下图为使用逻辑分析仪获取的SDIO读写SD卡时,CMD16指令发送的格式,通过逻辑分析仪总线分析,可以看到,该部分的CRC7校验值得0x05,大多数情况…...

每日一编程,早点拿offer
计算字符串最后一个单词的长度,单词以空格隔开 输入描述: 输入一行,代表要计算的字符串,非空 输出描述: 输出一个整数,表示输入字符串最后一个单词的长度。 输入:hello world输出:…...

https创建证书
需要下载httpd模块:yum install httpd -y 前提需要先搭建一个虚拟主机来测试证书创建的效果,以下面www.hehe.com为例,可以参考创建: [rootlocalhost conf.d]# vim vhost.conf <directory /www> allowoverride none requi…...

C++ 是否变得比 C 更流行了?
每年都会出现一种新的编程语言。创造一种新语言来解决计算机科学中的挑战的诱惑很难抗拒。一些资料表明,目前有多达 2,500 种语言,这并不奇怪! 对于我们嵌入式软件开发人员来说,这个列表并不长。事实上,我们可以用一只…...

Redis-Jedis连接池\RedisTemplate\StringRedisTemplate
Redis-Jedis连接池\RedisTemplate\StringRedisTemplate 1. Jedis连接池1.1 通过工具类1.1.1 连接池:JedisConnectionFactory:1.1.2 test:(代码其实只有连接池那里改变了) 2. SpringDataRedis(lettuce&#…...

Obsidian 文档编辑器
Obsidian是一款功能强大的笔记软件 Download - Obsidian...

Spring Boot项目中JPA操作视图会改变原表吗?
一直有一种认识就是:使用JPA对视图操作,不会影响到原表。 直观的原因就是视图是一种数据库中的虚拟表,它由一个或多个表中的数据通过SQL查询组成。视图不包含数据本身,而是保存了一条SQL查询,这条查询是用来展示数据的。 但是在实际项目种的一个场景颠覆和纠正了这个认识…...

C++之goto陈述
关键字 goto用于控制程式执行的顺序,使程式直接跳到指定标签(lable) 的地方继续执行。 形式如下 标签可以是任意的识别字,后面接一个冒号。 举例如下 #include <iostream>int main() {goto label_one;label_one: {std::cout << "Lab…...

ChatGPT提问提示指南PDF下载经典分享推荐书籍
ChatGPT提问提示指南PDF,在本书的帮助下,您将学习到如何有效地向 ChatGPT 提出问题,以获得更准确和有用的回答。我们希望这本书能够为您提供实用的指南和策略,帮助您更好地与 ChatGPT 交互。 ChatGPT提问提示指南PDF下载 无论您是…...
云原生架构与实例部署)
架构设计(2)云原生架构与实例部署
云原生架构 云原生架构是一种面向云环境设计和构建应用程序的方法论,旨在充分利用云计算的优势,如弹性、自动化和可扩展性,以实现更高效、可靠和灵活的应用部署和管理。以下是云原生架构的核心理念和关键特点: 核心理念…...

《UDS协议从入门到精通》系列——图解0x84:安全数据传输
《UDS协议从入门到精通》系列——图解0x84:安全数据传输 一、简介二、数据包格式2.1 服务请求格式2.2 服务响应格式2.2.1 肯定响应2.2.2 否定响应 Tip📌:本文描述中但凡涉及到其他UDS服务的,均提供专栏内文章链接跳转方式以便快速…...

AFT:Attention Free Transformer论文笔记
原文链接 2105.14103 (arxiv.org) 原文翻译 Abstract 我们介绍了 Attention Free Transformer (AFT),这是 Transformer [1] 的有效变体,它消除了点积自注意力的需要。在 AFT 层,键key和值value首先与一组学习的位置偏差position biases相结…...

Linux grep技巧 结合awk查询
目录 一. 前提1.1 数据准备1.2 数据说明 二. 查询2.1 统计每个加盟店搜索的次数 一. 前提 1.1 数据准备 ⏹file1.log 140 2024/07/08 12:35:01.547 c1server2 5485 [ERROR] SPLREQUEST seqNo11459,eventControllerPMT.payinfoforprc.test.search,oldest_data_search2 110 20…...

关于Qt模型插入最后一行数据中存在未填满的项,点击导致崩溃的解决办法
在使用Qt模型视图框架的时候,你可能会遇见这种情况:给QTableView设置设置模型的时候,网模型里面插入数据,因为数据是一行一行插入的,即要使用model的appandRow函数,但有时候最后一行数据没有填满一行&#…...
Interpretability 与 Explainability 机器学习
「AI秘籍」系列课程: 人工智能应用数学基础人工智能Python基础人工智能基础核心知识人工智能BI核心知识人工智能CV核心知识 Interpretability 模型和 Explainability 模型之间的区别以及为什么它可能不那么重要 当你第一次深入可解释机器学习领域时,你会…...

Vue3项目如何使用npm link本地测试组件库
一、组件库操作 1、在组件库项目中先运行npm run lib,其效果如下 2、在组件库项目中在运行npm link,其效果如下 会创建一个全局的软连接指向本地的组件库 二、Vue3项目使用 1、在项目中运行 npm link 组件名称(即:组件库packag…...
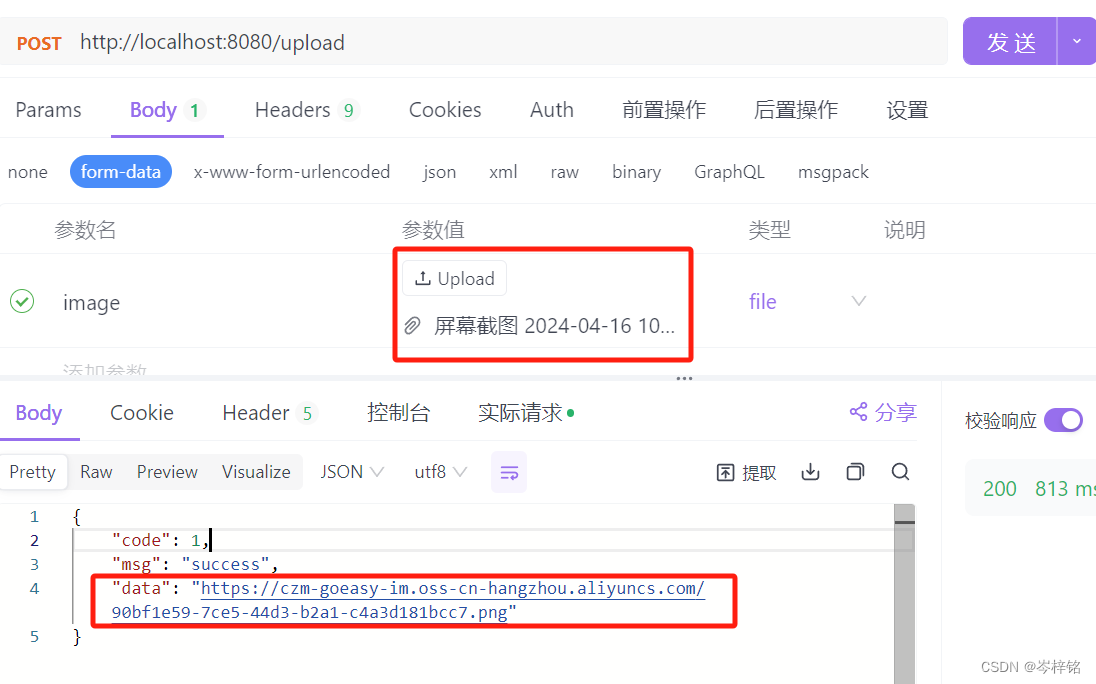
后端之路——阿里云OSS云存储
一、何为阿里云OSS 全名叫“阿里云对象存储OSS”,就是云存储,前端发文件到服务器,服务器不用再存到本地磁盘,可以直接传给“阿里云OSS”,存在网上。 二、怎么用 大体逻辑: 细分的话就是: 1、准…...

大模型/NLP/算法面试题总结2——transformer流程//多头//clip//对比学习//对比学习损失函数
用语言介绍一下Transformer的整体流程 1. 输入嵌入(Input Embedding) 输入序列(如句子中的单词)首先通过嵌入层转化为高维度的向量表示。嵌入层的输出是一个矩阵,每一行对应一个输入单词的嵌入向量。 2. 位置编码&…...

【atcoder】习题——位元枚举
题意:求i&M的popcount的和,i属于0……N 主要思路还是变加为乘。 举个例子N22,即10110 假设M的第3位是1,分析N中: 00110 00111 00100 00101 发现其实等价于 0010 0011 0000 0001 也就是左边第4位和第5…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...