Java Executors类的9种创建线程池的方法及应用场景分析
在Java中,Executors 类提供了多种静态工厂方法来创建不同类型的线程池。在学习线程池的过程中,一定避不开Executors类,掌握这个类的使用、原理、使用场景,对于实际项目开发时,运用自如,以下是一些常用的方法,V哥来一一细说:
-
newCachedThreadPool(): 创建一个可缓存的线程池,如果线程池中的线程超过60秒没有被使用,它们将被终止并从缓存中移除。 -
newFixedThreadPool(int nThreads): 创建一个固定大小的线程池,其中 nThreads 指定了线程池中线程的数量。 -
newSingleThreadExecutor(): 创建一个单线程的执行器,它创建单个工作线程来执行任务。 -
newScheduledThreadPool(int corePoolSize): 创建一个固定大小的线程池,它可以根据需要创建新线程,但会按照固定延迟执行具有给定初始延迟的任务。 -
newWorkStealingPool(int parallelism): 创建一个工作窃取线程池,它使用多个队列,每个线程都从自己的队列中窃取任务。 -
newSingleThreadScheduledExecutor(): 创建一个单线程的调度执行器,它可以根据需要创建新线程来执行任务。 -
privilegedThreadFactory(): 创建一个线程工厂,用于创建具有特权访问的线程。 -
defaultThreadFactory(): 创建一个默认的线程工厂,用于创建具有非特权访问的线程。 -
unconfigurableExecutorService(ExecutorService executor): 将给定的 ExecutorService 转换为不可配置的版本,这样调用者就不能修改它的配置。
这些方法提供了灵活的方式来创建和管理线程池,以满足不同的并发需求,下面 V 哥来一一介绍一下9个方法的实现以及使用场景。
1. newCachedThreadPool()
newCachedThreadPool 方法是 Java java.util.concurrent 包中的 Executors 类的一个静态工厂方法。这个方法用于创建一个可缓存的线程池,它能够根据需要创建新线程,并且当线程空闲超过一定时间后,线程会被终止并从线程池中移除。
下面是 newCachedThreadPool 方法的大致实现原理和源代码分析:
实现原理
- 线程创建: 当提交任务到线程池时,如果线程池中的线程数少于核心线程数,会创建新的线程来执行任务。
- 线程复用: 如果线程池中的线程数已经达到核心线程数,新提交的任务会被放入任务队列中等待执行。
- 线程回收: 如果线程池中的线程在一定时间内(默认是60秒)没有任务执行,它们会被终止,从而减少资源消耗。
源代码分析
在 Java 的 java.util.concurrent 包中,Executors 类并没有直接提供 newCachedThreadPool 的实现,而是通过调用 ThreadPoolExecutor 类的构造函数来实现的。以下是 ThreadPoolExecutor 构造函数的调用示例:
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
参数解释:
- corePoolSize: 核心线程数,这里设置为0,表示线程池不会保留任何核心线程。
- maximumPoolSize: 最大线程数,这里设置为 Integer.MAX_VALUE,表示理论上可以创建无限多的线程。
- keepAliveTime: 当线程数大于核心线程数时,多余的空闲线程能等待新任务的最长时间,这里设置为60秒。
- unit: keepAliveTime 参数的时间单位,这里是秒。
- workQueue: 一个任务队列,这里使用的是 SynchronousQueue,它是一个不存储元素的阻塞队列,每个插入操作必须等待一个相应的移除操作。
实现过程
- 初始化: 当调用 newCachedThreadPool 时,会创建一个 ThreadPoolExecutor 实例。
- 任务提交: 当任务提交给线程池时,线程池会检查是否有空闲线程可以立即执行任务。
- 线程创建: 如果没有空闲线程,并且当前线程数小于 maximumPoolSize,则创建新线程执行任务。
- 任务队列: 如果当前线程数已经达到 maximumPoolSize,则将任务放入 SynchronousQueue 中等待。
- 线程复用: 当一个线程执行完任务后,它不会立即终止,而是尝试从 SynchronousQueue 中获取新任务。
- 线程回收: 如果线程在 keepAliveTime 时间内没有获取到新任务,它将被终止。
这种设计使得 newCachedThreadPool 非常适合处理大量短生命周期的任务,因为它可以动态地调整线程数量以适应任务负载的变化。然而,由于它可以创建无限多的线程,如果没有适当的任务队列来控制任务的数量,可能会导致资源耗尽。因此,在使用 newCachedThreadPool 时,需要谨慎考虑任务的特性和系统的资源限制。
使用场景:
适用于执行大量短期异步任务,尤其是任务执行时间不确定的情况。例如,Web服务器处理大量并发请求,或者异步日志记录。
2. newFixedThreadPool(int nThreads)
newFixedThreadPool(int nThreads) 是 Java 中 java.util.concurrent 包的 Executors 类的一个静态工厂方法。这个方法用于创建一个固定大小的线程池,它能够确保线程池中始终有固定数量的线程在工作。
以下是 newFixedThreadPool 方法的实现原理、源代码分析以及实现过程:
实现原理
- 固定线程数: 线程池中的线程数量始终保持为 nThreads。
- 任务队列: 提交的任务首先由核心线程执行,如果核心线程都在忙碌状态,新任务将被放入一个阻塞队列中等待执行。
- 线程复用: 线程池中的线程会重复利用,执行完一个任务后,会立即尝试从队列中获取下一个任务执行。
源代码分析
newFixedThreadPool 方法是通过调用 ThreadPoolExecutor 类的构造函数来实现的。以下是 ThreadPoolExecutor 构造函数的调用示例:
public static ExecutorService newFixedThreadPool(int nThreads) {return new ThreadPoolExecutor(nThreads, // 核心线程数nThreads, // 最大线程数0L, // 线程空闲时间,这里设置为0,表示线程不会空闲TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>() // 使用阻塞队列来存储任务);
}
参数解释:
- corePoolSize: 核心线程数,这里设置为 nThreads,表示线程池中始终有 nThreads 个线程。
- maximumPoolSize: 最大线程数,这里也设置为 nThreads,表示线程池的线程数量不会超过 nThreads。
- keepAliveTime: 当线程数大于核心线程数时,多余的空闲线程能等待新任务的最长时间,这里设置为0,表示如果线程池中的线程数超过核心线程数,这些线程将立即终止。
- unit: keepAliveTime 参数的时间单位,这里是毫秒。
- workQueue: 一个任务队列,这里使用的是 LinkedBlockingQueue,它是一个基于链表的阻塞队列,可以存储任意数量的任务。
实现过程
- 初始化: 当调用 newFixedThreadPool 时,会创建一个 ThreadPoolExecutor 实例。
- 任务提交: 当任务提交给线程池时,线程池会检查是否有空闲的核心线程可以立即执行任务。
- 任务队列: 如果所有核心线程都在忙碌状态,新提交的任务将被放入 LinkedBlockingQueue 中等待。
- 线程复用: 核心线程执行完一个任务后,会尝试从 LinkedBlockingQueue 中获取新任务继续执行。
- 线程数量控制: 由于 keepAliveTime 设置为0,当线程池中的线程数超过核心线程数时,这些线程会立即终止,从而保证线程池中的线程数量不会超过 nThreads。
这种设计使得 newFixedThreadPool 非常适合处理大量且持续的任务,因为它可以保证任务以固定的线程数量并行执行,同时避免了线程数量的无限制增长。然而,由于线程池的大小是固定的,如果任务提交的速率超过了线程池的处理能力,可能会导致任务在队列中等待较长时间。因此,在使用 newFixedThreadPool 时,需要根据任务的特性和预期的负载来合理设置 nThreads 的值。
使用场景:
适用于执行大量长期运行的任务,其中线程数量需要固定。例如,同时运行多个数据加载或数据处理任务,且希望限制并发数以避免资源过载。
3. newSingleThreadExecutor()
newSingleThreadExecutor 是 Java 中 java.util.concurrent 包的 Executors 类的一个静态工厂方法,用于创建一个单线程的执行器。这个执行器确保所有任务都按照任务提交的顺序,在一个线程中顺序执行。
以下是 newSingleThreadExecutor 方法的实现原理、源代码分析以及实现过程:
实现原理
- 单线程执行: 线程池中只有一个线程,所有任务都由这个线程顺序执行。
- 任务队列: 如果这个线程在执行任务时有新任务提交,新任务会被放入一个阻塞队列中等待执行。
- 线程复用: 这个线程会重复利用,执行完一个任务后,会立即尝试从队列中获取下一个任务执行。
源代码分析
newSingleThreadExecutor 方法同样是通过调用 ThreadPoolExecutor 类的构造函数来实现的。以下是 ThreadPoolExecutor 构造函数的调用示例:
public static ExecutorService newSingleThreadExecutor() {return new ThreadPoolExecutor(1, // 核心线程数1, // 最大线程数0L, TimeUnit.MILLISECONDS, // 线程空闲时间,这里设置为0,表示线程不会空闲new LinkedBlockingQueue<Runnable>() // 使用阻塞队列来存储任务);
}
参数解释:
- corePoolSize: 核心线程数,这里设置为1,表示线程池中始终有一个核心线程。
- maximumPoolSize: 最大线程数,这里也设置为1,表示线程池的线程数量不会超过1。
- keepAliveTime: 线程空闲时间,这里设置为0,表示如果线程空闲,它将立即终止。
- unit: keepAliveTime 参数的时间单位,这里是毫秒。
- workQueue: 一个任务队列,这里使用的是 LinkedBlockingQueue,它是一个无界队列,可以存储任意数量的任务。
实现过程
- 初始化: 当调用 newSingleThreadExecutor 时,会创建一个 ThreadPoolExecutor 实例。
- 任务提交: 当任务提交给线程池时,如果核心线程空闲,则立即执行任务;如果核心线程忙碌,则将任务放入 LinkedBlockingQueue 中等待。
- 顺序执行: 由于只有一个线程,所有任务都将按照提交的顺序被执行。
- 任务队列: 如果核心线程在执行任务,新提交的任务将被放入 LinkedBlockingQueue 中排队等待。
- 线程复用: 核心线程执行完一个任务后,会尝试从 LinkedBlockingQueue 中获取新任务继续执行。
- 线程数量控制: 由于 keepAliveTime 设置为0,核心线程在没有任务执行时会立即终止。但由于 corePoolSize 和 maximumPoolSize 都为1,线程池会立即重新创建一个线程。
这种设计使得 newSingleThreadExecutor 非常适合处理需要保证任务顺序的场景,例如,当任务之间有依赖关系或者需要按照特定顺序执行时。同时,由于只有一个线程,这也避免了多线程环境下的并发问题。然而,由于只有一个线程执行任务,这也限制了并行处理的能力,如果任务执行时间较长,可能会导致后续任务等待较长时间。因此,在使用 newSingleThreadExecutor 时,需要根据任务的特性和对顺序的要求来决定是否适用。
使用场景:
适用于需要保证任务顺序执行的场景,例如,顺序处理队列中的消息或事件。也适用于需要单个后台线程持续处理周期性任务的情况。
4. newScheduledThreadPool(int corePoolSize)
newScheduledThreadPool 是 Java 中 java.util.concurrent 包的 Executors 类的一个静态工厂方法,用于创建一个固定大小的线程池,这个线程池支持定时以及周期性的任务执行。
以下是 newScheduledThreadPool 方法的实现原理、源代码分析以及实现过程:
实现原理
- 定时任务: 线程池能够按照指定的延迟执行任务,或者以固定间隔周期性地执行任务。
- 固定线程数: 线程池中的线程数量被限制为 corePoolSize 指定的大小。
- 任务队列: 任务首先由核心线程执行,如果核心线程都在忙碌状态,新任务将被放入一个延迟任务队列中等待执行。
源代码分析
newScheduledThreadPool 方法是通过调用 ScheduledThreadPoolExecutor 类的构造函数来实现的。以下是 ScheduledThreadPoolExecutor 构造函数的调用示例:
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {return new ScheduledThreadPoolExecutor(corePoolSize);
}
这里的 ScheduledThreadPoolExecutor 是 ThreadPoolExecutor 的一个子类,专门为执行定时任务设计。ScheduledThreadPoolExecutor 构造函数的参数 corePoolSize 定义了线程池中核心线程的数量。
ScheduledThreadPoolExecutor 内部使用了一个 DelayedWorkQueue 作为任务队列,这个队列能够按照任务的预定执行时间对任务进行排序。
实现过程
- 初始化: 当调用 newScheduledThreadPool 时,会创建一个 ScheduledThreadPoolExecutor 实例。
- 任务提交: 当任务提交给线程池时,线程池会根据任务的预定执行时间,将任务放入 DelayedWorkQueue 中。
- 任务调度: 线程池中的线程会从 DelayedWorkQueue 中获取任务,如果任务的执行时间已经到达,线程将执行该任务。
- 线程复用: 执行完一个任务的线程会再次尝试从 DelayedWorkQueue 中获取下一个任务。
- 线程数量控制: 如果任务队列中的任务数量超过了核心线程能够处理的范围,ScheduledThreadPoolExecutor 会创建新的线程来帮助处理任务,直到达到 corePoolSize 指定的最大线程数。
特点
- ScheduledThreadPoolExecutor 允许设置一个线程工厂,用于创建具有特定属性的线程。
- 它还允许设置一个 RejectedExecutionHandler,当任务无法被接受时(例如,线程池关闭或任务队列已满),这个处理器会被调用。
- 与 ThreadPoolExecutor 不同,ScheduledThreadPoolExecutor 的 shutdown 和 shutdownNow 方法不会等待延迟任务执行完成。
使用 newScheduledThreadPool 创建的线程池非常适合需要执行定时任务的场景,例如,定期执行的后台任务、定时检查等。然而,由于它是基于固定大小的线程池,所以在高负载情况下,任务可能会排队等待执行,这需要在设计时考虑适当的 corePoolSize 以满足性能要求。
使用场景:
适用于需要定期执行任务或在将来某个时间点执行任务的场景。例如,定时备份数据、定时发送提醒等。
5. newWorkStealingPool(int parallelism)
newWorkStealingPool 是 Java 8 中新增的 java.util.concurrent 包的 Executors 类的一个静态工厂方法。这个方法用于创建一个工作窃取(Work-Stealing)线程池,它能够提高并行任务的执行效率,特别是在多处理器系统上。
实现原理
- 工作窃取: 在工作窃取线程池中,每个线程都有自己的任务队列。当一个线程完成自己的任务后,它会尝试从其他线程的任务队列中“窃取”任务来执行。
- 并行级别: 线程池的大小由 parallelism 参数决定,这个参数通常等于主机上的处理器核心数。
- 动态调整: 工作窃取线程池可以动态地添加或移除线程,以适应任务的负载和线程的利用率。
源代码分析
newWorkStealingPool 方法是通过调用 ForkJoinPool 类的静态工厂方法 commonPoolFor 来实现的。以下是 ForkJoinPool 构造函数的调用示例:
public static ExecutorService newWorkStealingPool(int parallelism) {return new ForkJoinPool(parallelism,ForkJoinPool.defaultForkJoinWorkerThreadFactory,null, // 没有未处理的异常处理器false // 不是一个异步任务);
}
参数解释:
- parallelism: 线程池的并行级别,即线程池中的线程数量。
- ForkJoinPool.defaultForkJoinWorkerThreadFactory: 默认的线程工厂,用于创建线程。
- null: 未处理的异常处理器,这里没有指定,因此如果任务抛出未捕获的异常,它将被传播到 ForkJoinTask 的调用者。
- false: 表示这不是一个异步任务。
ForkJoinPool 内部使用了 ForkJoinWorkerThread 来执行任务,并且每个线程都有一个 ForkJoinQueue 来存储任务。
实现过程
- 初始化: 当调用 newWorkStealingPool 时,会创建一个 ForkJoinPool 实例。
- 任务提交: 当任务提交给线程池时,它们会被放入调用线程的本地队列中。
- 任务执行: 每个线程首先尝试执行其本地队列中的任务。
- 工作窃取: 如果本地队列为空,线程会尝试从其他线程的队列中窃取任务来执行。
- 动态调整: 线程池可以根据需要动态地添加或移除线程。
特点
- 工作窃取线程池特别适合于工作量不均匀分布的任务,因为它可以减少空闲时间并提高资源利用率。
- 它也适用于可分解为多个子任务的并行计算任务,因为可以将任务分解后,再将子任务提交给线程池。
- 由于每个线程都有自己的队列,因此减少了锁的争用,提高了并发性能。
使用 newWorkStealingPool 创建的线程池非常适合于需要高并发和高吞吐量的场景,尤其是在多处理器系统上。然而,由于工作窃取机制,它可能不适用于任务执行时间非常短或者任务数量非常少的场景,因为窃取任务本身可能会引入额外的开销。
使用场景:
适用于工作量不均匀或可分解为多个小任务的并行计算任务。例如,图像处理、数据分析等,可以在多核处理器上有效利用所有核心。
6. newSingleThreadScheduledExecutor()
newSingleThreadScheduledExecutor 是 Java 中 java.util.concurrent 包的 Executors 类的一个静态工厂方法。这个方法用于创建一个单线程的调度执行器,它可以安排命令在给定的延迟后运行,或者定期地执行。
以下是 newSingleThreadScheduledExecutor 方法的实现原理、源代码分析以及实现过程:
实现原理
- 单线程执行: 执行器确保所有任务都在单个线程中顺序执行,这保证了任务的执行顺序。
- 定时任务: 支持延迟执行和周期性执行任务。
- 任务队列: 所有任务首先被放入一个任务队列中,然后由单线程按顺序执行。
源代码分析
newSingleThreadScheduledExecutor 方法是通过调用 ScheduledThreadPoolExecutor 类的构造函数来实现的。以下是 ScheduledThreadPoolExecutor 构造函数的调用示例:
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {return new ScheduledThreadPoolExecutor(1);
}
这里,ScheduledThreadPoolExecutor 是 ExecutorService 的一个实现,专门为执行定时任务设计。构造函数只有一个参数,即核心线程数,这里设置为1,表示这是一个单线程的执行器。
ScheduledThreadPoolExecutor 内部使用了一个 DelayedWorkQueue 作为任务队列,这个队列能够按照任务的预定执行时间对任务进行排序。
实现过程
- 初始化: 当调用 newSingleThreadScheduledExecutor 时,会创建一个 ScheduledThreadPoolExecutor 实例,其核心线程数为1。
- 任务提交: 当任务提交给执行器时,任务会被封装成 ScheduledFutureTask 或者 RunnableScheduledFuture,然后放入 DelayedWorkQueue 中。
- 任务调度: 单线程会不断地从 DelayedWorkQueue 中获取任务,并按照预定的时间执行。如果任务的执行时间已经到达,任务将被执行;如果还没有到达,线程会等待直到执行时间到来。
- 顺序执行: 由于只有一个线程,所有任务都将按照它们被提交的顺序被执行。
- 周期性任务: 对于需要周期性执行的任务,执行器会在每次任务执行完毕后,重新计算下一次执行的时间,并再次将任务放入队列。
特点
- newSingleThreadScheduledExecutor 创建的执行器非常适合需要保证任务顺序的场景,例如,需要按照特定顺序执行的任务或者具有依赖关系的任务。
- 它也适合执行定时任务,如定期执行的维护任务或者后台任务。
- 由于只有一个线程,这也避免了多线程环境下的并发问题,简化了任务同步和状态管理。
使用 newSingleThreadScheduledExecutor 创建的执行器可以提供强大的定时任务功能,同时保持任务执行的顺序性。然而,由于只有一个线程执行任务,这也限制了并行处理的能力,如果任务执行时间较长,可能会导致后续任务等待较长时间。因此,在使用 newSingleThreadScheduledExecutor 时,需要根据任务的特性和对顺序的要求来决定是否适用。
使用场景:
适用于需要单个后台线程按计划执行任务的场景。例如,定时检查系统状态、定时执行维护任务等。
7. privilegedThreadFactory()
privilegedThreadFactory 是 Java 中 java.util.concurrent 包的 Executors 类的一个静态工厂方法,用于创建一个线程工厂,该工厂能够产生具有特权访问的线程。这意味着这些线程可以加载系统属性和库,并且可以访问文件系统。
以下是 privilegedThreadFactory 方法的实现原理、源代码分析以及实现过程:
实现原理
- 特权访问: 创建的线程将具有访问系统资源的权限,例如,加载系统属性和库。
- 线程创建: 线程工厂将创建新的线程实例,这些线程实例将继承创建它们的线程的上下文。
源代码分析
在 Java 的标准库中,privilegedThreadFactory 方法的实现细节并未公开,因为它是一个私有方法。然而,我们可以分析其大致工作原理。privilegedThreadFactory 方法的调用示例如下:
public static ThreadFactory privilegedThreadFactory() {return new PrivilegedThreadFactory();
}
这里,PrivilegedThreadFactory 是 Executors 类的一个私有静态内部类,它实现了 ThreadFactory 接口。ThreadFactory 接口定义了一个 newThread(Runnable r) 方法,用于创建新的线程。
实现过程
- 初始化: 当调用 privilegedThreadFactory 方法时,会返回一个新的 PrivilegedThreadFactory 实例。
- 线程创建: 当使用这个工厂创建线程时,它会调用 newThread(Runnable r) 方法。
- 特权访问: 在 newThread(Runnable r) 方法的实现中,会使用 AccessController.doPrivileged 方法来确保新创建的线程具有特权访问。
- 上下文复制: 通常,新线程会复制创建它的线程的上下文,包括类加载器等。
示例代码
虽然我们不能查看 privilegedThreadFactory 的具体实现,但是我们可以提供一个示例实现,以展示如何创建具有特权访问的线程:
public class PrivilegedThreadFactory implements ThreadFactory {@Overridepublic Thread newThread(Runnable r) {return AccessController.doPrivileged(new PrivilegedAction<>() {@Overridepublic Thread run() {return new Thread(r);}});}
}
在这个示例中,PrivilegedAction 是一个实现了 PrivilegedAction<T> 接口的匿名类,其 run 方法创建了一个新的线程。AccessController.doPrivileged 方法用于执行一个特权操作,这里是为了确保线程创建过程中具有必要的权限。
特点
- 使用 privilegedThreadFactory 创建的线程可以在需要访问敏感系统资源的情况下使用。
- 这种线程工厂通常用于需要执行特权操作的应用程序,例如,访问系统属性或者执行文件 I/O 操作。
使用 privilegedThreadFactory 可以确保线程在执行任务时具有适当的安全权限,从而避免安全异常。然而,需要注意的是,过度使用特权访问可能会带来安全风险,因此在设计应用程序时应谨慎使用。
使用场景:
适用于需要线程具有更高权限来访问系统资源的场景。例如,需要访问系统属性或执行文件I/O操作的应用程序。
8. defaultThreadFactory()
defaultThreadFactory 是 Java 中 java.util.concurrent 包的 Executors 类的一个静态工厂方法,用于创建一个默认的线程工厂。这个线程工厂生成的线程没有特殊的权限,它们是普通的线程,具有标准的访问权限。
以下是 defaultThreadFactory 方法的实现原理、源代码分析以及实现过程:
实现原理
- 标准线程创建: 创建的线程工厂将生成具有默认属性的线程。
- 线程名称: 生成的线程具有默认的线程名称前缀,通常是 “pool-x-thread-y”,其中 x 和 y 是数字。
- 线程优先级: 线程的优先级设置为 Thread.NORM_PRIORITY,这是 Java 线程的默认优先级。
- 非守护线程: 创建的线程不是守护线程(daemon threads),它们的存在不会阻止 JVM 退出。
源代码分析
Java 的 defaultThreadFactory 方法的具体实现细节并未完全公开,因为它是 Executors 类的一个私有静态方法。但是,我们可以根据 Java 的 ThreadFactory 接口和一些公开的源代码片段来分析其大致实现。
以下是 defaultThreadFactory 方法的调用示例:
public static ThreadFactory defaultThreadFactory() {return new DefaultThreadFactory();
}
这里,DefaultThreadFactory 是 Executors 类的一个私有静态内部类,它实现了 ThreadFactory 接口。ThreadFactory 接口定义了一个 newThread(Runnable r) 方法,用于创建新的线程。
实现过程
- 初始化: 当调用 defaultThreadFactory 方法时,会返回一个新的 DefaultThreadFactory 实例。
- 线程创建: 使用这个工厂创建线程时,它会调用 newThread(Runnable r) 方法。
- 设置线程名称: 在 newThread(Runnable r) 方法的实现中,会创建一个新的 Thread 对象,并设置一个默认的线程名称。
- 设置线程组: 新线程会被分配到一个默认的线程组中。
- 线程优先级和守护状态: 线程的优先级设置为默认值,且线程不是守护线程。
示例代码
虽然我们不能查看 defaultThreadFactory 的具体实现,但是我们可以提供一个示例实现,以展示如何创建具有默认属性的线程:
public class DefaultThreadFactory implements ThreadFactory {private static final AtomicInteger poolNumber = new AtomicInteger(1);private final ThreadGroup group;private final AtomicInteger threadNumber = new AtomicInteger(1);private final String namePrefix;DefaultThreadFactory() {SecurityManager s = System.getSecurityManager();group = (s != null) ? s.getThreadGroup() : Thread.currentThread().getThreadGroup();namePrefix = "pool-" +poolNumber.getAndIncrement() +"-thread-";}public Thread newThread(Runnable r) {Thread t = new Thread(group, r,namePrefix + threadNumber.getAndIncrement(),0);if (t.isDaemon())t.setDaemon(false);if (t.getPriority() != Thread.NORM_PRIORITY)t.setPriority(Thread.NORM_PRIORITY);return t;}
}
在这个示例中,DefaultThreadFactory 使用 AtomicInteger 来确保线程池和线程编号的唯一性。创建的线程名称具有前缀 “pool-x-thread-y”,其中 x 和 y 是自增的数字。线程不是守护线程,且优先级设置为 Thread.NORM_PRIORITY。
特点
- 使用 defaultThreadFactory 创建的线程工厂生成的线程具有标准的 Java 线程属性。
- 这种线程工厂通常用于不需要特殊权限的应用程序。
- 由于线程不是守护线程,它们的存在可以维持 JVM 的运行,直到所有非守护线程执行完毕。
使用 defaultThreadFactory 可以确保线程在执行任务时具有标准的安全和执行属性,适合大多数常规用途。然而,如果应用程序需要特殊的线程属性,如守护线程或不同的优先级,可能需要自定义线程工厂。
使用场景:
适用于大多数标准应用程序,需要创建具有默认属性的线程。这是大多数 ExecutorService 实现的默认选择。
9. unconfigurableExecutorService(ExecutorService executor)
unconfigurableExecutorService 是 Java 中 java.util.concurrent 包的 Executors 类的一个静态工厂方法。这个方法用于创建一个不可配置的 ExecutorService 包装器,这意味着一旦包装后的 ExecutorService 被创建,就不能更改其配置,比如不能修改其线程池大小或任务队列等。
以下是 unconfigurableExecutorService 方法的实现原理、源代码分析以及实现过程:
实现原理
- 封装: 将现有的 ExecutorService 封装在一个不可配置的代理中。
- 不可修改: 所有修改配置的方法调用,如 shutdown, shutdownNow, setCorePoolSize 等,都将抛出 UnsupportedOperationException。
- 转发: 除了配置修改的方法外,其他方法调用将被转发到原始的 ExecutorService。
源代码分析
unconfigurableExecutorService 方法的具体实现细节并未完全公开,因为它是 Executors 类的一个私有静态方法。但是,我们可以根据 Java 的 ExecutorService 接口和代理机制来分析其大致实现。
以下是 unconfigurableExecutorService 方法的调用示例:
public static ExecutorService unconfigurableExecutorService(ExecutorService executor) {return new FinalizableDelegatedExecutorService(executor);
}
这里,FinalizableDelegatedExecutorService 是 Executors 类的一个私有静态内部类,它实现了 ExecutorService 接口,并代理了对另一个 ExecutorService 的调用。
实现过程
- 初始化: 当调用 unconfigurableExecutorService 方法时,会返回一个新的 FinalizableDelegatedExecutorService 实例,它将原始的 ExecutorService 作为参数。
- 方法调用拦截: 对 FinalizableDelegatedExecutorService 的方法调用将首先被拦截。
- 配置修改拦截: 如果调用的方法是用于修改配置的,比如 shutdown 或 shutdownNow,将抛出 UnsupportedOperationException。
- 转发其他调用: 对于其他不涉及配置修改的方法调用,比如 submit, execute, 将被转发到原始的 ExecutorService。
示例代码
下面V哥来模拟一个示例实现,以展示如何创建一个不可配置的 ExecutorService 代理:
public class UnconfigurableExecutorService implements ExecutorService {private final ExecutorService executor;public UnconfigurableExecutorService(ExecutorService executor) {this.executor = executor;}@Overridepublic void shutdown() {throw new UnsupportedOperationException("Shutdown not allowed");}@Overridepublic List<Runnable> shutdownNow() {throw new UnsupportedOperationException("Shutdown not allowed");}@Overridepublic boolean isShutdown() {return executor.isShutdown();}@Overridepublic boolean isTerminated() {return executor.isTerminated();}@Overridepublic void execute(Runnable command) {executor.execute(command);}// 其他 ExecutorService 方法的实现,遵循相同的模式
}
在这个示例中,UnconfigurableExecutorService 拦截了 shutdown 和 shutdownNow 方法,并抛出了异常。其他方法则直接转发到原始的 ExecutorService。
特点
- 使用 unconfigurableExecutorService 创建的 ExecutorService 代理确保了线程池的配置不能被外部修改。
- 这可以用于防止意外地更改线程池的状态,提高线程池使用的安全性。
- 除了配置修改的方法外,其他所有方法都保持了原有 ExecutorService 的行为。
使用 unconfigurableExecutorService 可以为现有的 ExecutorService 提供一个安全层,确保它们的状态不会被意外地更改。这对于在多线程环境中共享 ExecutorService 时特别有用。
使用场景:
适用于需要确保线程池配置在创建后不被更改的场景。例如,当多个组件共享同一个线程池时,可以防止一个组件意外修改配置。
最后
以上是V哥在授课过程中整理的关于Executors 9种创建线程池的方法及原理分析,分享给大家,希望对正在学习 Java 的你有所帮助,每天分享技术干货,欢迎关注威哥爱编程,你的鼓励是V哥技术创作路上的助推器,不喜勿喷,感谢。
相关文章:

Java Executors类的9种创建线程池的方法及应用场景分析
在Java中,Executors 类提供了多种静态工厂方法来创建不同类型的线程池。在学习线程池的过程中,一定避不开Executors类,掌握这个类的使用、原理、使用场景,对于实际项目开发时,运用自如,以下是一些常用的方法…...

LY/T 3359-2023 耐化学腐蚀高压装饰层积板检测
耐化学腐蚀高压装饰层积板是指用酚醛树脂浸渍的层状植物纤维材料为基材,与涂布以丙烯酸树脂为主体的装饰纸的饰面层,在高温高压下层积压制而成的具有化学腐蚀功能的高压装饰层积板。 LY/T 3359-2023 耐化学腐蚀高压装饰层积板检测项目: 测试…...

【linux/shell】如何创建脚本函数库并在其他脚本中调用
目录 1. 创建脚本库文件 2. 修改脚本库权限,使脚本库可执行 3. 在其他脚本中调用脚本库 4. 使用环境变量或.bashrc 5. 使用Shellcheck 6. 编写注释及说明文档 在Shell中创建和使用脚本库通常涉及以下几个步骤: 1. 创建脚本库文件 脚本库通常是包…...

Instruct-GS2GS:通过用户指令编辑 GS 三维场景
Paper: Instruct-GS2GS: Editing 3D Gaussian Splats with Instructions Introduction: https://instruct-gs2gs.github.io/ Code: https://github.com/cvachha/instruct-gs2gs Instruct-GS2GS 复用了 Instruct-NeRF2NeRF 1 的架构,将基于 NeRF 的三维场景编辑方法迁…...
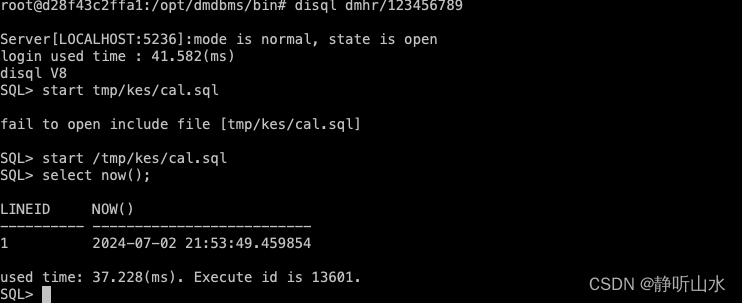
disql使用
SQL 交互式查询工具 | 达梦技术文档 进入bin目录:cd /opt/dmdbms/bin 启动disql:./disql,然后输入用户名、密码 sh文件直接使用disql: 临时添加路径到PATH环境变量:在当前会话中临时使用disql命令而无需每次都写完整…...

SpringBoot Mybatis-Plus 日志带参数
SpringBoot Mybatis-Plus 日志带参数 1 实现代码2 测试结果 在Spring Boot中,MyBatis插件机制通过拦截器(Interceptor)来实现。拦截器允许开发人员在执行SQL语句的各个阶段(如SQL语句创建、参数处理、结果映射等)插入自…...

【WebGIS平台】传统聚落建筑科普数字化建模平台
基于上述概括出建筑单体的特征部件,本文利用互联网、三维建模和地理信息等技术设计了基于浏览器/服务器(B/S)的传统聚落建筑科普数字化平台。该平台不仅实现了对传统聚落建筑风貌从基础到复杂的数字化再现,允许用户轻松在线构建从…...

Zookeeper分布式锁原理说明【简单易理解】
Zookeeper 非公平锁/公平锁/共享锁 。 1.zookeeper分布式锁加锁原理 如上实现方式在并发问题比较严重的情况下,性能会下降的比较厉害,主要原因是,所有的连接都在对同一个节点进行监听,当服务器检测到删除事件时,要通知…...

去除Win32 Tab Control控件每个选项卡上的深色对话框背景
一般情况下,我们是用不带边框的对话框来充当Tab Control的每个选项卡的内容的。 例如,主对话框IDD_TABBOX上有一个Tab Control,上面有两个选项卡,第一个选项卡用的是IDD_DIALOG1充当内容,第二个用的则是IDD_DIALOG2。I…...
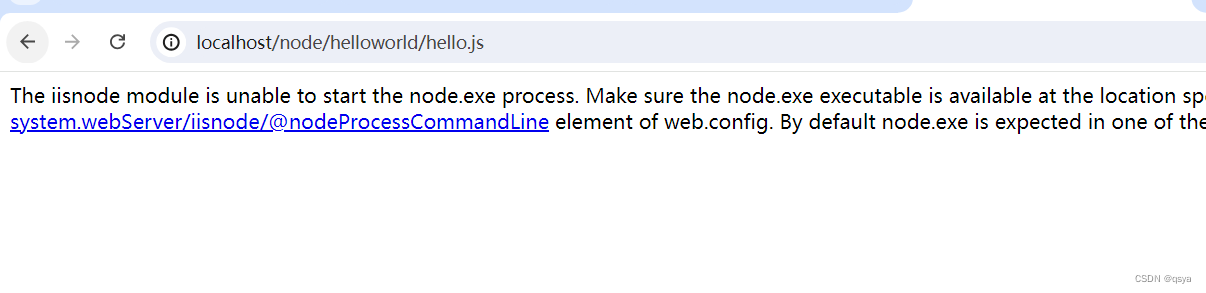
iis部署前后端分离项目(React前端,Node.js后端)
iis虽然已经有点过时,但不少用户还在用,故总结一下。 1. 安装iis 如果电脑没有自带iis管理器,打开控制面板->程序->启用或关闭Windows功能,勾选iis安装即可 2. 部署前端项目 打开iis,添加网站,物理…...

【前端项目笔记】9 数据报表
数据报表 效果展示: 在开发代码之前新建分支 git checkout -b report 新建分支report git branch 查看分支 git push -u origin report 将本地report分支推送到云端origin并命名为report 通过路由的形式将数据报表加载到页面中 渲染数据报表基本布局 面包屑导航…...

等保测评推动哈尔滨数字化转型中的安全保障
在数字经济的浪潮下,哈尔滨作为东北老工业基地的核心城市,正积极推动数字化转型,以创新技术驱动产业升级和经济发展。网络安全等级保护测评(简称“等保测评”)作为国家网络安全战略的重要组成部分,为哈尔滨…...

#pragma 指令
#pragma 指令作用是设定编译器的状态或者是指示编译器完成一些特定的动作 message 参数能够在编译信息输出窗口中输出相应的信息 #pragma message(“消息文本”) code_seg参数能够设置程序中函数代码存放的代码段,当我们开发驱动程序的时候就会使用到它 #pragma…...

【Excel】 批量跳转图片
目录标题 1. CtrlA全选图片 → 右键 → 大小和属性2. 取消 锁定纵横比 → 跳转高度宽度 → 关闭窗口3. 最后一图拉到最后一单元格 → Alt吸附边框4. CtrlA全选图片 → 对齐 → 左对齐 → 纵向分布!…...

网站更新改版了
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏:Leo杂谈 ✨特色专栏:MySQL学…...

初识大模型
前提:学习一项技术,要从原理、实践、认知三个方面进行攻克。 不懂原理就不会举一反三,走不了太远。 不懂实践就只能纸上谈兵,做事不落地。 认知不高就无法作对决策,天花板太低。 一、知识体系 二、什么是AI 基于机器…...

Open3D SVD算法实现对应点集配准
目录 一、概述 1.1基本思想 1.2实现步骤 二、代码实现 三、实现效果 3.1原始点云 3.2配准后点云 3.3变换矩阵 一、概述 在点云配准中,SVD(Singular Value Decomposition,奇异值分解)方法是一种常用的精确计算旋转和平移变换的算法。其目标是找到一个刚体变…...
bWAPP靶场安装
bWAPP安装 下载 git地址:https://github.com/raesene/bWAPP 百度网盘地址:链接:https://pan.baidu.com/s/1Y-LvHxyW7SozGFtHoc9PKA 提取码:4tt8 –来自百度网盘超级会员V5的分享 phpstudy中打开根目录,并将下载的文…...
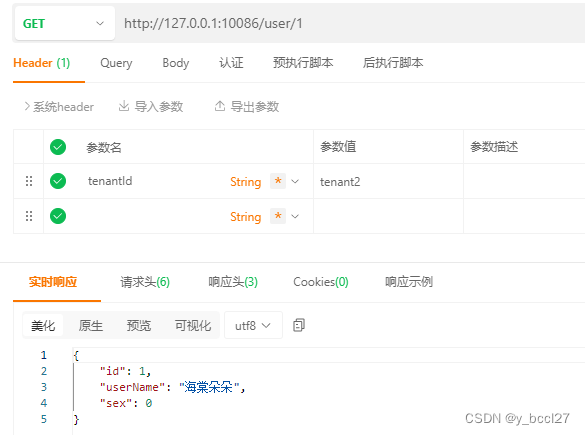
SpringBoot + MyBatisPlus 实现多租户分库
一、引言 在如今的软件开发中,多租户(Multi-Tenancy)应用已经变得越来越常见。多租户是一种软件架构技术,它允许一个应用程序实例为多个租户提供服务。每个租户都有自己的数据和配置,但应用程序实例是共享的。而在我们的Spring Boot MyBati…...

【数据挖掘】银行信用卡风险大数据分析与挖掘
银行信用卡风险大数据分析与挖掘 1、实验目的 中国某个商业银行高层发现自家信用卡存在严重的欺诈和拖欠现象,已经影响到自身经营和发展。银行高层希望大数据分析部门采用数据挖掘技术,对影响用户信用等级的主要因素进行分析,结合信用卡用户的人口特征属性对欺诈行为和拖欠…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...

Java多线程实现之Runnable接口深度解析
Java多线程实现之Runnable接口深度解析 一、Runnable接口概述1.1 接口定义1.2 与Thread类的关系1.3 使用Runnable接口的优势 二、Runnable接口的基本实现方式2.1 传统方式实现Runnable接口2.2 使用匿名内部类实现Runnable接口2.3 使用Lambda表达式实现Runnable接口 三、Runnabl…...

【题解-洛谷】P10480 可达性统计
题目:P10480 可达性统计 题目描述 给定一张 N N N 个点 M M M 条边的有向无环图,分别统计从每个点出发能够到达的点的数量。 输入格式 第一行两个整数 N , M N,M N,M,接下来 M M M 行每行两个整数 x , y x,y x,y,表示从 …...

以太网PHY布局布线指南
1. 简介 对于以太网布局布线遵循以下准则很重要,因为这将有助于减少信号发射,最大程度地减少噪声,确保器件作用,最大程度地减少泄漏并提高信号质量。 2. PHY设计准则 2.1 DRC错误检查 首先检查DRC规则是否设置正确,然…...